 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
PIEEG: Turn a Raspberry Pi into a Brain-Computer-Interface to measure biosignals
Jan 05, 2022
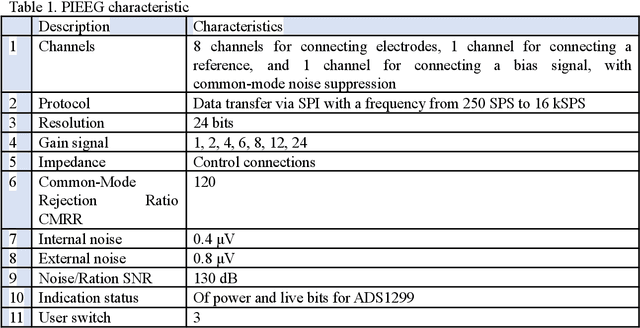
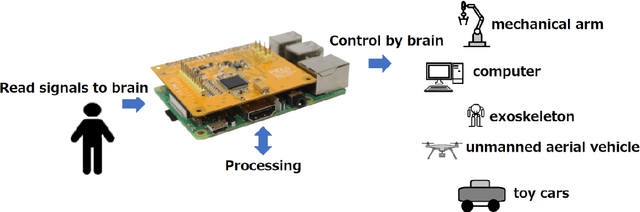
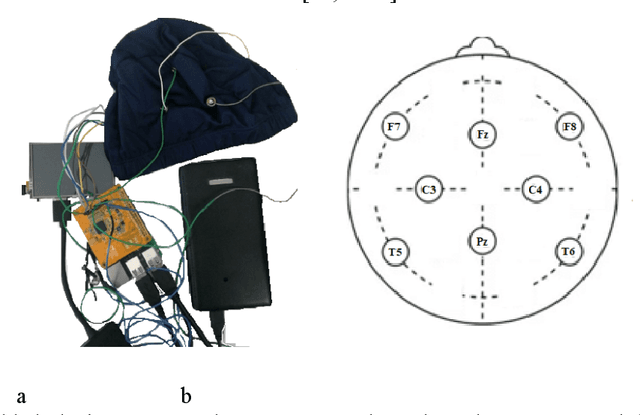
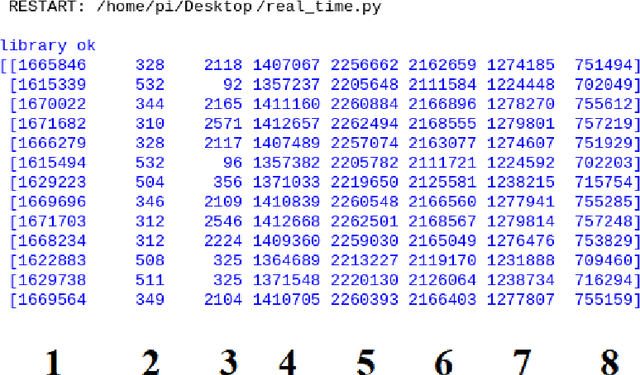
This paper presents an inexpensive, high-precision, but at the same time, easy-to-maintain PIEEG board to convert a RaspberryPI to a Brain-computer interface. This shield allows measuring and processing eight real-time EEG (Electroencephalography) signals. We used the most popular programming languages - C, C++ and Python to read the signals, recorded by the device . The process of reading EEG signals was demonstrated as completely and clearly as possible. This device can be easily used for machine learning enthusiasts to create projects for controlling robots and mechanical limbs using the power of thought. We will post use cases on GitHub (https://github.com/Ildaron/EEGwithRaspberryPI) for controlling a robotic machine, unmanned aerial vehicle, and more just using the power of thought.
When A Conventional Filter Meets Deep Learning: Basis Composition Learning on Image Filters
Mar 01, 2022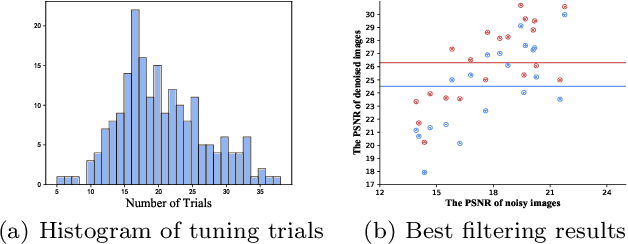
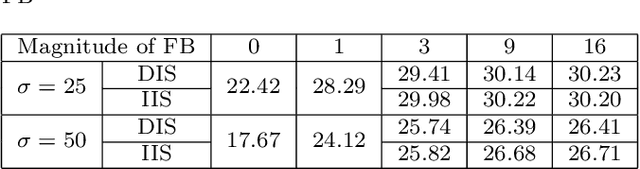
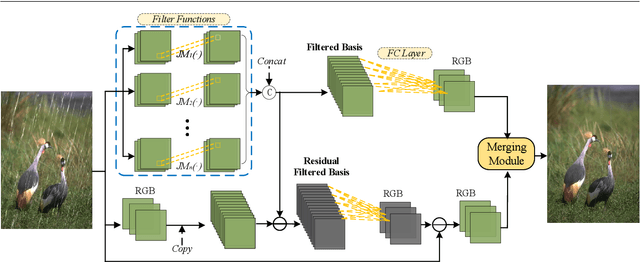
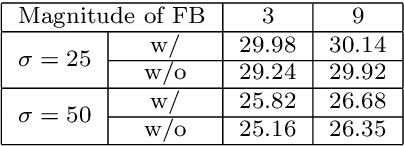
Image filters are fast, lightweight and effective, which make these conventional wisdoms preferable as basic tools in vision tasks. In practical scenarios, users have to tweak parameters multiple times to obtain satisfied results. This inconvenience heavily discounts the efficiency and user experience. We propose basis composition learning on single image filters to automatically determine their optimal formulas. The feasibility is based on a two-step strategy: first, we build a set of filtered basis (FB) consisting of approximations under selected parameter configurations; second, a dual-branch composition module is proposed to learn how the candidates in FB are combined to better approximate the target image. Our method is simple yet effective in practice; it renders filters to be user-friendly and benefits fundamental low-level vision problems including denoising, deraining and texture removal. Extensive experiments demonstrate that our method achieves an appropriate balance among the performance, time complexity and memory efficiency.
Robustness of Deep Recommendation Systems to Untargeted Interaction Perturbations
Jan 29, 2022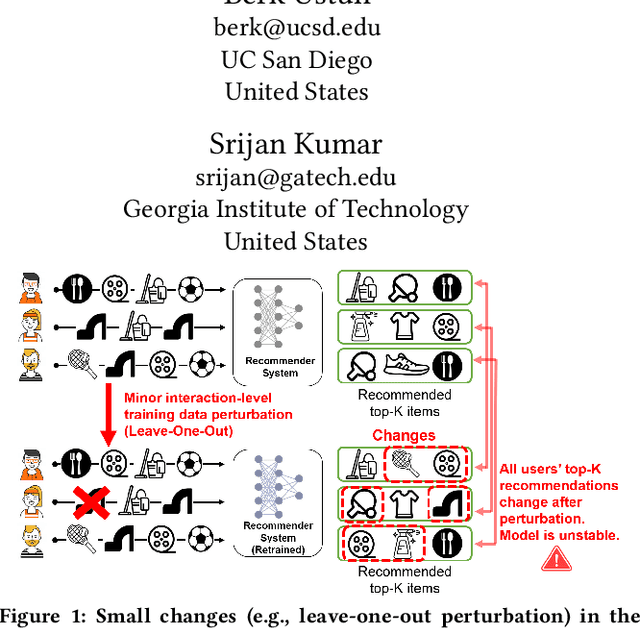

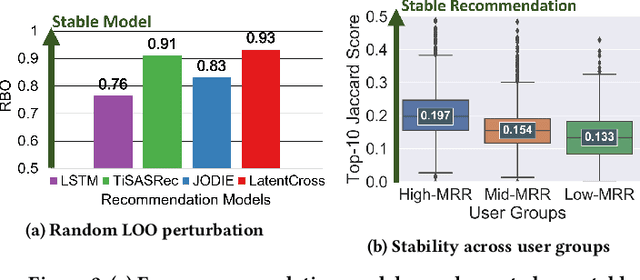
While deep learning-based sequential recommender systems are widely used in practice, their sensitivity to untargeted training data perturbations is unknown. Untargeted perturbations aim to modify ranked recommendation lists for all users at test time, by inserting imperceptible input perturbations during training time. Existing perturbation methods are mostly targeted attacks optimized to change ranks of target items, but not suitable for untargeted scenarios. In this paper, we develop a novel framework in which user-item training interactions are perturbed in unintentional and adversarial settings. First, through comprehensive experiments on four datasets, we show that four popular recommender models are unstable against even one random perturbation. Second, we establish a cascading effect in which minor manipulations of early training interactions can cause extensive changes to the model and the generated recommendations for all users. Leveraging this effect, we propose an adversarial perturbation method CASPER which identifies and perturbs an interaction that induces the maximal cascading effect. Experimentally, we demonstrate that CASPER reduces the stability of recommendation models the most, compared to several baselines and state-of-the-art methods. Finally, we show the runtime and success of CASPER scale near-linearly with the dataset size and the number of perturbations, respectively.
Label-Free Explainability for Unsupervised Models
Mar 03, 2022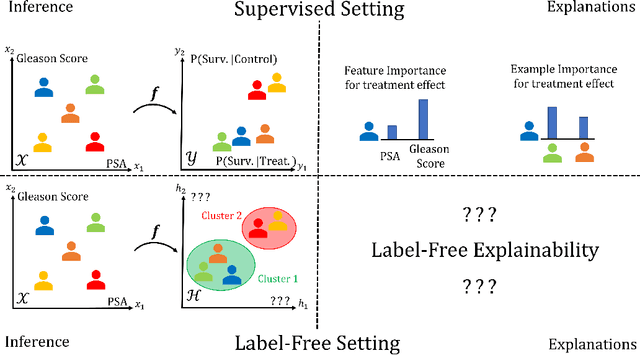


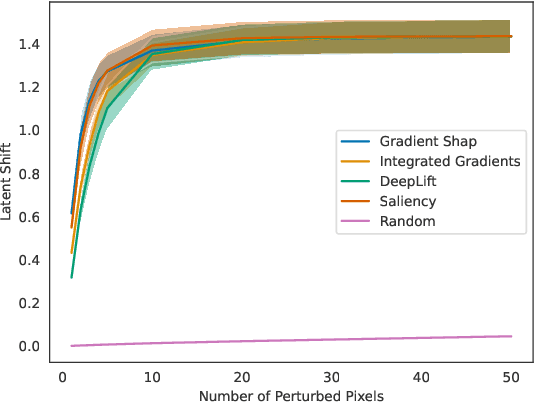
Unsupervised black-box models are challenging to interpret. Indeed, most existing explainability methods require labels to select which component(s) of the black-box's output to interpret. In the absence of labels, black-box outputs often are representation vectors whose components do not correspond to any meaningful quantity. Hence, choosing which component(s) to interpret in a label-free unsupervised/self-supervised setting is an important, yet unsolved problem. To bridge this gap in the literature, we introduce two crucial extensions of post-hoc explanation techniques: (1) label-free feature importance and (2) label-free example importance that respectively highlight influential features and training examples for a black-box to construct representations at inference time. We demonstrate that our extensions can be successfully implemented as simple wrappers around many existing feature and example importance methods. We illustrate the utility of our label-free explainability paradigm through a qualitative and quantitative comparison of representation spaces learned by various autoencoders trained on distinct unsupervised tasks.
Feature Selection for Multivariate Time Series via Network Pruning
Feb 11, 2021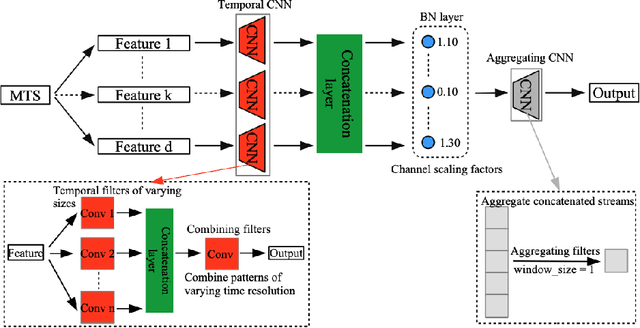
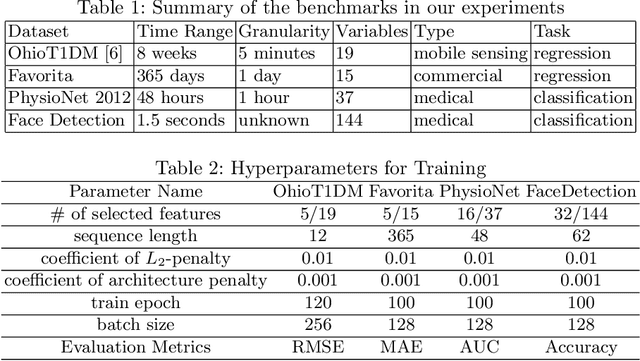

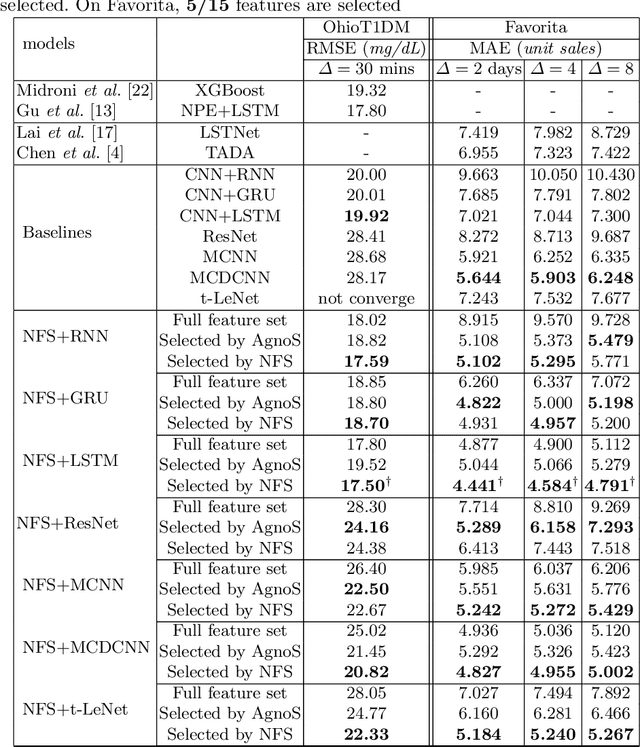
In recent years, there has been an ever increasing amount of multivariate time series (MTS) data in various domains, typically generated by a large family of sensors such as wearable devices. This has led to the development of novel learning methods on MTS data, with deep learning models dominating the most recent advancements. Prior literature has primarily focused on designing new network architectures for modeling temporal dependencies within MTS. However, a less studied challenge is associated with high dimensionality of MTS data. In this paper, we propose a novel neural component, namely Neural Feature Se-lector (NFS), as an end-2-end solution for feature selection in MTS data. Specifically, NFS is based on decomposed convolution design and includes two modules: firstly each feature stream within MTS is processed by a temporal CNN independently; then an aggregating CNN combines the processed streams to produce input for other downstream networks. We evaluated the proposed NFS model on four real-world MTS datasets and found that it achieves comparable results with state-of-the-art methods while providing the benefit of feature selection. Our paper also highlights the robustness and effectiveness of feature selection with NFS compared to using recent autoencoder-based methods.
Multi-image Super-resolution via Quality Map Associated Temporal Attention Network
Feb 26, 2022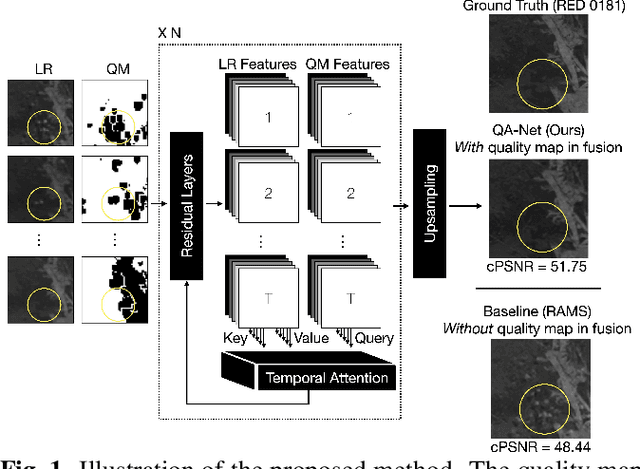
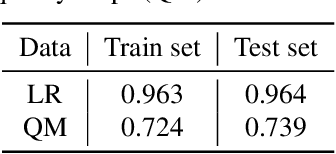

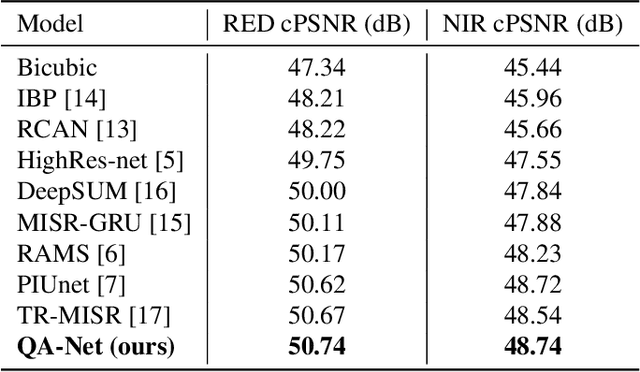
With the rising interest in deep learning-based methods in remote sensing, neural networks have made remarkable advancements in multi-image fusion and super-resolution. To fully exploit the advantages of multi-image super-resolution, temporal attention is crucial as it allows a model to focus on reliable features rather than noises. Despite the presence of quality maps (QMs) that indicate noises in images, most of the methods tested in the PROBA-V dataset have not been used QMs for temporal attention. We present a quality map associated temporal attention network (QA-Net), a novel method that incorporates QMs into both feature representation and fusion processes for the first time. Low-resolution features are temporally attended by QM features in repeated multi-head attention modules. The proposed method achieved state-of-the-art results in the PROBA-V dataset.
TransductGAN: a Transductive Adversarial Model for Novelty Detection
Mar 30, 2022


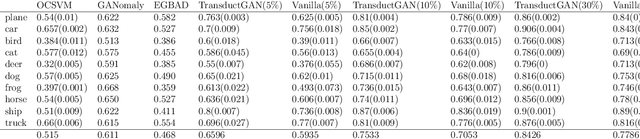
Novelty detection, a widely studied problem in machine learning, is the problem of detecting a novel class of data that has not been previously observed. A common setting for novelty detection is inductive whereby only examples of the negative class are available during training time. Transductive novelty detection on the other hand has only witnessed a recent surge in interest, it not only makes use of the negative class during training but also incorporates the (unlabeled) test set to detect novel examples. Several studies have emerged under the transductive setting umbrella that have demonstrated its advantage over its inductive counterpart. Depending on the assumptions about the data, these methods go by different names (e.g. transductive novelty detection, semi-supervised novelty detection, positive-unlabeled learning, out-of-distribution detection). With the use of generative adversarial networks (GAN), a segment of those studies have adopted a transductive setup in order to learn how to generate examples of the novel class. In this study, we propose TransductGAN, a transductive generative adversarial network that attempts to learn how to generate image examples from both the novel and negative classes by using a mixture of two Gaussians in the latent space. It achieves that by incorporating an adversarial autoencoder with a GAN network, the ability to generate examples of novel data points offers not only a visual representation of novelties, but also overcomes the hurdle faced by many inductive methods of how to tune the model hyperparameters at the decision rule level. Our model has shown superior performance over state-of-the-art inductive and transductive methods. Our study is fully reproducible with the code available publicly.
QCRI's COVID-19 Disinformation Detector: A System to Fight the COVID-19 Infodemic in Social Media
Mar 08, 2022
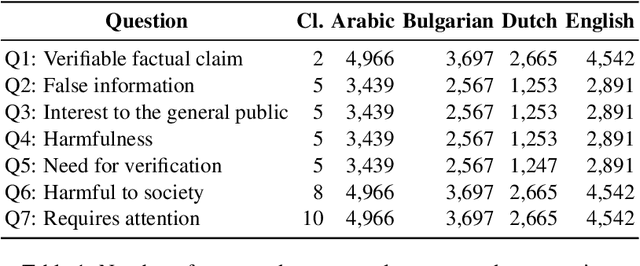
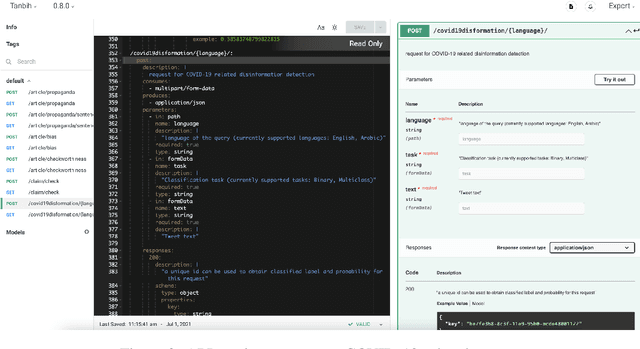
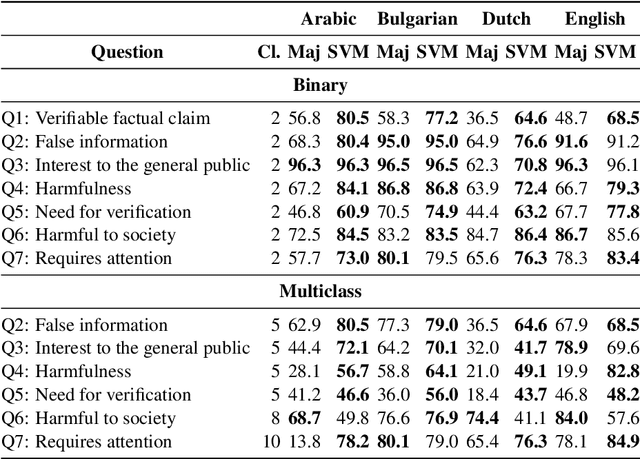
Fighting the ongoing COVID-19 infodemic has been declared as one of the most important focus areas by the World Health Organization since the onset of the COVID-19 pandemic. While the information that is consumed and disseminated consists of promoting fake cures, rumors, and conspiracy theories to spreading xenophobia and panic, at the same time there is information (e.g., containing advice, promoting cure) that can help different stakeholders such as policy-makers. Social media platforms enable the infodemic and there has been an effort to curate the content on such platforms, analyze and debunk them. While a majority of the research efforts consider one or two aspects (e.g., detecting factuality) of such information, in this study we focus on a multifaceted approach, including an API,\url{https://app.swaggerhub.com/apis/yifan2019/Tanbih/0.8.0/} and a demo system,\url{https://covid19.tanbih.org}, which we made freely and publicly available. We believe that this will facilitate researchers and different stakeholders. A screencast of the API services and demo is available.\url{https://youtu.be/zhbcSvxEKMk}
An Effective Graph Learning based Approach for Temporal Link Prediction: The First Place of WSDM Cup 2022
Mar 01, 2022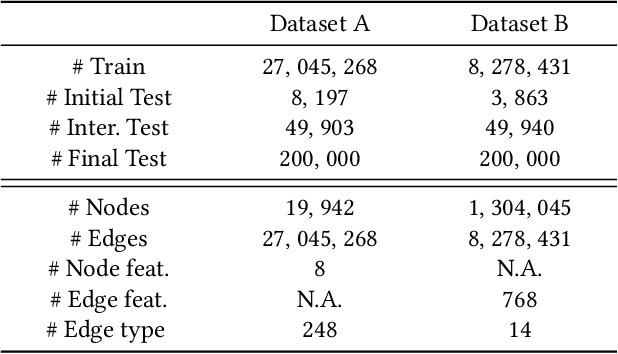


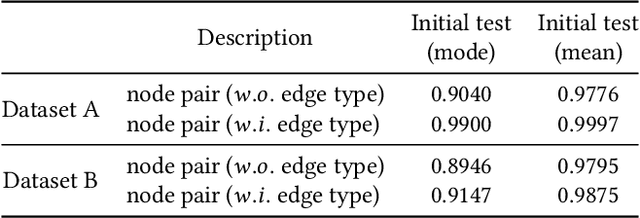
Temporal link prediction, as one of the most crucial work in temporal graphs, has attracted lots of attention from the research area. The WSDM Cup 2022 seeks for solutions that predict the existence probabilities of edges within time spans over temporal graph. This paper introduces the solution of AntGraph, which wins the 1st place in the competition. We first analysis the theoretical upper-bound of the performance by removing temporal information, which implies that only structure and attribute information on the graph could achieve great performance. Based on this hypothesis, then we introduce several well-designed features. Finally, experiments conducted on the competition datasets show the superiority of our proposal, which achieved AUC score of 0.666 on dataset A and 0.902 on dataset B, the ablation studies also prove the efficiency of each feature. Code is publicly available at https://github.com/im0qianqian/WSDM2022TGP-AntGraph.
Dense Air Quality Maps Using Regressive Facility Location Based Drive By Sensing
Jan 20, 2022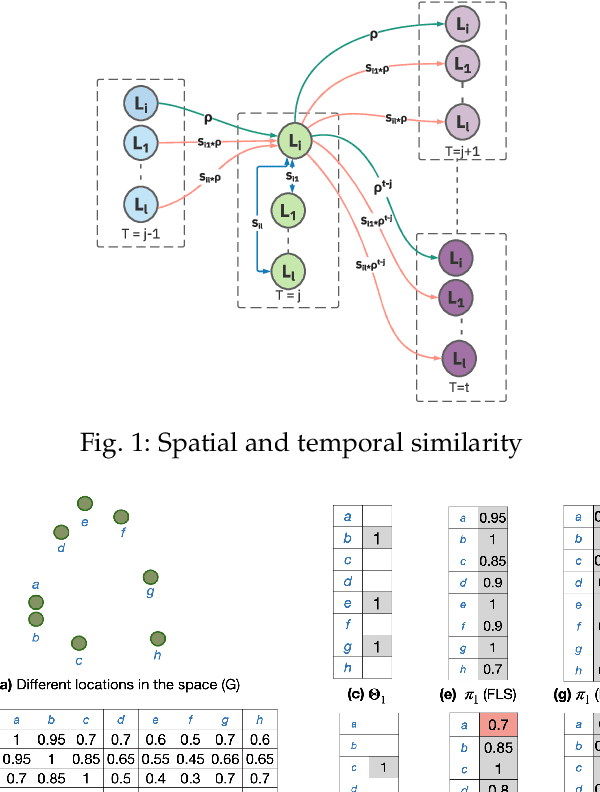
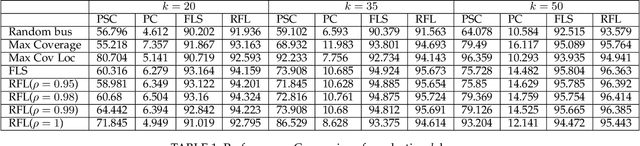

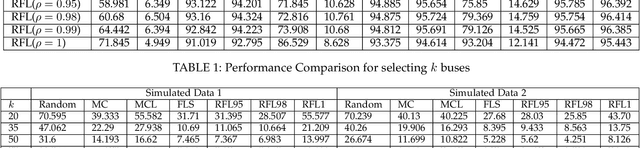
Currently, fixed static sensing is a primary way to monitor environmental data like air quality in cities. However, to obtain a dense spatial coverage, a large number of static monitors are required, thereby making it a costly option. Dense spatiotemporal coverage can be achieved using only a fraction of static sensors by deploying them on the moving vehicles, known as the drive by sensing paradigm. The redundancy present in the air quality data can be exploited by processing the sparsely sampled data to impute the remaining unobserved data points using the matrix completion techniques. However, the accuracy of imputation is dependent on the extent to which the moving sensors capture the inherent structure of the air quality matrix. Therefore, the challenge is to pick those set of paths (using vehicles) that perform representative sampling in space and time. Most works in the literature for vehicle subset selection focus on maximizing the spatiotemporal coverage by maximizing the number of samples for different locations and time stamps which is not an effective representative sampling strategy. We present regressive facility location-based drive by sensing, an efficient vehicle selection framework that incorporates the smoothness in neighboring locations and autoregressive time correlation while selecting the optimal set of vehicles for effective spatiotemporal sampling. We show that the proposed drive by sensing problem is submodular, thereby lending itself to a greedy algorithm but with performance guarantees. We evaluate our framework on selecting a subset from the fleet of public transport in Delhi, India. We illustrate that the proposed method samples the representative spatiotemporal data against the baseline methods, reducing the extrapolation error on the simulated air quality data. Our method, therefore, has the potential to provide cost effective dense air quality maps.