 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Matching Writers to Content Writing Tasks
Apr 07, 2022
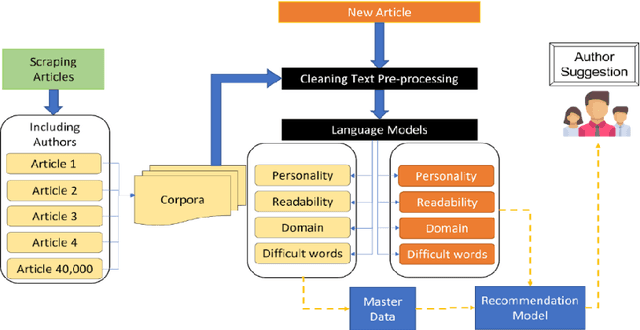
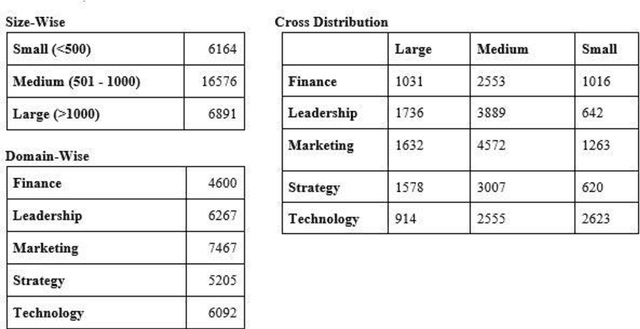
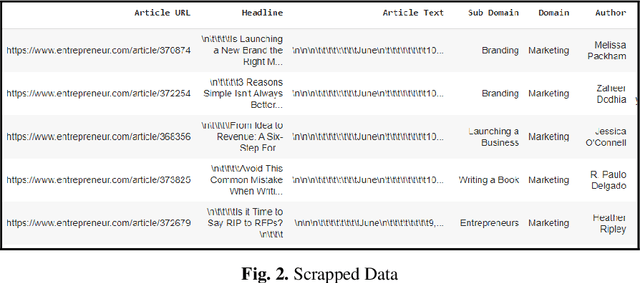
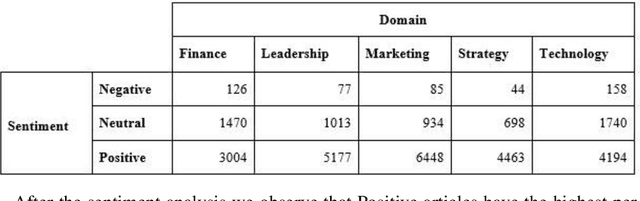
Businesses need content. In various forms and formats and for varied purposes. In fact, the content marketing industry is set to be worth $412.88 billion by the end of 2021. However, according to the Content Marketing Institute, creating engaging content is the #1 challenge that marketers face today. We under-stand that producing great content requires great writers who understand the business and can weave their message into reader (and search engine) friendly content. In this project, the team has attempted to bridge the gap between writers and projects by using AI and ML tools. We used NLP techniques to analyze thou-sands of publicly available business articles (corpora) to extract various defining factors for each writing sample. Through this project we aim to automate the highly time-consuming, and often biased task of manually shortlisting the most suitable writer for a given content writing requirement. We believe that a tool like this will have far reaching positive implications for both parties - businesses looking for suitable talent for niche writing jobs as well as experienced writers and Subject Matter Experts (SMEs) wanting to lend their services to content marketing projects. The business gets the content they need, the content writer/ SME gets a chance to leverage his or her talent, while the reader gets authentic content that adds real value.
Learning Robust Convolutional Neural Networks with Relevant Feature Focusing via Explanations
Feb 09, 2022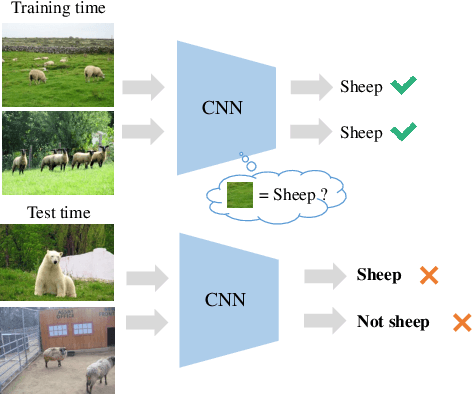
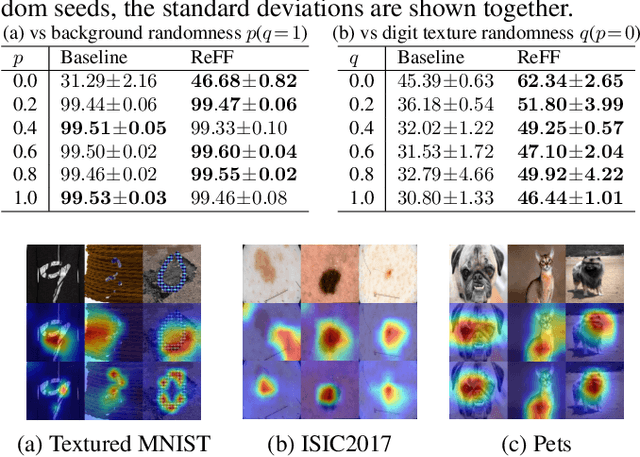
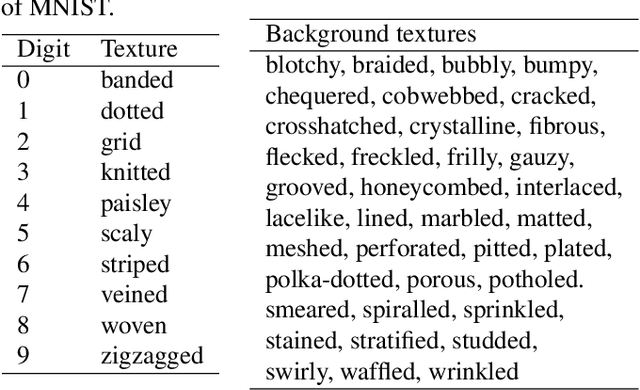
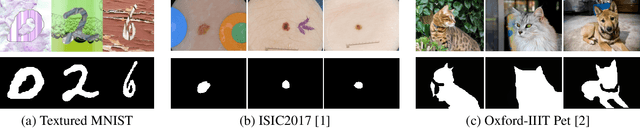
Existing image recognition techniques based on convolutional neural networks (CNNs) basically assume that the training and test datasets are sampled from i.i.d distributions. However, this assumption is easily broken in the real world because of the distribution shift that occurs when the co-occurrence relations between objects and backgrounds in input images change. Under this type of distribution shift, CNNs learn to focus on features that are not task-relevant, such as backgrounds from the training data, and degrade their accuracy on the test data. To tackle this problem, we propose relevant feature focusing (ReFF). ReFF detects task-relevant features and regularizes CNNs via explanation outputs (e.g., Grad-CAM). Since ReFF is composed of post-hoc explanation modules, it can be easily applied to off-the-shelf CNNs. Furthermore, ReFF requires no additional inference cost at test time because it is only used for regularization while training. We demonstrate that CNNs trained with ReFF focus on features relevant to the target task and that ReFF improves the test-time accuracy.
HASA: Hybrid Architecture Search with Aggregation Strategy for Echinococcosis Classification and Ovary Segmentation in Ultrasound Images
Apr 14, 2022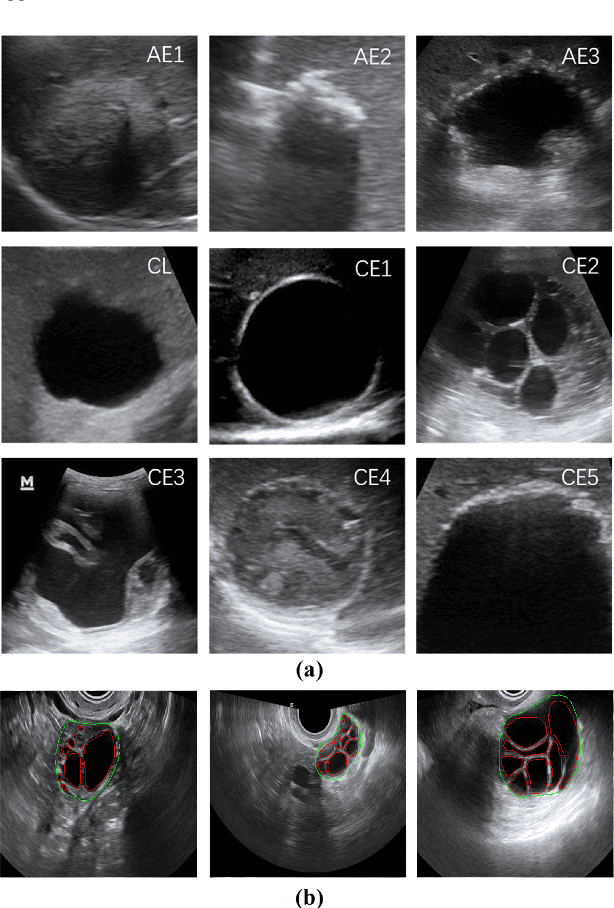
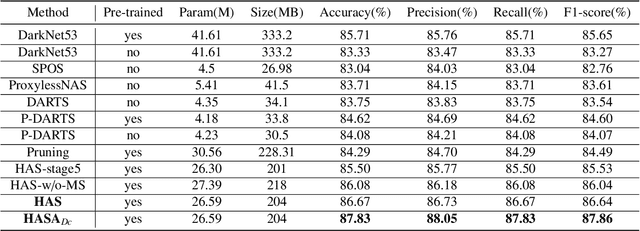
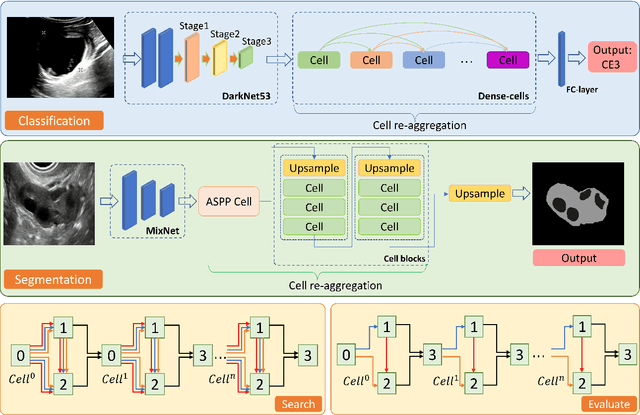
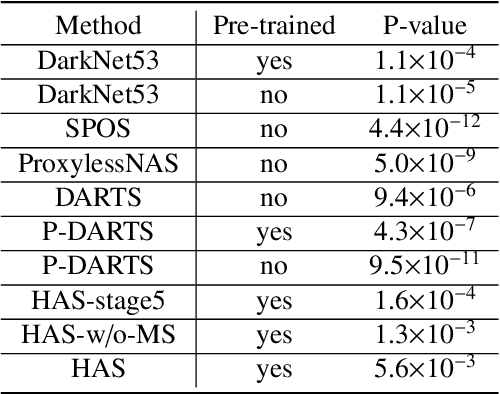
Different from handcrafted features, deep neural networks can automatically learn task-specific features from data. Due to this data-driven nature, they have achieved remarkable success in various areas. However, manual design and selection of suitable network architectures are time-consuming and require substantial effort of human experts. To address this problem, researchers have proposed neural architecture search (NAS) algorithms which can automatically generate network architectures but suffer from heavy computational cost and instability if searching from scratch. In this paper, we propose a hybrid NAS framework for ultrasound (US) image classification and segmentation. The hybrid framework consists of a pre-trained backbone and several searched cells (i.e., network building blocks), which takes advantage of the strengths of both NAS and the expert knowledge from existing convolutional neural networks. Specifically, two effective and lightweight operations, a mixed depth-wise convolution operator and a squeeze-and-excitation block, are introduced into the candidate operations to enhance the variety and capacity of the searched cells. These two operations not only decrease model parameters but also boost network performance. Moreover, we propose a re-aggregation strategy for the searched cells, aiming to further improve the performance for different vision tasks. We tested our method on two large US image datasets, including a 9-class echinococcosis dataset containing 9566 images for classification and an ovary dataset containing 3204 images for segmentation. Ablation experiments and comparison with other handcrafted or automatically searched architectures demonstrate that our method can generate more powerful and lightweight models for the above US image classification and segmentation tasks.
Hybrid Transformer Network for Different Horizons-based Enriched Wind Speed Forecasting
Apr 07, 2022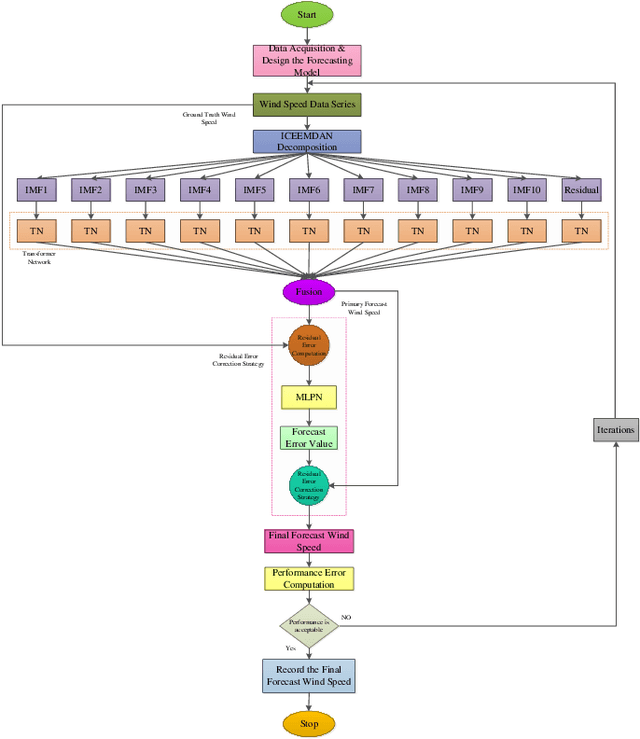
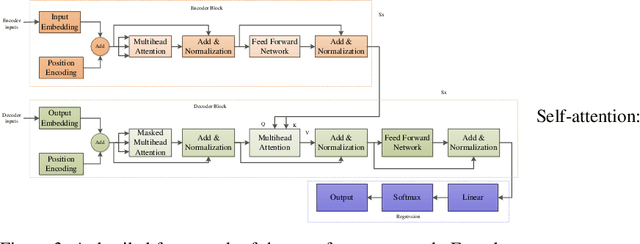
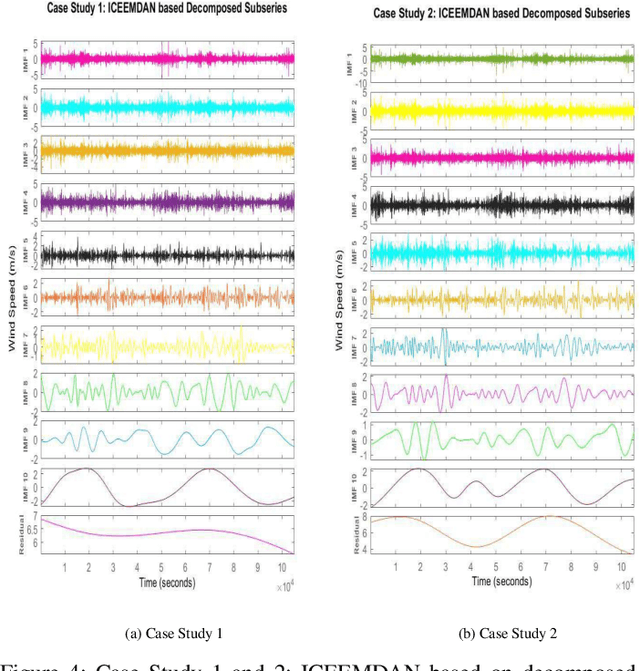
Highly accurate different horizon-based wind speed forecasting facilitates a better modern power system. This paper proposed a novel astute hybrid wind speed forecasting model and applied it to different horizons. The proposed hybrid forecasting model decomposes the original wind speed data into IMFs (Intrinsic Mode Function) using Improved Complete Ensemble Empirical Mode Decomposition with Adaptive Noise (ICEEMDAN). We fed the obtained subseries from ICEEMDAN to the transformer network. Each transformer network computes the forecast subseries and then passes to the fusion phase. Get the primary wind speed forecasting from the fusion of individual transformer network forecast subseries. Estimate the residual error values and predict errors using a multilayer perceptron neural network. The forecast error is added to the primary forecast wind speed to leverage the high accuracy of wind speed forecasting. Comparative analysis with real-time Kethanur, India wind farm dataset results reveals the proposed ICEEMDAN-TNF-MLPN-RECS hybrid model's superior performance with MAE=1.7096*10^-07, MAPE=2.8416*10^-06, MRE=2.8416*10^-08, MSE=5.0206*10^-14, and RMSE=2.2407*10^-07 for case study 1 and MAE=6.1565*10^-07, MAPE=9.5005*10^-06, MRE=9.5005*10^-08, MSE=8.9289*10^-13, and RMSE=9.4493*10^-07 for case study 2 enriched wind speed forecasting than state-of-the-art methods and reduces the burden on the power system engineer.
Backward Reachability Analysis for Neural Feedback Loops
Apr 14, 2022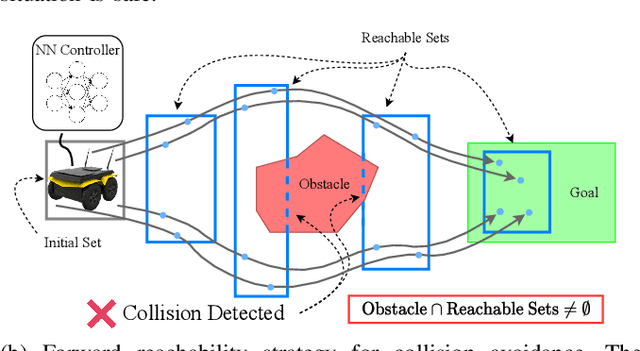
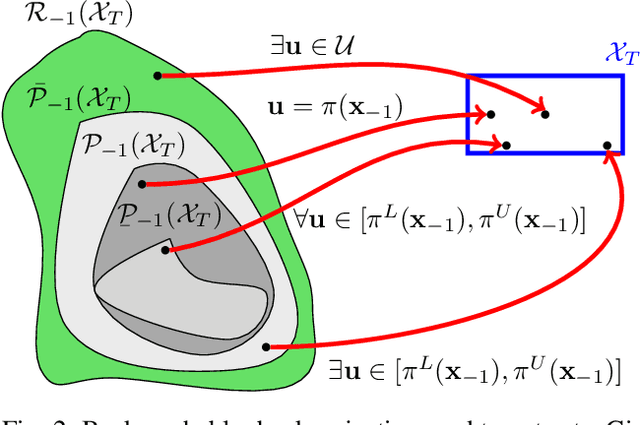
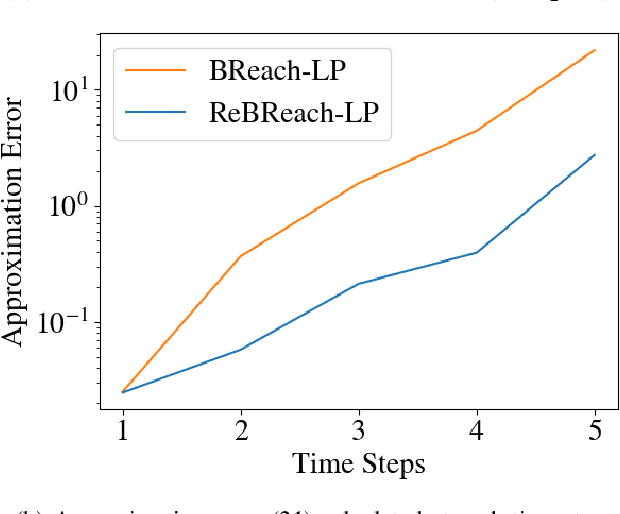
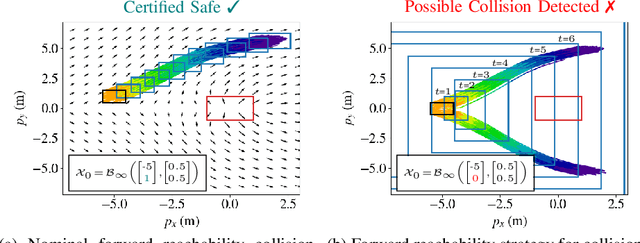
The increasing prevalence of neural networks (NNs) in safety-critical applications calls for methods to certify their behavior and guarantee safety. This paper presents a backward reachability approach for safety verification of neural feedback loops (NFLs), i.e., closed-loop systems with NN control policies. While recent works have focused on forward reachability as a strategy for safety certification of NFLs, backward reachability offers advantages over the forward strategy, particularly in obstacle avoidance scenarios. Prior works have developed techniques for backward reachability analysis for systems without NNs, but the presence of NNs in the feedback loop presents a unique set of problems due to the nonlinearities in their activation functions and because NN models are generally not invertible. To overcome these challenges, we use existing forward NN analysis tools to find affine bounds on the control inputs and solve a series of linear programs (LPs) to efficiently find an approximation of the backprojection (BP) set, i.e., the set of states for which the NN control policy will drive the system to a given target set. We present an algorithm to iteratively find BP set estimates over a given time horizon and demonstrate the ability to reduce conservativeness in the BP set estimates by up to 88% with low additional computational cost. We use numerical results from a double integrator model to verify the efficacy of these algorithms and demonstrate the ability to certify safety for a linearized ground robot model in a collision avoidance scenario where forward reachability fails.
Reproducibility Issues for BERT-based Evaluation Metrics
Mar 30, 2022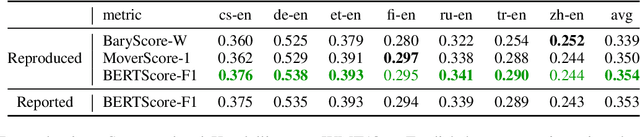
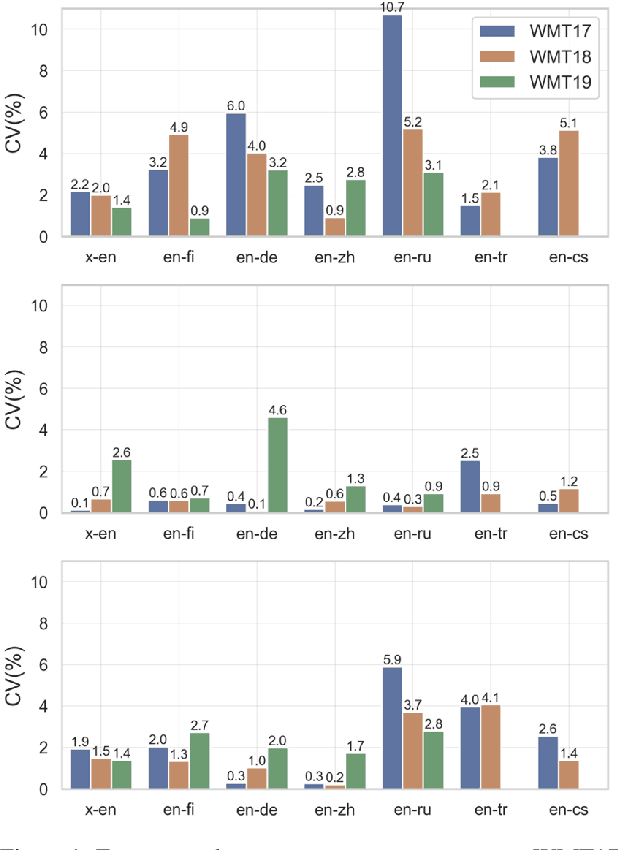
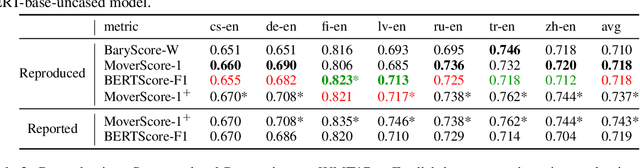
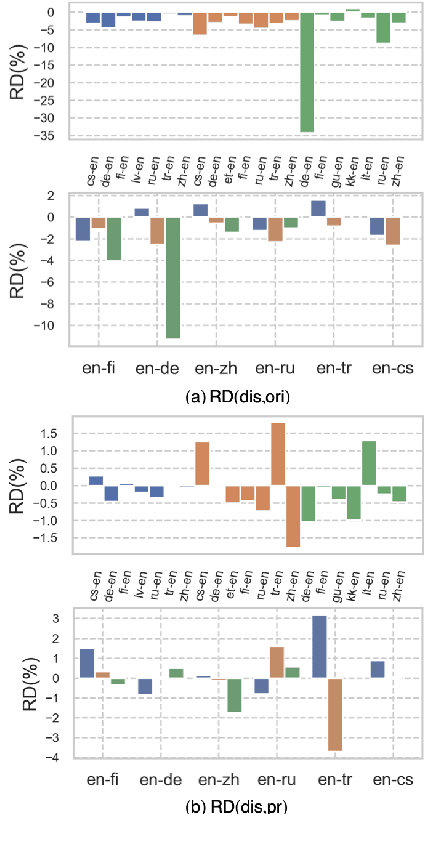
Reproducibility is of utmost concern in machine learning and natural language processing (NLP). In the field of natural language generation (especially machine translation), the seminal paper of Post (2018) has pointed out problems of reproducibility of the dominant metric, BLEU, at the time of publication. Nowadays, BERT-based evaluation metrics considerably outperform BLEU. In this paper, we ask whether results and claims from four recent BERT-based metrics can be reproduced. We find that reproduction of claims and results often fails because of (i) heavy undocumented preprocessing involved in the metrics, (ii) missing code and (iii) reporting weaker results for the baseline metrics. (iv) In one case, the problem stems from correlating not to human scores but to a wrong column in the csv file, inflating scores by 5 points. Motivated by the impact of preprocessing, we then conduct a second study where we examine its effects more closely (for one of the metrics). We find that preprocessing can have large effects, especially for highly inflectional languages. In this case, the effect of preprocessing may be larger than the effect of the aggregation mechanism (e.g., greedy alignment vs. Word Mover Distance).
Embarrassingly Simple Performance Prediction for Abductive Natural Language Inference
Feb 21, 2022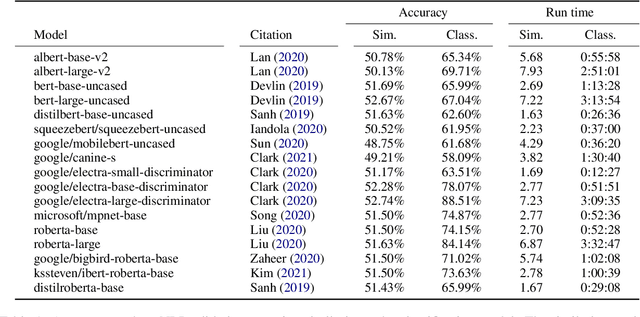
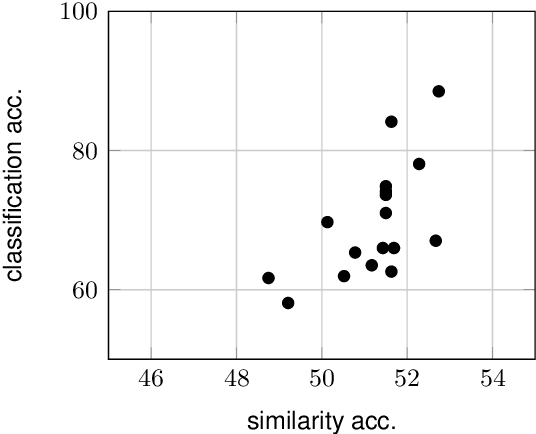
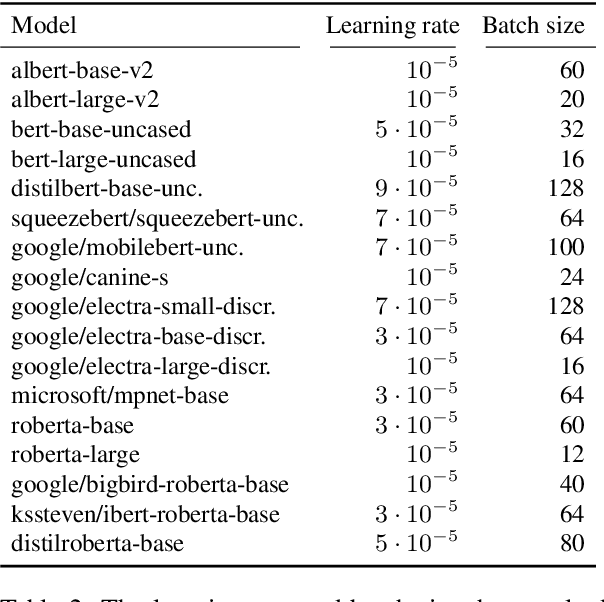
The task of abductive natural language inference (\alpha{}nli), to decide which hypothesis is the more likely explanation for a set of observations, is a particularly difficult type of NLI. Instead of just determining a causal relationship, it requires common sense to also evaluate how reasonable an explanation is. All recent competitive systems build on top of contextualized representations and make use of transformer architectures for learning an NLI model. When somebody is faced with a particular NLI task, they need to select the best model that is available. This is a time-consuming and resource-intense endeavour. To solve this practical problem, we propose a simple method for predicting the performance without actually fine-tuning the model. We do this by testing how well the pre-trained models perform on the \alpha{}nli task when just comparing sentence embeddings with cosine similarity to what the performance that is achieved when training a classifier on top of these embeddings. We show that the accuracy of the cosine similarity approach correlates strongly with the accuracy of the classification approach with a Pearson correlation coefficient of 0.65. Since the similarity computation is orders of magnitude faster to compute on a given dataset (less than a minute vs. hours), our method can lead to significant time savings in the process of model selection.
Joint Sensing, Communication and Localization of a Silent Abnormality Using Molecular Diffusion
Mar 30, 2022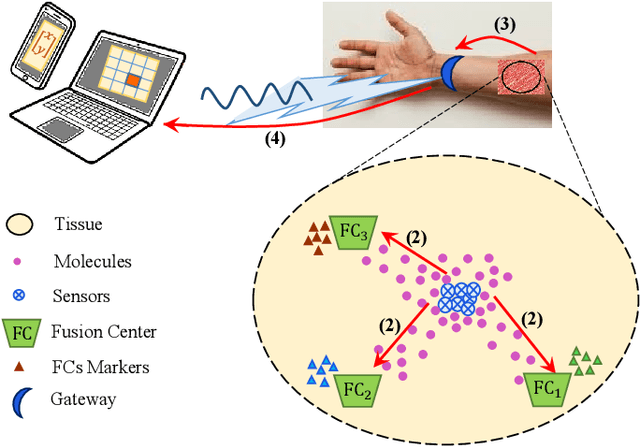
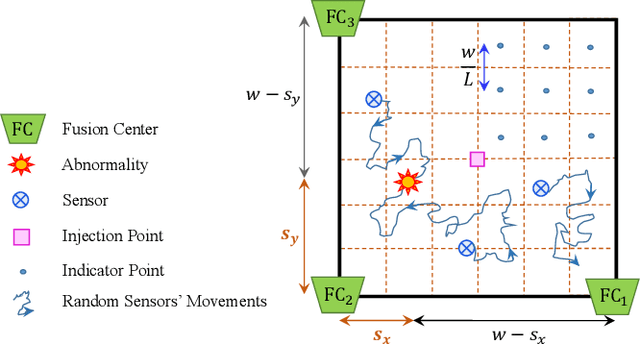
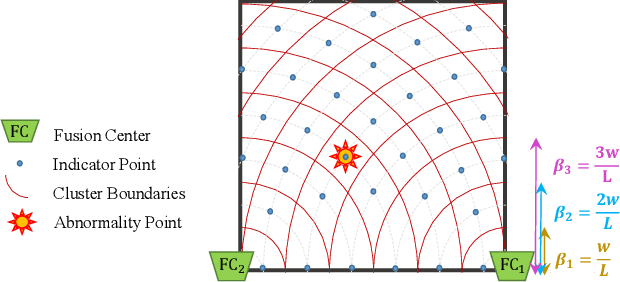
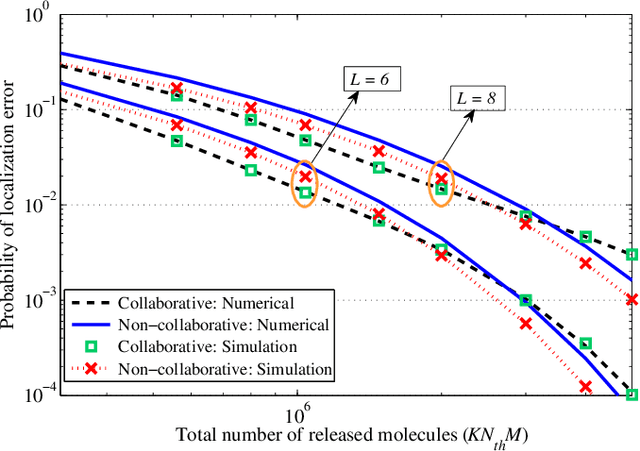
In this paper, we propose a molecular communication system to localize an abnormality in a diffusion based medium. We consider a general setup to perform joint sensing, communication and localization. This setup consists of three types of devices, each for a different task: mobile sensors for navigation and molecule releasing (for communication), fusion centers (FC)s for sampling, amplifying and forwarding the signal, and a gateway for making decision or exchanging the information with an external device. The sensors move randomly in the environment to reach the abnormality. We consider both collaborative and non-collaborative sensors that simultaneously release their molecules to the FCs when the number of activated sensors or the moving time reach a certain threshold, respectively. The FCs amplify the received signal and forward it to the gateway for decision making using either an ideal or a noisy communication channel. A practical application of the proposed model is drug delivery in a tissue of human body, in order to guide the nanomachine bound drug to the exact location. The decision rules and probabilities of error are obtained for two considered sensors types in both ideal and noisy communication channels.
NeRFusion: Fusing Radiance Fields for Large-Scale Scene Reconstruction
Mar 21, 2022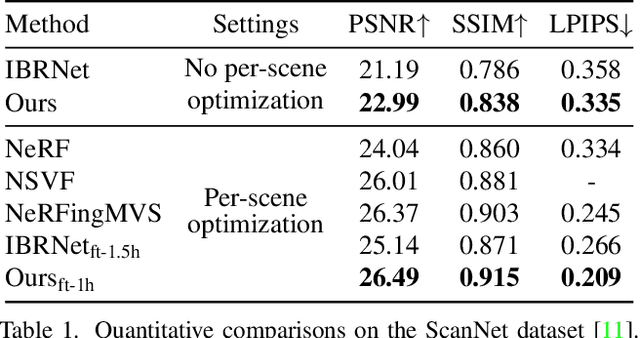
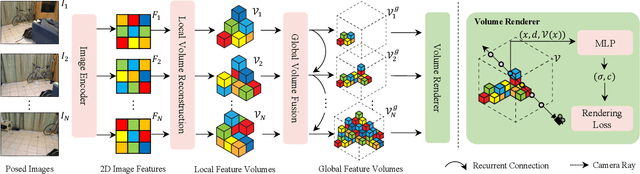
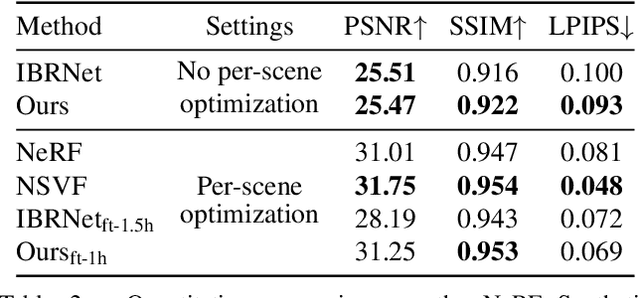
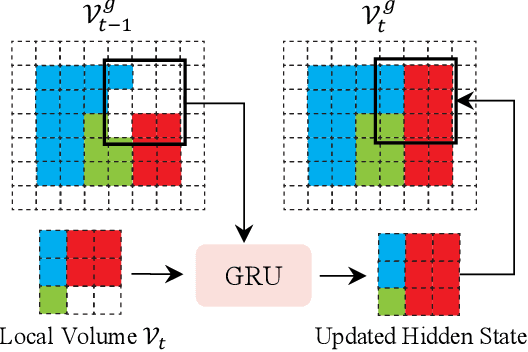
While NeRF has shown great success for neural reconstruction and rendering, its limited MLP capacity and long per-scene optimization times make it challenging to model large-scale indoor scenes. In contrast, classical 3D reconstruction methods can handle large-scale scenes but do not produce realistic renderings. We propose NeRFusion, a method that combines the advantages of NeRF and TSDF-based fusion techniques to achieve efficient large-scale reconstruction and photo-realistic rendering. We process the input image sequence to predict per-frame local radiance fields via direct network inference. These are then fused using a novel recurrent neural network that incrementally reconstructs a global, sparse scene representation in real-time at 22 fps. This global volume can be further fine-tuned to boost rendering quality. We demonstrate that NeRFusion achieves state-of-the-art quality on both large-scale indoor and small-scale object scenes, with substantially faster reconstruction than NeRF and other recent methods.
Is a Green Screen Really Necessary for Real-Time Portrait Matting?
Nov 29, 2020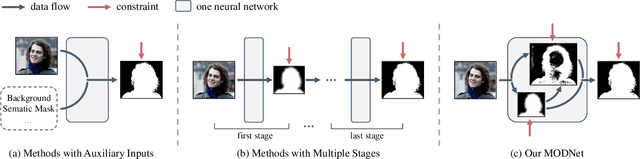
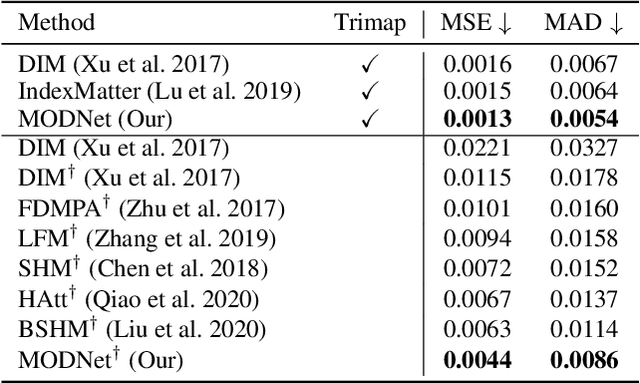
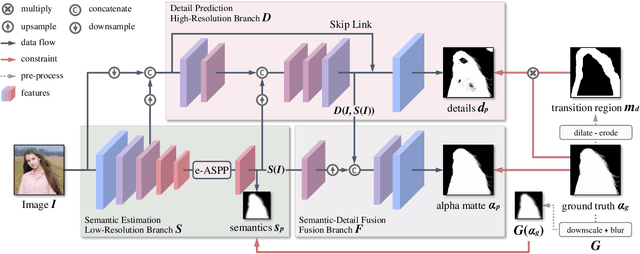
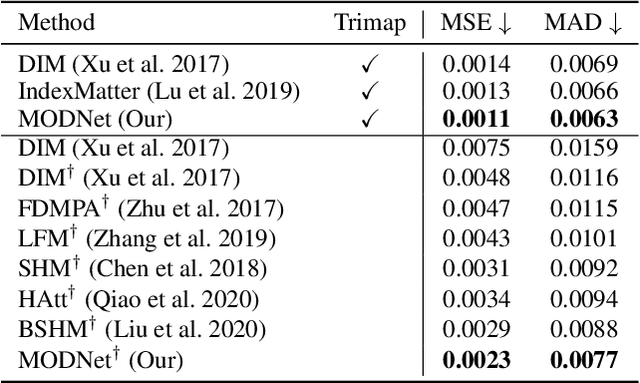
For portrait matting without the green screen, existing works either require auxiliary inputs that are costly to obtain or use multiple models that are computationally expensive. Consequently, they are unavailable in real-time applications. In contrast, we present a light-weight matting objective decomposition network (MODNet), which can process portrait matting from a single input image in real time. The design of MODNet benefits from optimizing a series of correlated sub-objectives simultaneously via explicit constraints. Moreover, since trimap-free methods usually suffer from the domain shift problem in practice, we introduce (1) a self-supervised strategy based on sub-objectives consistency to adapt MODNet to real-world data and (2) a one-frame delay trick to smooth the results when applying MODNet to portrait video sequence. MODNet is easy to be trained in an end-to-end style. It is much faster than contemporaneous matting methods and runs at 63 frames per second. On a carefully designed portrait matting benchmark newly proposed in this work, MODNet greatly outperforms prior trimap-free methods. More importantly, our method achieves remarkable results in daily photos and videos. Now, do you really need a green screen for real-time portrait matting?