 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Confidence Threshold Neural Diving
Feb 15, 2022
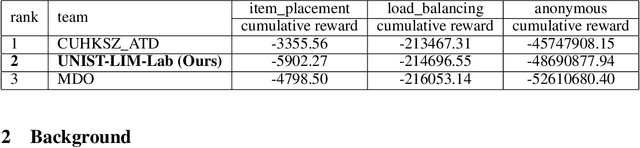
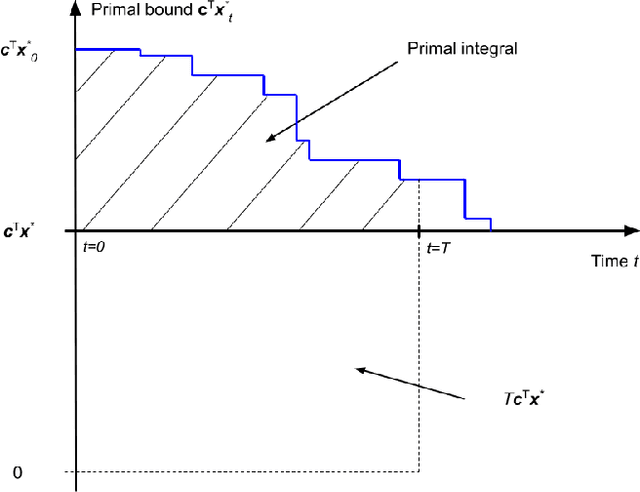
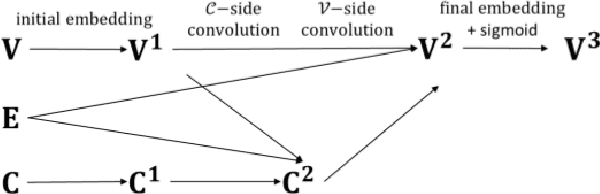
Finding a better feasible solution in a shorter time is an integral part of solving Mixed Integer Programs. We present a post-hoc method based on Neural Diving to build heuristics more flexibly. We hypothesize that variables with higher confidence scores are more definite to be included in the optimal solution. For our hypothesis, we provide empirical evidence that confidence threshold technique produces partial solutions leading to final solutions with better primal objective values. Our method won 2nd place in the primal task on the NeurIPS 2021 ML4CO competition. Also, our method shows the best score among other learning-based methods in the competition.
CheckSel: Efficient and Accurate Data-valuation Through Online Checkpoint Selection
Mar 14, 2022
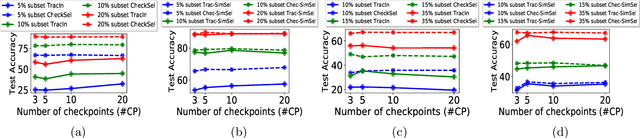
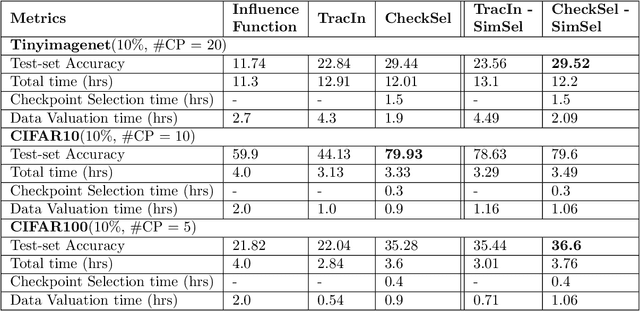
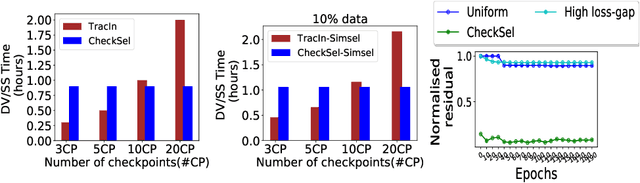
Data valuation and subset selection have emerged as valuable tools for application-specific selection of important training data. However, the efficiency-accuracy tradeoffs of state-of-the-art methods hinder their widespread application to many AI workflows. In this paper, we propose a novel 2-phase solution to this problem. Phase 1 selects representative checkpoints from an SGD-like training algorithm, which are used in phase-2 to estimate the approximate training data values, e.g. decrease in validation loss due to each training point. A key contribution of this paper is CheckSel, an Orthogonal Matching Pursuit-inspired online sparse approximation algorithm for checkpoint selection in the online setting, where the features are revealed one at a time. Another key contribution is the study of data valuation in the domain adaptation setting, where a data value estimator obtained using checkpoints from training trajectory in the source domain training dataset is used for data valuation in a target domain training dataset. Experimental results on benchmark datasets show the proposed algorithm outperforms recent baseline methods by up to 30% in terms of test accuracy while incurring a similar computational burden, for both standalone and domain adaptation settings.
TimeLMs: Diachronic Language Models from Twitter
Feb 08, 2022
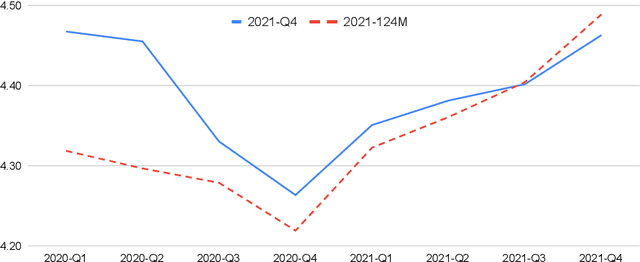
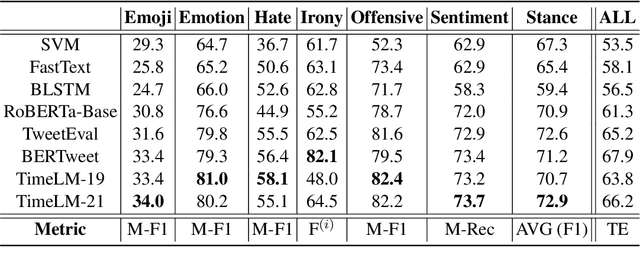
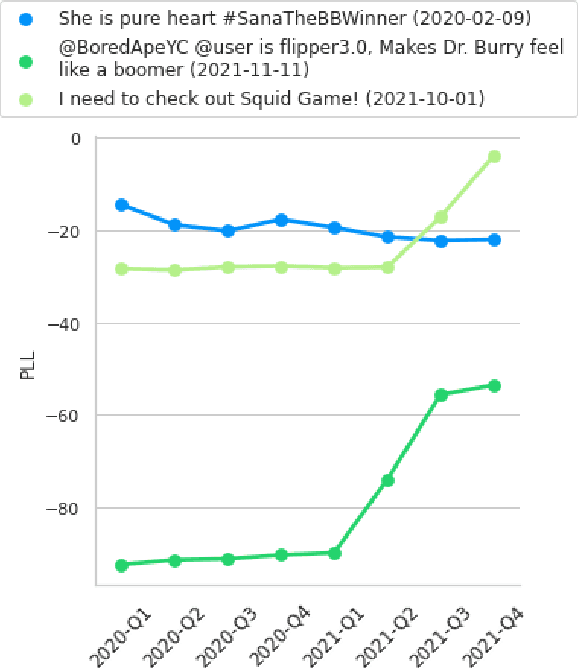
Despite its importance, the time variable has been largely neglected in the NLP and language model literature. In this paper, we present TimeLMs, a set of language models specialized on diachronic Twitter data. We show that a continual learning strategy contributes to enhancing Twitter-based language models' capacity to deal with future and out-of-distribution tweets, while making them competitive with standardized and more monolithic benchmarks. We also perform a number of qualitative analyses showing how they cope with trends and peaks in activity involving specific named entities or concept drift.
Evaluation of Time Series Forecasting Models for Estimation of PM2.5 Levels in Air
Apr 07, 2021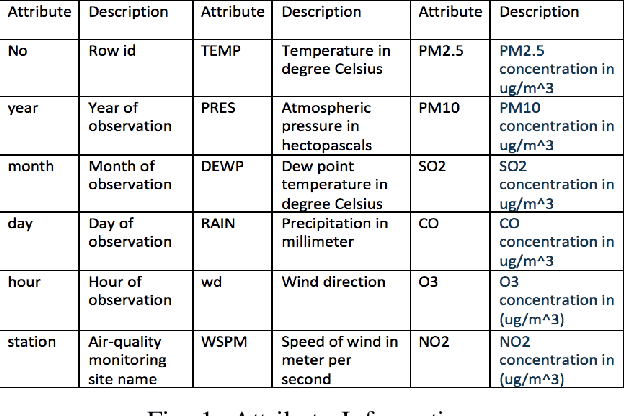
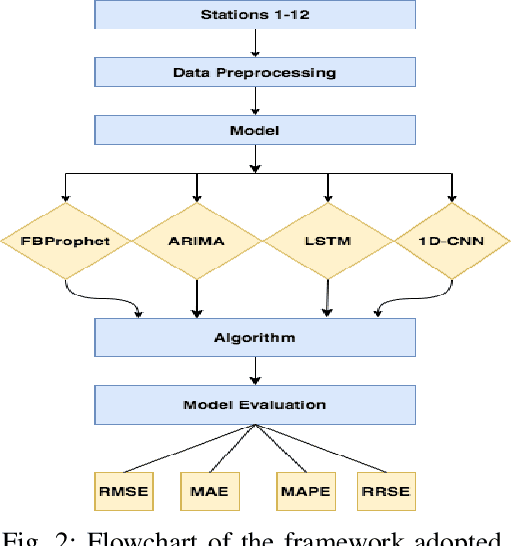
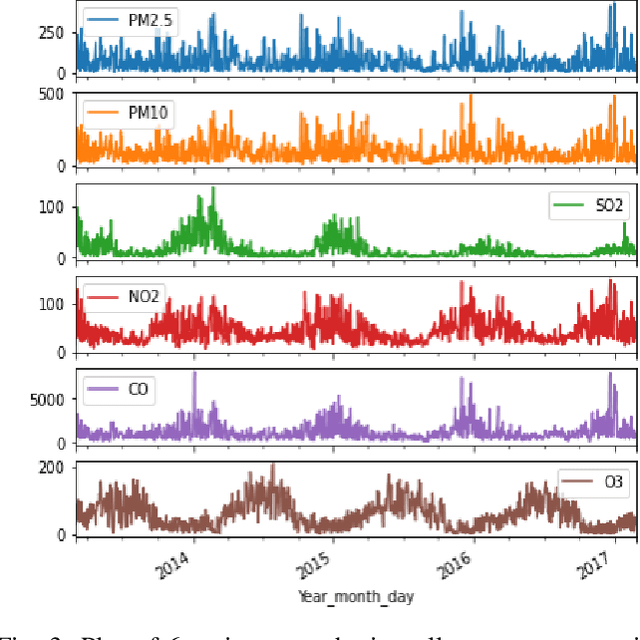
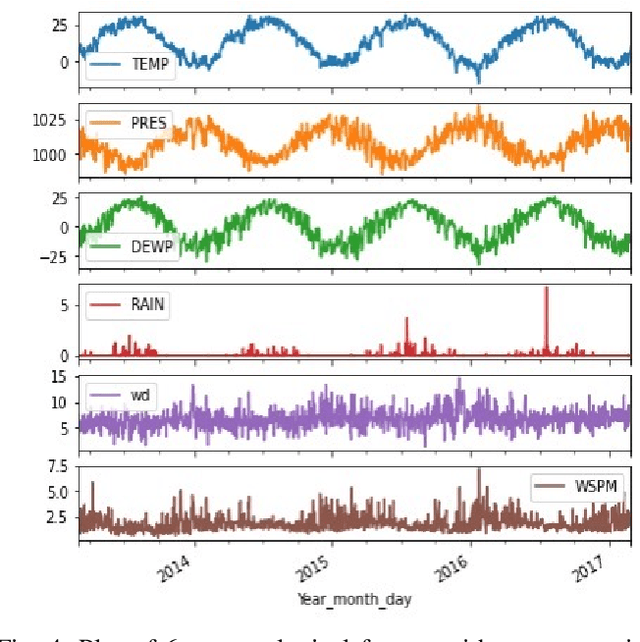
Air contamination in urban areas has risen consistently over the past few years. Due to expanding industrialization and increasing concentration of toxic gases in the climate, the air is getting more poisonous step by step at an alarming rate. Since the arrival of the Coronavirus pandemic, it is getting more critical to lessen air contamination to reduce its impact. The specialists and environmentalists are making a valiant effort to gauge air contamination levels. However, its genuinely unpredictable to mimic subatomic communication in the air, which brings about off base outcomes. There has been an ascent in using machine learning and deep learning models to foresee the results on time series data. This study adopts ARIMA, FBProphet, and deep learning models such as LSTM, 1D CNN, to estimate the concentration of PM2.5 in the environment. Our predicted results convey that all adopted methods give comparative outcomes in terms of average root mean squared error. However, the LSTM outperforms all other models with reference to mean absolute percentage error.
Geometric Optimisation on Manifolds with Applications to Deep Learning
Mar 09, 2022
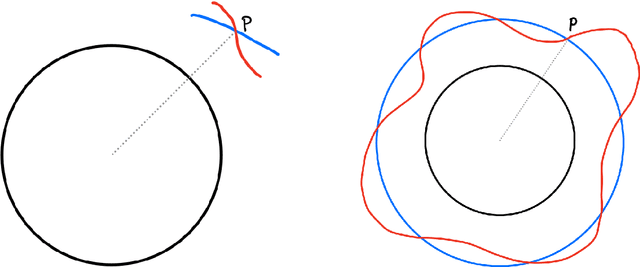
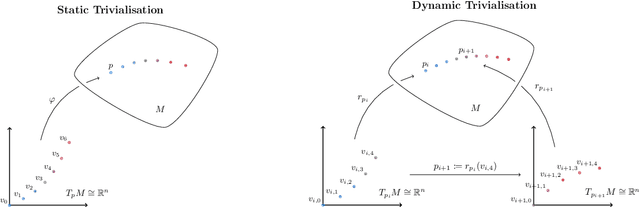
We design and implement a Python library to help the non-expert using all these powerful tools in a way that is efficient, extensible, and simple to incorporate into the workflow of the data scientist, practitioner, and applied researcher. The algorithms implemented in this library have been designed with usability and GPU efficiency in mind, and they can be added to any PyTorch model with just one extra line of code. We showcase the effectiveness of these tools on an application of optimisation on manifolds in the setting of time series analysis. In this setting, orthogonal and unitary optimisation is used to constraint and regularise recurrent models and avoid vanishing and exploding gradient problems. The algorithms designed for GeoTorch allow us to achieve state of the art results in the standard tests for this family of models. We use tools from comparison geometry to give bounds on quantities that are of interest in optimisation problems. In particular, we build on the work of (Kaul 1976) to give explicit bounds on the norm of the second derivative of the Riemannian exponential.
Human Instance Segmentation and Tracking via Data Association and Single-stage Detector
Mar 31, 2022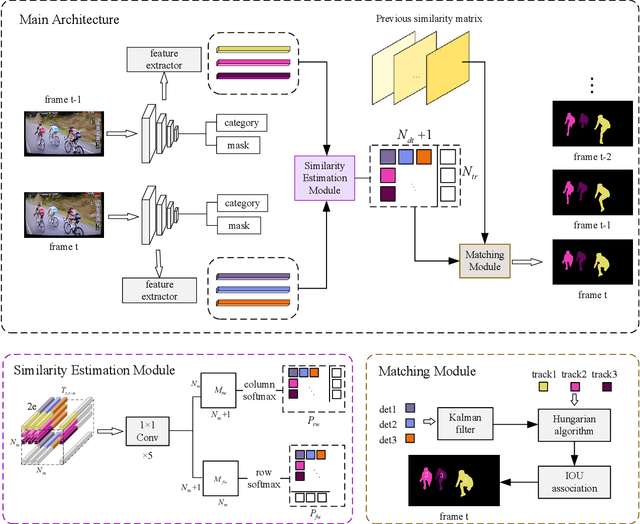


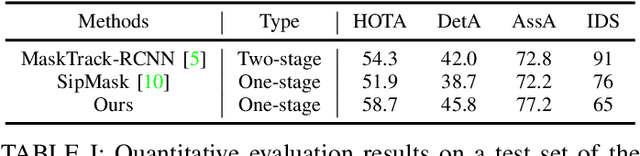
Human video instance segmentation plays an important role in computer understanding of human activities and is widely used in video processing, video surveillance, and human modeling in virtual reality. Most current VIS methods are based on Mask-RCNN framework, where the target appearance and motion information for data matching will increase computational cost and have an impact on segmentation real-time performance; on the other hand, the existing datasets for VIS focus less on all the people appearing in the video. In this paper, to solve the problems, we develop a new method for human video instance segmentation based on single-stage detector. To tracking the instance across the video, we have adopted data association strategy for matching the same instance in the video sequence, where we jointly learn target instance appearances and their affinities in a pair of video frames in an end-to-end fashion. We have also adopted the centroid sampling strategy for enhancing the embedding extraction ability of instance, which is to bias the instance position to the inside of each instance mask with heavy overlap condition. As a result, even there exists a sudden change in the character activity, the instance position will not move out of the mask, so that the problem that the same instance is represented by two different instances can be alleviated. Finally, we collect PVIS dataset by assembling several video instance segmentation datasets to fill the gap of the current lack of datasets dedicated to human video segmentation. Extensive simulations based on such dataset has been conduct. Simulation results verify the effectiveness and efficiency of the proposed work.
An Evaluation of Classification Methods for 3D Printing Time-Series Data
Oct 02, 2020
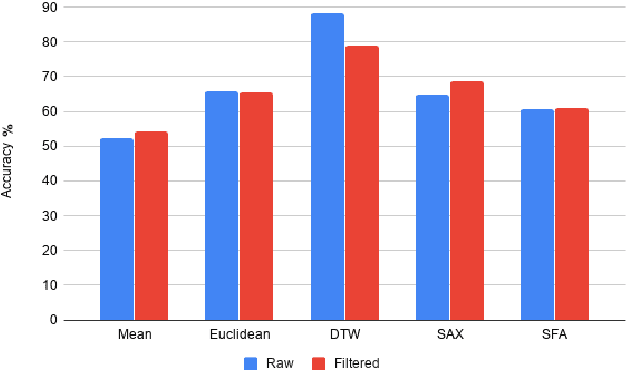
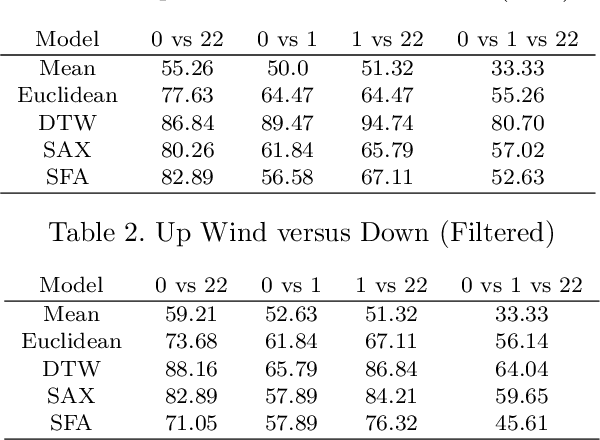
Additive Manufacturing presents a great application area for Machine Learning because of the vast volume of data generated and the potential to mine this data to control outcomes. In this paper we present preliminary work on classifying infrared time-series data representing melt-pool temperature in a metal 3D printing process. Our ultimate objective is to use this data to predict process outcomes (e.g. hardness, porosity, surface roughness). In the work presented here we simply show that there is a signal in this data that can be used for the classification of different components and stages of the AM process. In line with other Machine Learning research on time-series classification we use k-Nearest Neighbour classifiers. The results we present suggests that Dynamic Time Warping is an effective distance measure compared with alternatives for 3D printing data of this type.
Defending Black-box Skeleton-based Human Activity Classifiers
Mar 09, 2022
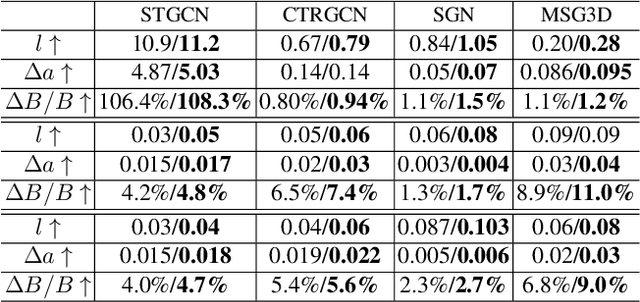
Deep learning has been regarded as the `go to' solution for many tasks today, but its intrinsic vulnerability to malicious attacks has become a major concern. The vulnerability is affected by a variety of factors including models, tasks, data, and attackers. Consequently, methods such as Adversarial Training and Randomized Smoothing have been proposed to tackle the problem in a wide range of applications. In this paper, we investigate skeleton-based Human Activity Recognition, which is an important type of time-series data but under-explored in defense against attacks. Our method is featured by (1) a new Bayesian Energy-based formulation of robust discriminative classifiers, (2) a new parameterization of the adversarial sample manifold of actions, and (3) a new post-train Bayesian treatment on both the adversarial samples and the classifier. We name our framework Bayesian Energy-based Adversarial Training or BEAT. BEAT is straightforward but elegant, which turns vulnerable black-box classifiers into robust ones without sacrificing accuracy. It demonstrates surprising and universal effectiveness across a wide range of action classifiers and datasets, under various attacks.
Uncertainty-Aware Deep Ensembles for Reliable and Explainable Predictions of Clinical Time Series
Oct 16, 2020
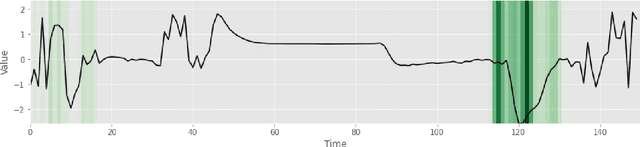
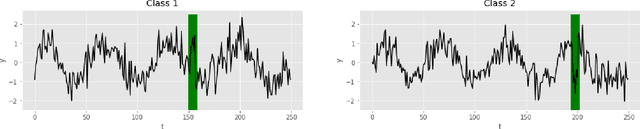
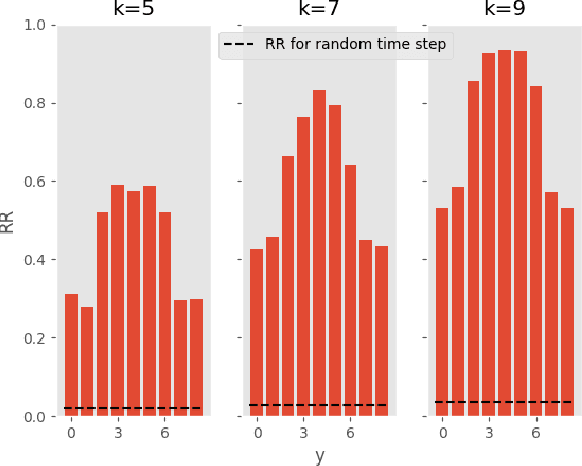
Deep learning-based support systems have demonstrated encouraging results in numerous clinical applications involving the processing of time series data. While such systems often are very accurate, they have no inherent mechanism for explaining what influenced the predictions, which is critical for clinical tasks. However, existing explainability techniques lack an important component for trustworthy and reliable decision support, namely a notion of uncertainty. In this paper, we address this lack of uncertainty by proposing a deep ensemble approach where a collection of DNNs are trained independently. A measure of uncertainty in the relevance scores is computed by taking the standard deviation across the relevance scores produced by each model in the ensemble, which in turn is used to make the explanations more reliable. The class activation mapping method is used to assign a relevance score for each time step in the time series. Results demonstrate that the proposed ensemble is more accurate in locating relevant time steps and is more consistent across random initializations, thus making the model more trustworthy. The proposed methodology paves the way for constructing trustworthy and dependable support systems for processing clinical time series for healthcare related tasks.
Hate Speech Classification Using SVM and Naive BAYES
Mar 21, 2022
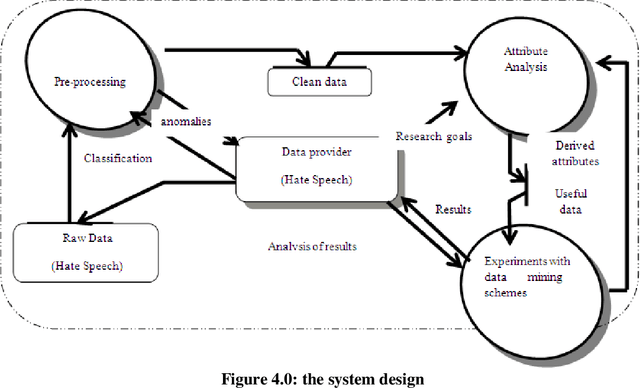
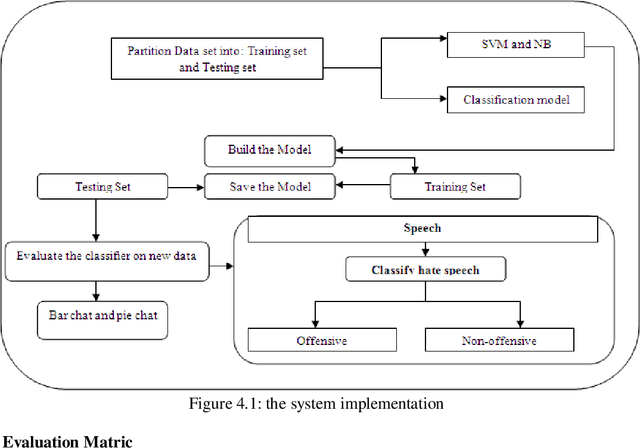
The spread of hatred that was formerly limited to verbal communications has rapidly moved over the Internet. Social media and community forums that allow people to discuss and express their opinions are becoming platforms for the spreading of hate messages. Many countries have developed laws to avoid online hate speech. They hold the companies that run the social media responsible for their failure to eliminate hate speech. But as online content continues to grow, so does the spread of hate speech However, manual analysis of hate speech on online platforms is infeasible due to the huge amount of data as it is expensive and time consuming. Thus, it is important to automatically process the online user contents to detect and remove hate speech from online media. Many recent approaches suffer from interpretability problem which means that it can be difficult to understand why the systems make the decisions they do. Through this work, some solutions for the problem of automatic detection of hate messages were proposed using Support Vector Machine (SVM) and Na\"ive Bayes algorithms. This achieved near state-of-the-art performance while being simpler and producing more easily interpretable decisions than other methods. Empirical evaluation of this technique has resulted in a classification accuracy of approximately 99% and 50% for SVM and NB respectively over the test set. Keywords: classification; hate speech; feature extraction, algorithm, supervised learning