 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Noise fingerprints in quantum computers: Machine learning software tools
Feb 09, 2022
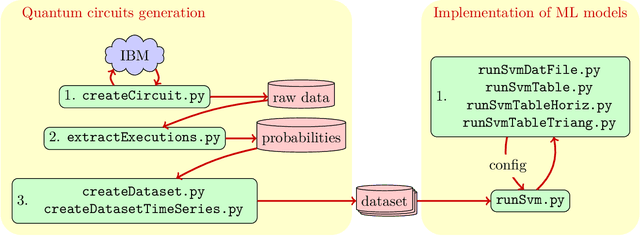
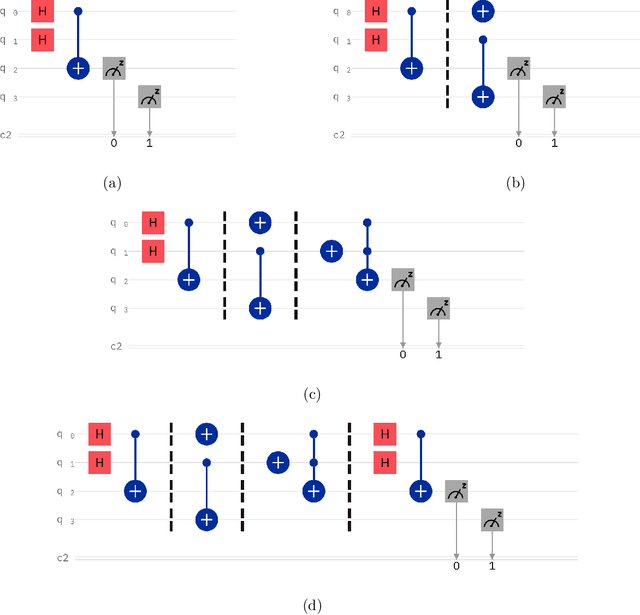
In this paper we present the high-level functionalities of a quantum-classical machine learning software, whose purpose is to learn the main features (the fingerprint) of quantum noise sources affecting a quantum device, as a quantum computer. Specifically, the software architecture is designed to classify successfully (more than 99% of accuracy) the noise fingerprints in different quantum devices with similar technical specifications, or distinct time-dependences of a noise fingerprint in single quantum machines.
Reinforcement Learning Approach to Clear Paths of Robots in Elevator Environment
Mar 18, 2022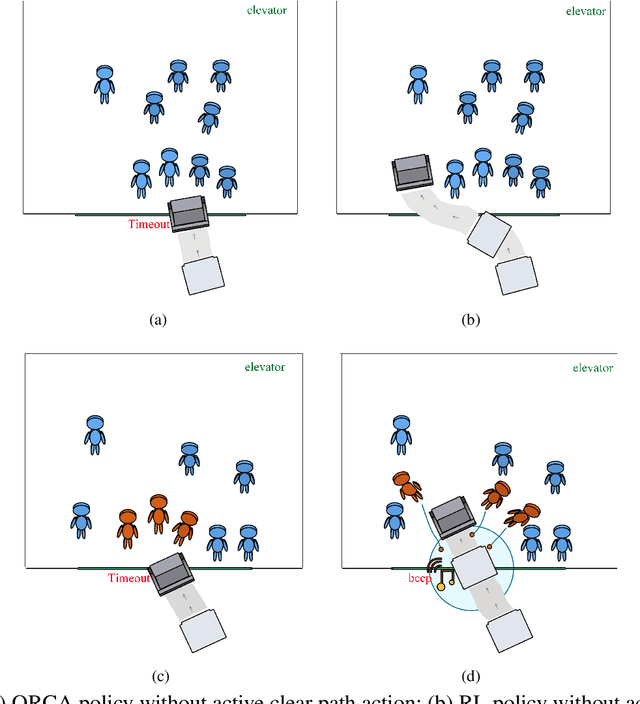
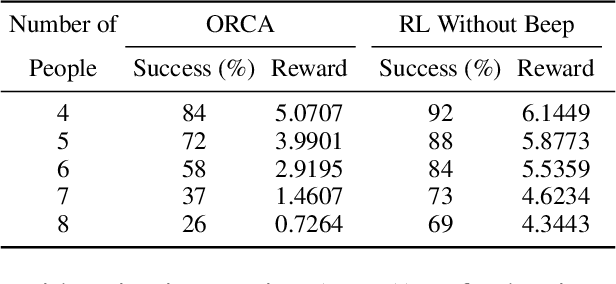
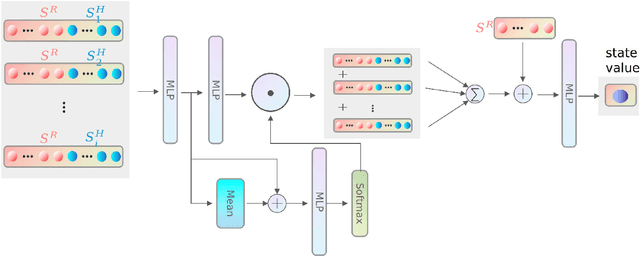
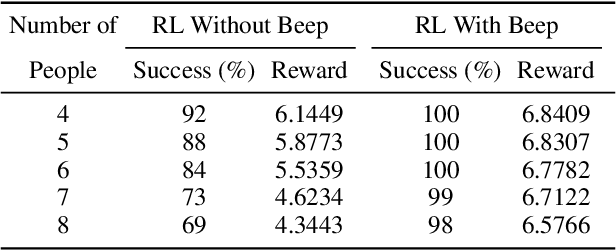
Efficiently using the space of an elevator for a service robot is very necessary, due to the need for reducing the amount of time caused by waiting for the next elevator. To solve this, we propose a hybrid approach that combines reinforcement learning (RL) with voice interaction for robot navigation in the scene of entering the elevator. RL provides robots with a high exploration ability to find a new clear path to enter the elevator compared to the traditional navigation methods such as Optimal Reciprocal Collision Avoidance (ORCA). The proposed method allows the robot to take an active clear path action towards the elevator whilst a crowd of people stands at the entrance of the elevator wherein there are still lots of space. This is done by embedding a clear path action (beep) into the RL framework, and the proposed navigation policy leads the robot to finish tasks efficiently and safely. Our model approach provides a great improvement in the success rate and reward of entering the elevator compared to state-of-the-art ORCA and RL navigation policy without beep.
On the Post-hoc Explainability of Deep Echo State Networks for Time Series Forecasting, Image and Video Classification
Feb 17, 2021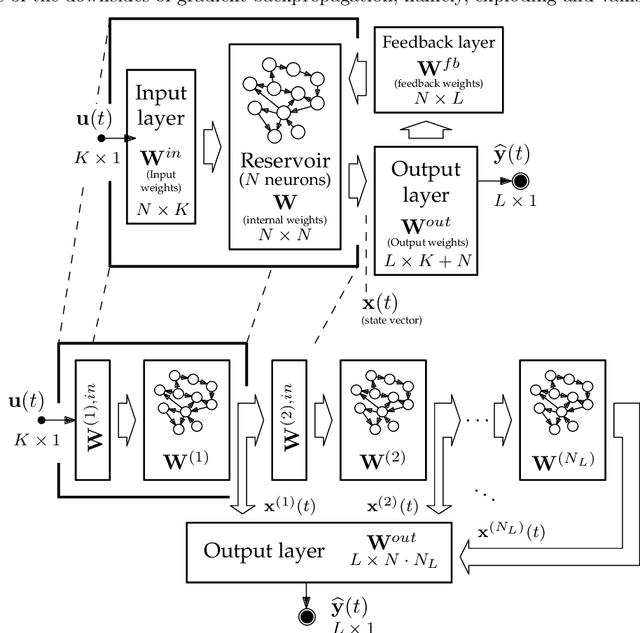
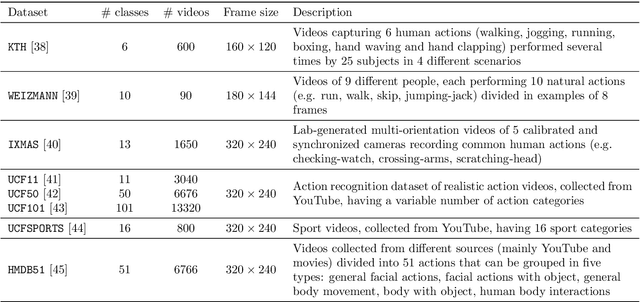
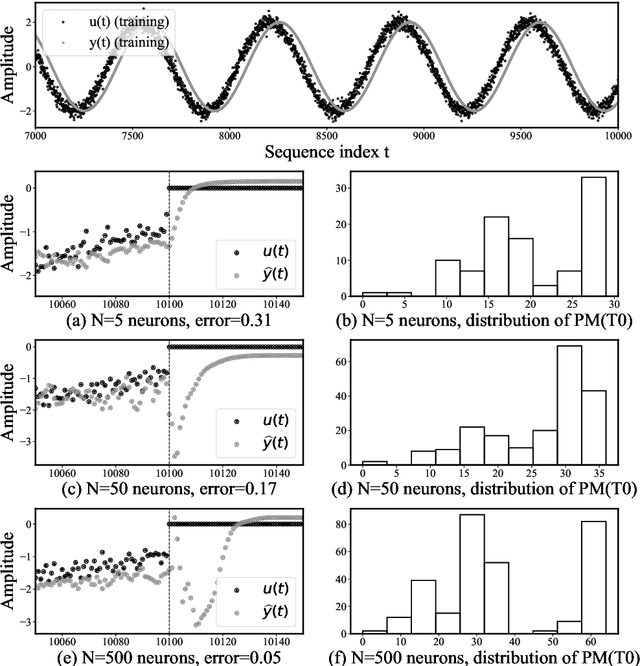
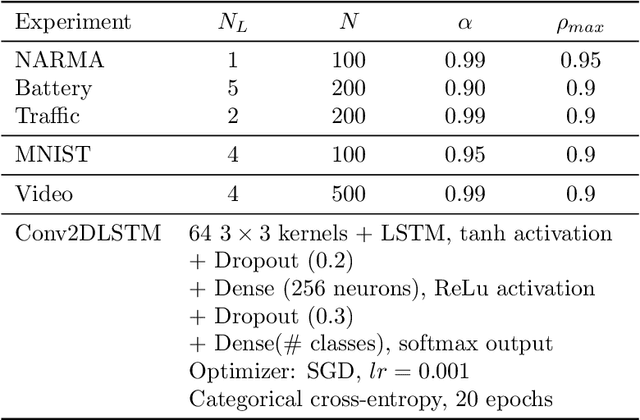
Since their inception, learning techniques under the Reservoir Computing paradigm have shown a great modeling capability for recurrent systems without the computing overheads required for other approaches. Among them, different flavors of echo state networks have attracted many stares through time, mainly due to the simplicity and computational efficiency of their learning algorithm. However, these advantages do not compensate for the fact that echo state networks remain as black-box models whose decisions cannot be easily explained to the general audience. This work addresses this issue by conducting an explainability study of Echo State Networks when applied to learning tasks with time series, image and video data. Specifically, the study proposes three different techniques capable of eliciting understandable information about the knowledge grasped by these recurrent models, namely, potential memory, temporal patterns and pixel absence effect. Potential memory addresses questions related to the effect of the reservoir size in the capability of the model to store temporal information, whereas temporal patterns unveils the recurrent relationships captured by the model over time. Finally, pixel absence effect attempts at evaluating the effect of the absence of a given pixel when the echo state network model is used for image and video classification. We showcase the benefits of our proposed suite of techniques over three different domains of applicability: time series modeling, image and, for the first time in the related literature, video classification. Our results reveal that the proposed techniques not only allow for a informed understanding of the way these models work, but also serve as diagnostic tools capable of detecting issues inherited from data (e.g. presence of hidden bias).
Information-Theoretic Odometry Learning
Mar 11, 2022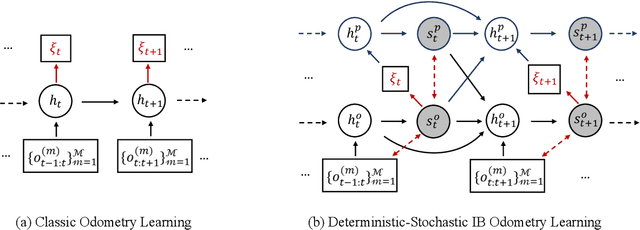
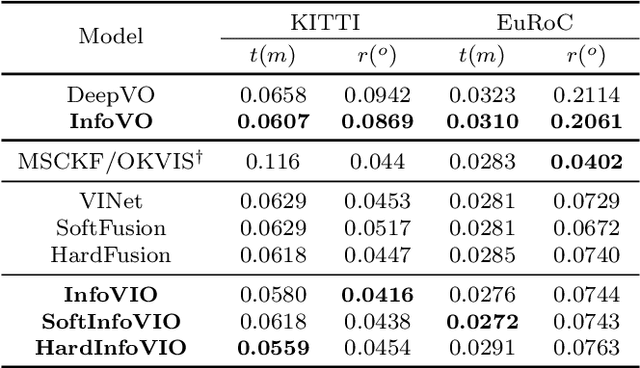
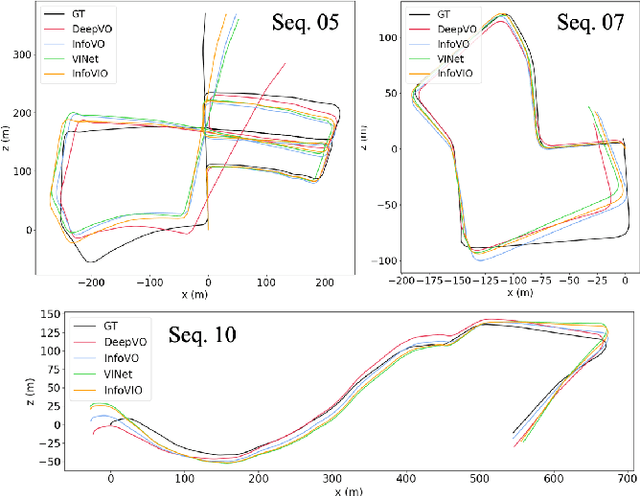
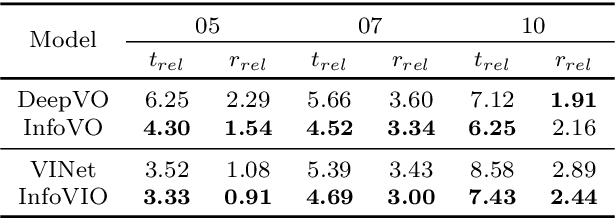
In this paper, we propose a unified information theoretic framework for learning-motivated methods aimed at odometry estimation, a crucial component of many robotics and vision tasks such as navigation and virtual reality where relative camera poses are required in real time. We formulate this problem as optimizing a variational information bottleneck objective function, which eliminates pose-irrelevant information from the latent representation. The proposed framework provides an elegant tool for performance evaluation and understanding in information-theoretic language. Specifically, we bound the generalization errors of the deep information bottleneck framework and the predictability of the latent representation. These provide not only a performance guarantee but also practical guidance for model design, sample collection, and sensor selection. Furthermore, the stochastic latent representation provides a natural uncertainty measure without the needs for extra structures or computations. Experiments on two well-known odometry datasets demonstrate the effectiveness of our method.
Reinforcement-learning calibration of coherent-state receivers on variable-loss optical channels
Mar 18, 2022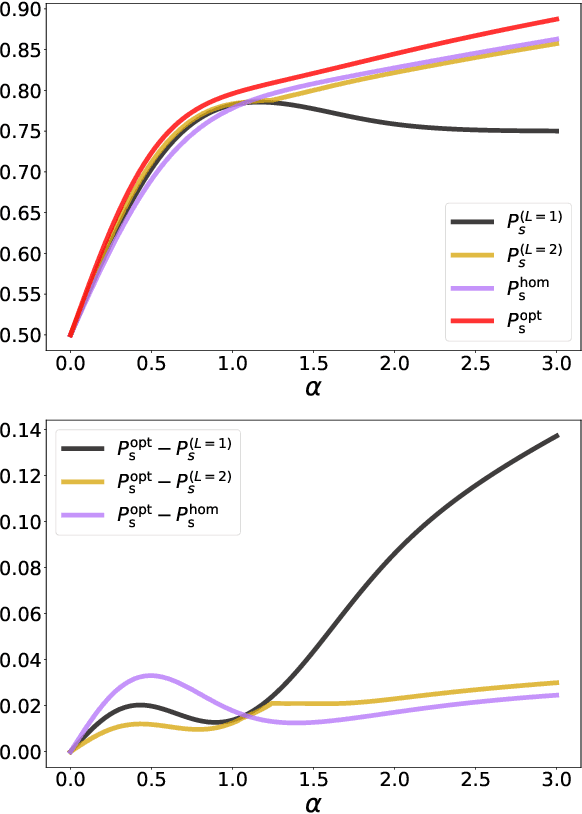

We study the problem of calibrating a quantum receiver for optical coherent states when transmitted on a quantum optical channel with variable transmissivity, a common model for long-distance optical-fiber and free/deep-space optical communication. We optimize the error probability of legacy adaptive receivers, such as Kennedy's and Dolinar's, on average with respect to the channel transmissivity distribution. We then compare our results with the ultimate error probability attainable by a general quantum device, computing the Helstrom bound for mixtures of coherent-state hypotheses, for the first time to our knowledge, and with homodyne measurements. With these tools, we first analyze the simplest case of two different transmissivity values; we find that the strategies adopted by adaptive receivers exhibit strikingly new features as the difference between the two transmissivities increases. Finally, we employ a recently introduced library of shallow reinforcement learning methods, demonstrating that an intelligent agent can learn the optimal receiver setup from scratch by training on repeated communication episodes on the channel with variable transmissivity and receiving rewards if the coherent-state message is correctly identified.
Three things everyone should know about Vision Transformers
Mar 18, 2022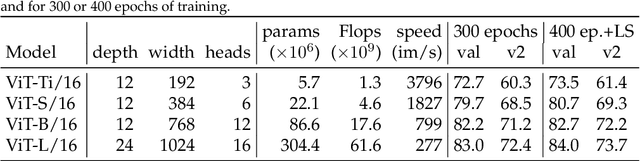
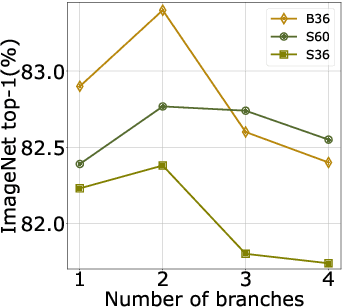
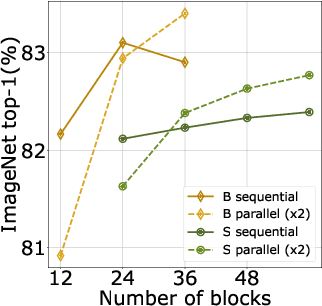
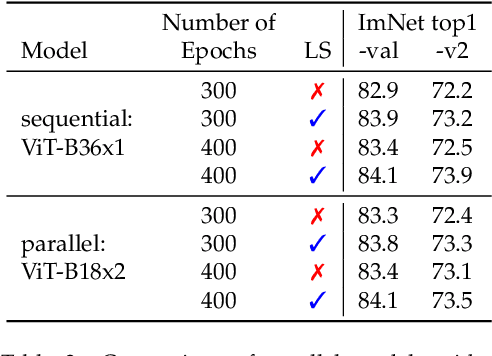
After their initial success in natural language processing, transformer architectures have rapidly gained traction in computer vision, providing state-of-the-art results for tasks such as image classification, detection, segmentation, and video analysis. We offer three insights based on simple and easy to implement variants of vision transformers. (1) The residual layers of vision transformers, which are usually processed sequentially, can to some extent be processed efficiently in parallel without noticeably affecting the accuracy. (2) Fine-tuning the weights of the attention layers is sufficient to adapt vision transformers to a higher resolution and to other classification tasks. This saves compute, reduces the peak memory consumption at fine-tuning time, and allows sharing the majority of weights across tasks. (3) Adding MLP-based patch pre-processing layers improves Bert-like self-supervised training based on patch masking. We evaluate the impact of these design choices using the ImageNet-1k dataset, and confirm our findings on the ImageNet-v2 test set. Transfer performance is measured across six smaller datasets.
Joint Activity and Blind Information Detection for UAV-Assisted Massive IoT Access
Jan 03, 2022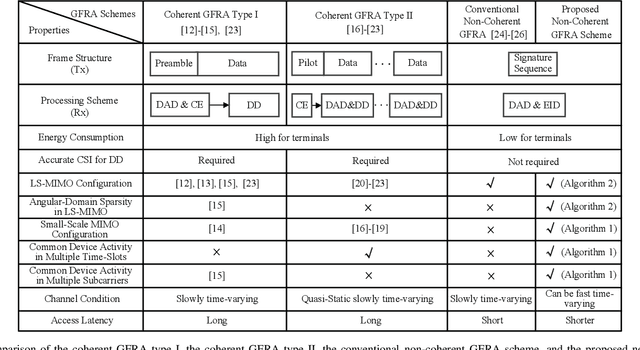
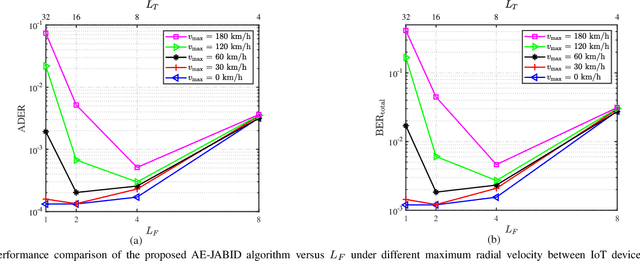
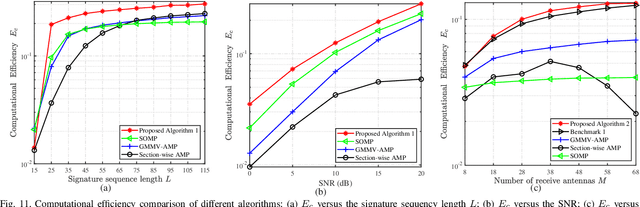
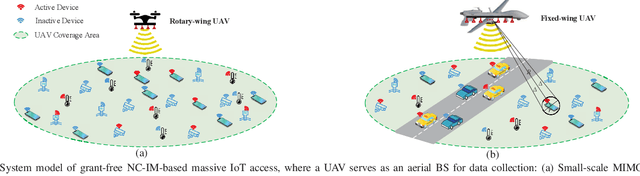
Grant-free non-coherent index-modulation (NC-IM) has been recently considered as an efficient massive access scheme for enabling cost- and energy-limited Internet-of-Things (IoT) devices that transmit small data packets. This paper investigates the grant-free NC-IM scheme combined with orthogonal frequency division multiplexing for applicant to unmanned aerial vehicle (UAV)-based massive IoT access. Specifically, each device is assigned a unique non-orthogonal signature sequence codebook. Each active device transmits one of its signature sequences in the given time-frequency resources, by modulating the information in the index of the transmitted signature sequence. For small-scale multiple-input multiple-output (MIMO) deployed at the UAV-based aerial base station (BS), by jointly exploiting the space-time-frequency domain device activity, we propose a computationally efficient space-time-frequency joint activity and blind information detection (JABID) algorithm with significantly improved detection performance. Furthermore, for large-scale MIMO deployed at the aerial BS, by leveraging the sparsity of the virtual angular-domain channels, we propose an angular-domain based JABID algorithm for improving the system performance with reduced access latency. In addition, for the case of high mobility IoT devices and/or UAVs, we introduce a time-frequency spread transmission (TFST) strategy for the proposed JABID algorithms to combat doubly-selective fading channels. Finally, extensive simulation results are illustrated to verify the superiority of the proposed algorithms and the TFST strategy over known state-of-the-art algorithms.
ThreshNet: An Efficient DenseNet using Threshold Mechanism to Reduce Connections
Jan 09, 2022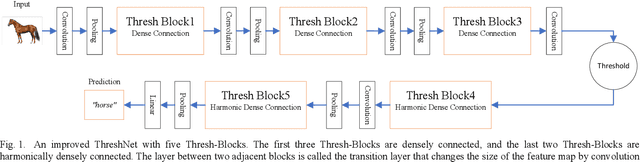
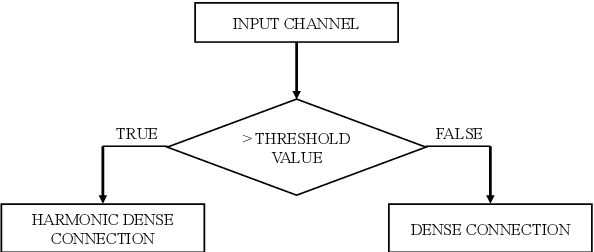
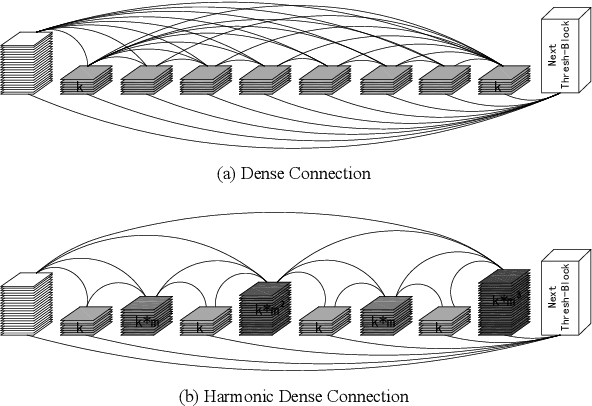
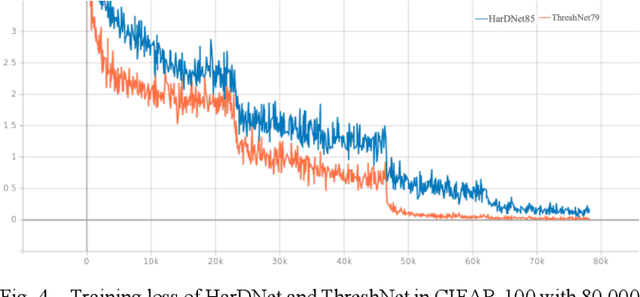
With the continuous development of neural networks in computer vision tasks, more and more network architectures have achieved outstanding success. As one of the most advanced neural network architectures, DenseNet shortcuts all feature maps to solve the problem of model depth. Although this network architecture has excellent accuracy at low MACs (multiplications and accumulations), it takes excessive inference time. To solve this problem, HarDNet reduces the connections between feature maps, making the remaining connections resemble harmonic waves. However, this compression method may result in decreasing model accuracy and increasing MACs and model size. This network architecture only reduces the memory access time, its overall performance still needs to be improved. Therefore, we propose a new network architecture using threshold mechanism to further optimize the method of connections. Different numbers of connections for different convolutional layers are discarded to compress the feature maps in ThreshNet. The proposed network architecture used three datasets, CIFAR-10, CIFAR-100, and SVHN, to evaluate the performance for image classifications. Experimental results show that ThreshNet achieves up to 60% reduction in inference time compared to DenseNet, and up to 35% faster training speed and 20% reduction in error rate compared to HarDNet on these datasets.
Towards Universal Backward-Compatible Representation Learning
Mar 18, 2022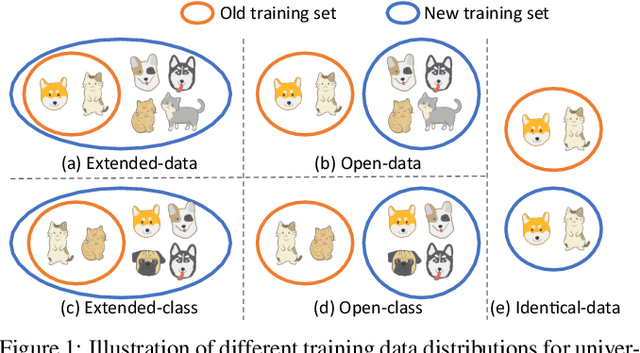
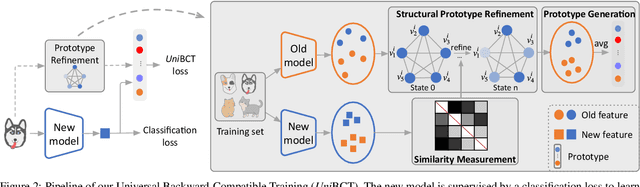
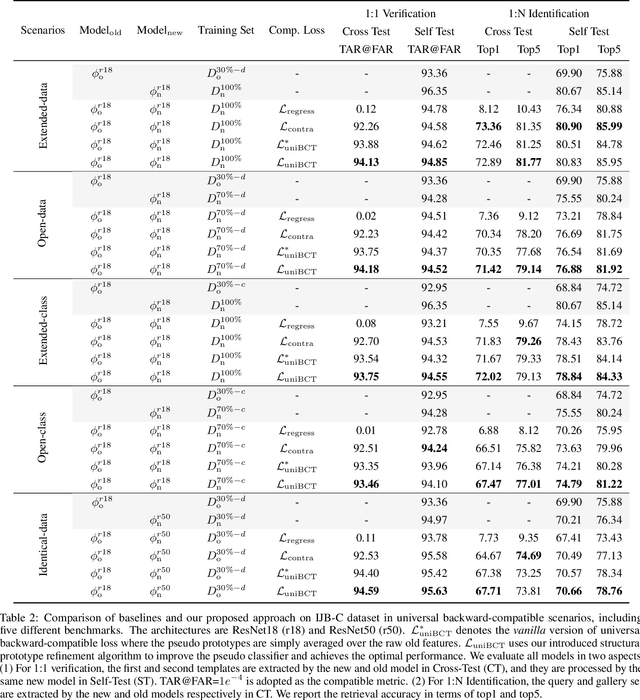
Conventional model upgrades for visual search systems require offline refresh of gallery features by feeding gallery images into new models (dubbed as "backfill"), which is time-consuming and expensive, especially in large-scale applications. The task of backward-compatible representation learning is therefore introduced to support backfill-free model upgrades, where the new query features are interoperable with the old gallery features. Despite the success, previous works only investigated a close-set training scenario (i.e., the new training set shares the same classes as the old one), and are limited by more realistic and challenging open-set scenarios. To this end, we first introduce a new problem of universal backward-compatible representation learning, covering all possible data split in model upgrades. We further propose a simple yet effective method, dubbed as Universal Backward-Compatible Training (UniBCT) with a novel structural prototype refinement algorithm, to learn compatible representations in all kinds of model upgrading benchmarks in a unified manner. Comprehensive experiments on the large-scale face recognition datasets MS1Mv3 and IJB-C fully demonstrate the effectiveness of our method.
SlimFL: Federated Learning with Superposition Coding over Slimmable Neural Networks
Mar 26, 2022
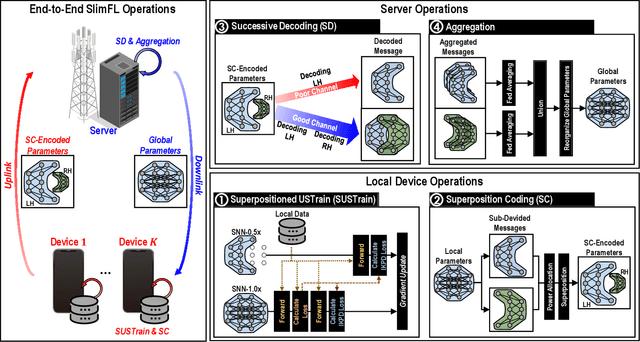
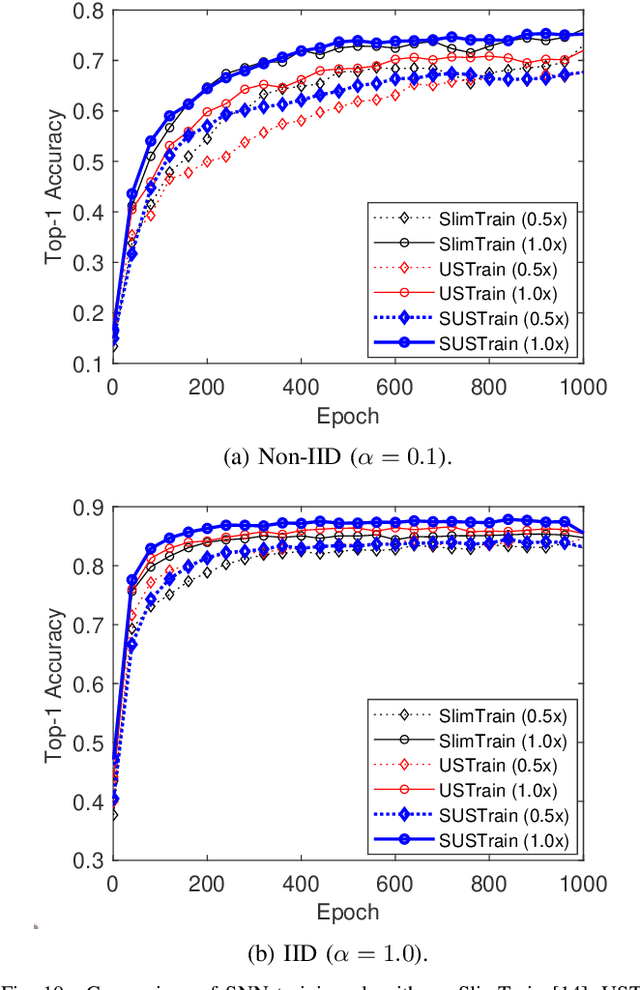
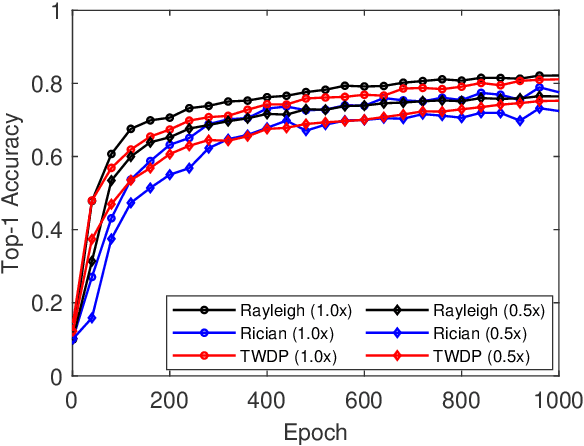
Federated learning (FL) is a key enabler for efficient communication and computing leveraging devices' distributed computing capabilities. However, applying FL in practice is challenging due to the local devices' heterogeneous energy, wireless channel conditions, and non-independently and identically distributed (non-IID) data distributions. To cope with these issues, this paper proposes a novel learning framework by integrating FL and width-adjustable slimmable neural networks (SNN). Integrating FL with SNNs is challenging due to time-varing channel conditions and data distributions. In addition, existing multi-width SNN training algorithms are sensitive to the data distributions across devices, which makes SNN ill-suited for FL. Motivated by this, we propose a communication and energy-efficient SNN-based FL (named SlimFL) that jointly utilizes superposition coding (SC) for global model aggregation and superposition training (ST) for updating local models. By applying SC, SlimFL exchanges the superposition of multiple width configurations decoded as many times as possible for a given communication throughput. Leveraging ST, SlimFL aligns the forward propagation of different width configurations while avoiding inter-width interference during backpropagation. We formally prove the convergence of SlimFL. The result reveals that SlimFL is not only communication-efficient but also deals with the non-IID data distributions and poor channel conditions, which is also corroborated by data-intensive simulations.