 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning to Adapt Clinical Sequences with Residual Mixture of Experts
Apr 06, 2022
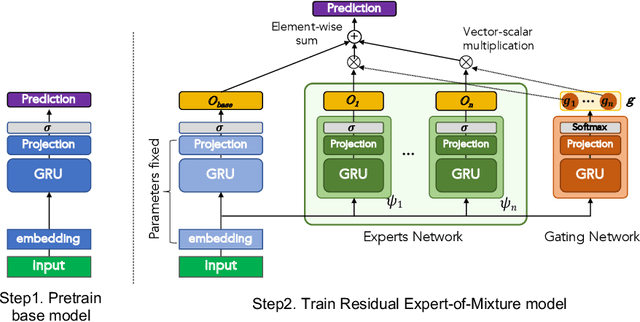

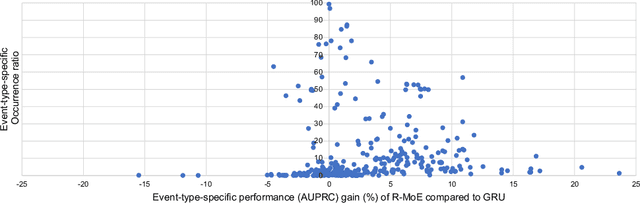
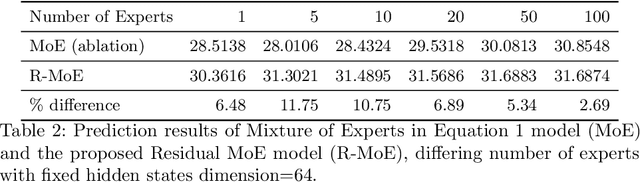
Clinical event sequences in Electronic Health Records (EHRs) record detailed information about the patient condition and patient care as they occur in time. Recent years have witnessed increased interest of machine learning community in developing machine learning models solving different types of problems defined upon information in EHRs. More recently, neural sequential models, such as RNN and LSTM, became popular and widely applied models for representing patient sequence data and for predicting future events or outcomes based on such data. However, a single neural sequential model may not properly represent complex dynamics of all patients and the differences in their behaviors. In this work, we aim to alleviate this limitation by refining a one-fits-all model using a Mixture-of-Experts (MoE) architecture. The architecture consists of multiple (expert) RNN models covering patient sub-populations and refining the predictions of the base model. That is, instead of training expert RNN models from scratch we define them on the residual signal that attempts to model the differences from the population-wide model. The heterogeneity of various patient sequences is modeled through multiple experts that consist of RNN. Particularly, instead of directly training MoE from scratch, we augment MoE based on the prediction signal from pretrained base GRU model. With this way, the mixture of experts can provide flexible adaptation to the (limited) predictive power of the single base RNN model. We experiment with the newly proposed model on real-world EHRs data and the multivariate clinical event prediction task. We implement RNN using Gated Recurrent Units (GRU). We show 4.1% gain on AUPRC statistics compared to a single RNN prediction.
On the link between conscious function and general intelligence in humans and machines
Mar 24, 2022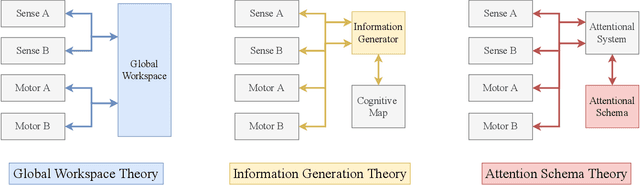
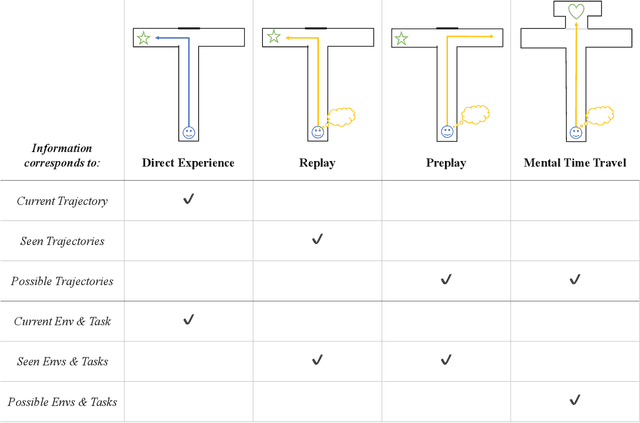
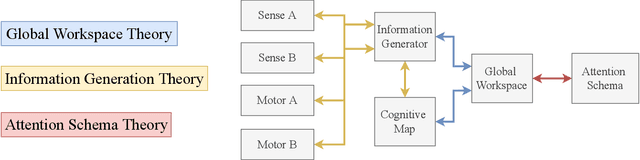
In popular media, there is often a connection drawn between the advent of awareness in artificial agents and those same agents simultaneously achieving human or superhuman level intelligence. In this work, we explore the validity and potential application of this seemingly intuitive link between consciousness and intelligence. We do so by examining the cognitive abilities associated with three contemporary theories of conscious function: Global Workspace Theory (GWT), Information Generation Theory (IGT), and Attention Schema Theory (AST). We find that all three theories specifically relate conscious function to some aspect of domain-general intelligence in humans. With this insight, we turn to the field of Artificial Intelligence (AI) and find that, while still far from demonstrating general intelligence, many state-of-the-art deep learning methods have begun to incorporate key aspects of each of the three functional theories. Given this apparent trend, we use the motivating example of mental time travel in humans to propose ways in which insights from each of the three theories may be combined into a unified model. We believe that doing so can enable the development of artificial agents which are not only more generally intelligent but are also consistent with multiple current theories of conscious function.
Key Point Agnostic Frequency-Selective Mesh-to-Grid Image Resampling using Spectral Weighting
Mar 15, 2022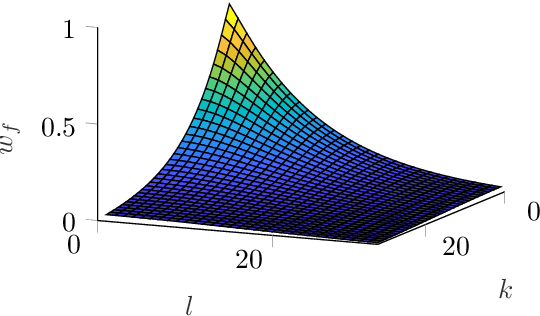
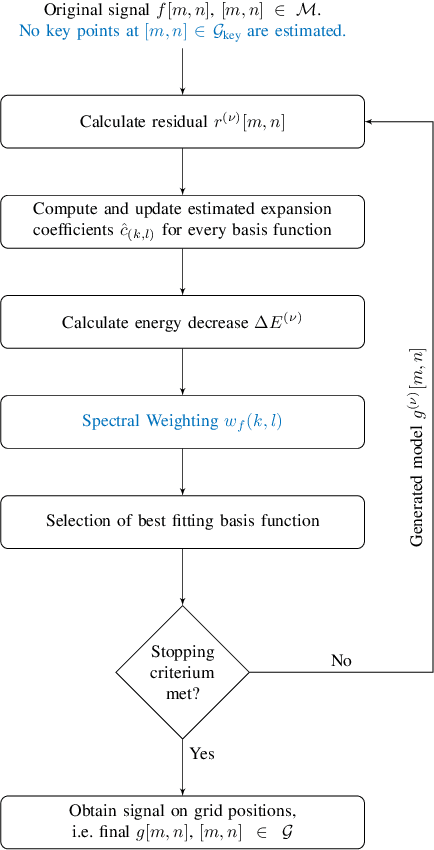
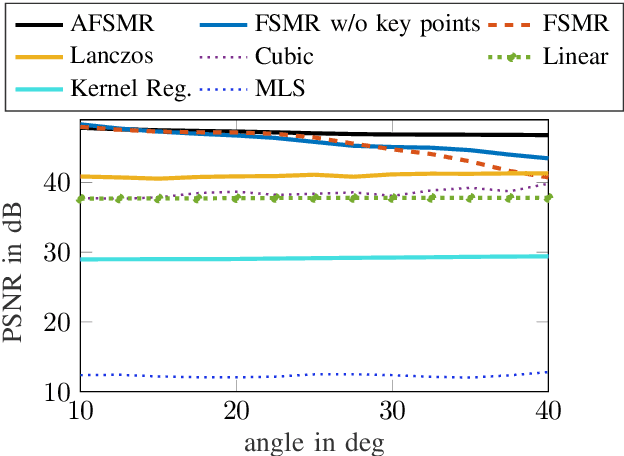

Many applications in image processing require resampling of arbitrarily located samples onto regular grid positions. This is important in frame-rate up-conversion, super-resolution, and image warping among others. A state-of-the-art high quality model-based resampling technique is frequency-selective mesh-to-grid resampling which requires pre-estimation of key points. In this paper, we propose a new key point agnostic frequency-selective mesh-to-grid resampling that does not depend on pre-estimated key points. Hence, the number of data points that are included is reduced drastically and the run time decreases significantly. To compensate for the key points, a spectral weighting function is introduced that models the optical transfer function in order to favor low frequencies more than high ones. Thereby, resampling artefacts like ringing are supressed reliably and the resampling quality increases. On average, the new AFSMR is conceptually simpler and gains up to 1.2 dB in terms of PSNR compared to the original mesh-to-grid resampling while being approximately 14.5 times faster.
* 6 pages, 5 figures; Originally submitted to IEEE MMSP 2020
Winning solutions and post-challenge analyses of the ChaLearn AutoDL challenge 2019
Jan 11, 2022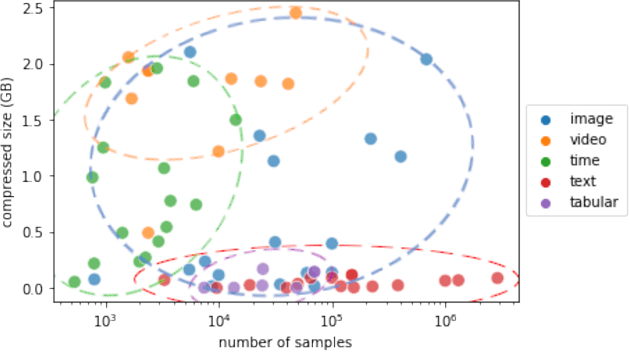
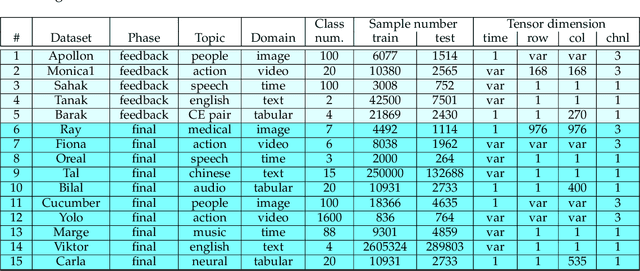
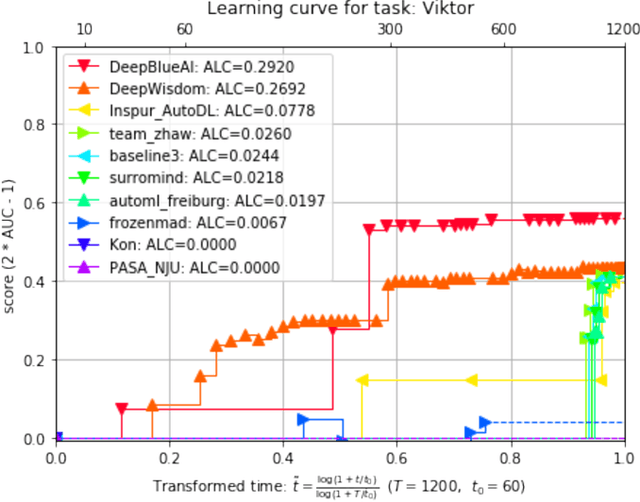
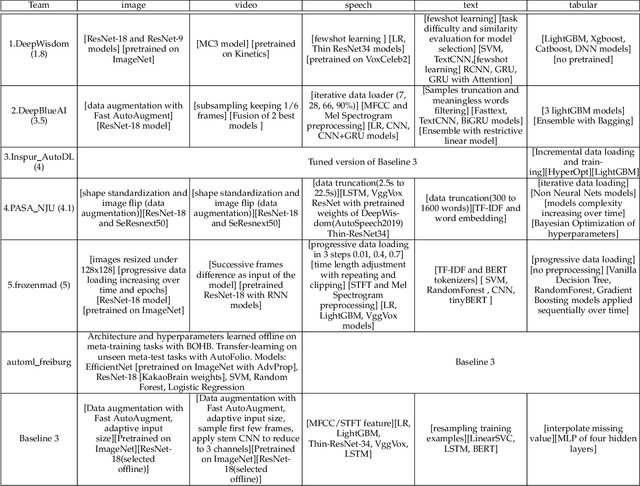
This paper reports the results and post-challenge analyses of ChaLearn's AutoDL challenge series, which helped sorting out a profusion of AutoML solutions for Deep Learning (DL) that had been introduced in a variety of settings, but lacked fair comparisons. All input data modalities (time series, images, videos, text, tabular) were formatted as tensors and all tasks were multi-label classification problems. Code submissions were executed on hidden tasks, with limited time and computational resources, pushing solutions that get results quickly. In this setting, DL methods dominated, though popular Neural Architecture Search (NAS) was impractical. Solutions relied on fine-tuned pre-trained networks, with architectures matching data modality. Post-challenge tests did not reveal improvements beyond the imposed time limit. While no component is particularly original or novel, a high level modular organization emerged featuring a "meta-learner", "data ingestor", "model selector", "model/learner", and "evaluator". This modularity enabled ablation studies, which revealed the importance of (off-platform) meta-learning, ensembling, and efficient data management. Experiments on heterogeneous module combinations further confirm the (local) optimality of the winning solutions. Our challenge legacy includes an ever-lasting benchmark (http://autodl.chalearn.org), the open-sourced code of the winners, and a free "AutoDL self-service".
* The first three authors contributed equally; This is only a draft version
Interactive Robotic Grasping with Attribute-Guided Disambiguation
Mar 15, 2022
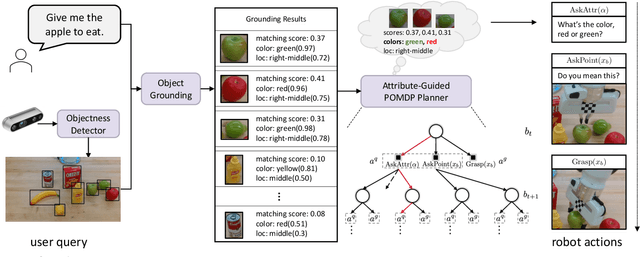

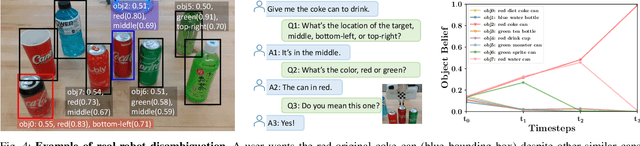
Interactive robotic grasping using natural language is one of the most fundamental tasks in human-robot interaction. However, language can be a source of ambiguity, particularly when there are ambiguous visual or linguistic contents. This paper investigates the use of object attributes in disambiguation and develops an interactive grasping system capable of effectively resolving ambiguities via dialogues. Our approach first predicts target scores and attribute scores through vision-and-language grounding. To handle ambiguous objects and commands, we propose an attribute-guided formulation of the partially observable Markov decision process (Attr-POMDP) for disambiguation. The Attr-POMDP utilizes target and attribute scores as the observation model to calculate the expected return of an attribute-based (e.g., "what is the color of the target, red or green?") or a pointing-based (e.g., "do you mean this one?") question. Our disambiguation module runs in real time on a real robot, and the interactive grasping system achieves a 91.43\% selection accuracy in the real-robot experiments, outperforming several baselines by large margins.
Text-free non-parallel many-to-many voice conversion using normalising flows
Mar 15, 2022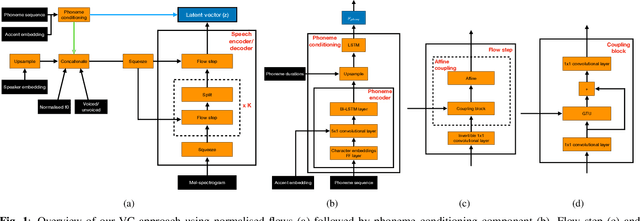
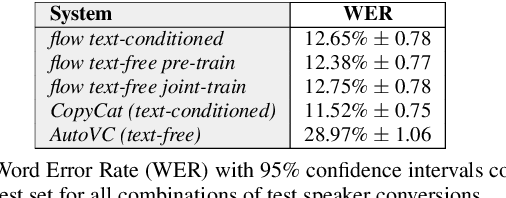
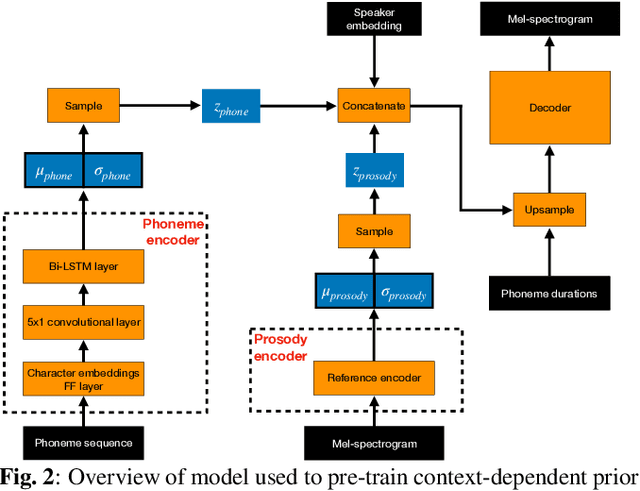
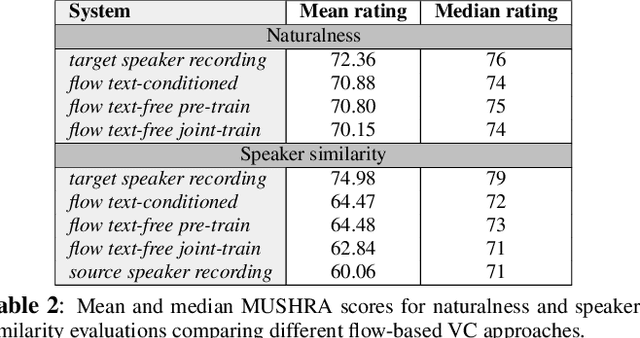
Non-parallel voice conversion (VC) is typically achieved using lossy representations of the source speech. However, ensuring only speaker identity information is dropped whilst all other information from the source speech is retained is a large challenge. This is particularly challenging in the scenario where at inference-time we have no knowledge of the text being read, i.e., text-free VC. To mitigate this, we investigate information-preserving VC approaches. Normalising flows have gained attention for text-to-speech synthesis, however have been under-explored for VC. Flows utilize invertible functions to learn the likelihood of the data, thus provide a lossless encoding of speech. We investigate normalising flows for VC in both text-conditioned and text-free scenarios. Furthermore, for text-free VC we compare pre-trained and jointly-learnt priors. Flow-based VC evaluations show no degradation between text-free and text-conditioned VC, resulting in improvements over the state-of-the-art. Also, joint-training of the prior is found to negatively impact text-free VC quality.
Language-Preserving Reduction Rules for Block-Structured Workflow Nets
Mar 19, 2022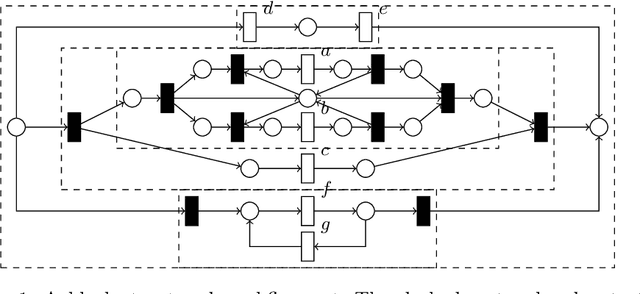
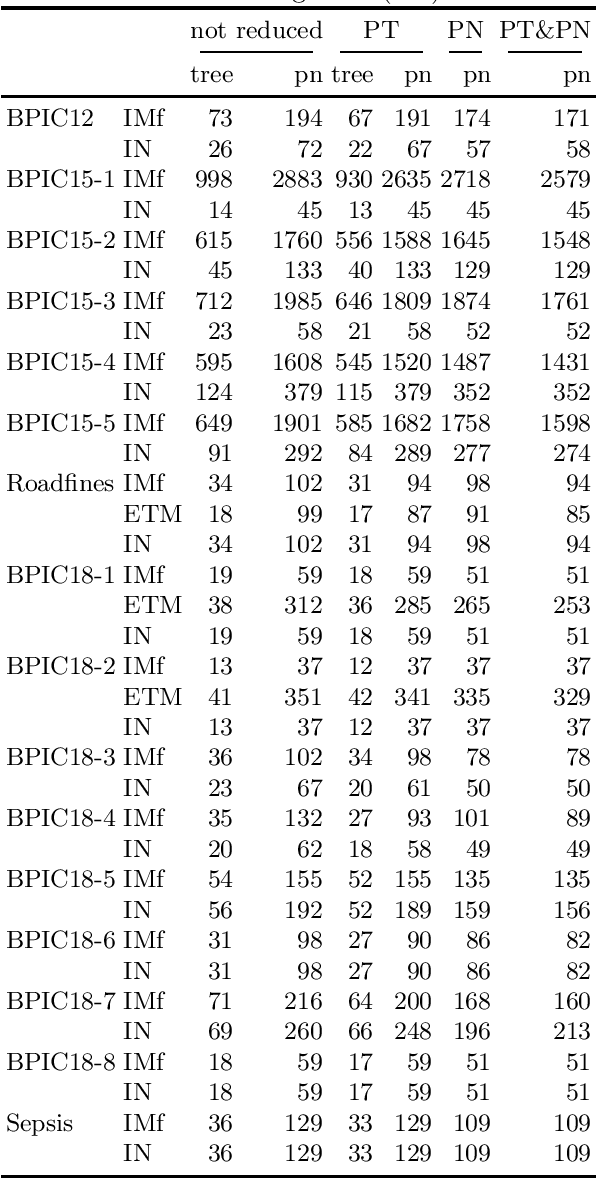
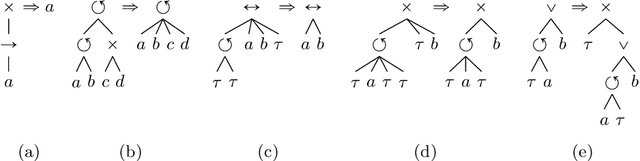
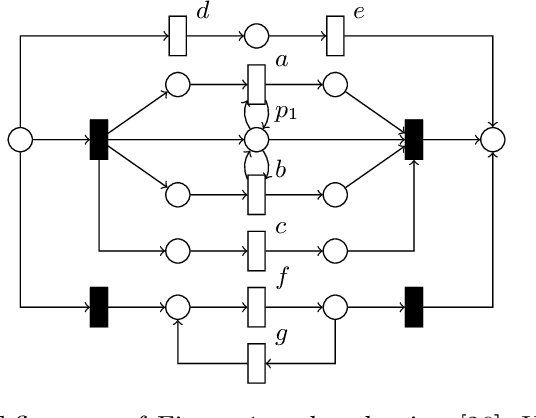
Process models are used by human analysts to model and analyse behaviour, and by machines to verify properties such as soundness, liveness or other reachability properties, and to compare their expressed behaviour with recorded behaviour within business processes of organisations. For both human and machine use, small models are preferable over large and complex models: for ease of human understanding and to reduce the time spent by machines in state space explorations. Reduction rules that preserve the behaviour of models have been defined for Petri nets, however in this paper we show that a subclass of Petri nets returned by process discovery techniques, that is, block-structured workflow nets, can be further reduced by considering their block structure in process trees. We revisit an existing set of reduction rules for process trees and show that the rules are correct, terminating, confluent and complete, and for which classes of process trees they are and are not complete. In a real-life experiment, we show that these rules can reduce process models discovered from real-life event logs further compared with rules that consider only Petri net structures.
Introducing Randomized High Order Fuzzy Cognitive Maps as Reservoir Computing Models: A Case Study in Solar Energy and Load Forecasting
Jan 07, 2022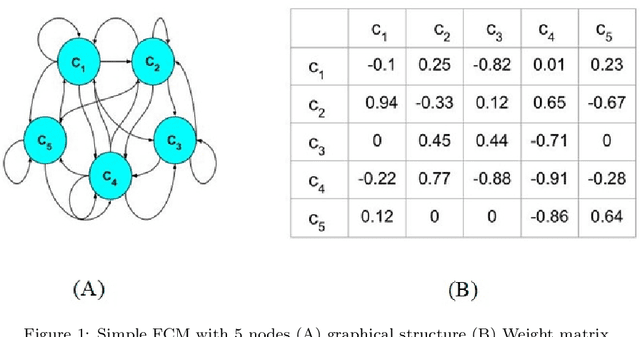

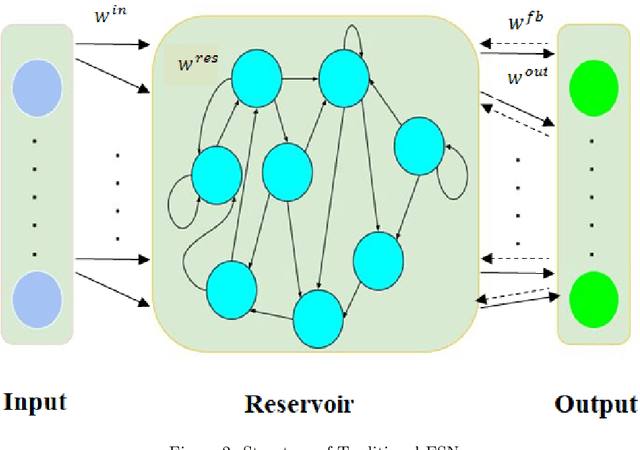

Fuzzy Cognitive Maps (FCMs) have emerged as an interpretable signed weighted digraph method consisting of nodes (concepts) and weights which represent the dependencies among the concepts. Although FCMs have attained considerable achievements in various time series prediction applications, designing an FCM model with time-efficient training method is still an open challenge. Thus, this paper introduces a novel univariate time series forecasting technique, which is composed of a group of randomized high order FCM models labeled R-HFCM. The novelty of the proposed R-HFCM model is relevant to merging the concepts of FCM and Echo State Network (ESN) as an efficient and particular family of Reservoir Computing (RC) models, where the least squares algorithm is applied to train the model. From another perspective, the structure of R-HFCM consists of the input layer, reservoir layer, and output layer in which only the output layer is trainable while the weights of each sub-reservoir components are selected randomly and keep constant during the training process. As case studies, this model considers solar energy forecasting with public data for Brazilian solar stations as well as Malaysia dataset, which includes hourly electric load and temperature data of the power supply company of the city of Johor in Malaysia. The experiment also includes the effect of the map size, activation function, the presence of bias and the size of the reservoir on the accuracy of R-HFCM method. The obtained results confirm the outperformance of the proposed R-HFCM model in comparison to the other methods. This study provides evidence that FCM can be a new way to implement a reservoir of dynamics in time series modelling.
Choice of technology and evaluation of the production capabilities of a 3d printer robot for creating elements of experimental equipment for the production of biofuel components
Feb 02, 2022Elements of experimental equipment for the production of biofuel components must meet high reliability and safety requirements. At the same time, in the course of research on the subject of creating equipment for the production of biofuels, a variable range of equipment is regularly proposed and should be checked. The manufacture of elements of such equipment by traditional methods is expensive and inefficient, time-consuming, which negatively affects the speed of scientific research. To this end, it is proposed to develop a robotic 3D printing complex that provides maximum flexibility in creating mock-ups and test samples of equipment for the production of biofuel components. The article discusses the experience of successfully creating equipment elements for the production of fuels using 3d printing. Next, the choice of a robotization scheme for a 3D printing installation is described and the choice of printing technology is substantiated. The article also presents the results of calculating the parameters of the 3v-printer robot and the results of calculating the similarity parameters for the implementation and evaluation of control algorithms. The results of a numerical experiment for calculating the strength characteristics of equipment elements manufactured using the selected 3d printing technology are presented.
Vid-ODE: Continuous-Time Video Generation with Neural Ordinary Differential Equation
Oct 16, 2020
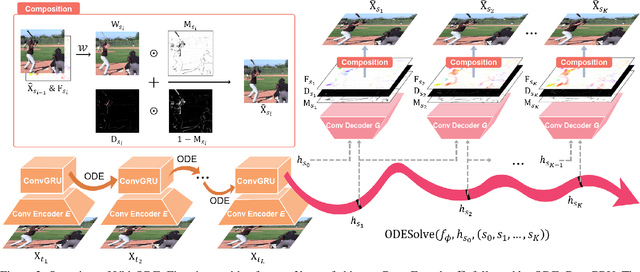
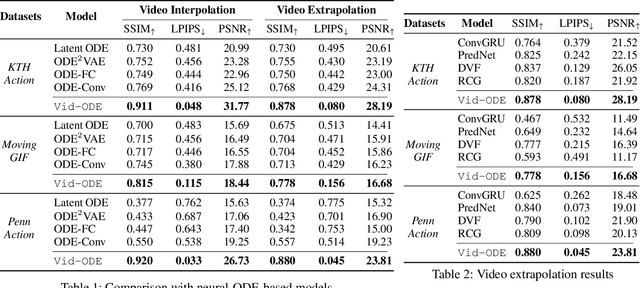

Video generation models often operate under the assumption of fixed frame rates, which leads to suboptimal performance when it comes to handling flexible frame rates (e.g., increasing the frame rate of more dynamic portion of the video as well as handling missing video frames). To resolve the restricted nature of existing video generation models' ability to handle arbitrary timesteps, we propose continuous-time video generation by combining neural ODE (Vid-ODE) with pixel-level video processing techniques. Using ODE-ConvGRU as an encoder, a convolutional version of the recently proposed neural ODE, which enables us to learn continuous-time dynamics, Vid-ODE can learn the spatio-temporal dynamics of input videos of flexible frame rates. The decoder integrates the learned dynamics function to synthesize video frames at any given timesteps, where the pixel-level composition technique is used to maintain the sharpness of individual frames. With extensive experiments on four real-world video datasets, we verify that the proposed Vid-ODE outperforms state-of-the-art approaches under various video generation settings, both within the trained time range (interpolation) and beyond the range (extrapolation). To the best of our knowledge, Vid-ODE is the first work successfully performing continuous-time video generation using real-world videos.