 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Monaural Speech Enhancement with Complex Convolutional Block Attention Module and Joint Time Frequency Losses
Feb 03, 2021
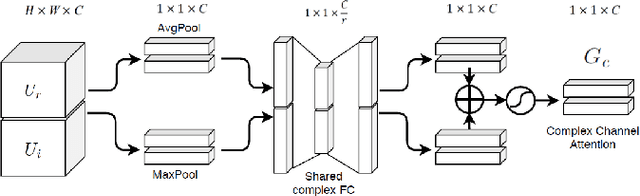
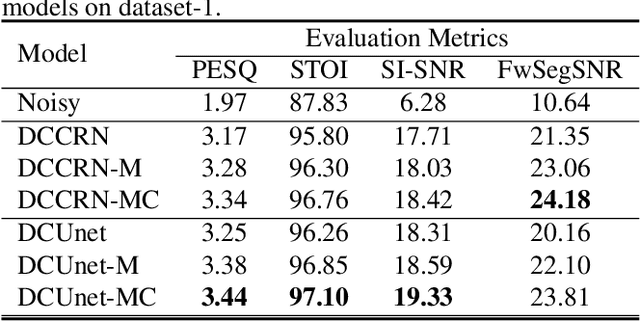
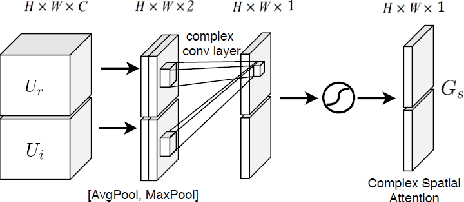
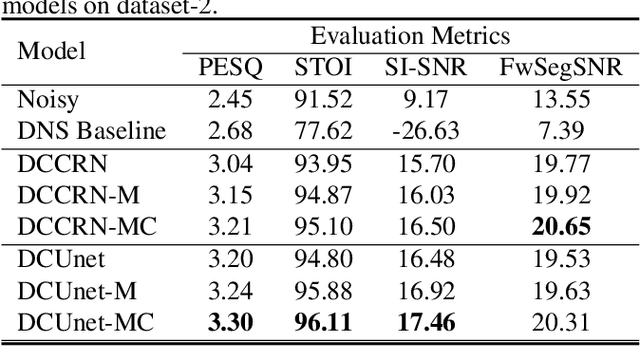
Deep complex U-Net structure and convolutional recurrent network (CRN) structure achieve state-of-the-art performance for monaural speech enhancement. Both deep complex U-Net and CRN are encoder and decoder structures with skip connections, which heavily rely on the representation power of the complex-valued convolutional layers. In this paper, we propose a complex convolutional block attention module (CCBAM) to boost the representation power of the complex-valued convolutional layers by constructing more informative features. The CCBAM is a lightweight and general module which can be easily integrated into any complex-valued convolutional layers. We integrate CCBAM with the deep complex U-Net and CRN to enhance their performance for speech enhancement. We further propose a mixed loss function to jointly optimize the complex models in both time-frequency (TF) domain and time domain. By integrating CCBAM and the mixed loss, we form a new end-to-end (E2E) complex speech enhancement framework. Ablation experiments and objective evaluations show the superior performance of the proposed approaches.
Short-term prediction of Time Series based on bounding techniques
Jan 26, 2021
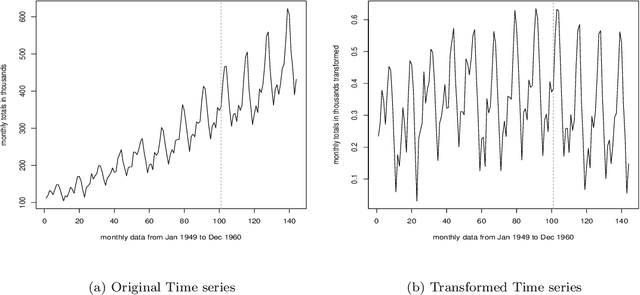
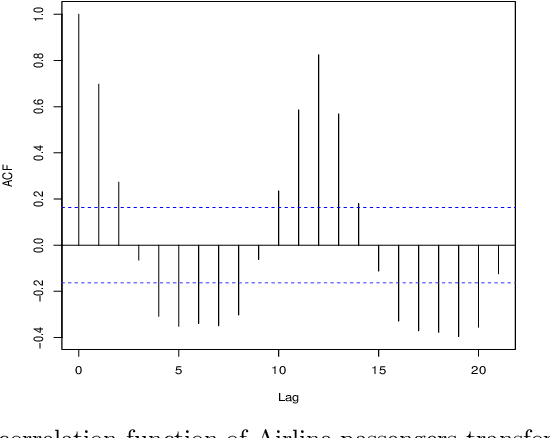

In this paper it is reconsidered the prediction problem in time series framework by using a new non-parametric approach. Through this reconsideration, the prediction is obtained by a weighted sum of past observed data. These weights are obtained by solving a constrained linear optimization problem that minimizes an outer bound of the prediction error. The innovation is to consider both deterministic and stochastic assumptions in order to obtain the upper bound of the prediction error, a tuning parameter is used to balance these deterministic-stochastic assumptions in order to improve the predictor performance. A benchmark is included to illustrate that the proposed predictor can obtain suitable results in a prediction scheme, and can be an interesting alternative method to the classical non-parametric methods. Besides, it is shown how this model can outperform the preexisting ones in a short term forecast.
Defending Black-box Skeleton-based Human Activity Classifiers
Mar 09, 2022
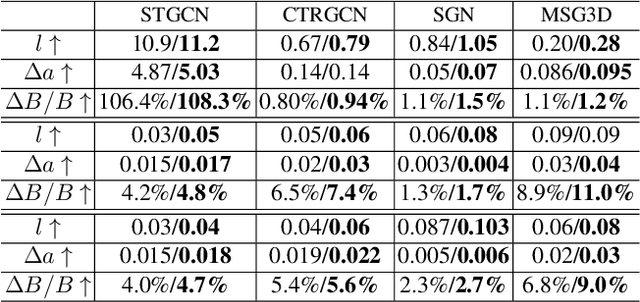
Deep learning has been regarded as the `go to' solution for many tasks today, but its intrinsic vulnerability to malicious attacks has become a major concern. The vulnerability is affected by a variety of factors including models, tasks, data, and attackers. Consequently, methods such as Adversarial Training and Randomized Smoothing have been proposed to tackle the problem in a wide range of applications. In this paper, we investigate skeleton-based Human Activity Recognition, which is an important type of time-series data but under-explored in defense against attacks. Our method is featured by (1) a new Bayesian Energy-based formulation of robust discriminative classifiers, (2) a new parameterization of the adversarial sample manifold of actions, and (3) a new post-train Bayesian treatment on both the adversarial samples and the classifier. We name our framework Bayesian Energy-based Adversarial Training or BEAT. BEAT is straightforward but elegant, which turns vulnerable black-box classifiers into robust ones without sacrificing accuracy. It demonstrates surprising and universal effectiveness across a wide range of action classifiers and datasets, under various attacks.
Time-of-Flight LiDAR-based Precise Mapping
Sep 21, 2020Last two decades, the problem of robotic mapping has made a lot of progress in the research community. However, since the data provided by the sensor still contains noise, how to obtain an accurate map is still an open problem. In this note, we analyze the problem from the perspective of mathematical analysis and propose a probabilistic map update method based on multiple explorations. The proposed method can help us estimate the number of rounds of robot exploration, which is meaningful for the hardware and time costs of the task.
Quantum neural networks force fields generation
Mar 09, 2022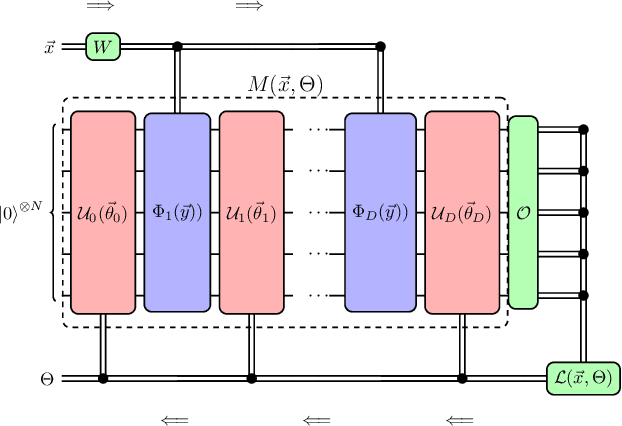

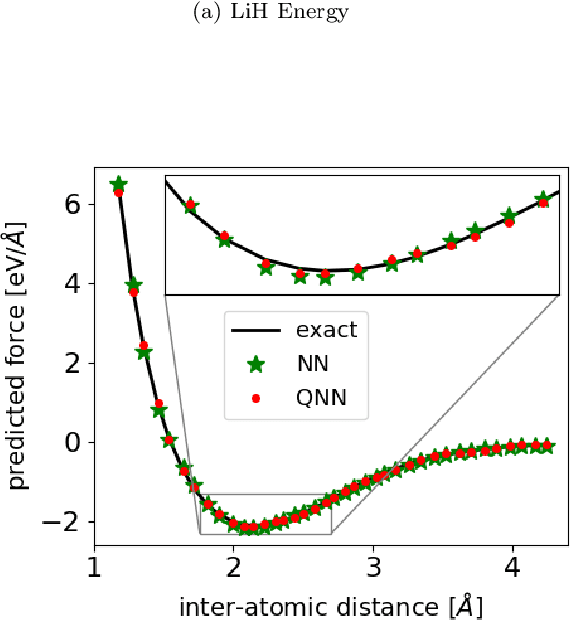
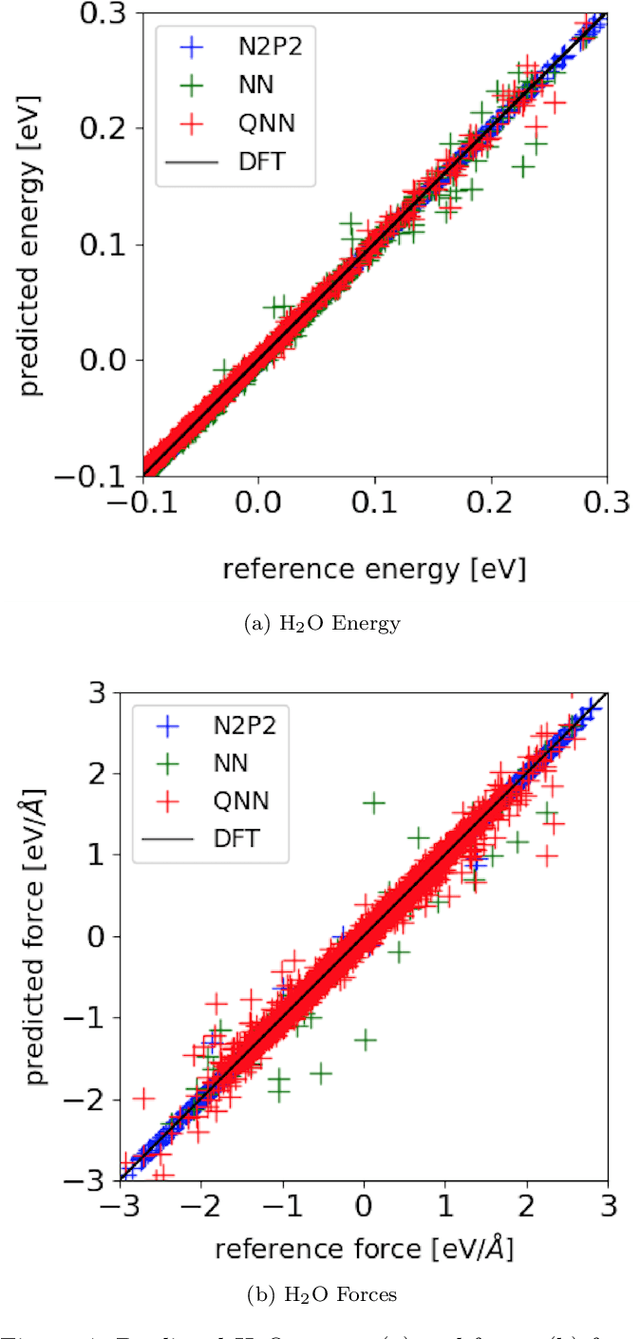
Accurate molecular force fields are of paramount importance for the efficient implementation of molecular dynamics techniques at large scales. In the last decade, machine learning methods have demonstrated impressive performances in predicting accurate values for energy and forces when trained on finite size ensembles generated with ab initio techniques. At the same time, quantum computers have recently started to offer new viable computational paradigms to tackle such problems. On the one hand, quantum algorithms may notably be used to extend the reach of electronic structure calculations. On the other hand, quantum machine learning is also emerging as an alternative and promising path to quantum advantage. Here we follow this second route and establish a direct connection between classical and quantum solutions for learning neural network potentials. To this end, we design a quantum neural network architecture and apply it successfully to different molecules of growing complexity. The quantum models exhibit larger effective dimension with respect to classical counterparts and can reach competitive performances, thus pointing towards potential quantum advantages in natural science applications via quantum machine learning.
Ray Tracing-Guided Design of Plenoptic Cameras
Mar 09, 2022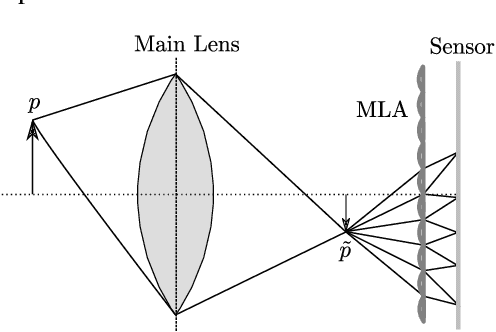


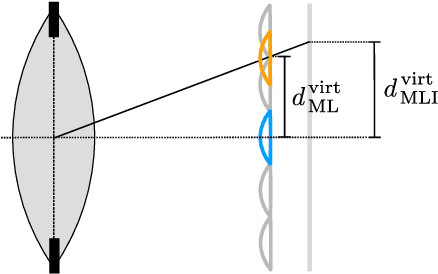
The design of a plenoptic camera requires the combination of two dissimilar optical systems, namely a main lens and an array of microlenses. And while the construction process of a conventional camera is mainly concerned with focusing the image onto a single plane, in the case of plenoptic cameras there can be additional requirements such as a predefined depth of field or a desired range of disparities in neighboring microlens images. Due to this complexity, the manual creation of multiple plenoptic camera setups is often a time-consuming task. In this work we assume a simulation framework as well as the main lens data given and present a method to calculate the remaining aperture, sensor and microlens array parameters under different sets of constraints. Our ray tracing-based approach is shown to result in models outperforming their pendants generated with the commonly used paraxial approximations in terms of image quality, while still meeting the desired constraints. Both the implementation and evaluation setup including 30 plenoptic camera designs are made publicly available.
In-flight Novelty Detection with Convolutional Neural Networks
Dec 07, 2021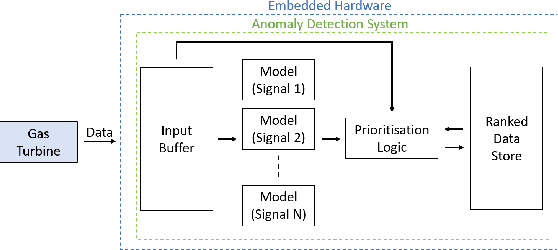
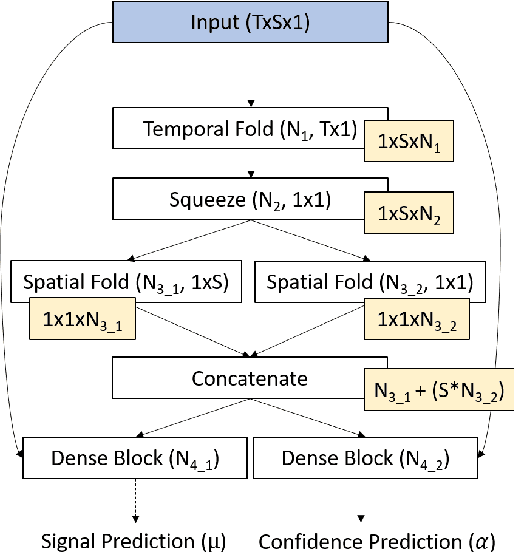
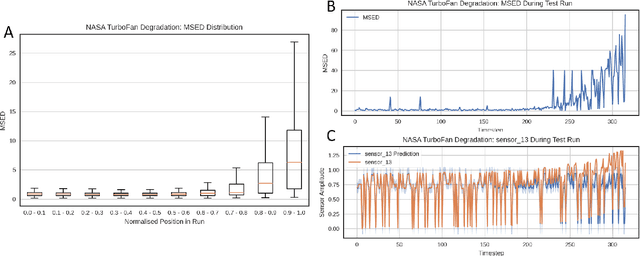
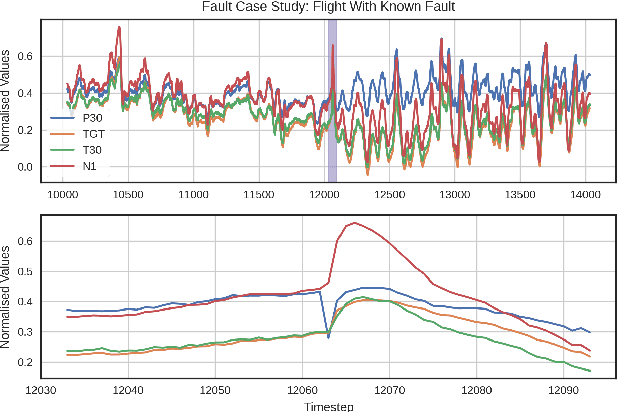
Gas turbine engines are complex machines that typically generate a vast amount of data, and require careful monitoring to allow for cost-effective preventative maintenance. In aerospace applications, returning all measured data to ground is prohibitively expensive, often causing useful, high value, data to be discarded. The ability to detect, prioritise, and return useful data in real-time is therefore vital. This paper proposes that system output measurements, described by a convolutional neural network model of normality, are prioritised in real-time for the attention of preventative maintenance decision makers. Due to the complexity of gas turbine engine time-varying behaviours, deriving accurate physical models is difficult, and often leads to models with low prediction accuracy and incompatibility with real-time execution. Data-driven modelling is a desirable alternative producing high accuracy, asset specific models without the need for derivation from first principles. We present a data-driven system for online detection and prioritisation of anomalous data. Biased data assessment deriving from novel operating conditions is avoided by uncertainty management integrated into the deep neural predictive model. Testing is performed on real and synthetic data, showing sensitivity to both real and synthetic faults. The system is capable of running in real-time on low-power embedded hardware and is currently in deployment on the Rolls-Royce Pearl 15 engine flight trials.
A Survey on Model Compression for Natural Language Processing
Feb 15, 2022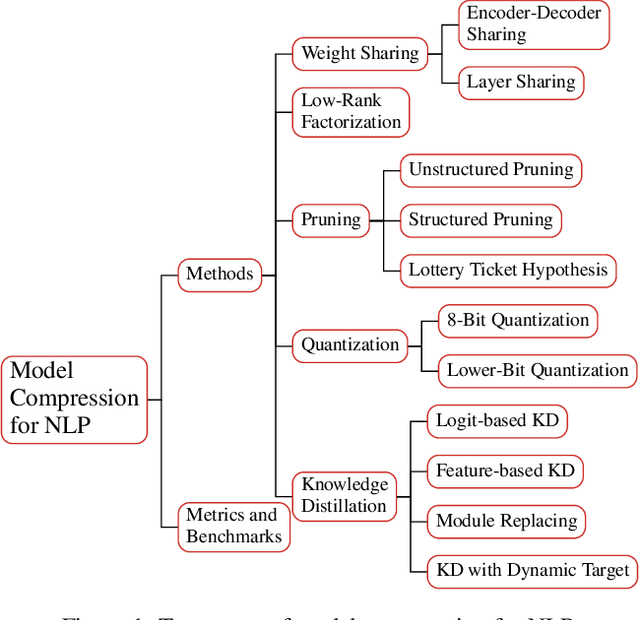

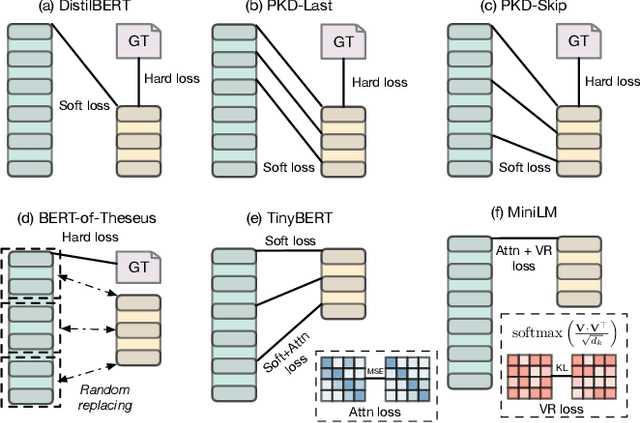
With recent developments in new architectures like Transformer and pretraining techniques, significant progress has been made in applications of natural language processing (NLP). However, the high energy cost and long inference delay of Transformer is preventing NLP from entering broader scenarios including edge and mobile computing. Efficient NLP research aims to comprehensively consider computation, time and carbon emission for the entire life-cycle of NLP, including data preparation, model training and inference. In this survey, we focus on the inference stage and review the current state of model compression for NLP, including the benchmarks, metrics and methodology. We outline the current obstacles and future research directions.
Hate Speech Classification Using SVM and Naive BAYES
Mar 21, 2022
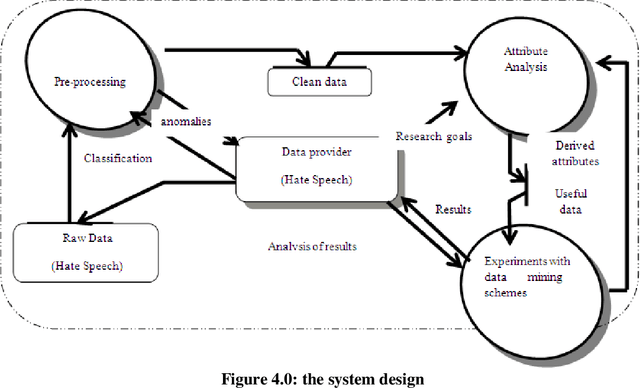
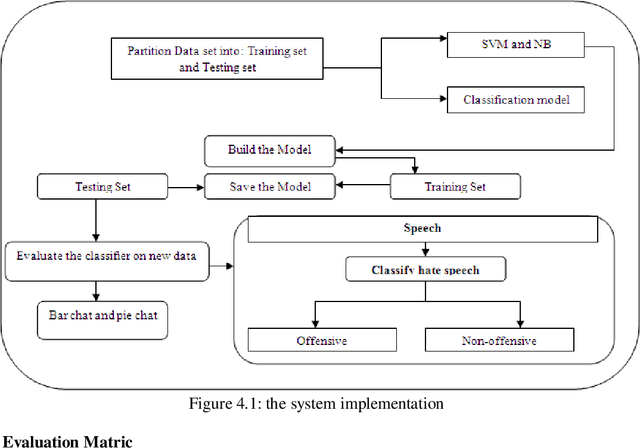
The spread of hatred that was formerly limited to verbal communications has rapidly moved over the Internet. Social media and community forums that allow people to discuss and express their opinions are becoming platforms for the spreading of hate messages. Many countries have developed laws to avoid online hate speech. They hold the companies that run the social media responsible for their failure to eliminate hate speech. But as online content continues to grow, so does the spread of hate speech However, manual analysis of hate speech on online platforms is infeasible due to the huge amount of data as it is expensive and time consuming. Thus, it is important to automatically process the online user contents to detect and remove hate speech from online media. Many recent approaches suffer from interpretability problem which means that it can be difficult to understand why the systems make the decisions they do. Through this work, some solutions for the problem of automatic detection of hate messages were proposed using Support Vector Machine (SVM) and Na\"ive Bayes algorithms. This achieved near state-of-the-art performance while being simpler and producing more easily interpretable decisions than other methods. Empirical evaluation of this technique has resulted in a classification accuracy of approximately 99% and 50% for SVM and NB respectively over the test set. Keywords: classification; hate speech; feature extraction, algorithm, supervised learning
Multi-modal Brain Tumor Segmentation via Missing Modality Synthesis and Modality-level Attention Fusion
Mar 09, 2022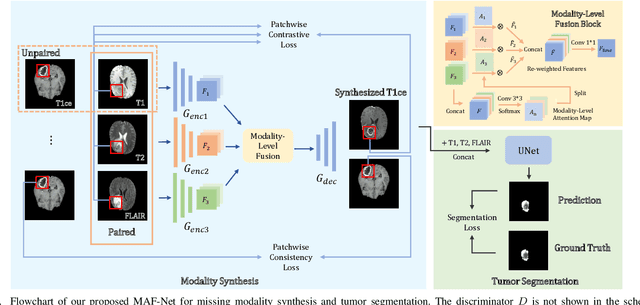
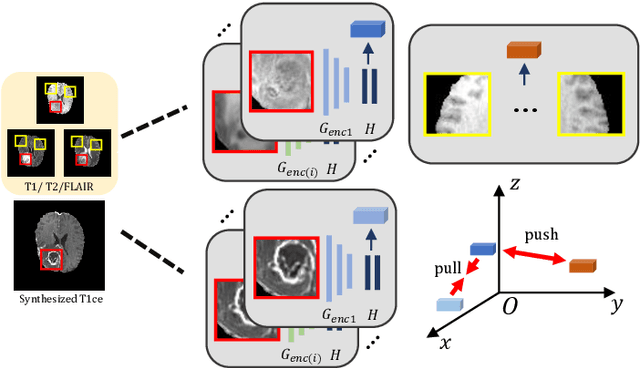
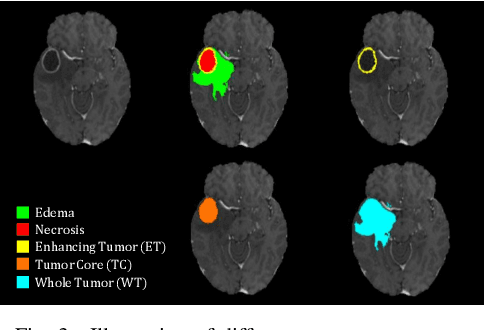
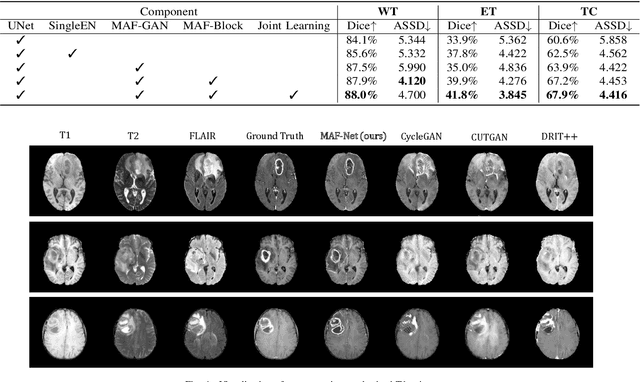
Multi-modal magnetic resonance (MR) imaging provides great potential for diagnosing and analyzing brain gliomas. In clinical scenarios, common MR sequences such as T1, T2 and FLAIR can be obtained simultaneously in a single scanning process. However, acquiring contrast enhanced modalities such as T1ce requires additional time, cost, and injection of contrast agent. As such, it is clinically meaningful to develop a method to synthesize unavailable modalities which can also be used as additional inputs to downstream tasks (e.g., brain tumor segmentation) for performance enhancing. In this work, we propose an end-to-end framework named Modality-Level Attention Fusion Network (MAF-Net), wherein we innovatively conduct patchwise contrastive learning for extracting multi-modal latent features and dynamically assigning attention weights to fuse different modalities. Through extensive experiments on BraTS2020, our proposed MAF-Net is found to yield superior T1ce synthesis performance (SSIM of 0.8879 and PSNR of 22.78) and accurate brain tumor segmentation (mean Dice scores of 67.9%, 41.8% and 88.0% on segmenting the tumor core, enhancing tumor and whole tumor).