 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Polynomial-Time Algorithms for Counting and Sampling Markov Equivalent DAGs
Dec 17, 2020
Counting and uniform sampling of directed acyclic graphs (DAGs) from a Markov equivalence class are fundamental tasks in graphical causal analysis. In this paper, we show that these tasks can be performed in polynomial time, solving a long-standing open problem in this area. Our algorithms are effective and easily implementable. Experimental results show that the algorithms significantly outperform state-of-the-art methods.
Finite-Time Analysis for Double Q-learning
Sep 29, 2020
Although Q-learning is one of the most successful algorithms for finding the best action-value function (and thus the optimal policy) in reinforcement learning, its implementation often suffers from large overestimation of Q-function values incurred by random sampling. The double Q-learning algorithm proposed in~\citet{hasselt2010double} overcomes such an overestimation issue by randomly switching the update between two Q-estimators, and has thus gained significant popularity in practice. However, the theoretical understanding of double Q-learning is rather limited. So far only the asymptotic convergence has been established, which does not characterize how fast the algorithm converges. In this paper, we provide the first non-asymptotic (i.e., finite-time) analysis for double Q-learning. We show that both synchronous and asynchronous double Q-learning are guaranteed to converge to an $\epsilon$-accurate neighborhood of the global optimum by taking $\tilde{\Omega}\left(\left( \frac{1}{(1-\gamma)^6\epsilon^2}\right)^{\frac{1}{\omega}} +\left(\frac{1}{1-\gamma}\right)^{\frac{1}{1-\omega}}\right)$ iterations, where $\omega\in(0,1)$ is the decay parameter of the learning rate, and $\gamma$ is the discount factor. Our analysis develops novel techniques to derive finite-time bounds on the difference between two inter-connected stochastic processes, which is new to the literature of stochastic approximation.
Dynamic GPU Energy Optimization for Machine Learning Training Workloads
Jan 05, 2022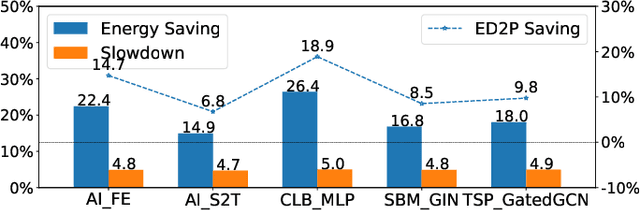
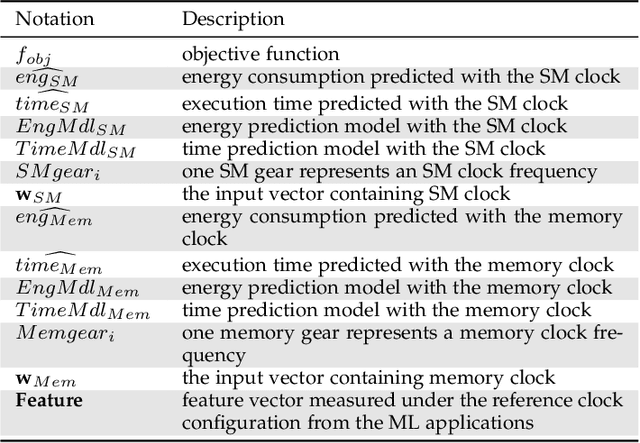
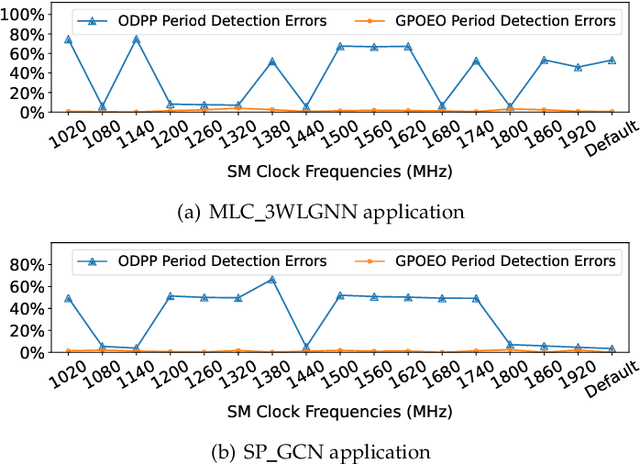
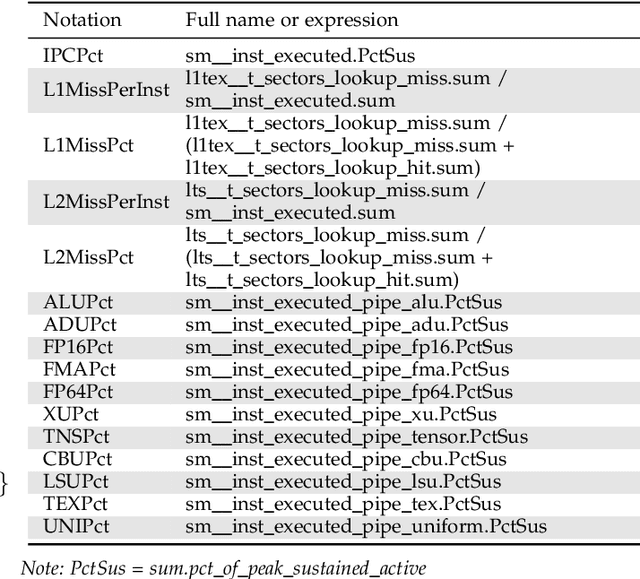
GPUs are widely used to accelerate the training of machine learning workloads. As modern machine learning models become increasingly larger, they require a longer time to train, leading to higher GPU energy consumption. This paper presents GPOEO, an online GPU energy optimization framework for machine learning training workloads. GPOEO dynamically determines the optimal energy configuration by employing novel techniques for online measurement, multi-objective prediction modeling, and search optimization. To characterize the target workload behavior, GPOEO utilizes GPU performance counters. To reduce the performance counter profiling overhead, it uses an analytical model to detect the training iteration change and only collects performance counter data when an iteration shift is detected. GPOEO employs multi-objective models based on gradient boosting and a local search algorithm to find a trade-off between execution time and energy consumption. We evaluate the GPOEO by applying it to 71 machine learning workloads from two AI benchmark suites running on an NVIDIA RTX3080Ti GPU. Compared with the NVIDIA default scheduling strategy, GPOEO delivers a mean energy saving of 16.2% with a modest average execution time increase of 5.1%.
TadGAN: Time Series Anomaly Detection Using Generative Adversarial Networks
Sep 19, 2020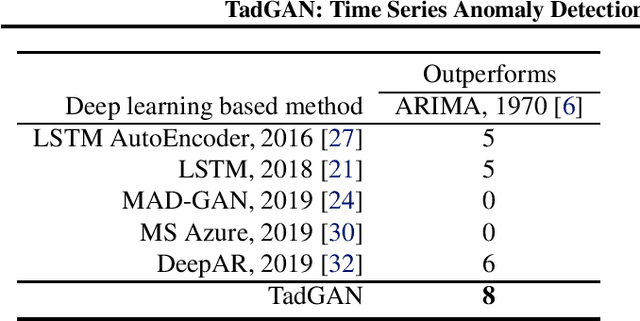
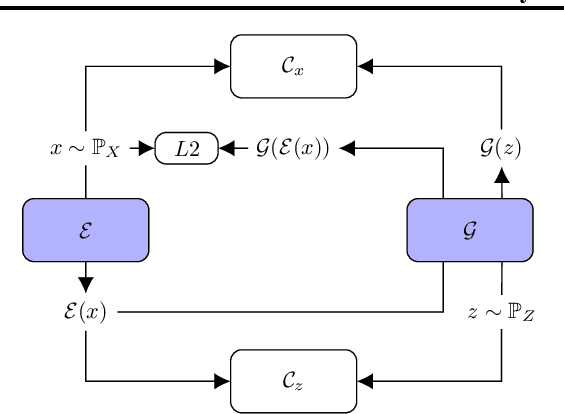
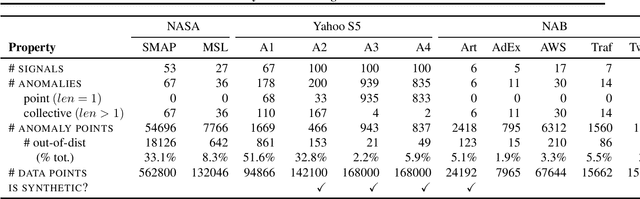
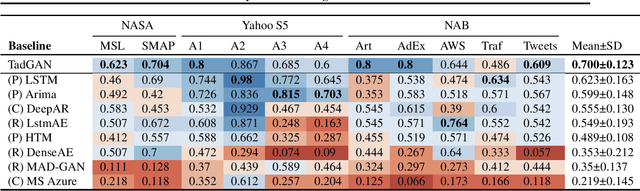
Time series anomalies can offer information relevant to critical situations facing various fields, from finance and aerospace to the IT, security, and medical domains. However, detecting anomalies in time series data is particularly challenging due to the vague definition of anomalies and said data's frequent lack of labels and highly complex temporal correlations. Current state-of-the-art unsupervised machine learning methods for anomaly detection suffer from scalability and portability issues, and may have high false positive rates. In this paper, we propose TadGAN, an unsupervised anomaly detection approach built on Generative Adversarial Networks (GANs). To capture the temporal correlations of time series distributions, we use LSTM Recurrent Neural Networks as base models for Generators and Critics. TadGAN is trained with cycle consistency loss to allow for effective time-series data reconstruction. We further propose several novel methods to compute reconstruction errors, as well as different approaches to combine reconstruction errors and Critic outputs to compute anomaly scores. To demonstrate the performance and generalizability of our approach, we test several anomaly scoring techniques and report the best-suited one. We compare our approach to 8 baseline anomaly detection methods on 11 datasets from multiple reputable sources such as NASA, Yahoo, Numenta, Amazon, and Twitter. The results show that our approach can effectively detect anomalies and outperform baseline methods in most cases (6 out of 11). Notably, our method has the highest averaged F1 score across all the datasets. Our code is open source and is available as a benchmarking tool.
Deep Reinforcement Agent for Efficient Instant Search
Mar 17, 2022
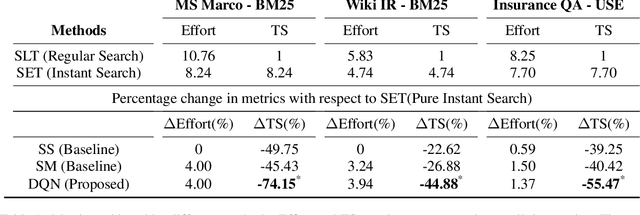
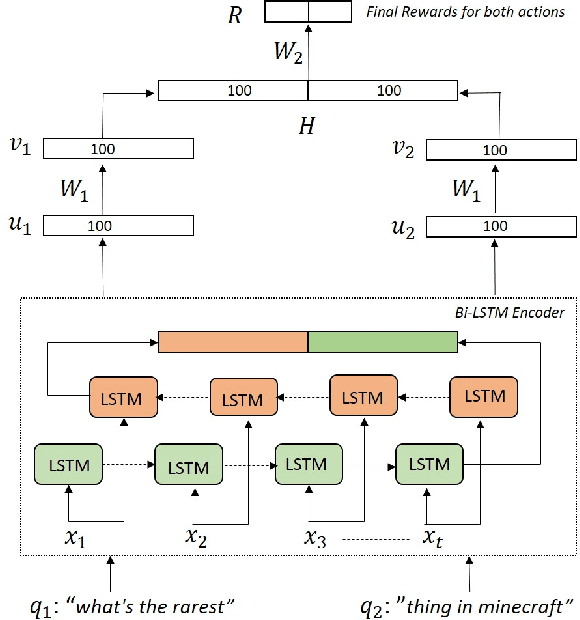
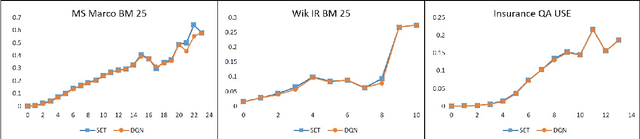
Instant Search is a paradigm where a search system retrieves answers on the fly while typing. The na\"ive implementation of an Instant Search system would hit the search back-end for results each time a user types a key, imposing a very high load on the underlying search system. In this paper, we propose to address the load issue by identifying tokens that are semantically more salient towards retrieving relevant documents and utilize this knowledge to trigger an instant search selectively. We train a reinforcement agent that interacts directly with the search engine and learns to predict the word's importance. Our proposed method treats the underlying search system as a black box and is more universally applicable to a diverse set of architectures. Furthermore, a novel evaluation framework is presented to study the trade-off between the number of triggered searches and the system's performance. We utilize the framework to evaluate and compare the proposed reinforcement method with other intuitive baselines. Experimental results demonstrate the efficacy of the proposed method towards achieving a superior trade-off.
Stable Online Control of LTV Systems Stable Online Control of Linear Time-Varying Systems
Apr 29, 2021
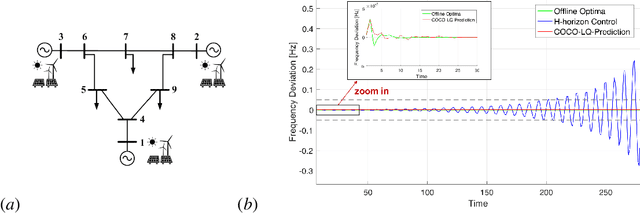

Linear time-varying (LTV) systems are widely used for modeling real-world dynamical systems due to their generality and simplicity. Providing stability guarantees for LTV systems is one of the central problems in control theory. However, existing approaches that guarantee stability typically lead to significantly sub-optimal cumulative control cost in online settings where only current or short-term system information is available. In this work, we propose an efficient online control algorithm, COvariance Constrained Online Linear Quadratic (COCO-LQ) control, that guarantees input-to-state stability for a large class of LTV systems while also minimizing the control cost. The proposed method incorporates a state covariance constraint into the semi-definite programming (SDP) formulation of the LQ optimal controller. We empirically demonstrate the performance of COCO-LQ in both synthetic experiments and a power system frequency control example.
Dynamic Gaussian Mixture based Deep Generative Model For Robust Forecasting on Sparse Multivariate Time Series
Mar 03, 2021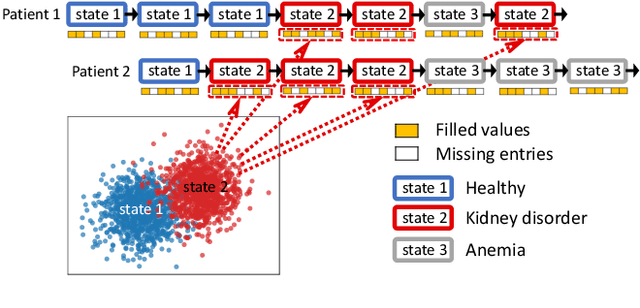
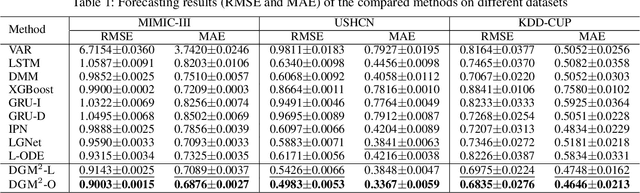
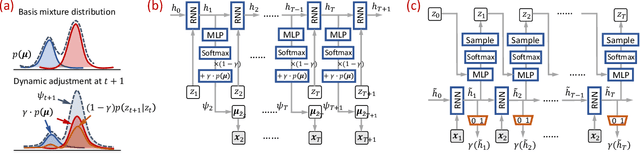
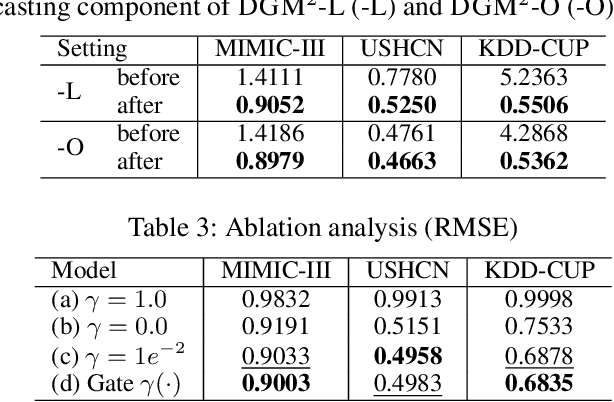
Forecasting on sparse multivariate time series (MTS) aims to model the predictors of future values of time series given their incomplete past, which is important for many emerging applications. However, most existing methods process MTS's individually, and do not leverage the dynamic distributions underlying the MTS's, leading to sub-optimal results when the sparsity is high. To address this challenge, we propose a novel generative model, which tracks the transition of latent clusters, instead of isolated feature representations, to achieve robust modeling. It is characterized by a newly designed dynamic Gaussian mixture distribution, which captures the dynamics of clustering structures, and is used for emitting timeseries. The generative model is parameterized by neural networks. A structured inference network is also designed for enabling inductive analysis. A gating mechanism is further introduced to dynamically tune the Gaussian mixture distributions. Extensive experimental results on a variety of real-life datasets demonstrate the effectiveness of our method.
Influence of Pedestrian Collision Warning Systems on Driver Behavior: A Driving Simulator Study
Dec 14, 2021
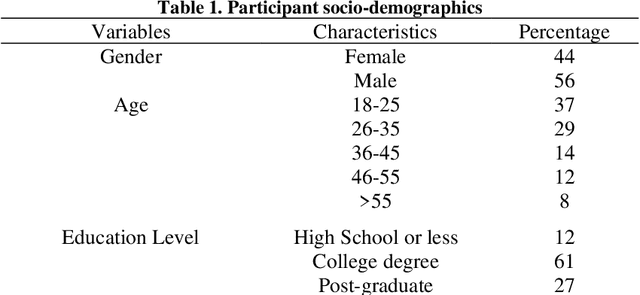

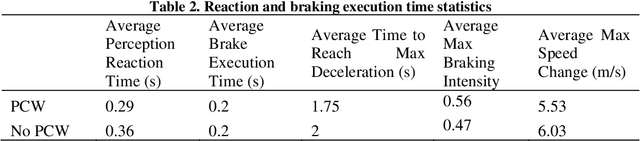
With the advent of connected and automated vehicle (CAV) technology, there is an increasing need to evaluate driver behavior while using such technology. In this first of a kind study, a pedestrian collision warning (PCW) system using CAV technology, was introduced in a driving simulator environment, to evaluate driver braking behavior, in the presence of a jaywalking pedestrian. A total of 93 participants from diverse socio-economic backgrounds were recruited for this study, for which a virtual network of downtown Baltimore was created. An eye tracking device was also used to observe distractions and head movements. A Log logistic accelerated failure time (AFT) distribution model was used for this analysis, to calculate speed reduction times; time from the moment the pedestrian becomes visible, to the point where a minimum speed was reached, to allow the pedestrian to pass. The presence of the PCW system significantly impacted the speed reduction time and deceleration rate, as it increased the former and reduced the latter, which proves the effectiveness of this system in providing an effective driving maneuver, by drastically reducing speed. A jerk analysis is conducted to analyze the suddenness of braking and acceleration. Gaze analysis showed that the system was able to attract the attention of the drivers, as the majority of the drivers noticed the displayed warning. The familiarity of the driver with the route and connected vehicles reduces the speed reduction time; gender also can have a significant impact as males tend to have longer speed reduction time, i.e. more time to comfortably brake and allow the pedestrian to pass.
Corralling a Larger Band of Bandits: A Case Study on Switching Regret for Linear Bandits
Feb 12, 2022We consider the problem of combining and learning over a set of adversarial bandit algorithms with the goal of adaptively tracking the best one on the fly. The CORRAL algorithm of Agarwal et al. (2017) and its variants (Foster et al., 2020a) achieve this goal with a regret overhead of order $\widetilde{O}(\sqrt{MT})$ where $M$ is the number of base algorithms and $T$ is the time horizon. The polynomial dependence on $M$, however, prevents one from applying these algorithms to many applications where $M$ is poly$(T)$ or even larger. Motivated by this issue, we propose a new recipe to corral a larger band of bandit algorithms whose regret overhead has only \emph{logarithmic} dependence on $M$ as long as some conditions are satisfied. As the main example, we apply our recipe to the problem of adversarial linear bandits over a $d$-dimensional $\ell_p$ unit-ball for $p \in (1,2]$. By corralling a large set of $T$ base algorithms, each starting at a different time step, our final algorithm achieves the first optimal switching regret $\widetilde{O}(\sqrt{d S T})$ when competing against a sequence of comparators with $S$ switches (for some known $S$). We further extend our results to linear bandits over a smooth and strongly convex domain as well as unconstrained linear bandits.
Combining Reinforcement Learning and Optimal Transport for the Traveling Salesman Problem
Mar 02, 2022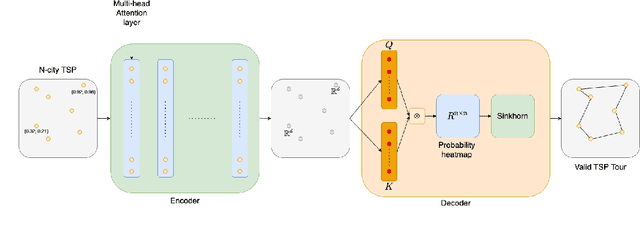
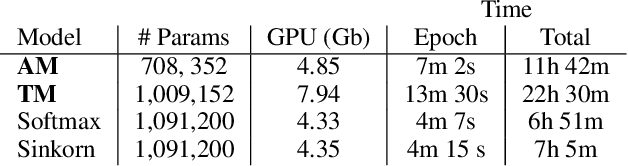
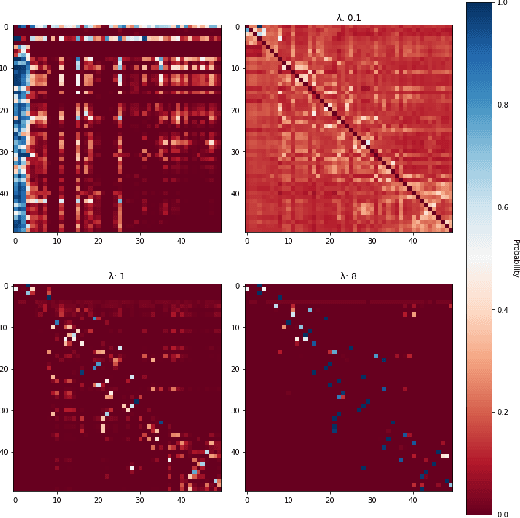
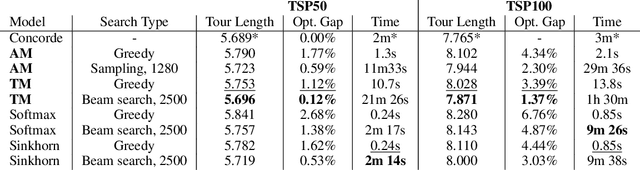
The traveling salesman problem is a fundamental combinatorial optimization problem with strong exact algorithms. However, as problems scale up, these exact algorithms fail to provide a solution in a reasonable time. To resolve this, current works look at utilizing deep learning to construct reasonable solutions. Such efforts have been very successful, but tend to be slow and compute intensive. This paper exemplifies the integration of entropic regularized optimal transport techniques as a layer in a deep reinforcement learning network. We show that we can construct a model capable of learning without supervision and inferences significantly faster than current autoregressive approaches. We also empirically evaluate the benefits of including optimal transport algorithms within deep learning models to enforce assignment constraints during end-to-end training.