 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Kernel Packet: An Exact and Scalable Algorithm for Gaussian Process Regression with Matérn Correlations
Mar 09, 2022
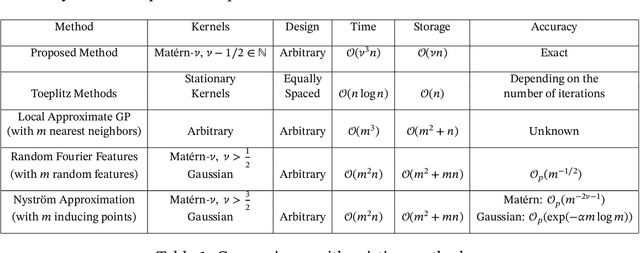
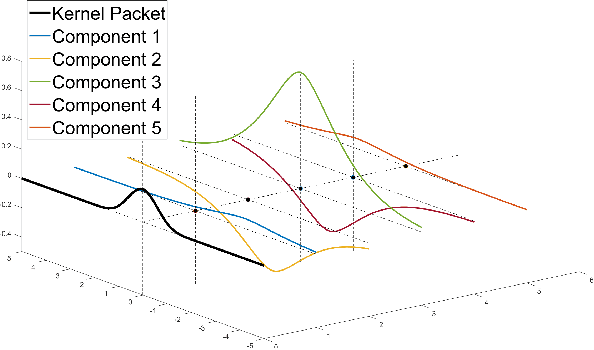
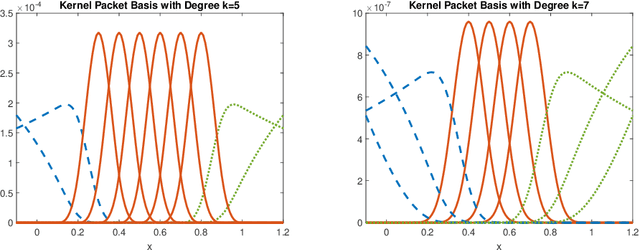

We develop an exact and scalable algorithm for one-dimensional Gaussian process regression with Mat\'ern correlations whose smoothness parameter $\nu$ is a half-integer. The proposed algorithm only requires $\mathcal{O}(\nu^3 n)$ operations and $\mathcal{O}(\nu n)$ storage. This leads to a linear-cost solver since $\nu$ is chosen to be fixed and usually very small in most applications. The proposed method can be applied to multi-dimensional problems if a full grid or a sparse grid design is used. The proposed method is based on a novel theory for Mat\'ern correlation functions. We find that a suitable rearrangement of these correlation functions can produce a compactly supported function, called a "kernel packet". Using a set of kernel packets as basis functions leads to a sparse representation of the covariance matrix that results in the proposed algorithm. Simulation studies show that the proposed algorithm, when applicable, is significantly superior to the existing alternatives in both the computational time and predictive accuracy.
Teachable Reinforcement Learning via Advice Distillation
Mar 19, 2022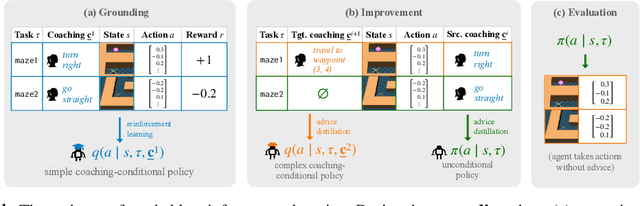
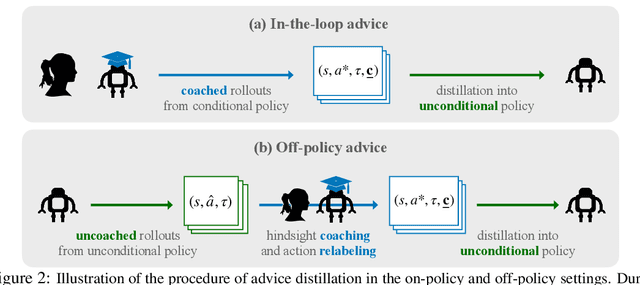
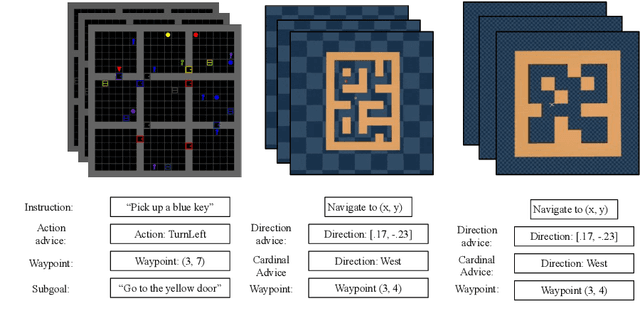
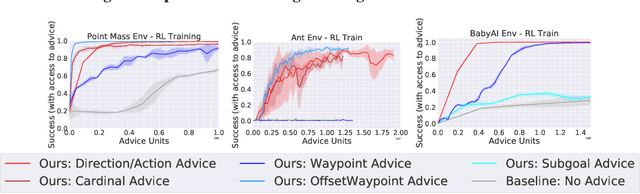
Training automated agents to complete complex tasks in interactive environments is challenging: reinforcement learning requires careful hand-engineering of reward functions, imitation learning requires specialized infrastructure and access to a human expert, and learning from intermediate forms of supervision (like binary preferences) is time-consuming and extracts little information from each human intervention. Can we overcome these challenges by building agents that learn from rich, interactive feedback instead? We propose a new supervision paradigm for interactive learning based on "teachable" decision-making systems that learn from structured advice provided by an external teacher. We begin by formalizing a class of human-in-the-loop decision making problems in which multiple forms of teacher-provided advice are available to a learner. We then describe a simple learning algorithm for these problems that first learns to interpret advice, then learns from advice to complete tasks even in the absence of human supervision. In puzzle-solving, navigation, and locomotion domains, we show that agents that learn from advice can acquire new skills with significantly less human supervision than standard reinforcement learning algorithms and often less than imitation learning.
Fast Doubly-Adaptive MCMC to Estimate the Gibbs Partition Function with Weak Mixing Time Bounds
Nov 14, 2021
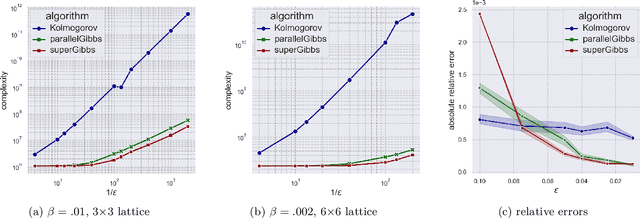
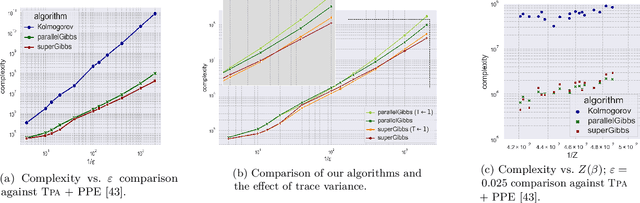
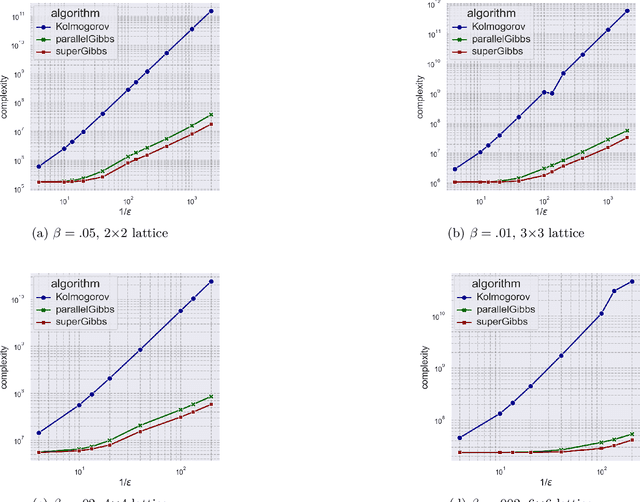
We present a novel method for reducing the computational complexity of rigorously estimating the partition functions (normalizing constants) of Gibbs (Boltzmann) distributions, which arise ubiquitously in probabilistic graphical models. A major obstacle to practical applications of Gibbs distributions is the need to estimate their partition functions. The state of the art in addressing this problem is multi-stage algorithms, which consist of a cooling schedule, and a mean estimator in each step of the schedule. While the cooling schedule in these algorithms is adaptive, the mean estimation computations use MCMC as a black-box to draw approximate samples. We develop a doubly adaptive approach, combining the adaptive cooling schedule with an adaptive MCMC mean estimator, whose number of Markov chain steps adapts dynamically to the underlying chain. Through rigorous theoretical analysis, we prove that our method outperforms the state of the art algorithms in several factors: (1) The computational complexity of our method is smaller; (2) Our method is less sensitive to loose bounds on mixing times, an inherent component in these algorithms; and (3) The improvement obtained by our method is particularly significant in the most challenging regime of high-precision estimation. We demonstrate the advantage of our method in experiments run on classic factor graphs, such as voting models and Ising models.
A framework for bilevel optimization that enables stochastic and global variance reduction algorithms
Jan 31, 2022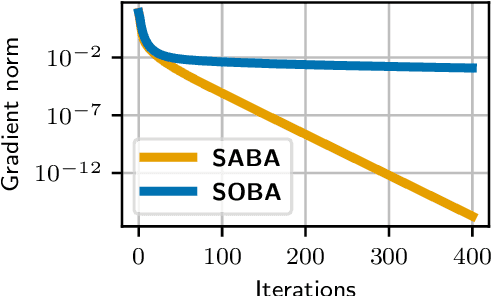
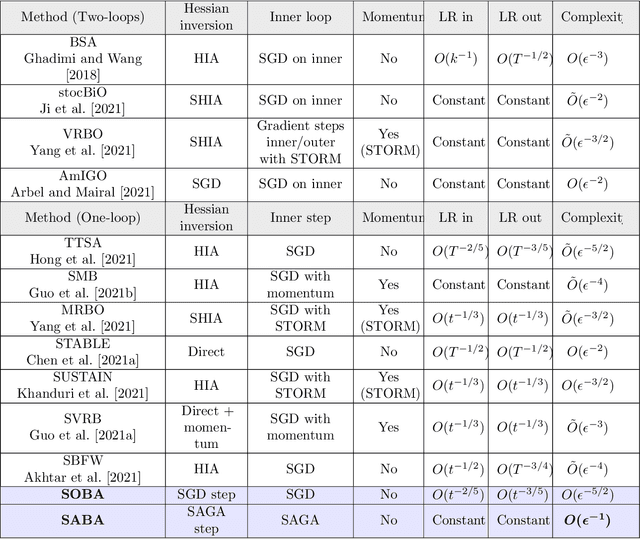

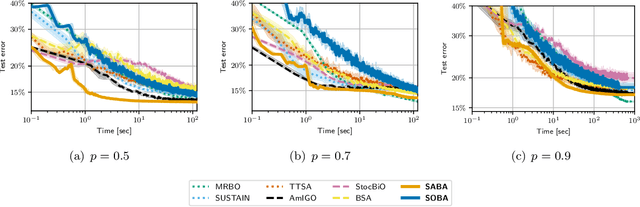
Bilevel optimization, the problem of minimizing a value function which involves the arg-minimum of another function, appears in many areas of machine learning. In a large scale setting where the number of samples is huge, it is crucial to develop stochastic methods, which only use a few samples at a time to progress. However, computing the gradient of the value function involves solving a linear system, which makes it difficult to derive unbiased stochastic estimates. To overcome this problem we introduce a novel framework, in which the solution of the inner problem, the solution of the linear system, and the main variable evolve at the same time. These directions are written as a sum, making it straightforward to derive unbiased estimates. The simplicity of our approach allows us to develop global variance reduction algorithms, where the dynamics of all variables is subject to variance reduction. We demonstrate that SABA, an adaptation of the celebrated SAGA algorithm in our framework, has $O(\frac1T)$ convergence rate, and that it achieves linear convergence under Polyak-Lojasciewicz assumption. This is the first stochastic algorithm for bilevel optimization that verifies either of these properties. Numerical experiments validate the usefulness of our method.
Shadows can be Dangerous: Stealthy and Effective Physical-world Adversarial Attack by Natural Phenomenon
Mar 23, 2022


Estimating the risk level of adversarial examples is essential for safely deploying machine learning models in the real world. One popular approach for physical-world attacks is to adopt the "sticker-pasting" strategy, which however suffers from some limitations, including difficulties in access to the target or printing by valid colors. A new type of non-invasive attacks emerged recently, which attempt to cast perturbation onto the target by optics based tools, such as laser beam and projector. However, the added optical patterns are artificial but not natural. Thus, they are still conspicuous and attention-grabbed, and can be easily noticed by humans. In this paper, we study a new type of optical adversarial examples, in which the perturbations are generated by a very common natural phenomenon, shadow, to achieve naturalistic and stealthy physical-world adversarial attack under the black-box setting. We extensively evaluate the effectiveness of this new attack on both simulated and real-world environments. Experimental results on traffic sign recognition demonstrate that our algorithm can generate adversarial examples effectively, reaching 98.23% and 90.47% success rates on LISA and GTSRB test sets respectively, while continuously misleading a moving camera over 95% of the time in real-world scenarios. We also offer discussions about the limitations and the defense mechanism of this attack.
Transfer Learning as an Essential Tool for Digital Twins in Renewable Energy Systems
Mar 09, 2022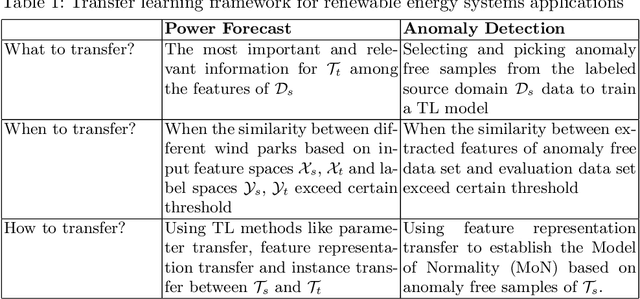
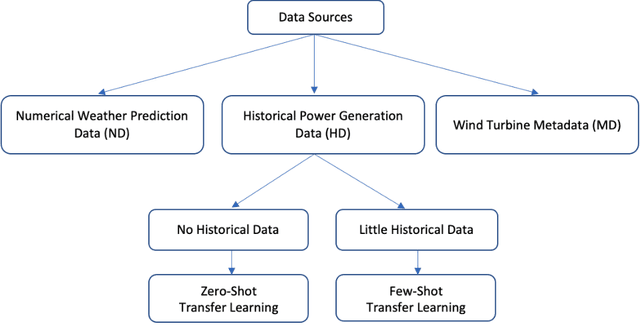
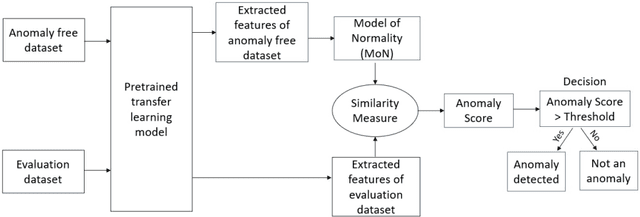
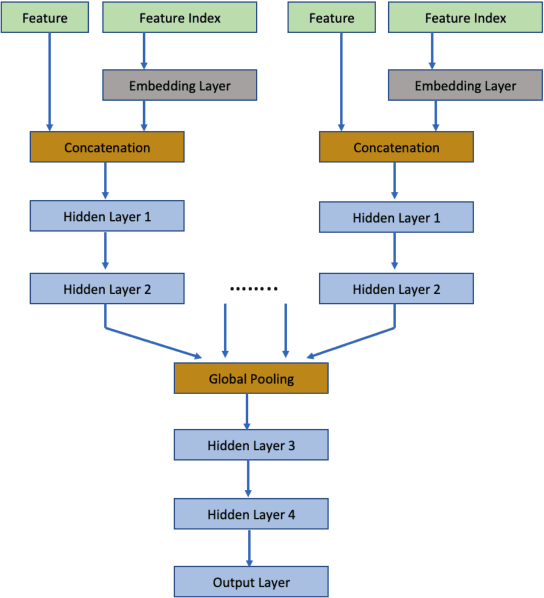
Transfer learning (TL), the next frontier in machine learning (ML), has gained much popularity in recent years, due to the various challenges faced in ML, like the requirement of vast amounts of training data, expensive and time-consuming labelling processes for data samples, and long training duration for models. TL is useful in tackling these problems, as it focuses on transferring knowledge from previously solved tasks to new tasks. Digital twins and other intelligent systems need to utilise TL to use the previously gained knowledge and solve new tasks in a more self-reliant way, and to incrementally increase their knowledge base. Therefore, in this article, the critical challenges in power forecasting and anomaly detection in the context of renewable energy systems are identified, and a potential TL framework to meet these challenges is proposed. This article also proposes a feature embedding approach to handle the missing sensors data. The proposed TL methods help to make a system more autonomous in the context of organic computing.
Pulses with Minimum Residual Intersymbol Interference for Faster than Nyquist Signaling
Mar 14, 2022
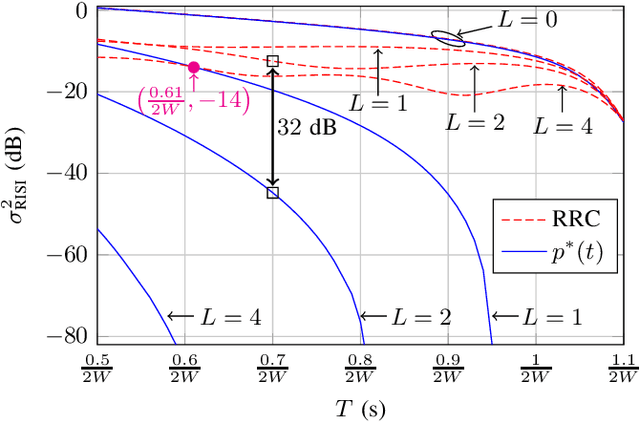
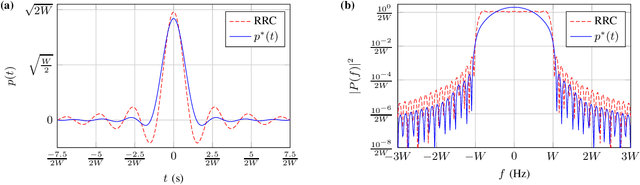
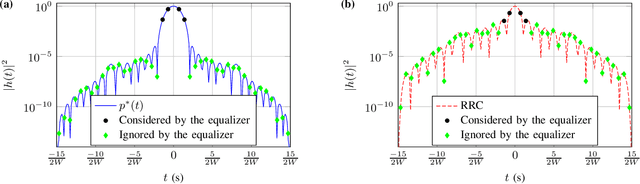
Faster than Nyquist signaling increases the spectral efficiency of pulse amplitude modulation by accepting intersymbol interference, where an equalizer is needed at the receiver. Since the complexity of an optimal equalizer increases exponentially with the number of the interfering symbols, practical truncated equalizers assume shorter memory. The power of the resulting residual interference depends on the transmit filter and limits the performance of truncated equalizers. In this paper, we use numerical optimizations and the prolate spheroidal wave functions to find optimal time-limited pulses that achieve minimum residual interference. Compared to root raised cosine pulses, the new pulses decrease the residual interference by an order of magnitude, for example, a decrease by 32 dB is achieved for an equalizer that considers four interfering symbols at 57% faster transmissions. As a proof of concept, for the 57% faster transmissions of binary symbols, we showed that using the new pulse with a 4-state equalizer has better bit error rate performance compared to using a root raised cosine pulse with a 128-state equalizer.
Analysis and Adaptation of YOLOv4 for Object Detection in Aerial Images
Mar 18, 2022
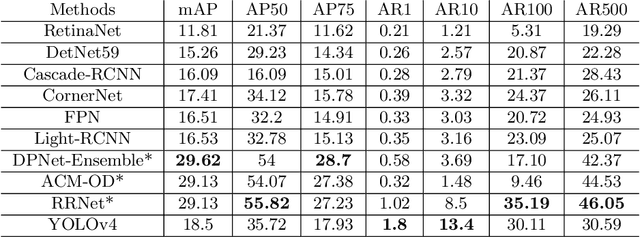
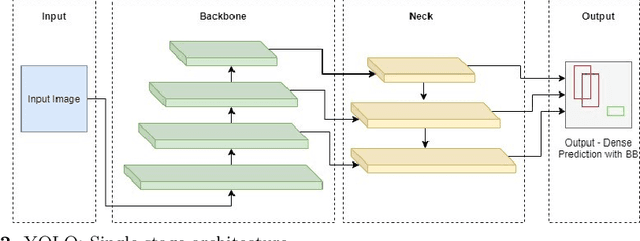
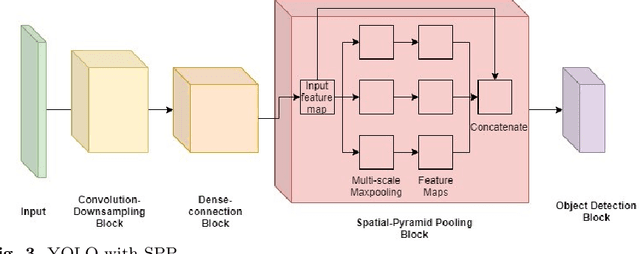
The recent and rapid growth in Unmanned Aerial Vehicles (UAVs) deployment for various computer vision tasks has paved the path for numerous opportunities to make them more effective and valuable. Object detection in aerial images is challenging due to variations in appearance, pose, and scale. Autonomous aerial flight systems with their inherited limited memory and computational power demand accurate and computationally efficient detection algorithms for real-time applications. Our work shows the adaptation of the popular YOLOv4 framework for predicting the objects and their locations in aerial images with high accuracy and inference speed. We utilized transfer learning for faster convergence of the model on the VisDrone DET aerial object detection dataset. The trained model resulted in a mean average precision (mAP) of 45.64% with an inference speed reaching 8.7 FPS on the Tesla K80 GPU and was highly accurate in detecting truncated and occluded objects. We experimentally evaluated the impact of varying network resolution sizes and training epochs on the performance. A comparative study with several contemporary aerial object detectors proved that YOLOv4 performed better, implying a more suitable detection algorithm to incorporate on aerial platforms.
Real-Time Glaucoma Detection from Digital Fundus Images using Self-ONNs
Sep 28, 2021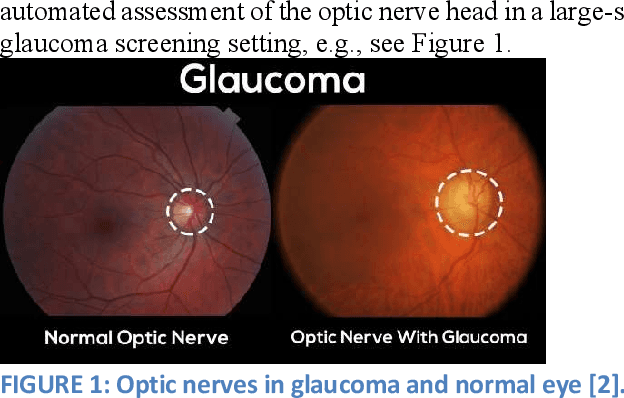
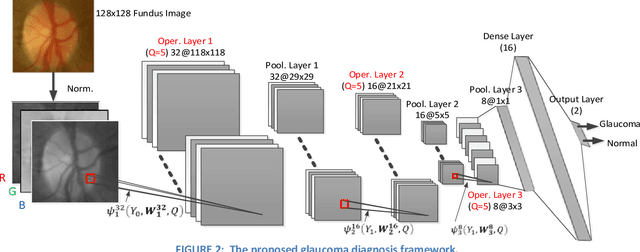
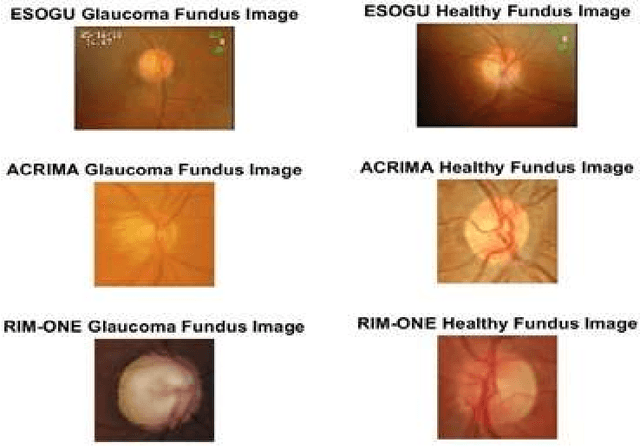

Glaucoma leads to permanent vision disability by damaging the optical nerve that transmits visual images to the brain. The fact that glaucoma does not show any symptoms as it progresses and cannot be stopped at the later stages, makes it critical to be diagnosed in its early stages. Although various deep learning models have been applied for detecting glaucoma from digital fundus images, due to the scarcity of labeled data, their generalization performance was limited along with high computational complexity and special hardware requirements. In this study, compact Self-Organized Operational Neural Networks (Self- ONNs) are proposed for early detection of glaucoma in fundus images and their performance is compared against the conventional (deep) Convolutional Neural Networks (CNNs) over three benchmark datasets: ACRIMA, RIM-ONE, and ESOGU. The experimental results demonstrate that Self-ONNs not only achieve superior detection performance but can also significantly reduce the computational complexity making it a potentially suitable network model for biomedical datasets especially when the data is scarce.
Can Deep Neural Networks be Converted to Ultra Low-Latency Spiking Neural Networks?
Dec 22, 2021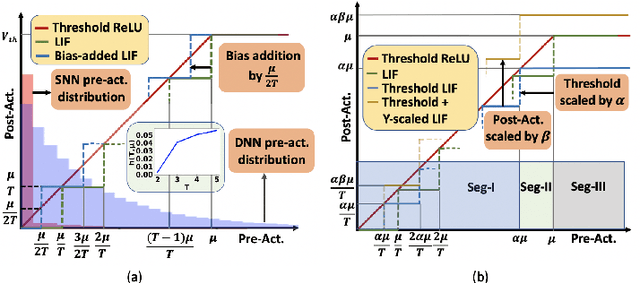
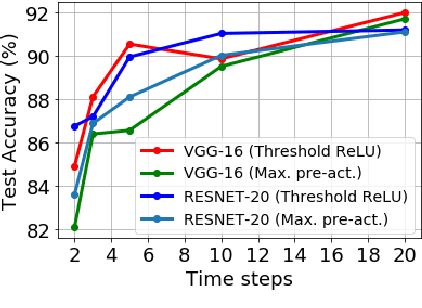

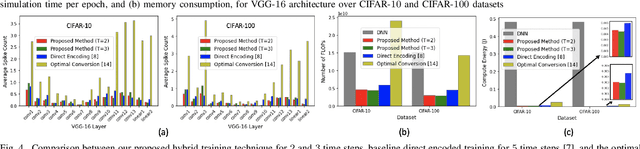
Spiking neural networks (SNNs), that operate via binary spikes distributed over time, have emerged as a promising energy efficient ML paradigm for resource-constrained devices. However, the current state-of-the-art (SOTA) SNNs require multiple time steps for acceptable inference accuracy, increasing spiking activity and, consequently, energy consumption. SOTA training strategies for SNNs involve conversion from a non-spiking deep neural network (DNN). In this paper, we determine that SOTA conversion strategies cannot yield ultra low latency because they incorrectly assume that the DNN and SNN pre-activation values are uniformly distributed. We propose a new training algorithm that accurately captures these distributions, minimizing the error between the DNN and converted SNN. The resulting SNNs have ultra low latency and high activation sparsity, yielding significant improvements in compute efficiency. In particular, we evaluate our framework on image recognition tasks from CIFAR-10 and CIFAR-100 datasets on several VGG and ResNet architectures. We obtain top-1 accuracy of 64.19% with only 2 time steps on the CIFAR-100 dataset with ~159.2x lower compute energy compared to an iso-architecture standard DNN. Compared to other SOTA SNN models, our models perform inference 2.5-8x faster (i.e., with fewer time steps).