 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TimeReplayer: Unlocking the Potential of Event Cameras for Video Interpolation
Mar 25, 2022


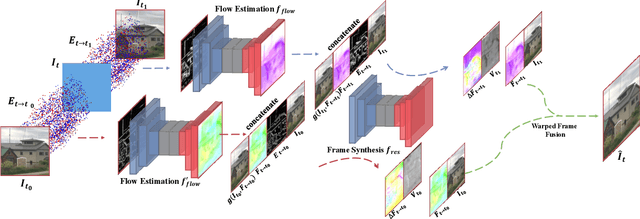
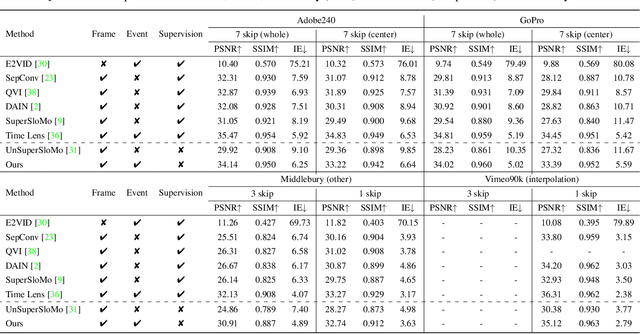
Recording fast motion in a high FPS (frame-per-second) requires expensive high-speed cameras. As an alternative, interpolating low-FPS videos from commodity cameras has attracted significant attention. If only low-FPS videos are available, motion assumptions (linear or quadratic) are necessary to infer intermediate frames, which fail to model complex motions. Event camera, a new camera with pixels producing events of brightness change at the temporal resolution of $\mu s$ $(10^{-6}$ second $)$, is a game-changing device to enable video interpolation at the presence of arbitrarily complex motion. Since event camera is a novel sensor, its potential has not been fulfilled due to the lack of processing algorithms. The pioneering work Time Lens introduced event cameras to video interpolation by designing optical devices to collect a large amount of paired training data of high-speed frames and events, which is too costly to scale. To fully unlock the potential of event cameras, this paper proposes a novel TimeReplayer algorithm to interpolate videos captured by commodity cameras with events. It is trained in an unsupervised cycle-consistent style, canceling the necessity of high-speed training data and bringing the additional ability of video extrapolation. Its state-of-the-art results and demo videos in supplementary reveal the promising future of event-based vision.
Accelerating Laue Depth Reconstruction Algorithm with CUDA
Jan 20, 2022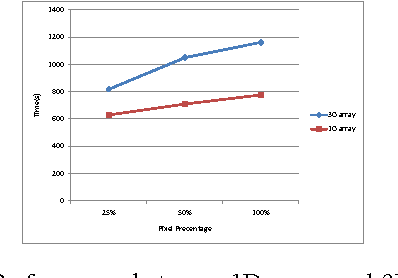
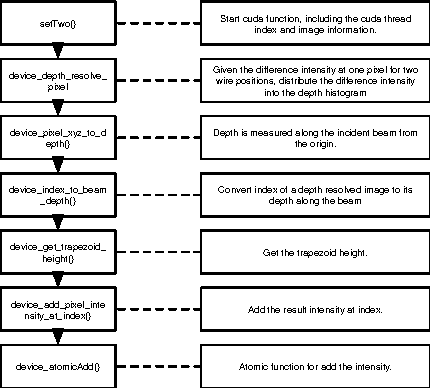
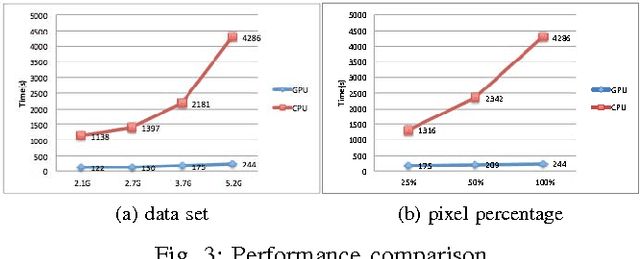
The Laue diffraction microscopy experiment uses the polychromatic Laue micro-diffraction technique to examine the structure of materials with sub-micron spatial resolution in all three dimensions. During this experiment, local crystallographic orientations, orientation gradients and strains are measured as properties which will be recorded in HDF5 image format. The recorded images will be processed with a depth reconstruction algorithm for future data analysis. But the current depth reconstruction algorithm consumes considerable processing time and might take up to 2 weeks for reconstructing data collected from one single experiment. To improve the depth reconstruction computation speed, we propose a scalable GPU program solution on the depth reconstruction problem in this paper. The test result shows that the running time would be 10 to 20 times faster than the prior CPU design for various size of input data.
Evaluating Token-Level and Passage-Level Dense Retrieval Models for Math Information Retrieval
Mar 21, 2022
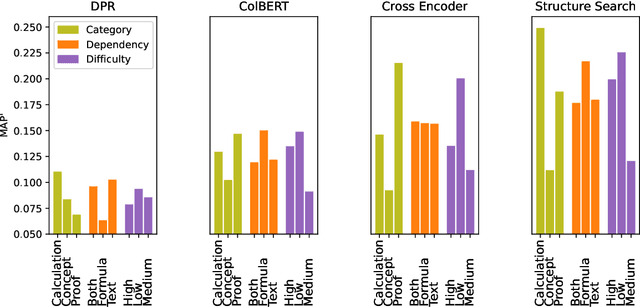
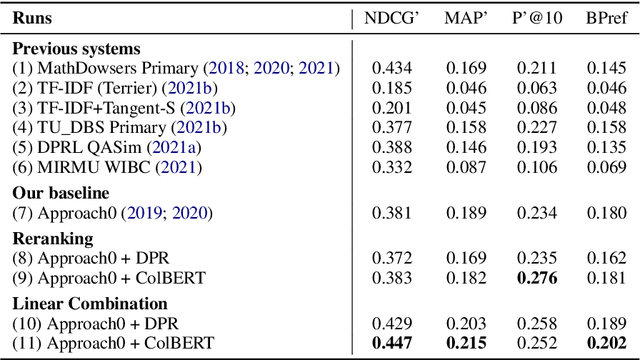
With the recent success of dense retrieval methods based on bi-encoders, a number of studies have applied this approach to various interesting downstream retrieval tasks with good efficiency and in-domain effectiveness. Recently, we have also seen the presence of dense retrieval models in Math Information Retrieval (MIR) tasks, but the most effective systems remain "classic" retrieval methods that consider rich structure features. In this work, we try to combine the best of both worlds: a well-defined structure search method for effective formula search and bi-encoder dense retrieval models to capture contextual similarities in mathematical documents. Specifically, we have evaluated two representative bi-encoder models (ColBERT and DPR) for token-level and passage-level dense retrieval on recent MIR tasks. To our best knowledge, this is the first time a DPR model has been evaluated in the MIR domain. Our result shows that bi-encoder models are complementary to existing structure search methods, and we are able to advance the state of the art on a recent MIR dataset. We have made our model checkpoints and source code publicly available for the reproduction of our results.
Telehealthcare and Covid-19: A Noninvasive & Low Cost Invasive, Scalable and Multimodal Real-Time Smartphone Application for Early Diagnosis of SARS-CoV-2 Infection
Sep 16, 2021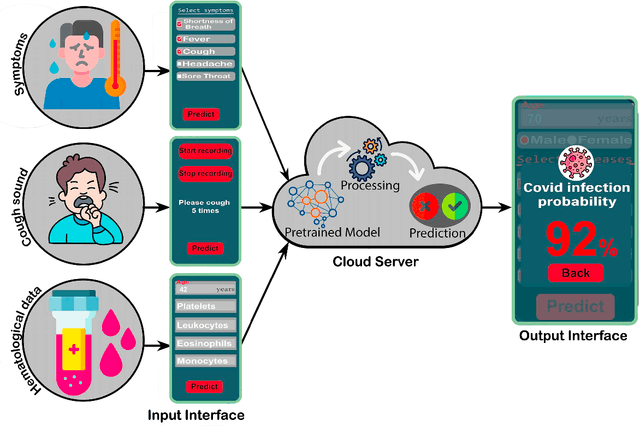
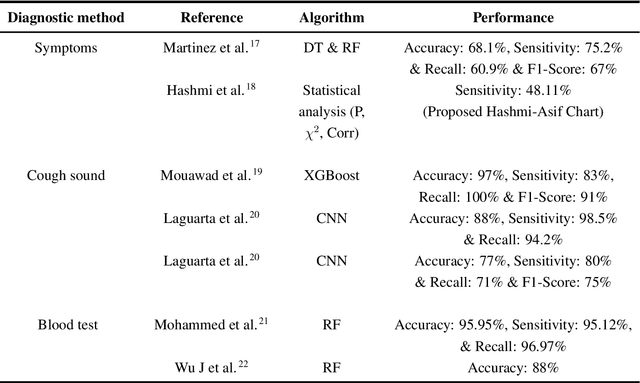
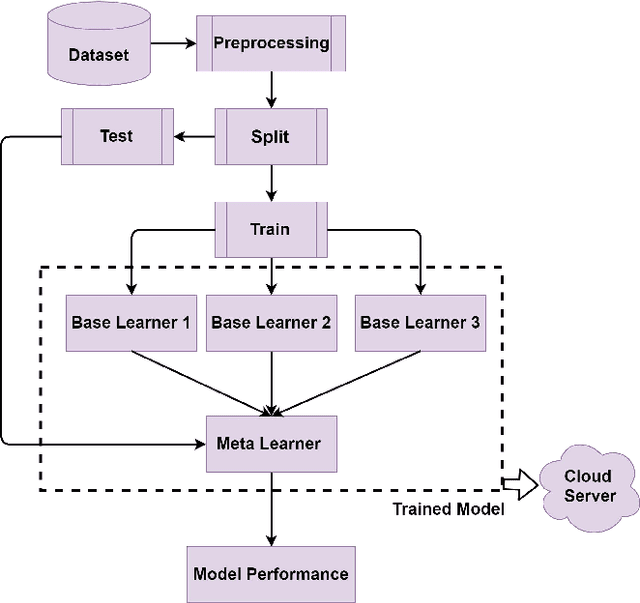
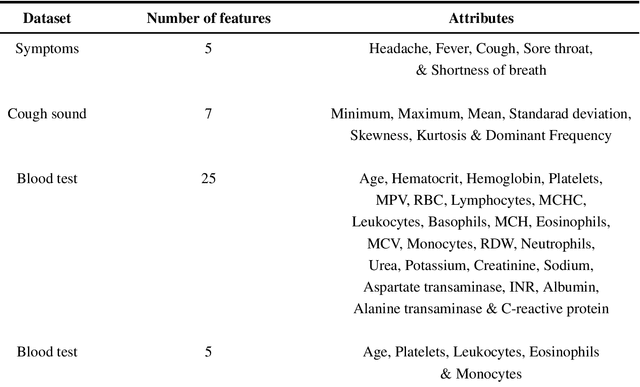
The global coronavirus pandemic overwhelmed many health care systems, enforcing lockdown and encouraged work from home to control the spread of the virus and prevent overrunning of hospitalized patients. This prompted a sharp widespread use of telehealth to provide low-risk care for patients. Nevertheless, a continuous mutation into new variants and widespread unavailability of test kits, especially in developing countries, possess the challenge to control future potential waves of infection. In this paper, we propose a novel Smartphone application-based platform for early diagnosis of possible Covid-19 infected patients. The application provides three modes of diagnosis from possible symptoms, cough sound, and specific blood biomarkers. When a user chooses a particular setting and provides the necessary information, it sends the data to a trained machine learning (ML) model deployed in a remote server using the internet. The ML algorithm then predicts the possibility of contracting Covid-19 and sends the feedback to the user. The entire procedure takes place in real-time. Our machine learning models can identify Covid-19 patients with an accuracy of 100%, 95.65%, and 77.59% from blood parameters, cough sound, and symptoms respectively. Moreover, the ML sensitivity for blood and sound is 100%, which indicates correct identification of Covid positive patients. This is significant in limiting the spread of the virus. The multimodality offers multiplex diagnostic methods to better classify possible infectees and together with the instantaneous nature of our technique, demonstrates the power of telehealthcare as an easy and widespread low-cost scalable diagnostic solution for future pandemics.
Decontextualized I3D ConvNet for ultra-distance runners performance analysis at a glance
Mar 25, 2022
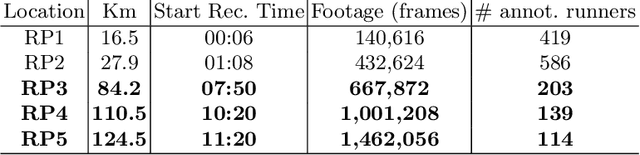
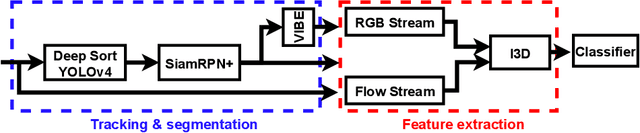

In May 2021, the site runnersworld.com published that participation in ultra-distance races has increased by 1,676% in the last 23 years. Moreover, nearly 41% of those runners participate in more than one race per year. The development of wearable devices has undoubtedly contributed to motivating participants by providing performance measures in real-time. However, we believe there is room for improvement, particularly from the organizers point of view. This work aims to determine how the runners performance can be quantified and predicted by considering a non-invasive technique focusing on the ultra-running scenario. In this sense, participants are captured when they pass through a set of locations placed along the race track. Each footage is considered an input to an I3D ConvNet to extract the participant's running gait in our work. Furthermore, weather and illumination capture conditions or occlusions may affect these footages due to the race staff and other runners. To address this challenging task, we have tracked and codified the participant's running gait at some RPs and removed the context intending to ensure a runner-of-interest proper evaluation. The evaluation suggests that the features extracted by an I3D ConvNet provide enough information to estimate the participant's performance along the different race tracks.
A Conformer Based Acoustic Model for Robust Automatic Speech Recognition
Mar 01, 2022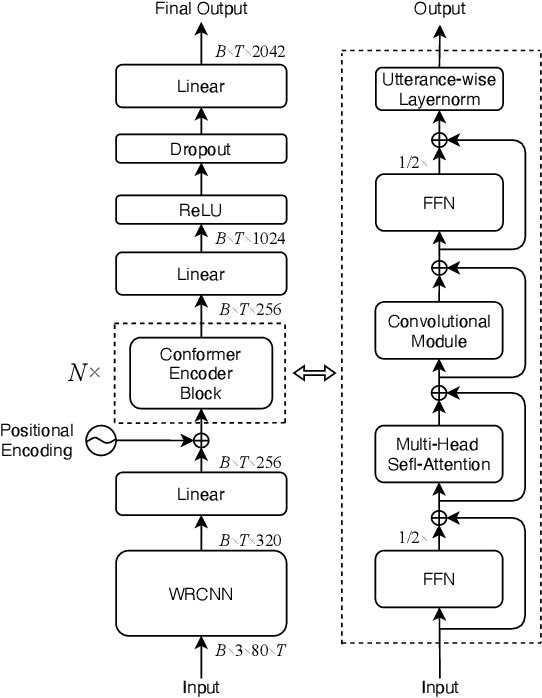
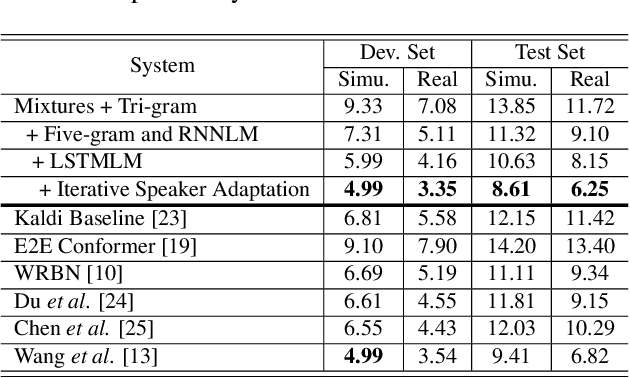
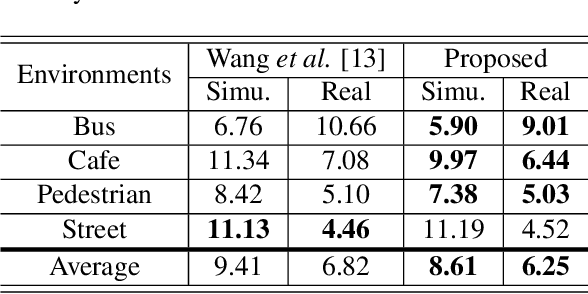
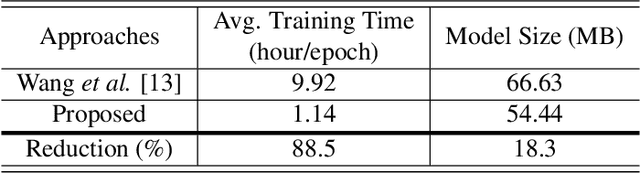
This study addresses robust automatic speech recognition (ASR) by introducing a Conformer-based acoustic model. The proposed model builds on a state-of-the-art recognition system using a bi-directional long short-term memory (BLSTM) model with utterance-wise dropout and iterative speaker adaptation, but employs a Conformer encoder instead of the BLSTM network. The Conformer encoder uses a convolution-augmented attention mechanism for acoustic modeling. The proposed system is evaluated on the monaural ASR task of the CHiME-4 corpus. Coupled with utterance-wise normalization and speaker adaptation, our model achieves $6.25\%$ word error rate, which outperforms the previous best system by $8.4\%$ relatively. In addition, the proposed Conformer-based model is $18.3\%$ smaller in model size and reduces training time by $88.5\%$.
Bayesian Neural Hawkes Process for Event Uncertainty Prediction
Dec 29, 2021

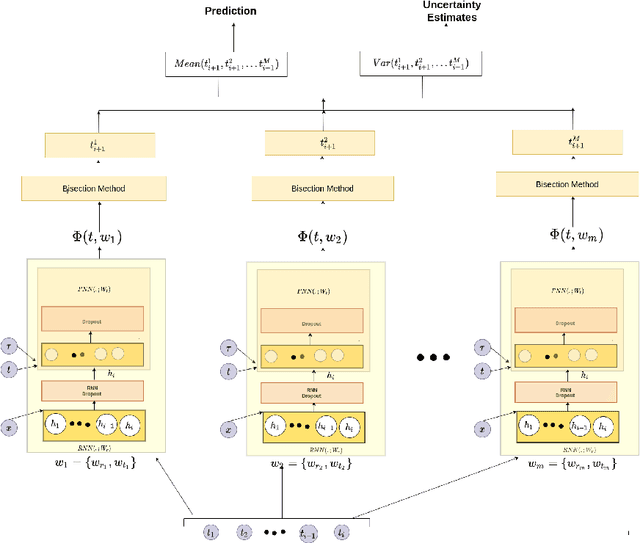
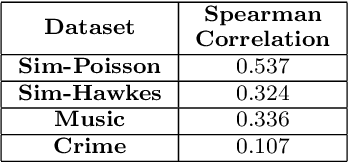
Many applications comprise of sequences of event data with the time of occurrence of the events. Models for predicting time of occurrence play a significant role in a diverse set of applications like social networks, financial transactions, healthcare, and human mobility. Recent works have introduced neural network based point process for modeling event-times, and were shown to provide state-of-the-art performance in predicting event-times. However, neural networks are poor at quantifying predictive uncertainty and tend to produce overconfident predictions during extrapolation. A proper uncertainty quantification is crucial for many practical applications. Therefore, we propose a novel point process model, Bayesian Neural Hawkes process which leverages uncertainty modelling capability of Bayesian models and generalization capability of the neural networks. The model is capable of predicting epistemic uncertainty over the event occurrence time and its effectiveness is demonstrated for on simulated and real-world datasets.
AdaSplats: Adaptative Splats from Semantic Point Cloud for Fast and High-Fidelity LiDAR Simulation
Mar 17, 2022
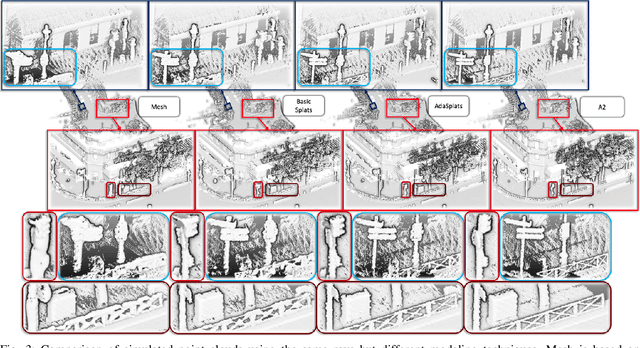
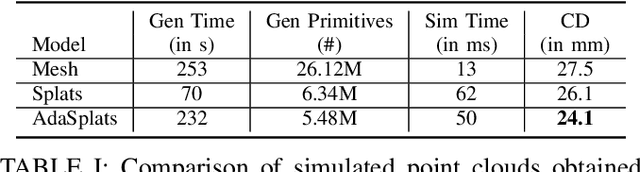
LiDAR sensors provide rich 3D information about surrounding scenes and are becoming increasingly important for autonomous vehicles' tasks, such as semantic segmentation, object detection, and tracking. Being able to simulate a LiDAR sensor will accelerate the testing, validation, and deployment of autonomous vehicles while reducing the cost and eliminating the risks of testing in real-world scenarios. To tackle the issue of simulating LiDAR data with high fidelity, we present a pipeline that leverages real-world point clouds acquired by mobile mapping systems. Point-based geometry representations, more specifically splats, have proven their ability to accurately model the underlying surface in very large point clouds. Showing the limits of basic splatting, we introduce an adaptative splats generation method that accurately models the underlying 3D geometry, especially for thin structures. We have also developed a LiDAR simulation that is 200 times faster-than-real-time by ray casting on GPU while focusing on efficiently handling large point clouds. We test our LiDAR simulation in real-world conditions, showing qualitative and quantitative results against basic splatting and meshing, demonstrating the superiority of our modeling technique.
Multipath-assisted Radio Sensing and Occupancy Detection for Smart In-house Parking in ITS
Jan 16, 2022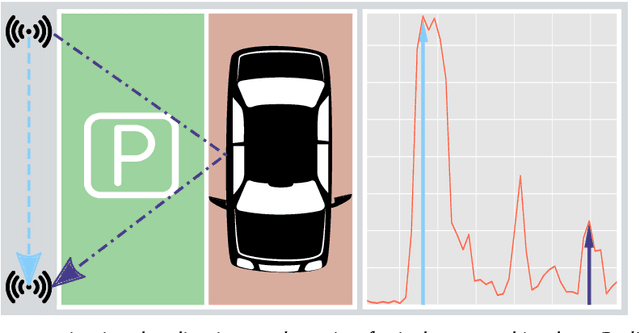

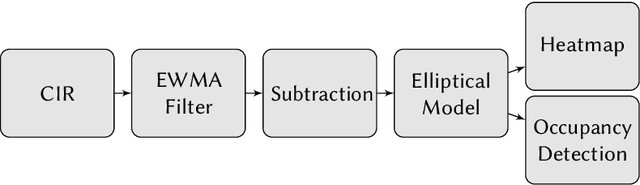

Joint, radio-based communication, localization and sensing is a rapidly emerging research field with various application potentials. Greatly benefiting from these capabilities, smart city, mobility, and logistic concepts are key components for maximizing the efficiency of modern transportation systems. In urban environments, both the search for parking space and freight transport are time- and space-consuming and present the bottlenecks for these transportation chains. Providing location information for these heterogeneous requirement profiles (both active and passive localization of objects), can be realized by using retrofittable wireless sensor networks, which are typically only deployed for active localization. An additional passive detection of objects can be achieved by assessing signal reflections and multipath properties of the transmission channel stored within the Channel Impulse Response (CIR). In this work, a proof-of-concept realization and preliminary experimental results of a CIR-based occupancy detection for parking lots are presented. As the time resolution is dependent on available bandwidth, the CIR of Ultra-wideband transceivers are used. For this, the CIR is smoothed and time-variant changes within it are detected by performing a background subtraction. Finally, the reflecting objects are mapped to individual parking lots. The developed method is tested in an in-house parking garage. The work provided is a foundation for passive occupancy detection, whose capabilities can prospectively be enhanced by exploiting additional physical layers, such as 5G or even 6G.
Triple M: A Practical Neural Text-to-speech System With Multi-guidance Attention And Multi-band Multi-time Lpcnet
Jan 30, 2021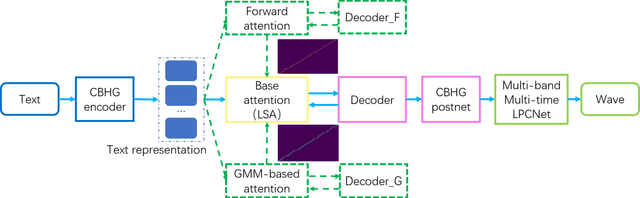

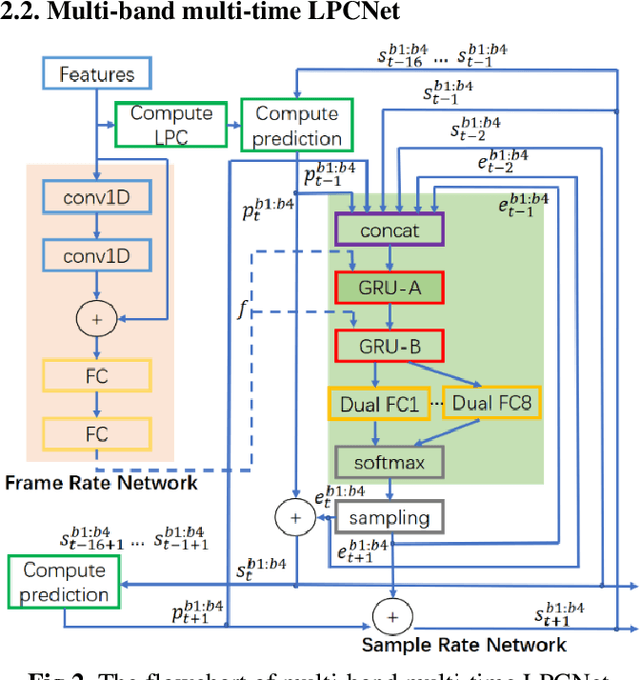

Although the sequence-to-sequence network with attention mechanism and neural vocoder has made great progress in the quality of speech synthesis, there are still some problems to be solved in large-scale real-time applications. For example, to avoid long sentence alignment failure while maintaining rich prosody, and to reduce the computational overhead while ensuring perceptual quality. In order to address these issues, we propose a practical neural text-to-speech system, named Triple M, consisting of a seq2seq model with multi-guidance attention and a multi-band multi-time LPCNet. The former uses alignment results of different attention mechanisms to guide the learning of the basic attention mechanism, and only retains the basic attention mechanism during inference. This approach can improve the performance of the text-to-feature module by absorbing the advantages of all guidance attention methods without modifying the basic inference architecture. The latter reduces the computational complexity of LPCNet through combining multi-band and multi-time strategies. The multi-band strategy enables the LPCNet to generate sub-band signals in each inference. By predicting the sub-band signals of adjacent time in one forward operation, the multi-time strategy further decreases the number of inferences required. Due to the multi-band and multi-time strategy, the vocoder speed is increased by 2.75x on a single CPU and the MOS (mean opinion score) degradation is slight.