 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Socially Fair Mitigation of Misinformation on Social Networks via Constraint Stochastic Optimization
Mar 23, 2022
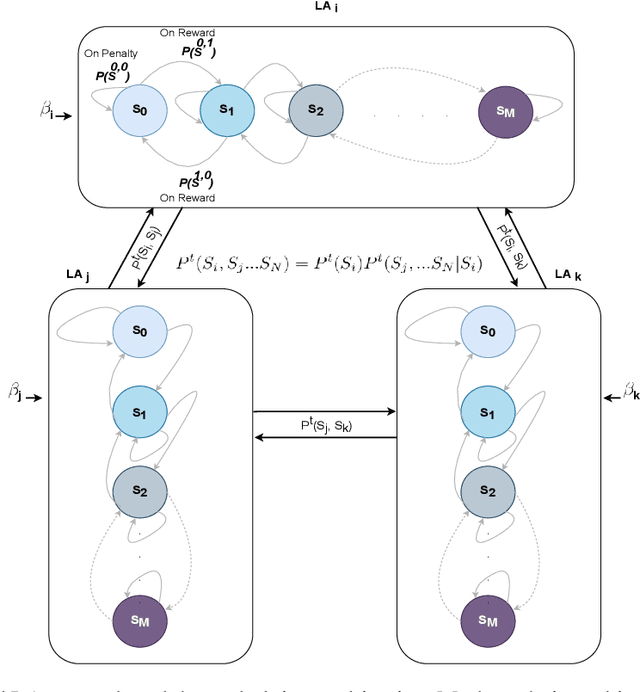
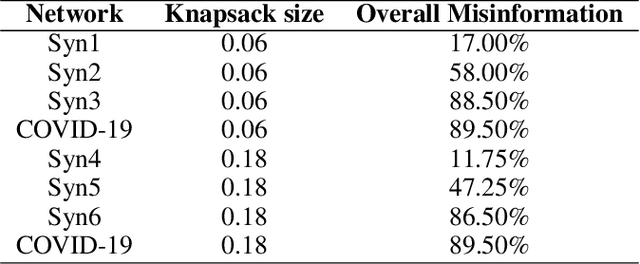
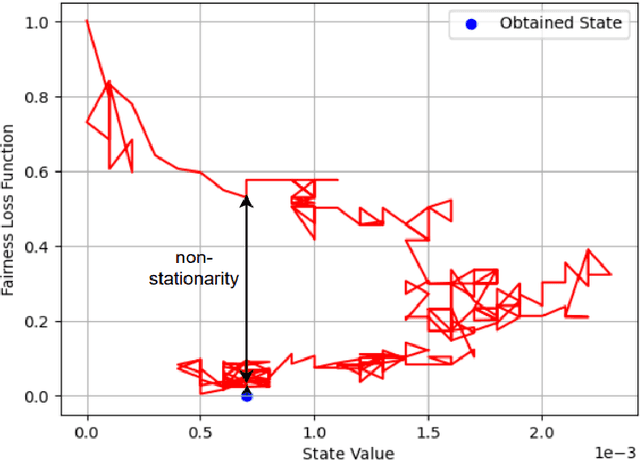
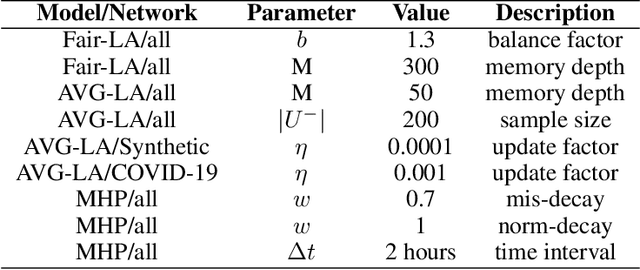
Recent social networks' misinformation mitigation approaches tend to investigate how to reduce misinformation by considering a whole-network statistical scale. However, unbalanced misinformation exposures among individuals urge to study fair allocation of mitigation resources. Moreover, the network has random dynamics which change over time. Therefore, we introduce a stochastic and non-stationary knapsack problem, and we apply its resolution to mitigate misinformation in social network campaigns. We further propose a generic misinformation mitigation algorithm that is robust to different social networks' misinformation statistics, allowing a promising impact in real-world scenarios. A novel loss function ensures fair mitigation among users. We achieve fairness by intelligently allocating a mitigation incentivization budget to the knapsack, and optimizing the loss function. To this end, a team of Learning Automata (LA) drives the budget allocation. Each LA is associated with a user and learns to minimize its exposure to misinformation by performing a non-stationary and stochastic walk over its state space. Our results show how our LA-based method is robust and outperforms similar misinformation mitigation methods in how the mitigation is fairly influencing the network users.
Dynamic Sampling Rate: Harnessing Frame Coherence in Graphics Applications for Energy-Efficient GPUs
Feb 21, 2022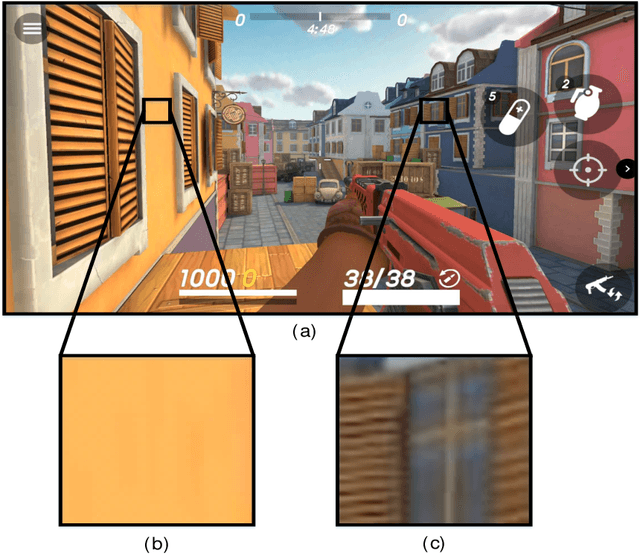
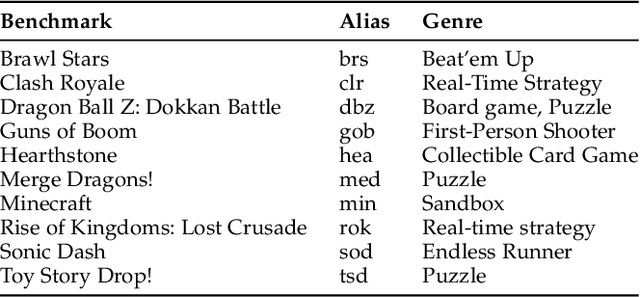
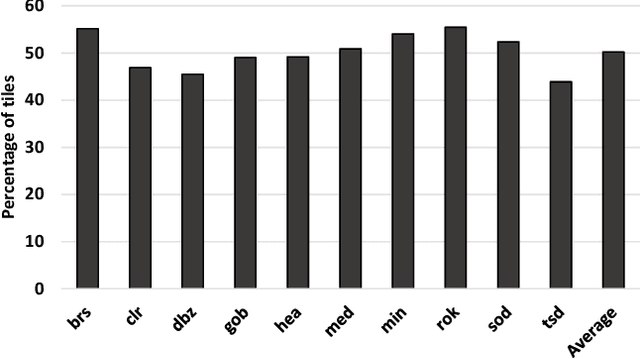
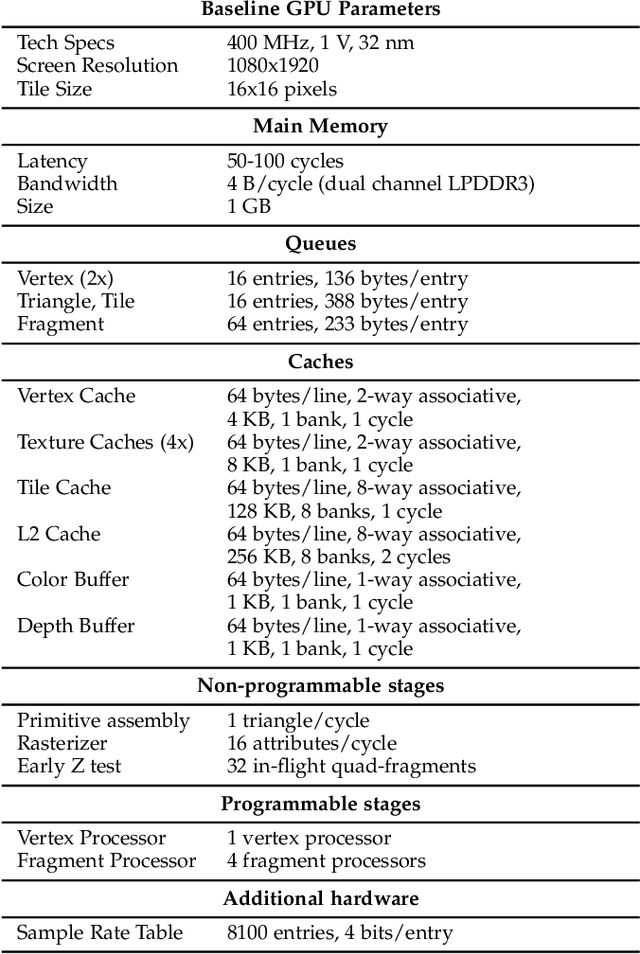
In real-time rendering, a 3D scene is modelled with meshes of triangles that the GPU projects to the screen. They are discretized by sampling each triangle at regular space intervals to generate fragments which are then added texture and lighting effects by a shader program. Realistic scenes require detailed geometric models, complex shaders, high-resolution displays and high screen refreshing rates, which all come at a great compute time and energy cost. This cost is often dominated by the fragment shader, which runs for each sampled fragment. Conventional GPUs sample the triangles once per pixel, however, there are many screen regions containing low variation that produce identical fragments and could be sampled at lower than pixel-rate with no loss in quality. Additionally, as temporal frame coherence makes consecutive frames very similar, such variations are usually maintained from frame to frame. This work proposes Dynamic Sampling Rate (DSR), a novel hardware mechanism to reduce redundancy and improve the energy efficiency in graphics applications. DSR analyzes the spatial frequencies of the scene once it has been rendered. Then, it leverages the temporal coherence in consecutive frames to decide, for each region of the screen, the lowest sampling rate to employ in the next frame that maintains image quality. We evaluate the performance of a state-of-the-art mobile GPU architecture extended with DSR for a wide variety of applications. Experimental results show that DSR is able to remove most of the redundancy inherent in the color computations at fragment granularity, which brings average speedups of 1.68x and energy savings of 40%.
Optical Fiber Fault Detection and Localization in a Noisy OTDR Trace Based on Denoising Convolutional Autoencoder and Bidirectional Long Short-Term Memory
Mar 19, 2022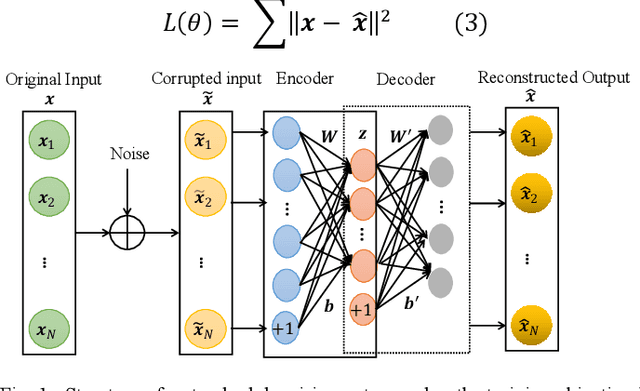
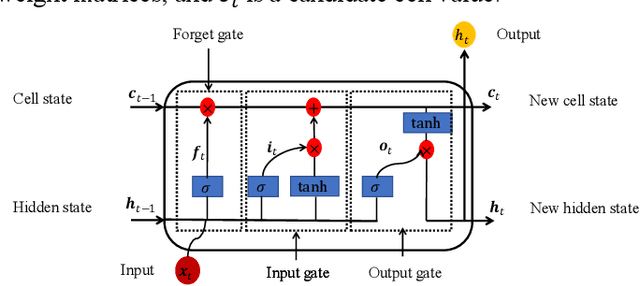
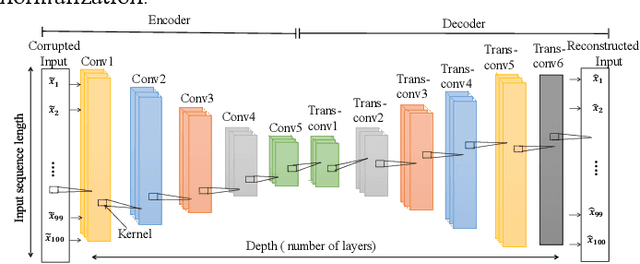
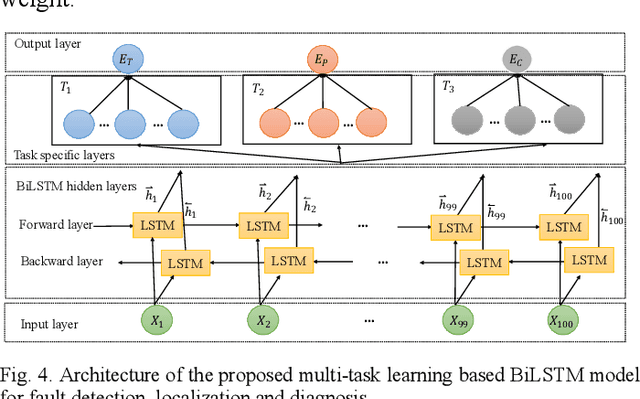
Optical time-domain reflectometry (OTDR) has been widely used for characterizing fiber optical links and for detecting and locating fiber faults. OTDR traces are prone to be distorted by different kinds of noise, causing blurring of the backscattered signals, and thereby leading to a misleading interpretation and a more cumbersome event detection task. To address this problem, a novel method combining a denoising convolutional autoencoder (DCAE) and a bidirectional long short-term memory (BiLSTM) is proposed, whereby the former is used for noise removal of OTDR signals and the latter for fault detection, localization, and diagnosis with the denoised signal as input. The proposed approach is applied to noisy OTDR signals of different levels of input SNR ranging from -5 dB to 15 dB. The experimental results demonstrate that: (i) the DCAE is efficient in denoising the OTDR traces and it outperforms other deep learning techniques and the conventional denoising methods; and (ii) the BiLSTM achieves a high detection and diagnostic accuracy of 96.7% with an improvement of 13.74% compared to the performance of the same model trained with noisy OTDR signals.
Point Scene Understanding via Disentangled Instance Mesh Reconstruction
Mar 31, 2022

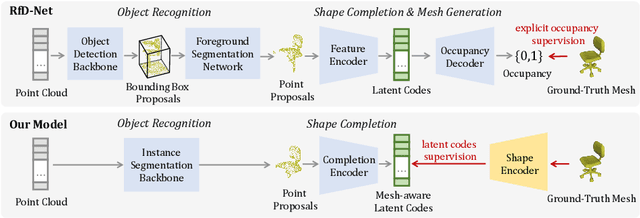
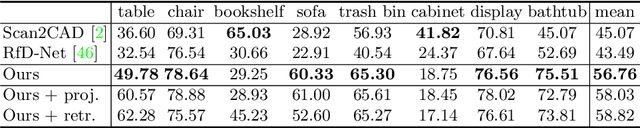
Semantic scene reconstruction from point cloud is an essential and challenging task for 3D scene understanding. This task requires not only to recognize each instance in the scene, but also to recover their geometries based on the partial observed point cloud. Existing methods usually attempt to directly predict occupancy values of the complete object based on incomplete point cloud proposals from a detection-based backbone. However, this framework always fails to reconstruct high fidelity mesh due to the obstruction of various detected false positive object proposals and the ambiguity of incomplete point observations for learning occupancy values of complete objects. To circumvent the hurdle, we propose a Disentangled Instance Mesh Reconstruction (DIMR) framework for effective point scene understanding. A segmentation-based backbone is applied to reduce false positive object proposals, which further benefits our exploration on the relationship between recognition and reconstruction. Based on the accurate proposals, we leverage a mesh-aware latent code space to disentangle the processes of shape completion and mesh generation, relieving the ambiguity caused by the incomplete point observations. Furthermore, with access to the CAD model pool at test time, our model can also be used to improve the reconstruction quality by performing mesh retrieval without extra training. We thoroughly evaluate the reconstructed mesh quality with multiple metrics, and demonstrate the superiority of our method on the challenging ScanNet dataset.
LiDAR Road-Atlas: An Efficient Map Representation for General 3D Urban Environment
Apr 12, 2022
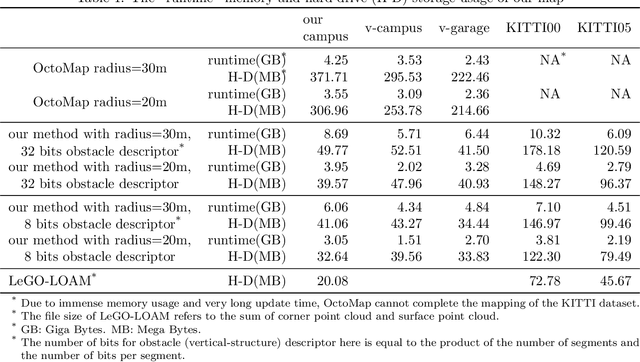

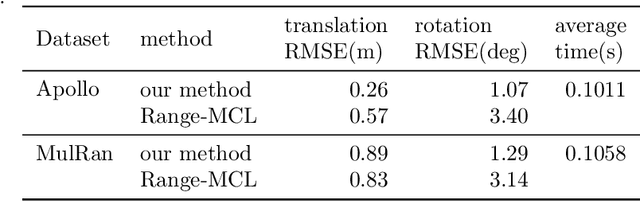
In this work, we propose the LiDAR Road-Atlas, a compactable and efficient 3D map representation, for autonomous robot or vehicle navigation in general urban environment. The LiDAR Road-Atlas can be generated by an online mapping framework based on incrementally merging local 2D occupancy grid maps (2D-OGM). Specifically, the contributions of our LiDAR Road-Atlas representation are threefold. First, we solve the challenging problem of creating local 2D-OGM in non-structured urban scenes based on a real-time delimitation of traversable and curb regions in LiDAR point cloud. Second, we achieve accurate 3D mapping in multiple-layer urban road scenarios by a probabilistic fusion scheme. Third, we achieve very efficient 3D map representation of general environment thanks to the automatic local-OGM induced traversable-region labeling and a sparse probabilistic local point-cloud encoding. Given the LiDAR Road-Atlas, one can achieve accurate vehicle localization, path planning and some other tasks. Our map representation is insensitive to dynamic objects which can be filtered out in the resulting map based on a probabilistic fusion. Empirically, we compare our map representation with a couple of popular map representation methods in robotics and autonomous driving societies, and our map representation is more favorable in terms of efficiency, scalability and compactness. In addition, we also evaluate localization accuracy extensively given the created LiDAR Road-Atlas representations on several public benchmark datasets. With a 16-channel LiDAR sensor, our method achieves an average global localization errors of 0.26m (translation) and 1.07 degrees (rotation) on the Apollo dataset, and 0.89m (translation) and 1.29 degrees (rotation) on the MulRan dataset, respectively, at 10Hz, which validates the promising performance of our map representation for autonomous driving.
Oversampling for Imbalanced Time Series Data
Apr 14, 2020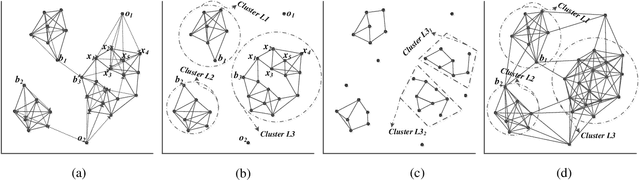
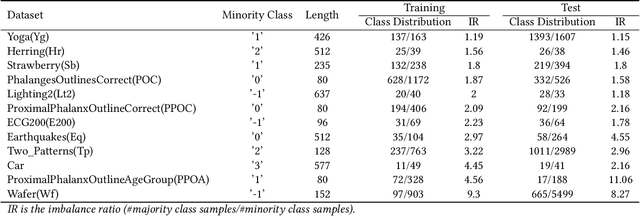
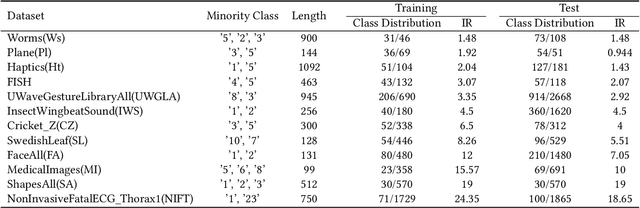
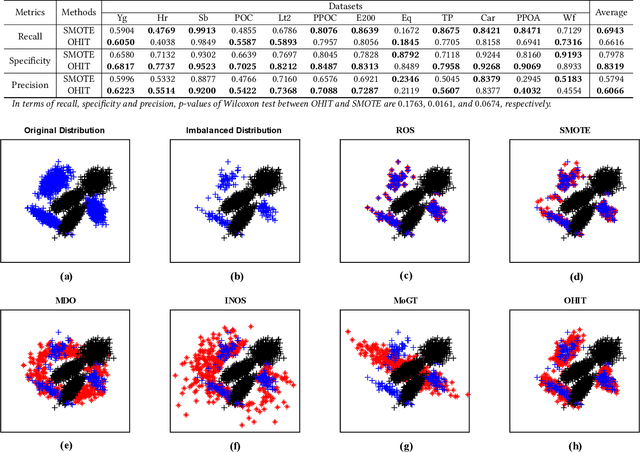
Many important real-world applications involve time-series data with skewed distribution. Compared to conventional imbalance learning problems, the classification of imbalanced time-series data is more challenging due to high dimensionality and high inter-variable correlation. This paper proposes a structure preserving Oversampling method to combat the High-dimensional Imbalanced Time-series classification (OHIT). OHIT first leverages a density-ratio based shared nearest neighbor clustering algorithm to capture the modes of minority class in high-dimensional space. It then for each mode applies the shrinkage technique of large-dimensional covariance matrix to obtain accurate and reliable covariance structure. Finally, OHIT generates the structure-preserving synthetic samples based on multivariate Gaussian distribution by using the estimated covariance matrices. Experimental results on several publicly available time-series datasets (including unimodal and multi-modal) demonstrate the superiority of OHIT against the state-of-the-art oversampling algorithms in terms of F-value, G-mean, and AUC.
TrajGen: Generating Realistic and Diverse Trajectories with Reactive and Feasible Agent Behaviors for Autonomous Driving
Mar 31, 2022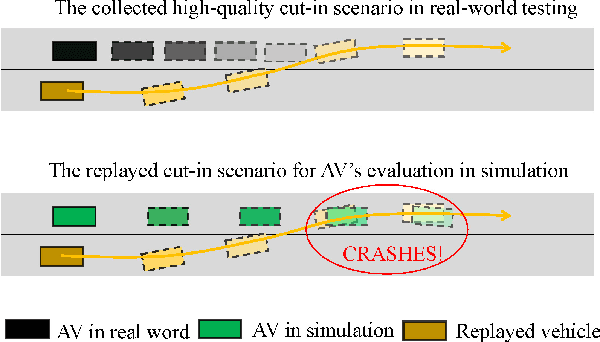
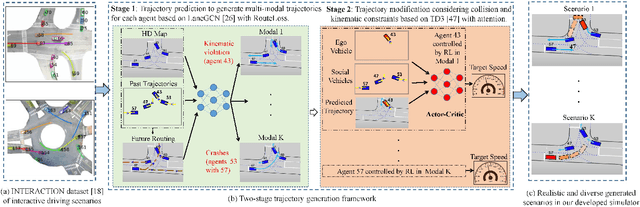
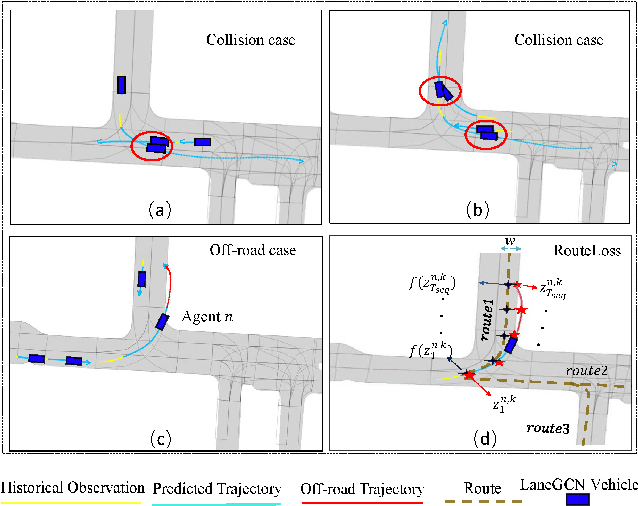
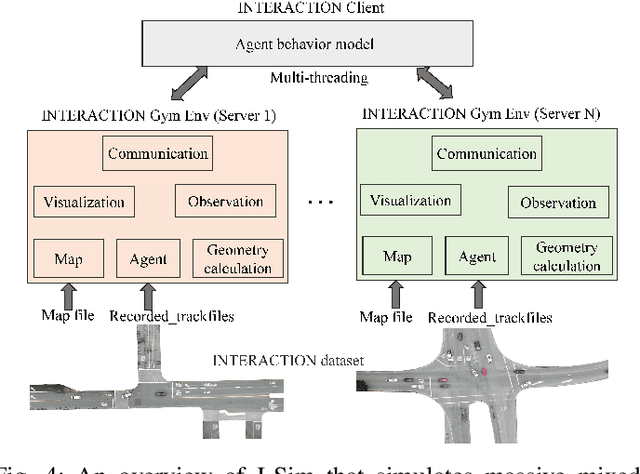
Realistic and diverse simulation scenarios with reactive and feasible agent behaviors can be used for validation and verification of self-driving system performance without relying on expensive and time-consuming real-world testing. Existing simulators rely on heuristic-based behavior models for background vehicles, which cannot capture the complex interactive behaviors in real-world scenarios. To bridge the gap between simulation and the real world, we propose TrajGen, a two-stage trajectory generation framework, which can capture more realistic behaviors directly from human demonstration. In particular, TrajGen consists of the multi-modal trajectory prediction stage and the reinforcement learning based trajectory modification stage. In the first stage, we propose a novel auxiliary RouteLoss for the trajectory prediction model to generate multi-modal diverse trajectories in the drivable area. In the second stage, reinforcement learning is used to track the predicted trajectories while avoiding collisions, which can improve the feasibility of generated trajectories. In addition, we develop a data-driven simulator I-Sim that can be used to train reinforcement learning models in parallel based on naturalistic driving data. The vehicle model in I-Sim can guarantee that the generated trajectories by TrajGen satisfy vehicle kinematic constraints. Finally, we give comprehensive metrics to evaluate generated trajectories for simulation scenarios, which shows that TrajGen outperforms either trajectory prediction or inverse reinforcement learning in terms of fidelity, reactivity, feasibility, and diversity.
Bayesian Spillover Graphs for Dynamic Networks
Mar 03, 2022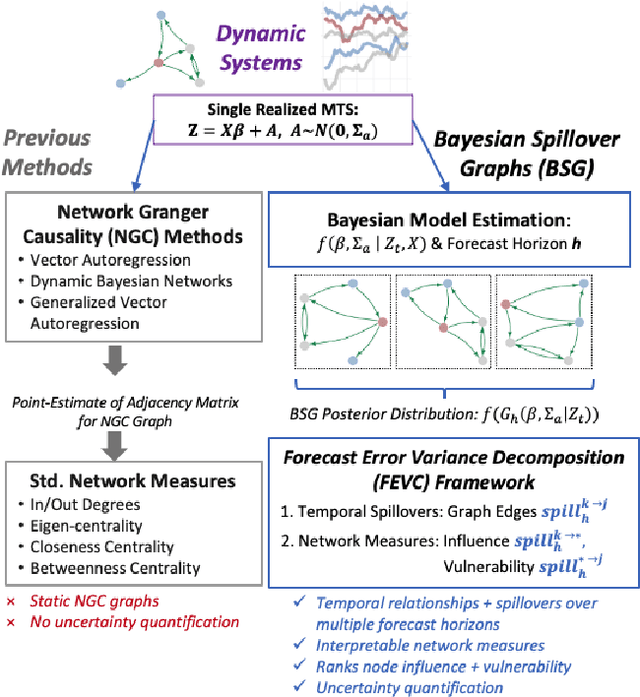
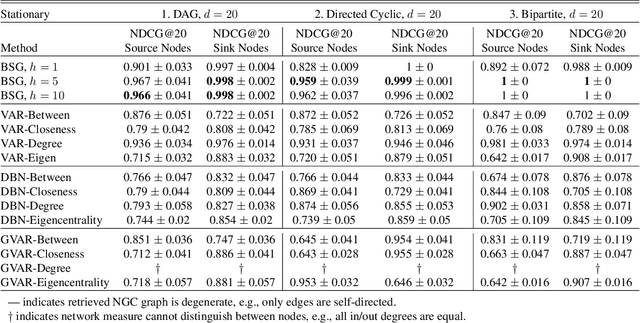
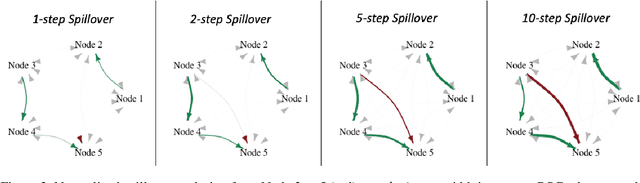
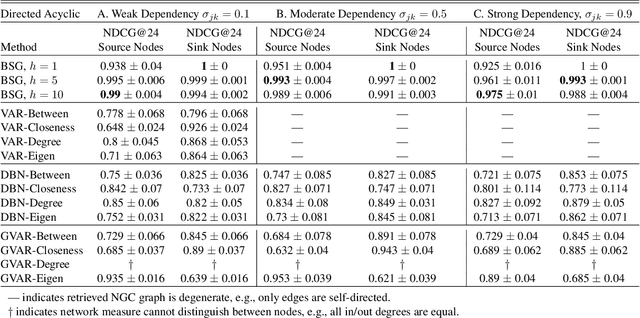
We present Bayesian Spillover Graphs (BSG), a novel method for learning temporal relationships, identifying critical nodes, and quantifying uncertainty for multi-horizon spillover effects in a dynamic system. BSG leverages both an interpretable framework via forecast error variance decompositions (FEVD) and comprehensive uncertainty quantification via Bayesian time series models to contextualize temporal relationships in terms of systemic risk and prediction variability. Forecast horizon hyperparameter $h$ allows for learning both short-term and equilibrium state network behaviors. Experiments for identifying source and sink nodes under various graph and error specifications show significant performance gains against state-of-the-art Bayesian Networks and deep-learning baselines. Applications to real-world systems also showcase BSG as an exploratory analysis tool for uncovering indirect spillovers and quantifying risk.
How to Register a Live onto a Liver ? Partial Matching in the Space of Varifolds
Apr 12, 2022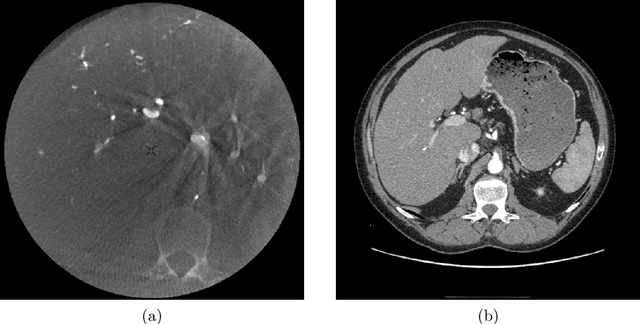
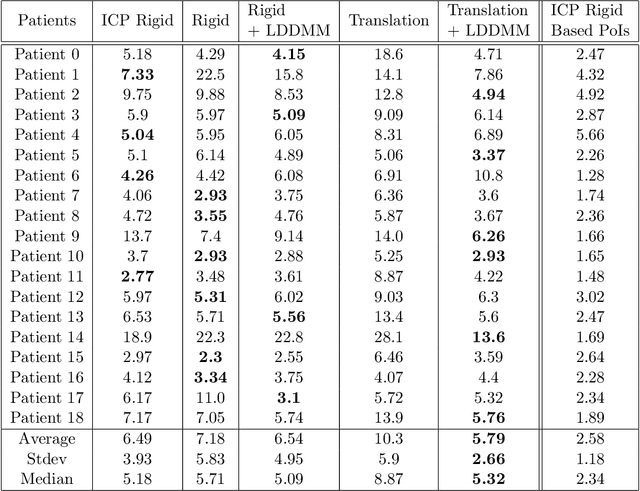

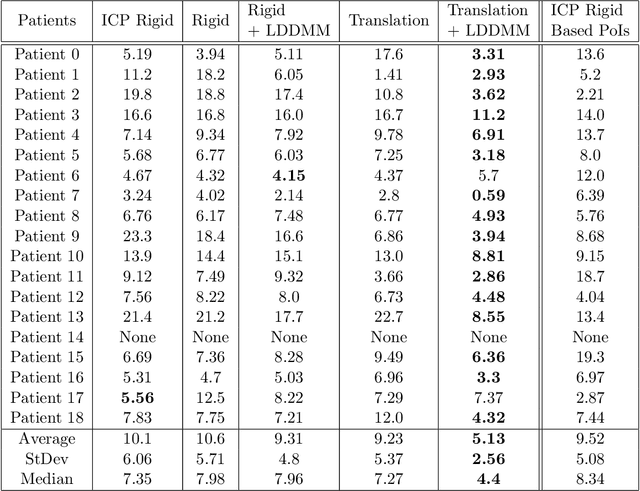
Partial shapes correspondences is a problem that often occurs in computer vision (occlusion, evolution in time...). In medical imaging, data may come from different modalities and be acquired under different conditions which leads to variations in shapes and topologies. In this paper we use an asymmetric data dissimilarity term applicable to various geometric shapes like sets of curves or surfaces, assessing the embedding of a shape into another one without relying on correspondences. It is designed as a data attachment for the Large Deformation Diffeomorphic Metric Mapping (LDDMM) framework, allowing to compute a meaningful deformation of one shape onto a subset of the other. We refine it in order to control the resulting non-rigid deformations and provide consistent deformations of the shapes along with their ambient space. We show that partial matching can be used for robust multi-modal liver registration between a Computed Tomography (CT) volume and a Cone Beam Computed Tomography (CBCT) volume. The 3D imaging of the patient CBCT at point of care that we call live is truncated while the CT pre-intervention provides a full visualization of the liver. The proposed method allows the truncated surfaces from CBCT to be aligned non-rigidly, yet realistically, with surfaces from CT with an average distance of 2.6mm(+/- 2.2). The generated deformations extend consistently to the liver volume, and are evaluated on points of interest for the physicians, with an average distance of 5.8mm (+/- 2.7) for vessels bifurcations and 5.13mm (+/- 2.5) for tumors landmarks. Such multi-modality volumes registrations would help the physicians in the perspective of navigating their tools in the patient's anatomy to locate structures that are hardly visible in the CBCT used during their procedures. Our code is available at https://github.com/plantonsanti/PartialMatchingVarifolds.
* 30 pages, 11 figures, Special Issue: Information Processing in Medical Imaging (IPMI) 2021, Accepted for publication at the Journal of Machine Learning for Biomedical Imaging (MELBA) https://www.melba-journal.org
Extracting associations and meanings of objects depicted in artworks through bi-modal deep networks
Mar 14, 2022
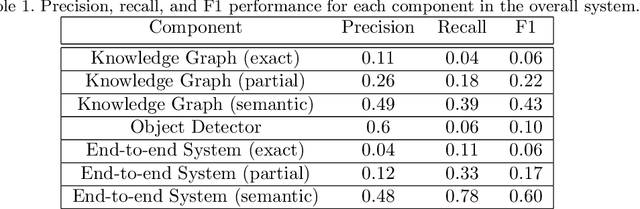


We present a novel bi-modal system based on deep networks to address the problem of learning associations and simple meanings of objects depicted in "authored" images, such as fine art paintings and drawings. Our overall system processes both the images and associated texts in order to learn associations between images of individual objects, their identities and the abstract meanings they signify. Unlike past deep net that describe depicted objects and infer predicates, our system identifies meaning-bearing objects ("signifiers") and their associations ("signifieds") as well as basic overall meanings for target artworks. Our system had precision of 48% and recall of 78% with an F1 metric of 0.6 on a curated set of Dutch vanitas paintings, a genre celebrated for its concentration on conveying a meaning of great import at the time of their execution. We developed and tested our system on fine art paintings but our general methods can be applied to other authored images.