 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fuzzy temporal convolutional neural networks in P300-based Brain-computer interface for smart home interaction
Apr 09, 2022
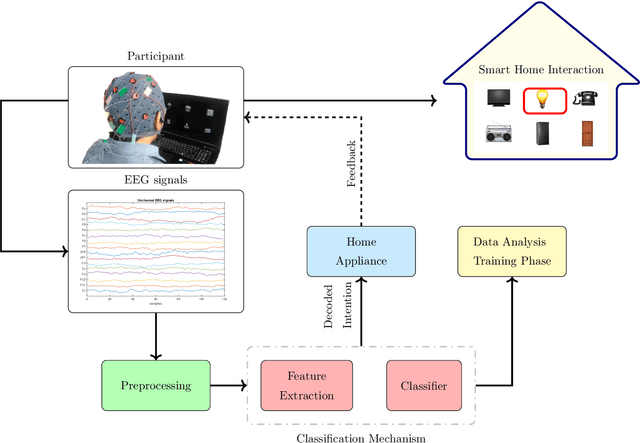
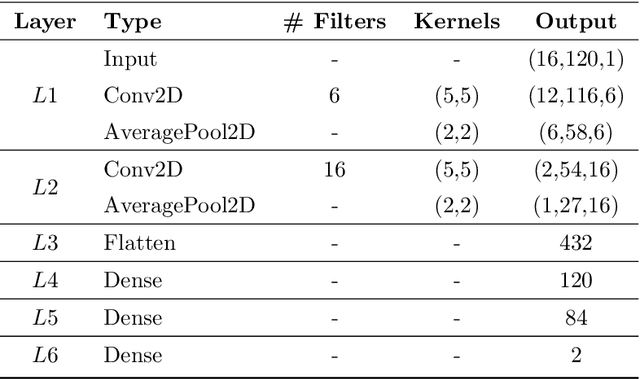
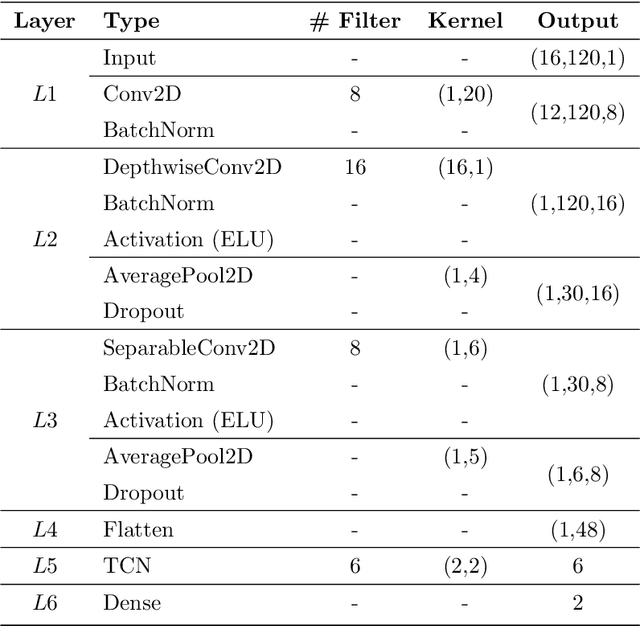

The processing and classification of electroencephalographic signals (EEG) are increasingly performed using deep learning frameworks, such as convolutional neural networks (CNNs), to generate abstract features from brain data, automatically paving the way for remarkable classification prowess. However, EEG patterns exhibit high variability across time and uncertainty due to noise. It is a significant problem to be addressed in P300-based Brain Computer Interface (BCI) for smart home interaction. It operates in a non-optimal natural environment where added noise is often present. In this work, we propose a sequential unification of temporal convolutional networks (TCNs) modified to EEG signals, LSTM cells, with a fuzzy neural block (FNB), which we called EEG-TCFNet. Fuzzy components may enable a higher tolerance to noisy conditions. We applied three different architectures comparing the effect of using block FNB to classify a P300 wave to build a BCI for smart home interaction with healthy and post-stroke individuals. Our results reported a maximum classification accuracy of 98.6% and 74.3% using the proposed method of EEG-TCFNet in subject-dependent strategy and subject-independent strategy, respectively. Overall, FNB usage in all three CNN topologies outperformed those without FNB. In addition, we compared the addition of FNB to other state-of-the-art methods and obtained higher classification accuracies on account of the integration with FNB. The remarkable performance of the proposed model, EEG-TCFNet, and the general integration of fuzzy units to other classifiers would pave the way for enhanced P300-based BCIs for smart home interaction within natural settings.
An Audit of Misinformation Filter Bubbles on YouTube: Bubble Bursting and Recent Behavior Changes
Mar 25, 2022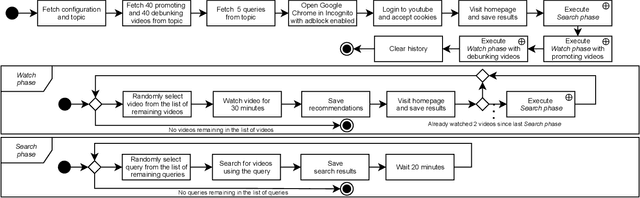


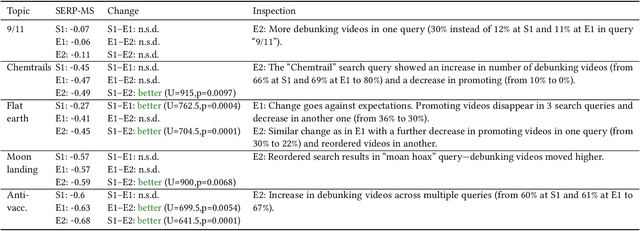
The negative effects of misinformation filter bubbles in adaptive systems have been known to researchers for some time. Several studies investigated, most prominently on YouTube, how fast a user can get into a misinformation filter bubble simply by selecting wrong choices from the items offered. Yet, no studies so far have investigated what it takes to burst the bubble, i.e., revert the bubble enclosure. We present a study in which pre-programmed agents (acting as YouTube users) delve into misinformation filter bubbles by watching misinformation promoting content (for various topics). Then, by watching misinformation debunking content, the agents try to burst the bubbles and reach more balanced recommendation mixes. We recorded the search results and recommendations, which the agents encountered, and analyzed them for the presence of misinformation. Our key finding is that bursting of a filter bubble is possible, albeit it manifests differently from topic to topic. Moreover, we observe that filter bubbles do not truly appear in some situations. We also draw a direct comparison with a previous study. Sadly, we did not find much improvements in misinformation occurrences, despite recent pledges by YouTube.
* RecSys '21: Fifteenth ACM Conference on Recommender System
Towards Everyday Virtual Reality through Eye Tracking
Mar 29, 2022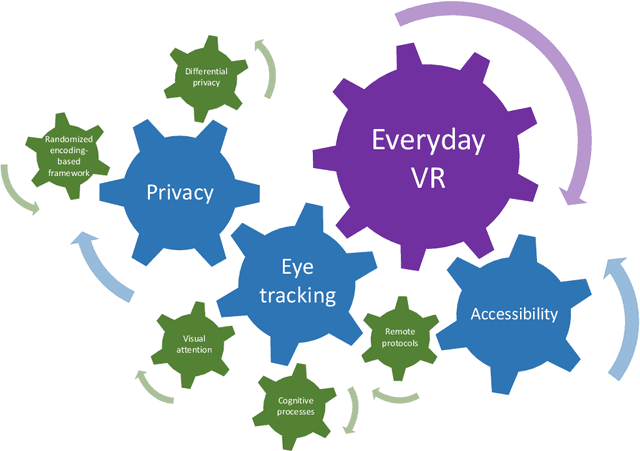

With developments in computer graphics, hardware technology, perception engineering, and human-computer interaction, virtual reality and virtual environments are becoming more integrated into our daily lives. Head-mounted displays, however, are still not used as frequently as other mobile devices such as smart phones and watches. With increased usage of this technology and the acclimation of humans to virtual application scenarios, it is possible that in the near future an everyday virtual reality paradigm will be realized. When considering the marriage of everyday virtual reality and head-mounted displays, eye tracking is an emerging technology that helps to assess human behaviors in a real time and non-intrusive way. Still, multiple aspects need to be researched before these technologies become widely available in daily life. Firstly, attention and cognition models in everyday scenarios should be thoroughly understood. Secondly, as eyes are related to visual biometrics, privacy preserving methodologies are necessary. Lastly, instead of studies or applications utilizing limited human participants with relatively homogeneous characteristics, protocols and use-cases for making such technology more accessible should be essential. In this work, taking the aforementioned points into account, a significant scientific push towards everyday virtual reality has been completed with three main research contributions.
Using Multi-scale SwinTransformer-HTC with Data augmentation in CoNIC Challenge
Mar 02, 2022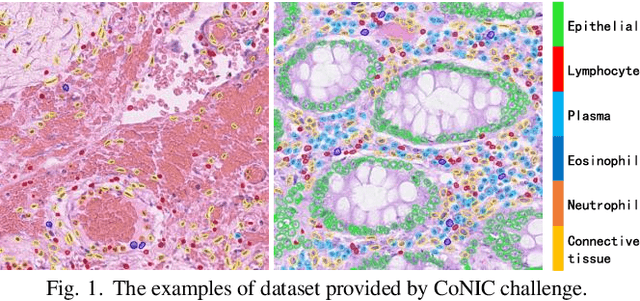
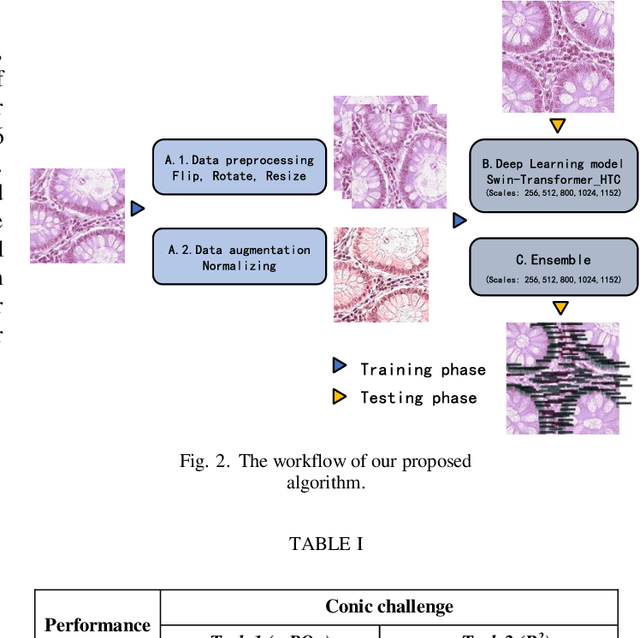
Colorectal cancer is one of the most common cancers worldwide, so early pathological examination is very important. However, it is time-consuming and labor-intensive to identify the number and type of cells on H&E images in clinical. Therefore, automatic segmentation and classification task and counting the cellular composition of H&E images from pathological sections is proposed by CoNIC Challenge 2022. We proposed a multi-scale Swin transformer with HTC for this challenge, and also applied the known normalization methods to generate more augmentation data. Finally, our strategy showed that the multi-scale played a crucial role to identify different scale features and the augmentation arose the recognition of model.
An Independently Learnable Hierarchical Model for Bilateral Control-Based Imitation Learning Applications
Mar 16, 2022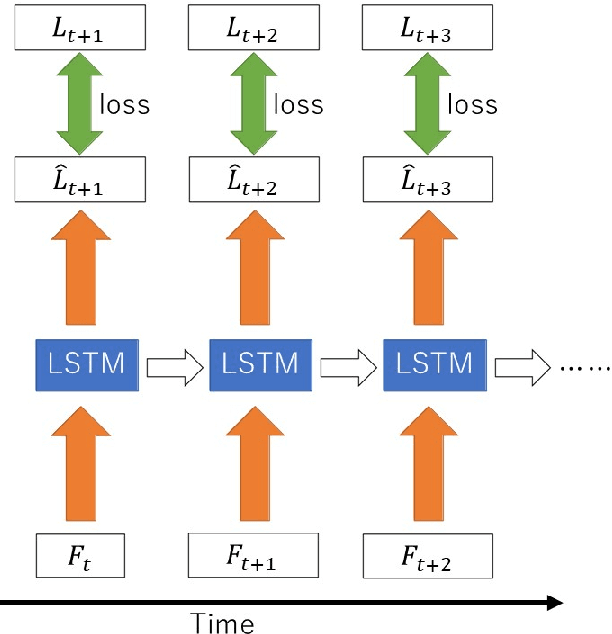

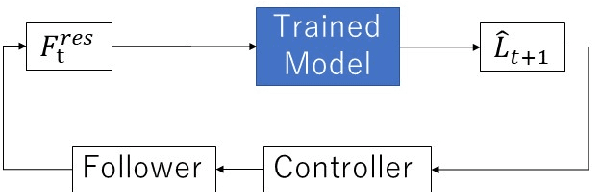

Recently, motion generation by machine learning has been actively researched to automate various tasks. Imitation learning is one such method that learns motions from data collected in advance. However, executing long-term tasks remains challenging. Therefore, a novel framework for imitation learning is proposed to solve this problem. The proposed framework comprises upper and lower layers, where the upper layer model, whose timescale is long, and lower layer model, whose timescale is short, can be independently trained. In this model, the upper layer learns long-term task planning, and the lower layer learns motion primitives. The proposed method was experimentally compared to hierarchical RNN-based methods to validate its effectiveness. Consequently, the proposed method showed a success rate equal to or greater than that of conventional methods. In addition, the proposed method required less than 1/20 of the training time compared to conventional methods. Moreover, it succeeded in executing unlearned tasks by reusing the trained lower layer.
Intelligent control of a single-link flexible manipulator using sliding modes and artificial neural networks
Mar 21, 2022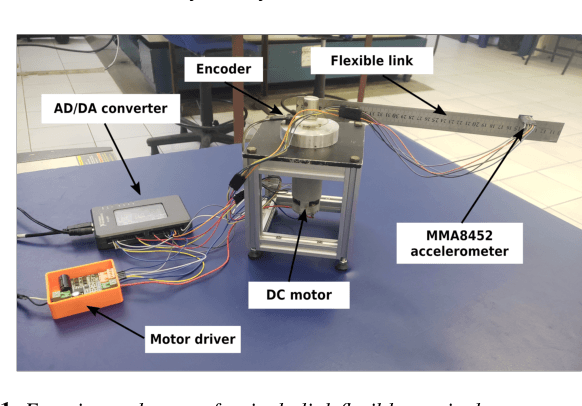
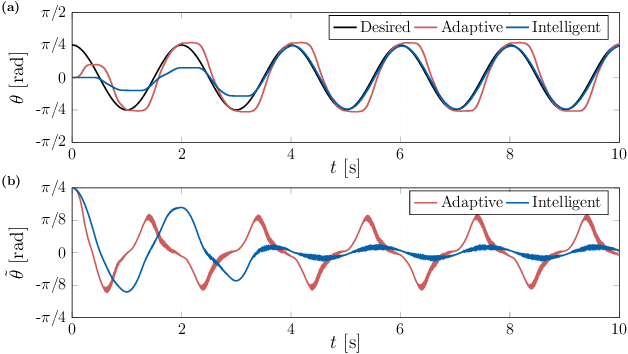
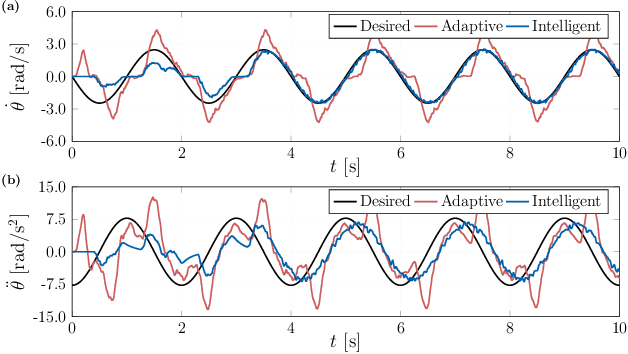
This letter presents a new intelligent control scheme for the accurate trajectory tracking of flexible link manipulators. The proposed approach is mainly based on a sliding mode controller for underactuated systems with an embedded artificial neural network to deal with modeling inaccuracies. The adopted neural network only needs a single input and one hidden layer, which drastically reduces the computational complexity of the control law and allows its implementation in low-power microcontrollers. Online learning, rather than supervised offline training, is chosen to allow the weights of the neural network to be adjusted in real time during the tracking. Therefore, the resulting controller is able to cope with the underactuating issues and to adapt itself by learning from experience, which grants the capacity to deal with plant dynamics properly. The boundedness and convergence properties of the tracking error are proved by evoking Barbalat's lemma in a Lyapunov-like stability analysis. Experimental results obtained with a small single-link flexible manipulator show the efficacy of the proposed control scheme, even in the presence of a high level of uncertainty and noisy signals.
* 4 pages, 5 figures
NL-FCOS: Improving FCOS through Non-Local Modules for Object Detection
Mar 29, 2022


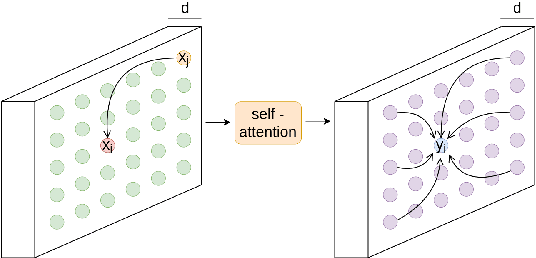
During the last years, we have seen significant advances in the object detection task, mainly due to the outperforming results of convolutional neural networks. In this vein, anchor-based models have achieved the best results. However, these models require prior information about the aspect and scales of target objects, needing more hyperparameters to fit. In addition, using anchors to fit bounding boxes seems far from how our visual system does the same visual task. Instead, our visual system uses the interactions of different scene parts to semantically identify objects, called perceptual grouping. An object detection methodology closer to the natural model is anchor-free detection, where models like FCOS or Centernet have shown competitive results, but these have not yet exploited the concept of perceptual grouping. Therefore, to increase the effectiveness of anchor-free models keeping the inference time low, we propose to add non-local attention (NL modules) modules to boost the feature map of the underlying backbone. NL modules implement the perceptual grouping mechanism, allowing receptive fields to cooperate in visual representation learning. We show that non-local modules combined with an FCOS head (NL-FCOS) are practical and efficient. Thus, we establish state-of-the-art performance in clothing detection and handwritten amount recognition problems.
In-Context Learning for Few-Shot Dialogue State Tracking
Mar 16, 2022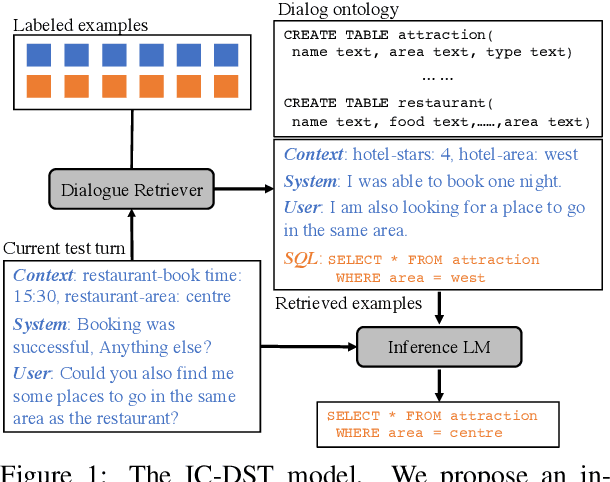
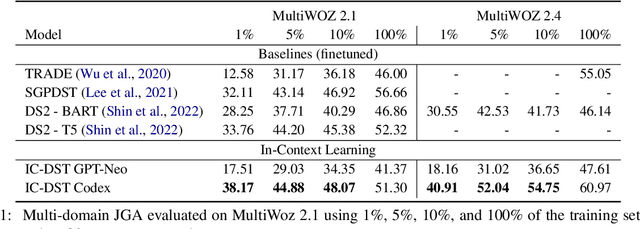
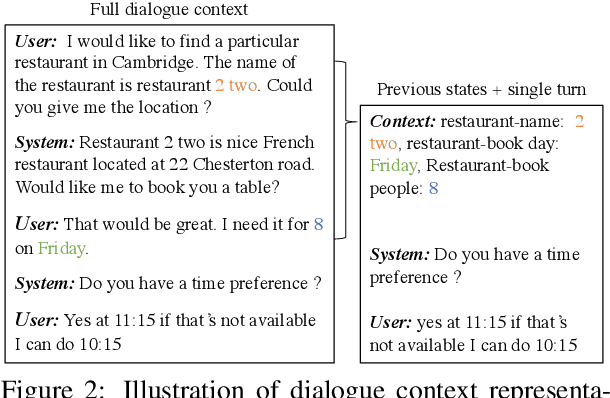
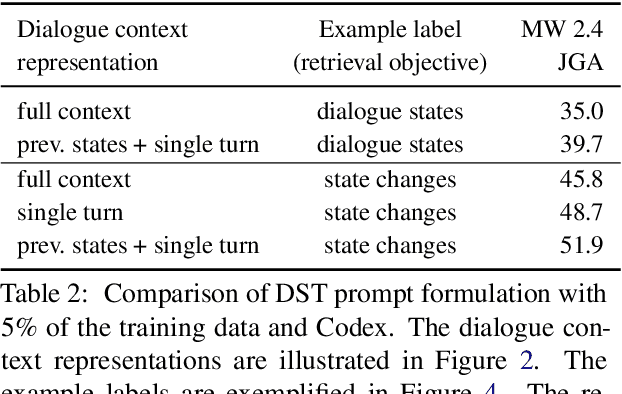
Collecting and annotating task-oriented dialogues is time-consuming and costly. Thus, few-shot learning for dialogue tasks presents an exciting opportunity. In this work, we propose an in-context (IC) learning framework for few-shot dialogue state tracking (DST), where a large pre-trained language model (LM) takes a test instance and a few annotated examples as input, and directly decodes the dialogue states without any parameter updates. This makes the LM more flexible and scalable compared to prior few-shot DST work when adapting to new domains and scenarios. We study ways to formulate dialogue context into prompts for LMs and propose an efficient approach to retrieve dialogues as exemplars given a test instance and a selection pool of few-shot examples. To better leverage the pre-trained LMs, we also reformulate DST into a text-to-SQL problem. Empirical results on MultiWOZ 2.1 and 2.4 show that our method IC-DST outperforms previous fine-tuned state-of-the-art models in few-shot settings.
On-Device Learning: A Neural Network Based Field-Trainable Edge AI
Mar 02, 2022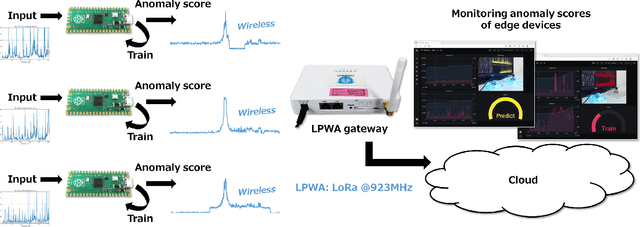
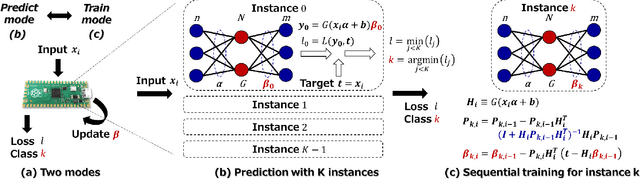
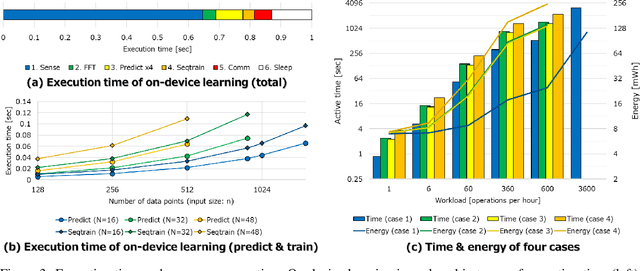
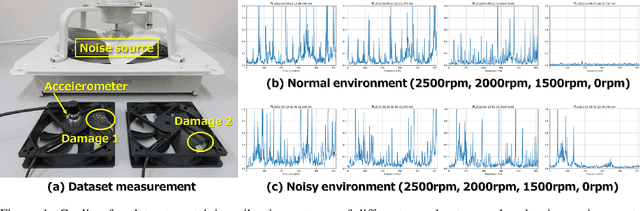
In real-world edge AI applications, their accuracy is often affected by various environmental factors, such as noises, location/calibration of sensors, and time-related changes. This article introduces a neural network based on-device learning approach to address this issue without going deep. Our approach is quite different from de facto backpropagation based training but tailored for low-end edge devices. This article introduces its algorithm and implementation on a wireless sensor node consisting of Raspberry Pi Pico and low-power wireless module. Experiments using vibration patterns of rotating machines demonstrate that retraining by the on-device learning significantly improves an anomaly detection accuracy at a noisy environment while saving computation and communication costs for low power.
Data-driven Influence Based Clustering of Dynamical Systems
Apr 05, 2022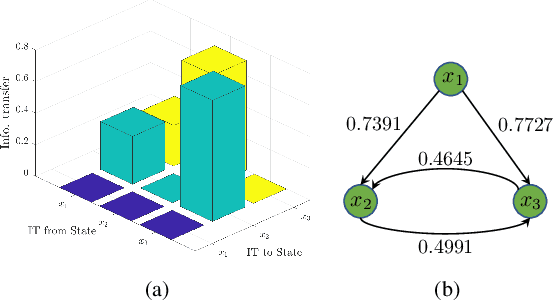
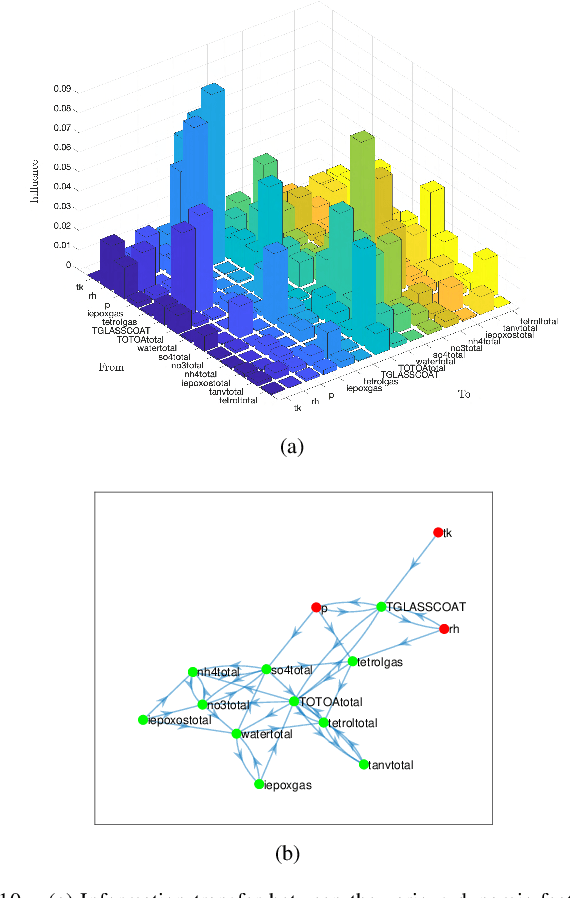
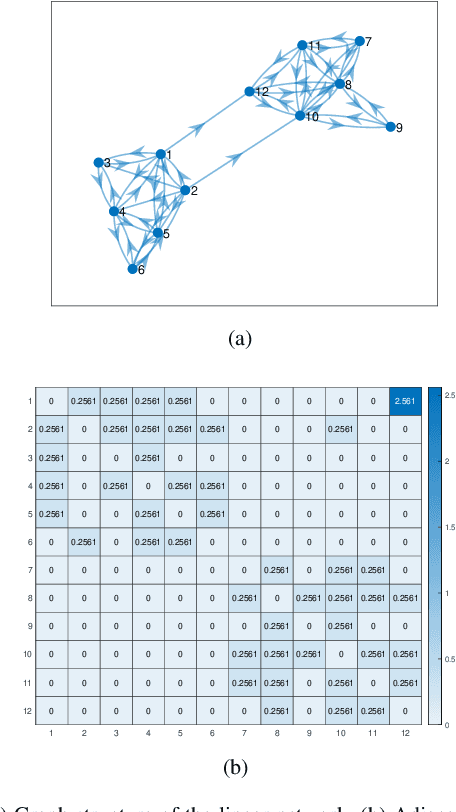
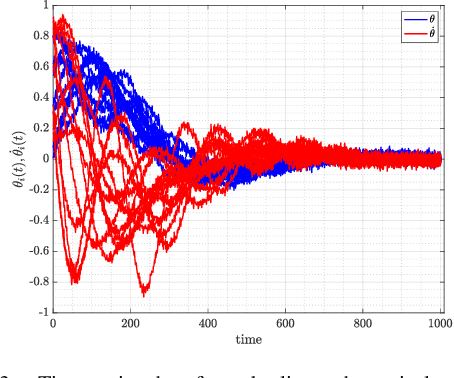
Community detection is a challenging and relevant problem in various disciplines of science and engineering like power systems, gene-regulatory networks, social networks, financial networks, astronomy etc. Furthermore, in many of these applications the underlying system is dynamical in nature and because of the complexity of the systems involved, deriving a mathematical model which can be used for clustering and community detection, is often impossible. Moreover, while clustering dynamical systems, it is imperative that the dynamical nature of the underlying system is taken into account. In this paper, we propose a novel approach for clustering dynamical systems purely from time-series data which inherently takes into account the dynamical evolution of the underlying system. In particular, we define a \emph{distance/similarity} measure between the states of the system which is a function of the influence that the states have on each other, and use the proposed measure for clustering of the dynamical system. For data-driven computation we leverage the Koopman operator framework which takes into account the nonlinearities (if present) of the underlying system, thus making the proposed framework applicable to a wide range of application areas. We illustrate the efficacy of the proposed approach by clustering three different dynamical systems, namely, a linear system, which acts like a proof of concept, the highly non-linear IEEE 39 bus transmission network and dynamic variables obtained from atmospheric data over the Amazon rain forest.