 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Echo-enabled Direction-of-Arrival and range estimation of a mobile source in Ambisonic domain
Mar 10, 2022
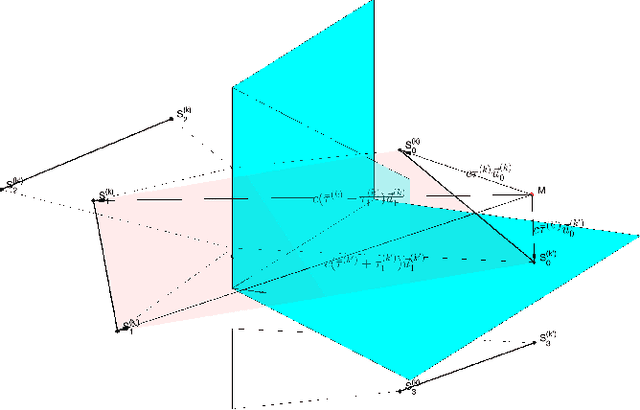
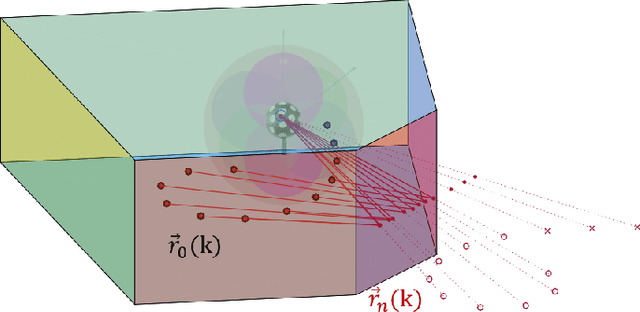

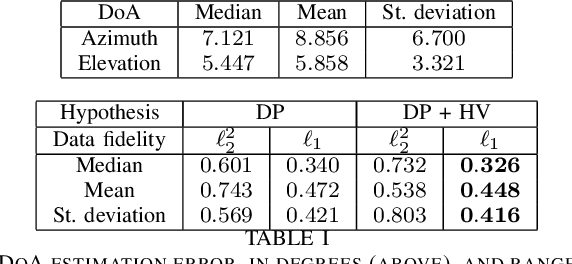
Range estimation of a far field sound source in a reverberant environment is known to be a notoriously difficult problem, hence most localization methods are only capable of estimating the source's Direction-of-Arrival (DoA). In an earlier work, we have demonstrated that, under certain restrictive acoustic conditions and given the orientation of a reflecting surface, one can exploit the dominant acoustic reflection to evaluate the DoA \emph{and} the distance to a static sound source in Ambisonic domain. In this article, we leverage the recently presented Generalized Time-domain Velocity Vector (GTVV) representation to estimate these quantities for a moving sound source without an a priori knowledge of reflectors' orientations. We show that the trajectories of a moving source and the corresponding reflections are spatially and temporally related, which can be used to infer the absolute delay of the propagating source signal and, therefore, approximate the microphone-to-source distance. Experiments on real sound data confirm the validity of the proposed approach.
Split HE: Fast Secure Inference Combining Split Learning and Homomorphic Encryption
Feb 27, 2022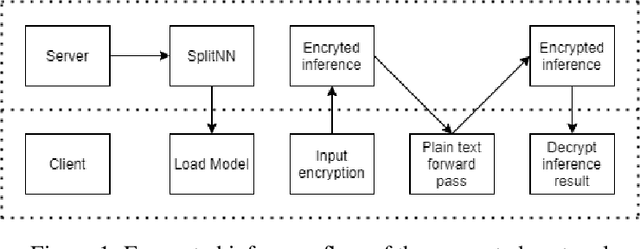

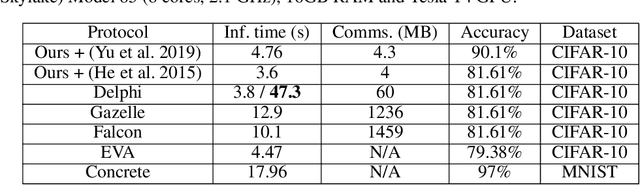
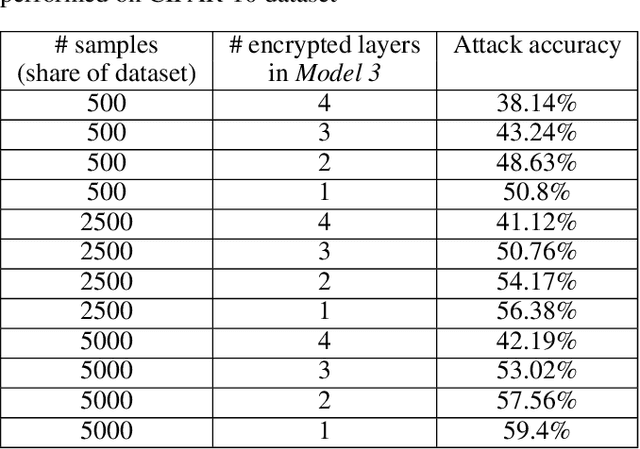
This work presents a novel protocol for fast secure inference of neural networks applied to computer vision applications. It focuses on improving the overall performance of the online execution by deploying a subset of the model weights in plaintext on the client's machine, in the fashion of SplitNNs. We evaluate our protocol on benchmark neural networks trained on the CIFAR-10 dataset using SEAL via TenSEAL and discuss runtime and security performances. Empirical security evaluation using Membership Inference and Model Extraction attacks showed that the protocol was more resilient under the same attacks than a similar approach also based on SplitNN. When compared to related work, we demonstrate improvements of 2.5x-10x for the inference time and 14x-290x in communication costs.
A Continuous-Time Approach for 3D Radar-to-Camera Extrinsic Calibration
Mar 12, 2021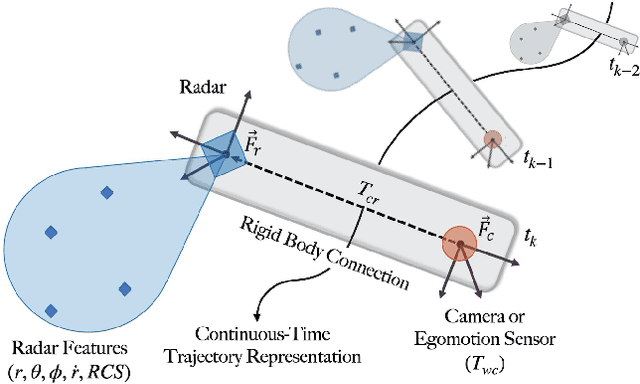
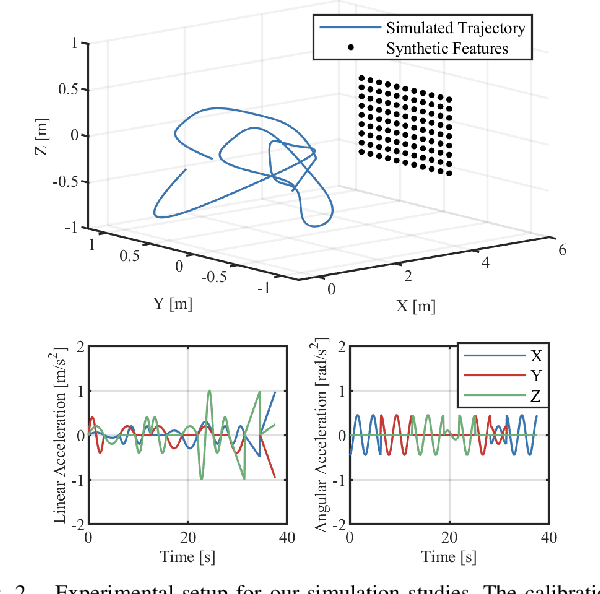
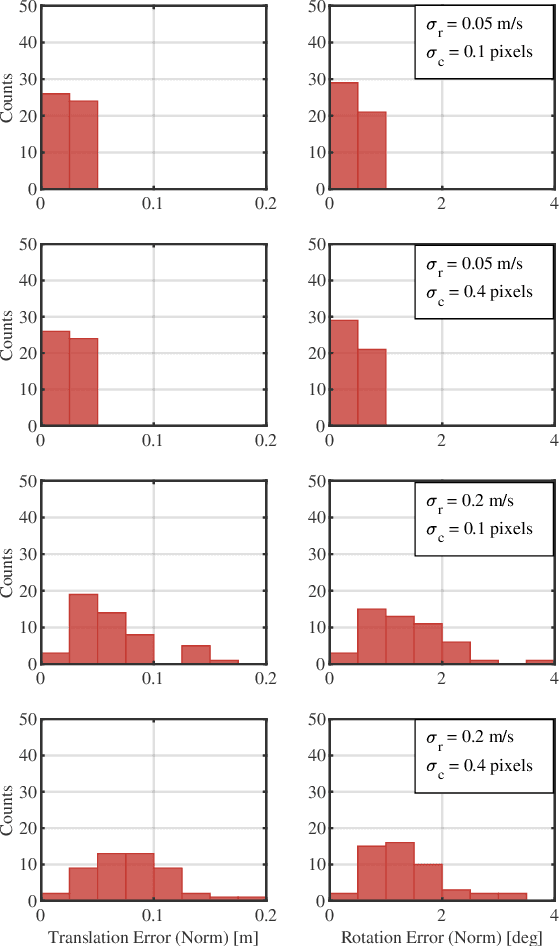

Reliable operation in inclement weather is essential to the deployment of safe autonomous vehicles (AVs). Robustness and reliability can be achieved by fusing data from the standard AV sensor suite (i.e., lidars, cameras) with weather robust sensors, such as millimetre-wavelength radar. Critically, accurate sensor data fusion requires knowledge of the rigid-body transform between sensor pairs, which can be determined through the process of extrinsic calibration. A number of extrinsic calibration algorithms have been designed for 2D (planar) radar sensors - however, recently-developed, low-cost 3D millimetre-wavelength radars are set to displace their 2D counterparts in many applications. In this paper, we present a continuous-time 3D radar-to-camera extrinsic calibration algorithm that utilizes radar velocity measurements and, unlike the majority of existing techniques, does not require specialized radar retroreflectors to be present in the environment. We derive the observability properties of our formulation and demonstrate the efficacy of our algorithm through synthetic and real-world experiments.
Time-aware Large Kernel Convolutions
Feb 08, 2020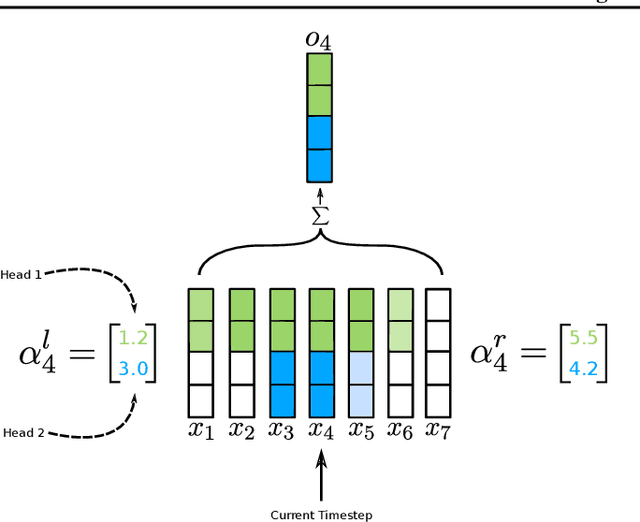

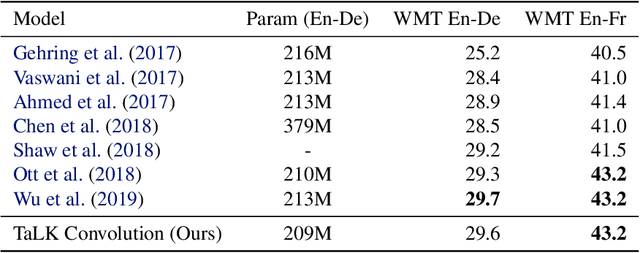
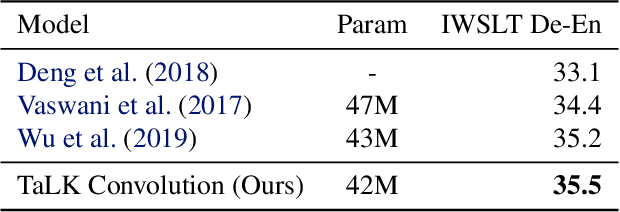
To date, most state-of-the-art sequence modelling architectures use attention to build generative models for language based tasks. Some of these models use all the available sequence tokens to generate an attention distribution which results in time complexity of $O(n^2)$. Alternatively, they utilize depthwise convolutions with softmax normalized kernels of size $k$ acting as a limited-window self-attention, resulting in time complexity of $O(k{\cdot}n)$. In this paper, we introduce Time-aware Large Kernel (TaLK) Convolutions, a novel adaptive convolution operation that learns to predict the size of a summation kernel instead of using the fixed-sized kernel matrix. This method yields a time complexity of $O(n)$, effectively making the sequence encoding process linear to the number of tokens. We evaluate the proposed method on large-scale standard machine translation and language modelling datasets and show that TaLK Convolutions constitute an efficient improvement over other attention/convolution based approaches.
Monocular Robot Navigation with Self-Supervised Pretrained Vision Transformers
Mar 07, 2022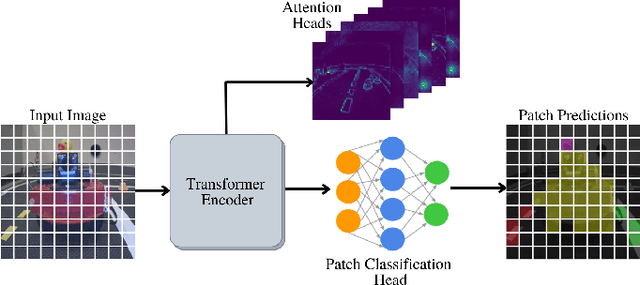

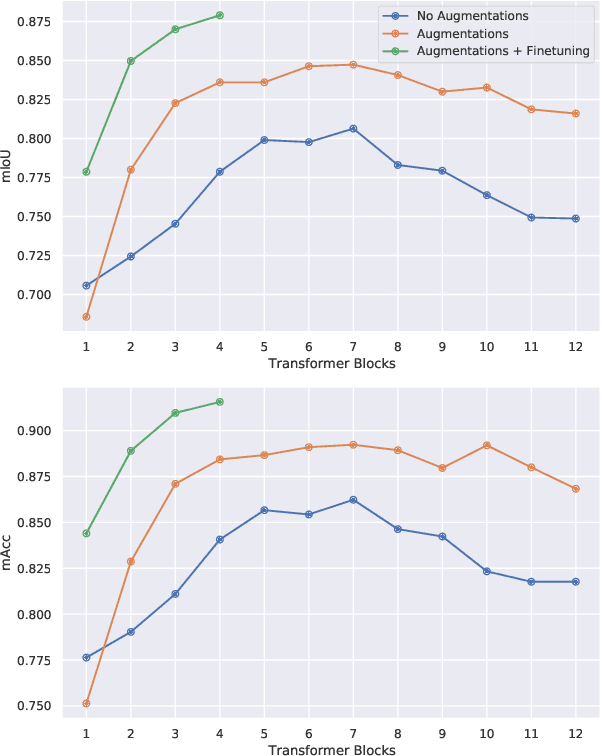

In this work, we consider the problem of learning a perception model for monocular robot navigation using few annotated images. Using a Vision Transformer (ViT) pretrained with a label-free self-supervised method, we successfully train a coarse image segmentation model for the Duckietown environment using 70 training images. Our model performs coarse image segmentation at the 8x8 patch level, and the inference resolution can be adjusted to balance prediction granularity and real-time perception constraints. We study how best to adapt a ViT to our task and environment, and find that some lightweight architectures can yield good single-image segmentations at a usable frame rate, even on CPU. The resulting perception model is used as the backbone for a simple yet robust visual servoing agent, which we deploy on a differential drive mobile robot to perform two tasks: lane following and obstacle avoidance.
Agile Maneuvers in Legged Robots: a Predictive Control Approach
Mar 14, 2022

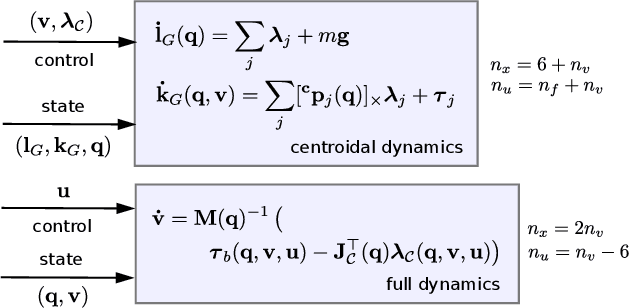
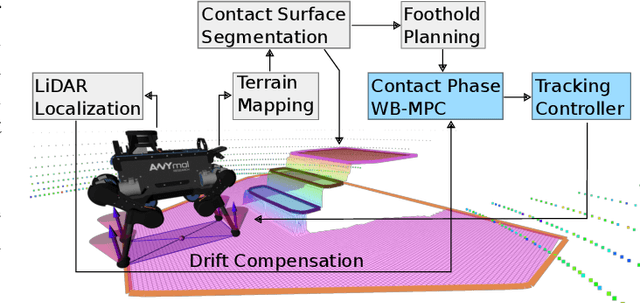
Achieving agile maneuvers through multiple contact phases has been a longstanding challenge in legged robotics. It requires to derive motion plans and local control feedback policies in real-time to handle the nonholonomy of the kinetic momenta. While a few recent predictive control approaches based on centroidal momentum have been able to generate dynamic motions, they assume unlimited actuation capabilities. This assumption is quite restrictive and does not hold for agile maneuvers on most robots. In this work, we present a contact-phase predictive and state-feedback controllers that enables legged robots to plan and perform agile locomotion skills. Our predictive controller models the contact phases using a hybrid paradigm that considers the robot's actuation limits and full dynamics. We demonstrate the benefits of our approach on agile maneuvers on ANYmal robots in realistic scenarios. To the best of our knowledge, our work is the first to show that predictive control can handle actuation limits, generate agile locomotion maneuvers and execute locally optimal feedback policies on hardware without the use of a separate whole-body controller.
Exosoul: ethical profiling in the digital world
Mar 30, 2022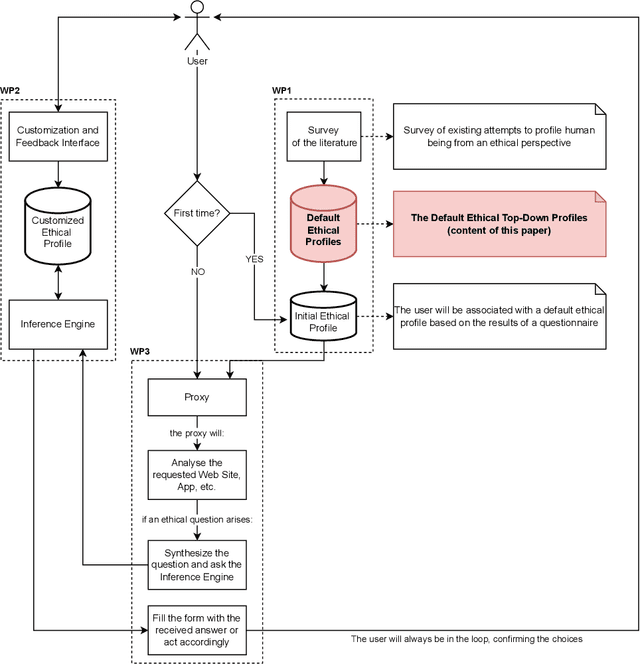
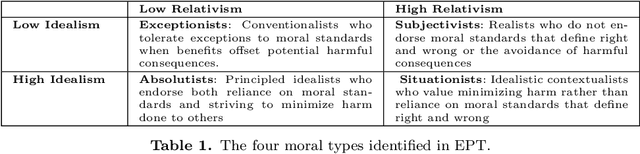
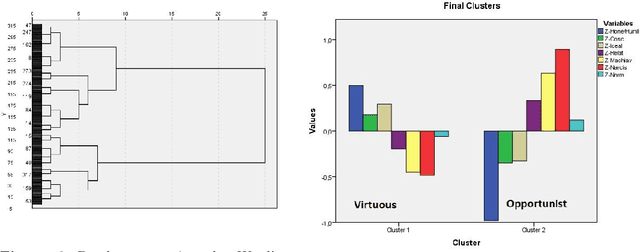
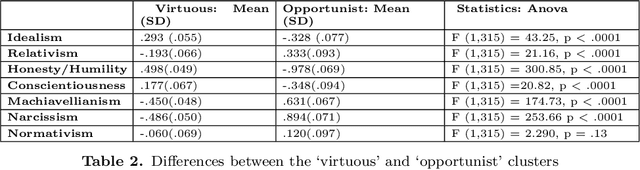
The development and the spread of increasingly autonomous digital technologies in our society pose new ethical challenges beyond data protection and privacy violation. Users are unprotected in their interactions with digital technologies and at the same time autonomous systems are free to occupy the space of decisions that is prerogative of each human being. In this context the multidisciplinary project Exosoul aims at developing a personalized software exoskeleton which mediates actions in the digital world according to the moral preferences of the user. The exoskeleton relies on the ethical profiling of a user, similar in purpose to the privacy profiling proposed in the literature, but aiming at reflecting and predicting general moral preferences. Our approach is hybrid, first based on the identification of profiles in a top-down manner, and then on the refinement of profiles by a personalized data-driven approach. In this work we report our initial experiment on building such top-down profiles. We consider the correlations between ethics positions (idealism and relativism) personality traits (honesty/humility, conscientiousness, Machiavellianism and narcissism) and worldview (normativism), and then we use a clustering approach to create ethical profiles predictive of user's digital behaviors concerning privacy violation, copy-right infringements, caution and protection. Data were collected by administering a questionnaire to 317 young individuals. In the paper we discuss two clustering solutions, one data-driven and one model-driven, in terms of validity and predictive power of digital behavior.
Machine Learning Methods in Solving the Boolean Satisfiability Problem
Mar 02, 2022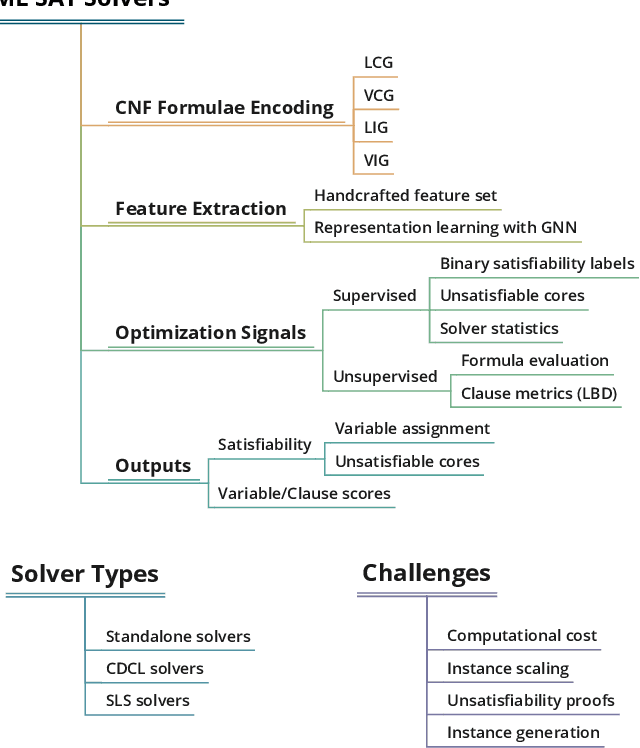
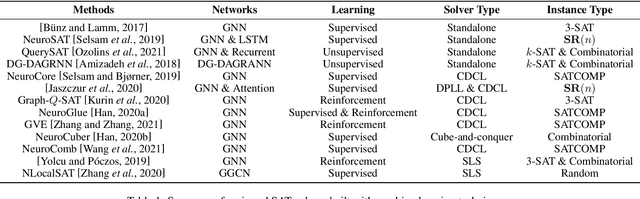
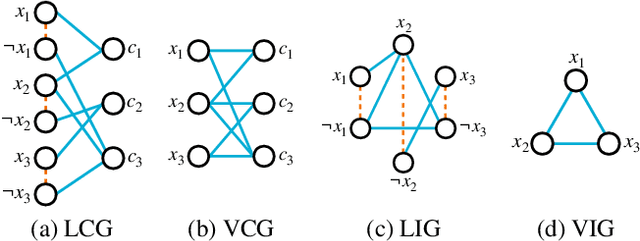
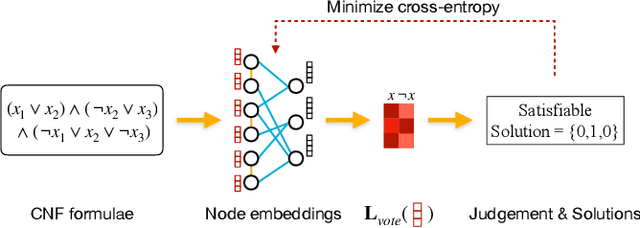
This paper reviews the recent literature on solving the Boolean satisfiability problem (SAT), an archetypal NP-complete problem, with the help of machine learning techniques. Despite the great success of modern SAT solvers to solve large industrial instances, the design of handcrafted heuristics is time-consuming and empirical. Under the circumstances, the flexible and expressive machine learning methods provide a proper alternative to solve this long-standing problem. We examine the evolving ML-SAT solvers from naive classifiers with handcrafted features to the emerging end-to-end SAT solvers such as NeuroSAT, as well as recent progress on combinations of existing CDCL and local search solvers with machine learning methods. Overall, solving SAT with machine learning is a promising yet challenging research topic. We conclude the limitations of current works and suggest possible future directions.
Winograd Convolution: A Perspective from Fault Tolerance
Feb 17, 2022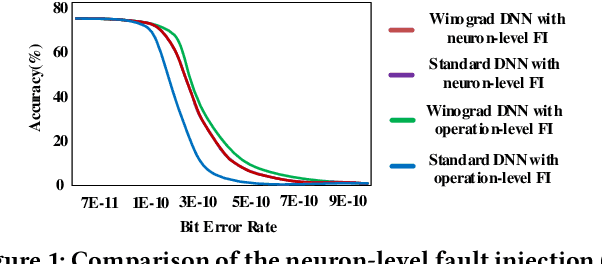
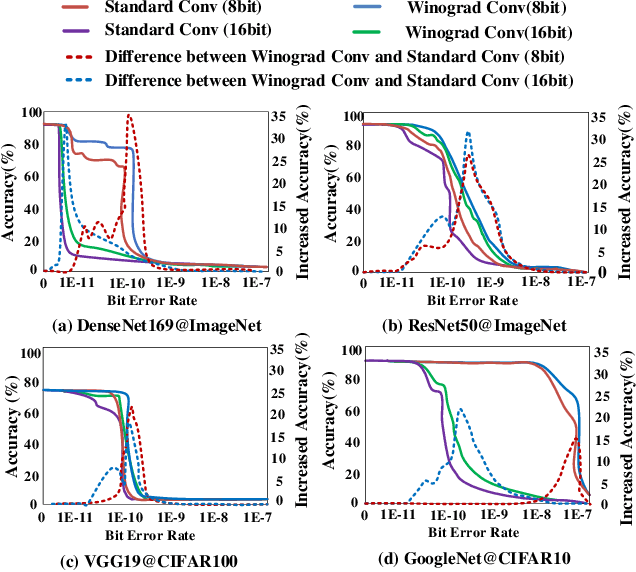
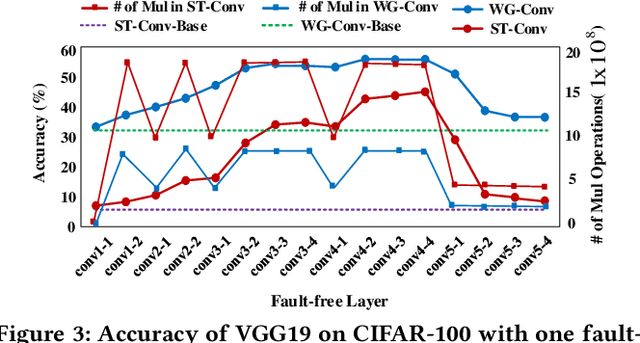
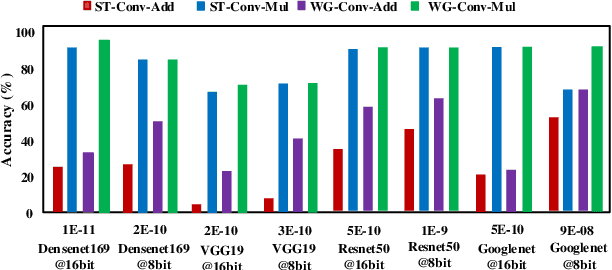
Winograd convolution is originally proposed to reduce the computing overhead by converting multiplication in neural network (NN) with addition via linear transformation. Other than the computing efficiency, we observe its great potential in improving NN fault tolerance and evaluate its fault tolerance comprehensively for the first time. Then, we explore the use of fault tolerance of winograd convolution for either fault-tolerant or energy-efficient NN processing. According to our experiments, winograd convolution can be utilized to reduce fault-tolerant design overhead by 27.49\% or energy consumption by 7.19\% without any accuracy loss compared to that without being aware of the fault tolerance
Conditioned Time-Dilated Convolutions for Sound Event Detection
Jul 10, 2020
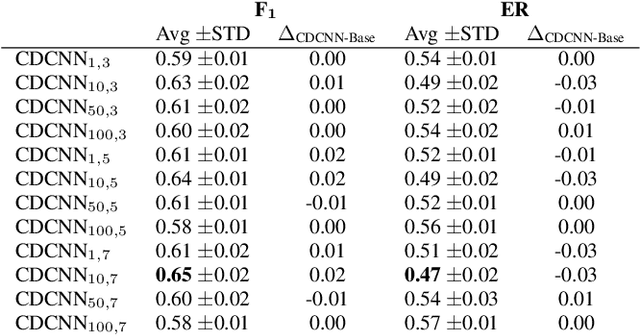
Sound event detection (SED) is the task of identifying sound events along with their onset and offset times. A recent, convolutional neural networks based SED method, proposed the usage of depthwise separable (DWS) and time-dilated convolutions. DWS and time-dilated convolutions yielded state-of-the-art results for SED, with considerable small amount of parameters. In this work we propose the expansion of the time-dilated convolutions, by conditioning them with jointly learned embeddings of the SED predictions by the SED classifier. We present a novel algorithm for the conditioning of the time-dilated convolutions which functions similarly to language modelling, and enhances the performance of the these convolutions. We employ the freely available TUT-SED Synthetic dataset, and we assess the performance of our method using the average per-frame $\text{F}_{1}$ score and average per-frame error rate, over the 10 experiments. We achieve an increase of 2\% (from 0.63 to 0.65) at the average $\text{F}_{1}$ score (the higher the better) and a decrease of 3\% (from 0.50 to 0.47) at the error rate (the lower the better).