 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Understanding the input-output relationship of neural networks in the time series forecasting radon levels at Canfranc Underground Laboratory
Feb 05, 2021
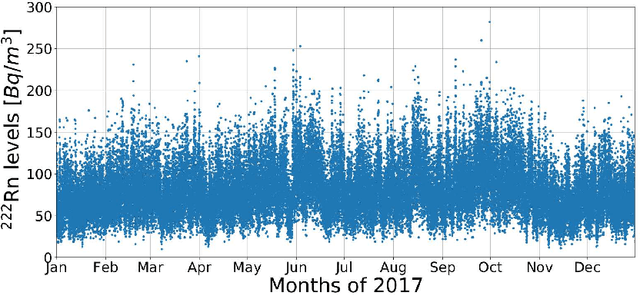
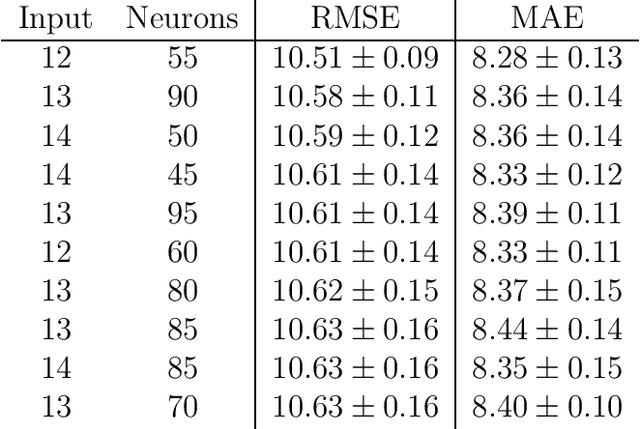
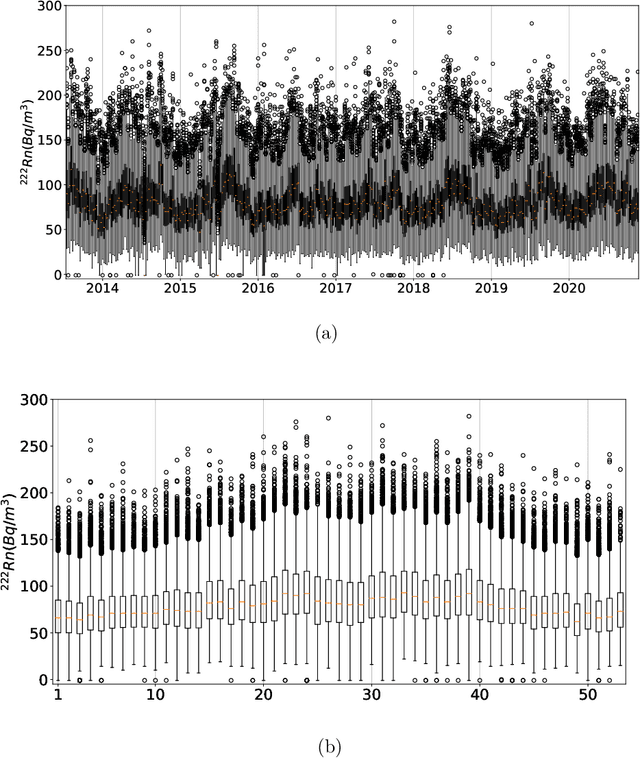
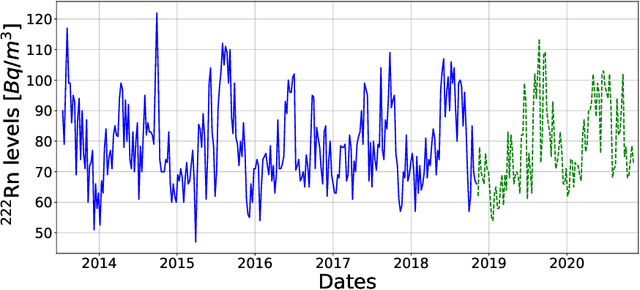
Underground physics experiments such as dark matter direct detection need to keep control of the background contribution. Hosting these experiments in underground facilities helps to minimize certain background sources such as the cosmic rays. One of the largest remaining background sources is the radon emanated from the rocks enclosing the research facility. The radon particles could be deposited inside the detectors when they are opened to perform the maintenance operations. Therefore, forecasting the radon levels is a crucial task in an attempt to schedule the maintenance operations when radon level is minimum. In the past, deep learning models have been implemented to forecast the radon time series at the Canfranc Underground Laboratory (LSC), in Spain, with satisfactory results. When forecasting time series, the past values of the time series are taken as input variables. The present work focuses on understanding the relative contribution of these input variables to the predictions generated by neural networks. The results allow us to understand how the predictions of the time series depend on the input variables. These results may be used to build better predictors in the future.
Design and Evaluation of an Augmented Reality Head-Mounted Display Interface for Human Robot Teams Collaborating in Physically Shared Manufacturing Tasks
Mar 16, 2022
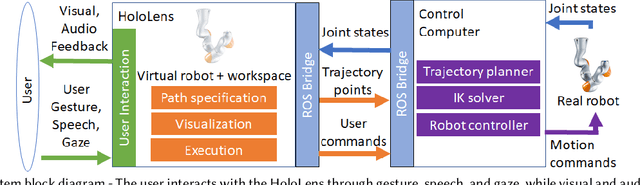
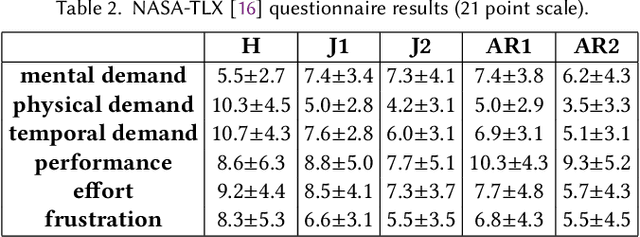

We provide an experimental evaluation of a wearable augmented reality (AR) system we have developed for human-robot teams working on tasks requiring collaboration in shared physical workspace. Recent advances in AR technology have facilitated the development of more intuitive user interfaces for many human-robot interaction applications. While it has been anticipated that AR can provided a more intuitive interface to robot assistants helping human workers in various manufacturing scenarios, existing studies in robotics have been largely limited to teleoperation and programming. Industry 5.0 envisions cooperation between human and robot working in teams. Indeed, there exist many industrial task that can benefit from human-robot collaboration. A prime example is high-value composite manufacturing. Working with our industry partner towards this example application, we evaluated our AR interface design for shared physical workspace collaboration in human-robot teams. We conducted a multi-dimensional analysis of our interface using establish metrics. Results from our user study (n=26) show that subjectively, the AR interface feels more novel and a standard joystick interface feels more dependable to users. However, the AR interface was found to reduce physical demand and task completion time, while increasing robot utilization. Furthermore, user's freedom of choice to collaborate with the robot may also affect the perceived usability of the system.
Far-UVC Disinfection with Robotic Mobile Manipulator
Mar 02, 2022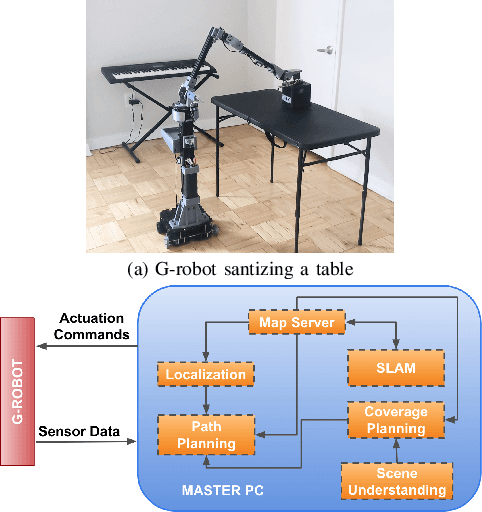

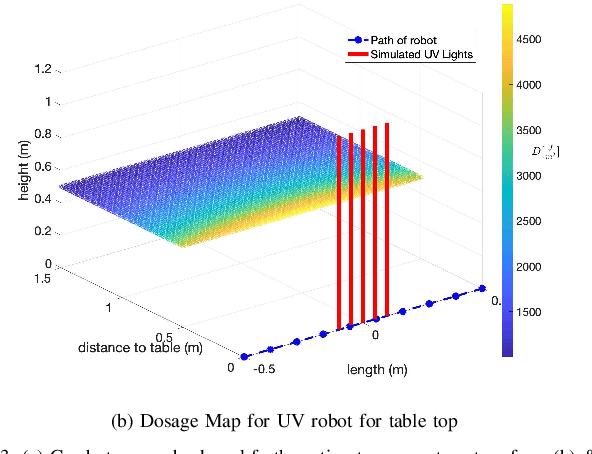
The COVID-19 pandemic has demonstrated the need for a more effective and efficient disinfection approach to combat infectious diseases. Ultraviolet germicidal irradiation (UVGI) is a proven mean for disinfection and sterilization and has been integrated into handheld devices and autonomous mobile robots. Existing UVGI robots which are commonly equipped with uncovered lamps that emit intense ultraviolet radiation suffer from: inability to be used in human presence, shadowing of objects, and long disinfection time. These robots also have a high operational cost. This paper introduces a cost-effective germicidal system that utilizes UVGI to disinfect pathogens, such as viruses, bacteria, and fungi, on high contact surfaces (e.g. doors and tables). This system is composed of a team of 5-DOF mobile manipulators with end-effectors that are equipped with far-UVC excimer lamps. The design of the system is discussed with emphasis on path planning, coverage planning, and scene understanding. Evaluations of the UVGI system using simulations and irradiance models are also included.
* Paper accepted at ISMR 2022
Neural CDEs for Long Time Series via the Log-ODE Method
Sep 17, 2020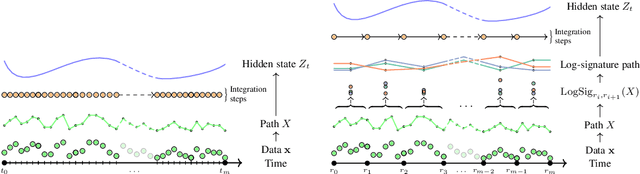
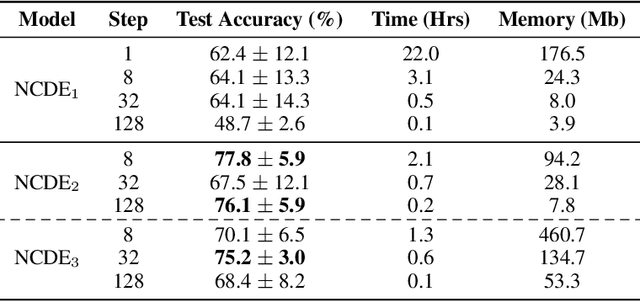
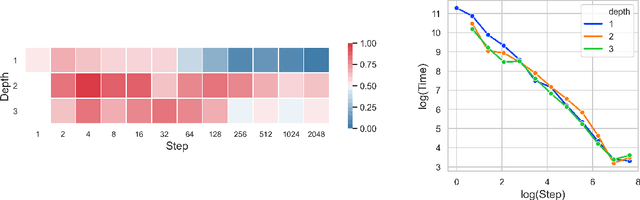
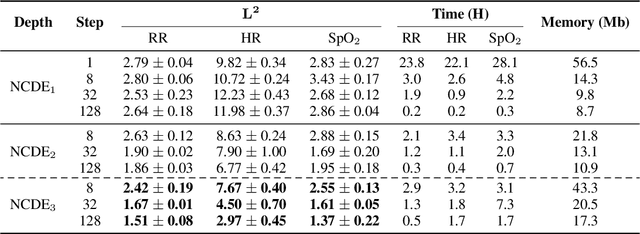
Neural Controlled Differential Equations (Neural CDEs) are the continuous-time analogue of an RNN, just as Neural ODEs are analogous to ResNets. However just like RNNs, training Neural CDEs can be difficult for long time series. Here, we propose to apply a technique drawn from stochastic analysis, namely the log-ODE method. Instead of using the original input sequence, our procedure summarises the information over local time intervals via the log-signature map, and uses the resulting shorter stream of log-signatures as the new input. This represents a length/channel trade-off. In doing so we demonstrate efficacy on problems of length up to 17k observations and observe significant training speed-ups, improvements in model performance, and reduced memory requirements compared to the existing algorithm.
Benchmarking Multivariate Time Series Classification Algorithms
Jul 26, 2020
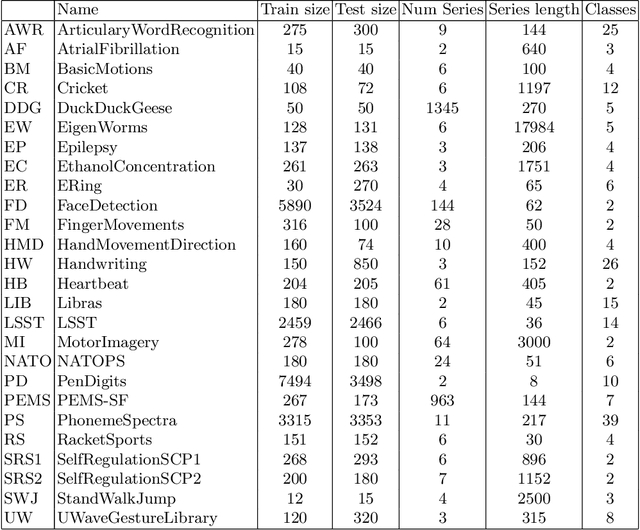
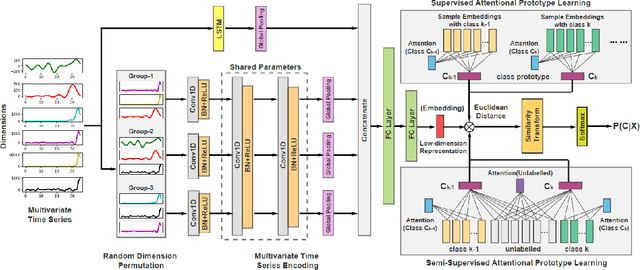
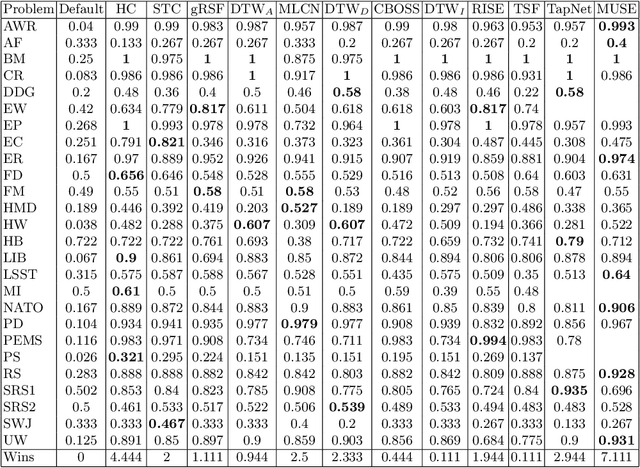
Time Series Classification (TSC) involved building predictive models for a discrete target variable from ordered, real valued, attributes. Over recent years, a new set of TSC algorithms have been developed which have made significant improvement over the previous state of the art. The main focus has been on univariate TSC, i.e. the problem where each case has a single series and a class label. In reality, it is more common to encounter multivariate TSC (MTSC) problems where multiple series are associated with a single label. Despite this, much less consideration has been given to MTSC than the univariate case. The UEA archive of 30 MTSC problems released in 2018 has made comparison of algorithms easier. We review recently proposed bespoke MTSC algorithms based on deep learning, shapelets and bag of words approaches. The simplest approach to MTSC is to ensemble univariate classifiers over the multivariate dimensions. We compare the bespoke algorithms to these dimension independent approaches on the 26 of the 30 MTSC archive problems where the data are all of equal length. We demonstrate that the independent ensemble of HIVE-COTE classifiers is the most accurate, but that, unlike with univariate classification, dynamic time warping is still competitive at MTSC.
Transformer Embeddings of Irregularly Spaced Events and Their Participants
Dec 31, 2021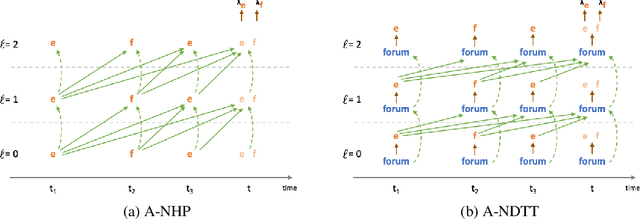

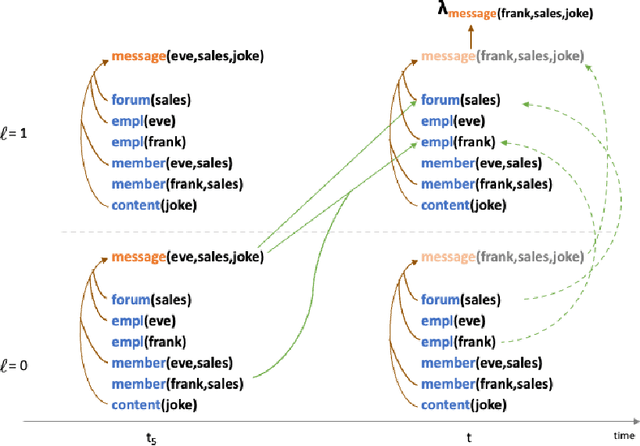

We propose an approach to modeling irregularly spaced sequences of discrete events. We begin with a continuous-time variant of the Transformer, which was originally formulated (Vaswani et al., 2017) for sequences without timestamps. We embed a possible event (or other boolean fact) at time $t$ by using attention over the events that occurred at times $< t$ (and the facts that were true when they occurred). We control this attention using pattern-matching logic rules that relate events and facts that share participants. These rules determine which previous events will be attended to, as well as how to transform the embeddings of the events and facts into the attentional queries, keys, and values. Other logic rules describe how to change the set of facts in response to events. Our approach closely follows Mei et al. (2020a), and adopts their Datalog Through Time formalism for logic rules. As in that work, a domain expert first writes a set of logic rules that establishes the set of possible events and other facts at each time $t$. Each possible event or other fact is embedded using a neural architecture that is derived from the rules that established it. Our only difference from Mei et al. (2020a) is that we derive a flatter, attention-based neural architecture whereas they used a more serial LSTM architecture. We find that our attention-based approach performs about equally well on the RoboCup dataset, where the logic rules play an important role in improving performance. We also compared these two methods with two previous attention-based methods (Zuo et al., 2020; Zhang et al., 2020a) on simpler synthetic and real domains without logic rules, and found our proposed approach to be at least as good, and sometimes better, than each of the other three methods.
Weighted Random Cut Forest Algorithm for Anomaly Detections
Feb 01, 2022
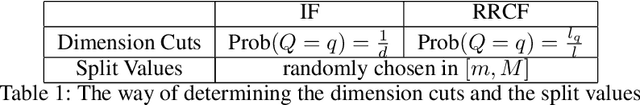
Random cut forest (RCF) algorithms have been developed for anomaly detection, particularly for the anomaly detection in time-series data. The RCF algorithm is the improved version of the isolation forest algorithm. Unlike the isolation forest algorithm, the RCF algorithm has the power of determining whether the real-time input has anomaly by inserting the input in the constructed tree network. There have been developed various RCF algorithms including Robust RCF (RRCF) with which the cutting procedure is adaptively chosen probabilistically. RRCF shows better performance compared to the isolation forest as the cutting dimension is decided based on the geometric range of the data. The overall data structure is, however, not considered in the adaptive cutting algorithm with the RRCF. In this paper, we propose a new RCF, so-called the weighted RCF (WRCF). In order to introduce the WRCF, we first introduce a new geometric measure, i.e., a \textit{density measure} which is crucial for the construction of the WRCF. We provide various mathematical properties of the density measure. The proposed WRCF also cuts the tree network adaptively, but with consideration of the denseness of the data. The proposed method is more efficient when the data is structured and achieves the desired anomaly score more rapidly than the RRCF. We provide theorems that prove our claims with numerical examples.
Quantile-Based Policy Optimization for Reinforcement Learning
Feb 16, 2022



Classical reinforcement learning (RL) aims to optimize the expected cumulative rewards. In this work, we consider the RL setting where the goal is to optimize the quantile of the cumulative rewards. We parameterize the policy controlling actions by neural networks and propose a novel policy gradient algorithm called Quantile-Based Policy Optimization (QPO) and its variant Quantile-Based Proximal Policy Optimization (QPPO) to solve deep RL problems with quantile objectives. QPO uses two coupled iterations running at different time scales for simultaneously estimating quantiles and policy parameters and is shown to converge to the global optimal policy under certain conditions. Our numerical results demonstrate that the proposed algorithms outperform the existing baseline algorithms under the quantile criterion.
Bandits Corrupted by Nature: Lower Bounds on Regret and Robust Optimistic Algorithm
Mar 07, 2022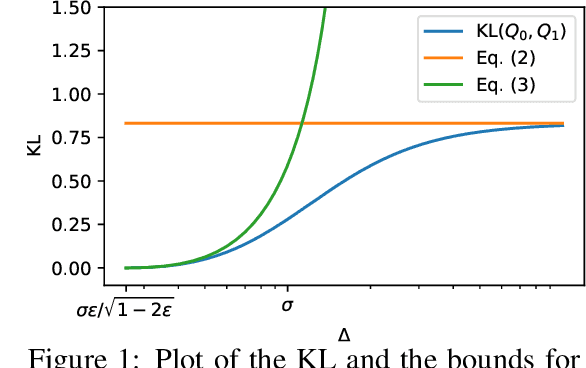
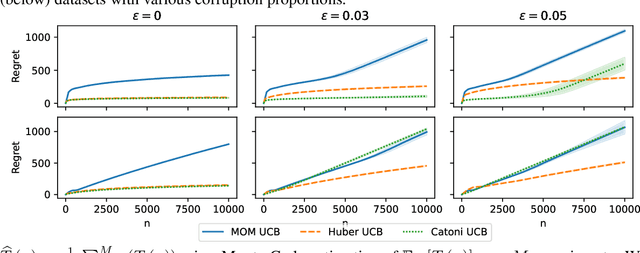
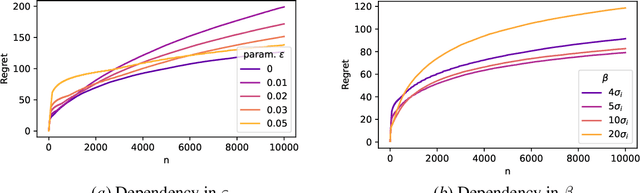
In this paper, we study the stochastic bandits problem with $k$ unknown heavy-tailed and corrupted reward distributions or arms with time-invariant corruption distributions. At each iteration, the player chooses an arm. Given the arm, the environment returns an uncorrupted reward with probability $1-\varepsilon$ and an arbitrarily corrupted reward with probability $\varepsilon$. In our setting, the uncorrupted reward might be heavy-tailed and the corrupted reward might be unbounded. We prove a lower bound on the regret indicating that the corrupted and heavy-tailed bandits are strictly harder than uncorrupted or light-tailed bandits. We observe that the environments can be categorised into hardness regimes depending on the suboptimality gap $\Delta$, variance $\sigma$, and corruption proportion $\epsilon$. Following this, we design a UCB-type algorithm, namely HuberUCB, that leverages Huber's estimator for robust mean estimation. HuberUCB leads to tight upper bounds on regret in the proposed corrupted and heavy-tailed setting. To derive the upper bound, we prove a novel concentration inequality for Huber's estimator, which might be of independent interest.
Towards Robust Online Dialogue Response Generation
Mar 07, 2022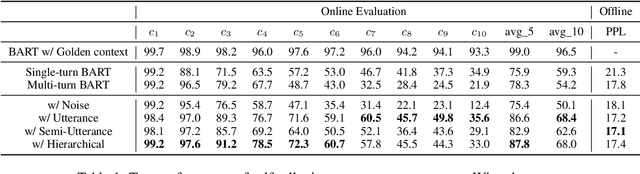
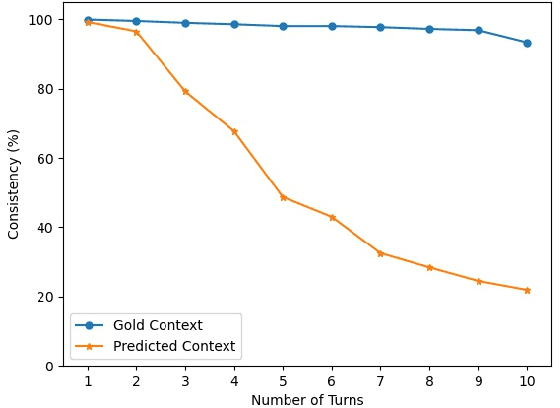

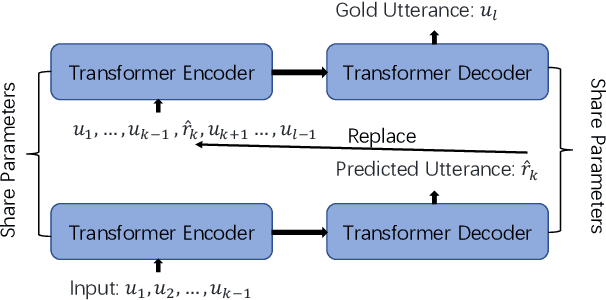
Although pre-trained sequence-to-sequence models have achieved great success in dialogue response generation, chatbots still suffer from generating inconsistent responses in real-world practice, especially in multi-turn settings. We argue that this can be caused by a discrepancy between training and real-world testing. At training time, chatbot generates the response with the golden context, while it has to generate based on the context consisting of both user utterances and the model predicted utterances during real-world testing. With the growth of the number of utterances, this discrepancy becomes more serious in the multi-turn settings. In this paper, we propose a hierarchical sampling-based method consisting of both utterance-level sampling and semi-utterance-level sampling, to alleviate the discrepancy, which implicitly increases the dialogue coherence. We further adopt reinforcement learning and re-ranking methods to explicitly optimize the dialogue coherence during training and inference, respectively. Empirical experiments show the effectiveness of the proposed methods for improving the robustness of chatbots in real practice.