 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Spatio-Temporal Joint Graph Convolutional Networks for Traffic Forecasting
Dec 02, 2021
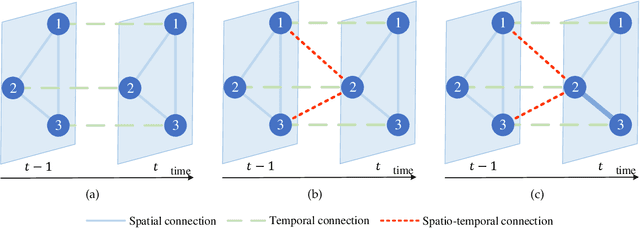
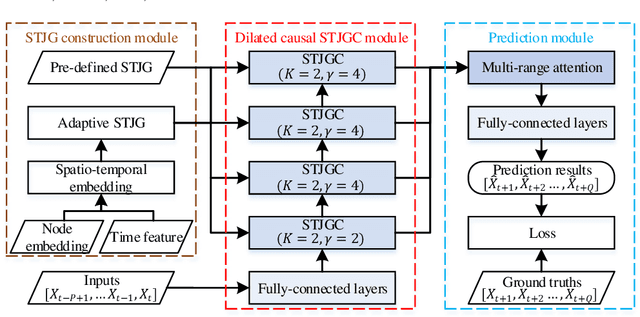
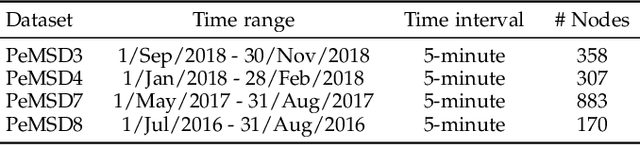
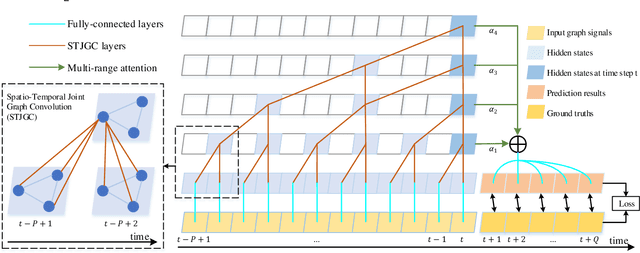
Recent studies focus on formulating the traffic forecasting as a spatio-temporal graph modeling problem. They typically construct a static spatial graph at each time step and then connect each node with itself between adjacent time steps to construct the spatio-temporal graph. In such a graph, the correlations between different nodes at different time steps are not explicitly reflected, which may restrict the learning ability of graph neural networks. Meanwhile, those models ignore the dynamic spatio-temporal correlations among nodes as they use the same adjacency matrix at different time steps. To overcome these limitations, we propose a Spatio-Temporal Joint Graph Convolutional Networks (STJGCN) for traffic forecasting over several time steps ahead on a road network. Specifically, we construct both pre-defined and adaptive spatio-temporal joint graphs (STJGs) between any two time steps, which represent comprehensive and dynamic spatio-temporal correlations. We further design dilated causal spatio-temporal joint graph convolution layers on STJG to capture the spatio-temporal dependencies from distinct perspectives with multiple ranges. A multi-range attention mechanism is proposed to aggregate the information of different ranges. Experiments on four public traffic datasets demonstrate that STJGCN is computationally efficient and outperforms 11 state-of-the-art baseline methods.
A Computational Architecture for Machine Consciousness and Artificial Superintelligence: Updating Working Memory Iteratively
Mar 29, 2022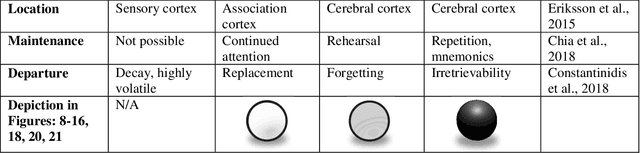
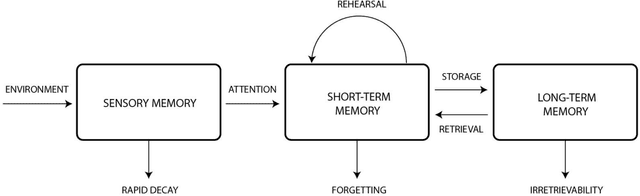

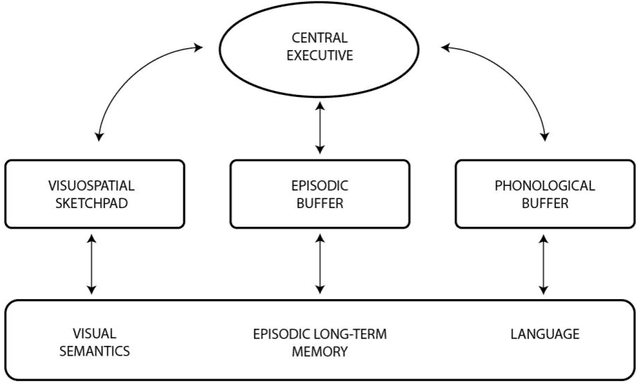
This theoretical article examines how to construct human-like working memory and thought processes within a computer. There should be two working memory stores, one analogous to sustained firing in association cortex, and one analogous to synaptic potentiation in the cerebral cortex. These stores must be constantly updated with new representations that arise from either environmental stimulation or internal processing. They should be updated continuously, and in an iterative fashion, meaning that, in the next state, some items in the set of coactive items should always be retained. Thus, the set of concepts coactive in working memory will evolve gradually and incrementally over time. This makes each state is a revised iteration of the preceding state and causes successive states to overlap and blend with respect to the set of representations they contain. As new representations are added and old ones are subtracted, some remain active for several seconds over the course of these changes. This persistent activity, similar to that used in artificial recurrent neural networks, is used to spread activation energy throughout the global workspace to search for the next associative update. The result is a chain of associatively linked intermediate states that are capable of advancing toward a solution or goal. Iterative updating is conceptualized here as an information processing strategy, a computational and neurophysiological determinant of the stream of thought, and an algorithm for designing and programming artificial intelligence.
Distributed Processing for Encoding and Decoding of Binary LDPC codes using MPI
Jan 12, 2022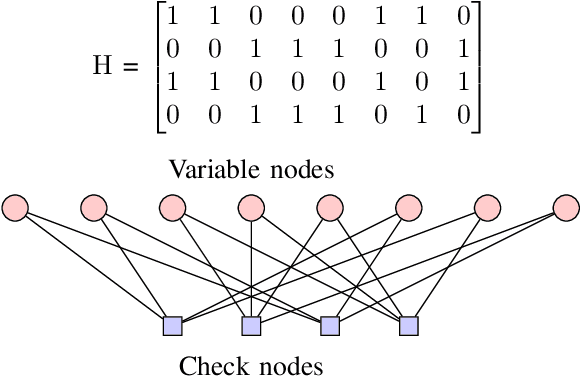
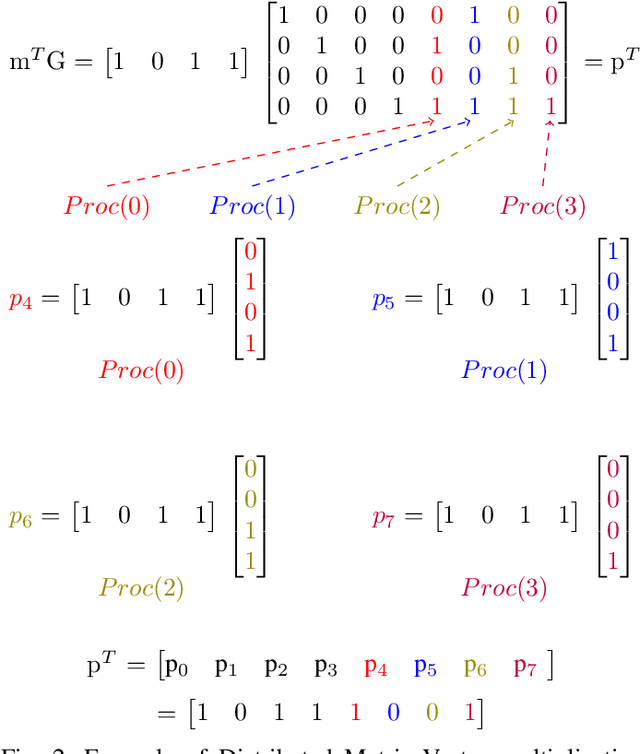
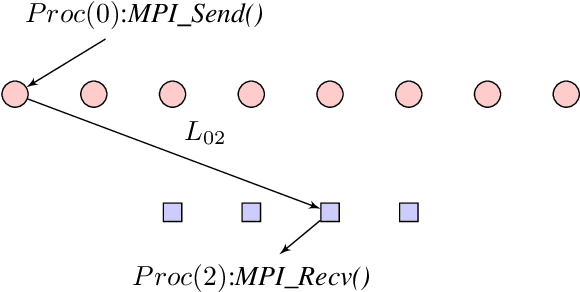
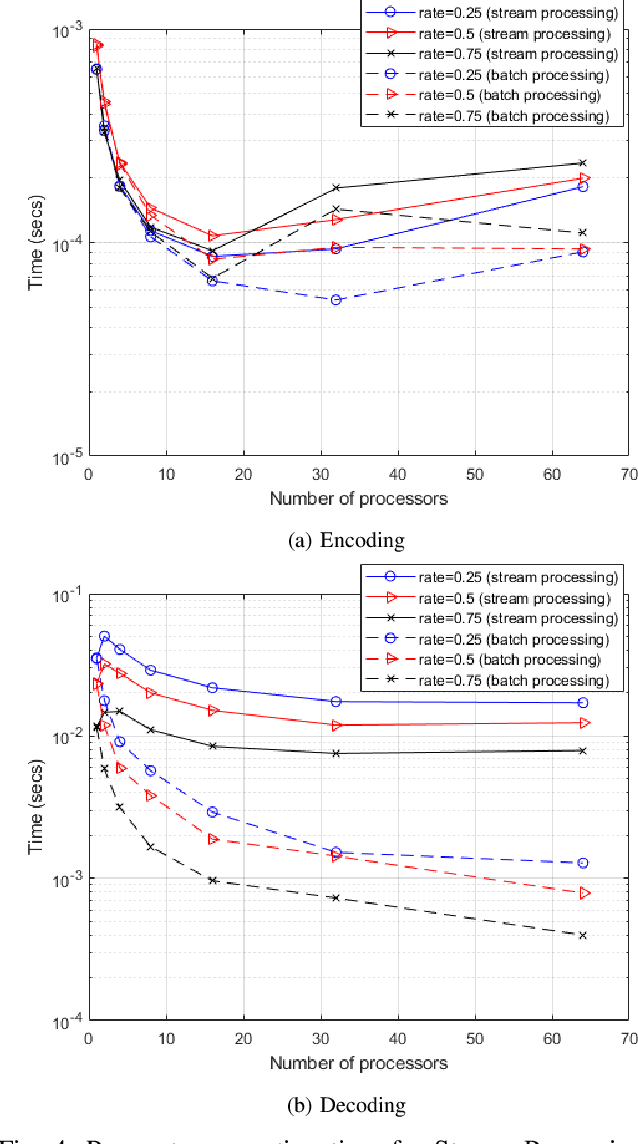
Low Density Parity Check (LDPC) codes are linear error correcting codes used in communication systems for Forward Error Correction (FEC). But, intensive computation is required for encoding and decoding of LDPC codes, making it difficult for practical usage in general purpose software based signal processing systems. In order to accelerate the encoding and decoding of LDPC codes, distributed processing over multiple multi-core CPUs using Message Passing Interface (MPI) is performed. Implementation is done using Stream Processing and Batch Processing mechanisms and the execution time for both implementations is compared w.r.t variation in number of CPUs and number of cores per CPU. Performance evaluation of distributed processing is shown by variation in execution time w.r.t. increase in number of processors (CPU cores).
Learning Semantic Ambiguities for Zero-Shot Learning
Jan 05, 2022

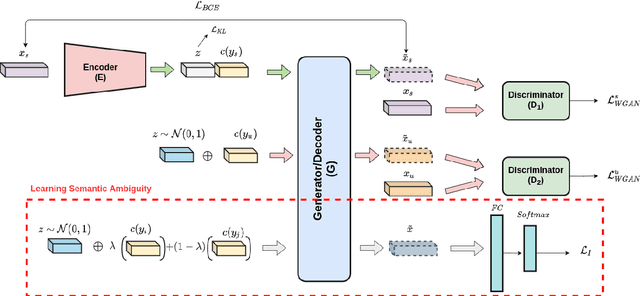
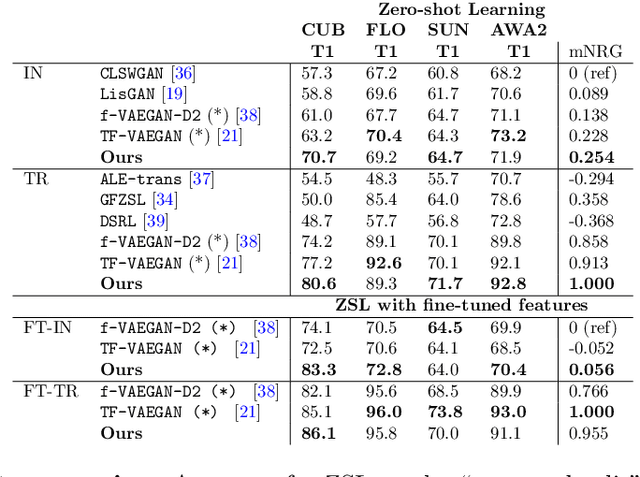
Zero-shot learning (ZSL) aims at recognizing classes for which no visual sample is available at training time. To address this issue, one can rely on a semantic description of each class. A typical ZSL model learns a mapping between the visual samples of seen classes and the corresponding semantic descriptions, in order to do the same on unseen classes at test time. State of the art approaches rely on generative models that synthesize visual features from the prototype of a class, such that a classifier can then be learned in a supervised manner. However, these approaches are usually biased towards seen classes whose visual instances are the only one that can be matched to a given class prototype. We propose a regularization method that can be applied to any conditional generative-based ZSL method, by leveraging only the semantic class prototypes. It learns to synthesize discriminative features for possible semantic description that are not available at training time, that is the unseen ones. The approach is evaluated for ZSL and GZSL on four datasets commonly used in the literature, either in inductive and transductive settings, with results on-par or above state of the art approaches.
A pipeline and comparative study of 12 machine learning models for text classification
Apr 04, 2022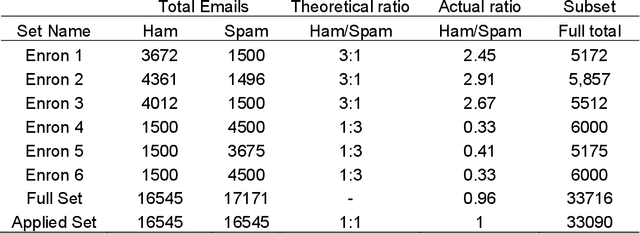
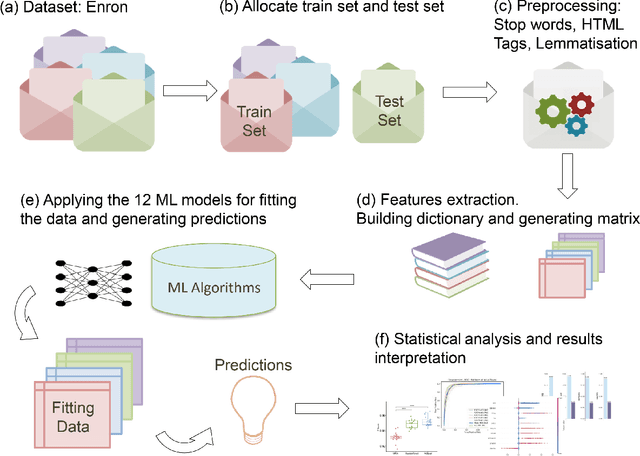
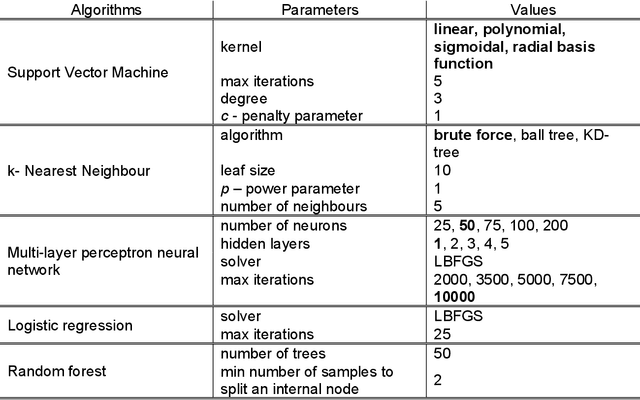
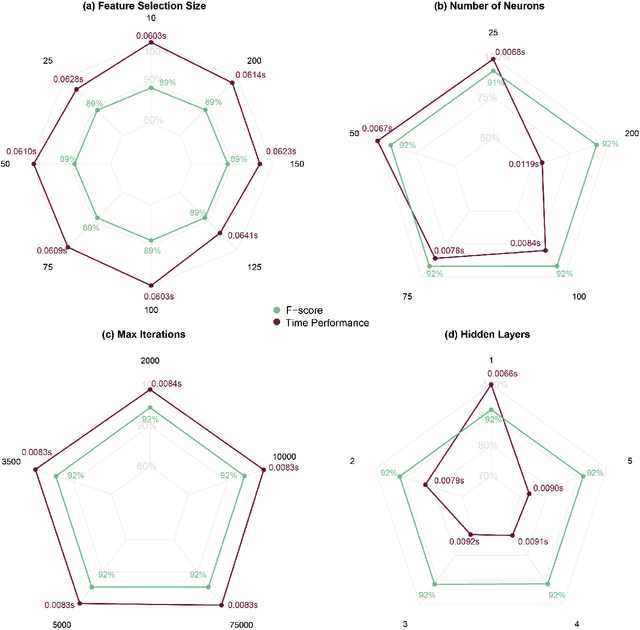
Text-based communication is highly favoured as a communication method, especially in business environments. As a result, it is often abused by sending malicious messages, e.g., spam emails, to deceive users into relaying personal information, including online accounts credentials or banking details. For this reason, many machine learning methods for text classification have been proposed and incorporated into the services of most email providers. However, optimising text classification algorithms and finding the right tradeoff on their aggressiveness is still a major research problem. We present an updated survey of 12 machine learning text classifiers applied to a public spam corpus. A new pipeline is proposed to optimise hyperparameter selection and improve the models' performance by applying specific methods (based on natural language processing) in the preprocessing stage. Our study aims to provide a new methodology to investigate and optimise the effect of different feature sizes and hyperparameters in machine learning classifiers that are widely used in text classification problems. The classifiers are tested and evaluated on different metrics including F-score (accuracy), precision, recall, and run time. By analysing all these aspects, we show how the proposed pipeline can be used to achieve a good accuracy towards spam filtering on the Enron dataset, a widely used public email corpus. Statistical tests and explainability techniques are applied to provide a robust analysis of the proposed pipeline and interpret the classification outcomes of the 12 machine learning models, also identifying words that drive the classification results. Our analysis shows that it is possible to identify an effective machine learning model to classify the Enron dataset with an F-score of 94%.
Embodied Active Domain Adaptation for Semantic Segmentation via Informative Path Planning
Mar 01, 2022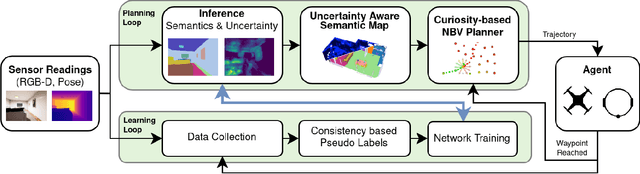
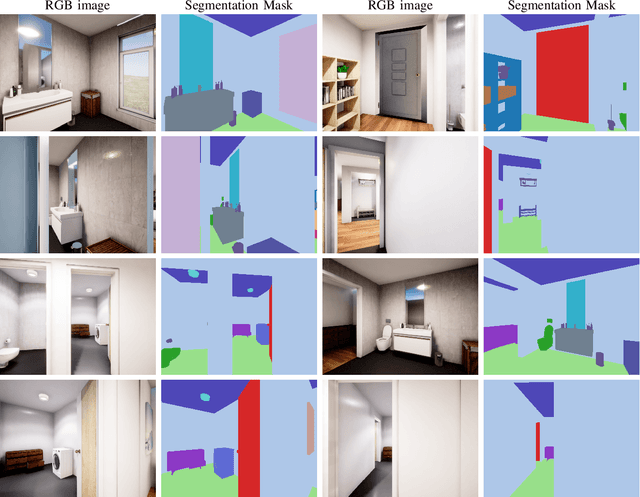


This work presents an embodied agent that can adapt its semantic segmentation network to new indoor environments in a fully autonomous way. Because semantic segmentation networks fail to generalize well to unseen environments, the agent collects images of the new environment which are then used for self-supervised domain adaptation. We formulate this as an informative path planning problem, and present a novel information gain that leverages uncertainty extracted from the semantic model to safely collect relevant data. As domain adaptation progresses, these uncertainties change over time and the rapid learning feedback of our system drives the agent to collect different data. Experiments show that our method adapts to new environments faster and with higher final performance compared to an exploration objective, and can successfully be deployed to real-world environments on physical robots.
Time-aware Large Kernel Convolutions
Feb 08, 2020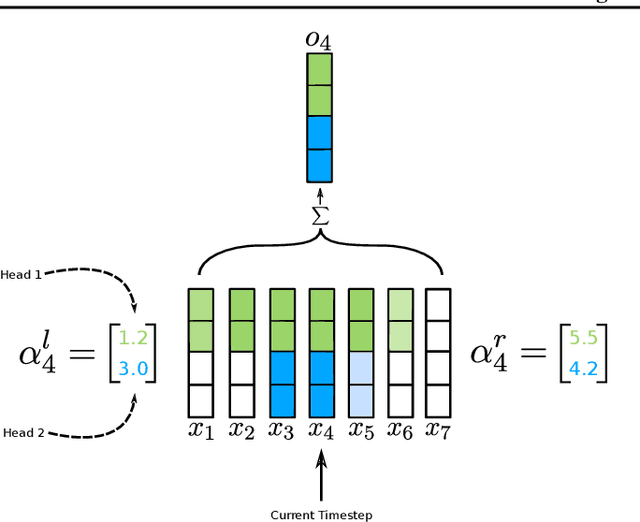

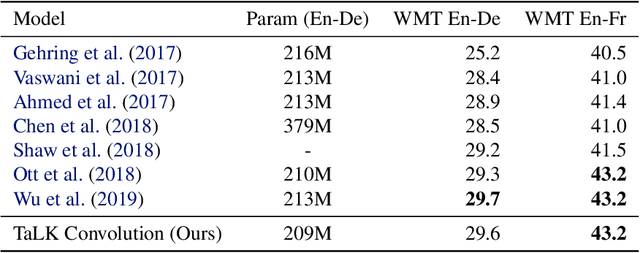
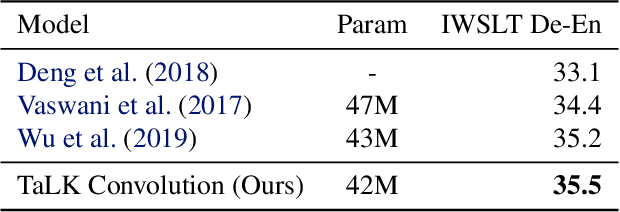
To date, most state-of-the-art sequence modelling architectures use attention to build generative models for language based tasks. Some of these models use all the available sequence tokens to generate an attention distribution which results in time complexity of $O(n^2)$. Alternatively, they utilize depthwise convolutions with softmax normalized kernels of size $k$ acting as a limited-window self-attention, resulting in time complexity of $O(k{\cdot}n)$. In this paper, we introduce Time-aware Large Kernel (TaLK) Convolutions, a novel adaptive convolution operation that learns to predict the size of a summation kernel instead of using the fixed-sized kernel matrix. This method yields a time complexity of $O(n)$, effectively making the sequence encoding process linear to the number of tokens. We evaluate the proposed method on large-scale standard machine translation and language modelling datasets and show that TaLK Convolutions constitute an efficient improvement over other attention/convolution based approaches.
Render-in-the-loop aerial robotics simulator: Case Study on Yield Estimation in Indoor Agriculture
Mar 01, 2022
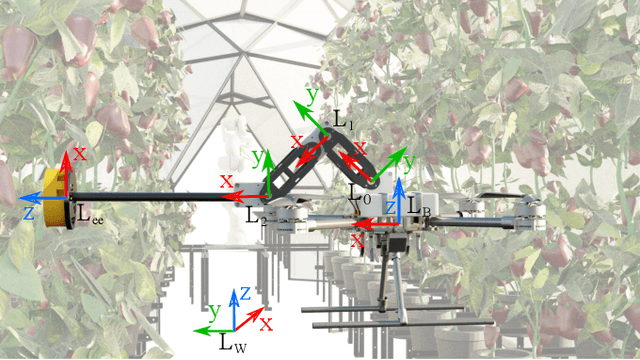

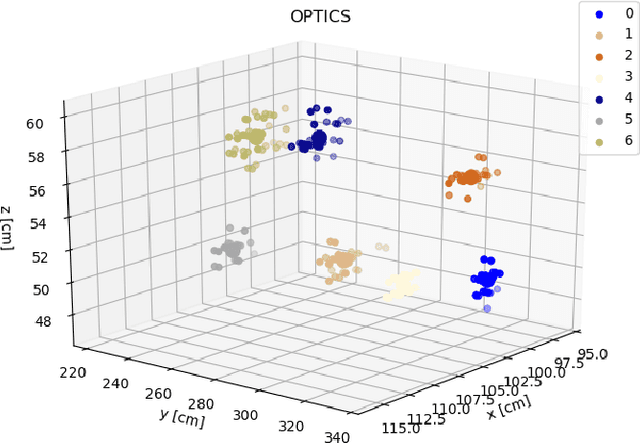
Inspired by recent promising results in sim-to-real transfer in deep learning we built a realistic simulation environment combining a Robot Operating System (ROS)-compatible physics simulator (Gazebo) with Cycles, the realistic production rendering engine from Blender. The proposed simulator pipeline allows us to simulate near-realistic RGB-D images. To showcase the capabilities of the simulator pipeline we propose a case study that focuses on indoor robotic farming. We developed a solution for sweet pepper yield estimation task. Our approach to yield estimation starts with aerial robotics control and trajectory planning, combined with deep learning-based pepper detection, and a clustering approach for counting fruit. The results of this case study show that we can combine real time dynamic simulation with near realistic rendering capabilities to simulate complex robotic systems.
NetRCA: An Effective Network Fault Cause Localization Algorithm
Mar 07, 2022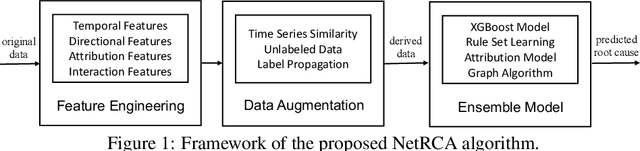
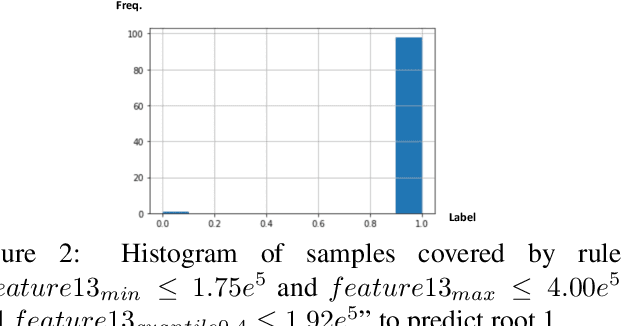
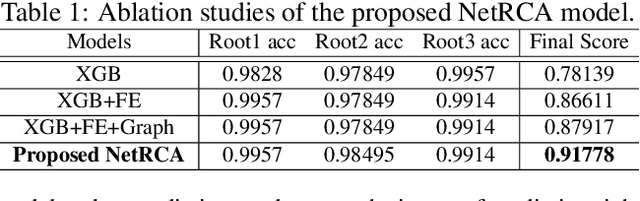
Localizing the root cause of network faults is crucial to network operation and maintenance. However, due to the complicated network architectures and wireless environments, as well as limited labeled data, accurately localizing the true root cause is challenging. In this paper, we propose a novel algorithm named NetRCA to deal with this problem. Firstly, we extract effective derived features from the original raw data by considering temporal, directional, attribution, and interaction characteristics. Secondly, we adopt multivariate time series similarity and label propagation to generate new training data from both labeled and unlabeled data to overcome the lack of labeled samples. Thirdly, we design an ensemble model which combines XGBoost, rule set learning, attribution model, and graph algorithm, to fully utilize all data information and enhance performance. Finally, experiments and analysis are conducted on the real-world dataset from ICASSP 2022 AIOps Challenge to demonstrate the superiority and effectiveness of our approach.
High Efficiency Pedestrian Crossing Prediction
Apr 04, 2022
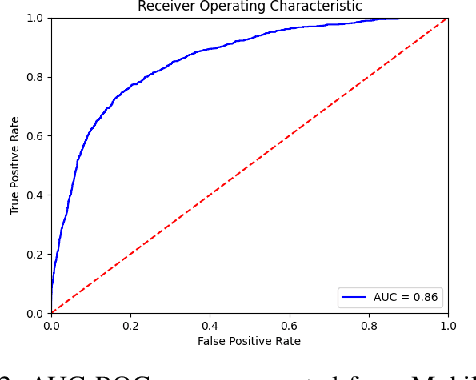
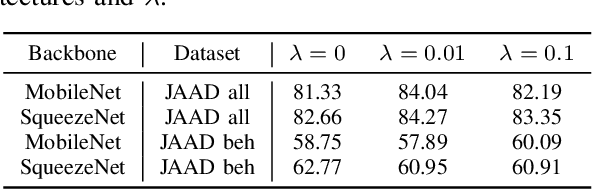

Predicting pedestrian crossing intention is an indispensable aspect of deploying advanced driving systems (ADS) or advanced driver-assistance systems (ADAS) to real life. State-of-the-art methods in predicting pedestrian crossing intention often rely on multiple streams of information as inputs, each of which requires massive computational resources and heavy network architectures to generate. However, such reliance limits the practical application of the systems. In this paper, driven the the real-world demands of pedestrian crossing intention prediction models with both high efficiency and accuracy, we introduce a network with only frames of pedestrians as the input. Every component in the introduced network is driven by the goal of light weight. Specifically, we reduce the multi-source input dependency and employ light neural networks that are tailored for mobile devices. These smaller neural networks can fit into computer memory and can be transmitted over a computer network more easily, thus making them more suitable for real-life deployment and real-time prediction. To compensate the removal of the multi-source input, we enhance the network effectiveness by adopting a multi-task learning training, named "side task learning", to include multiple auxiliary tasks to jointly learn the feature extractor for improved robustness. Each head handles a specific task that potentially shares knowledge with other heads. In the meantime, the feature extractor is shared across all tasks to ensure the sharing of basic knowledge across all layers. The light weight but high efficiency characteristics of our model endow it the potential of being deployed on vehicle-based systems. Experiments validate that our model consistently delivers outstanding performances.