 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Indy Autonomous Challenge -- Autonomous Race Cars at the Handling Limits
Feb 08, 2022
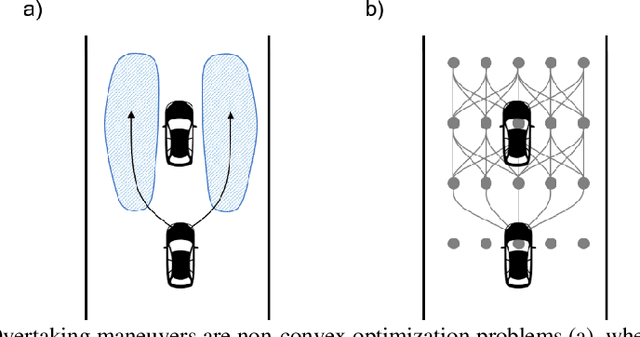
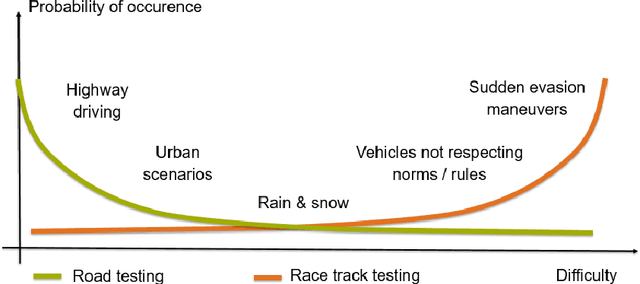

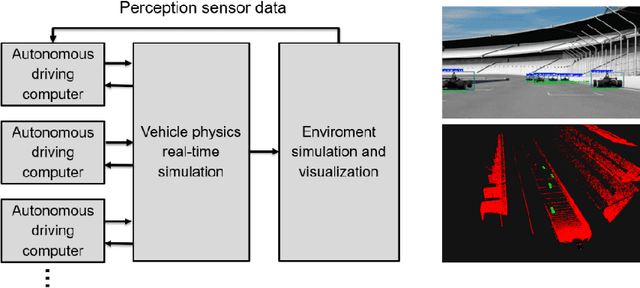
Motorsport has always been an enabler for technological advancement, and the same applies to the autonomous driving industry. The team TUM Auton-omous Motorsports will participate in the Indy Autonomous Challenge in Octo-ber 2021 to benchmark its self-driving software-stack by racing one out of ten autonomous Dallara AV-21 racecars at the Indianapolis Motor Speedway. The first part of this paper explains the reasons for entering an autonomous vehicle race from an academic perspective: It allows focusing on several edge cases en-countered by autonomous vehicles, such as challenging evasion maneuvers and unstructured scenarios. At the same time, it is inherently safe due to the motor-sport related track safety precautions. It is therefore an ideal testing ground for the development of autonomous driving algorithms capable of mastering the most challenging and rare situations. In addition, we provide insight into our soft-ware development workflow and present our Hardware-in-the-Loop simulation setup. It is capable of running simulations of up to eight autonomous vehicles in real time. The second part of the paper gives a high-level overview of the soft-ware architecture and covers our development priorities in building a high-per-formance autonomous racing software: maximum sensor detection range, relia-ble handling of multi-vehicle situations, as well as reliable motion control under uncertainty.
Socially Aware Robot Crowd Navigation with Interaction Graphs and Human Trajectory Prediction
Mar 03, 2022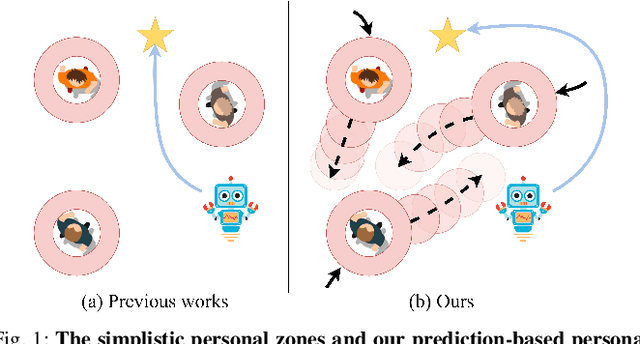
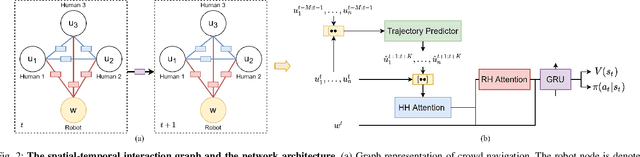
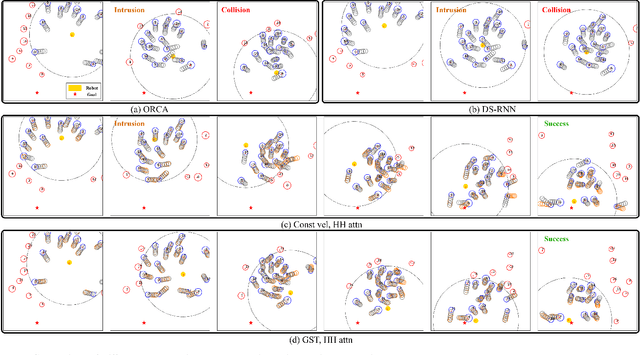

We study the problem of safe and socially aware robot navigation in dense and interactive human crowds. Previous works use simplified methods to model the personal spaces of pedestrians and ignore the social compliance of the robot behaviors. In this paper, we provide a more accurate representation of personal zones of walking pedestrians with their future trajectories. The predicted personal zones are incorporated into a reinforcement learning framework to prevent the robot from intruding into the personal zones. To learn socially aware navigation policies, we propose a novel recurrent graph neural network with attention mechanisms to capture the interactions among agents through space and time. We demonstrate that our method enables the robot to achieve good navigation performance and non-invasiveness in challenging crowd navigation scenarios. We successfully transfer the policy learned in the simulator to a real-world TurtleBot 2i.
The Analysis of Online Event Streams: Predicting the Next Activity for Anomaly Detection
Mar 17, 2022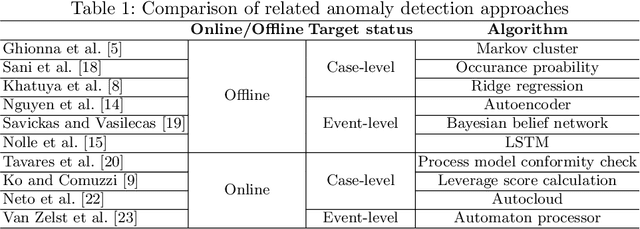
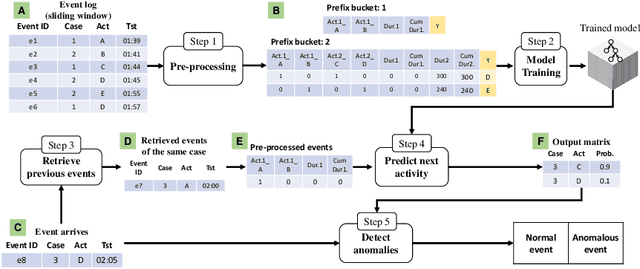
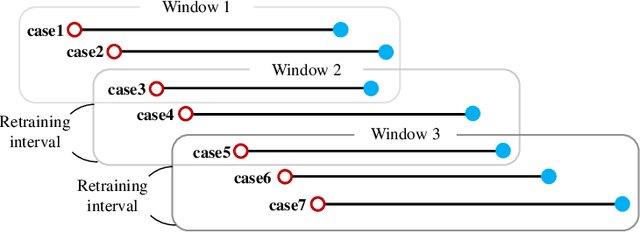
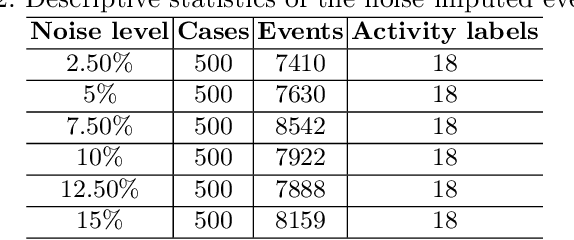
Anomaly detection in process mining focuses on identifying anomalous cases or events in process executions. The resulting diagnostics are used to provide measures to prevent fraudulent behavior, as well as to derive recommendations for improving process compliance and security. Most existing techniques focus on detecting anomalous cases in an offline setting. However, to identify potential anomalies in a timely manner and take immediate countermeasures, it is necessary to detect event-level anomalies online, in real-time. In this paper, we propose to tackle the online event anomaly detection problem using next-activity prediction methods. More specifically, we investigate the use of both ML models (such as RF and XGBoost) and deep models (such as LSTM) to predict the probabilities of next-activities and consider the events predicted unlikely as anomalies. We compare these predictive anomaly detection methods to four classical unsupervised anomaly detection approaches (such as Isolation forest and LOF) in the online setting. Our evaluation shows that the proposed method using ML models tends to outperform the one using a deep model, while both methods outperform the classical unsupervised approaches in detecting anomalous events.
Fast Doubly-Adaptive MCMC to Estimate the Gibbs Partition Function with Weak Mixing Time Bounds
Nov 14, 2021
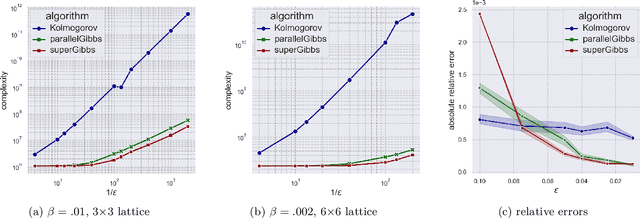
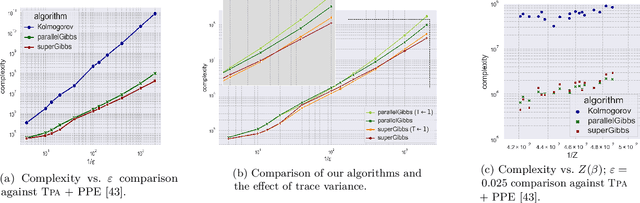
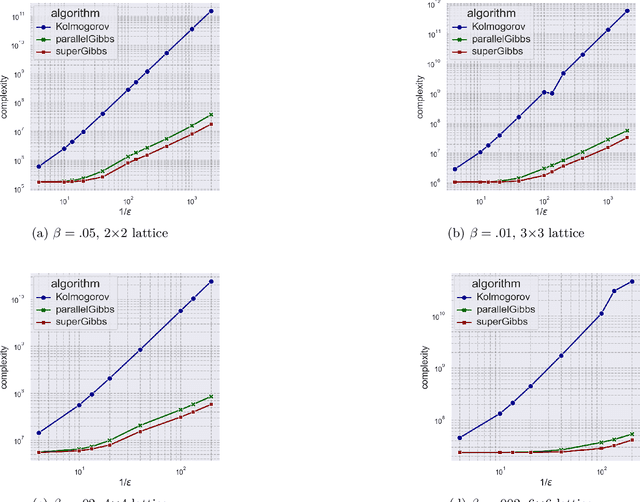
We present a novel method for reducing the computational complexity of rigorously estimating the partition functions (normalizing constants) of Gibbs (Boltzmann) distributions, which arise ubiquitously in probabilistic graphical models. A major obstacle to practical applications of Gibbs distributions is the need to estimate their partition functions. The state of the art in addressing this problem is multi-stage algorithms, which consist of a cooling schedule, and a mean estimator in each step of the schedule. While the cooling schedule in these algorithms is adaptive, the mean estimation computations use MCMC as a black-box to draw approximate samples. We develop a doubly adaptive approach, combining the adaptive cooling schedule with an adaptive MCMC mean estimator, whose number of Markov chain steps adapts dynamically to the underlying chain. Through rigorous theoretical analysis, we prove that our method outperforms the state of the art algorithms in several factors: (1) The computational complexity of our method is smaller; (2) Our method is less sensitive to loose bounds on mixing times, an inherent component in these algorithms; and (3) The improvement obtained by our method is particularly significant in the most challenging regime of high-precision estimation. We demonstrate the advantage of our method in experiments run on classic factor graphs, such as voting models and Ising models.
MultiRocket: Effective summary statistics for convolutional outputs in time series classification
Jan 31, 2021
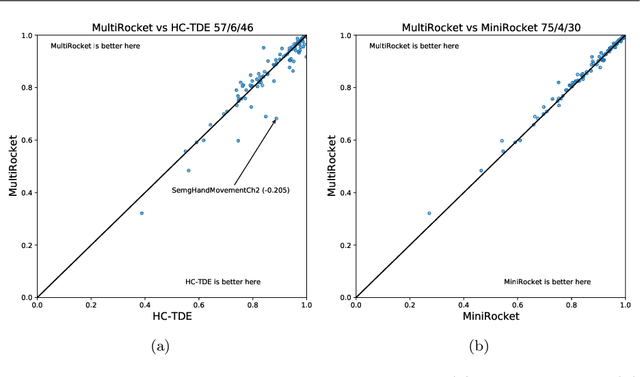

Rocket and MiniRocket, while two of the fastest methods for time series classification, are both somewhat less accurate than the current most accurate methods (namely, HIVE-COTE and its variants). We show that it is possible to significantly improve the accuracy of MiniRocket (and Rocket), with some additional computational expense, by expanding the set of features produced by the transform, making MultiRocket (for MiniRocket with Multiple Features) overall the single most accurate method on the datasets in the UCR archive, while still being orders of magnitude faster than any algorithm of comparable accuracy other than its precursors
Delta Distillation for Efficient Video Processing
Mar 17, 2022
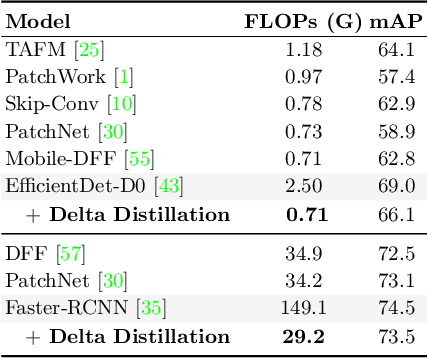

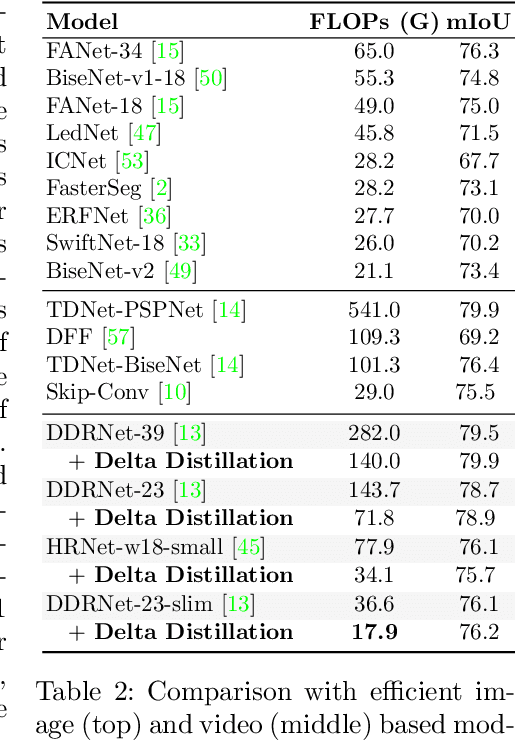
This paper aims to accelerate video stream processing, such as object detection and semantic segmentation, by leveraging the temporal redundancies that exist between video frames. Instead of propagating and warping features using motion alignment, such as optical flow, we propose a novel knowledge distillation schema coined as Delta Distillation. In our proposal, the student learns the variations in the teacher's intermediate features over time. We demonstrate that these temporal variations can be effectively distilled due to the temporal redundancies within video frames. During inference, both teacher and student cooperate for providing predictions: the former by providing initial representations extracted only on the key-frame, and the latter by iteratively estimating and applying deltas for the successive frames. Moreover, we consider various design choices to learn optimal student architectures including an end-to-end learnable architecture search. By extensive experiments on a wide range of architectures, including the most efficient ones, we demonstrate that delta distillation sets a new state of the art in terms of accuracy vs. efficiency trade-off for semantic segmentation and object detection in videos. Finally, we show that, as a by-product, delta distillation improves the temporal consistency of the teacher model.
Distill-VQ: Learning Retrieval Oriented Vector Quantization By Distilling Knowledge from Dense Embeddings
Apr 01, 2022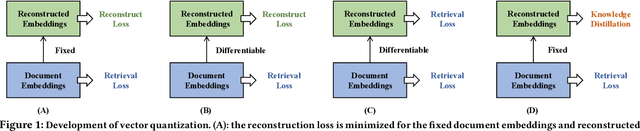
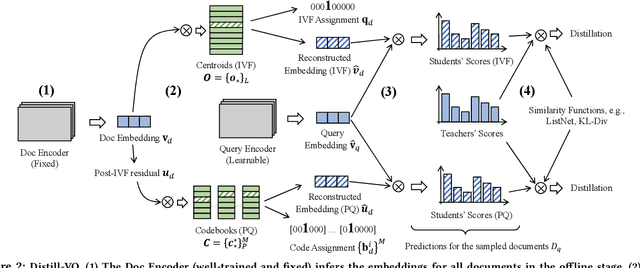
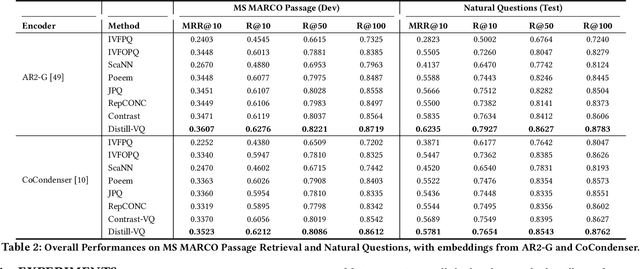
Vector quantization (VQ) based ANN indexes, such as Inverted File System (IVF) and Product Quantization (PQ), have been widely applied to embedding based document retrieval thanks to the competitive time and memory efficiency. Originally, VQ is learned to minimize the reconstruction loss, i.e., the distortions between the original dense embeddings and the reconstructed embeddings after quantization. Unfortunately, such an objective is inconsistent with the goal of selecting ground-truth documents for the input query, which may cause severe loss of retrieval quality. Recent works identify such a defect, and propose to minimize the retrieval loss through contrastive learning. However, these methods intensively rely on queries with ground-truth documents, whose performance is limited by the insufficiency of labeled data. In this paper, we propose Distill-VQ, which unifies the learning of IVF and PQ within a knowledge distillation framework. In Distill-VQ, the dense embeddings are leveraged as "teachers", which predict the query's relevance to the sampled documents. The VQ modules are treated as the "students", which are learned to reproduce the predicted relevance, such that the reconstructed embeddings may fully preserve the retrieval result of the dense embeddings. By doing so, Distill-VQ is able to derive substantial training signals from the massive unlabeled data, which significantly contributes to the retrieval quality. We perform comprehensive explorations for the optimal conduct of knowledge distillation, which may provide useful insights for the learning of VQ based ANN index. We also experimentally show that the labeled data is no longer a necessity for high-quality vector quantization, which indicates Distill-VQ's strong applicability in practice.
Bayesian Neural Hawkes Process for Event Uncertainty Prediction
Jan 19, 2022

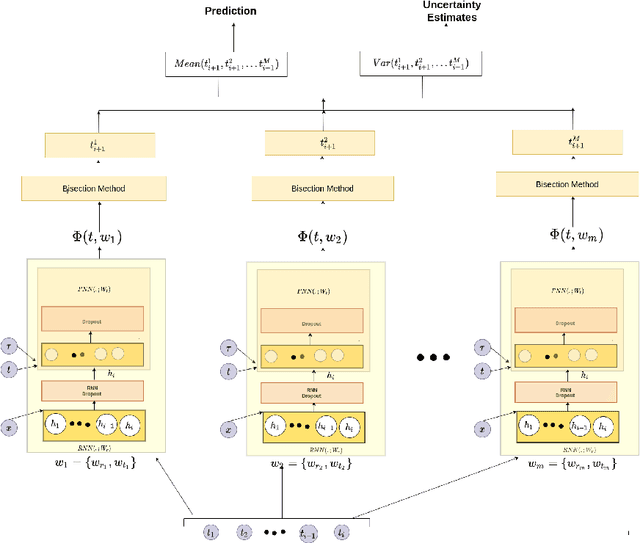
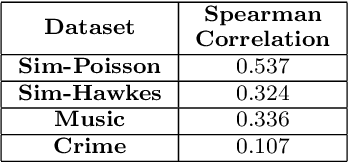
Event data consisting of time of occurrence of the events arises in several real-world applications. Recent works have introduced neural network based point processes for modeling event-times, and were shown to provide state-of-the-art performance in predicting event-times. However, neural point process models lack a good uncertainty quantification capability on predictions. A proper uncertainty quantification over event modeling will help in better decision making for many practical applications. Therefore, we propose a novel point process model, Bayesian Neural Hawkes process (BNHP) which leverages uncertainty modelling capability of Bayesian models and generalization capability of the neural networks to model event occurrence times. We augment the model with spatio-temporal modeling capability where it can consider uncertainty over predicted time and location of the events. Experiments on simulated and real-world datasets show that BNHP significantly improves prediction performance and uncertainty quantification for modelling events.
Can Deep Neural Networks be Converted to Ultra Low-Latency Spiking Neural Networks?
Dec 22, 2021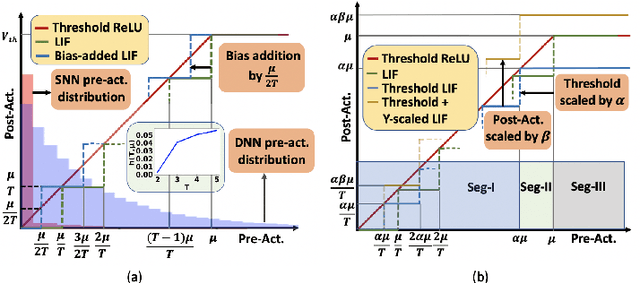
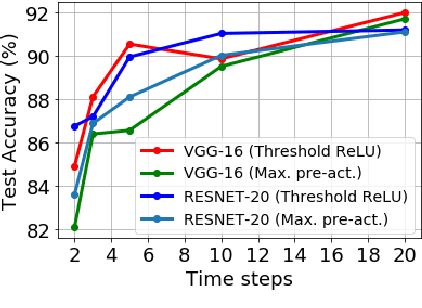

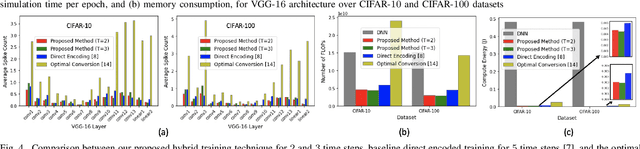
Spiking neural networks (SNNs), that operate via binary spikes distributed over time, have emerged as a promising energy efficient ML paradigm for resource-constrained devices. However, the current state-of-the-art (SOTA) SNNs require multiple time steps for acceptable inference accuracy, increasing spiking activity and, consequently, energy consumption. SOTA training strategies for SNNs involve conversion from a non-spiking deep neural network (DNN). In this paper, we determine that SOTA conversion strategies cannot yield ultra low latency because they incorrectly assume that the DNN and SNN pre-activation values are uniformly distributed. We propose a new training algorithm that accurately captures these distributions, minimizing the error between the DNN and converted SNN. The resulting SNNs have ultra low latency and high activation sparsity, yielding significant improvements in compute efficiency. In particular, we evaluate our framework on image recognition tasks from CIFAR-10 and CIFAR-100 datasets on several VGG and ResNet architectures. We obtain top-1 accuracy of 64.19% with only 2 time steps on the CIFAR-100 dataset with ~159.2x lower compute energy compared to an iso-architecture standard DNN. Compared to other SOTA SNN models, our models perform inference 2.5-8x faster (i.e., with fewer time steps).
Time-aware Large Kernel Convolutions
Feb 08, 2020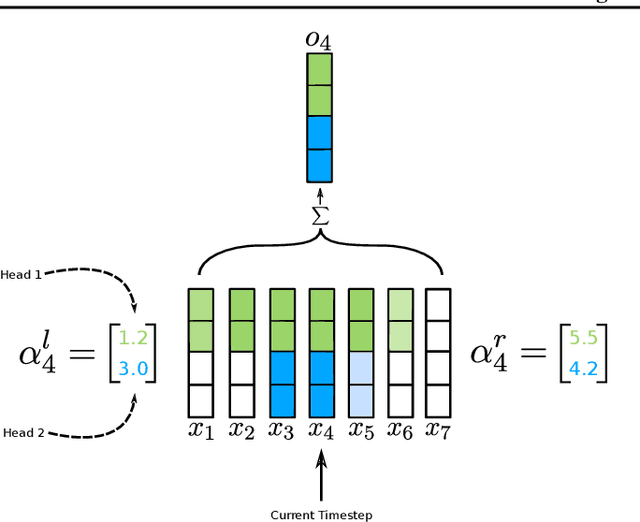

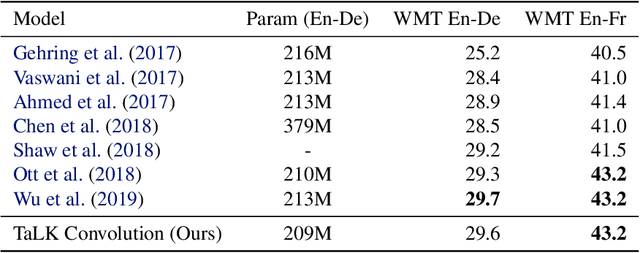
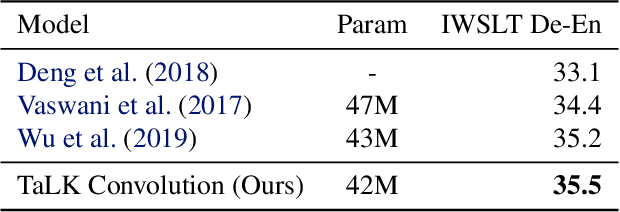
To date, most state-of-the-art sequence modelling architectures use attention to build generative models for language based tasks. Some of these models use all the available sequence tokens to generate an attention distribution which results in time complexity of $O(n^2)$. Alternatively, they utilize depthwise convolutions with softmax normalized kernels of size $k$ acting as a limited-window self-attention, resulting in time complexity of $O(k{\cdot}n)$. In this paper, we introduce Time-aware Large Kernel (TaLK) Convolutions, a novel adaptive convolution operation that learns to predict the size of a summation kernel instead of using the fixed-sized kernel matrix. This method yields a time complexity of $O(n)$, effectively making the sequence encoding process linear to the number of tokens. We evaluate the proposed method on large-scale standard machine translation and language modelling datasets and show that TaLK Convolutions constitute an efficient improvement over other attention/convolution based approaches.