 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Analysis and Adaptation of YOLOv4 for Object Detection in Aerial Images
Mar 18, 2022

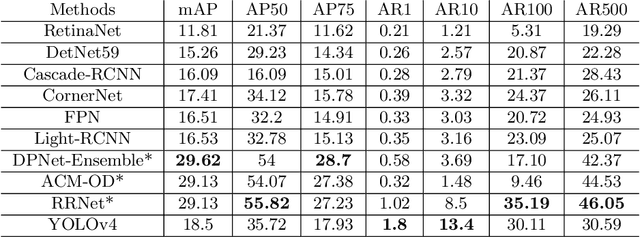
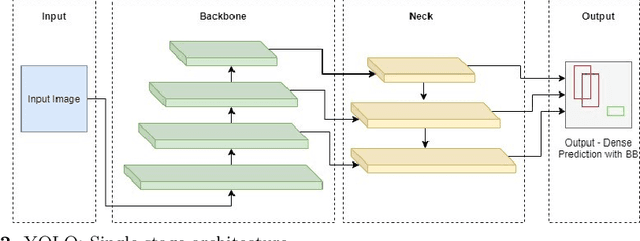
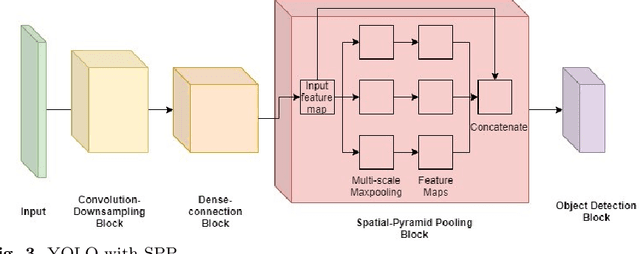
The recent and rapid growth in Unmanned Aerial Vehicles (UAVs) deployment for various computer vision tasks has paved the path for numerous opportunities to make them more effective and valuable. Object detection in aerial images is challenging due to variations in appearance, pose, and scale. Autonomous aerial flight systems with their inherited limited memory and computational power demand accurate and computationally efficient detection algorithms for real-time applications. Our work shows the adaptation of the popular YOLOv4 framework for predicting the objects and their locations in aerial images with high accuracy and inference speed. We utilized transfer learning for faster convergence of the model on the VisDrone DET aerial object detection dataset. The trained model resulted in a mean average precision (mAP) of 45.64% with an inference speed reaching 8.7 FPS on the Tesla K80 GPU and was highly accurate in detecting truncated and occluded objects. We experimentally evaluated the impact of varying network resolution sizes and training epochs on the performance. A comparative study with several contemporary aerial object detectors proved that YOLOv4 performed better, implying a more suitable detection algorithm to incorporate on aerial platforms.
Time-Variant Variational Transfer for Value Functions
May 26, 2020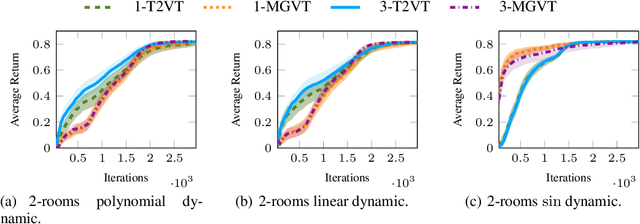
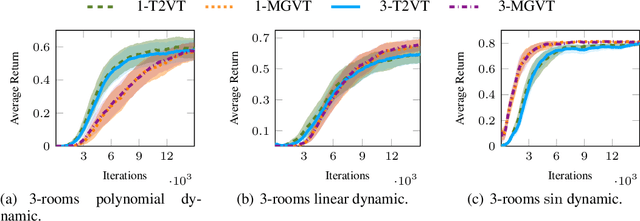
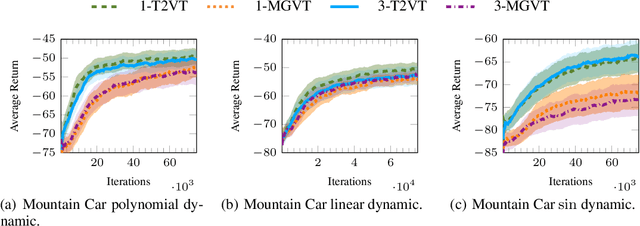
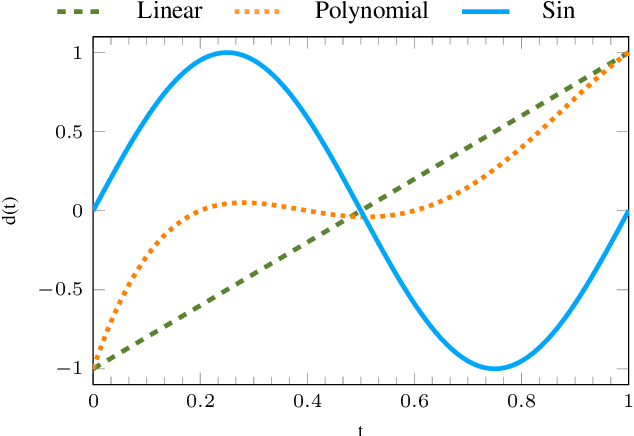
In most transfer learning approaches to reinforcement learning (RL) the distribution over the tasks is assumed to be stationary. Therefore, the target and source tasks are i.i.d. samples of the same distribution. In the context of this work, we will consider the problem of transferring value functions through a variational method when the distribution generating the tasks is time-variant, proposing a solution leveraging this temporal structure inherent to the task generating process. Moreover, by means of a finite sample analysis, the previously mentioned solution will be theoretically compared to its time-invariant version. Finally, we will provide an experimental evaluation of the proposed technique with three distinct time dynamics in three different RL environments.
Pulses with Minimum Residual Intersymbol Interference for Faster than Nyquist Signaling
Mar 14, 2022
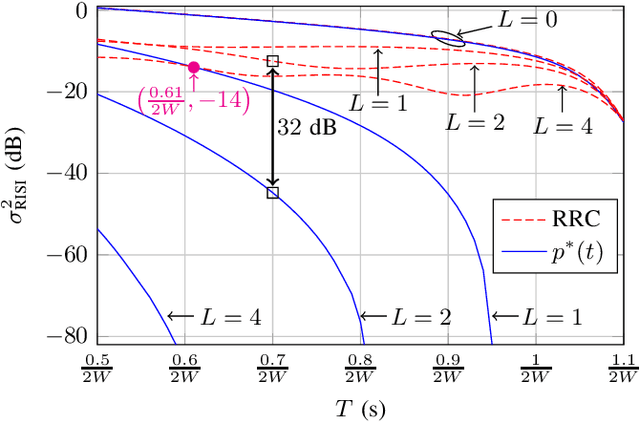
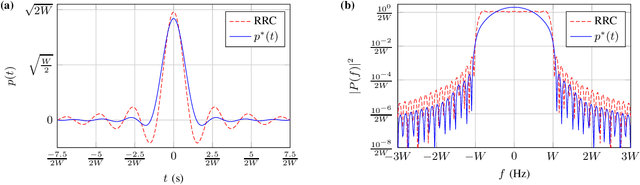
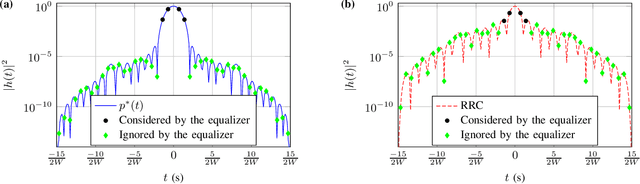
Faster than Nyquist signaling increases the spectral efficiency of pulse amplitude modulation by accepting intersymbol interference, where an equalizer is needed at the receiver. Since the complexity of an optimal equalizer increases exponentially with the number of the interfering symbols, practical truncated equalizers assume shorter memory. The power of the resulting residual interference depends on the transmit filter and limits the performance of truncated equalizers. In this paper, we use numerical optimizations and the prolate spheroidal wave functions to find optimal time-limited pulses that achieve minimum residual interference. Compared to root raised cosine pulses, the new pulses decrease the residual interference by an order of magnitude, for example, a decrease by 32 dB is achieved for an equalizer that considers four interfering symbols at 57% faster transmissions. As a proof of concept, for the 57% faster transmissions of binary symbols, we showed that using the new pulse with a 4-state equalizer has better bit error rate performance compared to using a root raised cosine pulse with a 128-state equalizer.
Transfer Learning as an Essential Tool for Digital Twins in Renewable Energy Systems
Mar 09, 2022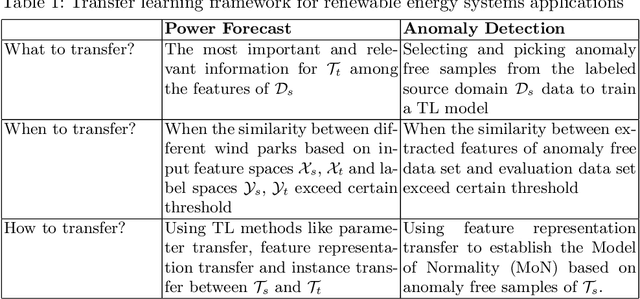
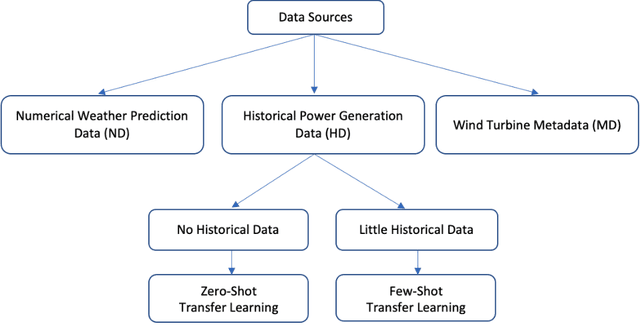
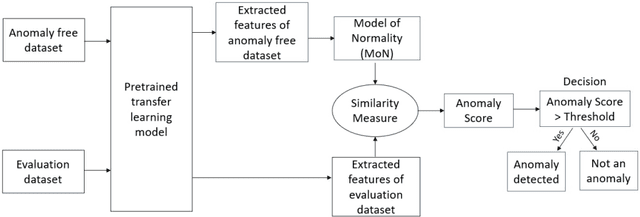
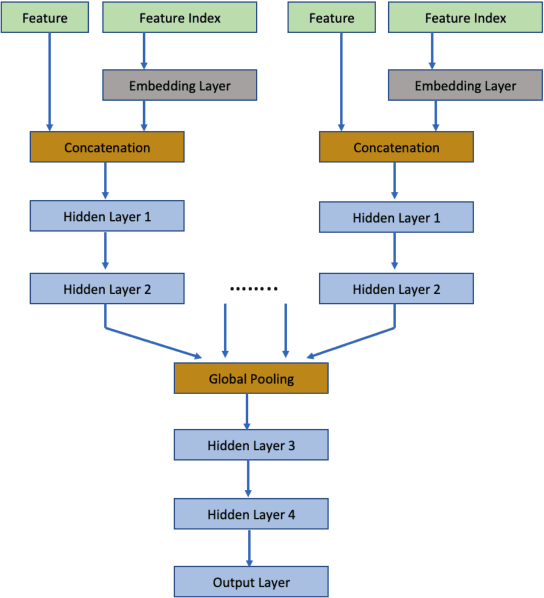
Transfer learning (TL), the next frontier in machine learning (ML), has gained much popularity in recent years, due to the various challenges faced in ML, like the requirement of vast amounts of training data, expensive and time-consuming labelling processes for data samples, and long training duration for models. TL is useful in tackling these problems, as it focuses on transferring knowledge from previously solved tasks to new tasks. Digital twins and other intelligent systems need to utilise TL to use the previously gained knowledge and solve new tasks in a more self-reliant way, and to incrementally increase their knowledge base. Therefore, in this article, the critical challenges in power forecasting and anomaly detection in the context of renewable energy systems are identified, and a potential TL framework to meet these challenges is proposed. This article also proposes a feature embedding approach to handle the missing sensors data. The proposed TL methods help to make a system more autonomous in the context of organic computing.
Towards Unifying the Label Space for Aspect- and Sentence-based Sentiment Analysis
Mar 14, 2022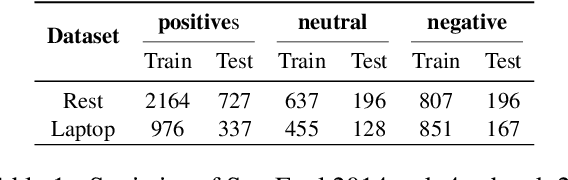
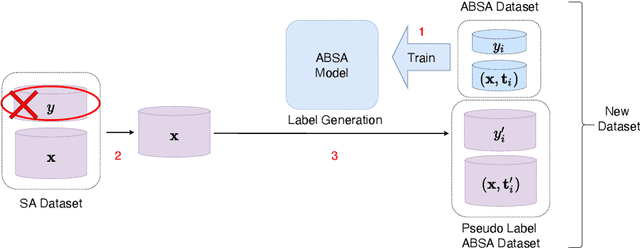
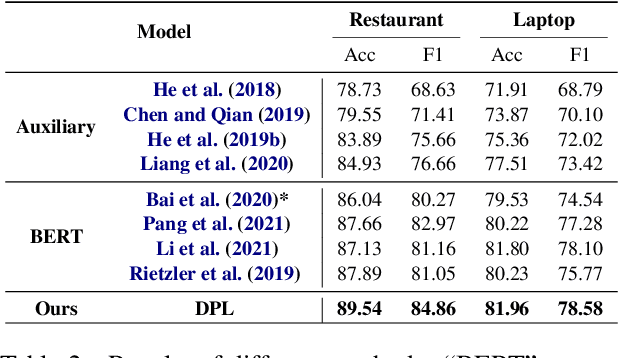
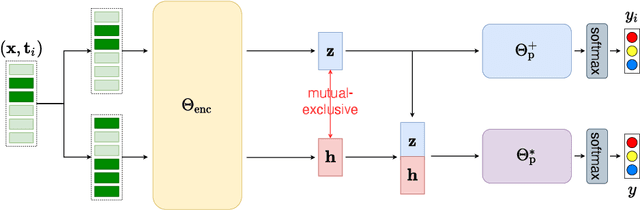
The aspect-based sentiment analysis (ABSA) is a fine-grained task that aims to determine the sentiment polarity towards targeted aspect terms occurring in the sentence. The development of the ABSA task is very much hindered by the lack of annotated data. To tackle this, the prior works have studied the possibility of utilizing the sentiment analysis (SA) datasets to assist in training the ABSA model, primarily via pretraining or multi-task learning. In this article, we follow this line, and for the first time, we manage to apply the Pseudo-Label (PL) method to merge the two homogeneous tasks. While it seems straightforward to use generated pseudo labels to handle this case of label granularity unification for two highly related tasks, we identify its major challenge in this paper and propose a novel framework, dubbed as Dual-granularity Pseudo Labeling (DPL). Further, similar to PL, we regard the DPL as a general framework capable of combining other prior methods in the literature. Through extensive experiments, DPL has achieved state-of-the-art performance on standard benchmarks surpassing the prior work significantly.
Magnetic Field Prediction Using Generative Adversarial Networks
Mar 14, 2022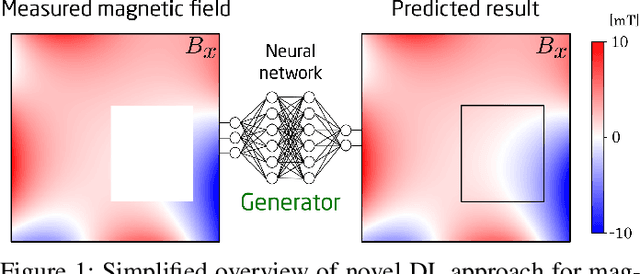
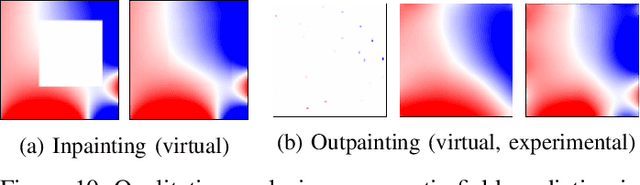
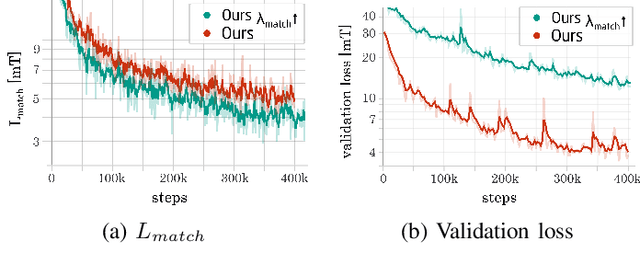
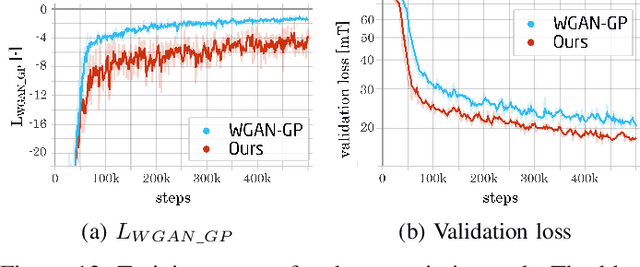
Plenty of scientific and real-world applications are built on magnetic fields and their characteristics. To retrieve the valuable magnetic field information in high resolution, extensive field measurements are required, which are either time-consuming to conduct or even not feasible due to physical constraints. To alleviate this problem, we predict magnetic field values at a random point in space from a few point measurements by using a generative adversarial network (GAN) structure. The deep learning (DL) architecture consists of two neural networks: a generator, which predicts missing field values of a given magnetic field, and a critic, which is trained to calculate the statistical distance between real and generated magnetic field distributions. By minimizing this statistical distance, a reconstruction loss as well as physical losses, our trained generator has learned to predict the missing field values with a median reconstruction test error of 5.14%, when a single coherent region of field points is missing, and 5.86%, when only a few point measurements in space are available and the field measurements around are predicted. We verify the results on an experimentally validated field.
Towards On-Board Panoptic Segmentation of Multispectral Satellite Images
Apr 05, 2022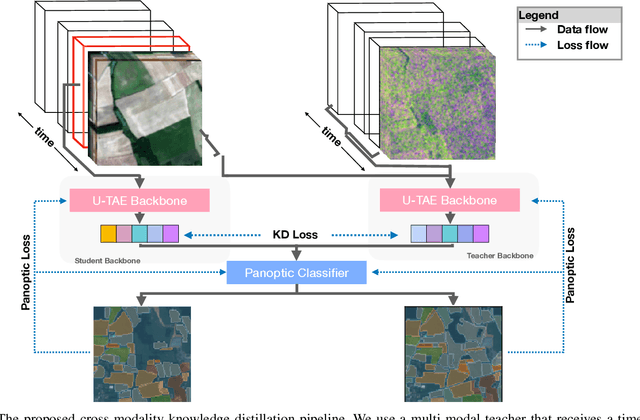


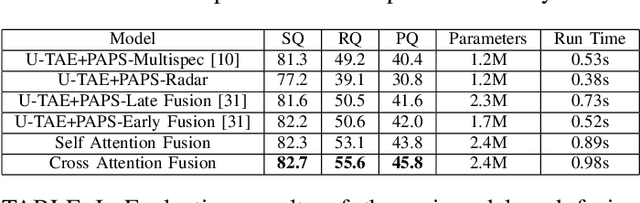
With tremendous advancements in low-power embedded computing devices and remote sensing instruments, the traditional satellite image processing pipeline which includes an expensive data transfer step prior to processing data on the ground is being replaced by on-board processing of captured data. This paradigm shift enables critical and time-sensitive analytic intelligence to be acquired in a timely manner on-board the satellite itself. However, at present, the on-board processing of multi-spectral satellite images is limited to classification and segmentation tasks. Extending this processing to its next logical level, in this paper we propose a lightweight pipeline for on-board panoptic segmentation of multi-spectral satellite images. Panoptic segmentation offers major economic and environmental insights, ranging from yield estimation from agricultural lands to intelligence for complex military applications. Nevertheless, the on-board intelligence extraction raises several challenges due to the loss of temporal observations and the need to generate predictions from a single image sample. To address this challenge, we propose a multimodal teacher network based on a cross-modality attention-based fusion strategy to improve the segmentation accuracy by exploiting data from multiple modes. We also propose an online knowledge distillation framework to transfer the knowledge learned by this multi-modal teacher network to a uni-modal student which receives only a single frame input, and is more appropriate for an on-board environment. We benchmark our approach against existing state-of-the-art panoptic segmentation models using the PASTIS multi-spectral panoptic segmentation dataset considering an on-board processing setting. Our evaluations demonstrate a substantial increase in accuracy metrics compared to the existing state-of-the-art models.
Finite-Time Analysis and Restarting Scheme for Linear Two-Time-Scale Stochastic Approximation
Jan 09, 2020Motivated by their broad applications in reinforcement learning, we study the linear two-time-scale stochastic approximation, an iterative method using two different step sizes for finding the solutions of a system of two equations. Our main focus is to characterize the finite-time complexity of this method under time-varying step sizes and Markovian noise. In particular, we show that the mean square errors of the variables generated by the method converge to zero at a sublinear rate $\Ocal(k^{2/3})$, where $k$ is the number of iterations. We then improve the performance of this method by considering the restarting scheme, where we restart the algorithm after every predetermined number of iterations. We show that using this restarting method the complexity of the algorithm under time-varying step sizes is as good as the one using constant step sizes, but still achieving an exact converge to the desired solution. Moreover, the restarting scheme also helps to prevent the step sizes from getting too small, which is useful for the practical implementation of the linear two-time-scale stochastic approximation.
A Computational Architecture for Machine Consciousness and Artificial Superintelligence: Updating Working Memory Iteratively
Mar 29, 2022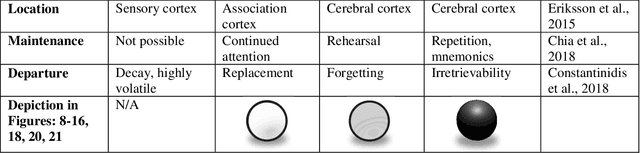
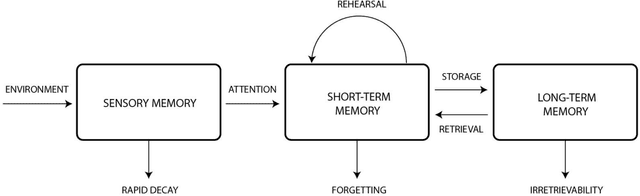

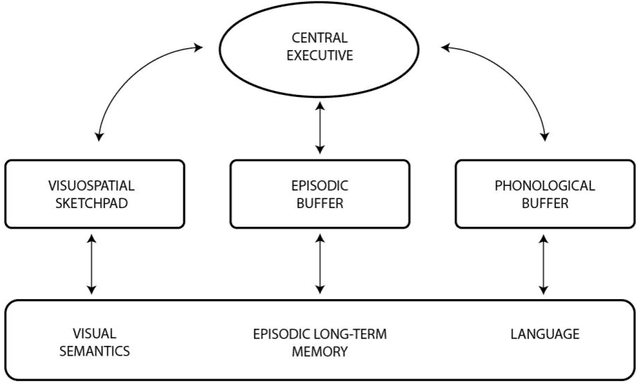
This theoretical article examines how to construct human-like working memory and thought processes within a computer. There should be two working memory stores, one analogous to sustained firing in association cortex, and one analogous to synaptic potentiation in the cerebral cortex. These stores must be constantly updated with new representations that arise from either environmental stimulation or internal processing. They should be updated continuously, and in an iterative fashion, meaning that, in the next state, some items in the set of coactive items should always be retained. Thus, the set of concepts coactive in working memory will evolve gradually and incrementally over time. This makes each state is a revised iteration of the preceding state and causes successive states to overlap and blend with respect to the set of representations they contain. As new representations are added and old ones are subtracted, some remain active for several seconds over the course of these changes. This persistent activity, similar to that used in artificial recurrent neural networks, is used to spread activation energy throughout the global workspace to search for the next associative update. The result is a chain of associatively linked intermediate states that are capable of advancing toward a solution or goal. Iterative updating is conceptualized here as an information processing strategy, a computational and neurophysiological determinant of the stream of thought, and an algorithm for designing and programming artificial intelligence.
A Continuous-Time Approach for 3D Radar-to-Camera Extrinsic Calibration
Mar 12, 2021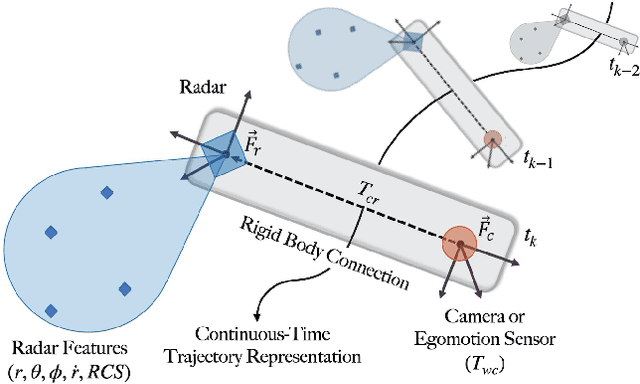
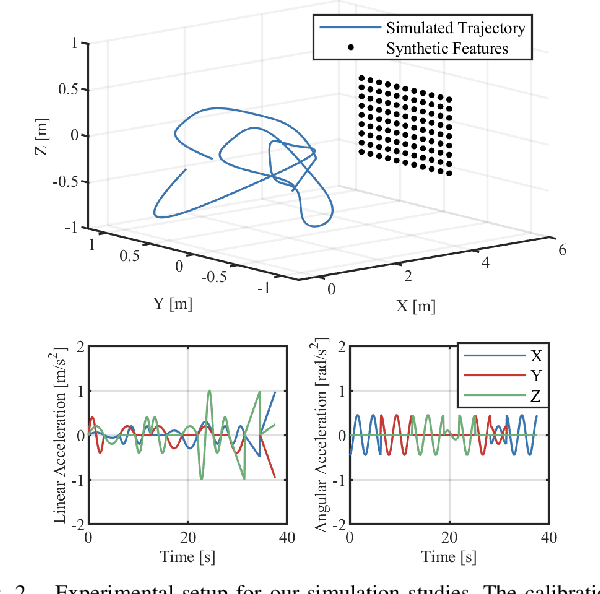
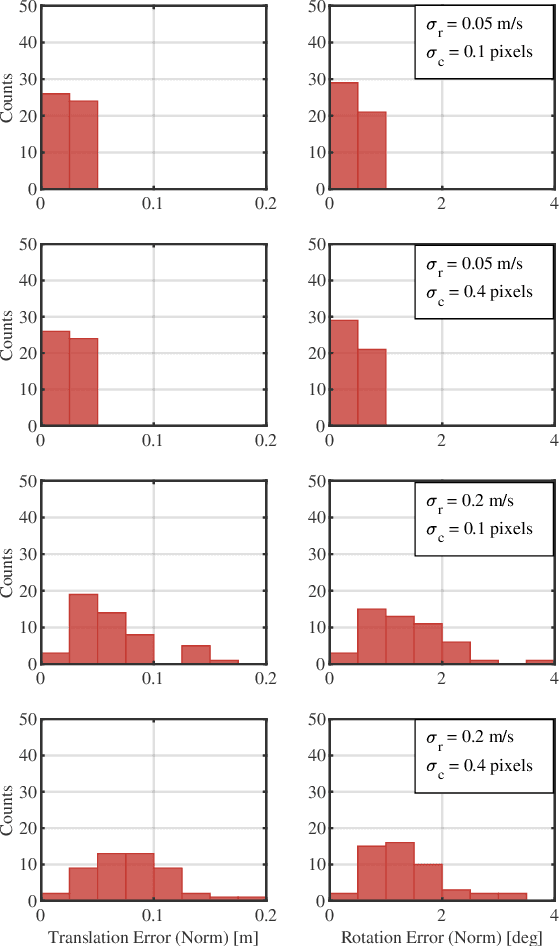

Reliable operation in inclement weather is essential to the deployment of safe autonomous vehicles (AVs). Robustness and reliability can be achieved by fusing data from the standard AV sensor suite (i.e., lidars, cameras) with weather robust sensors, such as millimetre-wavelength radar. Critically, accurate sensor data fusion requires knowledge of the rigid-body transform between sensor pairs, which can be determined through the process of extrinsic calibration. A number of extrinsic calibration algorithms have been designed for 2D (planar) radar sensors - however, recently-developed, low-cost 3D millimetre-wavelength radars are set to displace their 2D counterparts in many applications. In this paper, we present a continuous-time 3D radar-to-camera extrinsic calibration algorithm that utilizes radar velocity measurements and, unlike the majority of existing techniques, does not require specialized radar retroreflectors to be present in the environment. We derive the observability properties of our formulation and demonstrate the efficacy of our algorithm through synthetic and real-world experiments.