 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Exploiting Single-Channel Speech for Multi-Channel End-to-End Speech Recognition: A Comparative Study
Mar 31, 2022
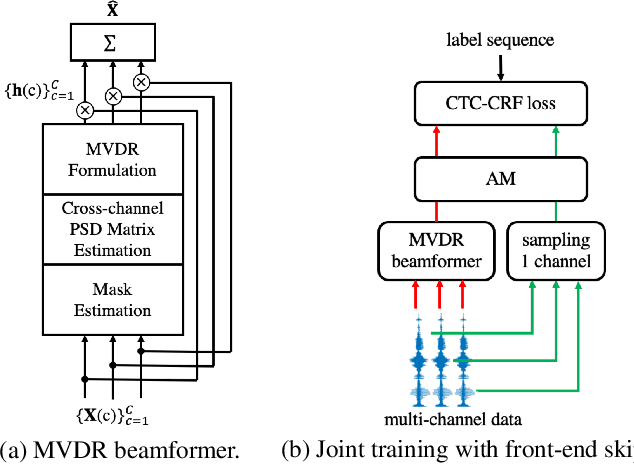

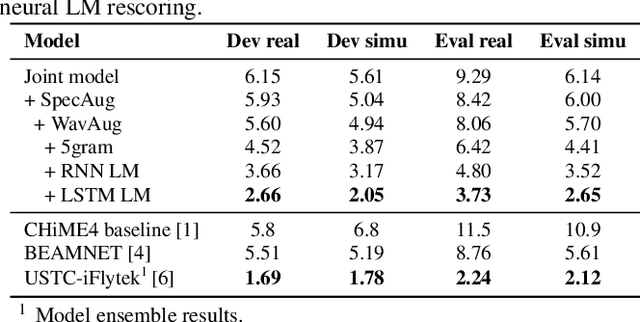
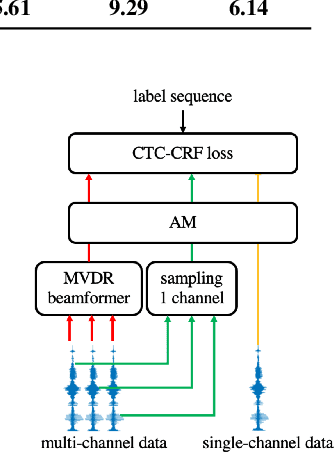
Recently, the end-to-end training approach for multi-channel ASR has shown its effectiveness, which usually consists of a beamforming front-end and a recognition back-end. However, the end-to-end training becomes more difficult due to the integration of multiple modules, particularly considering that multi-channel speech data recorded in real environments are limited in size. This raises the demand to exploit the single-channel data for multi-channel end-to-end ASR. In this paper, we systematically compare the performance of three schemes to exploit external single-channel data for multi-channel end-to-end ASR, namely back-end pre-training, data scheduling, and data simulation, under different settings such as the sizes of the single-channel data and the choices of the front-end. Extensive experiments on CHiME-4 and AISHELL-4 datasets demonstrate that while all three methods improve the multi-channel end-to-end speech recognition performance, data simulation outperforms the other two, at the cost of longer training time. Data scheduling outperforms back-end pre-training marginally but nearly consistently, presumably because that in the pre-training stage, the back-end tends to overfit on the single-channel data, especially when the single-channel data size is small.
Casual 6-DoF: free-viewpoint panorama using a handheld 360 camera
Mar 31, 2022

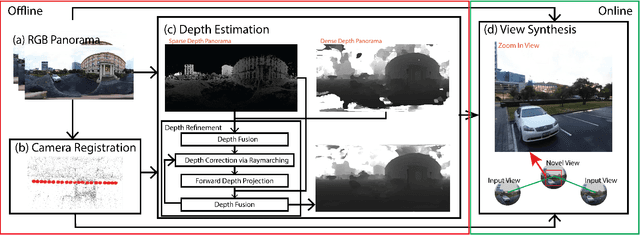
Six degrees-of-freedom (6-DoF) video provides telepresence by enabling users to move around in the captured scene with a wide field of regard. Compared to methods requiring sophisticated camera setups, the image-based rendering method based on photogrammetry can work with images captured with any poses, which is more suitable for casual users. However, existing image-based rendering methods are based on perspective images. When used to reconstruct 6-DoF views, it often requires capturing hundreds of images, making data capture a tedious and time-consuming process. In contrast to traditional perspective images, 360{\deg} images capture the entire surrounding view in a single shot, thus, providing a faster capturing process for 6-DoF view reconstruction. This paper presents a novel method to provide 6-DoF experiences over a wide area using an unstructured collection of 360{\deg} panoramas captured by a conventional 360{\deg} camera. Our method consists of 360{\deg} data capturing, novel depth estimation to produce a high-quality spherical depth panorama, and high-fidelity free-viewpoint generation. We compared our method against state-of-the-art methods, using data captured in various environments. Our method shows better visual quality and robustness in the tested scenes.
SPICEprop: Backpropagating Errors Through Memristive Spiking Neural Networks
Mar 10, 2022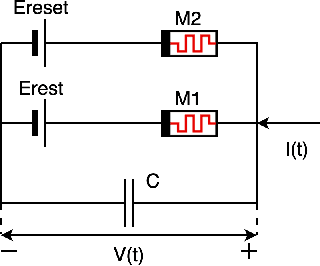
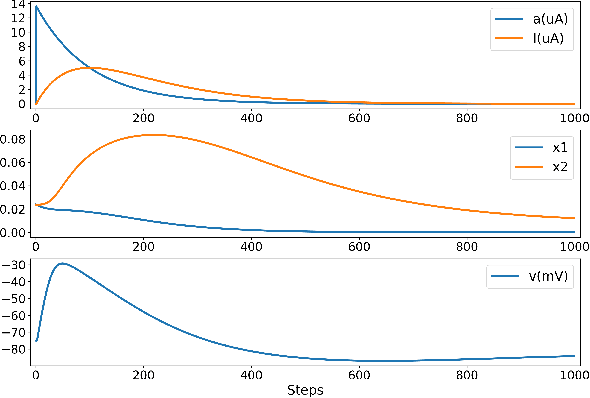
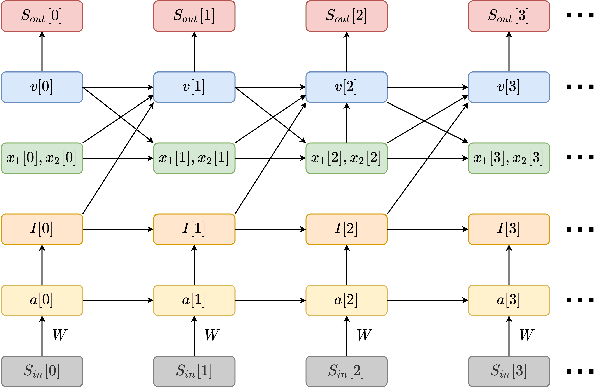
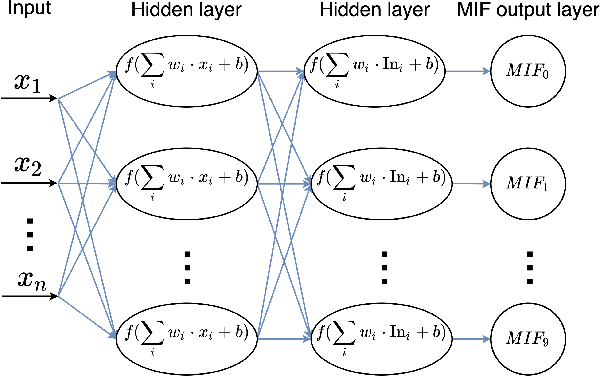
We present a fully memristive spiking neural network (MSNN) consisting of novel memristive neurons trained using the backpropagation through time (BPTT) learning rule. Gradient descent is applied directly to the memristive integrated-and-fire (MIF) neuron designed using analog SPICE circuit models, which generates distinct depolarization, hyperpolarization, and repolarization voltage waveforms. Synaptic weights are trained by BPTT using the membrane potential of the MIF neuron model and can be processed on memristive crossbars. The natural spiking dynamics of the MIF neuron model are fully differentiable, eliminating the need for gradient approximations that are prevalent in the spiking neural network literature. Despite the added complexity of training directly on SPICE circuit models, we achieve 97.58% accuracy on the MNIST testing dataset and 75.26% on the Fashion-MNIST testing dataset, the highest accuracies among all fully MSNNs.
Time Dependence in Non-Autonomous Neural ODEs
May 06, 2020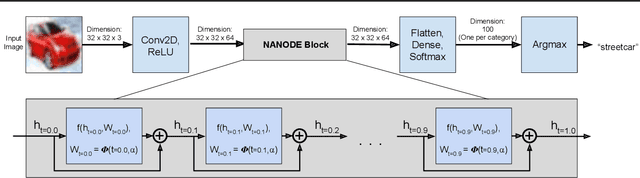
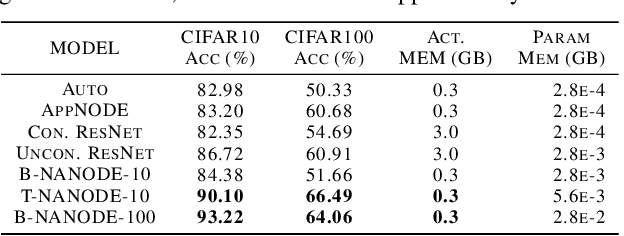
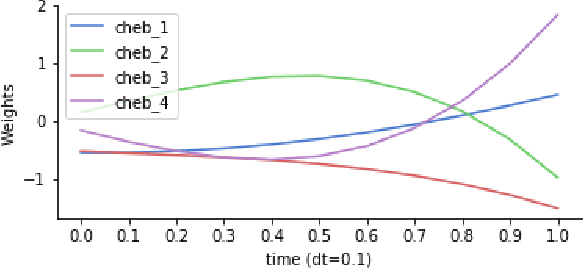
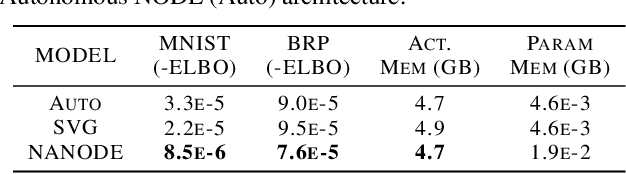
Neural Ordinary Differential Equations (ODEs) are elegant reinterpretations of deep networks where continuous time can replace the discrete notion of depth, ODE solvers perform forward propagation, and the adjoint method enables efficient, constant memory backpropagation. Neural ODEs are universal approximators only when they are non-autonomous, that is, the dynamics depends explicitly on time. We propose a novel family of Neural ODEs with time-varying weights, where time-dependence is non-parametric, and the smoothness of weight trajectories can be explicitly controlled to allow a tradeoff between expressiveness and efficiency. Using this enhanced expressiveness, we outperform previous Neural ODE variants in both speed and representational capacity, ultimately outperforming standard ResNet and CNN models on select image classification and video prediction tasks.
Understanding the input-output relationship of neural networks in the time series forecasting radon levels at Canfranc Underground Laboratory
Mar 01, 2021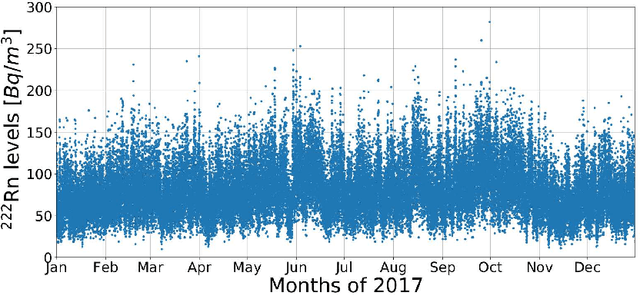
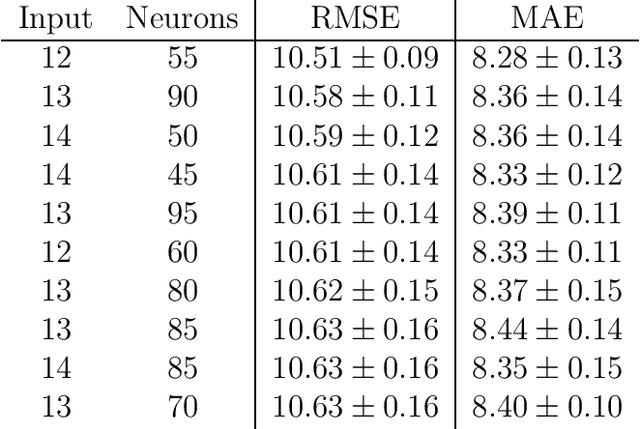
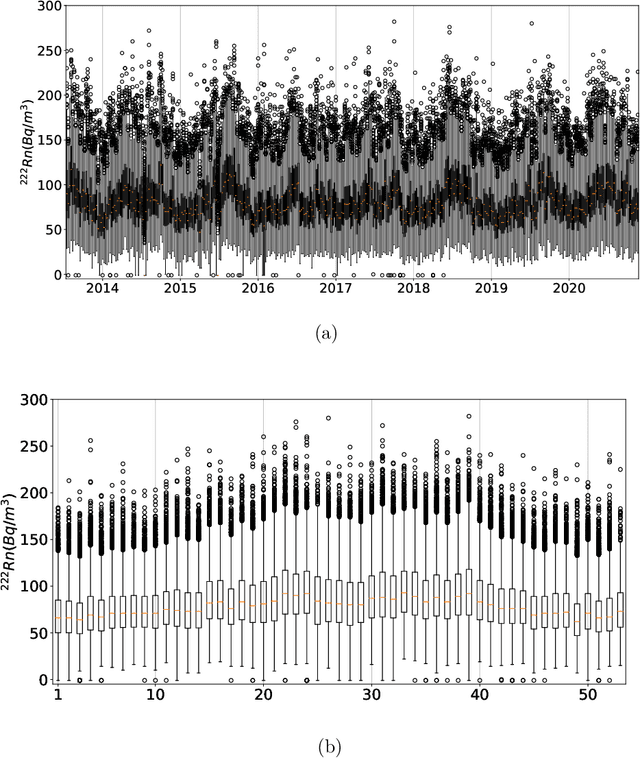
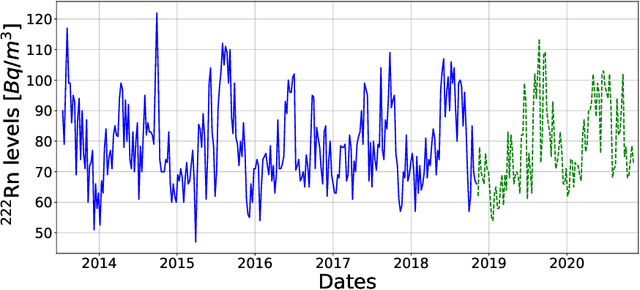
Underground physics experiments such as dark matter direct detection need to keep control of the background contribution. Hosting these experiments in underground facilities helps to minimize certain background sources such as the cosmic rays. One of the largest remaining background sources is the radon emanated from the rocks enclosing the research facility. The radon particles could be deposited inside the detectors when they are opened to perform the maintenance operations. Therefore, forecasting the radon levels is a crucial task in an attempt to schedule the maintenance operations when radon level is minimum. In the past, deep learning models have been implemented to forecast the radon time series at the Canfranc Underground Laboratory (LSC), in Spain, with satisfactory results. When forecasting time series, the past values of the time series are taken as input variables. The present work focuses on understanding the relative contribution of these input variables to the predictions generated by neural networks. The results allow us to understand how the predictions of the time series depend on the input variables. These results may be used to build better predictors in the future.
On Robust Classification using Contractive Hamiltonian Neural ODEs
Mar 22, 2022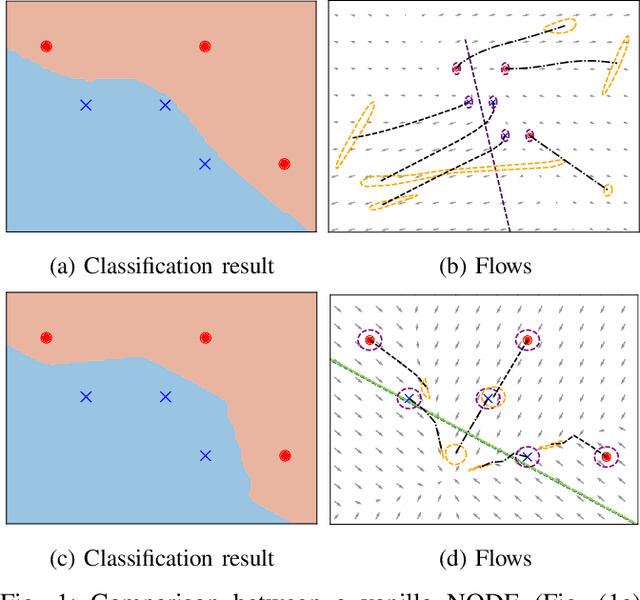

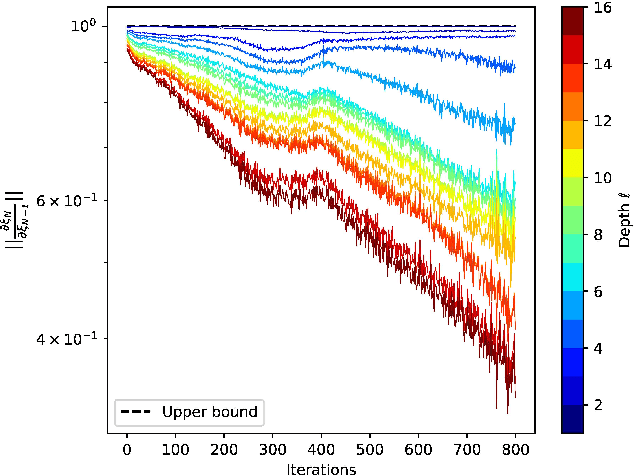
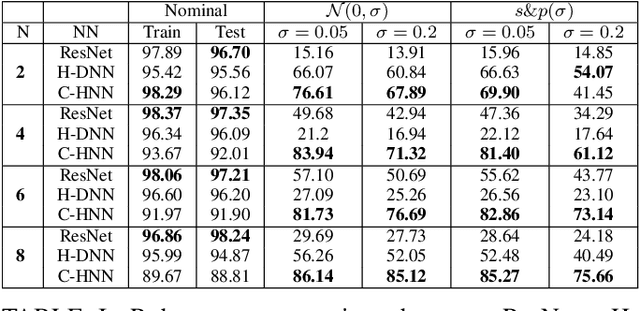
Deep neural networks can be fragile and sensitive to small input perturbations that might cause a significant change in the output. In this paper, we employ contraction theory to improve the robustness of neural ODEs (NODEs). A dynamical system is contractive if all solutions with different initial conditions converge to each other asymptotically. As a consequence, perturbations in initial conditions become less and less relevant over time. Since in NODEs, the input data corresponds to the initial condition of dynamical systems, we show contractivity can mitigate the effect of input perturbations. More precisely, inspired by NODEs with Hamiltonian dynamics, we propose a class of contractive Hamiltonian NODEs (CH-NODEs). By properly tuning a scalar parameter, CH-NODEs ensure contractivity by design and can be trained using standard backpropagation and gradient descent algorithms. Moreover, CH-NODEs enjoy built-in guarantees of non-exploding gradients, which ensures a well-posed training process. Finally, we demonstrate the robustness of CH-NODEs on the MNIST image classification problem with noisy test datasets.
Constraint-Based Learning for Continuous-Time Bayesian Networks
Jul 07, 2020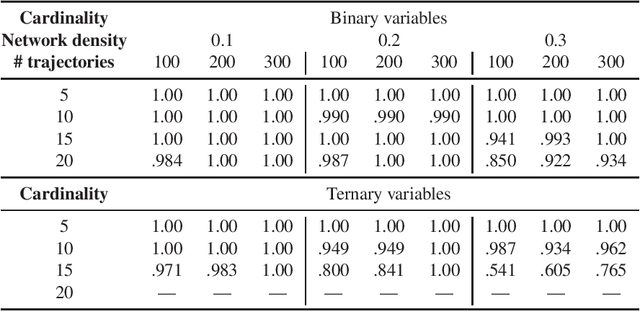
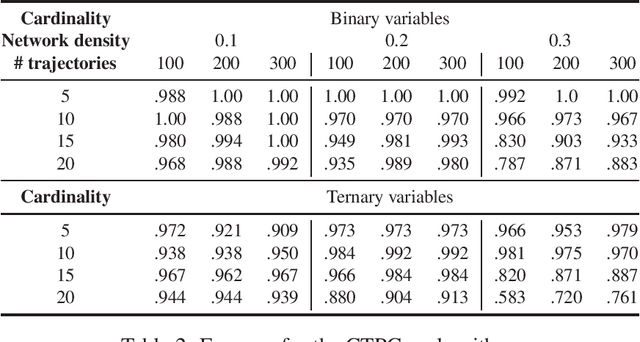
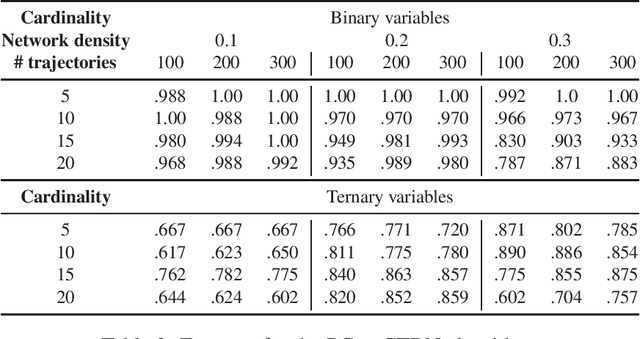
Dynamic Bayesian networks have been well explored in the literature as discrete-time models; however, their continuous-time extensions have seen comparatively little attention. In this paper, we propose the first constraint-based algorithm for learning the structure of continuous-time Bayesian networks. We discuss the different statistical tests and the underlying hypotheses used by our proposal to establish conditional independence. Finally, we validate its performance using synthetic data, and discuss its strengths and limitations. We find that score-based is more accurate in learning networks with binary variables, while our constraint-based approach is more accurate with variables assuming more than two values. However, more experiments are needed for confirmation.
Local Directional Gradient Pattern: A Local Descriptor for Face Recognition
Jan 03, 2022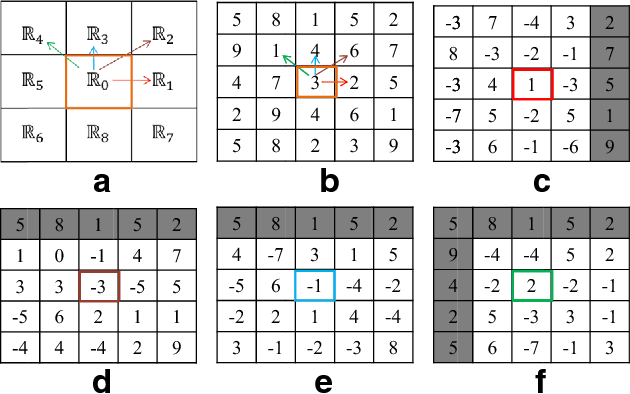

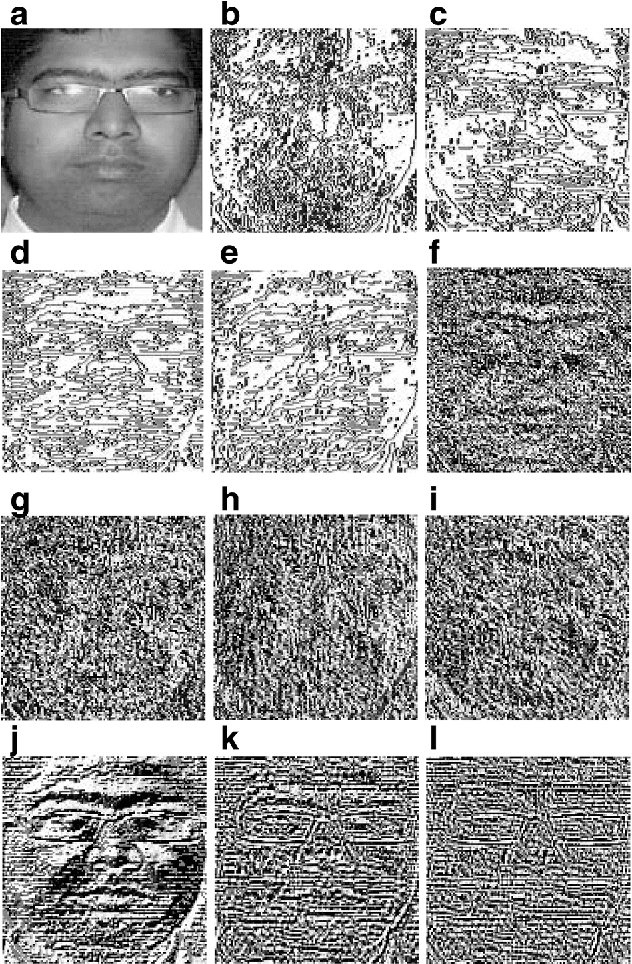
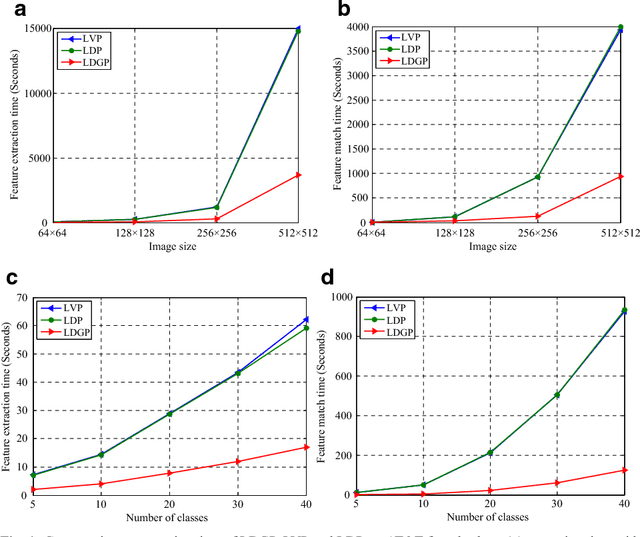
In this paper a local pattern descriptor in high order derivative space is proposed for face recognition. The proposed local directional gradient pattern (LDGP) is a 1D local micropattern computed by encoding the relationships between the higher order derivatives of the reference pixel in four distinct directions. The proposed descriptor identifies the relationship between the high order derivatives of the referenced pixel in four different directions to compute the micropattern which corresponds to the local feature. Proposed descriptor considerably reduces the length of the micropattern which consequently reduces the extraction time and matching time while maintaining the recognition rate. Results of the extensive experiments conducted on benchmark databases AT&T, Extended Yale B and CMU-PIE show that the proposed descriptor significantly reduces the extraction as well as matching time while the recognition rate is almost similar to the existing state of the art methods.
On the complexity of All $\varepsilon$-Best Arms Identification
Feb 13, 2022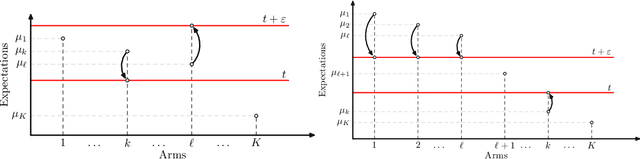
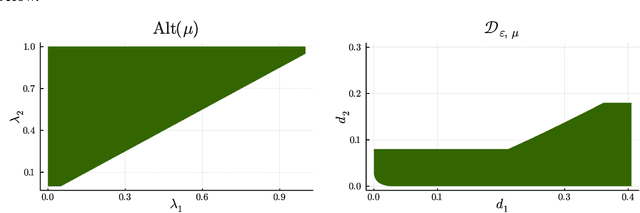
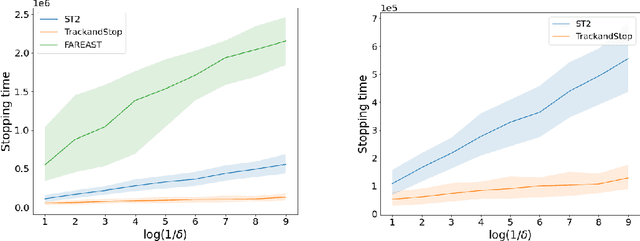
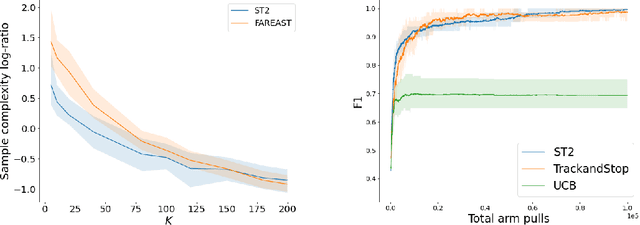
We consider the problem introduced by \cite{Mason2020} of identifying all the $\varepsilon$-optimal arms in a finite stochastic multi-armed bandit with Gaussian rewards. In the fixed confidence setting, we give a lower bound on the number of samples required by any algorithm that returns the set of $\varepsilon$-good arms with a failure probability less than some risk level $\delta$. This bound writes as $T_{\varepsilon}^*(\mu)\log(1/\delta)$, where $T_{\varepsilon}^*(\mu)$ is a characteristic time that depends on the vector of mean rewards $\mu$ and the accuracy parameter $\varepsilon$. We also provide an efficient numerical method to solve the convex max-min program that defines the characteristic time. Our method is based on a complete characterization of the alternative bandit instances that the optimal sampling strategy needs to rule out, thus making our bound tighter than the one provided by \cite{Mason2020}. Using this method, we propose a Track-and-Stop algorithm that identifies the set of $\varepsilon$-good arms w.h.p and enjoys asymptotic optimality (when $\delta$ goes to zero) in terms of the expected sample complexity. Finally, using numerical simulations, we demonstrate our algorithm's advantage over state-of-the-art methods, even for moderate values of the risk parameter.
Private Sequential Hypothesis Testing for Statisticians: Privacy, Error Rates, and Sample Size
Apr 10, 2022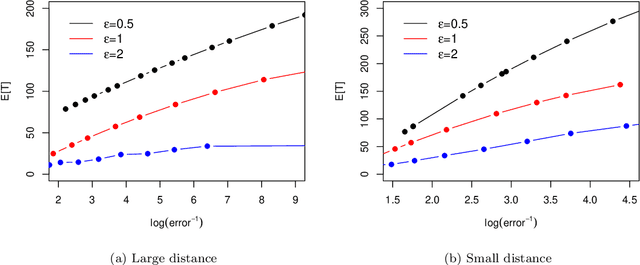
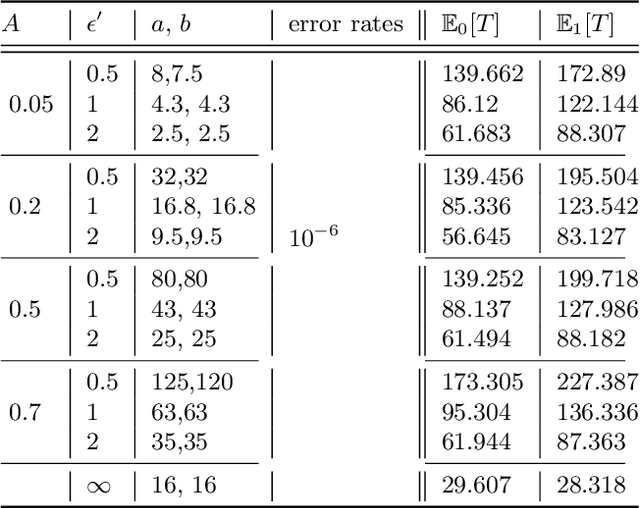
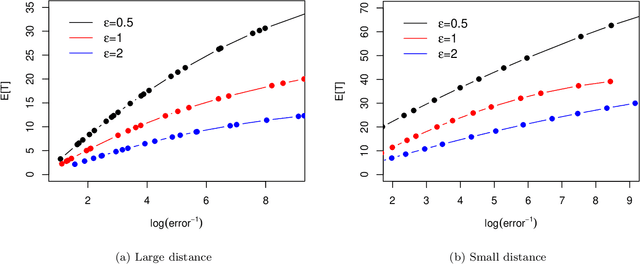
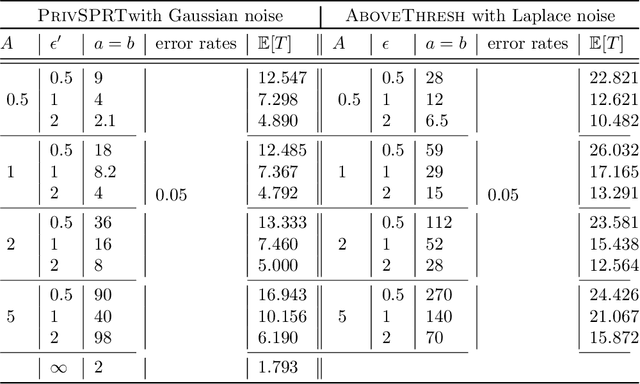
The sequential hypothesis testing problem is a class of statistical analyses where the sample size is not fixed in advance. Instead, the decision-process takes in new observations sequentially to make real-time decisions for testing an alternative hypothesis against a null hypothesis until some stopping criterion is satisfied. In many common applications of sequential hypothesis testing, the data can be highly sensitive and may require privacy protection; for example, sequential hypothesis testing is used in clinical trials, where doctors sequentially collect data from patients and must determine when to stop recruiting patients and whether the treatment is effective. The field of differential privacy has been developed to offer data analysis tools with strong privacy guarantees, and has been commonly applied to machine learning and statistical tasks. In this work, we study the sequential hypothesis testing problem under a slight variant of differential privacy, known as Renyi differential privacy. We present a new private algorithm based on Wald's Sequential Probability Ratio Test (SPRT) that also gives strong theoretical privacy guarantees. We provide theoretical analysis on statistical performance measured by Type I and Type II error as well as the expected sample size. We also empirically validate our theoretical results on several synthetic databases, showing that our algorithms also perform well in practice. Unlike previous work in private hypothesis testing that focused only on the classical fixed sample setting, our results in the sequential setting allow a conclusion to be reached much earlier, and thus saving the cost of collecting additional samples.