 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Asynchronous Parallel Incremental Block-Coordinate Descent for Decentralized Machine Learning
Feb 07, 2022
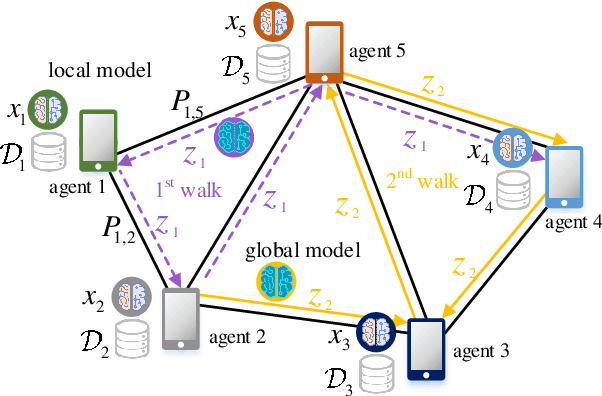
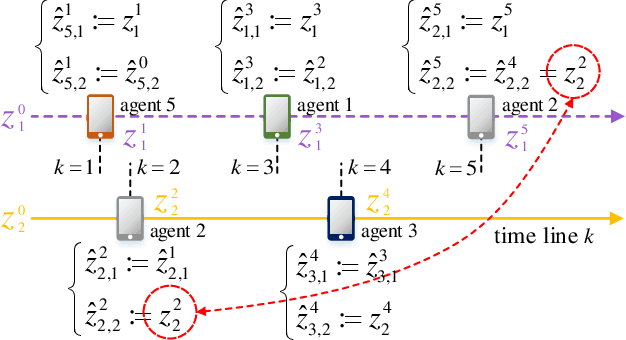
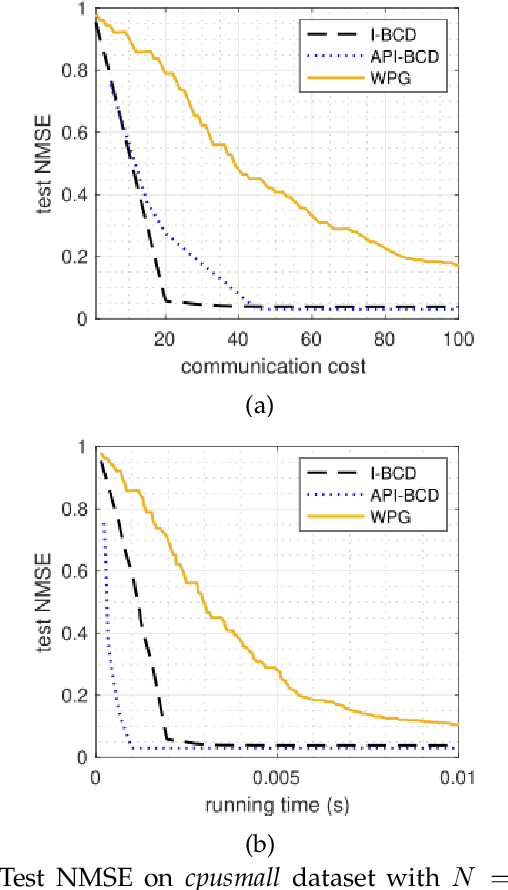
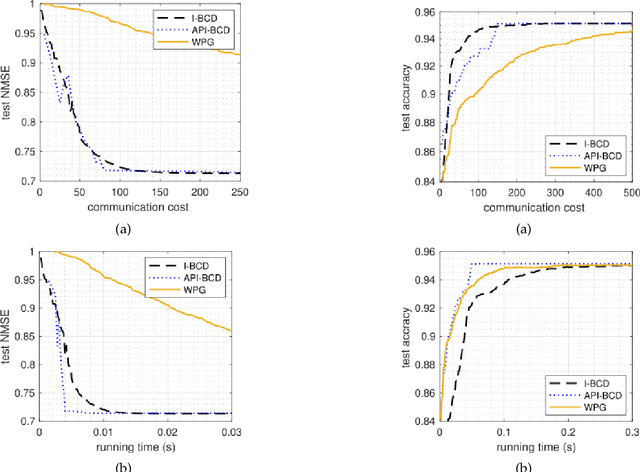
Machine learning (ML) is a key technique for big-data-driven modelling and analysis of massive Internet of Things (IoT) based intelligent and ubiquitous computing. For fast-increasing applications and data amounts, distributed learning is a promising emerging paradigm since it is often impractical or inefficient to share/aggregate data to a centralized location from distinct ones. This paper studies the problem of training an ML model over decentralized systems, where data are distributed over many user devices and the learning algorithm run on-device, with the aim of relaxing the burden at a central entity/server. Although gossip-based approaches have been used for this purpose in different use cases, they suffer from high communication costs, especially when the number of devices is large. To mitigate this, incremental-based methods are proposed. We first introduce incremental block-coordinate descent (I-BCD) for the decentralized ML, which can reduce communication costs at the expense of running time. To accelerate the convergence speed, an asynchronous parallel incremental BCD (API-BCD) method is proposed, where multiple devices/agents are active in an asynchronous fashion. We derive convergence properties for the proposed methods. Simulation results also show that our API-BCD method outperforms state of the art in terms of running time and communication costs.
A Novel Chaos-based Light-weight Image Encryption Scheme for Multi-modal Hearing Aids
Feb 11, 2022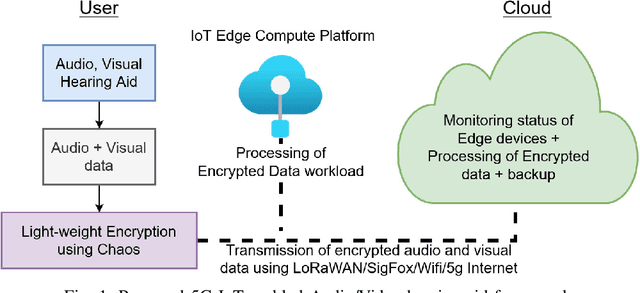

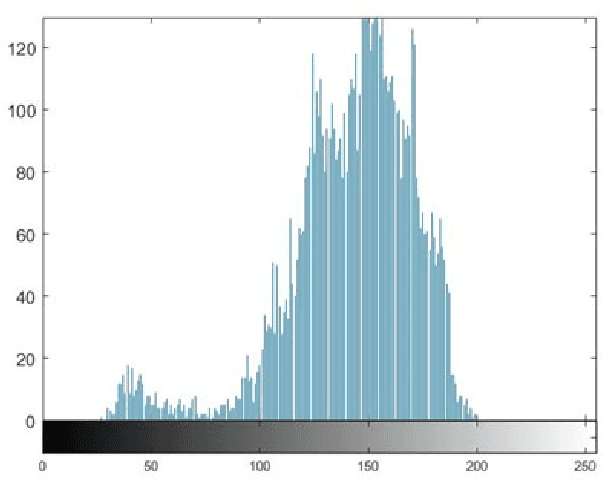
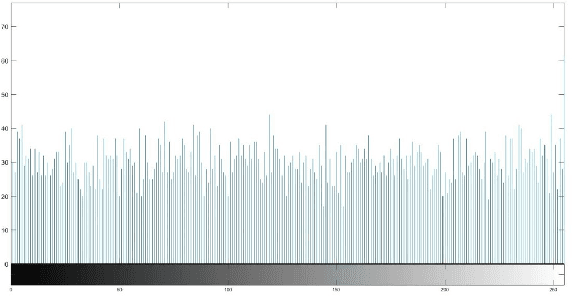
Multimodal hearing aids (HAs) aim to deliver more intelligible audio in noisy environments by contextually sensing and processing data in the form of not only audio but also visual information (e.g. lip reading). Machine learning techniques can play a pivotal role for the contextually processing of multimodal data. However, since the computational power of HA devices is low, therefore this data must be processed either on the edge or cloud which, in turn, poses privacy concerns for sensitive user data. Existing literature proposes several techniques for data encryption but their computational complexity is a major bottleneck to meet strict latency requirements for development of future multi-modal hearing aids. To overcome this problem, this paper proposes a novel real-time audio/visual data encryption scheme based on chaos-based encryption using the Tangent-Delay Ellipse Reflecting Cavity-Map System (TD-ERCS) map and Non-linear Chaotic (NCA) Algorithm. The results achieved against different security parameters, including Correlation Coefficient, Unified Averaged Changed Intensity (UACI), Key Sensitivity Analysis, Number of Changing Pixel Rate (NPCR), Mean-Square Error (MSE), Peak Signal to Noise Ratio (PSNR), Entropy test, and Chi-test, indicate that the newly proposed scheme is more lightweight due to its lower execution time as compared to existing schemes and more secure due to increased key-space against modern brute-force attacks.
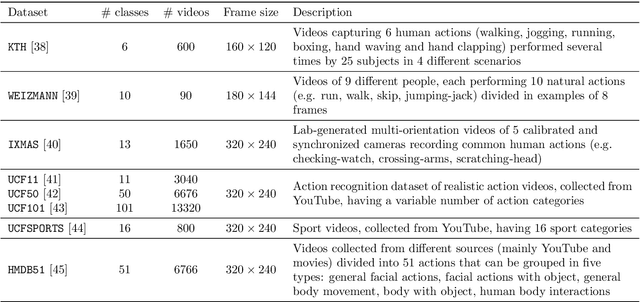
Automatic Recognition and Digital Documentation of Cultural Heritage Hemispherical Domes using Images
Jan 25, 2022


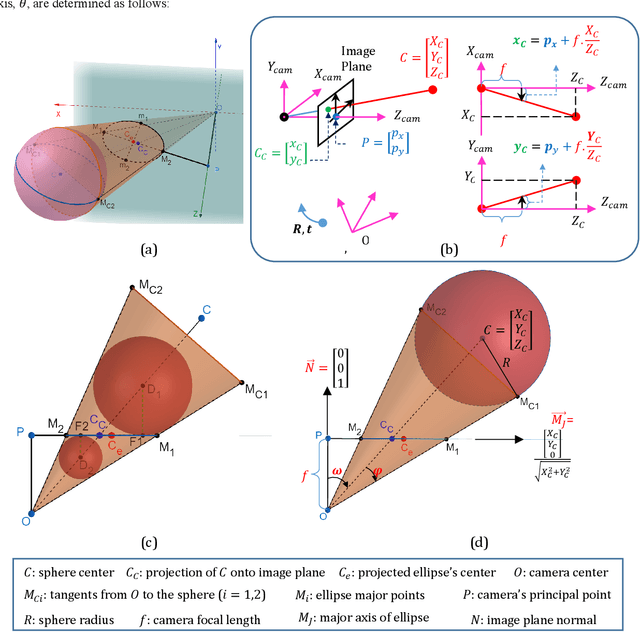
Advancements in optical metrology has enabled documentation of dense 3D point clouds of cultural heritage sites. For large scale and continuous digital documentation, processing of dense 3D point clouds becomes computationally cumbersome, and often requires additional hardware for data management, increasing the time cost, and complexity of projects. To this end, this manuscript presents an original approach to generate fast and reliable semantic digital models of heritage hemispherical domes using only two images. New closed formulations were derived to establish the relationships between spheres and their projected ellipses onto images, which fostered the development of a new automatic framework for as-built generation of spheres. The effectiveness of the proposed method was evaluated under both laboratory and real-world datasets. The results revealed that the proposed method achieved as-built modeling accuracy of around 6mm, while improving the computation time by a factor of 7, when compared to established point cloud processing methods.
TadGAN: Time Series Anomaly Detection Using Generative Adversarial Networks
Sep 16, 2020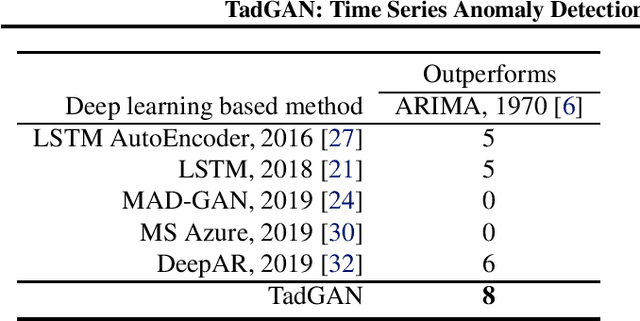
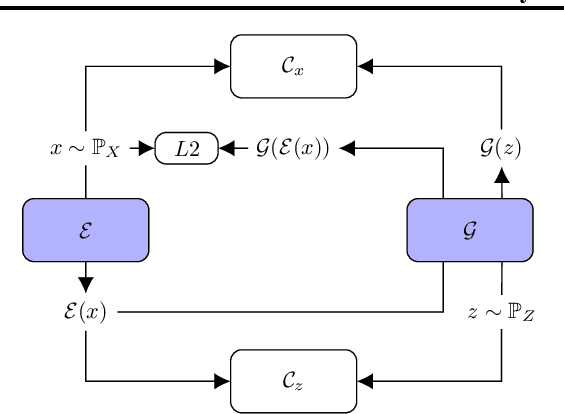
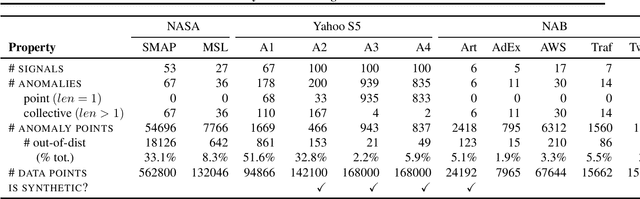
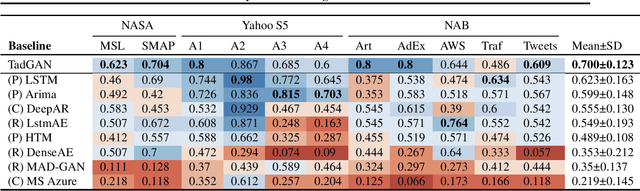
Time series anomalies can offer information relevant to critical situations facing various fields, from finance and aerospace to the IT, security, and medical domains. However, detecting anomalies in time series data is particularly challenging due to the vague definition of anomalies and said data's frequent lack of labels and highly complex temporal correlations. Current state-of-the-art unsupervised machine learning methods for anomaly detection suffer from scalability and portability issues, and may have high false positive rates. In this paper, we propose TadGAN, an unsupervised anomaly detection approach built on Generative Adversarial Networks (GANs). To capture the temporal correlations of time series distributions, we use LSTM Recurrent Neural Networks as base models for Generators and Critics. TadGAN is trained with cycle consistency loss to allow for effective time-series data reconstruction. We further propose several novel methods to compute reconstruction errors, as well as different approaches to combine reconstruction errors and Critic outputs to compute anomaly scores. To demonstrate the performance and generalizability of our approach, we test several anomaly scoring techniques and report the best-suited one. We compare our approach to 8 baseline anomaly detection methods on 11 datasets from multiple reputable sources such as NASA, Yahoo, Numenta, Amazon, and Twitter. The results show that our approach can effectively detect anomalies and outperform baseline methods in most cases (6 out of 11). Notably, our method has the highest averaged F1 score across all the datasets. Our code is open source and is available as a benchmarking tool.
Multi-Objective reward generalization: Improving performance of Deep Reinforcement Learning for selected applications in stock and cryptocurrency trading
Mar 09, 2022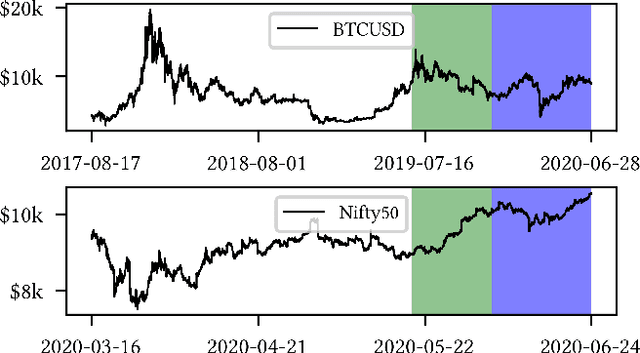
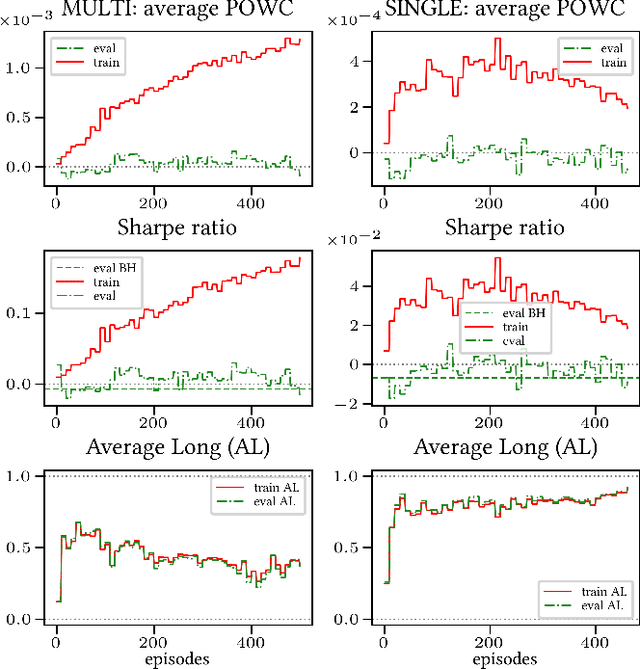
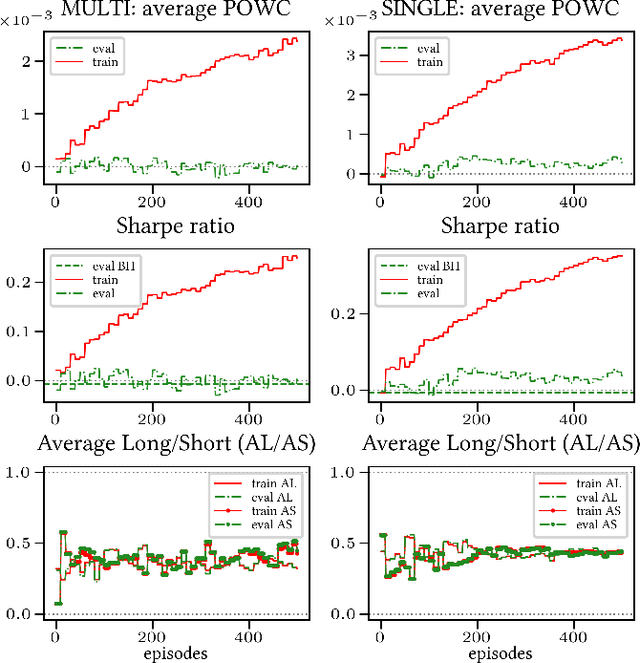
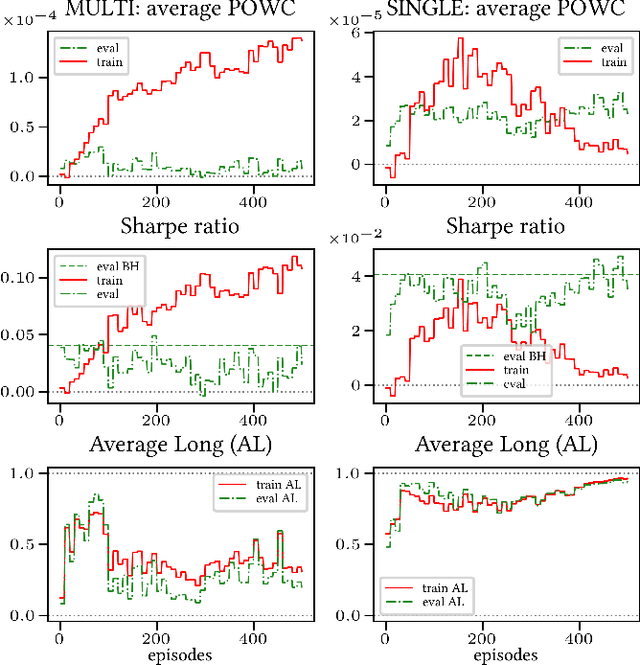
We investigate the potential of Multi-Objective, Deep Reinforcement Learning for stock and cryptocurrency trading. More specifically, we build on the generalized setting \`a la Fontaine and Friedman arXiv:1809.06364 (where the reward weighting mechanism is not specified a priori, but embedded in the learning process) by complementing it with computational speed-ups, and adding the cumulative reward's discount factor to the learning process. Firstly, we verify that the resulting Multi-Objective algorithm generalizes well, and we provide preliminary statistical evidence showing that its prediction is more stable than the corresponding Single-Objective strategy's. Secondly, we show that the Multi-Objective algorithm has a clear edge over the corresponding Single-Objective strategy when the reward mechanism is sparse (i.e., when non-null feedback is infrequent over time). Finally, we discuss the generalization properties of the discount factor. The entirety of our code is provided in open source format.
Multivariate Time Series Classification Using Spiking Neural Networks
Jul 07, 2020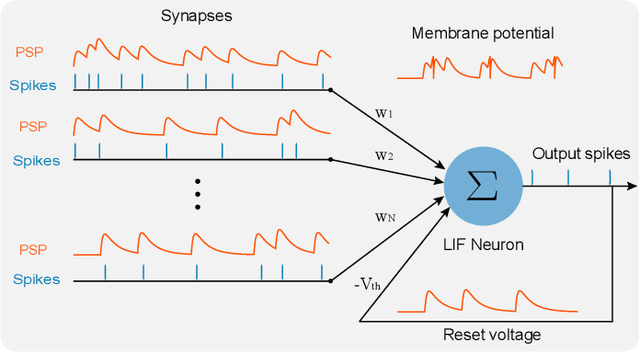
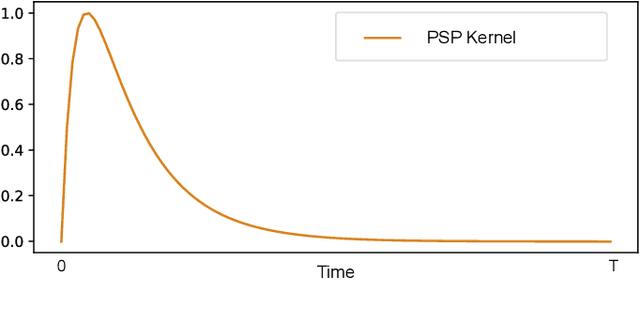
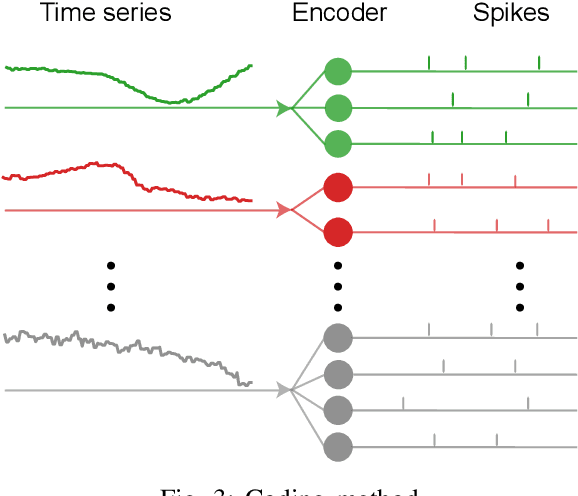
There is an increasing demand to process streams of temporal data in energy-limited scenarios such as embedded devices, driven by the advancement and expansion of Internet of Things (IoT) and Cyber-Physical Systems (CPS). Spiking neural network has drawn attention as it enables low power consumption by encoding and processing information as sparse spike events, which can be exploited for event-driven computation. Recent works also show SNNs' capability to process spatial temporal information. Such advantages can be exploited by power-limited devices to process real-time sensor data. However, most existing SNN training algorithms focus on vision tasks and temporal credit assignment is not addressed. Furthermore, widely adopted rate encoding ignores temporal information, hence it's not suitable for representing time series. In this work, we present an encoding scheme to convert time series into sparse spatial temporal spike patterns. A training algorithm to classify spatial temporal patterns is also proposed. Proposed approach is evaluated on multiple time series datasets in the UCR repository and achieved performance comparable to deep neural networks.
3D ToF LiDAR in Mobile Robotics: A Review
Feb 22, 2022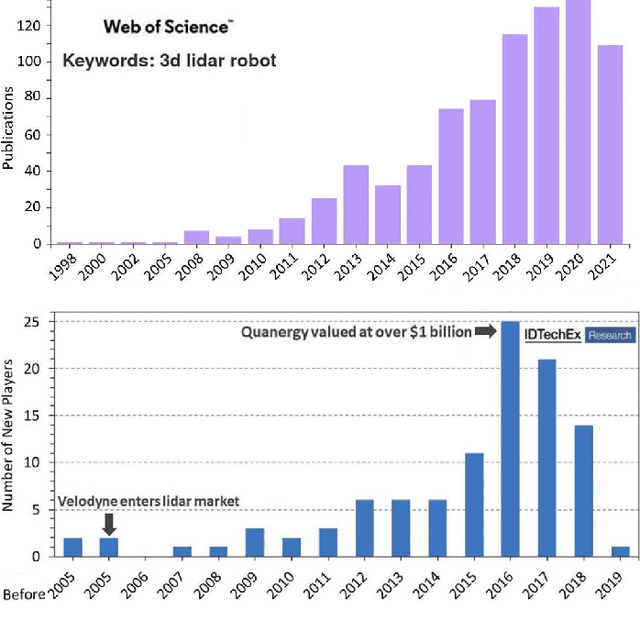
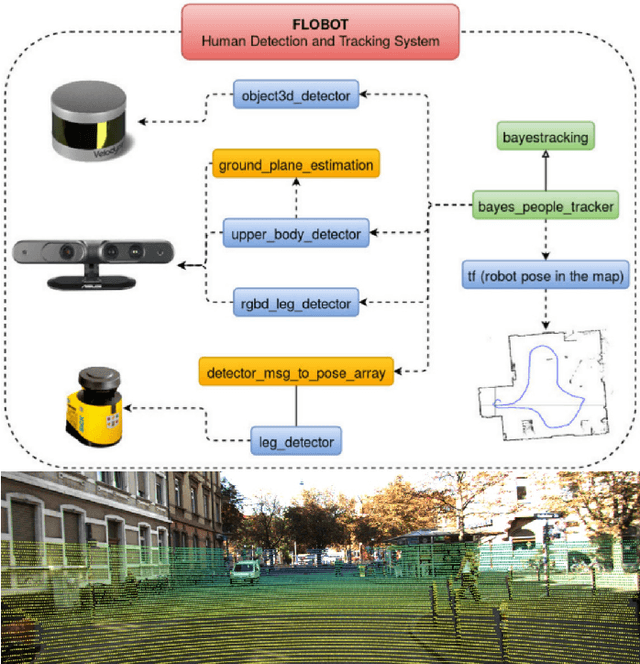

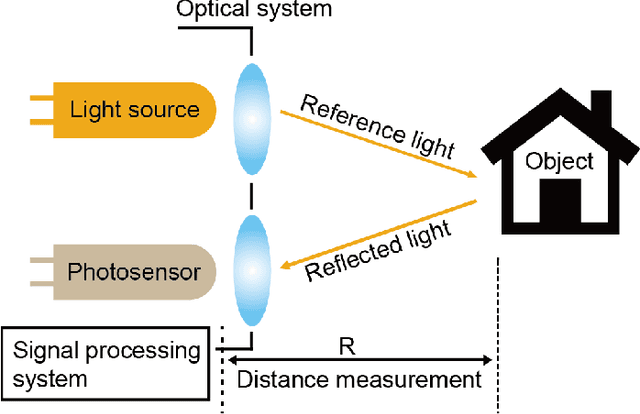
In the past ten years, the use of 3D Time-of-Flight (ToF) LiDARs in mobile robotics has grown rapidly. Based on our accumulation of relevant research, this article systematically reviews and analyzes the use 3D ToF LiDARs in research and industrial applications. The former includes object detection, robot localization, long-term autonomy, LiDAR data processing under adverse weather conditions, and sensor fusion. The latter encompasses service robots, assisted and autonomous driving, and recent applications performed in response to public health crises. We hope that our efforts can effectively provide readers with relevant references and promote the deployment of existing mature technologies in real-world systems.
Optimizing Deep Neural Networks via Discretization of Finite-Time Convergent Flows
Oct 09, 2020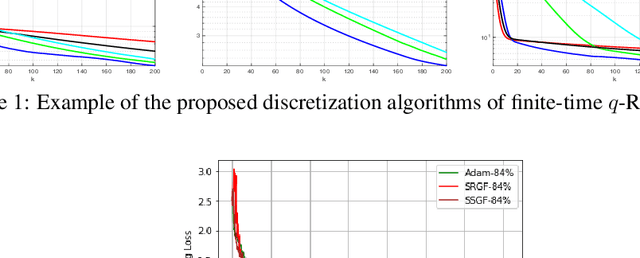
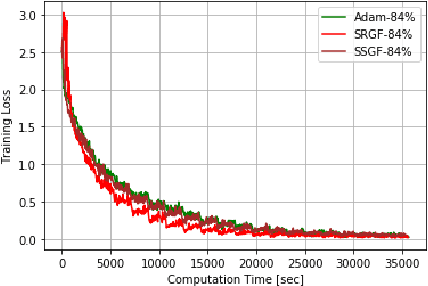
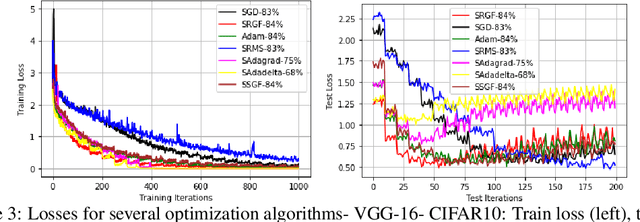
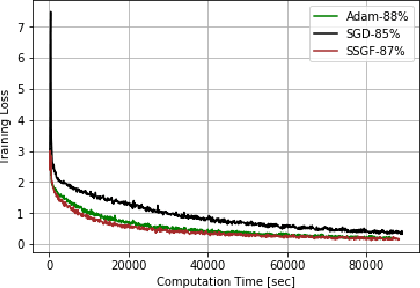
In this paper, we investigate in the context of deep neural networks, the performance of several discretization algorithms for two first-order finite-time optimization flows. These flows are, namely, the rescaled-gradient flow (RGF) and the signed-gradient flow (SGF), and consist of non-Lipscthiz or discontinuous dynamical systems that converge locally in finite time to the minima of gradient-dominated functions. We introduce three discretization methods for these first-order finite-time flows, and provide convergence guarantees. We then apply the proposed algorithms in training neural networks and empirically test their performances on three standard datasets, namely, CIFAR10, SVHN, and MNIST. Our results show that our schemes demonstrate faster convergences against standard optimization alternatives, while achieving equivalent or better accuracy.
On the Post-hoc Explainability of Deep Echo State Networks for Time Series Forecasting, Image and Video Classification
Feb 17, 2021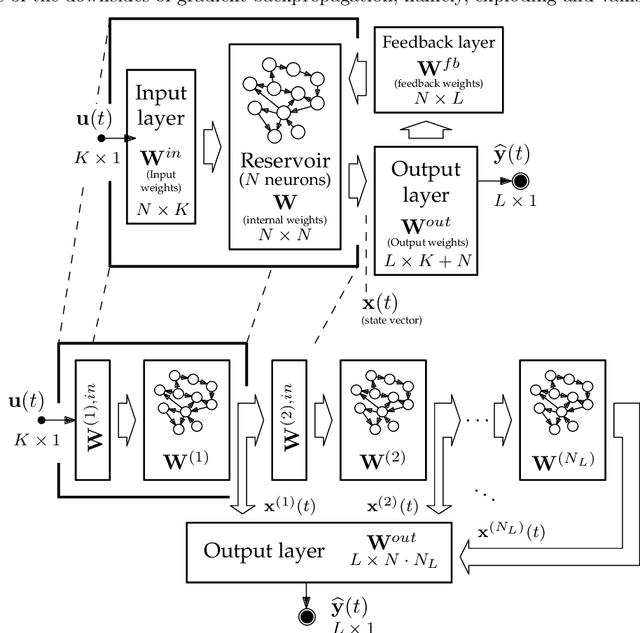
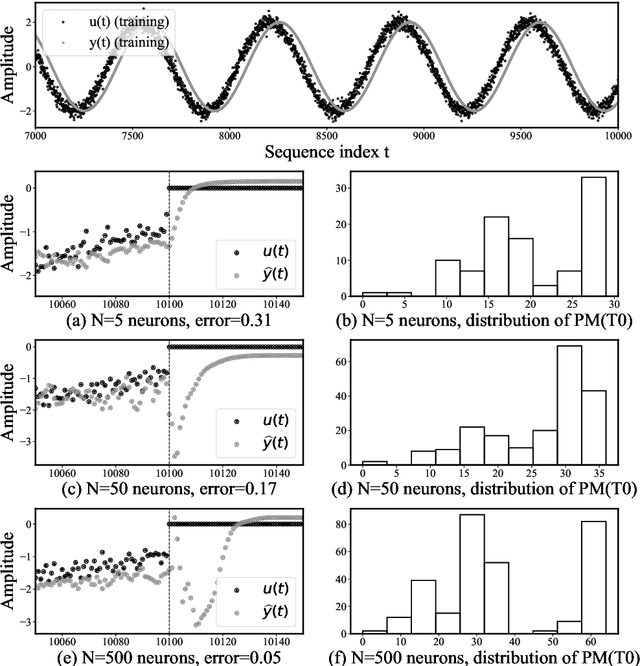
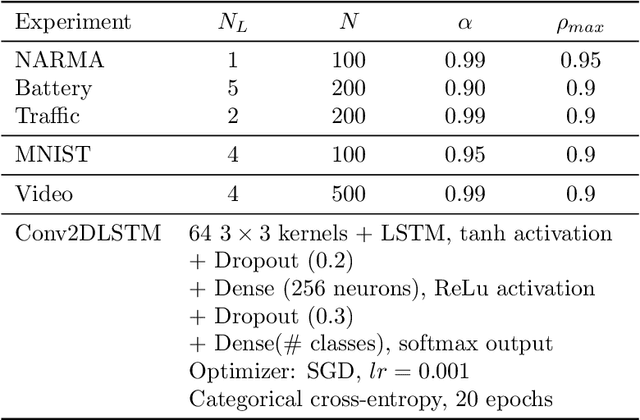
Since their inception, learning techniques under the Reservoir Computing paradigm have shown a great modeling capability for recurrent systems without the computing overheads required for other approaches. Among them, different flavors of echo state networks have attracted many stares through time, mainly due to the simplicity and computational efficiency of their learning algorithm. However, these advantages do not compensate for the fact that echo state networks remain as black-box models whose decisions cannot be easily explained to the general audience. This work addresses this issue by conducting an explainability study of Echo State Networks when applied to learning tasks with time series, image and video data. Specifically, the study proposes three different techniques capable of eliciting understandable information about the knowledge grasped by these recurrent models, namely, potential memory, temporal patterns and pixel absence effect. Potential memory addresses questions related to the effect of the reservoir size in the capability of the model to store temporal information, whereas temporal patterns unveils the recurrent relationships captured by the model over time. Finally, pixel absence effect attempts at evaluating the effect of the absence of a given pixel when the echo state network model is used for image and video classification. We showcase the benefits of our proposed suite of techniques over three different domains of applicability: time series modeling, image and, for the first time in the related literature, video classification. Our results reveal that the proposed techniques not only allow for a informed understanding of the way these models work, but also serve as diagnostic tools capable of detecting issues inherited from data (e.g. presence of hidden bias).
Deep AutoAugment
Mar 11, 2022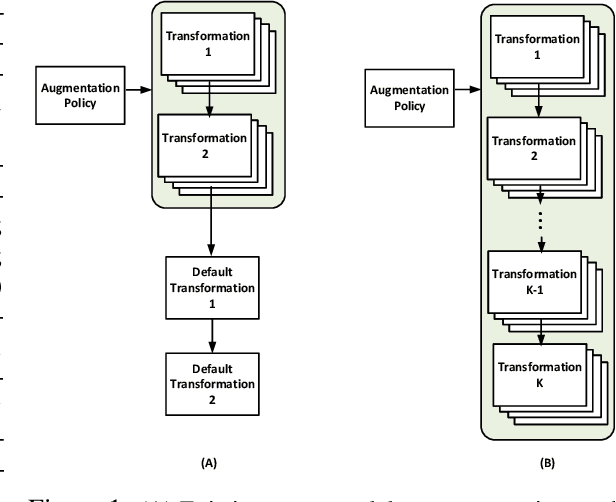


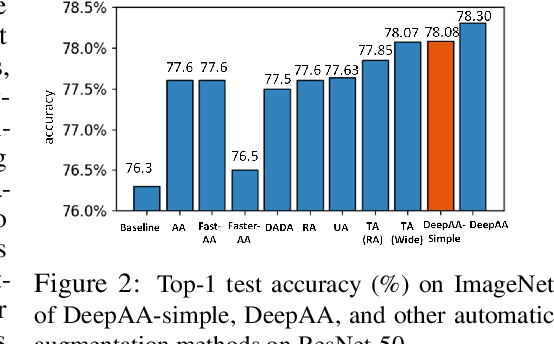
While recent automated data augmentation methods lead to state-of-the-art results, their design spaces and the derived data augmentation strategies still incorporate strong human priors. In this work, instead of fixing a set of hand-picked default augmentations alongside the searched data augmentations, we propose a fully automated approach for data augmentation search named Deep AutoAugment (DeepAA). DeepAA progressively builds a multi-layer data augmentation pipeline from scratch by stacking augmentation layers one at a time until reaching convergence. For each augmentation layer, the policy is optimized to maximize the cosine similarity between the gradients of the original and augmented data along the direction with low variance. Our experiments show that even without default augmentations, we can learn an augmentation policy that achieves strong performance with that of previous works. Extensive ablation studies show that the regularized gradient matching is an effective search method for data augmentation policies. Our code is available at: https://github.com/MSU-MLSys-Lab/DeepAA .