 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Feature visualization for convolutional neural network models trained on neuroimaging data
Mar 24, 2022
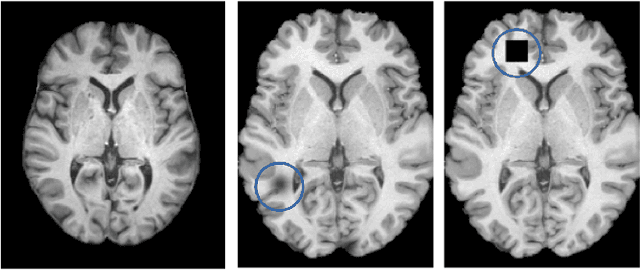
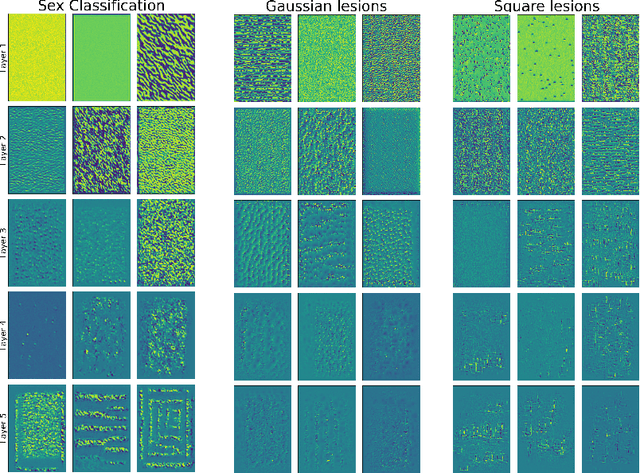
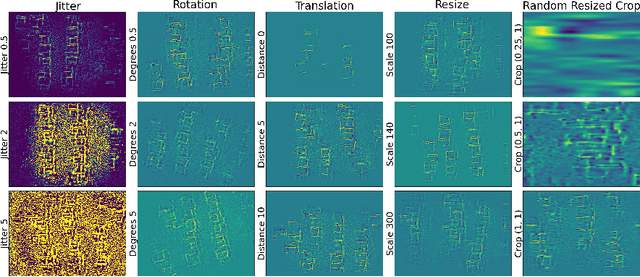
A major prerequisite for the application of machine learning models in clinical decision making is trust and interpretability. Current explainability studies in the neuroimaging community have mostly focused on explaining individual decisions of trained models, e.g. obtained by a convolutional neural network (CNN). Using attribution methods such as layer-wise relevance propagation or SHAP heatmaps can be created that highlight which regions of an input are more relevant for the decision than others. While this allows the detection of potential data set biases and can be used as a guide for a human expert, it does not allow an understanding of the underlying principles the model has learned. In this study, we instead show, to the best of our knowledge, for the first time results using feature visualization of neuroimaging CNNs. Particularly, we have trained CNNs for different tasks including sex classification and artificial lesion classification based on structural magnetic resonance imaging (MRI) data. We have then iteratively generated images that maximally activate specific neurons, in order to visualize the patterns they respond to. To improve the visualizations we compared several regularization strategies. The resulting images reveal the learned concepts of the artificial lesions, including their shapes, but remain hard to interpret for abstract features in the sex classification task.
WegFormer: Transformers for Weakly Supervised Semantic Segmentation
Mar 16, 2022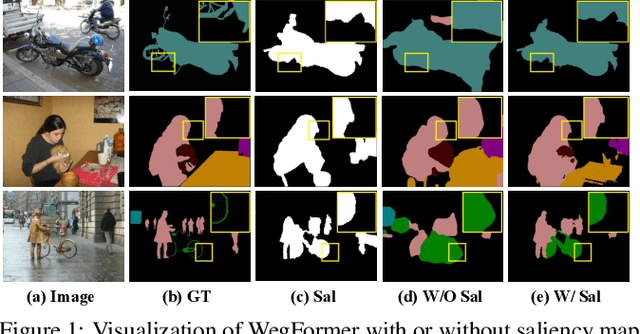
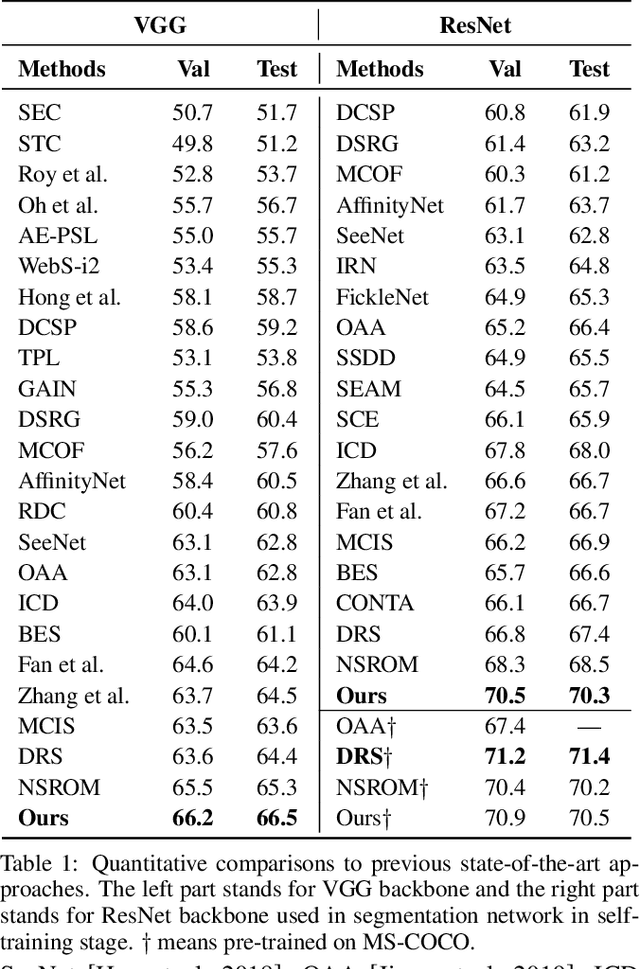
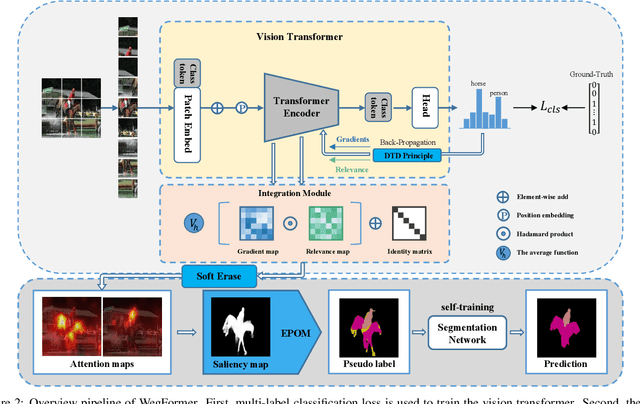

Although convolutional neural networks (CNNs) have achieved remarkable progress in weakly supervised semantic segmentation (WSSS), the effective receptive field of CNN is insufficient to capture global context information, leading to sub-optimal results. Inspired by the great success of Transformers in fundamental vision areas, this work for the first time introduces Transformer to build a simple and effective WSSS framework, termed WegFormer. Unlike existing CNN-based methods, WegFormer uses Vision Transformer (ViT) as a classifier to produce high-quality pseudo segmentation masks. To this end, we introduce three tailored components in our Transformer-based framework, which are (1) a Deep Taylor Decomposition (DTD) to generate attention maps, (2) a soft erasing module to smooth the attention maps, and (3) an efficient potential object mining (EPOM) to filter noisy activation in the background. Without any bells and whistles, WegFormer achieves state-of-the-art 70.5% mIoU on the PASCAL VOC dataset, significantly outperforming the previous best method. We hope WegFormer provides a new perspective to tap the potential of Transformer in weakly supervised semantic segmentation. Code will be released.
Reproducible Subjective Evaluation
Mar 08, 2022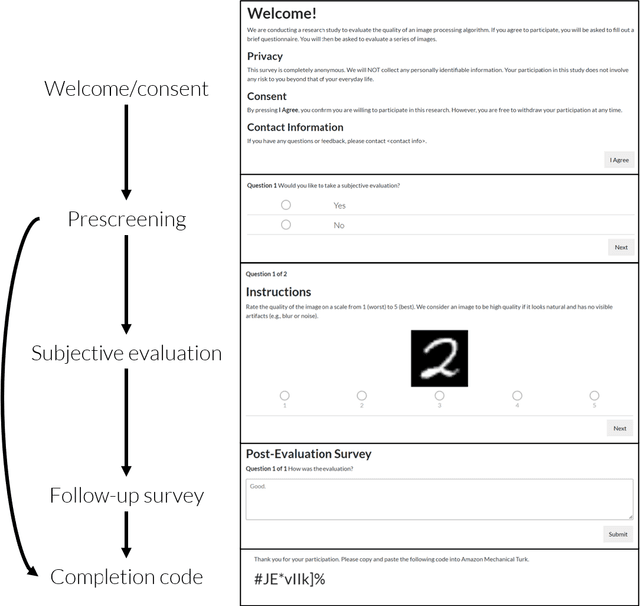

Human perceptual studies are the gold standard for the evaluation of many research tasks in machine learning, linguistics, and psychology. However, these studies require significant time and cost to perform. As a result, many researchers use objective measures that can correlate poorly with human evaluation. When subjective evaluations are performed, they are often not reported with sufficient detail to ensure reproducibility. We propose Reproducible Subjective Evaluation (ReSEval), an open-source framework for quickly deploying crowdsourced subjective evaluations directly from Python. ReSEval lets researchers launch A/B, ABX, Mean Opinion Score (MOS) and MUltiple Stimuli with Hidden Reference and Anchor (MUSHRA) tests on audio, image, text, or video data from a command-line interface or using one line of Python, making it as easy to run as objective evaluation. With ReSEval, researchers can reproduce each other's subjective evaluations by sharing a configuration file and the audio, image, text, or video files.
Time-Stamped Language Model: Teaching Language Models to Understand the Flow of Events
Apr 15, 2021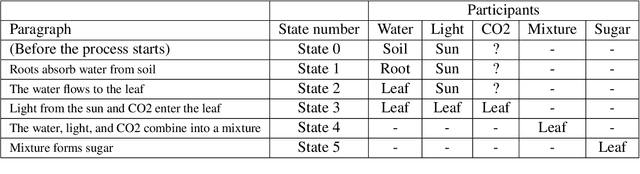
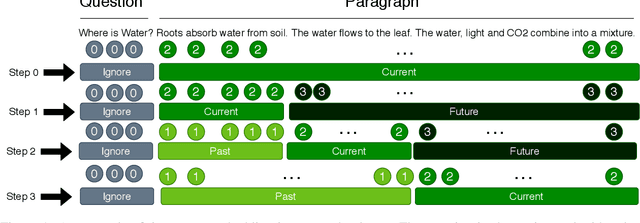
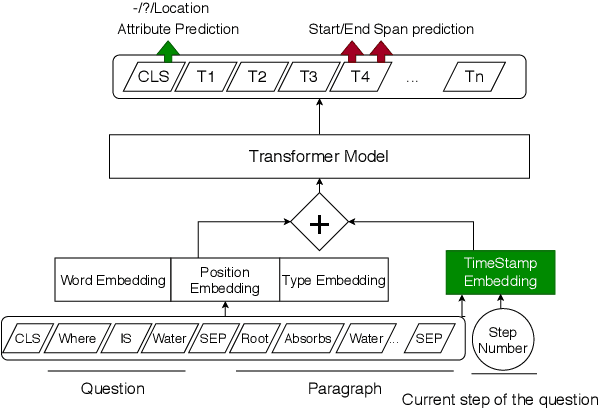
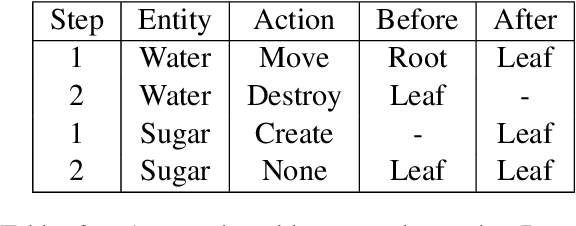
Tracking entities throughout a procedure described in a text is challenging due to the dynamic nature of the world described in the process. Firstly, we propose to formulate this task as a question answering problem. This enables us to use pre-trained transformer-based language models on other QA benchmarks by adapting those to the procedural text understanding. Secondly, since the transformer-based language models cannot encode the flow of events by themselves, we propose a Time-Stamped Language Model~(TSLM model) to encode event information in LMs architecture by introducing the timestamp encoding. Our model evaluated on the Propara dataset shows improvements on the published state-of-the-art results with a $3.1\%$ increase in F1 score. Moreover, our model yields better results on the location prediction task on the NPN-Cooking dataset. This result indicates that our approach is effective for procedural text understanding in general.
Linearization and Identification of Multiple-Attractors Dynamical System through Laplacian Eigenmaps
Feb 18, 2022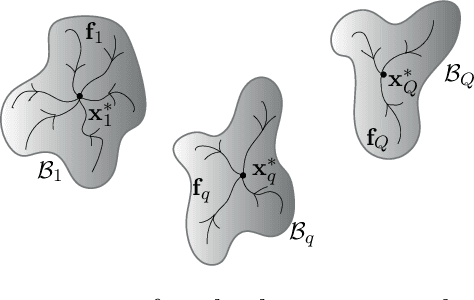
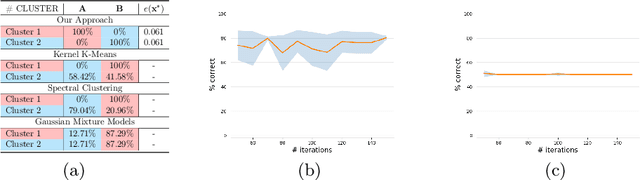
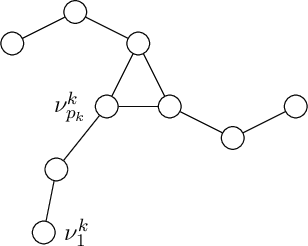
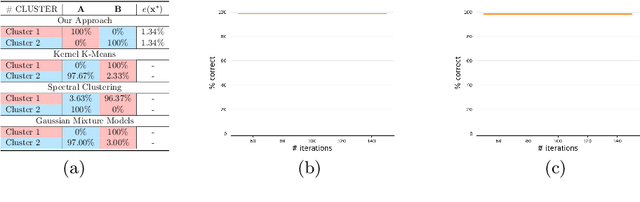
Dynamical Systems (DS) are fundamental to the modeling and understanding of time evolving phenomena, and find application in physics, biology and control. As determining an analytical description of the dynamics is often difficult, data-driven approaches are preferred for identifying and controlling nonlinear DS with multiple equilibrium points. Identification of such DS has been treated largely as a supervised learning problem. Instead, we focus on a unsupervised learning scenario where we know neither the number nor the type of dynamics. We propose a Graph-based spectral clustering method that takes advantage of a velocity-augmented kernel to connect data-points belonging to the same dynamics, while preserving the natural temporal evolution. We study the eigenvectors and eigenvalues of the Graph Laplacian and show that they form a set of orthogonal embedding spaces, one for each sub-dynamics. We prove that there always exist a set of 2-dimensional embedding spaces in which the sub-dynamics are linear, and n-dimensional embedding where they are quasi-linear. We compare the clustering performance of our algorithm to Kernel K-Means, Spectral Clustering and Gaussian Mixtures and show that, even when these algorithms are provided with the true number of sub-dynamics, they fail to cluster them correctly. We learn a diffeomorphism from the Laplacian embedding space to the original space and show that the Laplacian embedding leads to good reconstruction accuracy and a faster training time through an exponential decaying loss, compared to the state of the art diffeomorphism-based approaches.
Toxic Comments Hunter : Score Severity of Toxic Comments
Feb 15, 2022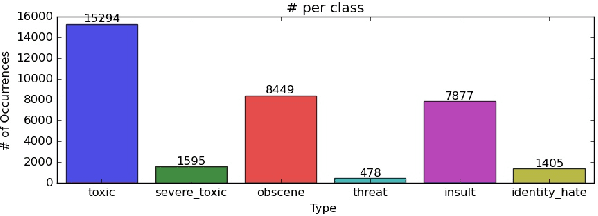
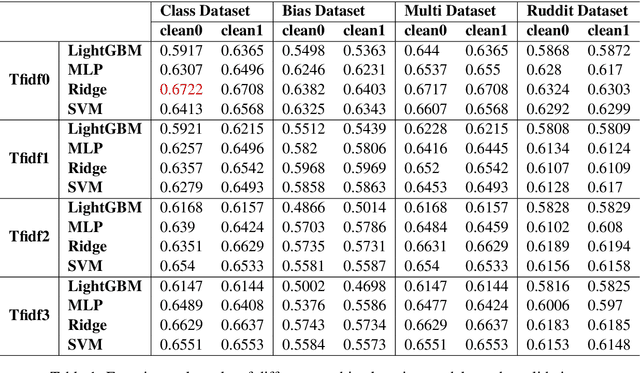

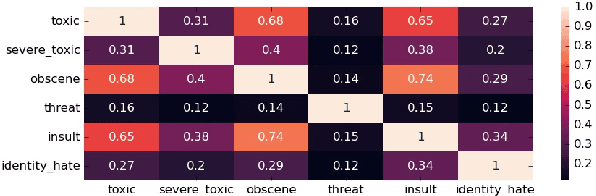
The detection and identification of toxic comments are conducive to creating a civilized and harmonious Internet environment. In this experiment, we collected various data sets related to toxic comments. Because of the characteristics of comment data, we perform data cleaning and feature extraction operations on it from different angles to obtain different toxic comment training sets. In terms of model construction, we used the training set to train the models based on TFIDF and finetuned the Bert model separately. Finally, we encapsulated the code into software to score toxic comments in real-time.
A Survey for Deep RGBT Tracking
Jan 29, 2022
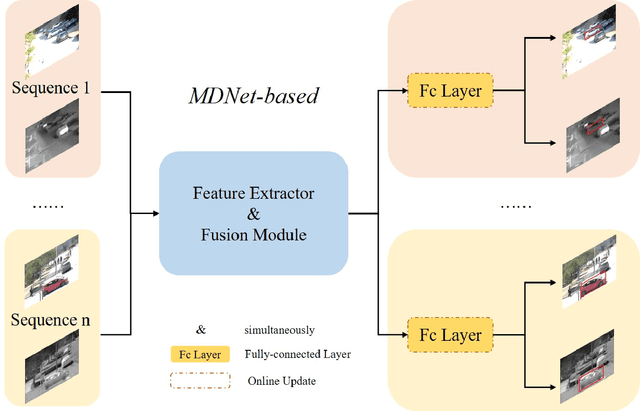
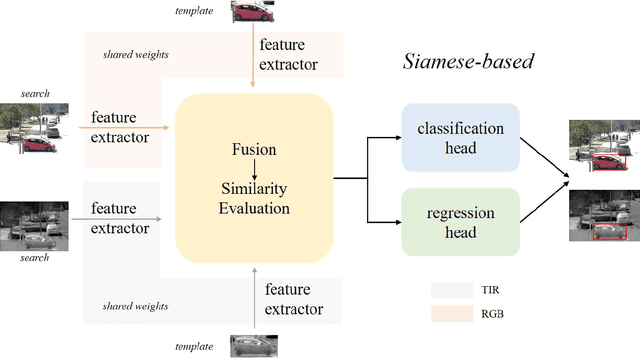
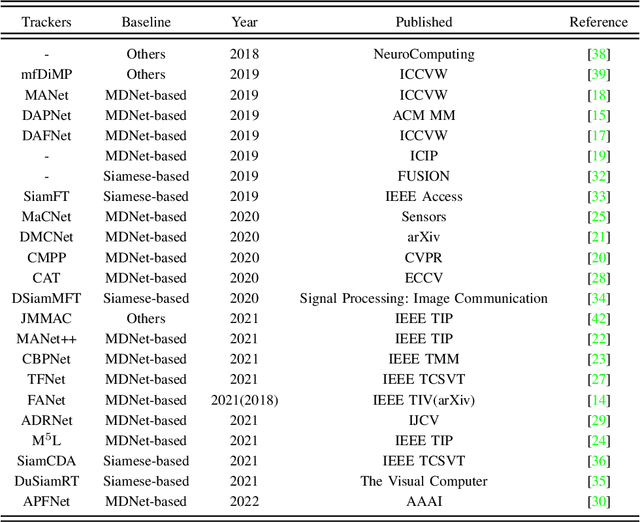
Visual object tracking with the visible (RGB) and thermal infrared (TIR) electromagnetic waves, shorted in RGBT tracking, recently draws increasing attention in the tracking community. Considering the rapid development of deep learning, a survey for the recent deep neural network based RGBT trackers is presented in this paper. Firstly, we give brief introduction for the RGBT trackers concluded into this category. Then, a comparison among the existing RGBT trackers on several challenging benchmarks is given statistically. Specifically, MDNet and Siamese architectures are the two mainstream frameworks in the RGBT community, especially the former. Trackers based on MDNet achieve higher performance while Siamese-based trackers satisfy the real-time requirement. In summary, since the large-scale dataset LasHeR is published, the integration of end-to-end framework, e.g., Siamese and Transformer, should be further considered to fulfil the real-time as well as more robust performance. Furthermore, the mathematical meaning should be more considered during designing the network. This survey can be treated as a look-up-table for researchers who are concerned about RGBT tracking.
A sinusoidal signal reconstruction method for the inversion of the mel-spectrogram
Jan 07, 2022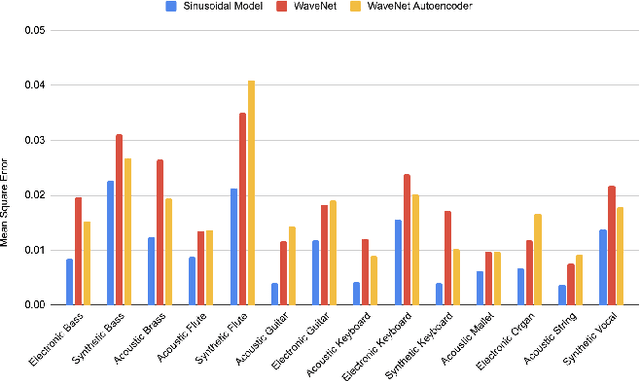
The synthesis of sound via deep learning methods has recently received much attention. Some problems for deep learning approaches to sound synthesis relate to the amount of data needed to specify an audio signal and the necessity of preserving both the long and short time coherence of the synthesised signal. Visual time-frequency representations such as the log-mel-spectrogram have gained in popularity. The log-mel-spectrogram is a perceptually informed representation of audio that greatly compresses the amount of information required for the description of the sound. However, because of this compression, this representation is not directly invertible. Both signal processing and machine learning techniques have previously been applied to the inversion of the log-mel-spectrogram but they both caused audible distortions in the synthesized sounds due to issues of temporal and spectral coherence. In this paper, we outline the application of a sinusoidal model to the inversion of the log-mel-spectrogram for pitched musical instrument sounds outperforming state-of-the-art deep learning methods. The approach could be later used as a general decoding step from spectral to time intervals in neural applications.
Point-NeRF: Point-based Neural Radiance Fields
Jan 21, 2022
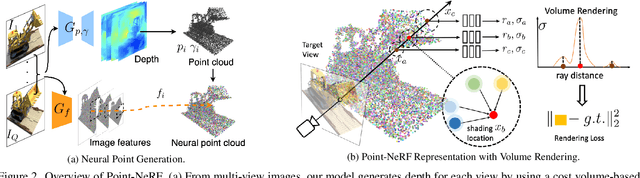

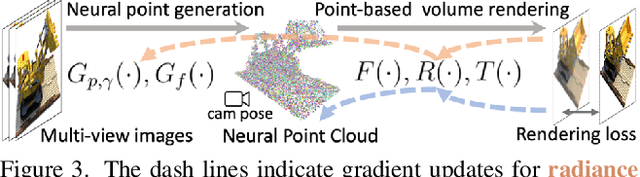
Volumetric neural rendering methods like NeRF generate high-quality view synthesis results but are optimized per-scene leading to prohibitive reconstruction time. On the other hand, deep multi-view stereo methods can quickly reconstruct scene geometry via direct network inference. Point-NeRF combines the advantages of these two approaches by using neural 3D point clouds, with associated neural features, to model a radiance field. Point-NeRF can be rendered efficiently by aggregating neural point features near scene surfaces, in a ray marching-based rendering pipeline. Moreover, Point-NeRF can be initialized via direct inference of a pre-trained deep network to produce a neural point cloud; this point cloud can be finetuned to surpass the visual quality of NeRF with 30X faster training time. Point-NeRF can be combined with other 3D reconstruction methods and handles the errors and outliers in such methods via a novel pruning and growing mechanism.
Spatial-Temporal Sequential Hypergraph Network for Crime Prediction
Jan 07, 2022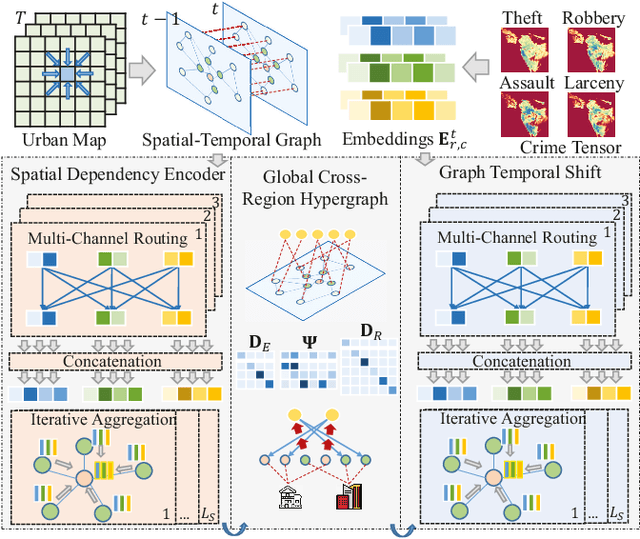
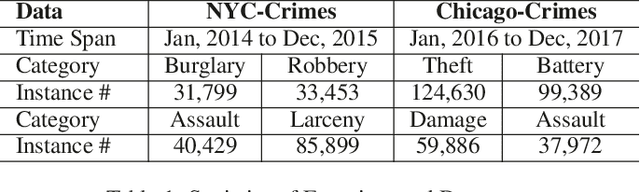
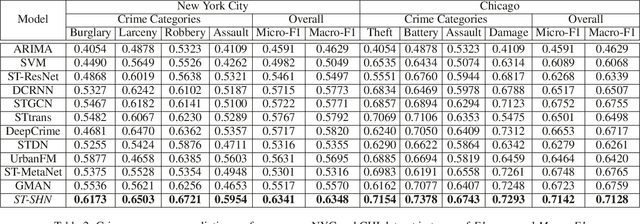
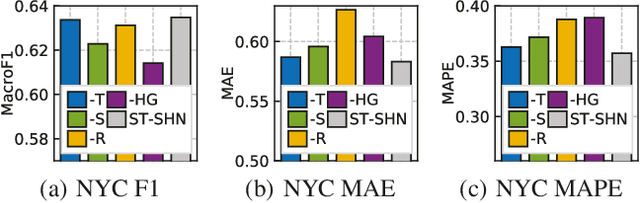
Crime prediction is crucial for public safety and resource optimization, yet is very challenging due to two aspects: i) the dynamics of criminal patterns across time and space, crime events are distributed unevenly on both spatial and temporal domains; ii) time-evolving dependencies between different types of crimes (e.g., Theft, Robbery, Assault, Damage) which reveal fine-grained semantics of crimes. To tackle these challenges, we propose Spatial-Temporal Sequential Hypergraph Network (ST-SHN) to collectively encode complex crime spatial-temporal patterns as well as the underlying category-wise crime semantic relationships. In specific, to handle spatial-temporal dynamics under the long-range and global context, we design a graph-structured message passing architecture with the integration of the hypergraph learning paradigm. To capture category-wise crime heterogeneous relations in a dynamic environment, we introduce a multi-channel routing mechanism to learn the time-evolving structural dependency across crime types. We conduct extensive experiments on two real-world datasets, showing that our proposed ST-SHN framework can significantly improve the prediction performance as compared to various state-of-the-art baselines. The source code is available at: https://github.com/akaxlh/ST-SHN.