 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Improving the Accuracy of Global Forecasting Models using Time Series Data Augmentation
Aug 06, 2020
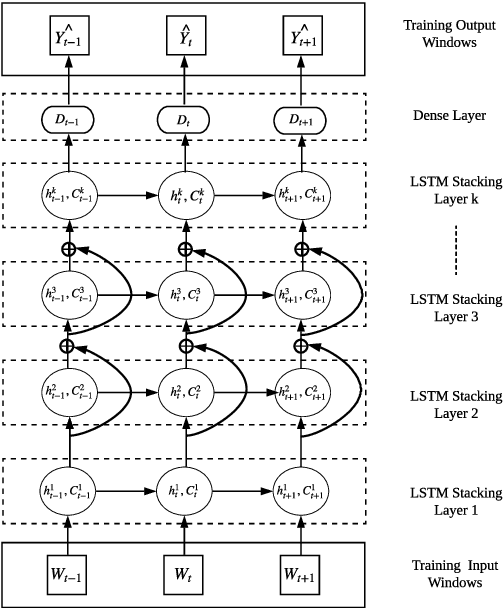
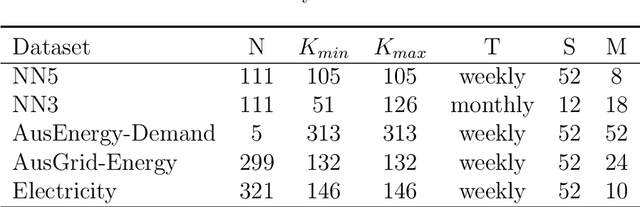
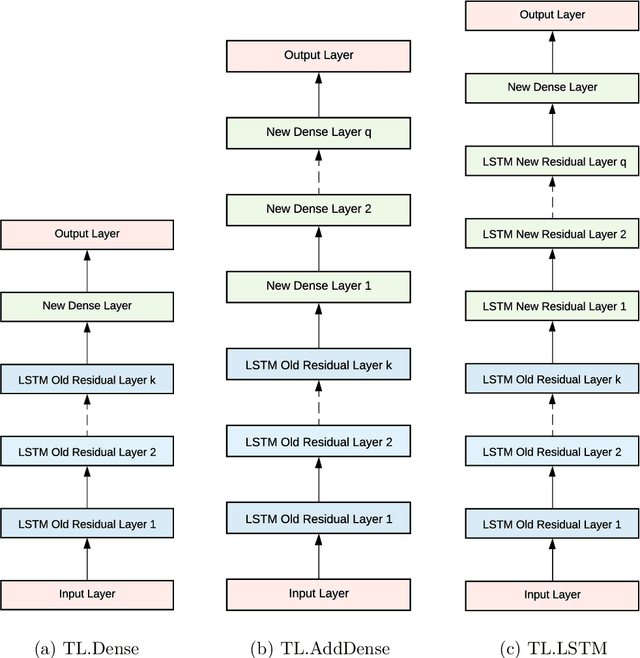
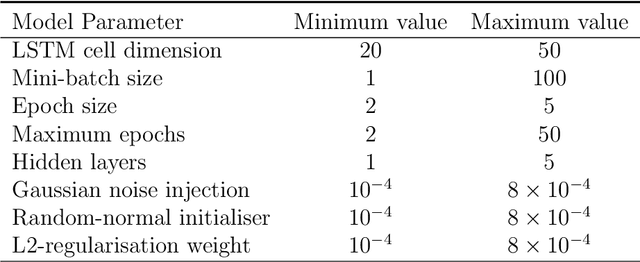
Forecasting models that are trained across sets of many time series, known as Global Forecasting Models (GFM), have shown recently promising results in forecasting competitions and real-world applications, outperforming many state-of-the-art univariate forecasting techniques. In most cases, GFMs are implemented using deep neural networks, and in particular Recurrent Neural Networks (RNN), which require a sufficient amount of time series to estimate their numerous model parameters. However, many time series databases have only a limited number of time series. In this study, we propose a novel, data augmentation based forecasting framework that is capable of improving the baseline accuracy of the GFM models in less data-abundant settings. We use three time series augmentation techniques: GRATIS, moving block bootstrap (MBB), and dynamic time warping barycentric averaging (DBA) to synthetically generate a collection of time series. The knowledge acquired from these augmented time series is then transferred to the original dataset using two different approaches: the pooled approach and the transfer learning approach. When building GFMs, in the pooled approach, we train a model on the augmented time series alongside the original time series dataset, whereas in the transfer learning approach, we adapt a pre-trained model to the new dataset. In our evaluation on competition and real-world time series datasets, our proposed variants can significantly improve the baseline accuracy of GFM models and outperform state-of-the-art univariate forecasting methods.
A Gradient Estimator for Time-Varying Electrical Networks with Non-Linear Dissipation
Mar 09, 2021We propose a method for extending the technique of equilibrium propagation for estimating gradients in fixed-point neural networks to the more general setting of directed, time-varying neural networks by modeling them as electrical circuits. We use electrical circuit theory to construct a Lagrangian capable of describing deep, directed neural networks modeled using nonlinear capacitors and inductors, linear resistors and sources, and a special class of nonlinear dissipative elements called fractional memristors. We then derive an estimator for the gradient of the physical parameters of the network, such as synapse conductances, with respect to an arbitrary loss function. This estimator is entirely local, in that it only depends on information locally available to each synapse. We conclude by suggesting methods for extending these results to networks of biologically plausible neurons, e.g. Hodgkin-Huxley neurons.
Real-Time Video Super-Resolution on Smartphones with Deep Learning, Mobile AI 2021 Challenge: Report
May 17, 2021

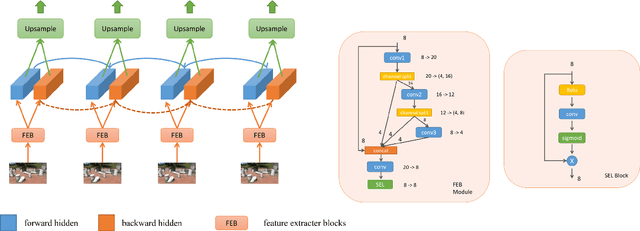
Video super-resolution has recently become one of the most important mobile-related problems due to the rise of video communication and streaming services. While many solutions have been proposed for this task, the majority of them are too computationally expensive to run on portable devices with limited hardware resources. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop an end-to-end deep learning-based video super-resolution solutions that can achieve a real-time performance on mobile GPUs. The participants were provided with the REDS dataset and trained their models to do an efficient 4X video upscaling. The runtime of all models was evaluated on the OPPO Find X2 smartphone with the Snapdragon 865 SoC capable of accelerating floating-point networks on its Adreno GPU. The proposed solutions are fully compatible with any mobile GPU and can upscale videos to HD resolution at up to 80 FPS while demonstrating high fidelity results. A detailed description of all models developed in the challenge is provided in this paper.
Interspace Pruning: Using Adaptive Filter Representations to Improve Training of Sparse CNNs
Mar 15, 2022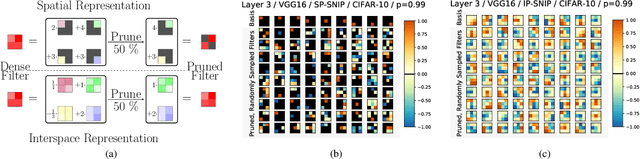

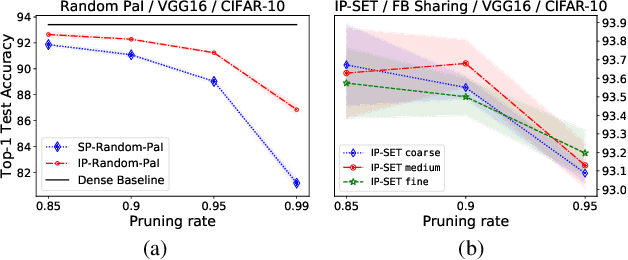
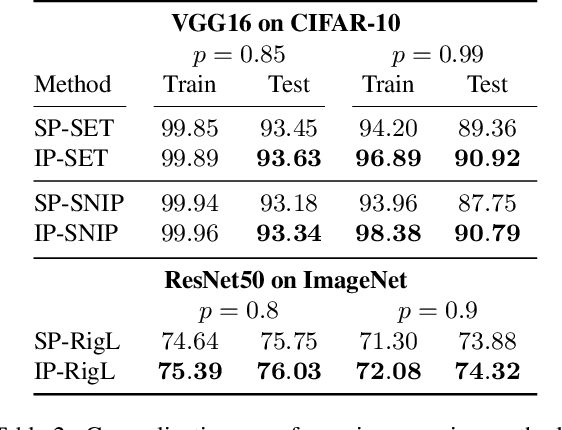
Unstructured pruning is well suited to reduce the memory footprint of convolutional neural networks (CNNs), both at training and inference time. CNNs contain parameters arranged in $K \times K$ filters. Standard unstructured pruning (SP) reduces the memory footprint of CNNs by setting filter elements to zero, thereby specifying a fixed subspace that constrains the filter. Especially if pruning is applied before or during training, this induces a strong bias. To overcome this, we introduce interspace pruning (IP), a general tool to improve existing pruning methods. It uses filters represented in a dynamic interspace by linear combinations of an underlying adaptive filter basis (FB). For IP, FB coefficients are set to zero while un-pruned coefficients and FBs are trained jointly. In this work, we provide mathematical evidence for IP's superior performance and demonstrate that IP outperforms SP on all tested state-of-the-art unstructured pruning methods. Especially in challenging situations, like pruning for ImageNet or pruning to high sparsity, IP greatly exceeds SP with equal runtime and parameter costs. Finally, we show that advances of IP are due to improved trainability and superior generalization ability.
The Canonical Interval Forest (CIF) Classifier for Time Series Classification
Aug 20, 2020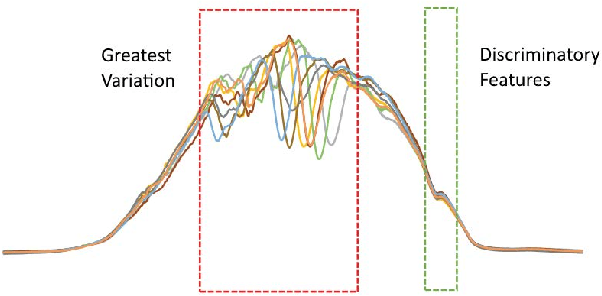

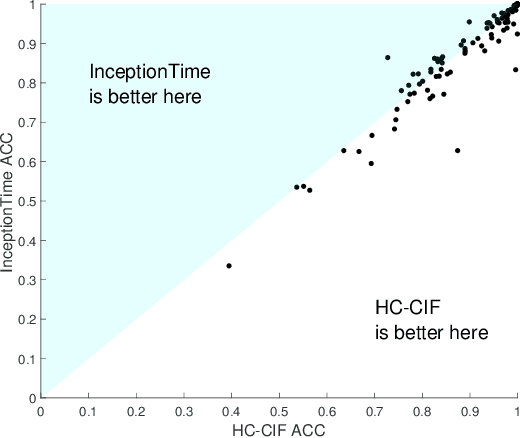
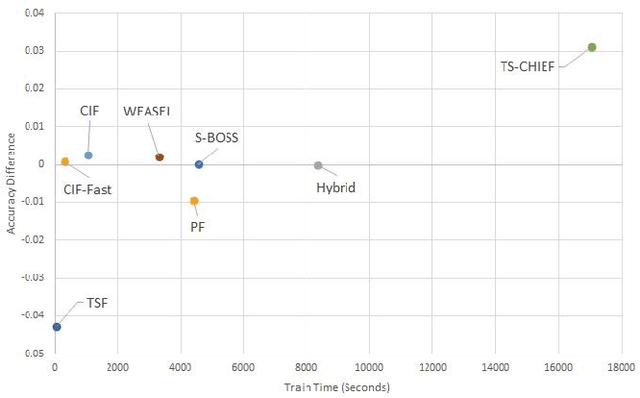
Time series classification (TSC) is home to a number of algorithm groups that utilise different kinds of discriminatory patterns. One of these groups describes classifiers that predict using phase dependant intervals. The time series forest (TSF) classifier is one of the most well known interval methods, and has demonstrated strong performance as well as relative speed in training and predictions. However, recent advances in other approaches have left TSF behind. TSF originally summarises intervals using three simple summary statistics. The `catch22' feature set of 22 time series features was recently proposed to aid time series analysis through a concise set of diverse and informative descriptive characteristics. We propose combining TSF and catch22 to form a new classifier, the Canonical Interval Forest (CIF). We outline additional enhancements to the training procedure, and extend the classifier to include multivariate classification capabilities. We demonstrate a large and significant improvement in accuracy over both TSF and catch22, and show it to be on par with top performers from other algorithmic classes. By upgrading the interval-based component from TSF to CIF, we also demonstrate a significant improvement in the hierarchical vote collective of transformation-based ensembles (HIVE-COTE) that combines different time series representations. HIVE-COTE using CIF is significantly more accurate on the UCR archive than any other classifier we are aware of and represents a new state of the art for TSC.
Reverse Back Propagation to Make Full Use of Derivative
Feb 13, 2022The development of the back-propagation algorithm represents a landmark in neural networks. We provide an approach that conducts the back-propagation again to reverse the traditional back-propagation process to optimize the input loss at the input end of a neural network for better effects without extra costs during the inference time. Then we further analyzed its principles and advantages and disadvantages, reformulated the weight initialization strategy for our method. And experiments on MNIST, CIFAR10, and CIFAR100 convinced our approaches could adapt to a larger range of learning rate and learn better than vanilla back-propagation.
A Survey for Deep RGBT Tracking
Jan 23, 2022
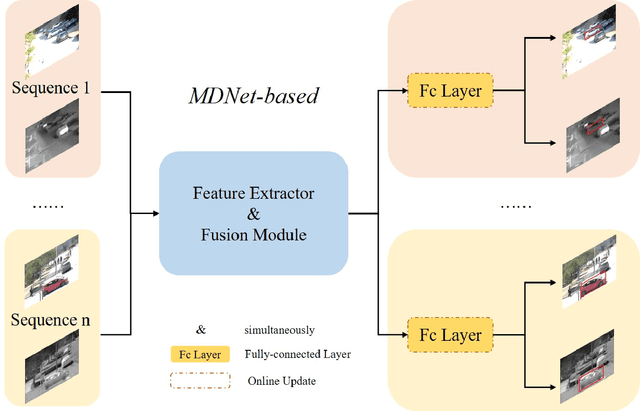
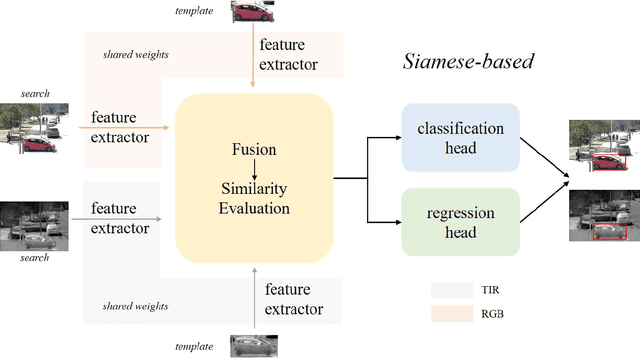
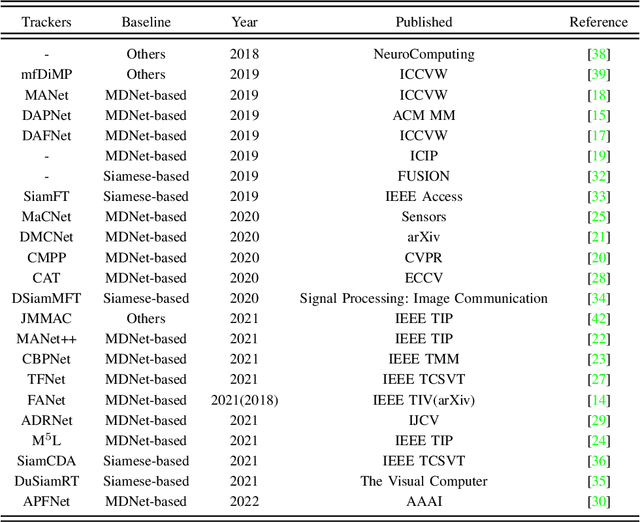
Visual object tracking with the visible (RGB) and thermal infrared (TIR) electromagnetic waves, shorted in RGBT tracking, recently draws increasing attention in the tracking community. Considering the rapid development of deep learning, a survey for the recent deep neural network based RGBT trackers is presented in this paper. Firstly, we give brief introduction for the RGBT trackers concluded into this category. Then, a comparison among the existing RGBT trackers on several challenging benchmarks is given statistically. Specifically, MDNet and Siamese architectures are the two mainstream frameworks in the RGBT community, especially the former. Trackers based on MDNet achieve higher performance while Siamese-based trackers satisfy the real-time requirement. In summary, since the large-scale dataset LasHeR is published, the integration of end-to-end framework, e.g., Siamese and Transformer, should be further considered to fulfil the real-time as well as more robust performance. Furthermore, the mathematical meaning should be more considered during designing the network. This survey can be treated as a look-up-table for researchers who are concerned about RGBT tracking.
Temporal Knowledge Graph Completion: A Survey
Jan 16, 2022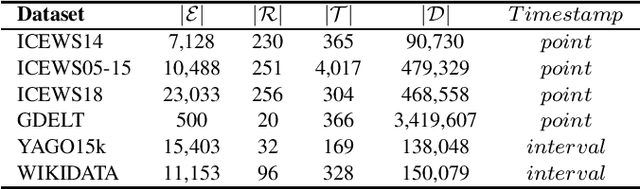
Knowledge graph completion (KGC) can predict missing links and is crucial for real-world knowledge graphs, which widely suffer from incompleteness. KGC methods assume a knowledge graph is static, but that may lead to inaccurate prediction results because many facts in the knowledge graphs change over time. Recently, emerging methods have shown improved predictive results by further incorporating the timestamps of facts; namely, temporal knowledge graph completion (TKGC). With this temporal information, TKGC methods can learn the dynamic evolution of the knowledge graph that KGC methods fail to capture. In this paper, for the first time, we summarize the recent advances in TKGC research. First, we detail the background of TKGC, including the problem definition, benchmark datasets, and evaluation metrics. Then, we summarize existing TKGC methods based on how timestamps of facts are used to capture the temporal dynamics. Finally, we conclude the paper and present future research directions of TKGC.
Echofilter: A Deep Learning Segmentation Model Improves the Automation, Standardization, and Timeliness for Post-Processing Echosounder Data in Tidal Energy Streams
Feb 19, 2022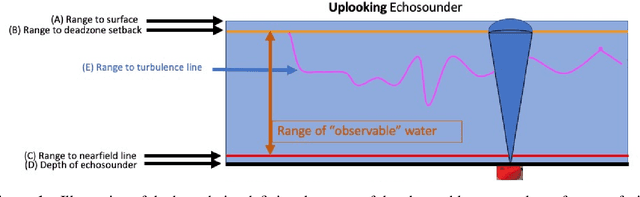


Understanding the abundance and distribution of fish in tidal energy streams is important for assessing the risk presented by the introduction of tidal energy devices into the habitat. However, the impressive tidal currents that make sites favorable for tidal energy development are often highly turbulent and entrain air into the water, complicating the interpretation of echosounder data. The portion of the water column contaminated by returns from entrained air must be excluded from data used for biological analyses. Application of a single algorithm to identify the depth-of-penetration of entrained-air is insufficient for a boundary that is discontinuous, depth-dynamic, porous, and widely variable across the tidal flow speeds which can range from 0 to 5m/s. Using a case study at a tidal energy demonstration site in the Bay of Fundy, we describe the development and application of deep learning models that produce a pronounced, consistent, substantial, and measurable improvement of the automated detection of the extent to which entrained-air has penetrated the water column. Our model, Echofilter, was highly responsive to the dynamic range of turbulence conditions and sensitive to the fine-scale nuances in the boundary position, producing an entrained-air boundary line with an average error of 0.32m on mobile downfacing and 0.5-1.0m on stationary upfacing data. The model's annotations had a high level of agreement with the human segmentation (mobile downfacing Jaccard index: 98.8%; stationary upfacing: 93-95%). This resulted in a 50% reduction in the time required for manual edits compared to the time required to manually edit the line placed by currently available algorithms. Because of the improved initial automated placement, the implementation of the models generated a marked increase in the standardization and repeatability of line placement.
Gym-$μ$RTS: Toward Affordable Full Game Real-time Strategy Games Research with Deep Reinforcement Learning
May 21, 2021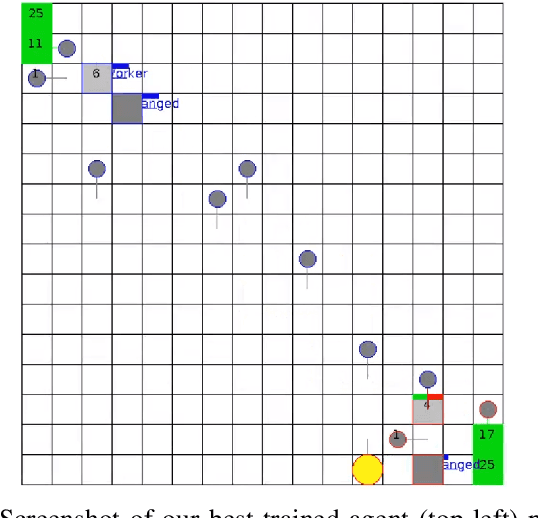
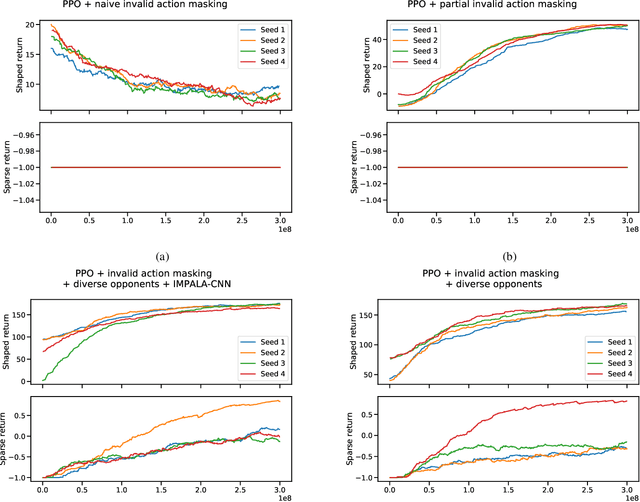
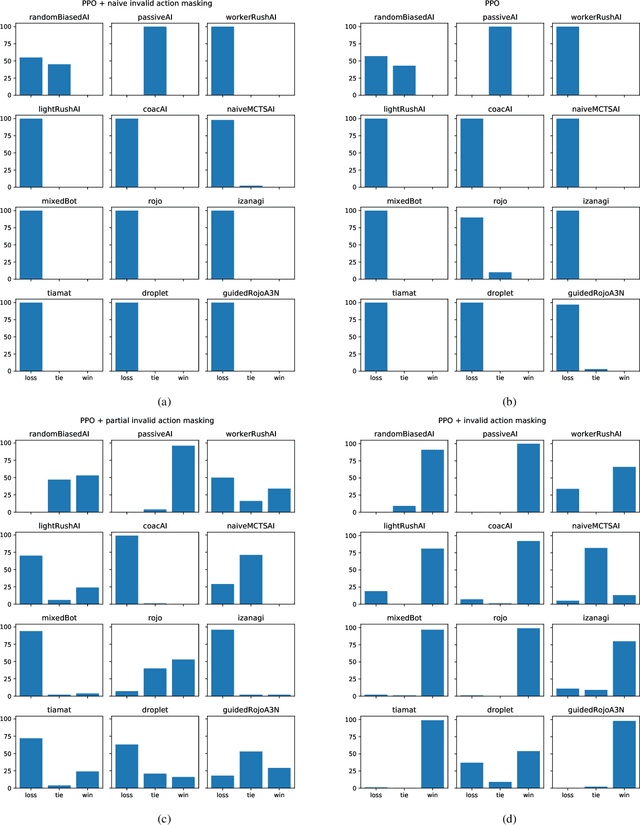
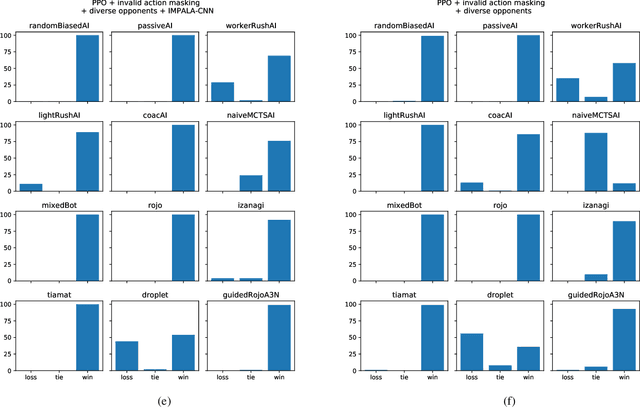
In recent years, researchers have achieved great success in applying Deep Reinforcement Learning (DRL) algorithms to Real-time Strategy (RTS) games, creating strong autonomous agents that could defeat professional players in StarCraft~II. However, existing approaches to tackle full games have high computational costs, usually requiring the use of thousands of GPUs and CPUs for weeks. This paper has two main contributions to address this issue: 1) We introduce Gym-$\mu$RTS (pronounced "gym-micro-RTS") as a fast-to-run RL environment for full-game RTS research and 2) we present a collection of techniques to scale DRL to play full-game $\mu$RTS as well as ablation studies to demonstrate their empirical importance. Our best-trained bot can defeat every $\mu$RTS bot we tested from the past $\mu$RTS competitions when working in a single-map setting, resulting in a state-of-the-art DRL agent while only taking about 60 hours of training using a single machine (one GPU, three vCPU, 16GB RAM).