 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A sinusoidal signal reconstruction method for the inversion of the mel-spectrogram
Jan 07, 2022
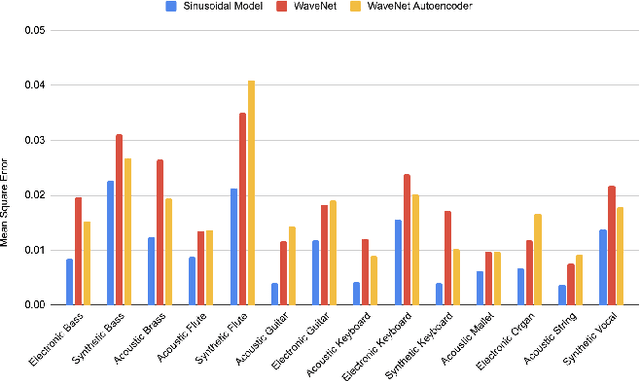
The synthesis of sound via deep learning methods has recently received much attention. Some problems for deep learning approaches to sound synthesis relate to the amount of data needed to specify an audio signal and the necessity of preserving both the long and short time coherence of the synthesised signal. Visual time-frequency representations such as the log-mel-spectrogram have gained in popularity. The log-mel-spectrogram is a perceptually informed representation of audio that greatly compresses the amount of information required for the description of the sound. However, because of this compression, this representation is not directly invertible. Both signal processing and machine learning techniques have previously been applied to the inversion of the log-mel-spectrogram but they both caused audible distortions in the synthesized sounds due to issues of temporal and spectral coherence. In this paper, we outline the application of a sinusoidal model to the inversion of the log-mel-spectrogram for pitched musical instrument sounds outperforming state-of-the-art deep learning methods. The approach could be later used as a general decoding step from spectral to time intervals in neural applications.
A Continuous-Time Approach for 3D Radar-to-Camera Extrinsic Calibration
Mar 12, 2021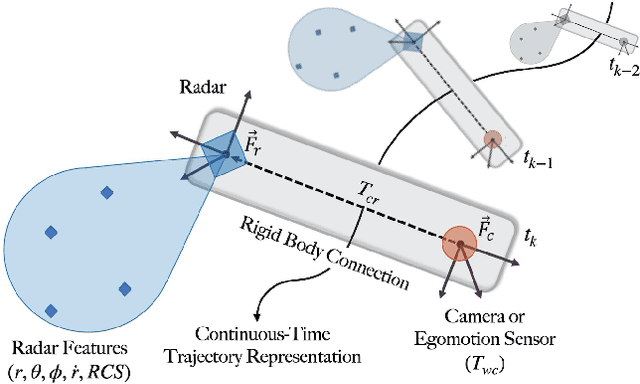
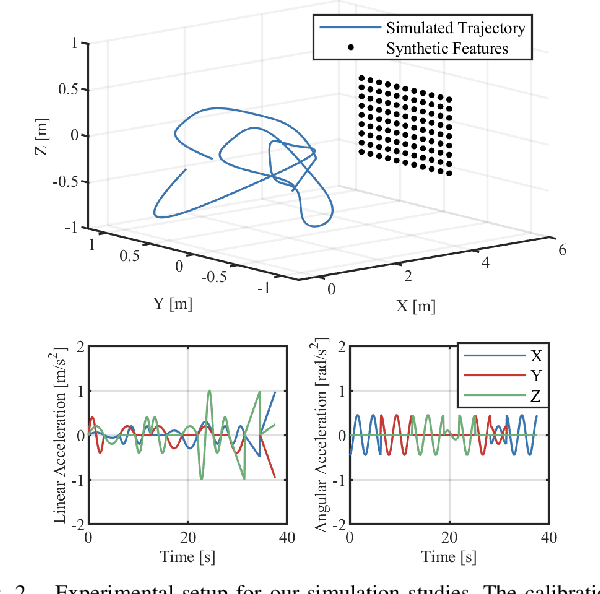
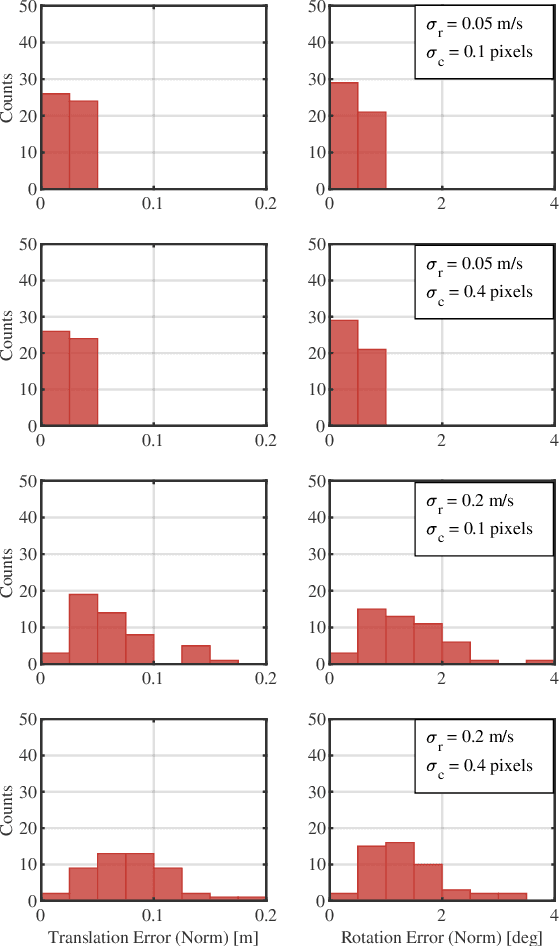

Reliable operation in inclement weather is essential to the deployment of safe autonomous vehicles (AVs). Robustness and reliability can be achieved by fusing data from the standard AV sensor suite (i.e., lidars, cameras) with weather robust sensors, such as millimetre-wavelength radar. Critically, accurate sensor data fusion requires knowledge of the rigid-body transform between sensor pairs, which can be determined through the process of extrinsic calibration. A number of extrinsic calibration algorithms have been designed for 2D (planar) radar sensors - however, recently-developed, low-cost 3D millimetre-wavelength radars are set to displace their 2D counterparts in many applications. In this paper, we present a continuous-time 3D radar-to-camera extrinsic calibration algorithm that utilizes radar velocity measurements and, unlike the majority of existing techniques, does not require specialized radar retroreflectors to be present in the environment. We derive the observability properties of our formulation and demonstrate the efficacy of our algorithm through synthetic and real-world experiments.
Graph Enhanced Contrastive Learning for Radiology Findings Summarization
Apr 01, 2022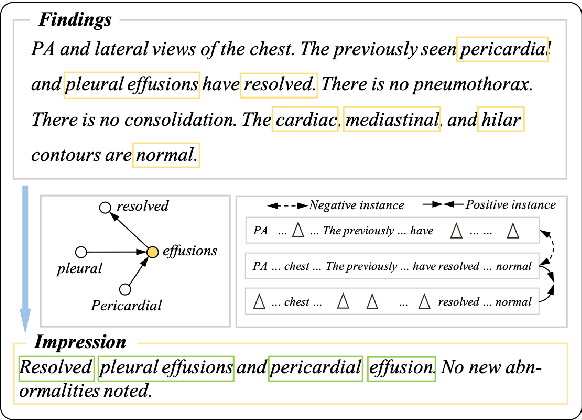
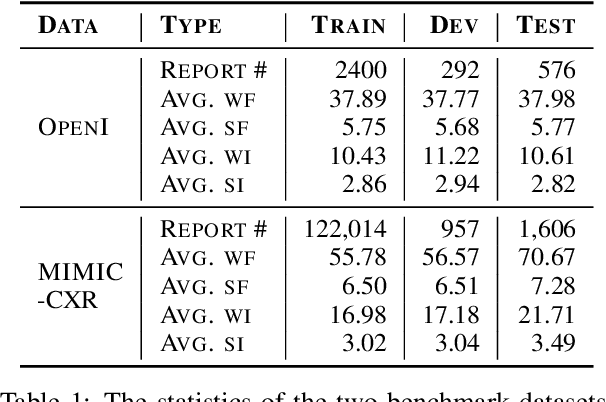
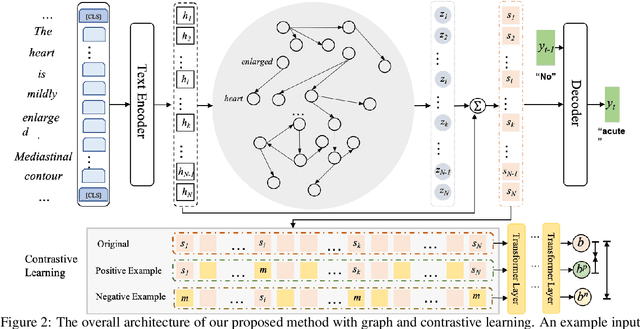
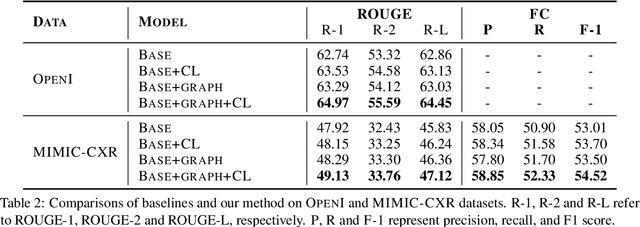
The impression section of a radiology report summarizes the most prominent observation from the findings section and is the most important section for radiologists to communicate to physicians. Summarizing findings is time-consuming and can be prone to error for inexperienced radiologists, and thus automatic impression generation has attracted substantial attention. With the encoder-decoder framework, most previous studies explore incorporating extra knowledge (e.g., static pre-defined clinical ontologies or extra background information). Yet, they encode such knowledge by a separate encoder to treat it as an extra input to their models, which is limited in leveraging their relations with the original findings. To address the limitation, we propose a unified framework for exploiting both extra knowledge and the original findings in an integrated way so that the critical information (i.e., key words and their relations) can be extracted in an appropriate way to facilitate impression generation. In detail, for each input findings, it is encoded by a text encoder, and a graph is constructed through its entities and dependency tree. Then, a graph encoder (e.g., graph neural networks (GNNs)) is adopted to model relation information in the constructed graph. Finally, to emphasize the key words in the findings, contrastive learning is introduced to map positive samples (constructed by masking non-key words) closer and push apart negative ones (constructed by masking key words). The experimental results on OpenI and MIMIC-CXR confirm the effectiveness of our proposed method.
Heterogeneous Ultra-Dense Networks with Traffic Hotspots: A Unified Handover Analysis
Apr 07, 2022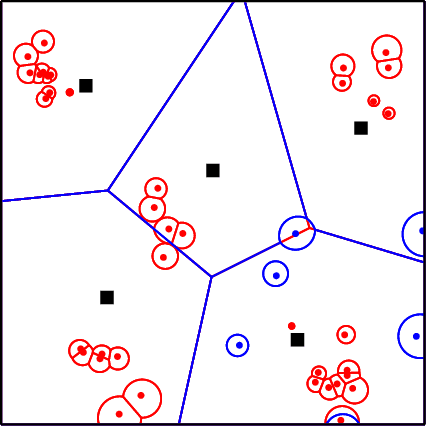
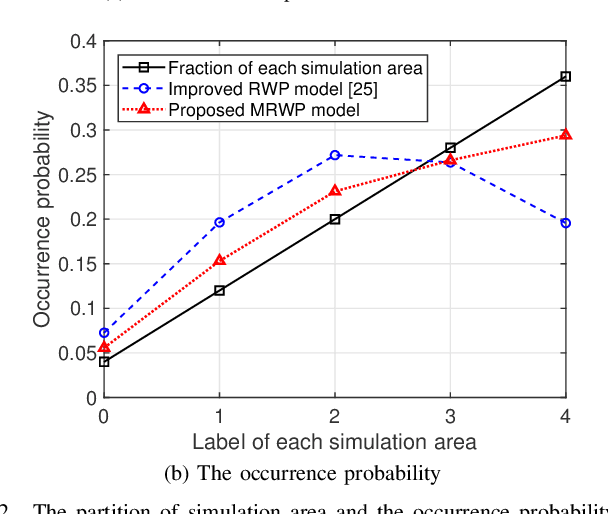
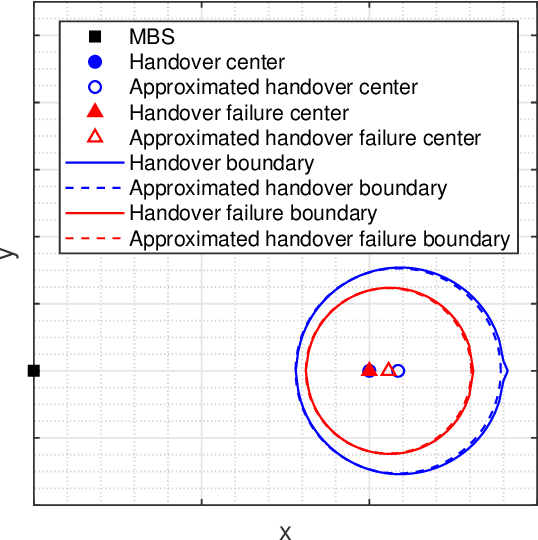
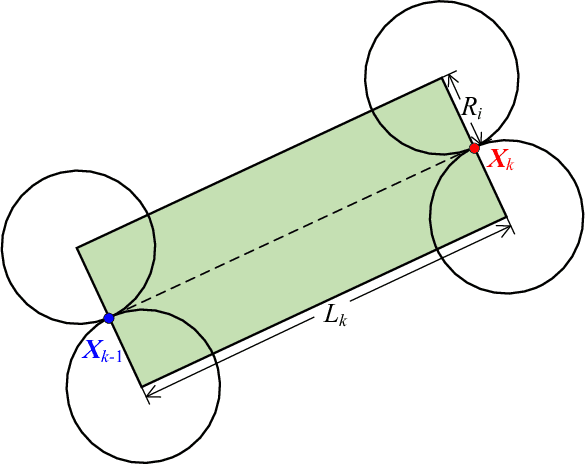
With the ever-growing communication demands and the unceasing miniaturization of mobile devices, the Internet of Things is expanding the amount of mobile terminals to an enormous level. To deal with such numbers of communication data, plenty of base stations (BSs) need to be deployed. However, denser deployments of heterogeneous networks (HetNets) lead to more frequent handovers, which could increase network burden and degrade the users experience, especially in traffic hotspot areas. In this paper, we develop a unified framework to investigate the handover performance of wireless networks with traffic hotspots. Using the stochastic geometry, we derive the theoretical expressions of average distances and handover metrics in HetNets, where the correlations between users and BSs in hotspots are captured. Specifically, the distributions of macro cells are modeled as independent Poisson point processes (PPPs), and the two tiers of small cells outside and inside the hotspots are modeled as PPP and Poisson cluster process (PCP) separately. A modified random waypoint (MRWP) model is also proposed to eliminate the density wave phenomenon in traditional models and to increase the accuracy of handover decision. By combining the PCP and MRWP model, the distributions of distances from a typical terminal to the BSs in different tiers are derived. Afterwards, we derive the expressions of average distances from a typical terminal to different BSs, and reveal that the handover rate, handover failure rate, and ping-pong rate are deduced as the functions of BS density, scattering variance of clustered small cell, user velocity, and threshold of triggered time. Simulation results verify the accuracy of the proposed analytical model and closed-form theoretical expressions.
Time-Based Roofline for Deep Learning Performance Analysis
Sep 22, 2020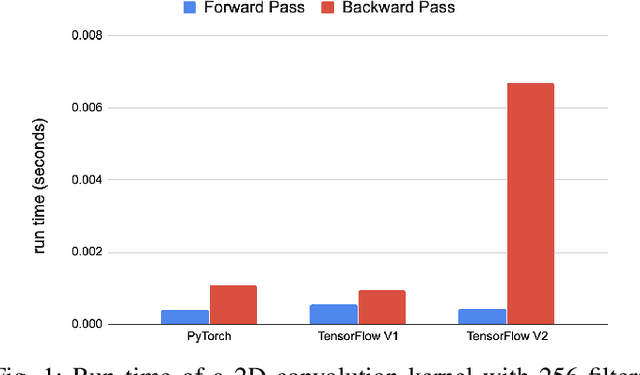
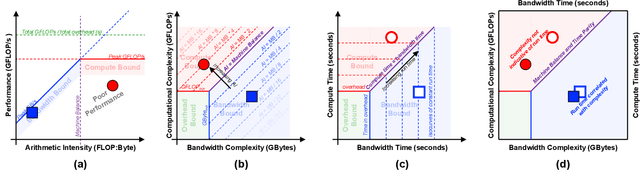
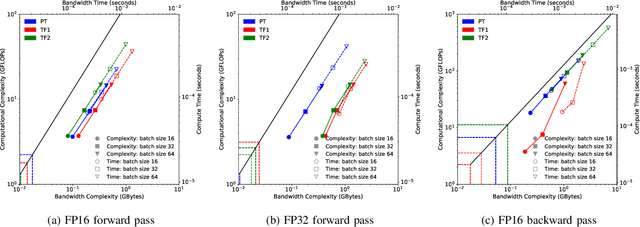
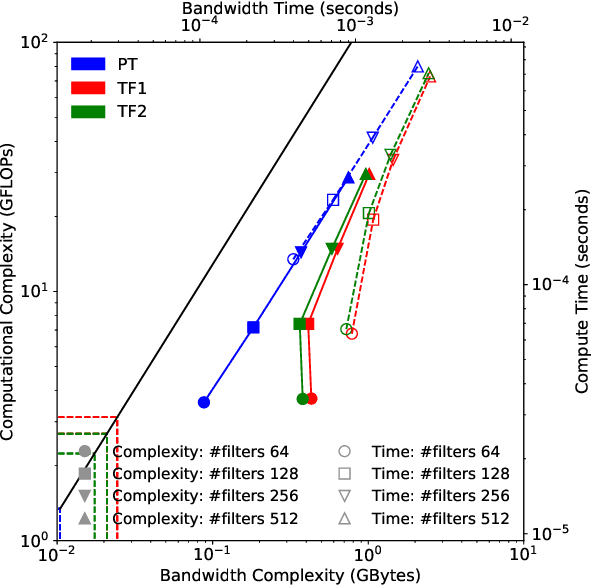
Deep learning applications are usually very compute-intensive and require a long run time for training and inference. This has been tackled by researchers from both hardware and software sides, and in this paper, we propose a Roofline-based approach to performance analysis to facilitate the optimization of these applications. This approach is an extension of the Roofline model widely used in traditional high-performance computing applications, and it incorporates both compute/bandwidth complexity and run time in its formulae to provide insights into deep learning-specific characteristics. We take two sets of representative kernels, 2D convolution and long short-term memory, to validate and demonstrate the use of this new approach, and investigate how arithmetic intensity, cache locality, auto-tuning, kernel launch overhead, and Tensor Core usage can affect performance. Compared to the common ad-hoc approach, this study helps form a more systematic way to analyze code performance and identify optimization opportunities for deep learning applications.
Deep AutoAugment
Mar 11, 2022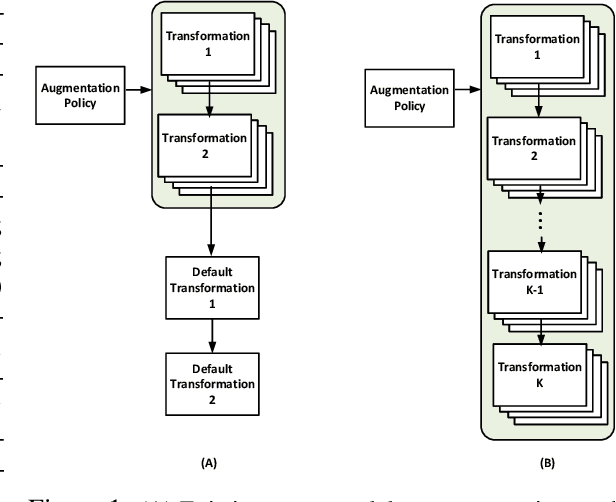


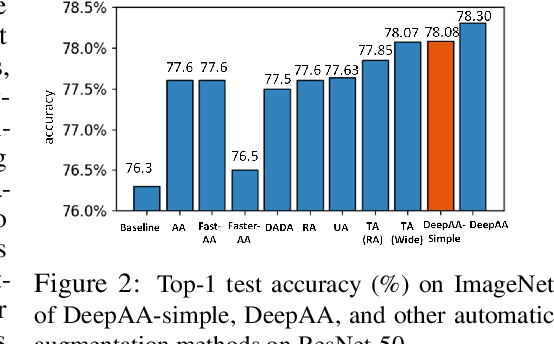
While recent automated data augmentation methods lead to state-of-the-art results, their design spaces and the derived data augmentation strategies still incorporate strong human priors. In this work, instead of fixing a set of hand-picked default augmentations alongside the searched data augmentations, we propose a fully automated approach for data augmentation search named Deep AutoAugment (DeepAA). DeepAA progressively builds a multi-layer data augmentation pipeline from scratch by stacking augmentation layers one at a time until reaching convergence. For each augmentation layer, the policy is optimized to maximize the cosine similarity between the gradients of the original and augmented data along the direction with low variance. Our experiments show that even without default augmentations, we can learn an augmentation policy that achieves strong performance with that of previous works. Extensive ablation studies show that the regularized gradient matching is an effective search method for data augmentation policies. Our code is available at: https://github.com/MSU-MLSys-Lab/DeepAA .
Single-shot Embedding Dimension Search in Recommender System
Apr 07, 2022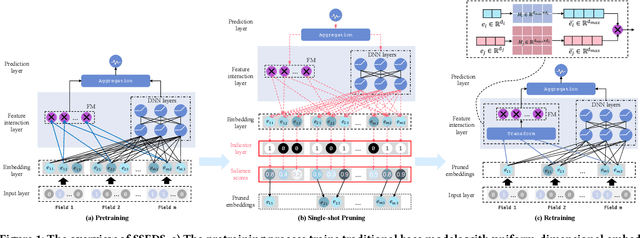
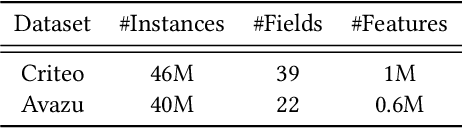
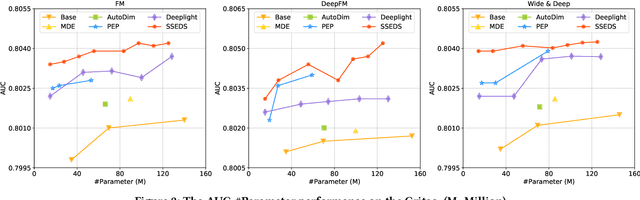
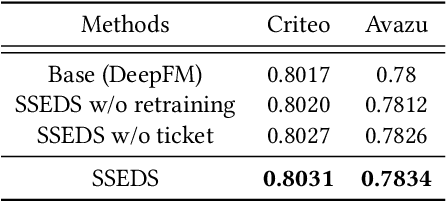
As a crucial component of most modern deep recommender systems, feature embedding maps high-dimensional sparse user/item features into low-dimensional dense embeddings. However, these embeddings are usually assigned a unified dimension, which suffers from the following issues: (1) high memory usage and computation cost. (2) sub-optimal performance due to inferior dimension assignments. In order to alleviate the above issues, some works focus on automated embedding dimension search by formulating it as hyper-parameter optimization or embedding pruning problems. However, they either require well-designed search space for hyperparameters or need time-consuming optimization procedures. In this paper, we propose a Single-Shot Embedding Dimension Search method, called SSEDS, which can efficiently assign dimensions for each feature field via a single-shot embedding pruning operation while maintaining the recommendation accuracy of the model. Specifically, it introduces a criterion for identifying the importance of each embedding dimension for each feature field. As a result, SSEDS could automatically obtain mixed-dimensional embeddings by explicitly reducing redundant embedding dimensions based on the corresponding dimension importance ranking and the predefined parameter budget. Furthermore, the proposed SSEDS is model-agnostic, meaning that it could be integrated into different base recommendation models. The extensive offline experiments are conducted on two widely used public datasets for CTR prediction tasks, and the results demonstrate that SSEDS can still achieve strong recommendation performance even if it has reduced 90\% parameters. Moreover, SSEDS has also been deployed on the WeChat Subscription platform for practical recommendation services. The 7-day online A/B test results show that SSEDS can significantly improve the performance of the online recommendation model.
Spatial-Temporal Sequential Hypergraph Network for Crime Prediction
Jan 07, 2022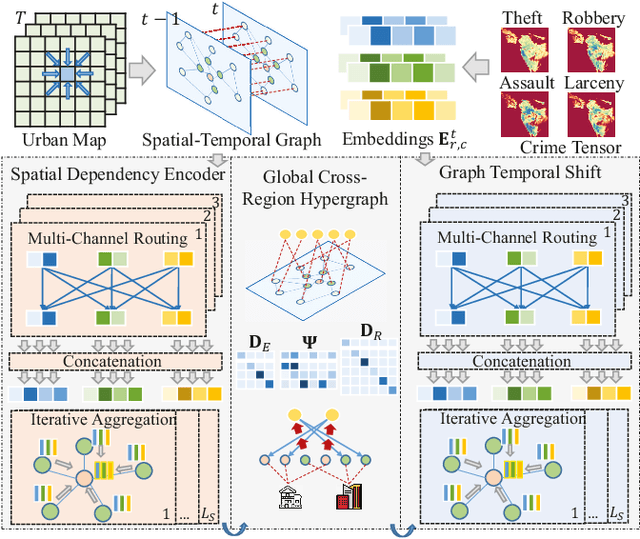
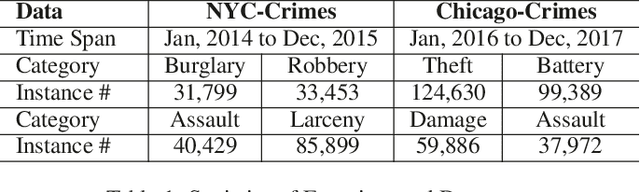
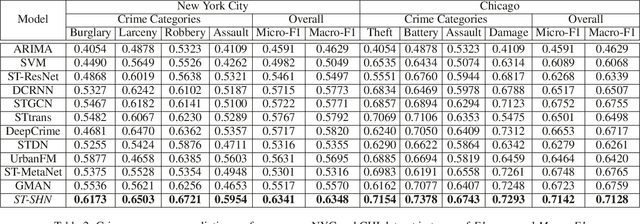
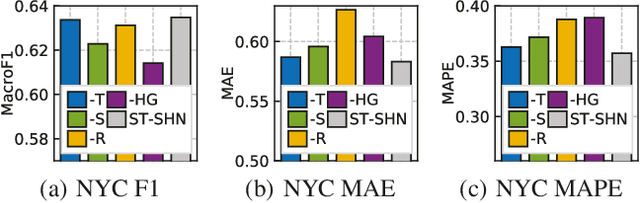
Crime prediction is crucial for public safety and resource optimization, yet is very challenging due to two aspects: i) the dynamics of criminal patterns across time and space, crime events are distributed unevenly on both spatial and temporal domains; ii) time-evolving dependencies between different types of crimes (e.g., Theft, Robbery, Assault, Damage) which reveal fine-grained semantics of crimes. To tackle these challenges, we propose Spatial-Temporal Sequential Hypergraph Network (ST-SHN) to collectively encode complex crime spatial-temporal patterns as well as the underlying category-wise crime semantic relationships. In specific, to handle spatial-temporal dynamics under the long-range and global context, we design a graph-structured message passing architecture with the integration of the hypergraph learning paradigm. To capture category-wise crime heterogeneous relations in a dynamic environment, we introduce a multi-channel routing mechanism to learn the time-evolving structural dependency across crime types. We conduct extensive experiments on two real-world datasets, showing that our proposed ST-SHN framework can significantly improve the prediction performance as compared to various state-of-the-art baselines. The source code is available at: https://github.com/akaxlh/ST-SHN.
A Survey for Deep RGBT Tracking
Jan 29, 2022
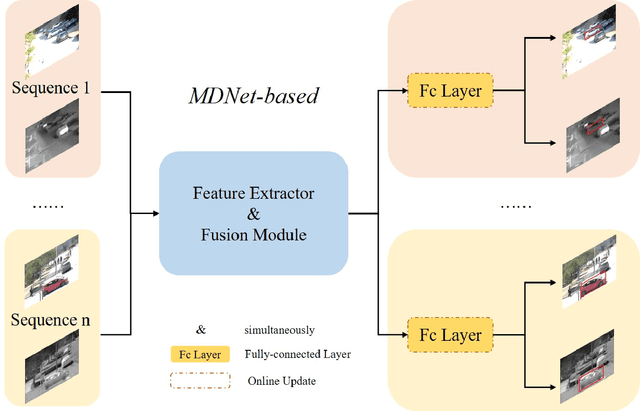
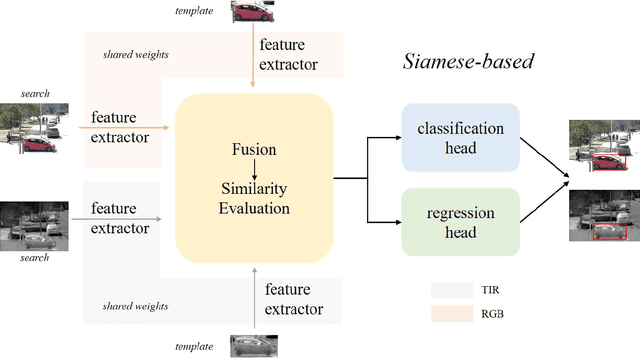
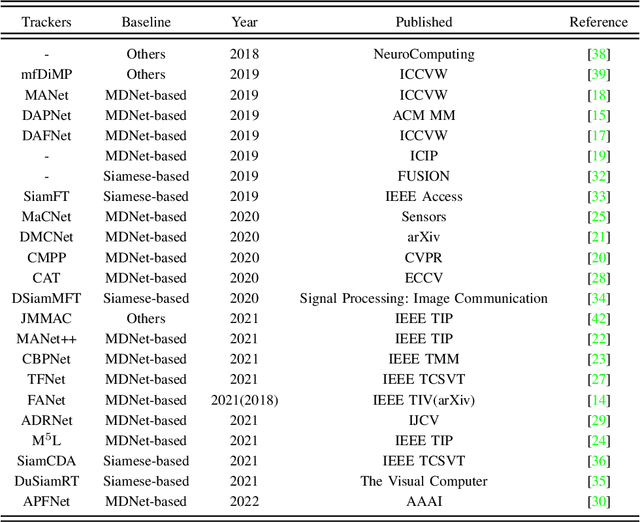
Visual object tracking with the visible (RGB) and thermal infrared (TIR) electromagnetic waves, shorted in RGBT tracking, recently draws increasing attention in the tracking community. Considering the rapid development of deep learning, a survey for the recent deep neural network based RGBT trackers is presented in this paper. Firstly, we give brief introduction for the RGBT trackers concluded into this category. Then, a comparison among the existing RGBT trackers on several challenging benchmarks is given statistically. Specifically, MDNet and Siamese architectures are the two mainstream frameworks in the RGBT community, especially the former. Trackers based on MDNet achieve higher performance while Siamese-based trackers satisfy the real-time requirement. In summary, since the large-scale dataset LasHeR is published, the integration of end-to-end framework, e.g., Siamese and Transformer, should be further considered to fulfil the real-time as well as more robust performance. Furthermore, the mathematical meaning should be more considered during designing the network. This survey can be treated as a look-up-table for researchers who are concerned about RGBT tracking.
Neuromorphic Data Augmentation for Training Spiking Neural Networks
Mar 11, 2022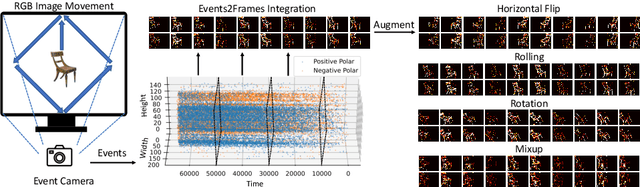
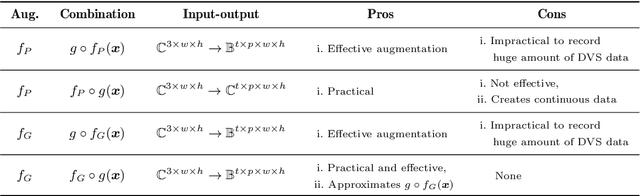
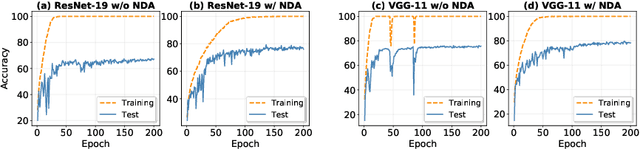

Developing neuromorphic intelligence on event-based datasets with spiking neural networks (SNNs) has recently attracted much research attention. However, the limited size of event-based datasets makes SNNs prone to overfitting and unstable convergence. This issue remains unexplored by previous academic works. In an effort to minimize this generalization gap, we propose neuromorphic data augmentation (NDA), a family of geometric augmentations specifically designed for event-based datasets with the goal of significantly stabilizing the SNN training and reducing the generalization gap between training and test performance. The proposed method is simple and compatible with existing SNN training pipelines. Using the proposed augmentation, for the first time, we demonstrate the feasibility of unsupervised contrastive learning for SNNs. We conduct comprehensive experiments on prevailing neuromorphic vision benchmarks and show that NDA yields substantial improvements over previous state-of-the-art results. For example, NDA-based SNN achieves accuracy gain on CIFAR10-DVS and N-Caltech 101 by 10.1% and 13.7%, respectively.