 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Learning-Based Joint Control of Acoustic Echo Cancellation, Beamforming and Postfiltering
Mar 03, 2022
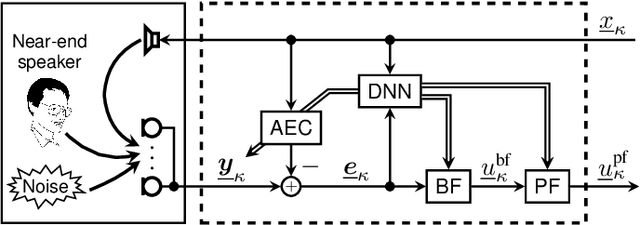
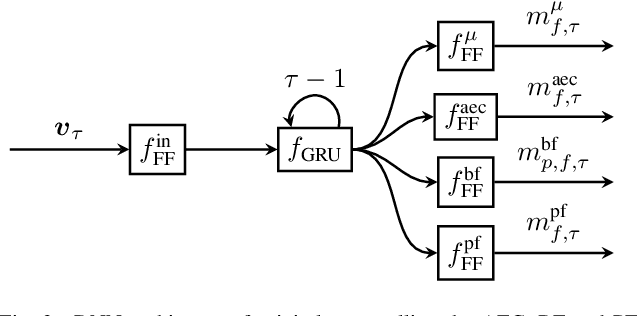
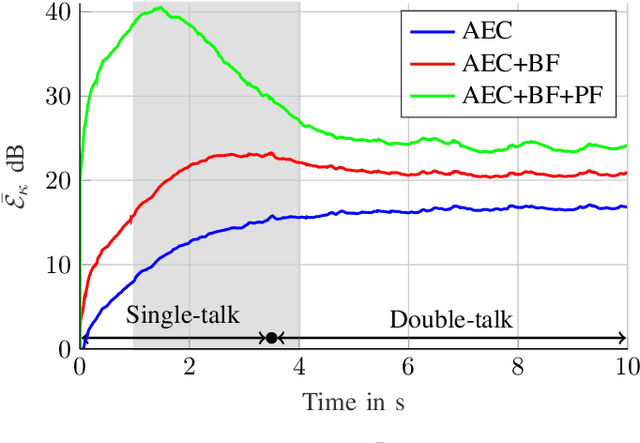
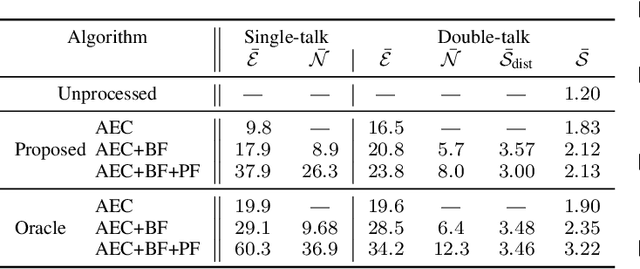
We introduce a novel method for controlling the functionality of a hands-free speech communication device which comprises a model-based acoustic echo canceller (AEC), minimum variance distortionless response (MVDR) beamformer (BF) and spectral postfilter (PF). While the AEC removes the early echo component, the MVDR BF and PF suppress the residual echo and background noise. As key innovation, we suggest to use a single deep neural network (DNN) to jointly control the adaptation of the various algorithmic components. This allows for rapid convergence and high steady-state performance in the presence of high-level interfering double-talk. End-to-end training of the DNN using a time-domain speech extraction loss function avoids the design of individual control strategies.
Enabling Deep Learning on Edge Devices through Filter Pruning and Knowledge Transfer
Jan 22, 2022Deep learning models have introduced various intelligent applications to edge devices, such as image classification, speech recognition, and augmented reality. There is an increasing need of training such models on the devices in order to deliver personalized, responsive, and private learning. To address this need, this paper presents a new solution for deploying and training state-of-the-art models on the resource-constrained devices. First, the paper proposes a novel filter-pruning-based model compression method to create lightweight trainable models from large models trained in the cloud, without much loss of accuracy. Second, it proposes a novel knowledge transfer method to enable the on-device model to update incrementally in real time or near real time using incremental learning on new data and enable the on-device model to learn the unseen categories with the help of the in-cloud model in an unsupervised fashion. The results show that 1) our model compression method can remove up to 99.36% parameters of WRN-28-10, while preserving a Top-1 accuracy of over 90% on CIFAR-10; 2) our knowledge transfer method enables the compressed models to achieve more than 90% accuracy on CIFAR-10 and retain good accuracy on old categories; 3) it allows the compressed models to converge within real time (three to six minutes) on the edge for incremental learning tasks; 4) it enables the model to classify unseen categories of data (78.92% Top-1 accuracy) that it is never trained with.
Reachability analysis in stochastic directed graphs by reinforcement learning
Feb 25, 2022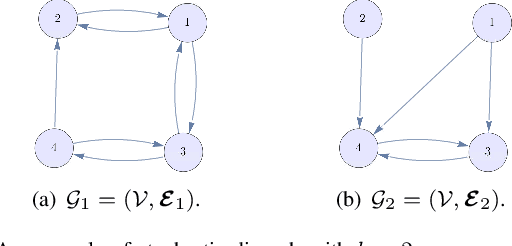
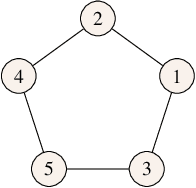
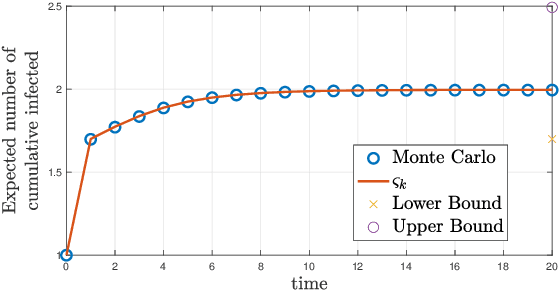
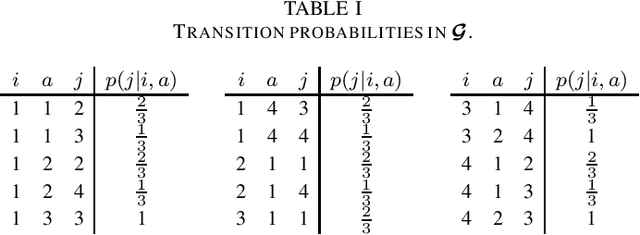
We characterize the reachability probabilities in stochastic directed graphs by means of reinforcement learning methods. In particular, we show that the dynamics of the transition probabilities in a stochastic digraph can be modeled via a difference inclusion, which, in turn, can be interpreted as a Markov decision process. Using the latter framework, we offer a methodology to design reward functions to provide upper and lower bounds on the reachability probabilities of a set of nodes for stochastic digraphs. The effectiveness of the proposed technique is demonstrated by application to the diffusion of epidemic diseases over time-varying contact networks generated by the proximity patterns of mobile agents.
On the Post-hoc Explainability of Deep Echo State Networks for Time Series Forecasting, Image and Video Classification
Feb 17, 2021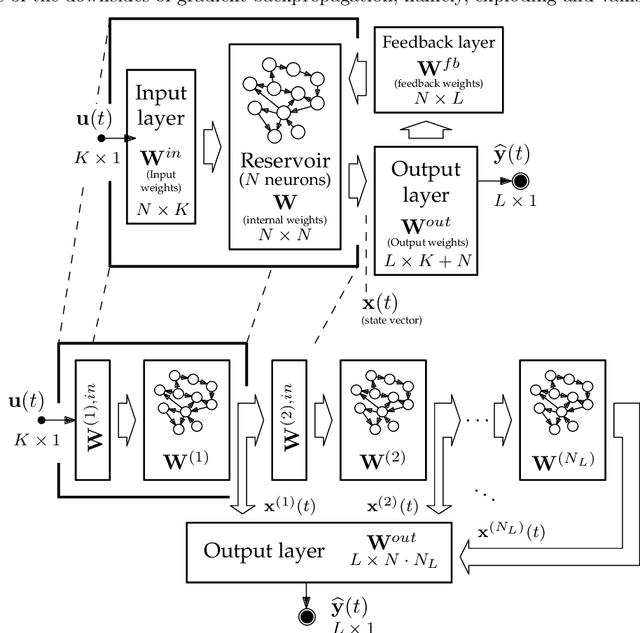
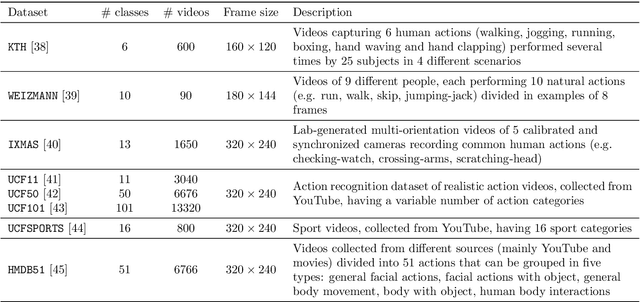
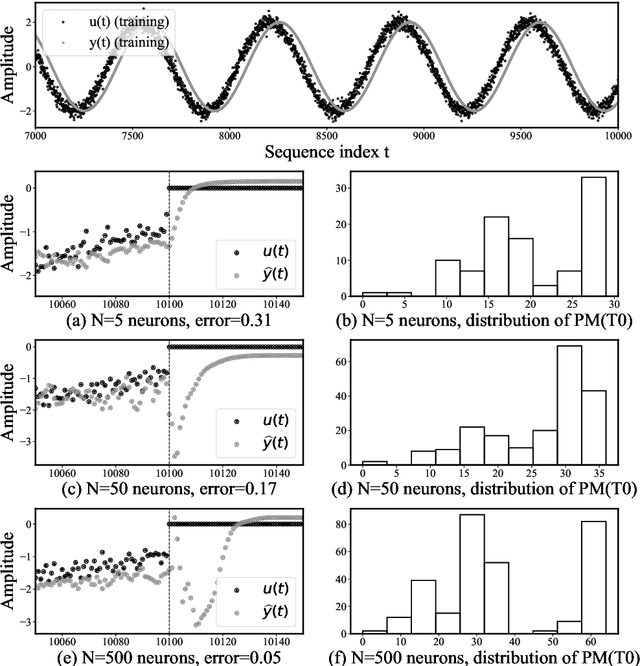
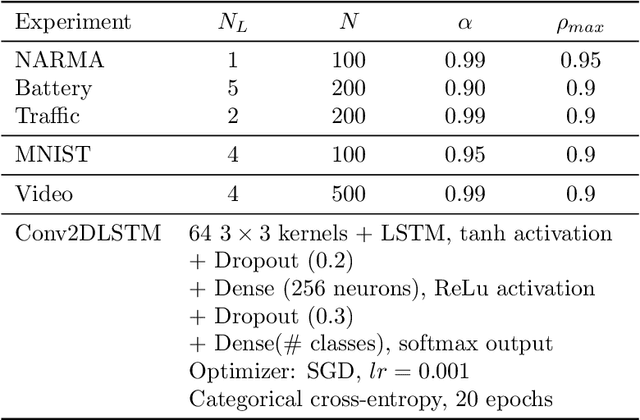
Since their inception, learning techniques under the Reservoir Computing paradigm have shown a great modeling capability for recurrent systems without the computing overheads required for other approaches. Among them, different flavors of echo state networks have attracted many stares through time, mainly due to the simplicity and computational efficiency of their learning algorithm. However, these advantages do not compensate for the fact that echo state networks remain as black-box models whose decisions cannot be easily explained to the general audience. This work addresses this issue by conducting an explainability study of Echo State Networks when applied to learning tasks with time series, image and video data. Specifically, the study proposes three different techniques capable of eliciting understandable information about the knowledge grasped by these recurrent models, namely, potential memory, temporal patterns and pixel absence effect. Potential memory addresses questions related to the effect of the reservoir size in the capability of the model to store temporal information, whereas temporal patterns unveils the recurrent relationships captured by the model over time. Finally, pixel absence effect attempts at evaluating the effect of the absence of a given pixel when the echo state network model is used for image and video classification. We showcase the benefits of our proposed suite of techniques over three different domains of applicability: time series modeling, image and, for the first time in the related literature, video classification. Our results reveal that the proposed techniques not only allow for a informed understanding of the way these models work, but also serve as diagnostic tools capable of detecting issues inherited from data (e.g. presence of hidden bias).
Semantic Sensor Network Ontology based Decision Support System for Forest Fire Management
Apr 03, 2022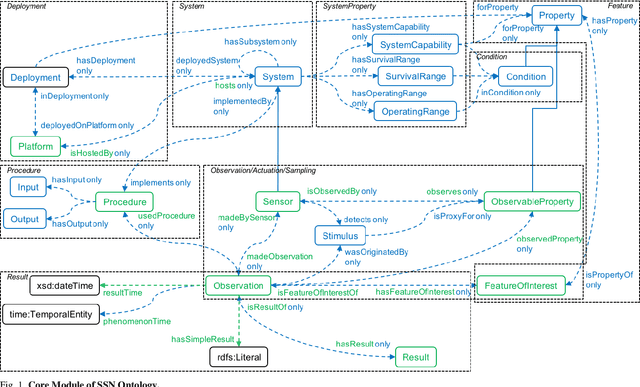



The forests are significant assets for every country. When it gets destroyed, it may negatively impact the environment, and forest fire is one of the primary causes. Fire weather indices are widely used to measure fire danger and are used to issue bushfire warnings. It can also be used to predict the demand for emergency management resources. Sensor networks have grown in popularity in data collection and processing capabilities for a variety of applications in industries such as medical, environmental monitoring, home automation etc. Semantic sensor networks can collect various climatic circumstances like wind speed, temperature, and relative humidity. However, estimating fire weather indices is challenging due to the various issues involved in processing the data streams generated by the sensors. Hence, the importance of forest fire detection has increased day by day. The underlying Semantic Sensor Network (SSN) ontologies are built to allow developers to create rules for calculating fire weather indices and also the convert dataset into Resource Description Framework (RDF). This research describes the various steps involved in developing rules for calculating fire weather indices. Besides, this work presents a Web-based mapping interface to help users visualize the changes in fire weather indices over time. With the help of the inference rule, it designed a decision support system using the SSN ontology and query on it through SPARQL. The proposed fire management system acts according to the situation, supports reasoning and the general semantics of the open-world followed by all the ontologies
Extracting associations and meanings of objects depicted in artworks through bi-modal deep networks
Mar 14, 2022
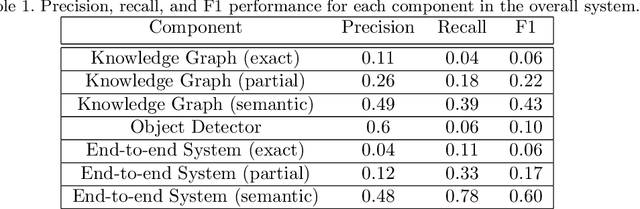


We present a novel bi-modal system based on deep networks to address the problem of learning associations and simple meanings of objects depicted in "authored" images, such as fine art paintings and drawings. Our overall system processes both the images and associated texts in order to learn associations between images of individual objects, their identities and the abstract meanings they signify. Unlike past deep net that describe depicted objects and infer predicates, our system identifies meaning-bearing objects ("signifiers") and their associations ("signifieds") as well as basic overall meanings for target artworks. Our system had precision of 48% and recall of 78% with an F1 metric of 0.6 on a curated set of Dutch vanitas paintings, a genre celebrated for its concentration on conveying a meaning of great import at the time of their execution. We developed and tested our system on fine art paintings but our general methods can be applied to other authored images.
VIS-iTrack: Visual Intention through Gaze Tracking using Low-Cost Webcam
Feb 05, 2022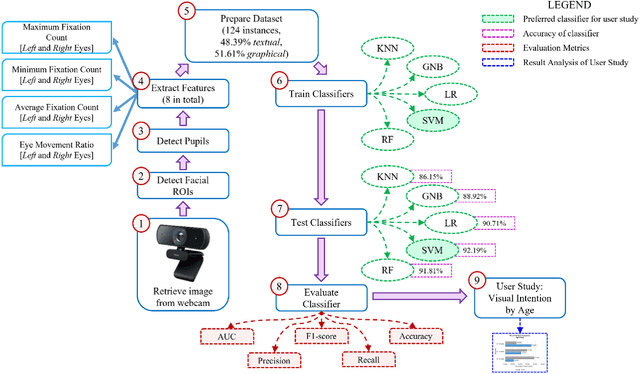
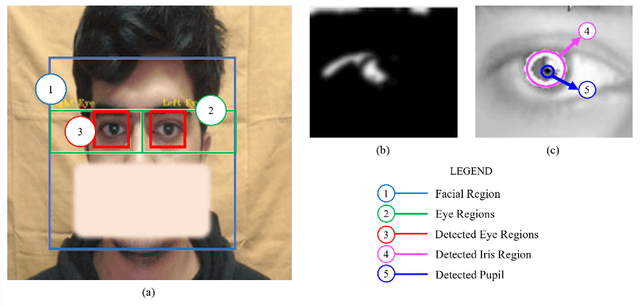
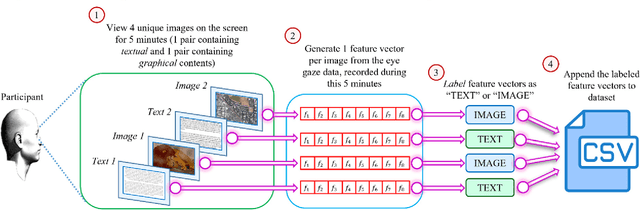
Human intention is an internal, mental characterization for acquiring desired information. From interactive interfaces containing either textual or graphical information, intention to perceive desired information is subjective and strongly connected with eye gaze. In this work, we determine such intention by analyzing real-time eye gaze data with a low-cost regular webcam. We extracted unique features (e.g., Fixation Count, Eye Movement Ratio) from the eye gaze data of 31 participants to generate a dataset containing 124 samples of visual intention for perceiving textual or graphical information, labeled as either TEXT or IMAGE, having 48.39% and 51.61% distribution, respectively. Using this dataset, we analyzed 5 classifiers, including Support Vector Machine (SVM) (Accuracy: 92.19%). Using the trained SVM, we investigated the variation of visual intention among 30 participants, distributed in 3 age groups, and found out that young users were more leaned towards graphical contents whereas older adults felt more interested in textual ones. This finding suggests that real-time eye gaze data can be a potential source of identifying visual intention, analyzing which intention aware interactive interfaces can be designed and developed to facilitate human cognition.
Point Scene Understanding via Disentangled Instance Mesh Reconstruction
Mar 31, 2022

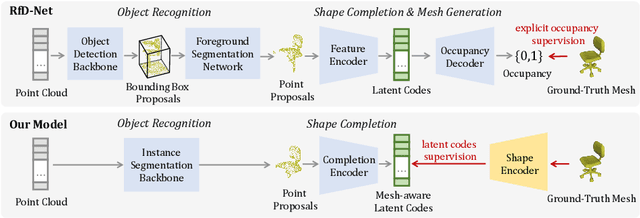
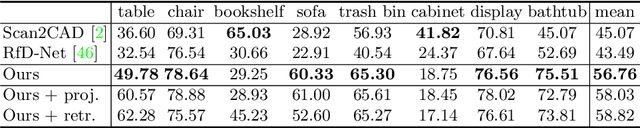
Semantic scene reconstruction from point cloud is an essential and challenging task for 3D scene understanding. This task requires not only to recognize each instance in the scene, but also to recover their geometries based on the partial observed point cloud. Existing methods usually attempt to directly predict occupancy values of the complete object based on incomplete point cloud proposals from a detection-based backbone. However, this framework always fails to reconstruct high fidelity mesh due to the obstruction of various detected false positive object proposals and the ambiguity of incomplete point observations for learning occupancy values of complete objects. To circumvent the hurdle, we propose a Disentangled Instance Mesh Reconstruction (DIMR) framework for effective point scene understanding. A segmentation-based backbone is applied to reduce false positive object proposals, which further benefits our exploration on the relationship between recognition and reconstruction. Based on the accurate proposals, we leverage a mesh-aware latent code space to disentangle the processes of shape completion and mesh generation, relieving the ambiguity caused by the incomplete point observations. Furthermore, with access to the CAD model pool at test time, our model can also be used to improve the reconstruction quality by performing mesh retrieval without extra training. We thoroughly evaluate the reconstructed mesh quality with multiple metrics, and demonstrate the superiority of our method on the challenging ScanNet dataset.
Simultaneous Multivariate Forecast of Space Weather Indices using Deep Neural Network Ensembles
Dec 16, 2021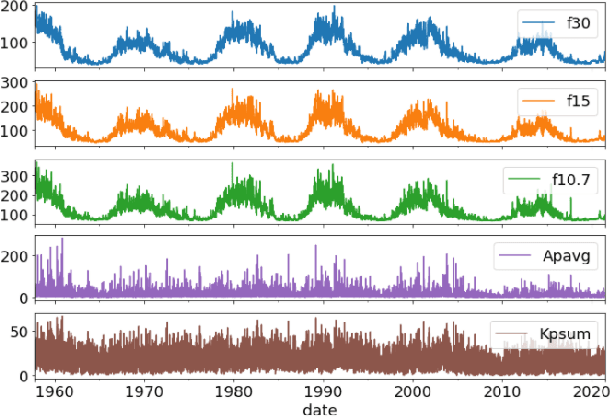
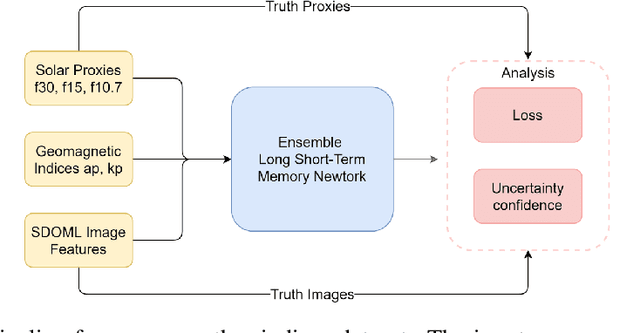
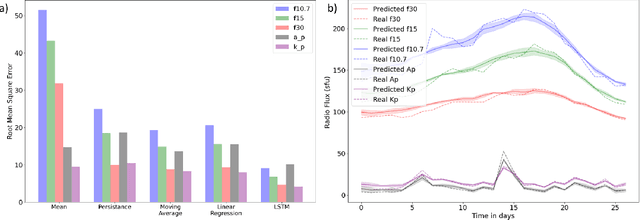
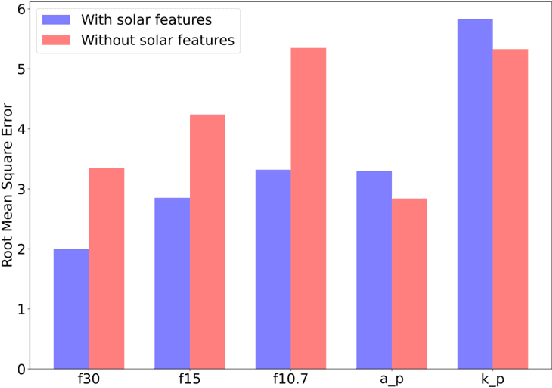
Solar radio flux along with geomagnetic indices are important indicators of solar activity and its effects. Extreme solar events such as flares and geomagnetic storms can negatively affect the space environment including satellites in low-Earth orbit. Therefore, forecasting these space weather indices is of great importance in space operations and science. In this study, we propose a model based on long short-term memory neural networks to learn the distribution of time series data with the capability to provide a simultaneous multivariate 27-day forecast of the space weather indices using time series as well as solar image data. We show a 30-40\% improvement of the root mean-square error while including solar image data with time series data compared to using time series data alone. Simple baselines such as a persistence and running average forecasts are also compared with the trained deep neural network models. We also quantify the uncertainty in our prediction using a model ensemble.
TrajGen: Generating Realistic and Diverse Trajectories with Reactive and Feasible Agent Behaviors for Autonomous Driving
Mar 31, 2022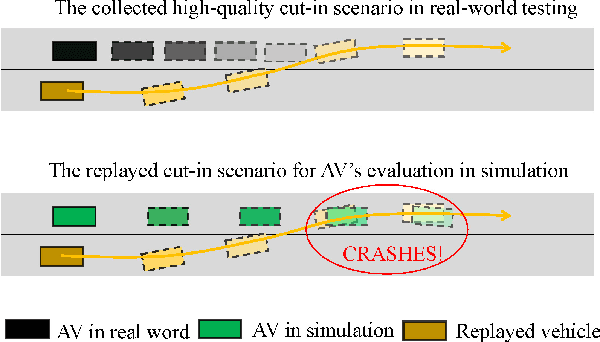
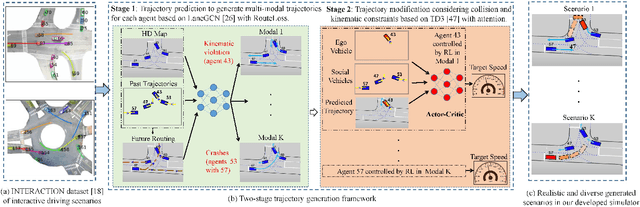
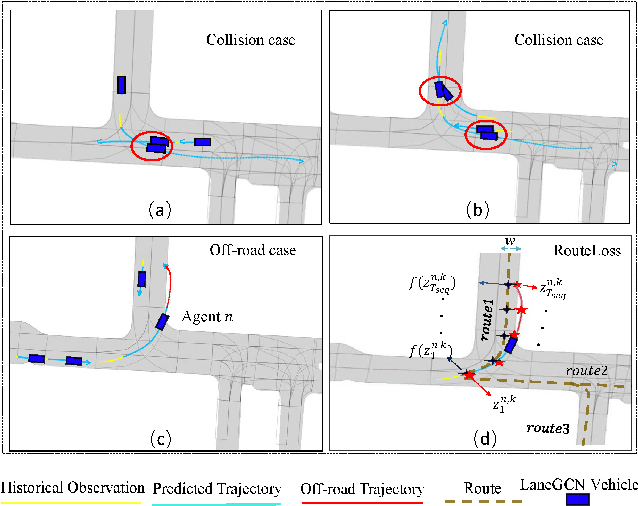
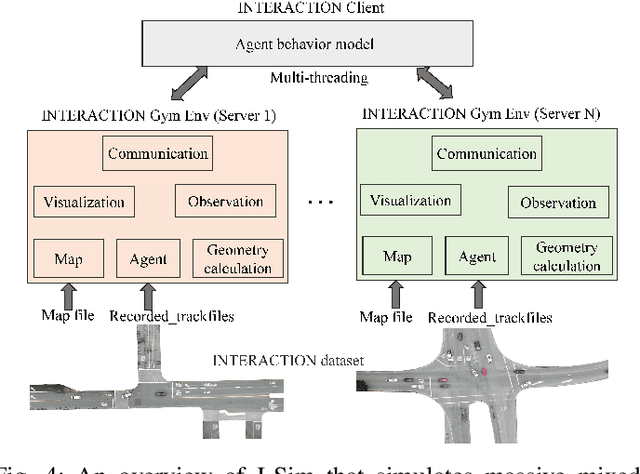
Realistic and diverse simulation scenarios with reactive and feasible agent behaviors can be used for validation and verification of self-driving system performance without relying on expensive and time-consuming real-world testing. Existing simulators rely on heuristic-based behavior models for background vehicles, which cannot capture the complex interactive behaviors in real-world scenarios. To bridge the gap between simulation and the real world, we propose TrajGen, a two-stage trajectory generation framework, which can capture more realistic behaviors directly from human demonstration. In particular, TrajGen consists of the multi-modal trajectory prediction stage and the reinforcement learning based trajectory modification stage. In the first stage, we propose a novel auxiliary RouteLoss for the trajectory prediction model to generate multi-modal diverse trajectories in the drivable area. In the second stage, reinforcement learning is used to track the predicted trajectories while avoiding collisions, which can improve the feasibility of generated trajectories. In addition, we develop a data-driven simulator I-Sim that can be used to train reinforcement learning models in parallel based on naturalistic driving data. The vehicle model in I-Sim can guarantee that the generated trajectories by TrajGen satisfy vehicle kinematic constraints. Finally, we give comprehensive metrics to evaluate generated trajectories for simulation scenarios, which shows that TrajGen outperforms either trajectory prediction or inverse reinforcement learning in terms of fidelity, reactivity, feasibility, and diversity.