 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Gradient Estimator for Time-Varying Electrical Networks with Non-Linear Dissipation
Mar 09, 2021
We propose a method for extending the technique of equilibrium propagation for estimating gradients in fixed-point neural networks to the more general setting of directed, time-varying neural networks by modeling them as electrical circuits. We use electrical circuit theory to construct a Lagrangian capable of describing deep, directed neural networks modeled using nonlinear capacitors and inductors, linear resistors and sources, and a special class of nonlinear dissipative elements called fractional memristors. We then derive an estimator for the gradient of the physical parameters of the network, such as synapse conductances, with respect to an arbitrary loss function. This estimator is entirely local, in that it only depends on information locally available to each synapse. We conclude by suggesting methods for extending these results to networks of biologically plausible neurons, e.g. Hodgkin-Huxley neurons.
Improving the Accuracy of Global Forecasting Models using Time Series Data Augmentation
Aug 06, 2020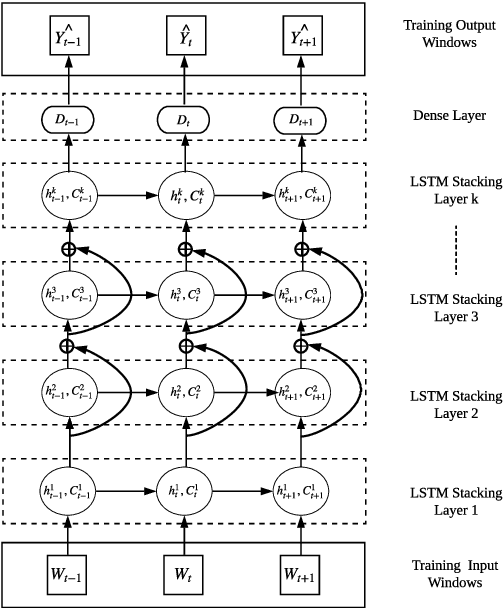
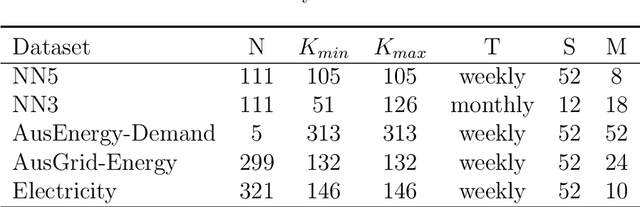
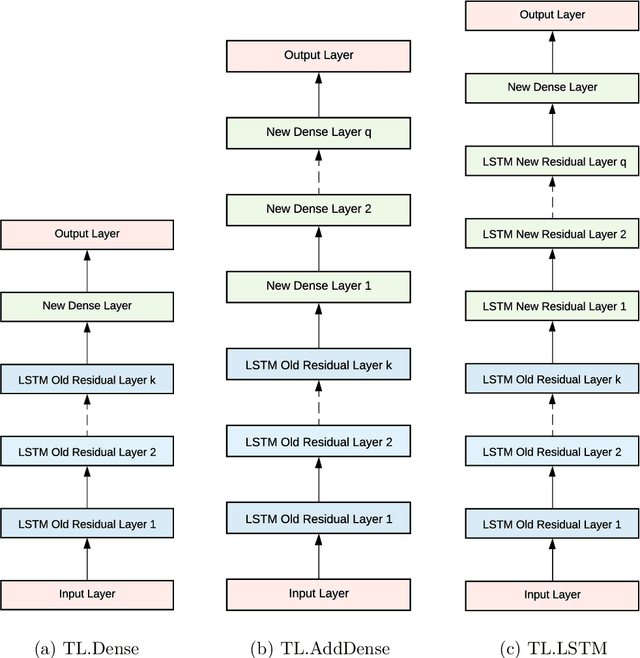
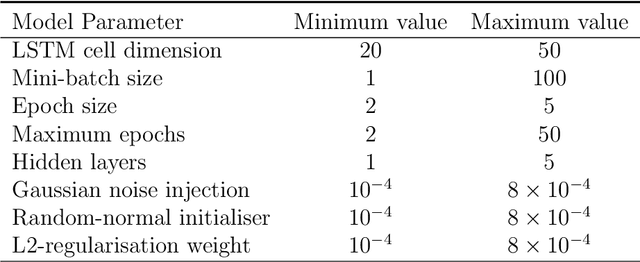
Forecasting models that are trained across sets of many time series, known as Global Forecasting Models (GFM), have shown recently promising results in forecasting competitions and real-world applications, outperforming many state-of-the-art univariate forecasting techniques. In most cases, GFMs are implemented using deep neural networks, and in particular Recurrent Neural Networks (RNN), which require a sufficient amount of time series to estimate their numerous model parameters. However, many time series databases have only a limited number of time series. In this study, we propose a novel, data augmentation based forecasting framework that is capable of improving the baseline accuracy of the GFM models in less data-abundant settings. We use three time series augmentation techniques: GRATIS, moving block bootstrap (MBB), and dynamic time warping barycentric averaging (DBA) to synthetically generate a collection of time series. The knowledge acquired from these augmented time series is then transferred to the original dataset using two different approaches: the pooled approach and the transfer learning approach. When building GFMs, in the pooled approach, we train a model on the augmented time series alongside the original time series dataset, whereas in the transfer learning approach, we adapt a pre-trained model to the new dataset. In our evaluation on competition and real-world time series datasets, our proposed variants can significantly improve the baseline accuracy of GFM models and outperform state-of-the-art univariate forecasting methods.
End-to-End Learning to Grasp from Object Point Clouds
Mar 10, 2022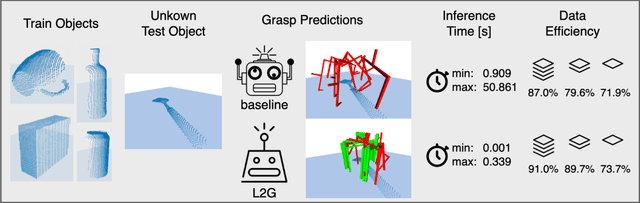
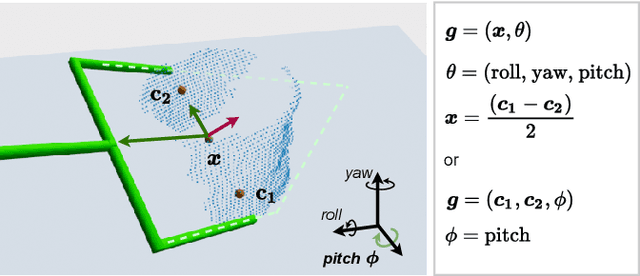
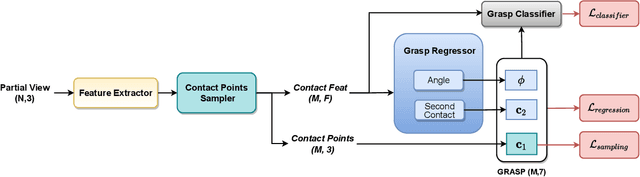
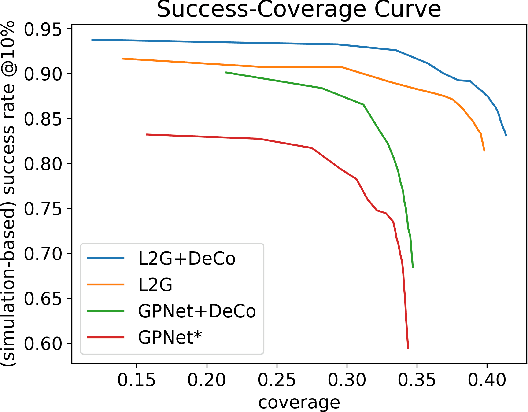
The ability to grasp objects is an essential skill that enables many robotic manipulation tasks. Recent works have studied point cloud-based methods for object grasping by starting from simulated datasets and have shown promising performance in real-world scenarios. Nevertheless, many of them still strongly rely on ad-hoc geometric heuristics to generate grasp candidates, which fail to generalize to objects with significantly different shapes with respect to those observed during training. Moreover, these methods are generally inefficient with respect to the number of training samples and the time needed during deployment. In this paper, we propose an end-to-end learning solution to generate 6-DOF parallel-jaw grasps starting from the partial view of the object. Our Learning to Grasp (L2G) method takes as input object point clouds and is guided by a principled multi-task optimization objective that generates a diverse set of grasps combining contact point sampling, grasp regression, and grasp evaluation. With a thorough experimental analysis, we show the effectiveness of the proposed method as well as its robustness and generalization abilities.
The Canonical Interval Forest (CIF) Classifier for Time Series Classification
Aug 20, 2020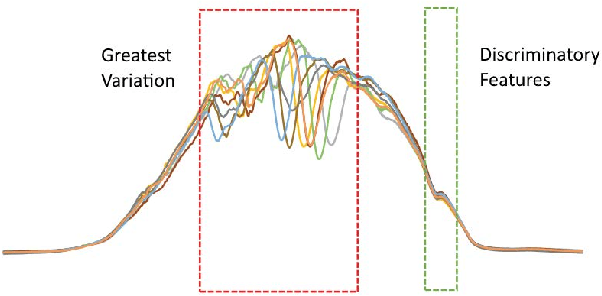

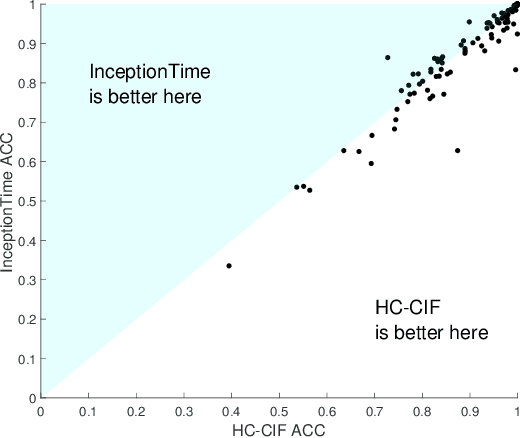
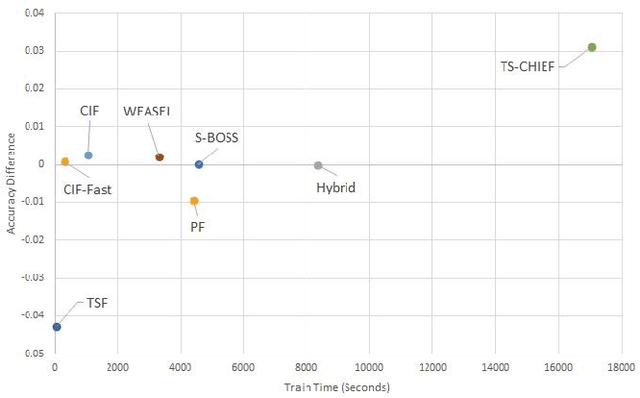
Time series classification (TSC) is home to a number of algorithm groups that utilise different kinds of discriminatory patterns. One of these groups describes classifiers that predict using phase dependant intervals. The time series forest (TSF) classifier is one of the most well known interval methods, and has demonstrated strong performance as well as relative speed in training and predictions. However, recent advances in other approaches have left TSF behind. TSF originally summarises intervals using three simple summary statistics. The `catch22' feature set of 22 time series features was recently proposed to aid time series analysis through a concise set of diverse and informative descriptive characteristics. We propose combining TSF and catch22 to form a new classifier, the Canonical Interval Forest (CIF). We outline additional enhancements to the training procedure, and extend the classifier to include multivariate classification capabilities. We demonstrate a large and significant improvement in accuracy over both TSF and catch22, and show it to be on par with top performers from other algorithmic classes. By upgrading the interval-based component from TSF to CIF, we also demonstrate a significant improvement in the hierarchical vote collective of transformation-based ensembles (HIVE-COTE) that combines different time series representations. HIVE-COTE using CIF is significantly more accurate on the UCR archive than any other classifier we are aware of and represents a new state of the art for TSC.
Meta-Forecasting by combining Global Deep Representations with Local Adaptation
Nov 12, 2021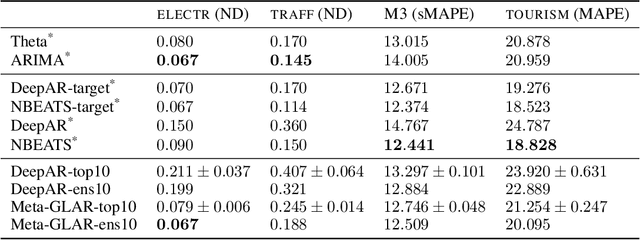
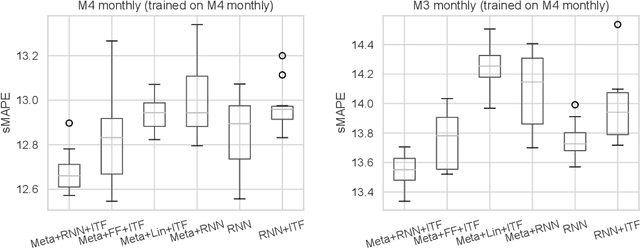
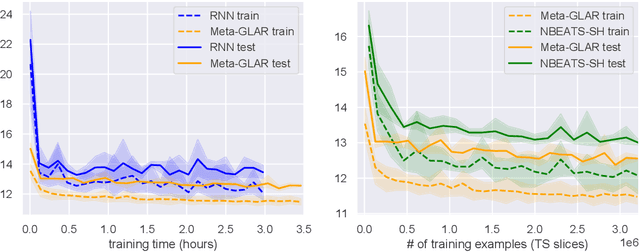

While classical time series forecasting considers individual time series in isolation, recent advances based on deep learning showed that jointly learning from a large pool of related time series can boost the forecasting accuracy. However, the accuracy of these methods suffers greatly when modeling out-of-sample time series, significantly limiting their applicability compared to classical forecasting methods. To bridge this gap, we adopt a meta-learning view of the time series forecasting problem. We introduce a novel forecasting method, called Meta Global-Local Auto-Regression (Meta-GLAR), that adapts to each time series by learning in closed-form the mapping from the representations produced by a recurrent neural network (RNN) to one-step-ahead forecasts. Crucially, the parameters ofthe RNN are learned across multiple time series by backpropagating through the closed-form adaptation mechanism. In our extensive empirical evaluation we show that our method is competitive with the state-of-the-art in out-of-sample forecasting accuracy reported in earlier work.
Gym-$μ$RTS: Toward Affordable Full Game Real-time Strategy Games Research with Deep Reinforcement Learning
May 21, 2021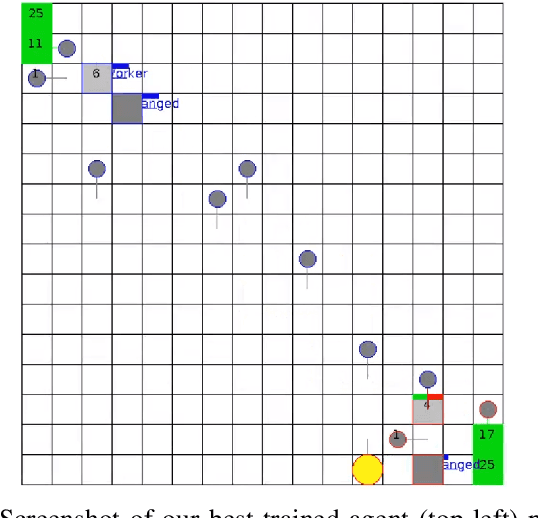
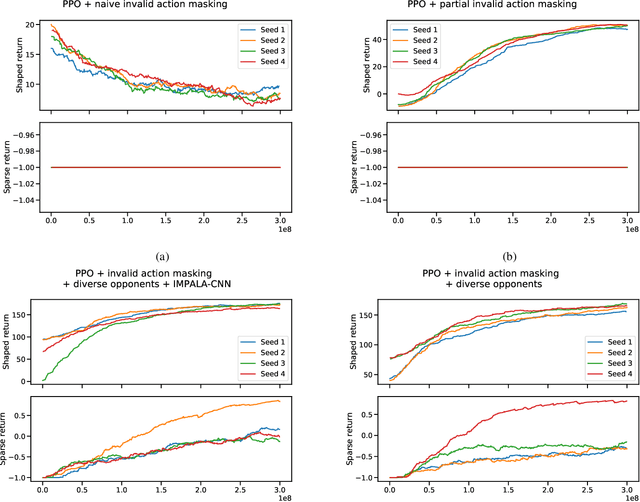
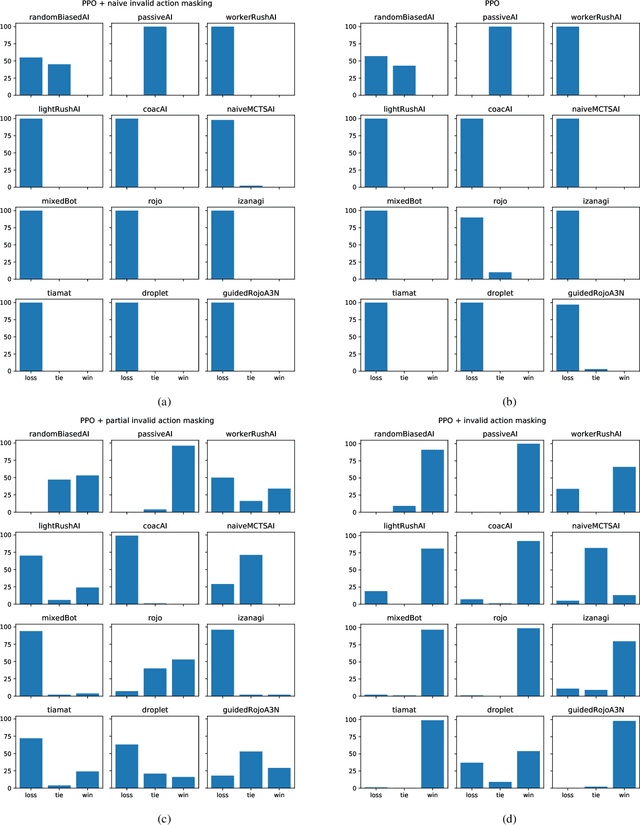
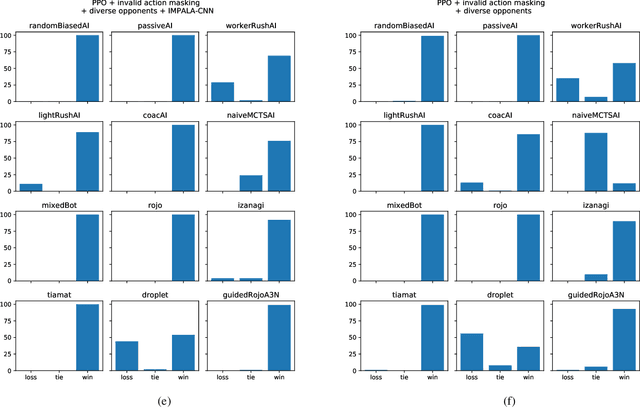
In recent years, researchers have achieved great success in applying Deep Reinforcement Learning (DRL) algorithms to Real-time Strategy (RTS) games, creating strong autonomous agents that could defeat professional players in StarCraft~II. However, existing approaches to tackle full games have high computational costs, usually requiring the use of thousands of GPUs and CPUs for weeks. This paper has two main contributions to address this issue: 1) We introduce Gym-$\mu$RTS (pronounced "gym-micro-RTS") as a fast-to-run RL environment for full-game RTS research and 2) we present a collection of techniques to scale DRL to play full-game $\mu$RTS as well as ablation studies to demonstrate their empirical importance. Our best-trained bot can defeat every $\mu$RTS bot we tested from the past $\mu$RTS competitions when working in a single-map setting, resulting in a state-of-the-art DRL agent while only taking about 60 hours of training using a single machine (one GPU, three vCPU, 16GB RAM).
"If you could see me through my eyes": Predicting Pedestrian Perception
Feb 28, 2022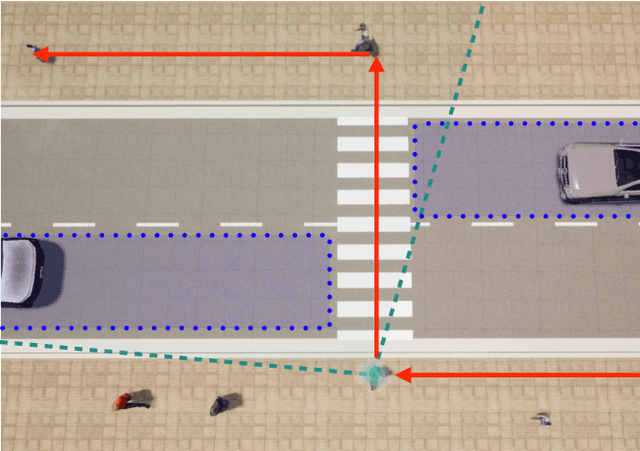
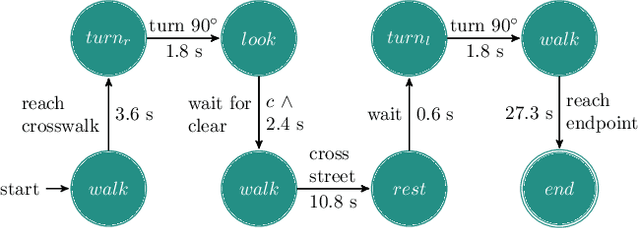
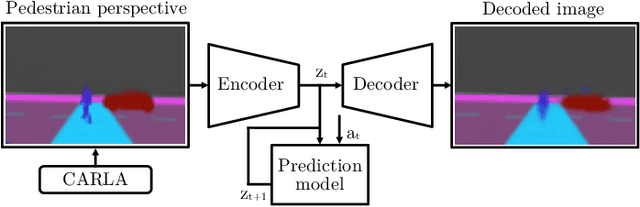

Pedestrians are particularly vulnerable road users in urban traffic. With the arrival of autonomous driving, novel technologies can be developed specifically to protect pedestrians. We propose a~machine learning toolchain to train artificial neural networks as models of pedestrian behavior. In a~preliminary study, we use synthetic data from simulations of a~specific pedestrian crossing scenario to train a~variational autoencoder and a~long short-term memory network to predict a~pedestrian's future visual perception. We can accurately predict a~pedestrian's future perceptions within relevant time horizons. By iteratively feeding these predicted frames into these networks, they can be used as simulations of pedestrians as indicated by our results. Such trained networks can later be used to predict pedestrian behaviors even from the perspective of the autonomous car. Another future extension will be to re-train these networks with real-world video data.
Weisfeiler-Lehman meets Gromov-Wasserstein
Feb 05, 2022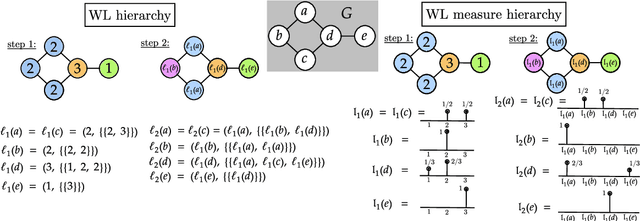


The Weisfeiler-Lehman (WL) test is a classical procedure for graph isomorphism testing. The WL test has also been widely used both for designing graph kernels and for analyzing graph neural networks. In this paper, we propose the Weisfeiler-Lehman (WL) distance, a notion of distance between labeled measure Markov chains (LMMCs), of which labeled graphs are special cases. The WL distance is polynomial time computable and is also compatible with the WL test in the sense that the former is positive if and only if the WL test can distinguish the two involved graphs. The WL distance captures and compares subtle structures of the underlying LMMCs and, as a consequence of this, it is more discriminating than the distance between graphs used for defining the state-of-the-art Wasserstein Weisfeiler-Lehman graph kernel. Inspired by the structure of the WL distance we identify a neural network architecture on LMMCs which turns out to be universal w.r.t. continuous functions defined on the space of all LMMCs (which includes all graphs) endowed with the WL distance. Finally, the WL distance turns out to be stable w.r.t. a natural variant of the Gromov-Wasserstein (GW) distance for comparing metric Markov chains that we identify. Hence, the WL distance can also be construed as a polynomial time lower bound for the GW distance which is in general NP-hard to compute.
Convergence of a robust deep FBSDE method for stochastic control
Jan 18, 2022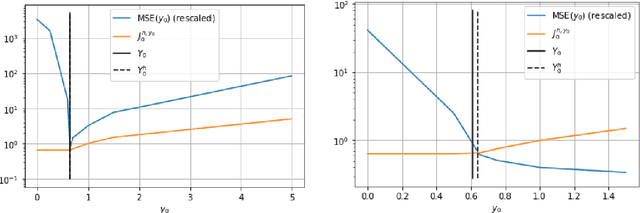
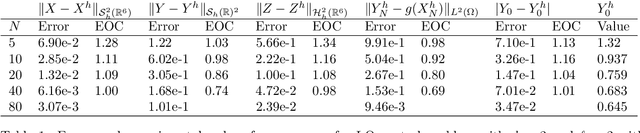
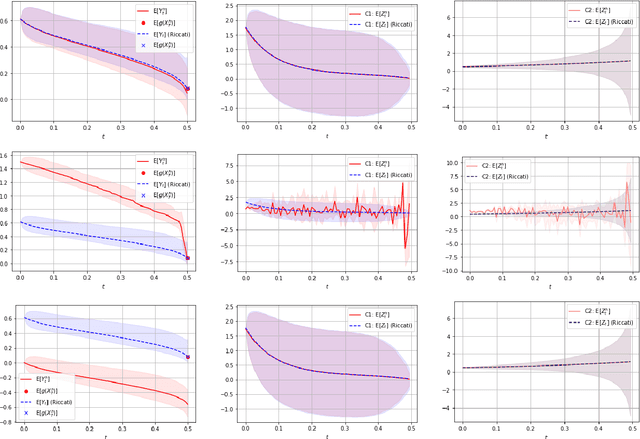

In this paper we propose a deep learning based numerical scheme for strongly coupled FBSDE, stemming from stochastic control. It is a modification of the deep BSDE method in which the initial value to the backward equation is not a free parameter, and with a new loss function being the weighted sum of the cost of the control problem, and a variance term which coincides with the means square error in the terminal condition. We show by a numerical example that a direct extension of the classical deep BSDE method to FBSDE, fails for a simple linear-quadratic control problem, and motivate why the new method works. Under regularity and boundedness assumptions on the exact controls of time continuous and time discrete control problems we provide an error analysis for our method. We show empirically that the method converges for three different problems, one being the one that failed for a direct extension of the deep BSDE method.
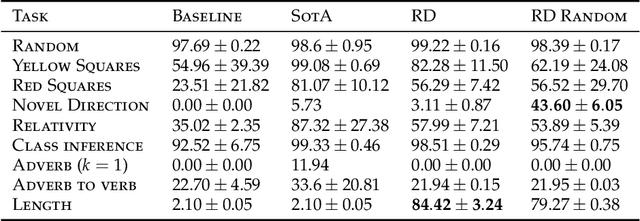
Recursive Decoding: A Situated Cognition Approach to Compositional Generation in Grounded Language Understanding
Jan 27, 2022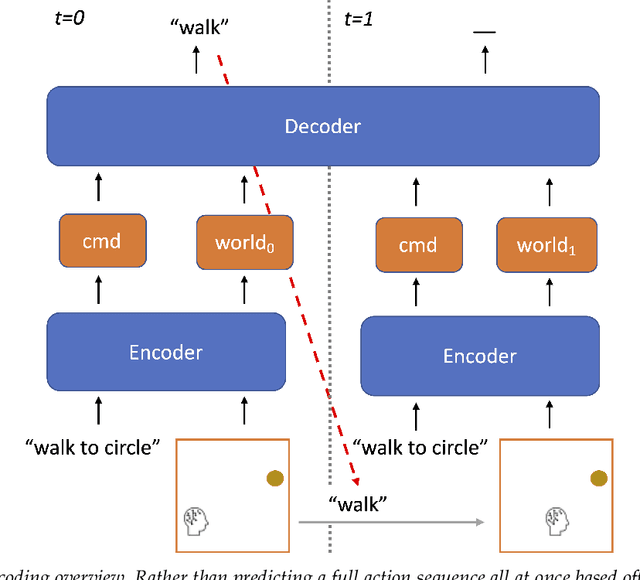
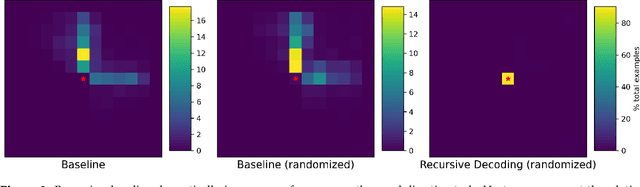
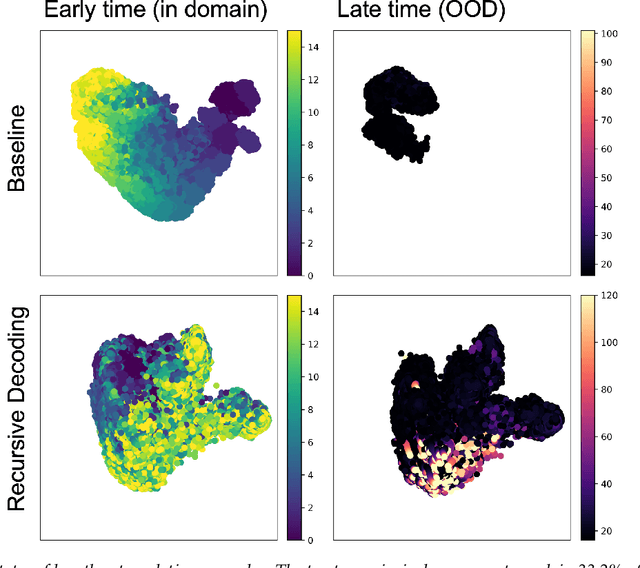
Compositional generalization is a troubling blind spot for neural language models. Recent efforts have presented techniques for improving a model's ability to encode novel combinations of known inputs, but less work has focused on generating novel combinations of known outputs. Here we focus on this latter "decode-side" form of generalization in the context of gSCAN, a synthetic benchmark for compositional generalization in grounded language understanding. We present Recursive Decoding (RD), a novel procedure for training and using seq2seq models, targeted towards decode-side generalization. Rather than generating an entire output sequence in one pass, models are trained to predict one token at a time. Inputs (i.e., the external gSCAN environment) are then incrementally updated based on predicted tokens, and re-encoded for the next decoder time step. RD thus decomposes a complex, out-of-distribution sequence generation task into a series of incremental predictions that each resemble what the model has already seen during training. RD yields dramatic improvement on two previously neglected generalization tasks in gSCAN. We provide analyses to elucidate these gains over failure of a baseline, and then discuss implications for generalization in naturalistic grounded language understanding, and seq2seq more generally.