 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Kernel Packet: An Exact and Scalable Algorithm for Gaussian Process Regression with Matérn Correlations
Mar 09, 2022
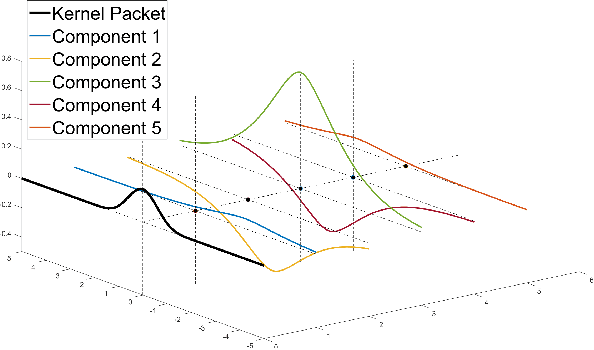
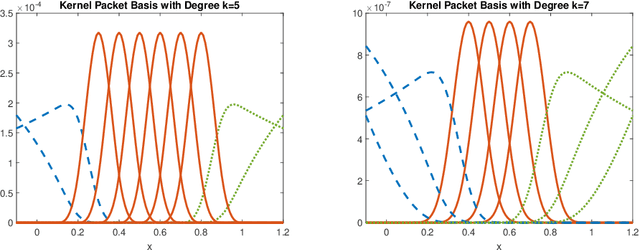

We develop an exact and scalable algorithm for one-dimensional Gaussian process regression with Mat\'ern correlations whose smoothness parameter $\nu$ is a half-integer. The proposed algorithm only requires $\mathcal{O}(\nu^3 n)$ operations and $\mathcal{O}(\nu n)$ storage. This leads to a linear-cost solver since $\nu$ is chosen to be fixed and usually very small in most applications. The proposed method can be applied to multi-dimensional problems if a full grid or a sparse grid design is used. The proposed method is based on a novel theory for Mat\'ern correlation functions. We find that a suitable rearrangement of these correlation functions can produce a compactly supported function, called a "kernel packet". Using a set of kernel packets as basis functions leads to a sparse representation of the covariance matrix that results in the proposed algorithm. Simulation studies show that the proposed algorithm, when applicable, is significantly superior to the existing alternatives in both the computational time and predictive accuracy.
ShapeNet: Shape Constraint for Galaxy Image Deconvolution
Mar 14, 2022

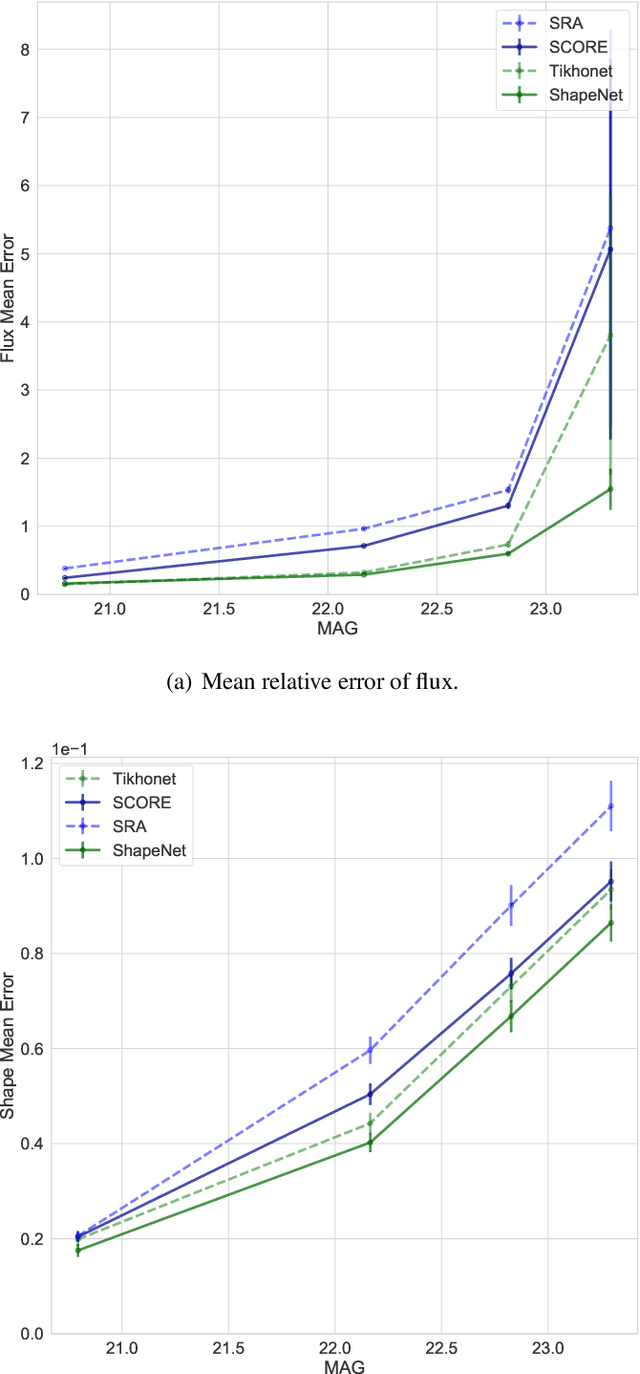
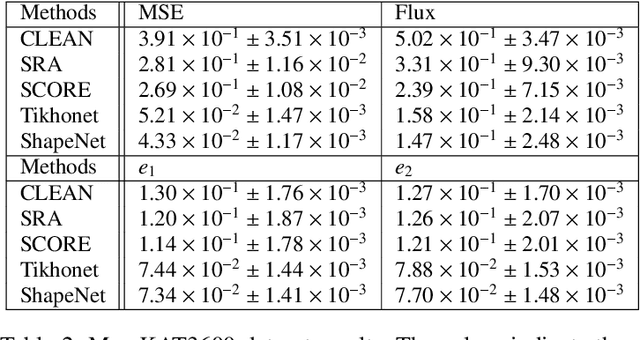
Deep Learning (DL) has shown remarkable results in solving inverse problems in various domains. In particular, the Tikhonet approach is very powerful to deconvolve optical astronomical images (Sureau et al. 2020). Yet, this approach only uses the $\ell_2$ loss, which does not guarantee the preservation of physical information (e.g. flux and shape) of the object reconstructed in the image. In Nammour et al. (2021), a new loss function was proposed in the framework of sparse deconvolution, which better preserves the shape of galaxies and reduces the pixel error. In this paper, we extend Tikhonet to take into account this shape constraint, and apply our new DL method, called ShapeNet, to optical and radio-interferometry simulated data set. The originality of the paper relies on i) the shape constraint we use in the neural network framework, ii) the application of deep learning to radio-interferometry image deconvolution for the first time, and iii) the generation of a simulated radio data set that we make available for the community. A range of examples illustrates the results.
Exosoul: ethical profiling in the digital world
Mar 30, 2022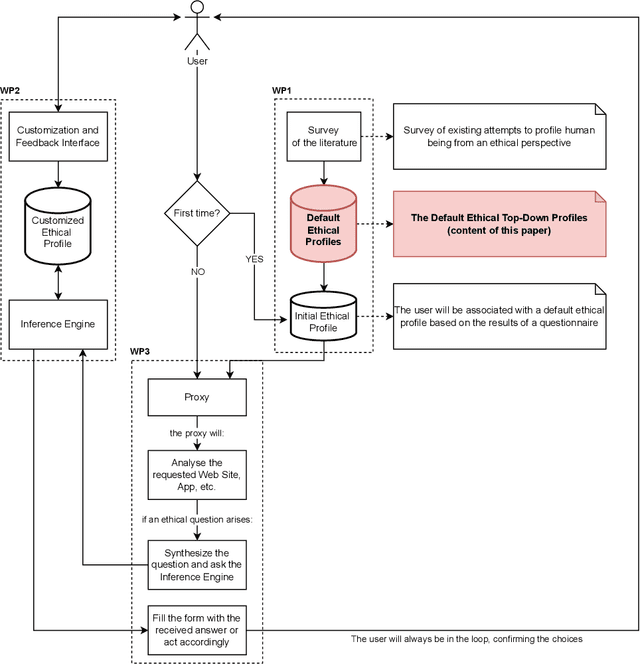
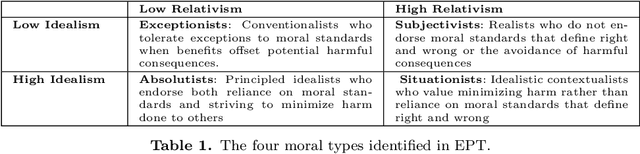
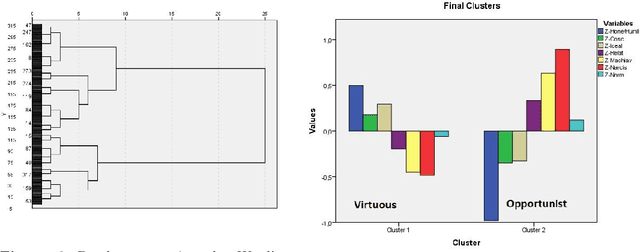
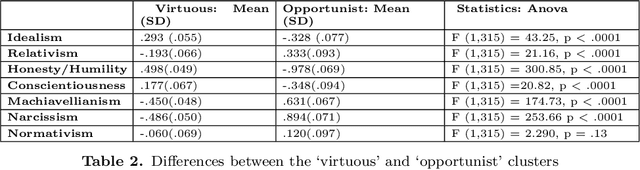
The development and the spread of increasingly autonomous digital technologies in our society pose new ethical challenges beyond data protection and privacy violation. Users are unprotected in their interactions with digital technologies and at the same time autonomous systems are free to occupy the space of decisions that is prerogative of each human being. In this context the multidisciplinary project Exosoul aims at developing a personalized software exoskeleton which mediates actions in the digital world according to the moral preferences of the user. The exoskeleton relies on the ethical profiling of a user, similar in purpose to the privacy profiling proposed in the literature, but aiming at reflecting and predicting general moral preferences. Our approach is hybrid, first based on the identification of profiles in a top-down manner, and then on the refinement of profiles by a personalized data-driven approach. In this work we report our initial experiment on building such top-down profiles. We consider the correlations between ethics positions (idealism and relativism) personality traits (honesty/humility, conscientiousness, Machiavellianism and narcissism) and worldview (normativism), and then we use a clustering approach to create ethical profiles predictive of user's digital behaviors concerning privacy violation, copy-right infringements, caution and protection. Data were collected by administering a questionnaire to 317 young individuals. In the paper we discuss two clustering solutions, one data-driven and one model-driven, in terms of validity and predictive power of digital behavior.
Can Deep Neural Networks be Converted to Ultra Low-Latency Spiking Neural Networks?
Dec 22, 2021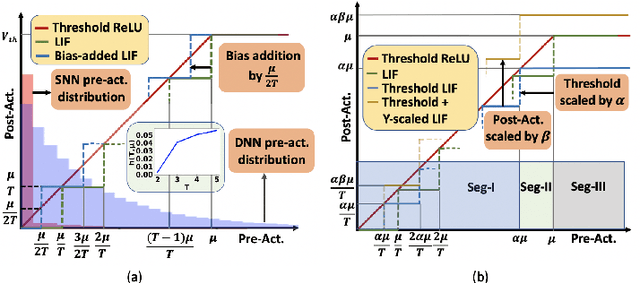
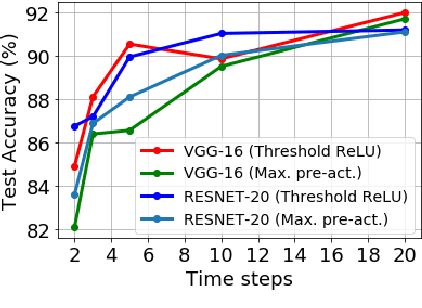

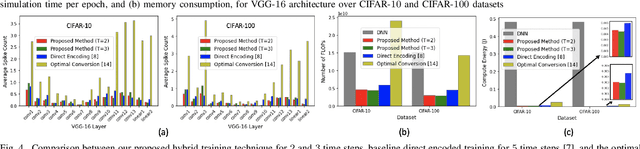
Spiking neural networks (SNNs), that operate via binary spikes distributed over time, have emerged as a promising energy efficient ML paradigm for resource-constrained devices. However, the current state-of-the-art (SOTA) SNNs require multiple time steps for acceptable inference accuracy, increasing spiking activity and, consequently, energy consumption. SOTA training strategies for SNNs involve conversion from a non-spiking deep neural network (DNN). In this paper, we determine that SOTA conversion strategies cannot yield ultra low latency because they incorrectly assume that the DNN and SNN pre-activation values are uniformly distributed. We propose a new training algorithm that accurately captures these distributions, minimizing the error between the DNN and converted SNN. The resulting SNNs have ultra low latency and high activation sparsity, yielding significant improvements in compute efficiency. In particular, we evaluate our framework on image recognition tasks from CIFAR-10 and CIFAR-100 datasets on several VGG and ResNet architectures. We obtain top-1 accuracy of 64.19% with only 2 time steps on the CIFAR-100 dataset with ~159.2x lower compute energy compared to an iso-architecture standard DNN. Compared to other SOTA SNN models, our models perform inference 2.5-8x faster (i.e., with fewer time steps).
DONeRF: Towards Real-Time Rendering of Neural Radiance Fields using Depth Oracle Networks
Mar 04, 2021
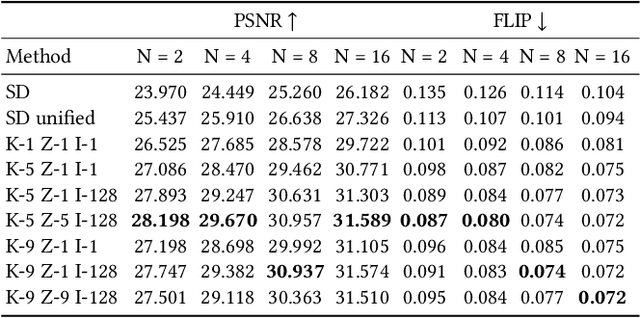
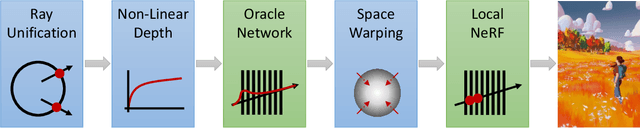
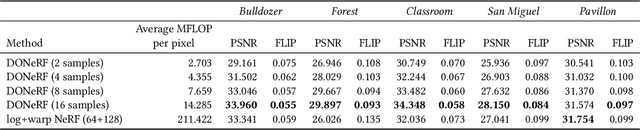
The recent research explosion around Neural Radiance Fields (NeRFs) shows that there is immense potential for implicitly storing scene and lighting information in neural networks, e.g., for novel view generation. However, one major limitation preventing the widespread use of NeRFs is the prohibitive computational cost of excessive network evaluations along each view ray, requiring dozens of petaFLOPS when aiming for real-time rendering on current devices. We show that the number of samples required for each view ray can be significantly reduced when local samples are placed around surfaces in the scene. To this end, we propose a depth oracle network, which predicts ray sample locations for each view ray with a single network evaluation. We show that using a classification network around logarithmically discretized and spherically warped depth values is essential to encode surface locations rather than directly estimating depth. The combination of these techniques leads to DONeRF, a dual network design with a depth oracle network as a first step and a locally sampled shading network for ray accumulation. With our design, we reduce the inference costs by up to 48x compared to NeRF. Using an off-the-shelf inference API in combination with simple compute kernels, we are the first to render raymarching-based neural representations at interactive frame rates (15 frames per second at 800x800) on a single GPU. At the same time, since we focus on the important parts of the scene around surfaces, we achieve equal or better quality compared to NeRF.
Teachable Reinforcement Learning via Advice Distillation
Mar 19, 2022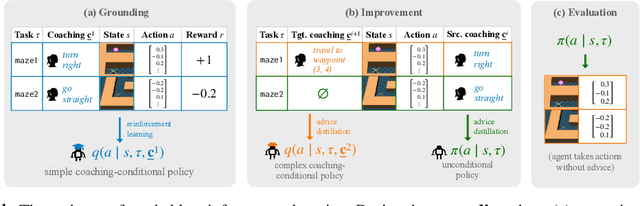
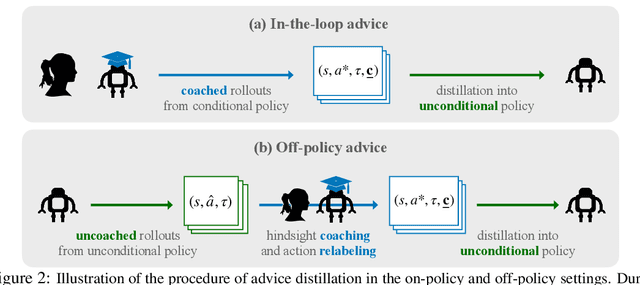
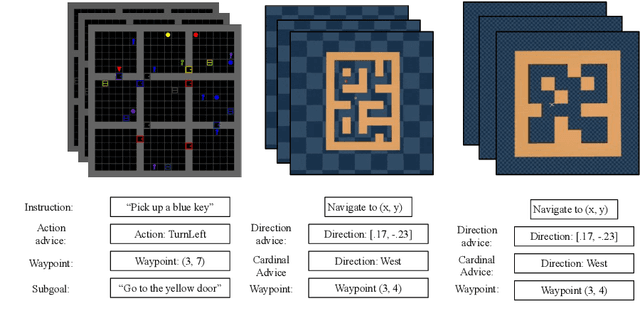
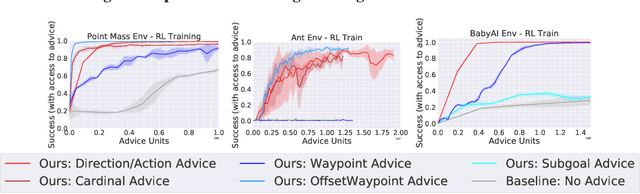
Training automated agents to complete complex tasks in interactive environments is challenging: reinforcement learning requires careful hand-engineering of reward functions, imitation learning requires specialized infrastructure and access to a human expert, and learning from intermediate forms of supervision (like binary preferences) is time-consuming and extracts little information from each human intervention. Can we overcome these challenges by building agents that learn from rich, interactive feedback instead? We propose a new supervision paradigm for interactive learning based on "teachable" decision-making systems that learn from structured advice provided by an external teacher. We begin by formalizing a class of human-in-the-loop decision making problems in which multiple forms of teacher-provided advice are available to a learner. We then describe a simple learning algorithm for these problems that first learns to interpret advice, then learns from advice to complete tasks even in the absence of human supervision. In puzzle-solving, navigation, and locomotion domains, we show that agents that learn from advice can acquire new skills with significantly less human supervision than standard reinforcement learning algorithms and often less than imitation learning.
Transfer Learning as an Essential Tool for Digital Twins in Renewable Energy Systems
Mar 09, 2022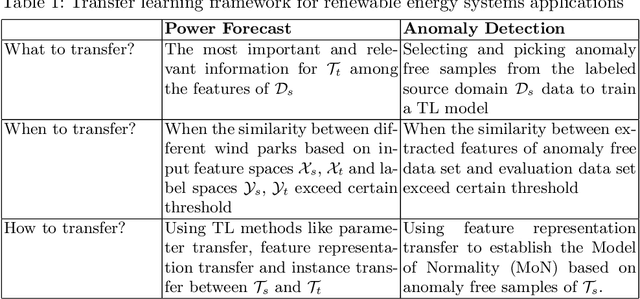
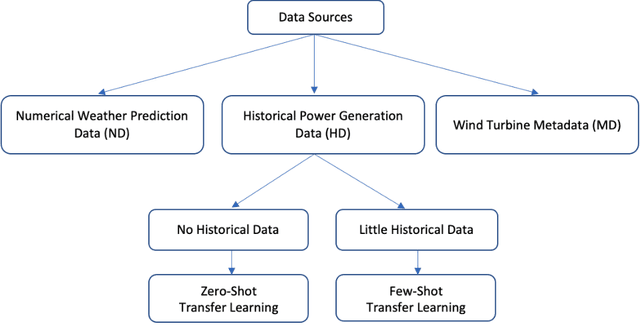
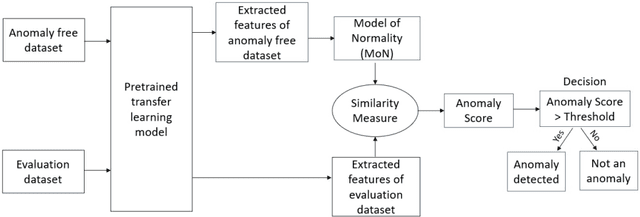
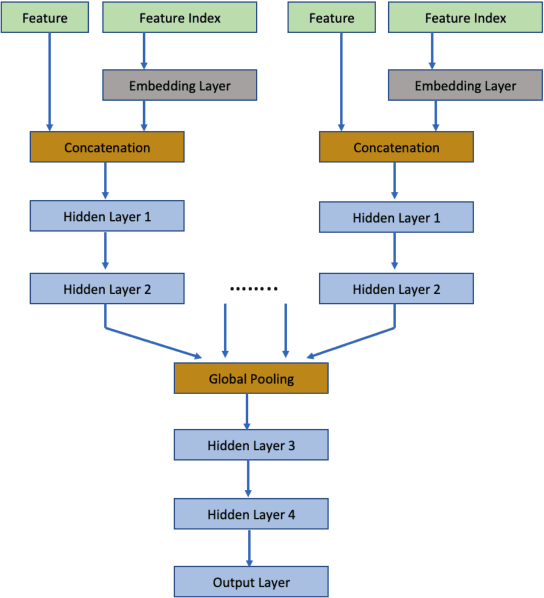
Transfer learning (TL), the next frontier in machine learning (ML), has gained much popularity in recent years, due to the various challenges faced in ML, like the requirement of vast amounts of training data, expensive and time-consuming labelling processes for data samples, and long training duration for models. TL is useful in tackling these problems, as it focuses on transferring knowledge from previously solved tasks to new tasks. Digital twins and other intelligent systems need to utilise TL to use the previously gained knowledge and solve new tasks in a more self-reliant way, and to incrementally increase their knowledge base. Therefore, in this article, the critical challenges in power forecasting and anomaly detection in the context of renewable energy systems are identified, and a potential TL framework to meet these challenges is proposed. This article also proposes a feature embedding approach to handle the missing sensors data. The proposed TL methods help to make a system more autonomous in the context of organic computing.
Pulses with Minimum Residual Intersymbol Interference for Faster than Nyquist Signaling
Mar 14, 2022
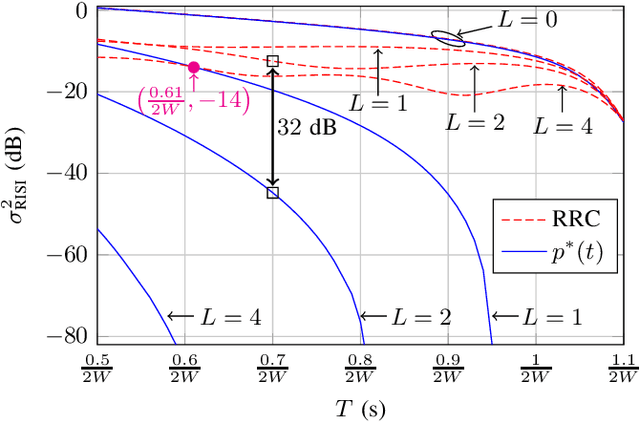
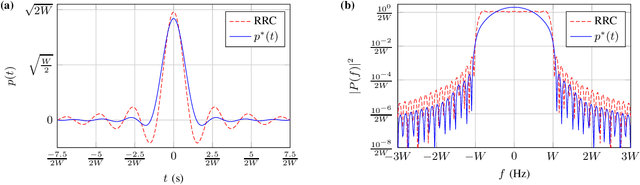
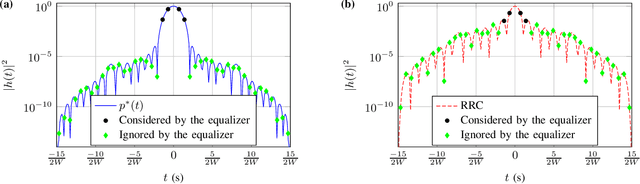
Faster than Nyquist signaling increases the spectral efficiency of pulse amplitude modulation by accepting intersymbol interference, where an equalizer is needed at the receiver. Since the complexity of an optimal equalizer increases exponentially with the number of the interfering symbols, practical truncated equalizers assume shorter memory. The power of the resulting residual interference depends on the transmit filter and limits the performance of truncated equalizers. In this paper, we use numerical optimizations and the prolate spheroidal wave functions to find optimal time-limited pulses that achieve minimum residual interference. Compared to root raised cosine pulses, the new pulses decrease the residual interference by an order of magnitude, for example, a decrease by 32 dB is achieved for an equalizer that considers four interfering symbols at 57% faster transmissions. As a proof of concept, for the 57% faster transmissions of binary symbols, we showed that using the new pulse with a 4-state equalizer has better bit error rate performance compared to using a root raised cosine pulse with a 128-state equalizer.
Shadows can be Dangerous: Stealthy and Effective Physical-world Adversarial Attack by Natural Phenomenon
Mar 23, 2022

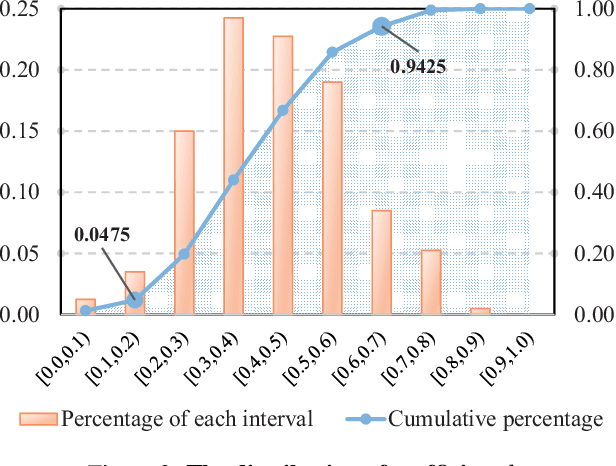

Estimating the risk level of adversarial examples is essential for safely deploying machine learning models in the real world. One popular approach for physical-world attacks is to adopt the "sticker-pasting" strategy, which however suffers from some limitations, including difficulties in access to the target or printing by valid colors. A new type of non-invasive attacks emerged recently, which attempt to cast perturbation onto the target by optics based tools, such as laser beam and projector. However, the added optical patterns are artificial but not natural. Thus, they are still conspicuous and attention-grabbed, and can be easily noticed by humans. In this paper, we study a new type of optical adversarial examples, in which the perturbations are generated by a very common natural phenomenon, shadow, to achieve naturalistic and stealthy physical-world adversarial attack under the black-box setting. We extensively evaluate the effectiveness of this new attack on both simulated and real-world environments. Experimental results on traffic sign recognition demonstrate that our algorithm can generate adversarial examples effectively, reaching 98.23% and 90.47% success rates on LISA and GTSRB test sets respectively, while continuously misleading a moving camera over 95% of the time in real-world scenarios. We also offer discussions about the limitations and the defense mechanism of this attack.
ECONet: Efficient Convolutional Online Likelihood Network for Scribble-based Interactive Segmentation
Feb 08, 2022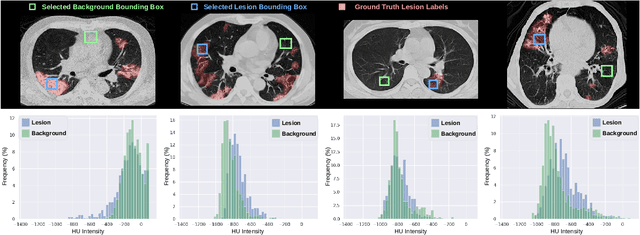

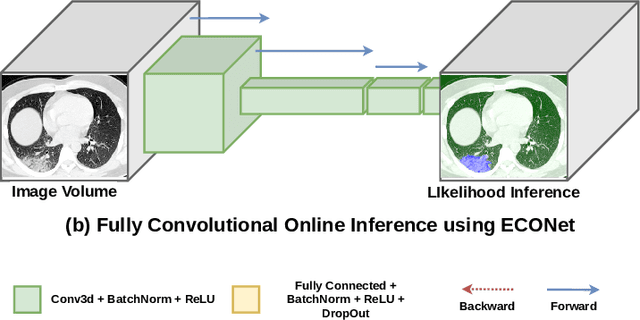
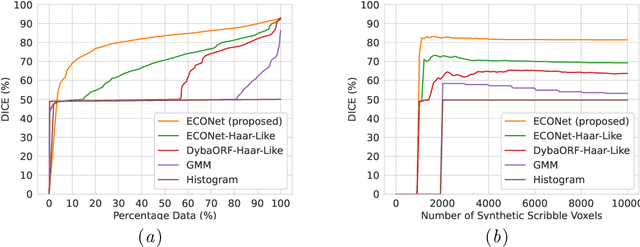
Automatic segmentation of lung lesions associated with COVID-19 in CT images requires large amount of annotated volumes. Annotations mandate expert knowledge and are time-intensive to obtain through fully manual segmentation methods. Additionally, lung lesions have large inter-patient variations, with some pathologies having similar visual appearance as healthy lung tissues. This poses a challenge when applying existing semi-automatic interactive segmentation techniques for data labelling. To address these challenges, we propose an efficient convolutional neural networks (CNNs) that can be learned online while the annotator provides scribble-based interaction. To accelerate learning from only the samples labelled through user-interactions, a patch-based approach is used for training the network. Moreover, we use weighted cross-entropy loss to address the class imbalance that may result from user-interactions. During online inference, the learned network is applied to the whole input volume using a fully convolutional approach. We compare our proposed method with state-of-the-art using synthetic scribbles and show that it outperforms existing methods on the task of annotating lung lesions associated with COVID-19, achieving 16% higher Dice score while reducing execution time by 3$\times$ and requiring 9000 lesser scribbles-based labelled voxels. Due to the online learning aspect, our approach adapts quickly to user input, resulting in high quality segmentation labels. Source code for ECONet is available at: https://github.com/masadcv/ECONet-MONAILabel