 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-Time Glaucoma Detection from Digital Fundus Images using Self-ONNs
Sep 28, 2021
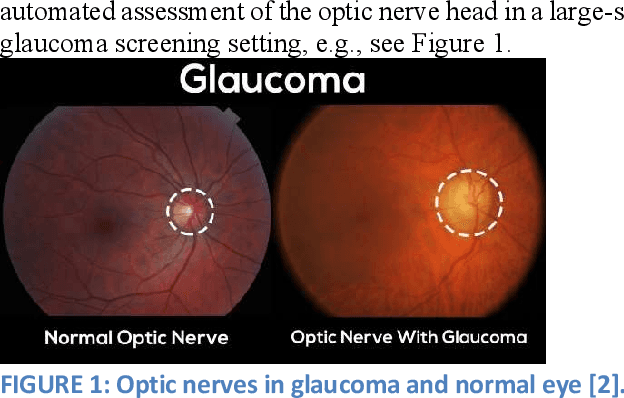
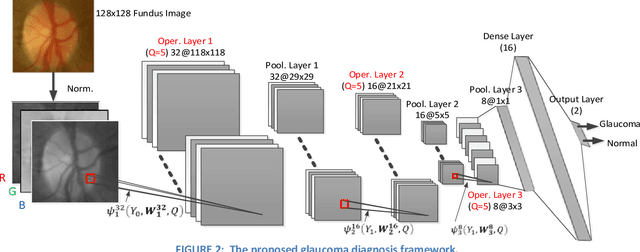
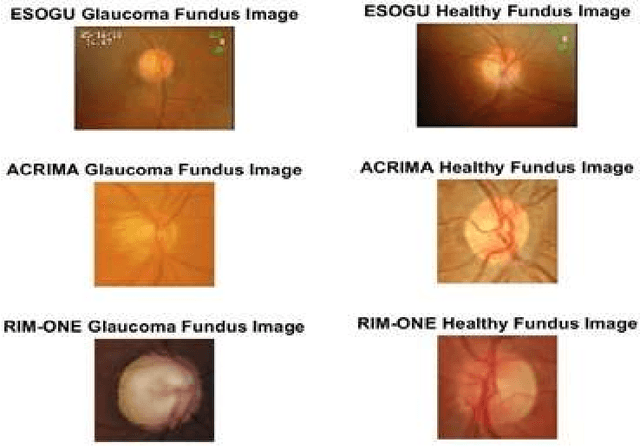

Glaucoma leads to permanent vision disability by damaging the optical nerve that transmits visual images to the brain. The fact that glaucoma does not show any symptoms as it progresses and cannot be stopped at the later stages, makes it critical to be diagnosed in its early stages. Although various deep learning models have been applied for detecting glaucoma from digital fundus images, due to the scarcity of labeled data, their generalization performance was limited along with high computational complexity and special hardware requirements. In this study, compact Self-Organized Operational Neural Networks (Self- ONNs) are proposed for early detection of glaucoma in fundus images and their performance is compared against the conventional (deep) Convolutional Neural Networks (CNNs) over three benchmark datasets: ACRIMA, RIM-ONE, and ESOGU. The experimental results demonstrate that Self-ONNs not only achieve superior detection performance but can also significantly reduce the computational complexity making it a potentially suitable network model for biomedical datasets especially when the data is scarce.
A windowed correlation based feature selection method to improve time series prediction of dengue fever cases
Apr 21, 2021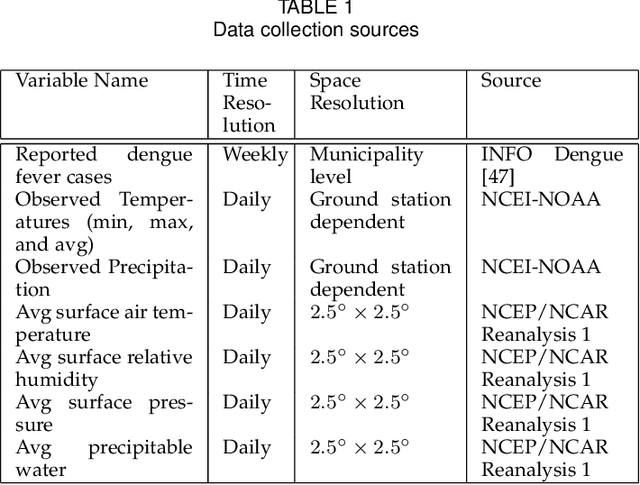
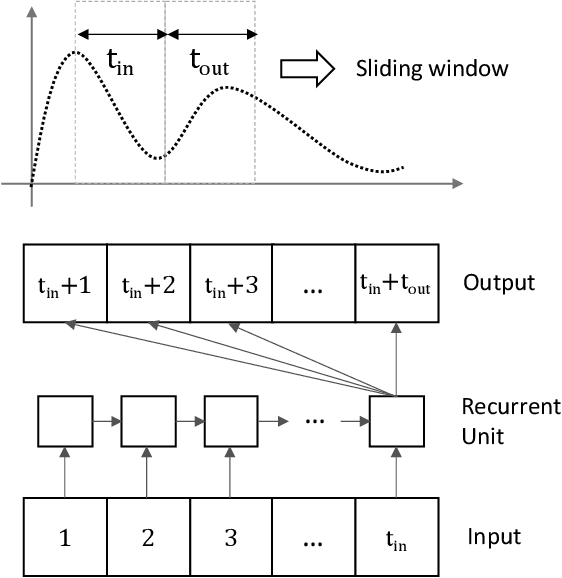
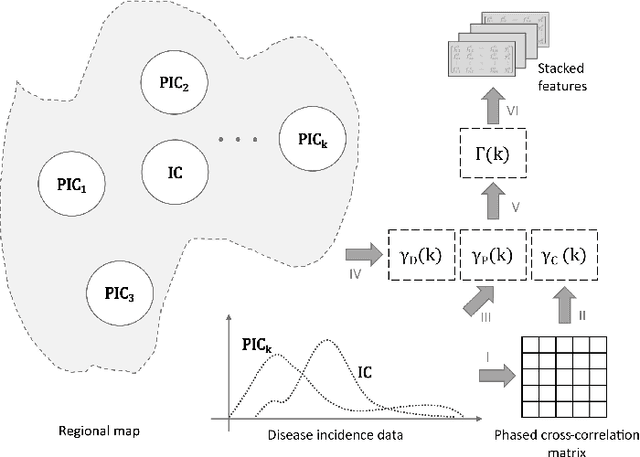

The performance of data-driven prediction models depends on the availability of data samples for model training. A model that learns about dengue fever incidence in a population uses historical data from that corresponding location. Poor performance in prediction can result in places with inadequate data. This work aims to enhance temporally limited dengue case data by methodological addition of epidemically relevant data from nearby locations as predictors (features). A novel framework is presented for windowing incidence data and computing time-shifted correlation-based metrics to quantify feature relevance. The framework ranks incidence data of adjacent locations around a target location by combining the correlation metric with two other metrics: spatial distance and local prevalence. Recurrent neural network-based prediction models achieve up to 33.6% accuracy improvement on average using the proposed method compared to using training data from the target location only. These models achieved mean absolute error (MAE) values as low as 0.128 on [0,1] normalized incidence data for a municipality with the highest dengue prevalence in Brazil's Espirito Santo. When predicting cases aggregated over geographical ecoregions, the models achieved accuracy improvements up to 16.5%, using only 6.5% of incidence data from ranked feature sets. The paper also includes two techniques for windowing time series data: fixed-sized windows and outbreak detection windows. Both of these techniques perform comparably, while the window detection method uses less data for computations. The framework presented in this paper is application-independent, and it could improve the performances of prediction models where data from spatially adjacent locations are available.
A Reinforcement Learning Approach to the Orienteering Problem with Time Windows
Nov 07, 2020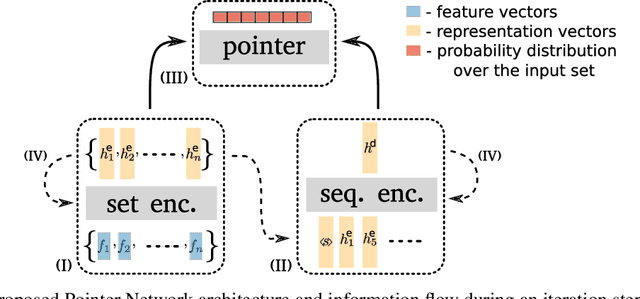
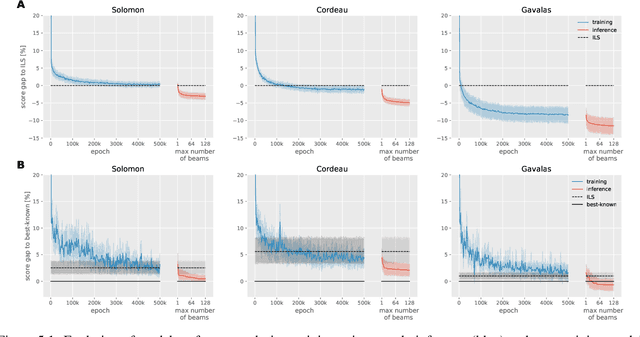
The Orienteering Problem with Time Windows (OPTW) is a combinatorial optimization problem where the goal is to maximize the total scores collected from visited locations, under some time constraints. Several heuristics have been proposed for the OPTW, yet in comparison with machine learning models, a heuristic typically has a smaller potential for generalization and personalization. The application of neural network models to combinatorial optimization has recently shown promising results in similar problems like the Travelling Salesman Problem. A neural network allows learning solutions using reinforcement learning or in a supervised way, depending on the available data. After learning, it can potentially generalize and be quickly fine-tuned to further improve performance and personalization. This is advantageous since, for real word applications, a solution's quality, personalization and execution times are all important factors to be taken into account. Here we explore the use of Pointer Network models trained with reinforcement learning for solving the OPTW problem. Among its various applications, the OPTW can be used to model the Tourist Trip Design Problem (TTDP). We train the Pointer Network with the TTDP problem in mind, by sampling variables that can change across tourists for a particular instance-region: starting position, starting time, time available and the scores of each point of interest. After a model-region is trained it can infer a solution for a particular tourist using beam search. We evaluate our approach on several existing benchmark OPTW instances. We show that it is able to generalize across different generated tourists for each region and that it generally outperforms the most commonly used heuristic while computing the solution in realistic times.
Aligning Videos in Space and Time
Jul 09, 2020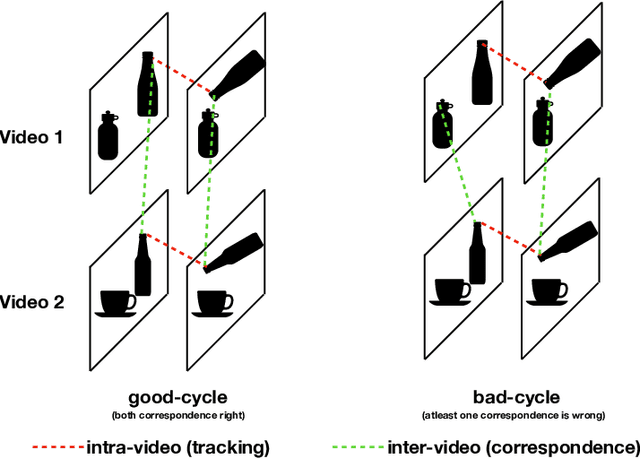

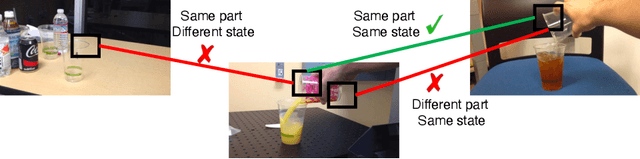

In this paper, we focus on the task of extracting visual correspondences across videos. Given a query video clip from an action class, we aim to align it with training videos in space and time. Obtaining training data for such a fine-grained alignment task is challenging and often ambiguous. Hence, we propose a novel alignment procedure that learns such correspondence in space and time via cross video cycle-consistency. During training, given a pair of videos, we compute cycles that connect patches in a given frame in the first video by matching through frames in the second video. Cycles that connect overlapping patches together are encouraged to score higher than cycles that connect non-overlapping patches. Our experiments on the Penn Action and Pouring datasets demonstrate that the proposed method can successfully learn to correspond semantically similar patches across videos, and learns representations that are sensitive to object and action states.
Finnish Parliament ASR corpus - Analysis, benchmarks and statistics
Mar 28, 2022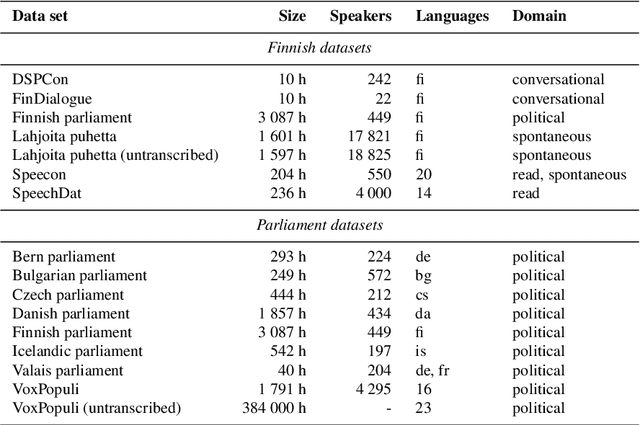
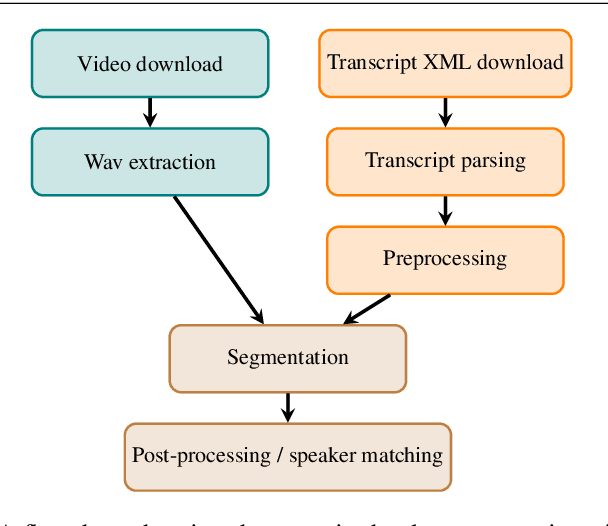

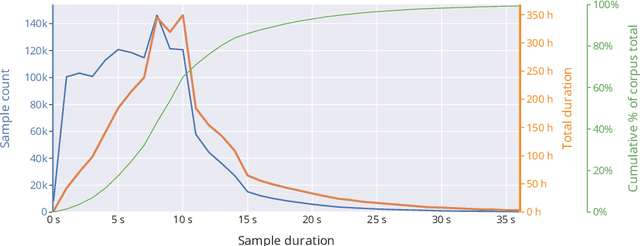
Public sources like parliament meeting recordings and transcripts provide ever-growing material for the training and evaluation of automatic speech recognition (ASR) systems. In this paper, we publish and analyse the Finnish parliament ASR corpus, the largest publicly available collection of manually transcribed speech data for Finnish with over 3000 hours of speech and 449 speakers for which it provides rich demographic metadata. This corpus builds on earlier initial work, and as a result the corpus has a natural split into two training subsets from two periods of time. Similarly, there are two official, corrected test sets covering different times, setting an ASR task with longitudinal distribution-shift characteristics. An official development set is also provided. We develop a complete Kaldi-based data preparation pipeline, and hidden Markov model (HMM), hybrid deep neural network (HMM-DNN) and attention-based encoder-decoder (AED) ASR recipes. We set benchmarks on the official test sets, as well as multiple other recently used test sets. Both temporal corpus subsets are already large, and we observe that beyond their scale, ASR performance on the official test sets plateaus, whereas other domains benefit from added data. The HMM-DNN and AED approaches are compared in a carefully matched equal data setting, with the HMM-DNN system consistently performing better. Finally, the variation of the ASR accuracy is compared between the speaker categories available in the parliament metadata to detect potential biases based on factors such as gender, age, and education.
SleepPPG-Net: a deep learning algorithm for robust sleep staging from continuous photoplethysmography
Feb 11, 2022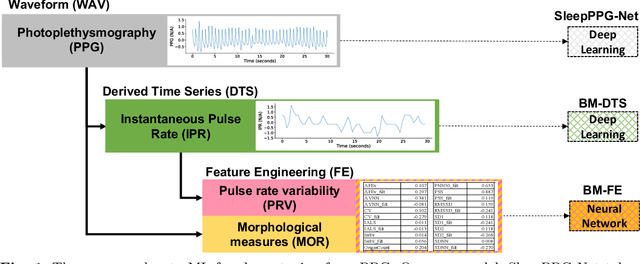
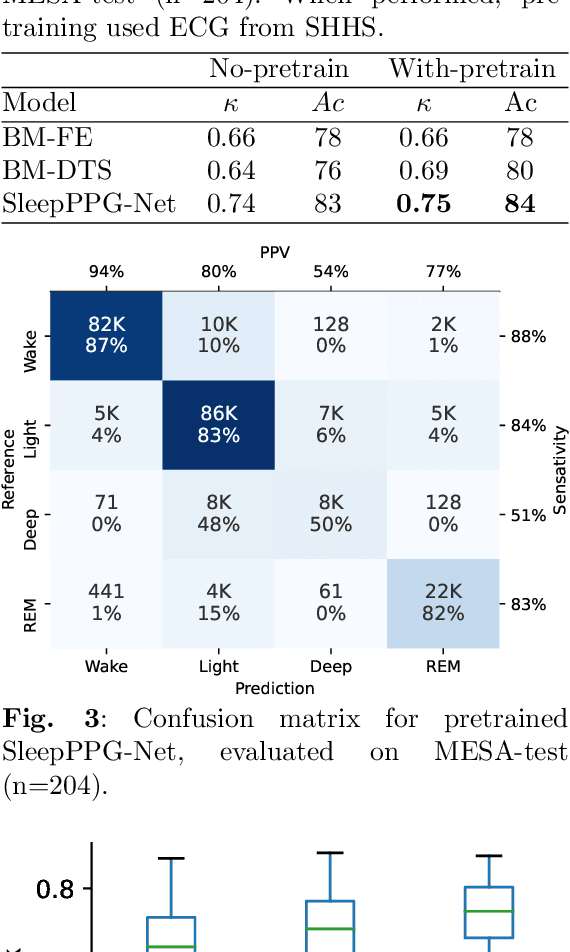
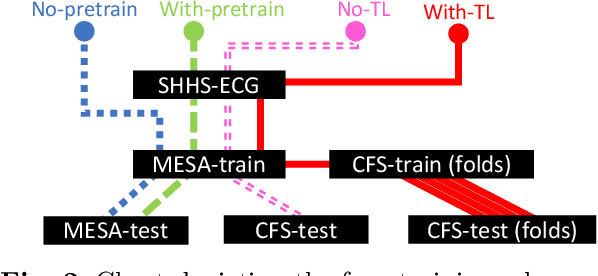
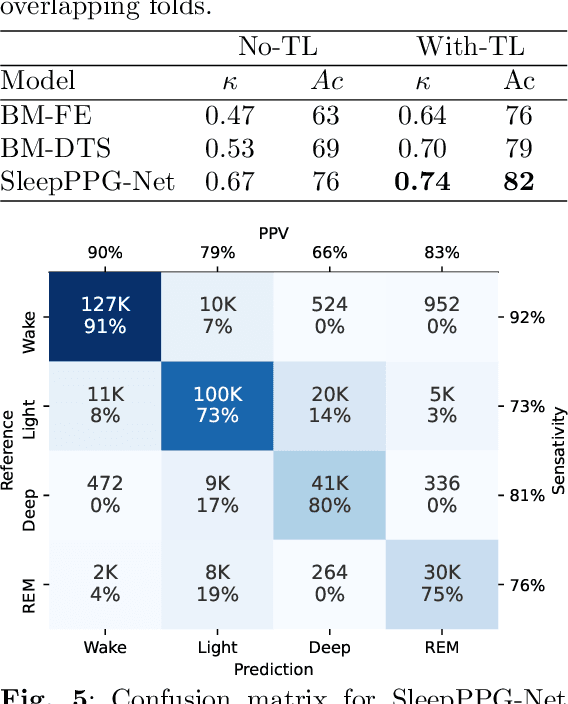
Introduction: Sleep staging is an essential component in the diagnosis of sleep disorders and management of sleep health. It is traditionally measured in a clinical setting and requires a labor-intensive labeling process. We hypothesize that it is possible to perform robust 4-class sleep staging using the raw photoplethysmography (PPG) time series and modern advances in deep learning (DL). Methods: We used two publicly available sleep databases that included raw PPG recordings, totalling 2,374 patients and 23,055 hours. We developed SleepPPG-Net, a DL model for 4-class sleep staging from the raw PPG time series. SleepPPG-Net was trained end-to-end and consists of a residual convolutional network for automatic feature extraction and a temporal convolutional network to capture long-range contextual information. We benchmarked the performance of SleepPPG-Net against models based on the best-reported state-of-the-art (SOTA) algorithms. Results: When benchmarked on a held-out test set, SleepPPG-Net obtained a median Cohen's Kappa ($\kappa$) score of 0.75 against 0.69 for the best SOTA approach. SleepPPG-Net showed good generalization performance to an external database, obtaining a $\kappa$ score of 0.74 after transfer learning. Perspective: Overall, SleepPPG-Net provides new SOTA performance. In addition, performance is high enough to open the path to the development of wearables that meet the requirements for usage in clinical applications such as the diagnosis and monitoring of obstructive sleep apnea.
Contrastive Learning for Automotive mmWave Radar Detection Points Based Instance Segmentation
Mar 13, 2022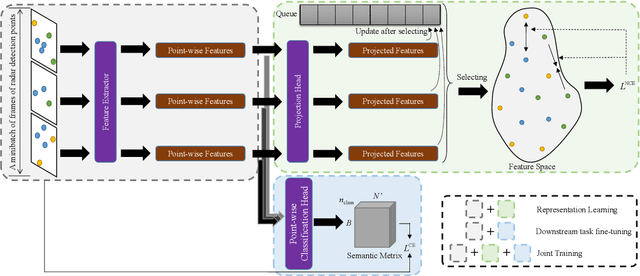
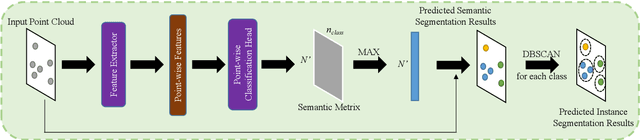
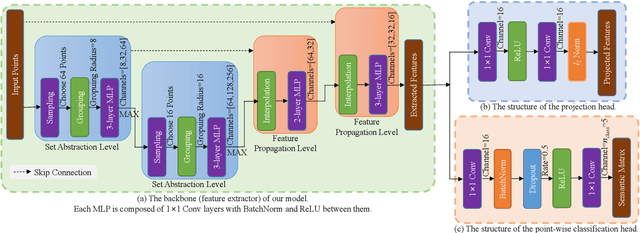
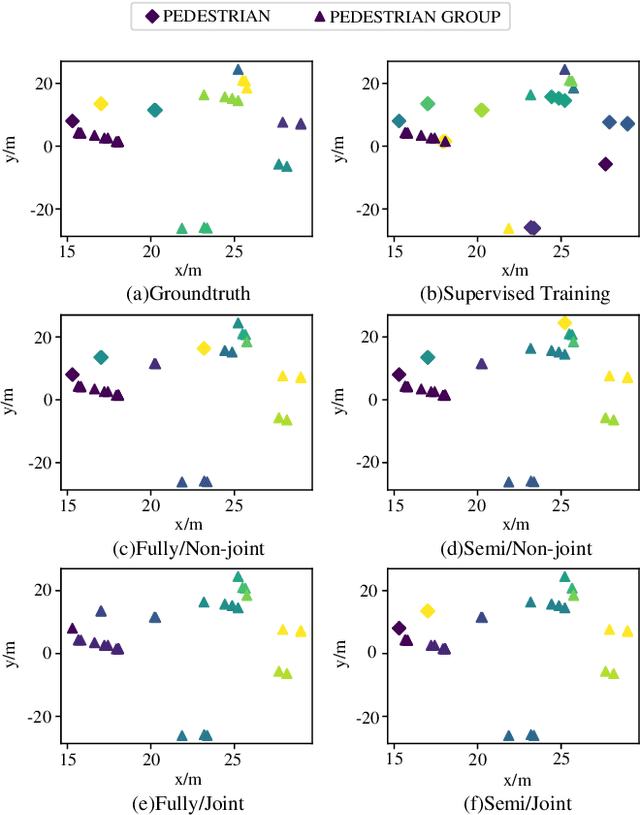
The automotive mmWave radar plays a key role in advanced driver assistance systems (ADAS) and autonomous driving. Deep learning-based instance segmentation enables real-time object identification from the radar detection points. In the conventional training process, accurate annotation is the key. However, high-quality annotations of radar detection points are challenging to achieve due to their ambiguity and sparsity. To address this issue, we propose a contrastive learning approach for implementing radar detection points-based instance segmentation. We define the positive and negative samples according to the ground-truth label, apply the contrastive loss to train the model first, and then perform training for the following downstream task. In addition, these two steps can be merged into one, and pseudo labels can be generated for the unlabeled data to improve the performance further. Thus, there are four different training settings for our method. Experiments show that when the ground-truth information is only available for 5% of the training data, our method still achieves a comparable performance to the approach trained in a supervised manner with 100% ground-truth information.
ROLL: Long-Term Robust LiDAR-based Localization With Temporary Mapping in Changing Environments
Mar 08, 2022
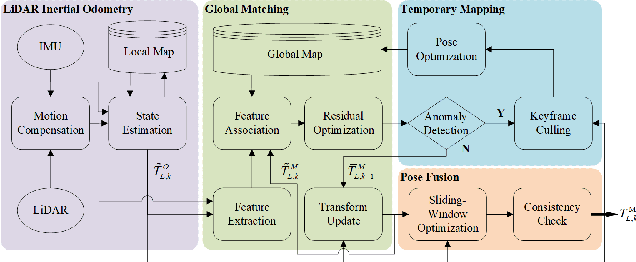

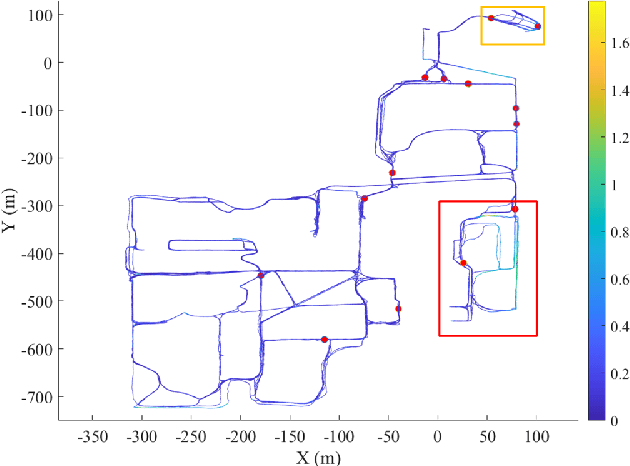
Long-term scene changes present challenges to localization systems using a pre-built map. This paper presents a LiDAR-based system that can provide robust localization against those challenges. Our method starts with activation of a mapping process temporarily when global matching towards the pre-built map is unreliable. The temporary map will be merged onto the pre-built map for later localization runs once reliable matching is obtained again. We further integrate a LiDAR inertial odometry (LIO) to provide motion-compensated LiDAR scans and a reliable initial pose guess for the global matching module. To generate a smooth real-time trajectory for navigation purposes, we fuse poses from odometry and global matching by solving a pose graph optimization problem. We evaluate our localization system with extensive experiments on the NCLT dataset including a variety of changing indoor and outdoor environments, and the results demonstrate a robust and accurate localization performance for over a year. The implementations are open sourced on GitHub.
E-CIR: Event-Enhanced Continuous Intensity Recovery
Mar 03, 2022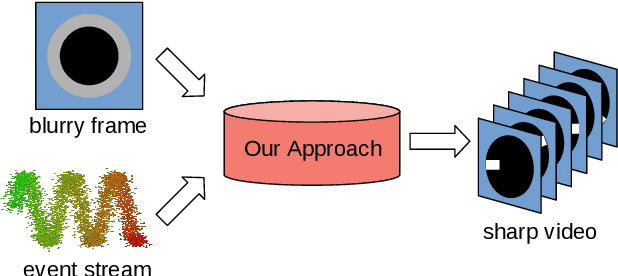
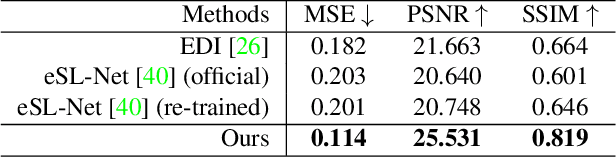
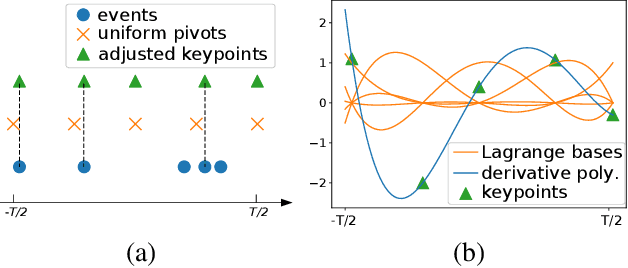

A camera begins to sense light the moment we press the shutter button. During the exposure interval, relative motion between the scene and the camera causes motion blur, a common undesirable visual artifact. This paper presents E-CIR, which converts a blurry image into a sharp video represented as a parametric function from time to intensity. E-CIR leverages events as an auxiliary input. We discuss how to exploit the temporal event structure to construct the parametric bases. We demonstrate how to train a deep learning model to predict the function coefficients. To improve the appearance consistency, we further introduce a refinement module to propagate visual features among consecutive frames. Compared to state-of-the-art event-enhanced deblurring approaches, E-CIR generates smoother and more realistic results. The implementation of E-CIR is available at https://github.com/chensong1995/E-CIR.
Unified Multivariate Gaussian Mixture for Efficient Neural Image Compression
Mar 21, 2022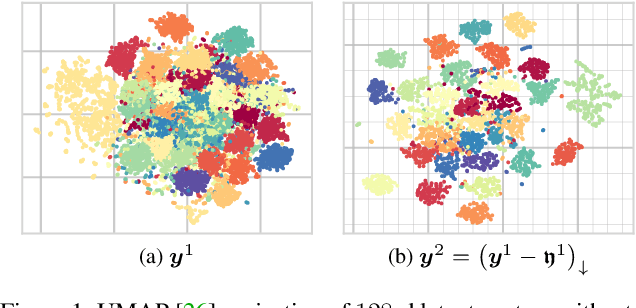
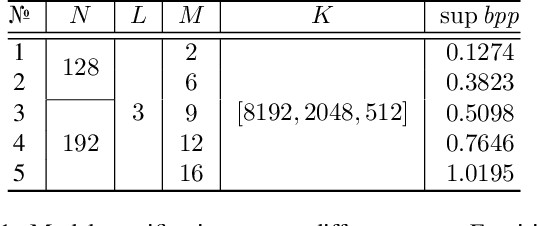
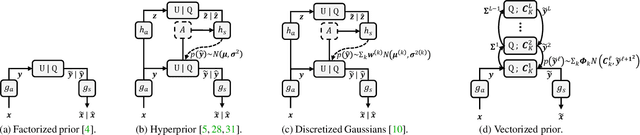
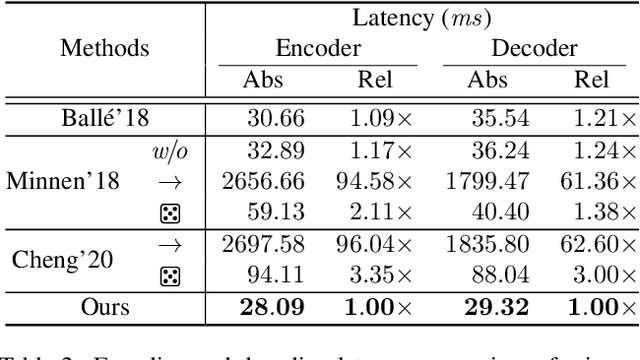
Modeling latent variables with priors and hyperpriors is an essential problem in variational image compression. Formally, trade-off between rate and distortion is handled well if priors and hyperpriors precisely describe latent variables. Current practices only adopt univariate priors and process each variable individually. However, we find inter-correlations and intra-correlations exist when observing latent variables in a vectorized perspective. These findings reveal visual redundancies to improve rate-distortion performance and parallel processing ability to speed up compression. This encourages us to propose a novel vectorized prior. Specifically, a multivariate Gaussian mixture is proposed with means and covariances to be estimated. Then, a novel probabilistic vector quantization is utilized to effectively approximate means, and remaining covariances are further induced to a unified mixture and solved by cascaded estimation without context models involved. Furthermore, codebooks involved in quantization are extended to multi-codebooks for complexity reduction, which formulates an efficient compression procedure. Extensive experiments on benchmark datasets against state-of-the-art indicate our model has better rate-distortion performance and an impressive $3.18\times$ compression speed up, giving us the ability to perform real-time, high-quality variational image compression in practice. Our source code is publicly available at \url{https://github.com/xiaosu-zhu/McQuic}.
* Accepted to CVPR 2022