 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
RIS-aided Zero-Forcing and Regularized Zero-Forcing Beamforming in Integrated Information and Energy Delivery
Jan 08, 2022
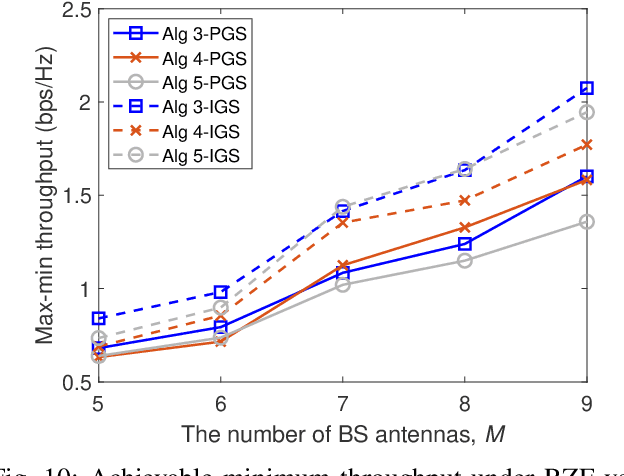
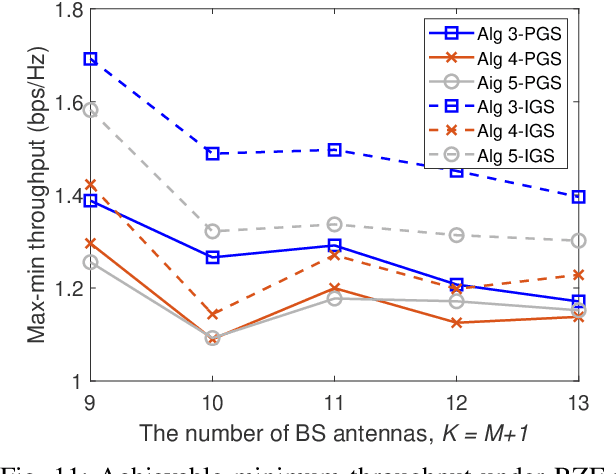
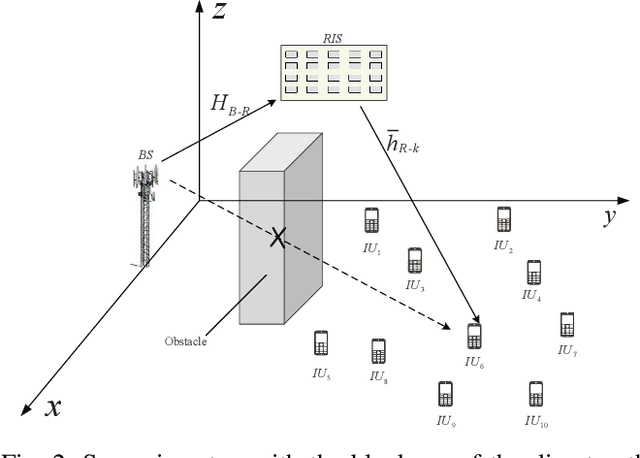
This paper considers a network of a multi-antenna array base station (BS) and a reconfigurable intelligent surface (RIS) to deliver both information to information users (IUs) and power to energy users (EUs). The RIS links the connection between the IUs and the BS as there is no direct path between the former and the latter. The EUs are located nearby the BS in order to effectively harvest energy from the high-power signal from the BS, while the much weaker signal reflected from the RIS hardly contributes to the EUs' harvested energy. To provide reliable links for all users over the same time-slot, we adopt the transmit time-switching (transmit-TS) approach, under which information and energy are delivered over different time-slot fractions. This allows us to rely on conjugate beamforming for energy links and zero-forcing/regularized zero-forcing beamforming (ZFB/RZFB) and on the programmable reflecting coefficients (PRCs) of the RIS for information links. We show that ZFB/RZFB and PRCs can be still separately optimized in their joint design, where PRC optimization is based on iterative closed-form expressions. We then develop a path-following algorithm for solving our max-min IU throughput optimization problem subject to a realistic constraint on the quality-of-energy-service in terms of the EUs' harvested energy thresholds. We also propose a new RZFB for substantially improving the IUs' throughput.
FPGA-optimized Hardware acceleration for Spiking Neural Networks
Jan 18, 2022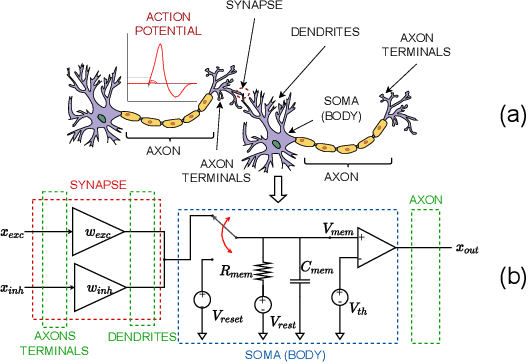
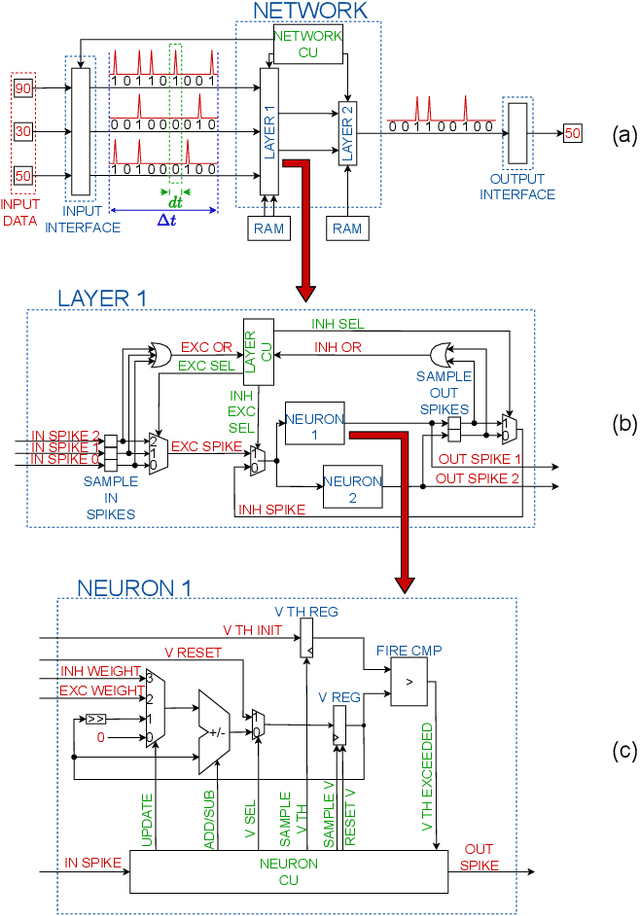
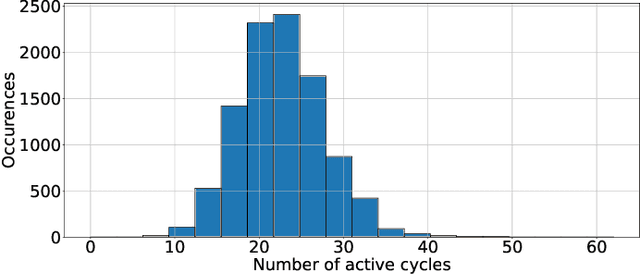
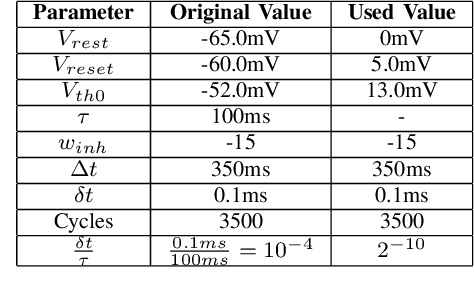
Artificial intelligence (AI) is gaining success and importance in many different tasks. The growing pervasiveness and complexity of AI systems push researchers towards developing dedicated hardware accelerators. Spiking Neural Networks (SNN) represent a promising solution in this sense since they implement models that are more suitable for a reliable hardware design. Moreover, from a neuroscience perspective, they better emulate a human brain. This work presents the development of a hardware accelerator for an SNN, with off-line training, applied to an image recognition task, using the MNIST as the target dataset. Many techniques are used to minimize the area and to maximize the performance, such as the replacement of the multiplication operation with simple bit shifts and the minimization of the time spent on inactive spikes, useless for the update of neurons' internal state. The design targets a Xilinx Artix-7 FPGA, using in total around the 40% of the available hardware resources and reducing the classification time by three orders of magnitude, with a small 4.5% impact on the accuracy, if compared to its software, full precision counterpart.
Manipulating UAV Imagery for Satellite Model Training, Calibration and Testing
Mar 22, 2022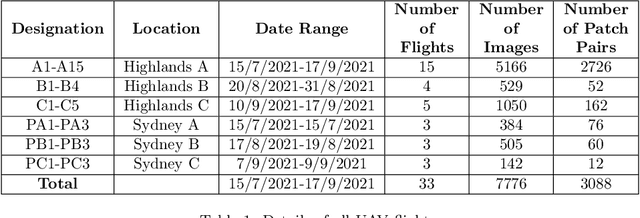


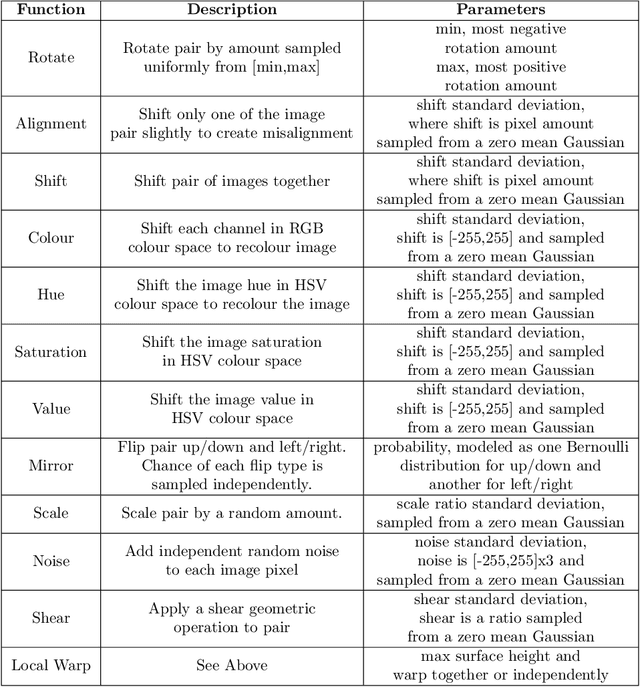
Modern livestock farming is increasingly data driven and frequently relies on efficient remote sensing to gather data over wide areas. High resolution satellite imagery is one such data source, which is becoming more accessible for farmers as coverage increases and cost falls. Such images can be used to detect and track animals, monitor pasture changes, and understand land use. Many of the data driven models being applied to these tasks require ground truthing at resolutions higher than satellites can provide. Simultaneously, there is a lack of available aerial imagery focused on farmland changes that occur over days or weeks, such as herd movement. With this goal in mind, we present a new multi-temporal dataset of high resolution UAV imagery which is artificially degraded to match satellite data quality. An empirical blurring metric is used to calibrate the degradation process against actual satellite imagery of the area. UAV surveys were flown repeatedly over several weeks, for specific farm locations. This 5cm/pixel data is sufficiently high resolution to accurately ground truth cattle locations, and other factors such as grass cover. From 33 wide area UAV surveys, 1869 patches were extracted and artificially degraded using an accurate satellite optical model to simulate satellite data. Geographic patches from multiple time periods are aligned and presented as sets, providing a multi-temporal dataset that can be used for detecting changes on farms. The geo-referenced images and 27,853 manually annotated cattle labels are made publicly available.
Nonnegative-Constrained Joint Collaborative Representation with Union Dictionary for Hyperspectral Anomaly Detection
Mar 18, 2022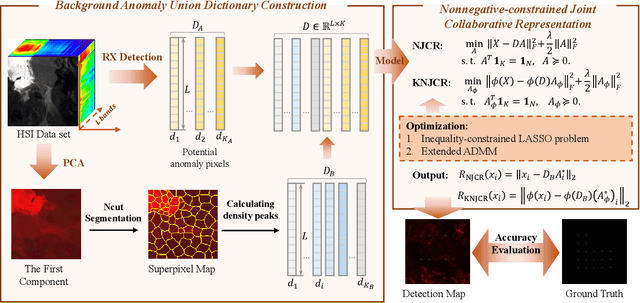
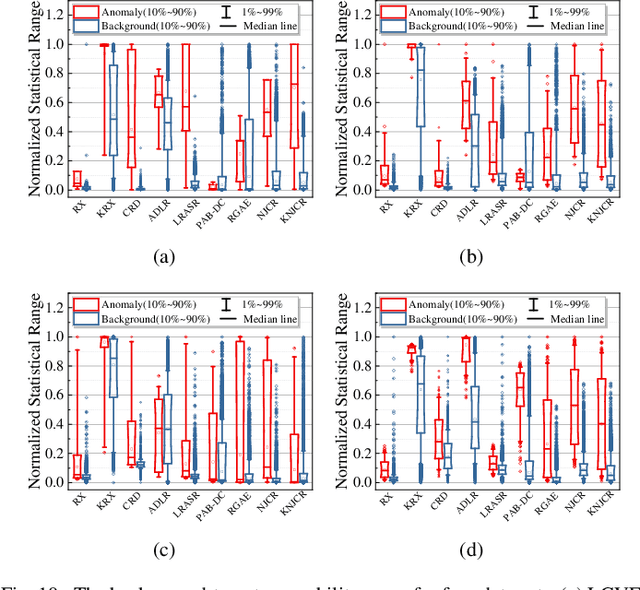
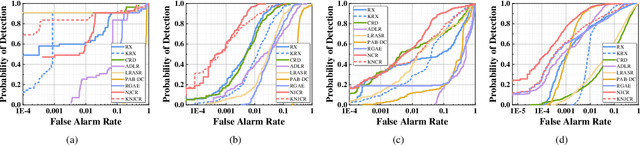
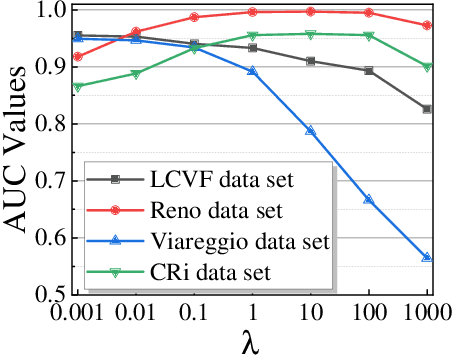
Recently, many collaborative representation-based (CR) algorithms have been proposed for hyperspectral anomaly detection. CR-based detectors approximate the image by a linear combination of background dictionaries and the coefficient matrix, and derive the detection map by utilizing recovery residuals. However, these CR-based detectors are often established on the premise of precise background features and strong image representation, which are very difficult to obtain. In addition, pursuing the coefficient matrix reinforced by the general $l_2$-min is very time consuming. To address these issues, a nonnegative-constrained joint collaborative representation model is proposed in this paper for the hyperspectral anomaly detection task. To extract reliable samples, a union dictionary consisting of background and anomaly sub-dictionaries is designed, where the background sub-dictionary is obtained at the superpixel level and the anomaly sub-dictionary is extracted by the pre-detection process. And the coefficient matrix is jointly optimized by the Frobenius norm regularization with a nonnegative constraint and a sum-to-one constraint. After the optimization process, the abnormal information is finally derived by calculating the residuals that exclude the assumed background information. To conduct comparable experiments, the proposed nonnegative-constrained joint collaborative representation (NJCR) model and its kernel version (KNJCR) are tested in four HSI data sets and achieve superior results compared with other state-of-the-art detectors.
LARD: Large-scale Artificial Disfluency Generation
Jan 13, 2022

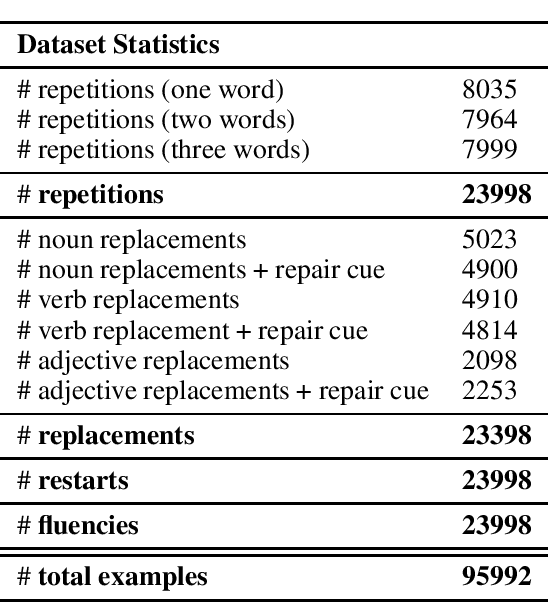
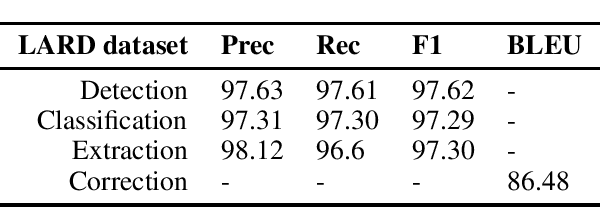
Disfluency detection is a critical task in real-time dialogue systems. However, despite its importance, it remains a relatively unexplored field, mainly due to the lack of appropriate datasets. At the same time, existing datasets suffer from various issues, including class imbalance issues, which can significantly affect the performance of the model on rare classes, as it is demonstrated in this paper. To this end, we propose LARD, a method for generating complex and realistic artificial disfluencies with little effort. The proposed method can handle three of the most common types of disfluencies: repetitions, replacements and restarts. In addition, we release a new large-scale dataset with disfluencies that can be used on four different tasks: disfluency detection, classification, extraction and correction. Experimental results on the LARD dataset demonstrate that the data produced by the proposed method can be effectively used for detecting and removing disfluencies, while also addressing limitations of existing datasets.
AI for Closed-Loop Control Systems --- New Opportunities for Modeling, Designing, and Tuning Control Systems
Jan 18, 2022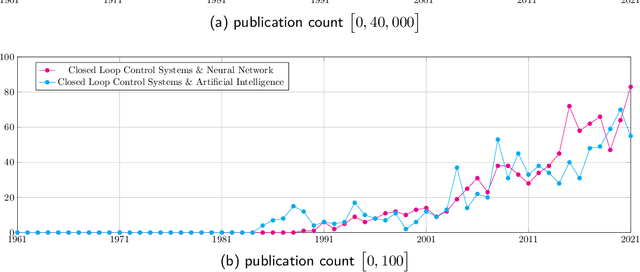
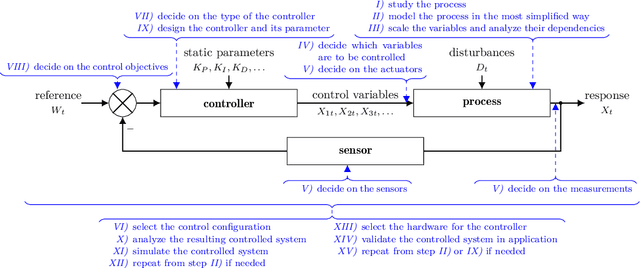
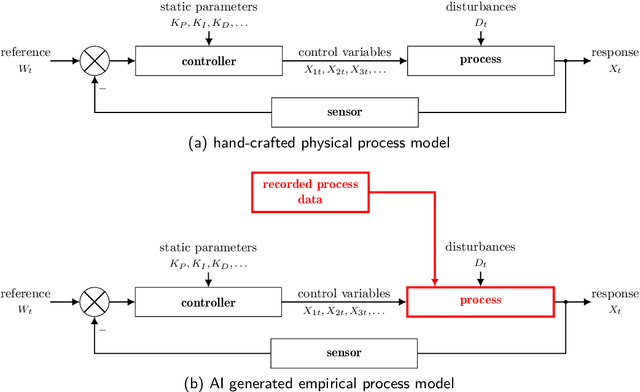
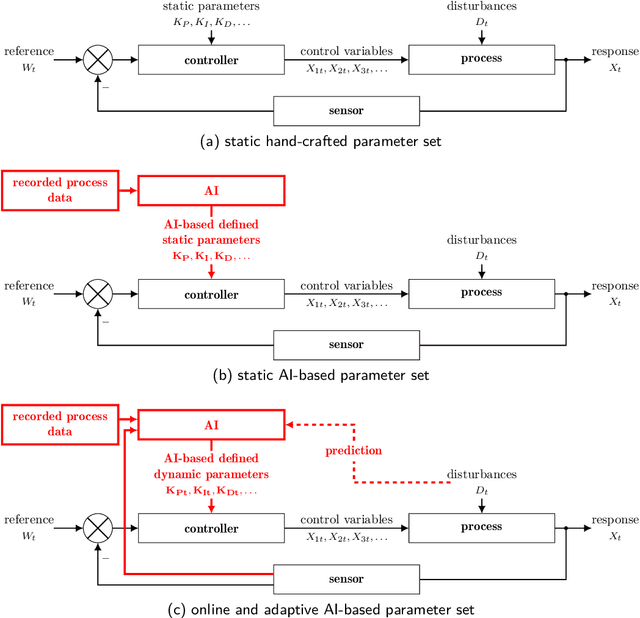
Control Systems, particularly closed-loop control systems (CLCS), are frequently used in production machines, vehicles, and robots nowadays. CLCS are needed to actively align actual values of a process to a given reference or set values in real-time with a very high precession. Yet, artificial intelligence (AI) is not used to model, design, optimize, and tune CLCS. This paper will highlight potential AI-empowered and -based control system designs and designing procedures, gathering new opportunities and research direction in the field of control system engineering. Therefore, this paper illustrates which building blocks within the standard block diagram of CLCS can be replaced by AI, i.e., artificial neuronal networks (ANN). Having processes with real-time contains and functional safety in mind, it is discussed if AI-based controller blocks can cope with these demands. By concluding the paper, the pros and cons of AI-empowered as well as -based CLCS designs are discussed, and possible research directions for introducing AI in the domain of control system engineering are given.
Making use of supercomputers in financial machine learning
Mar 01, 2022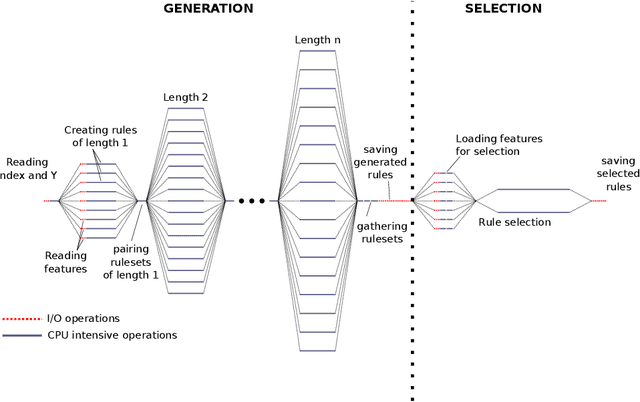

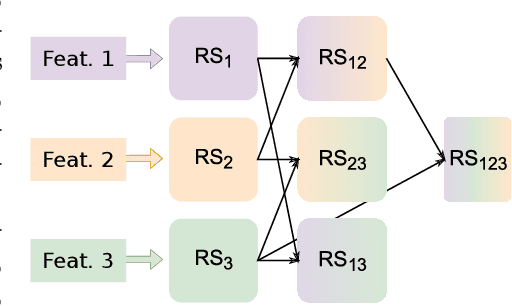
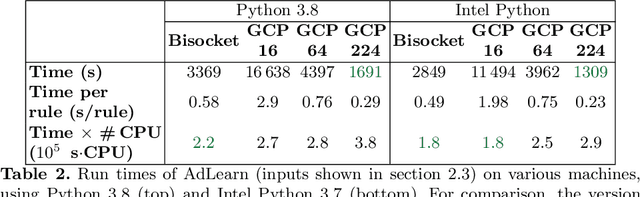
This article is the result of a collaboration between Fujitsu and Advestis. This collaboration aims at refactoring and running an algorithm based on systematic exploration producing investment recommendations on a high-performance computer of the Fugaku, to see whether a very high number of cores could allow for a deeper exploration of the data compared to a cloud machine, hopefully resulting in better predictions. We found that an increase in the number of explored rules results in a net increase in the predictive performance of the final ruleset. Also, in the particular case of this study, we found that using more than around 40 cores does not bring a significant computation time gain. However, the origin of this limitation is explained by a threshold-based search heuristic used to prune the search space. We have evidence that for similar data sets with less restrictive thresholds, the number of cores actually used could very well be much higher, allowing parallelization to have a much greater effect.
AI Annotated Recommendations in an Efficient Visual Learning Environment with Emphasis on YouTube (AI-EVL)
Mar 10, 2022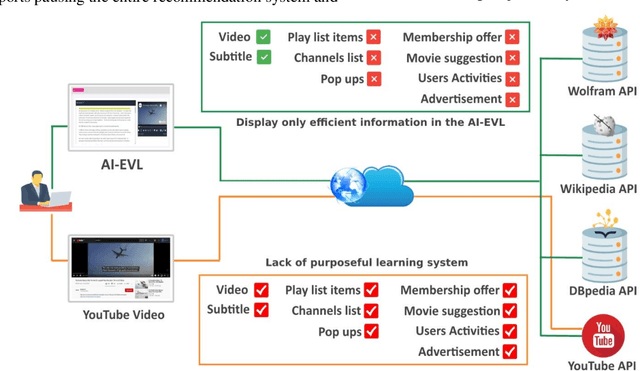
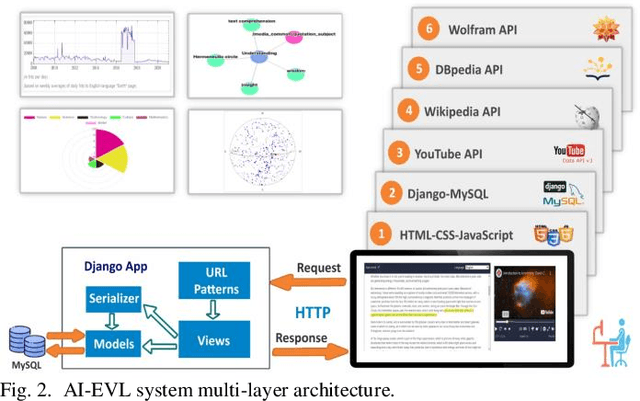
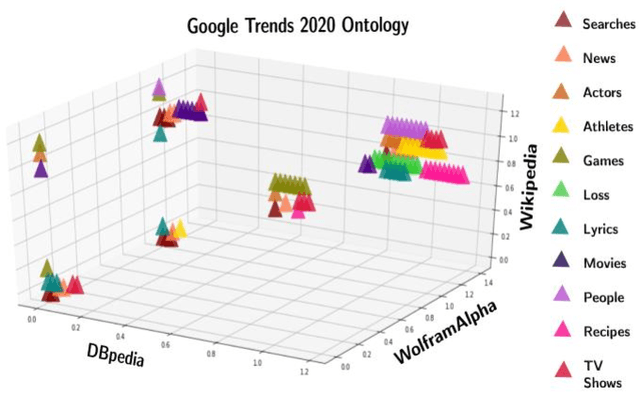
In this article, we create a system called AI-EVL. This is an annotated-based learning system. We extend AI to learning experience. If a user from the main YouTube page browses YouTube videos and a user from the AI-EVL system does the same, the amount of traffic used will be much less. It is due to ignoring unwanted contents which indicates a reduction in bandwidth usage too. This system is designed to be embedded with online learning tools and platforms to enrich their curriculum. In evaluating the system using Google 2020 trend data, we were able to extract rich ontological information for each data. Of the data collected, 34.86% belong to wolfram, 30.41% to DBpedia, and 34.73% to Wikipedia. The video subtitle information is displayed interactively and functionally to the user over time as the video is played. This effective visual learning system, due to the unique features, prevents the user's distraction and makes learning more focused. The information about the subtitle text is displayed in multiple layers including AI-annotated topics, Wikipedia/DBpedia, and Wolfram enriched texts via interactive and visual widgets.
Artificial Intelligence and Auction Design
Feb 12, 2022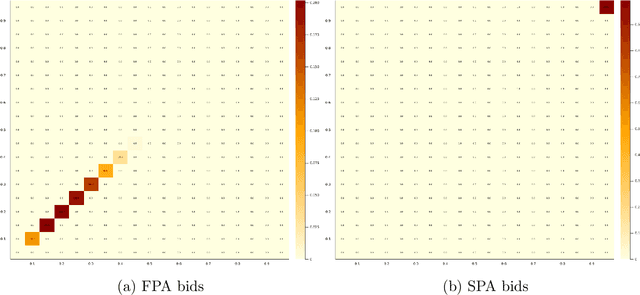
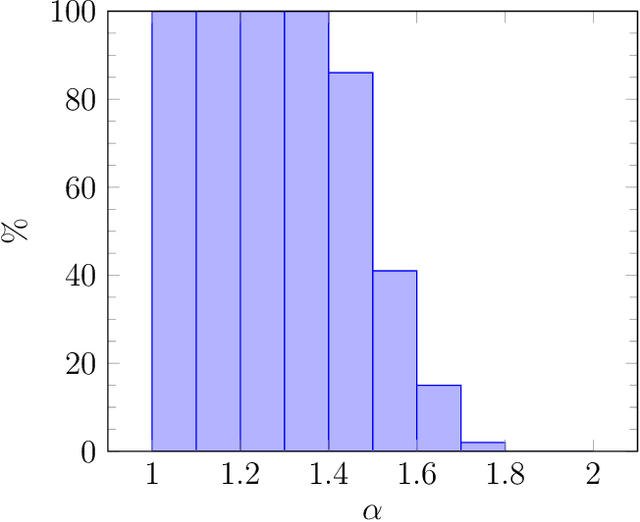
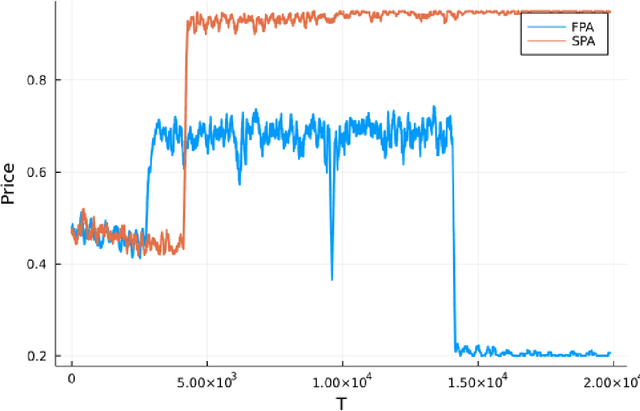
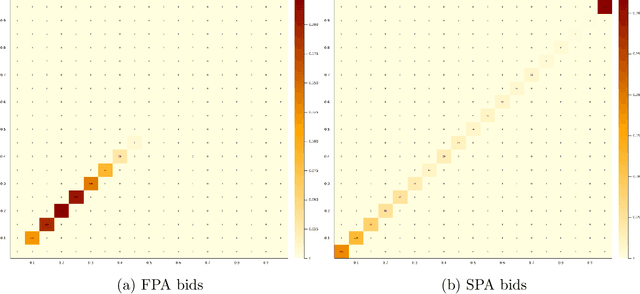
Motivated by online advertising auctions, we study auction design in repeated auctions played by simple Artificial Intelligence algorithms (Q-learning). We find that first-price auctions with no additional feedback lead to tacit-collusive outcomes (bids lower than values), while second-price auctions do not. We show that the difference is driven by the incentive in first-price auctions to outbid opponents by just one bid increment. This facilitates re-coordination on low bids after a phase of experimentation. We also show that providing information about lowest bid to win, as introduced by Google at the time of switch to first-price auctions, increases competitiveness of auctions.
Compactness Score: A Fast Filter Method for Unsupervised Feature Selection
Jan 31, 2022
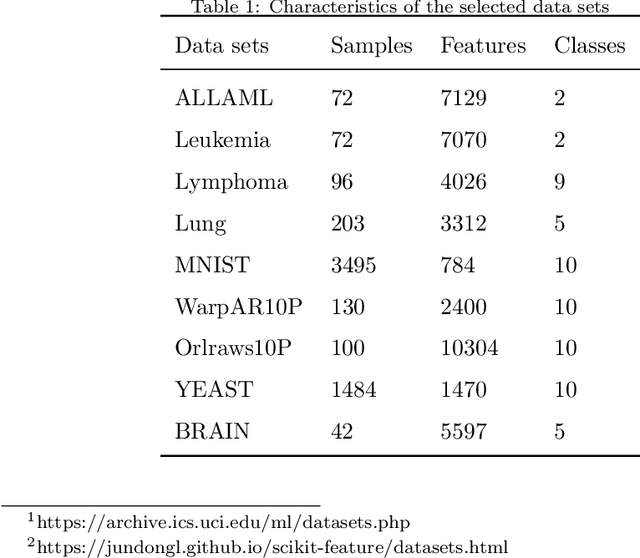
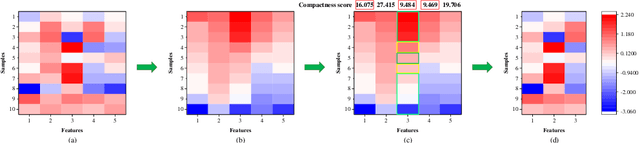
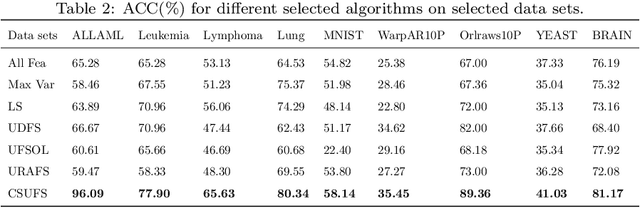
For feature engineering, feature selection seems to be an important research content in which is anticipated to select "excellent" features from candidate ones. Different functions can be realized through feature selection, such as dimensionality reduction, model effect improvement, and model performance improvement. Along with the flourish of the information age, huge amounts of high-dimensional data are generated day by day, while we need to spare great efforts and time to label such data. Therefore, various algorithms are proposed to address such data, among which unsupervised feature selection has attracted tremendous interests. In many classification tasks, researchers found that data seem to be usually close to each other if they are from the same class; thus, local compactness is of great importance for the evaluation of a feature. In this manuscript, we propose a fast unsupervised feature selection method, named as, Compactness Score (CSUFS), to select desired features. To demonstrate the efficiency and accuracy, several data sets are chosen with intensive experiments being performed. Later, the effectiveness and superiority of our method are revealed through addressing clustering tasks. Here, the performance is indicated by several well-known evaluation metrics, while the efficiency is reflected by the corresponding running time. As revealed by the simulation results, our proposed algorithm seems to be more accurate and efficient compared with existing algorithms.