 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Semi-DRDNet Semi-supervised Detail-recovery Image Deraining Network via Unpaired Contrastive Learning
Apr 06, 2022

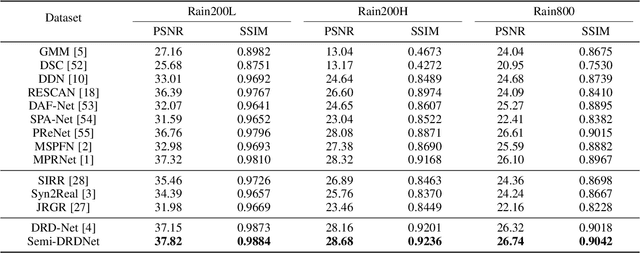
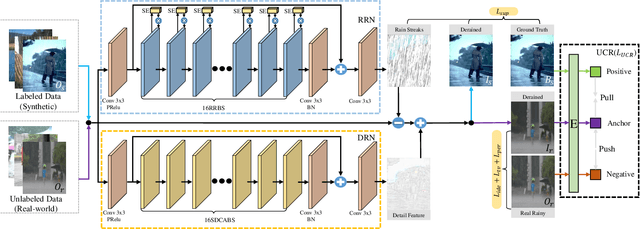

The intricacy of rainy image contents often leads cutting-edge deraining models to image degradation including remnant rain, wrongly-removed details, and distorted appearance. Such degradation is further exacerbated when applying the models trained on synthetic data to real-world rainy images. We raise an intriguing question -- if leveraging both accessible unpaired clean/rainy yet real-world images and additional detail repair guidance, can improve the generalization ability of a deraining model? To answer it, we propose a semi-supervised detail-recovery image deraining network (termed as Semi-DRDNet). Semi-DRDNet consists of three branches: 1) for removing rain streaks without remnants, we present a \textit{squeeze-and-excitation} (SE)-based rain residual network; 2) for encouraging the lost details to return, we construct a \textit{structure detail context aggregation} (SDCAB)-based detail repair network; to our knowledge, this is the first time; and 3) for bridging the domain gap, we develop a novel contrastive regularization network to learn from unpaired positive (clean) and negative (rainy) yet real-world images. As a semi-supervised learning paradigm, Semi-DRDNet operates smoothly on both synthetic and real-world rainy data in terms of deraining robustness and detail accuracy. Comparisons on four datasets show clear visual and numerical improvements of our Semi-DRDNet over thirteen state-of-the-arts.
Modurec: Recommender Systems with Feature and Time Modulation
Oct 13, 2020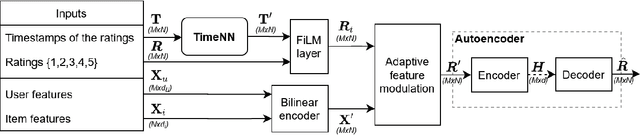
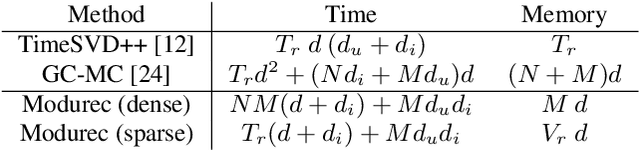

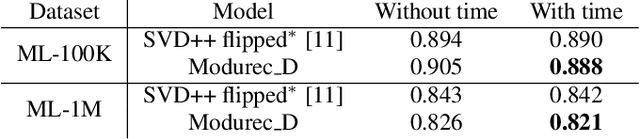
Current state of the art algorithms for recommender systems are mainly based on collaborative filtering, which exploits user ratings to discover latent factors in the data. These algorithms unfortunately do not make effective use of other features, which can help solve two well identified problems of collaborative filtering: cold start (not enough data is available for new users or products) and concept shift (the distribution of ratings changes over time). To address these problems, we propose Modurec: an autoencoder-based method that combines all available information using the feature-wise modulation mechanism, which has demonstrated its effectiveness in several fields. While time information helps mitigate the effects of concept shift, the combination of user and item features improve prediction performance when little data is available. We show on Movielens datasets that these modifications produce state-of-the-art results in most evaluated settings compared with standard autoencoder-based methods and other collaborative filtering approaches.
A Framework for Real-time Traffic Trajectory Tracking, Speed Estimation, and Driver Behavior Calibration at Urban Intersections Using Virtual Traffic Lanes
Jun 18, 2021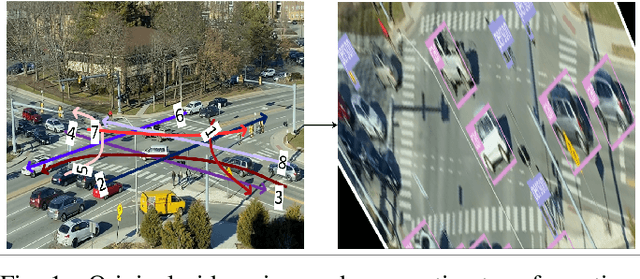


In a previous study, we presented VT-Lane, a three-step framework for real-time vehicle detection, tracking, and turn movement classification at urban intersections. In this study, we present a case study incorporating the highly accurate trajectories and movement classification obtained via VT-Lane for the purpose of speed estimation and driver behavior calibration for traffic at urban intersections. First, we use a highly instrumented vehicle to verify the estimated speeds obtained from video inference. The results of the speed validation show that our method can estimate the average travel speed of detected vehicles in real-time with an error of 0.19 m/sec, which is equivalent to 2% of the average observed travel speeds in the intersection of the study. Instantaneous speeds (at the resolution of 30 Hz) were found to be estimated with an average error of 0.21 m/sec and 0.86 m/sec respectively for free-flowing and congested traffic conditions. We then use the estimated speeds to calibrate the parameters of a driver behavior model for the vehicles in the area of study. The results show that the calibrated model replicates the driving behavior with an average error of 0.45 m/sec, indicating the high potential for using this framework for automated, large-scale calibration of car-following models from roadside traffic video data, which can lead to substantial improvements in traffic modeling via microscopic simulation.
StyleGAN-V: A Continuous Video Generator with the Price, Image Quality and Perks of StyleGAN2
Dec 29, 2021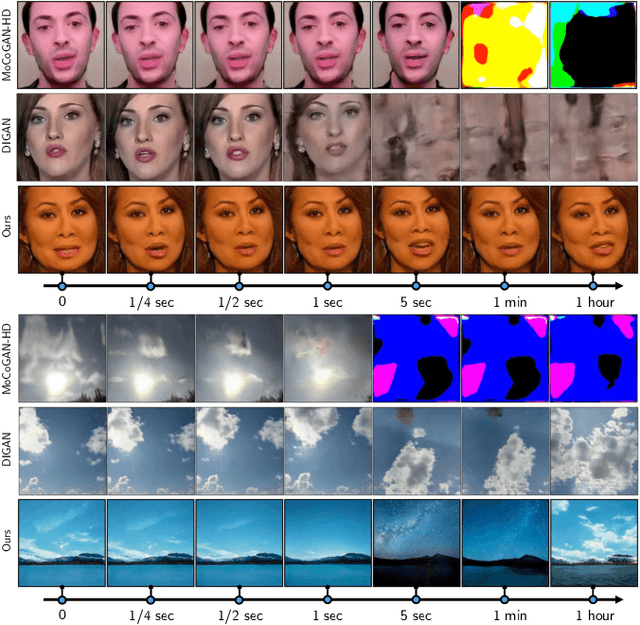
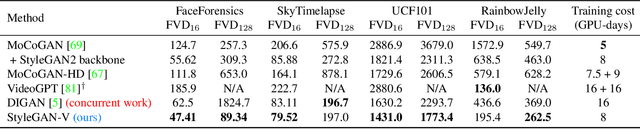

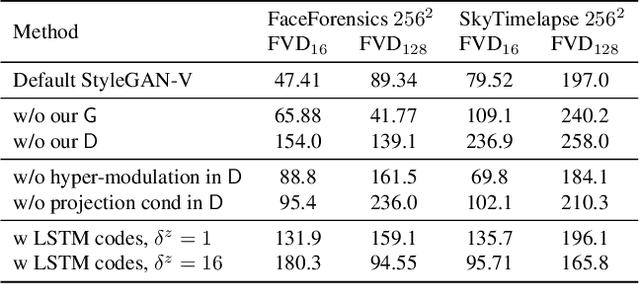
Videos show continuous events, yet most - if not all - video synthesis frameworks treat them discretely in time. In this work, we think of videos of what they should be - time-continuous signals, and extend the paradigm of neural representations to build a continuous-time video generator. For this, we first design continuous motion representations through the lens of positional embeddings. Then, we explore the question of training on very sparse videos and demonstrate that a good generator can be learned by using as few as 2 frames per clip. After that, we rethink the traditional image and video discriminators pair and propose to use a single hypernetwork-based one. This decreases the training cost and provides richer learning signal to the generator, making it possible to train directly on 1024$^2$ videos for the first time. We build our model on top of StyleGAN2 and it is just 5% more expensive to train at the same resolution while achieving almost the same image quality. Moreover, our latent space features similar properties, enabling spatial manipulations that our method can propagate in time. We can generate arbitrarily long videos at arbitrary high frame rate, while prior work struggles to generate even 64 frames at a fixed rate. Our model achieves state-of-the-art results on four modern 256$^2$ video synthesis benchmarks and one 1024$^2$ resolution one. Videos and the source code are available at the project website: https://universome.github.io/stylegan-v.
Performance Analysis of Intelligent Reflecting Surface Assisted Opportunistic Communications
Apr 06, 2022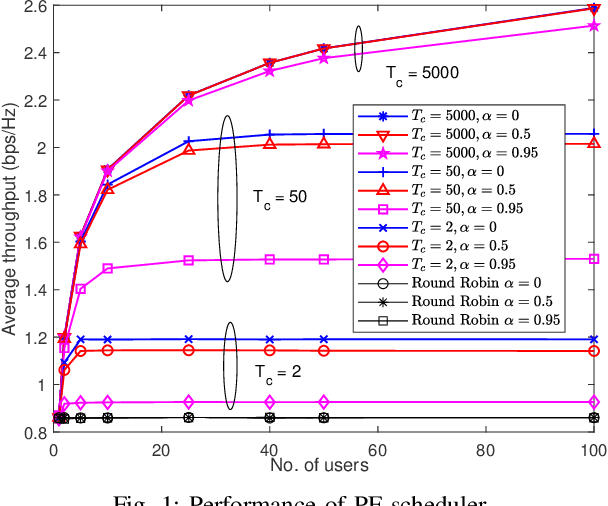
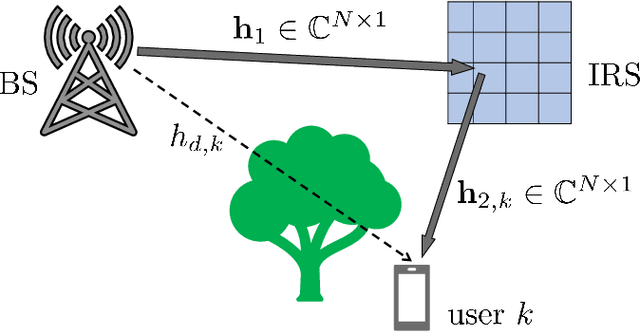
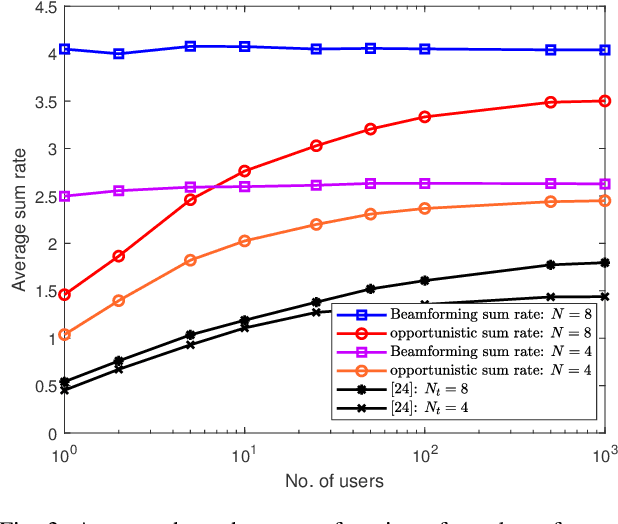
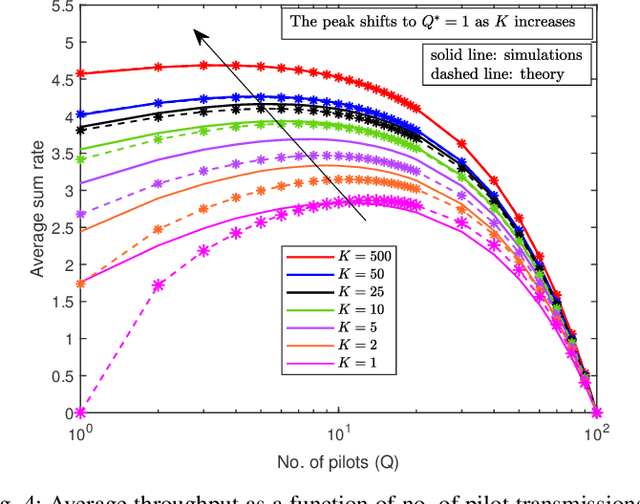
Intelligent reflecting surfaces (IRSs) are a promising technology for enhancing coverage and spectral efficiency, especially in the millimeter wave (mmWave) bands. Existing approaches to leverage the benefits of IRS involve the use of a resource-intensive channel estimation step followed by a computationally expensive algorithm to optimize the reflection coefficients at the IRS. In this work, we present and analyze several alternative schemes, where the phase configuration of the IRS is randomized and multi-user diversity is exploited to opportunistically select the best user at each point in time for data transmission. We show that the throughput of an IRS assisted opportunistic communication (OC) system asymptotically converges to the optimal beamforming-based throughput under fair allocation of resources, as the number of users gets large. We also introduce schemes that enhance the rate of convergence of the OC rate to the beamforming rate with the number of users. For all the proposed schemes, we derive the scaling law of the throughput in terms of the system parameters, as the number of users gets large. Following this, we extend the setup to wideband channels via an orthogonal frequency division multiplexing (OFDM) system and discuss two OC schemes in an IRS assisted setting that clearly elucidate the superior performance that IRS aided OC systems can offer over conventional systems, at very low implementation cost and complexity.
Fast and Data Efficient Reinforcement Learning from Pixels via Non-Parametric Value Approximation
Mar 07, 2022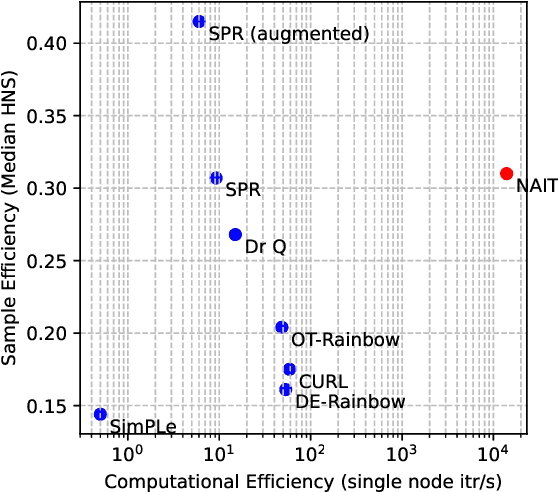
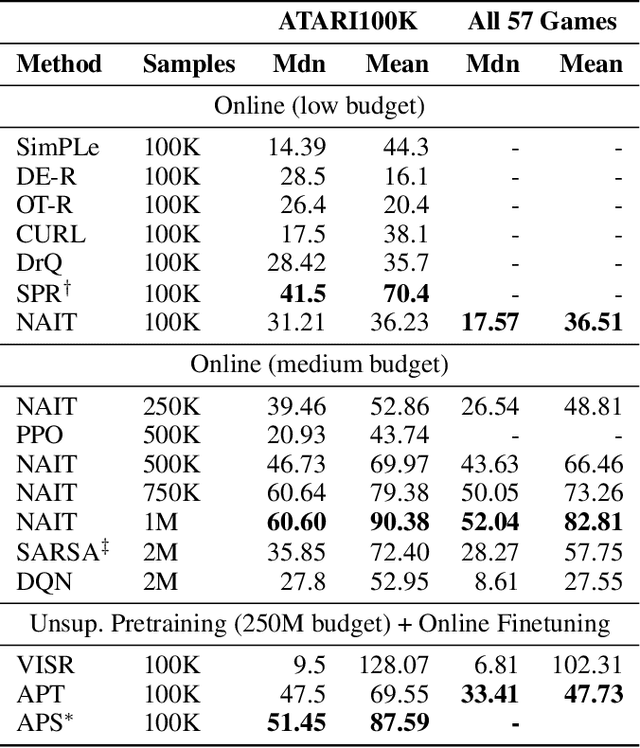
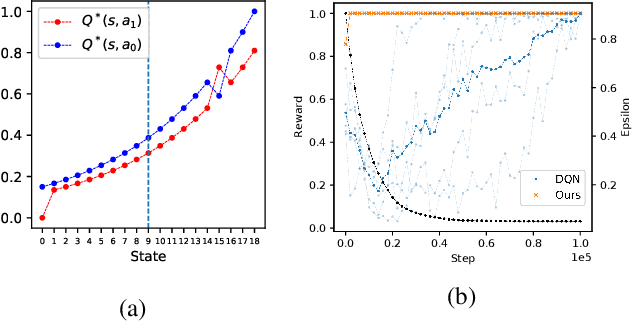
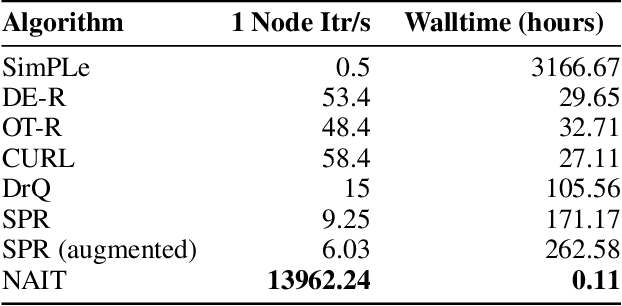
We present Nonparametric Approximation of Inter-Trace returns (NAIT), a Reinforcement Learning algorithm for discrete action, pixel-based environments that is both highly sample and computation efficient. NAIT is a lazy-learning approach with an update that is equivalent to episodic Monte-Carlo on episode completion, but that allows the stable incorporation of rewards while an episode is ongoing. We make use of a fixed domain-agnostic representation, simple distance based exploration and a proximity graph-based lookup to facilitate extremely fast execution. We empirically evaluate NAIT on both the 26 and 57 game variants of ATARI100k where, despite its simplicity, it achieves competitive performance in the online setting with greater than 100x speedup in wall-time.
Self-Supervised Monte Carlo Tree Search Learning for Object Retrieval in Clutter
Feb 03, 2022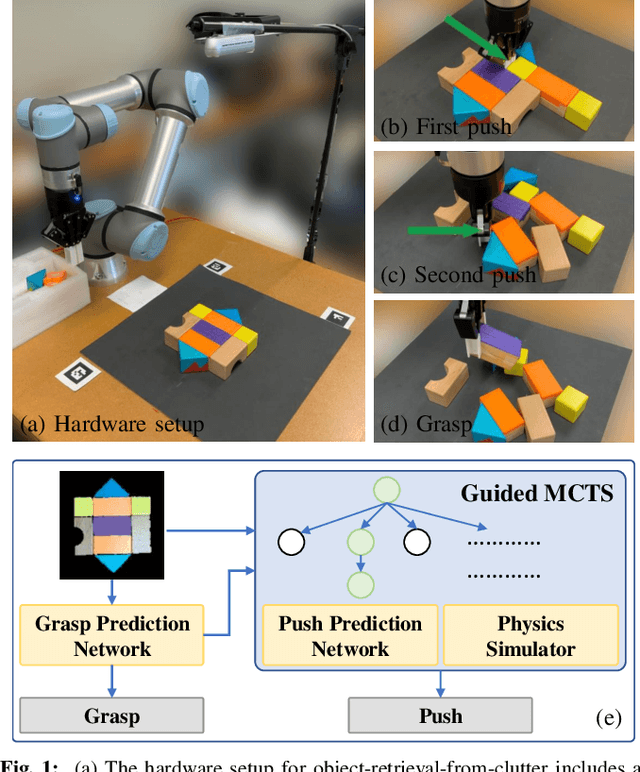
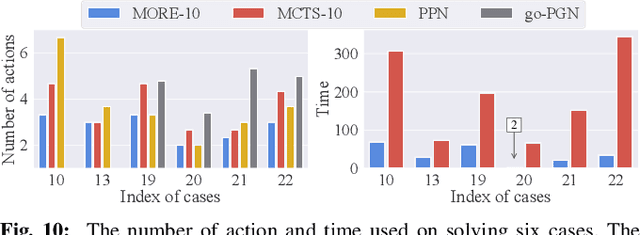
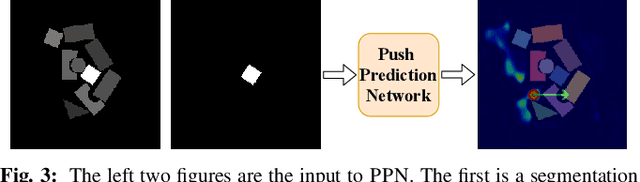
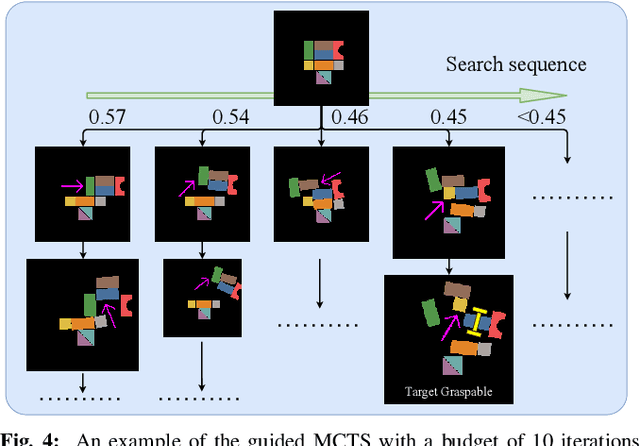
In this study, working with the task of object retrieval in clutter, we have developed a robot learning framework in which Monte Carlo Tree Search (MCTS) is first applied to enable a Deep Neural Network (DNN) to learn the intricate interactions between a robot arm and a complex scene containing many objects, allowing the DNN to partially clone the behavior of MCTS. In turn, the trained DNN is integrated into MCTS to help guide its search effort. We call this approach Monte Carlo tree search and learning for Object REtrieval (MORE), which delivers significant computational efficiency gains and added solution optimality. MORE is a self-supervised robotics framework/pipeline capable of working in the real world that successfully embodies the System 2 $\to$ System 1 learning philosophy proposed by Kahneman, where learned knowledge, used properly, can help greatly speed up a time-consuming decision process over time. Videos and supplementary material can be found at https://github.com/arc-l/more
Estimation of Looming from LiDAR
Mar 15, 2022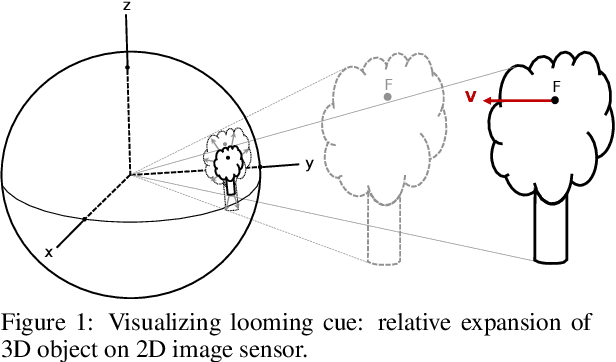
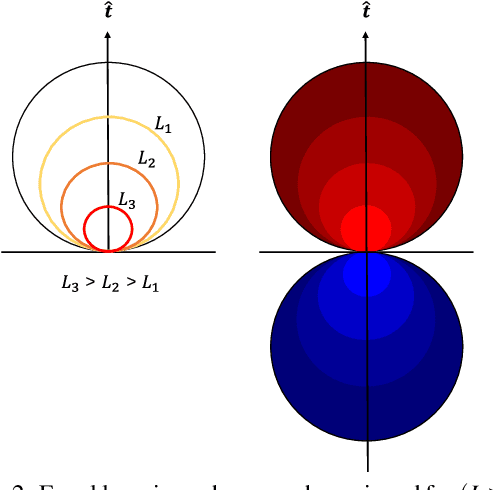
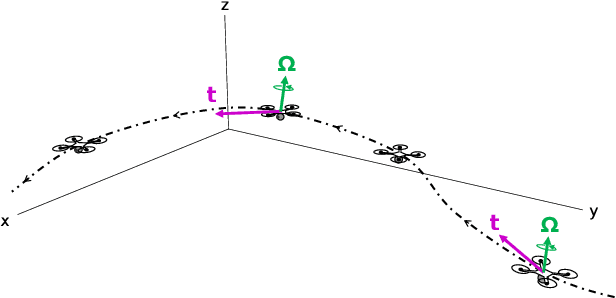
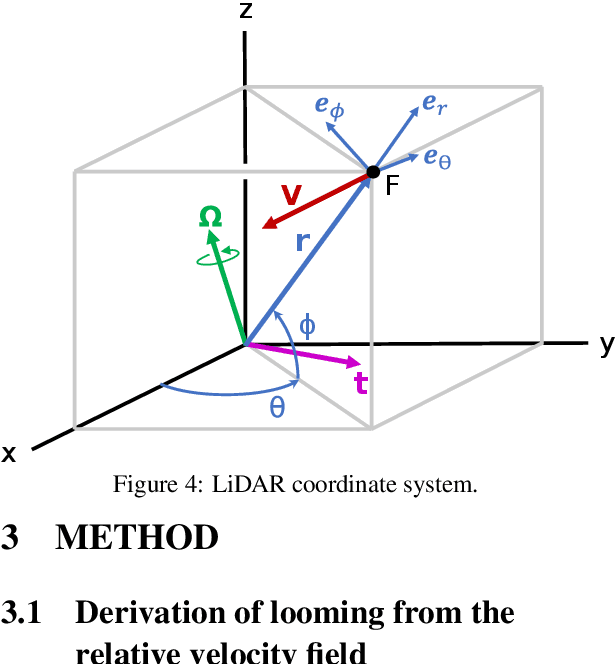
Looming, traditionally defined as the relative expansion of objects in the observer's retina, is a fundamental visual cue for perception of threat and can be used to accomplish collision free navigation. The measurement of the looming cue is not only limited to vision, and can also be obtained from range sensors like LiDAR (Light Detection and Ranging). In this article we present two methods that process raw LiDAR data to estimate the looming cue. Using looming values we show how to obtain threat zones for collision avoidance tasks. The methods are general enough to be suitable for any six-degree-of-freedom motion and can be implemented in real-time without the need for fine matching, point-cloud registration, object classification or object segmentation. Quantitative results using the KITTI dataset shows advantages and limitations of the methods.
Streaming parallel transducer beam search with fast-slow cascaded encoders
Mar 29, 2022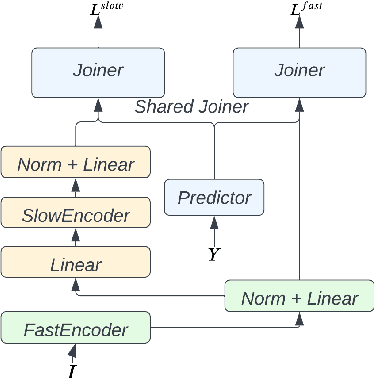
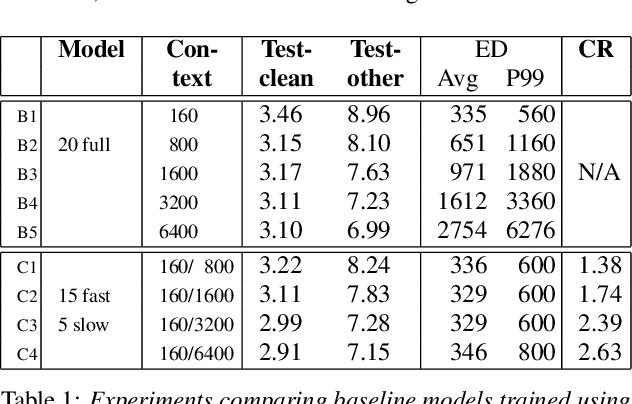
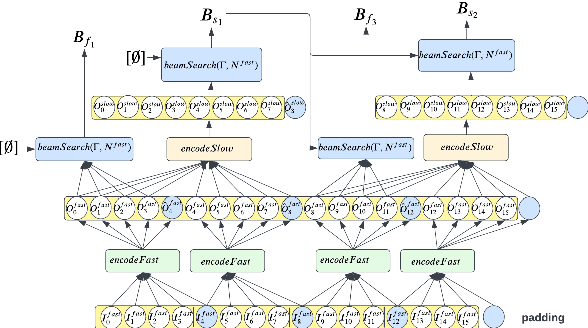
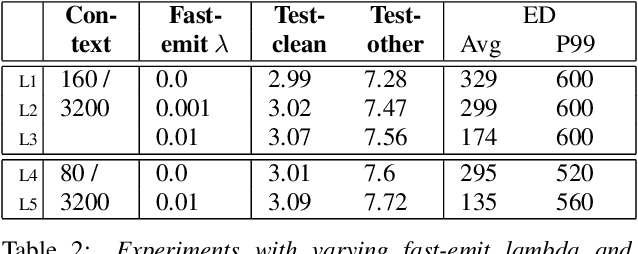
Streaming ASR with strict latency constraints is required in many speech recognition applications. In order to achieve the required latency, streaming ASR models sacrifice accuracy compared to non-streaming ASR models due to lack of future input context. Previous research has shown that streaming and non-streaming ASR for RNN Transducers can be unified by cascading causal and non-causal encoders. This work improves upon this cascaded encoders framework by leveraging two streaming non-causal encoders with variable input context sizes that can produce outputs at different audio intervals (e.g. fast and slow). We propose a novel parallel time-synchronous beam search algorithm for transducers that decodes from fast-slow encoders, where the slow encoder corrects the mistakes generated from the fast encoder. The proposed algorithm, achieves up to 20% WER reduction with a slight increase in token emission delays on the public Librispeech dataset and in-house datasets. We also explore techniques to reduce the computation by distributing processing between the fast and slow encoders. Lastly, we explore sharing the parameters in the fast encoder to reduce the memory footprint. This enables low latency processing on edge devices with low computation cost and a low memory footprint.
Thermodynamics-informed graph neural networks
Mar 03, 2022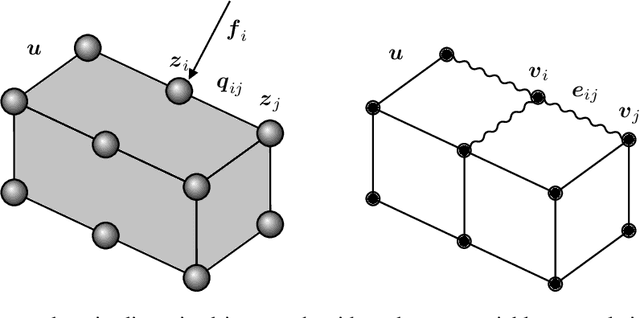
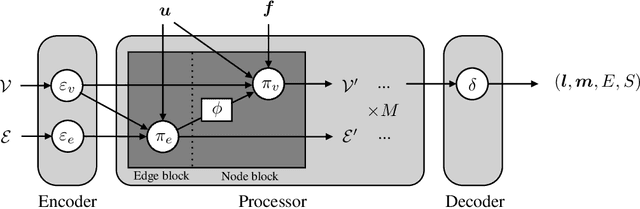
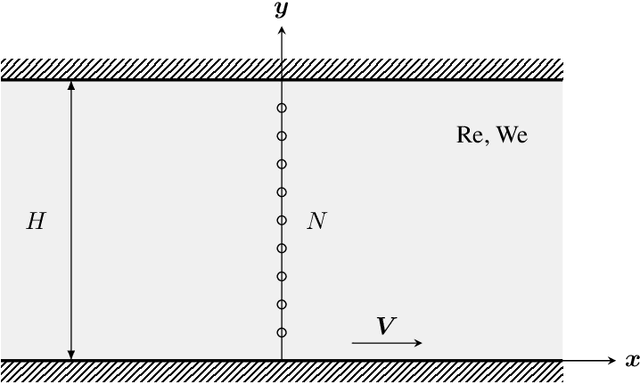
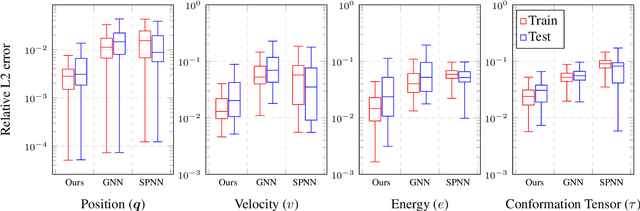
In this paper we present a deep learning method to predict the time evolution of dissipative dynamical systems. We propose using both geometric and thermodynamic inductive biases to improve accuracy and generalization of the resulting integration scheme. The first is achieved with Graph Neural Networks, which induces a non-Euclidean geometrical prior and permutation invariant node and edge update functions. The second bias is forced by learning the GENERIC structure of the problem, an extension of the Hamiltonian formalism, to model more general non-conservative dynamics. Several examples are provided in both Eulerian and Lagrangian description in the context of fluid and solid mechanics respectively.