 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Understanding the input-output relationship of neural networks in the time series forecasting radon levels at Canfranc Underground Laboratory
Mar 01, 2021
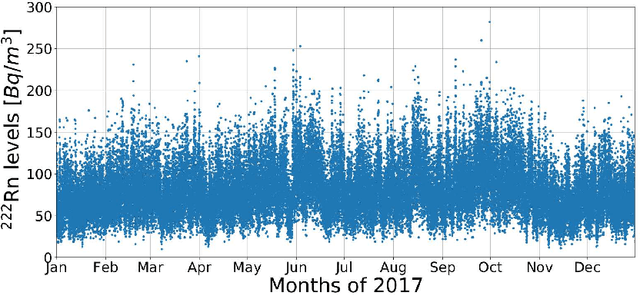
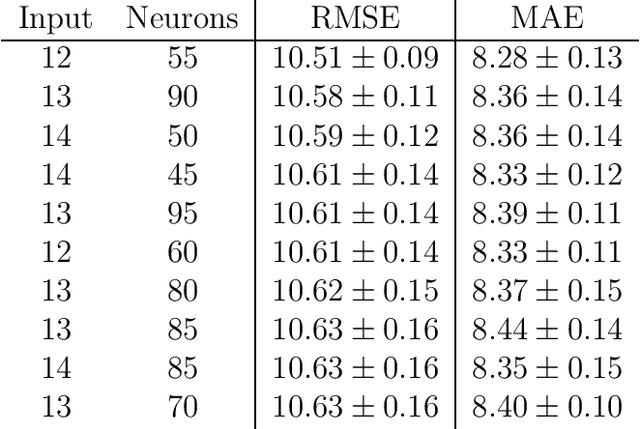
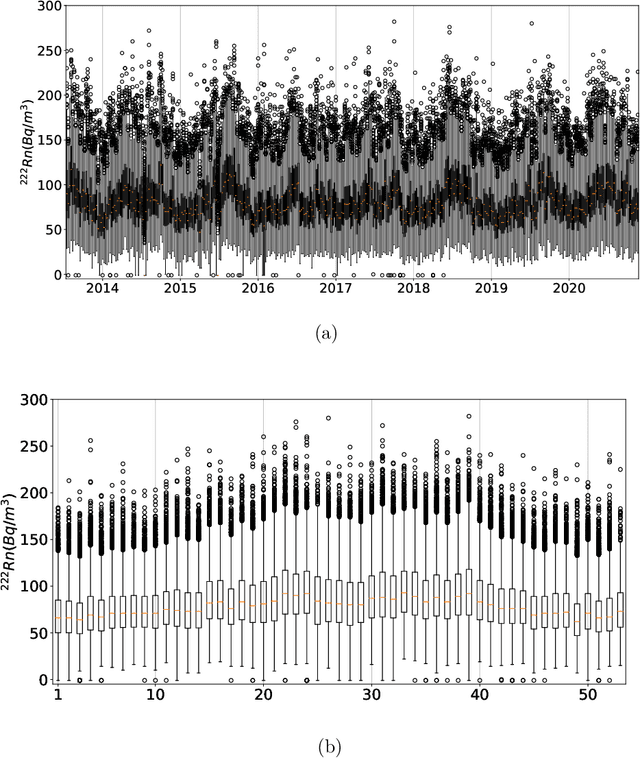
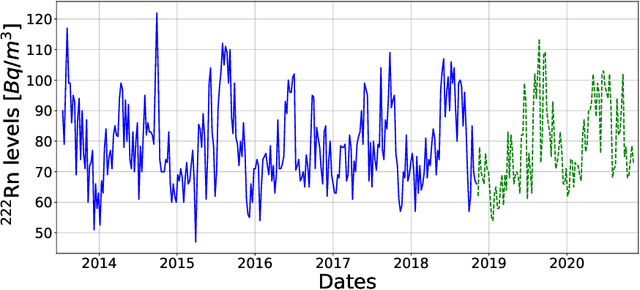
Underground physics experiments such as dark matter direct detection need to keep control of the background contribution. Hosting these experiments in underground facilities helps to minimize certain background sources such as the cosmic rays. One of the largest remaining background sources is the radon emanated from the rocks enclosing the research facility. The radon particles could be deposited inside the detectors when they are opened to perform the maintenance operations. Therefore, forecasting the radon levels is a crucial task in an attempt to schedule the maintenance operations when radon level is minimum. In the past, deep learning models have been implemented to forecast the radon time series at the Canfranc Underground Laboratory (LSC), in Spain, with satisfactory results. When forecasting time series, the past values of the time series are taken as input variables. The present work focuses on understanding the relative contribution of these input variables to the predictions generated by neural networks. The results allow us to understand how the predictions of the time series depend on the input variables. These results may be used to build better predictors in the future.
Inverse Design and Experimental Verification of a Bianisotropic Metasurface Using Optimization and Machine Learning
Mar 28, 2022
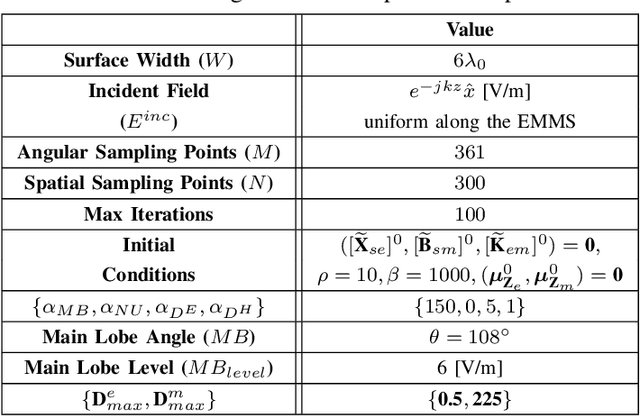
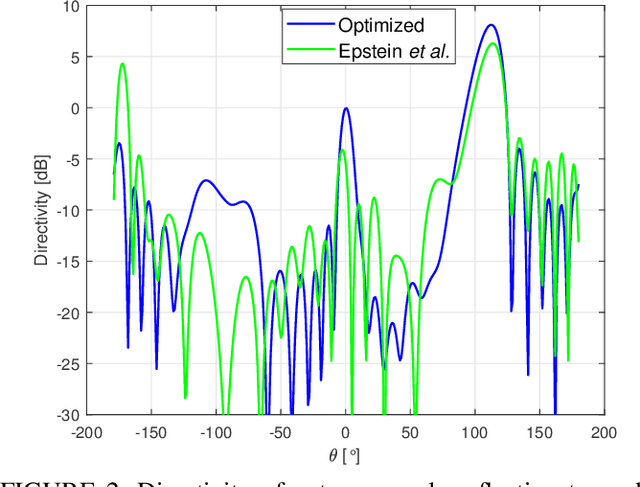
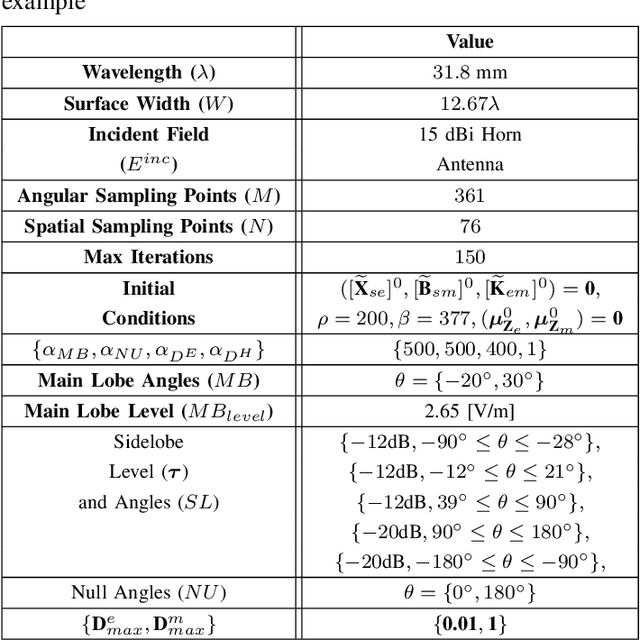
Electromagnetic metasurfaces have attracted significant interest recently due to their low profile and advantageous applications. Practically, many metasurface designs start with a set of constraints for the radiated far-field, such as main-beam direction(s) and side lobe levels, and end with a non-uniform physical structure for the surface. This problem is quite challenging, since the required tangential field transformations are not completely known when only constraints are placed on the scattered fields. Hence, the required surface properties cannot be solved for analytically. Moreover, the translation of the desired surface properties to the physical unit cells can be time-consuming and difficult, as it is often a one-to-many mapping in a large solution space. Here, we divide the inverse design process into two steps: a macroscopic and microscopic design step. In the former, we use an iterative optimization process to find the surface properties that radiate a far-field pattern that complies with specified constraints. This iterative process exploits non-radiating currents to ensure a passive and lossless design. In the microscopic step, these optimized surface properties are realized with physical unit cells using machine learning surrogate models. The effectiveness of this end-to-end synthesis process is demonstrated through measurement results of a beam-splitting prototype.
Pan-cancer computational histopathology reveals tumor mutational burden status through weakly-supervised deep learning
Apr 07, 2022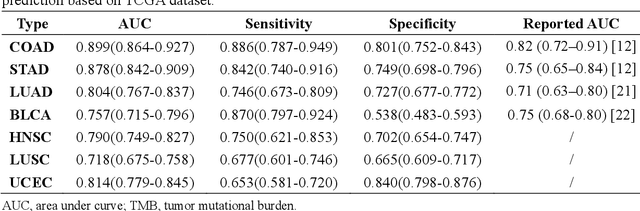
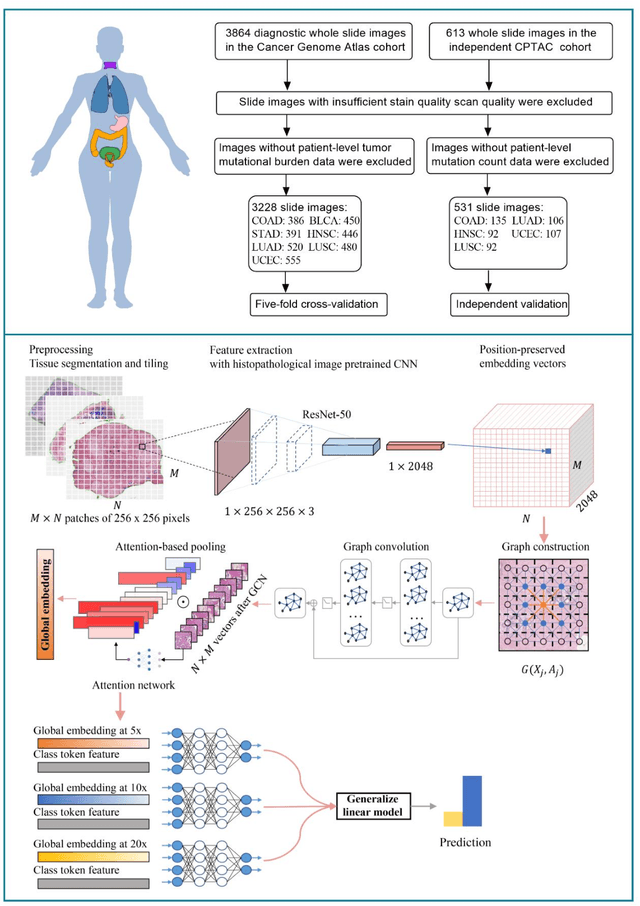
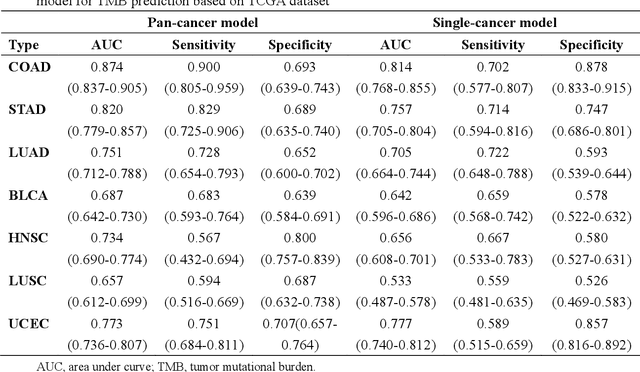
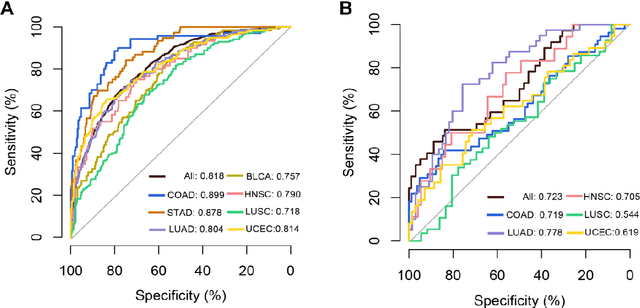
Tumor mutational burden (TMB) is a potential genomic biomarker that can help identify patients who will benefit from immunotherapy across a variety of cancers. We included whole slide images (WSIs) of 3228 diagnostic slides from the Cancer Genome Atlas and 531 WSIs from the Clinical Proteomic Tumor Analysis Consortium for the development and verification of a pan-cancer TMB prediction model (PC-TMB). We proposed a multiscale weakly-supervised deep learning framework for predicting TMB of seven types of tumors based only on routinely used hematoxylin-eosin (H&E)-stained WSIs. PC-TMB achieved a mean area under curve (AUC) of 0.818 (0.804-0.831) in the cross-validation cohort, which was superior to the best single-scale model. In comparison with the state-of-the-art TMB prediction model from previous publications, our multiscale model achieved better performance over previously reported models. In addition, the improvements of PC-TMB over the single-tumor models were also confirmed by the ablation tests on 10x magnification. The PC-TMB algorithm also exhibited good generalization on external validation cohort with AUC of 0.732 (0.683-0.761). PC-TMB possessed a comparable survival-risk stratification performance to the TMB measured by whole exome sequencing, but with low cost and being time-efficient for providing a prognostic biomarker of multiple solid tumors. Moreover, spatial heterogeneity of TMB within tumors was also identified through our PC-TMB, which might enable image-based screening for molecular biomarkers with spatial variation and potential exploring for genotype-spatial heterogeneity relationships.
Two-dimensional structure functions to characterize convective rolls in the marine atmospheric boundary layer from Sentinel-1 SAR images
Mar 04, 2022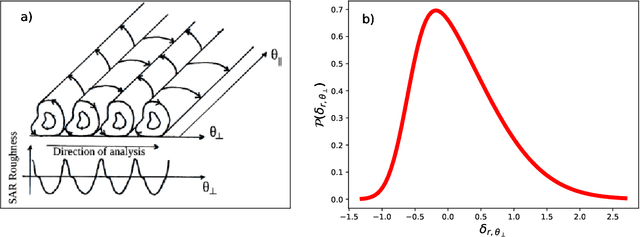
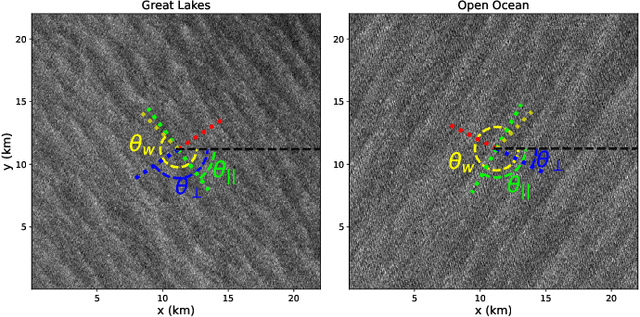
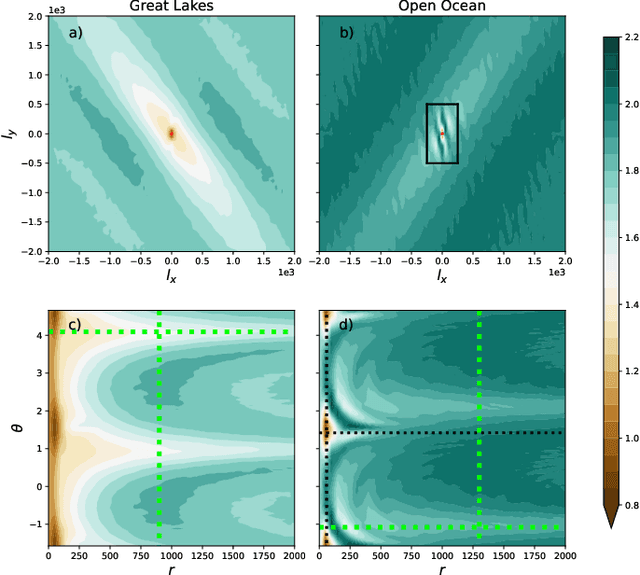
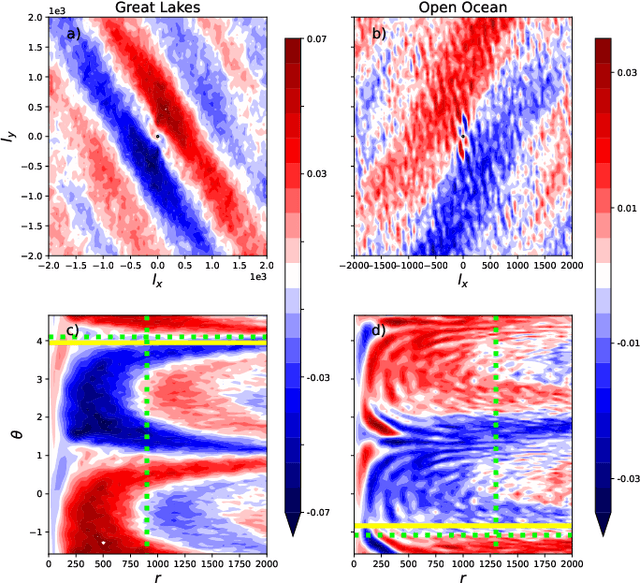
We study the shape of convective rolls in the Marine Atmospheric Boundary Layer from Synthetic Aperture Radar images of the ocean. We propose a multiscale analysis with structure functions which allow an easy generalization to analyse high-order statistics and so to finely describe the shape of the rolls. The two main results are : 1) second order structure function characterizes the size and direction of rolls just like correlation or power spectrum do, 2) high order statistics can be studied with skewness and Flatness which characterize the asymmetry and intermittency of rolls respectively. From the best of our knowledge, this is the first time that the asymmetry and intermittency of rolls is shown from radar images of the ocean surface.
AEGNN: Asynchronous Event-based Graph Neural Networks
Mar 31, 2022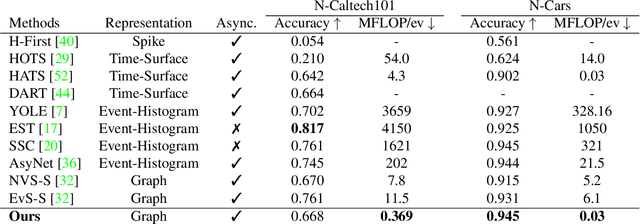
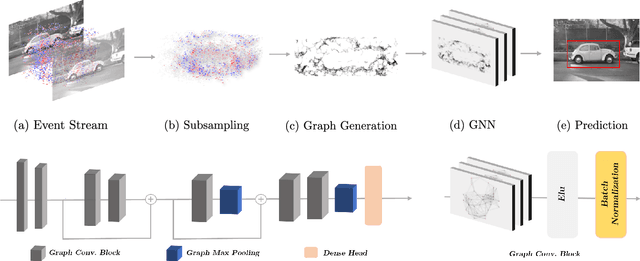
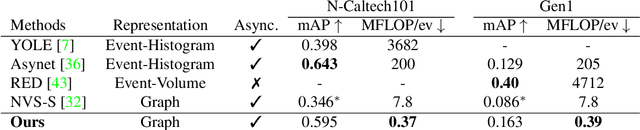
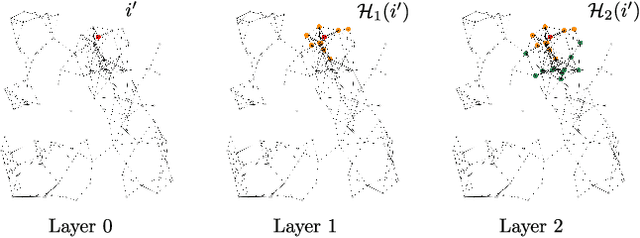
The best performing learning algorithms devised for event cameras work by first converting events into dense representations that are then processed using standard CNNs. However, these steps discard both the sparsity and high temporal resolution of events, leading to high computational burden and latency. For this reason, recent works have adopted Graph Neural Networks (GNNs), which process events as "static" spatio-temporal graphs, which are inherently "sparse". We take this trend one step further by introducing Asynchronous, Event-based Graph Neural Networks (AEGNNs), a novel event-processing paradigm that generalizes standard GNNs to process events as "evolving" spatio-temporal graphs. AEGNNs follow efficient update rules that restrict recomputation of network activations only to the nodes affected by each new event, thereby significantly reducing both computation and latency for event-by-event processing. AEGNNs are easily trained on synchronous inputs and can be converted to efficient, "asynchronous" networks at test time. We thoroughly validate our method on object classification and detection tasks, where we show an up to a 200-fold reduction in computational complexity (FLOPs), with similar or even better performance than state-of-the-art asynchronous methods. This reduction in computation directly translates to an 8-fold reduction in computational latency when compared to standard GNNs, which opens the door to low-latency event-based processing.
TODS: An Automated Time Series Outlier Detection System
Sep 18, 2020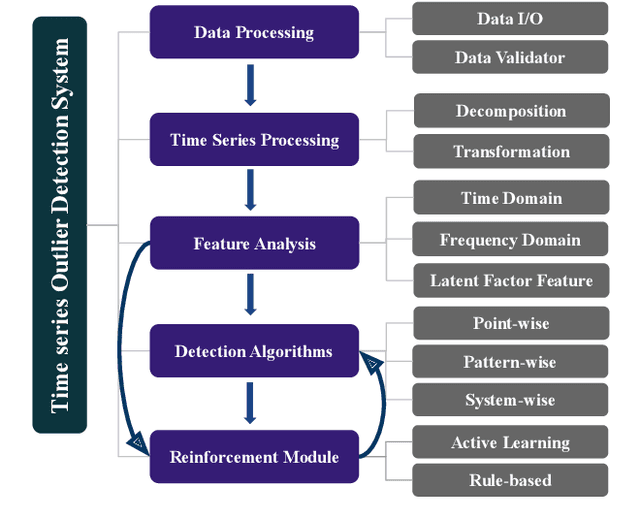
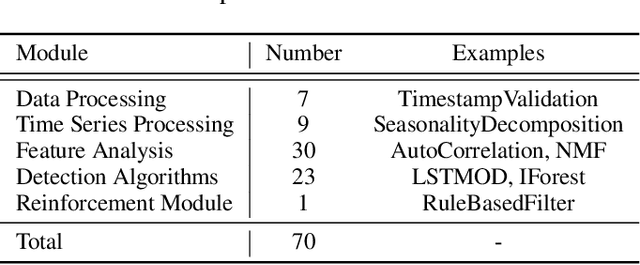
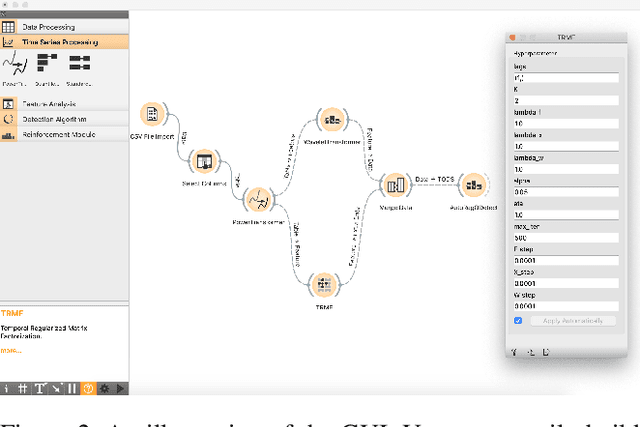
We present TODS, an automated Time Series Outlier Detection System for research and industrial applications. TODS is a highly modular system that supports easy pipeline construction. The basic building block of TODS is primitive, which is an implementation of a function with hyperparameters. TODS currently supports 70 primitives, including data processing, time series processing, feature analysis, detection algorithms, and a reinforcement module. Users can freely construct a pipeline using these primitives and perform end- to-end outlier detection with the constructed pipeline. TODS provides a Graphical User Interface (GUI), where users can flexibly design a pipeline with drag-and-drop. Moreover, a data-driven searcher is provided to automatically discover the most suitable pipelines given a dataset. TODS is released under Apache 2.0 license at https://github.com/datamllab/tods.
A Semi-Supervised Deep Clustering Pipeline for Mining Intentions From Texts
Feb 01, 2022Mining the latent intentions from large volumes of natural language inputs is a key step to help data analysts design and refine Intelligent Virtual Assistants (IVAs) for customer service. To aid data analysts in this task we present Verint Intent Manager (VIM), an analysis platform that combines unsupervised and semi-supervised approaches to help analysts quickly surface and organize relevant user intentions from conversational texts. For the initial exploration of data we make use of a novel unsupervised and semi-supervised pipeline that integrates the fine-tuning of high performing language models, a distributed k-NN graph building method and community detection techniques for mining the intentions and topics from texts. The fine-tuning step is necessary because pre-trained language models cannot encode texts to efficiently surface particular clustering structures when the target texts are from an unseen domain or the clustering task is not topic detection. For flexibility we deploy two clustering approaches: where the number of clusters must be specified and where the number of clusters is detected automatically with comparable clustering quality but at the expense of additional computation time. We describe the application and deployment and demonstrate its performance using BERT on three text mining tasks. Our experiments show that BERT begins to produce better task-aware representations using a labeled subset as small as 0.5% of the task data. The clustering quality exceeds the state-of-the-art results when BERT is fine-tuned with labeled subsets of only 2.5% of the task data. As deployed in the VIM application, this flexible clustering pipeline produces high quality results, improving the performance of data analysts and reducing the time it takes to surface intentions from customer service data, thereby reducing the time it takes to build and deploy IVAs in new domains.
Unfolding a blurred image
Jan 28, 2022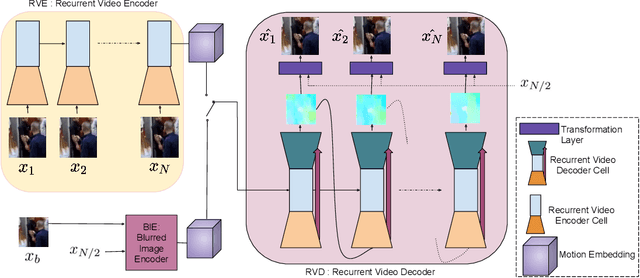
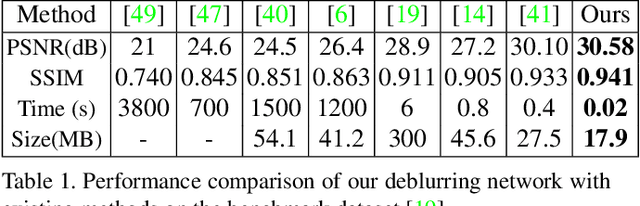
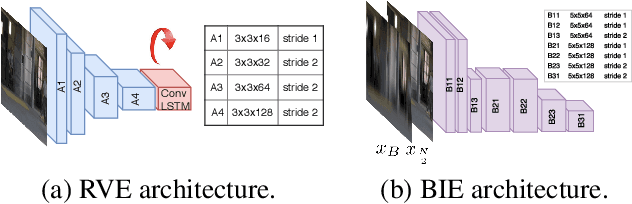
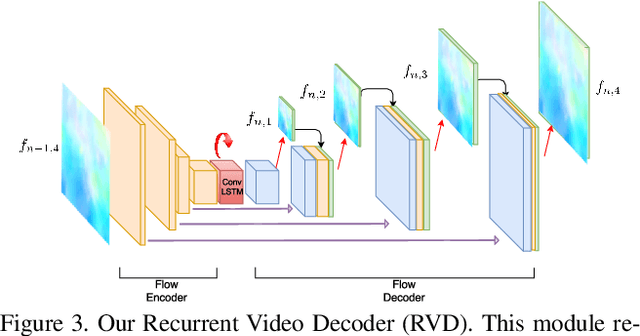
We present a solution for the goal of extracting a video from a single motion blurred image to sequentially reconstruct the clear views of a scene as beheld by the camera during the time of exposure. We first learn motion representation from sharp videos in an unsupervised manner through training of a convolutional recurrent video autoencoder network that performs a surrogate task of video reconstruction. Once trained, it is employed for guided training of a motion encoder for blurred images. This network extracts embedded motion information from the blurred image to generate a sharp video in conjunction with the trained recurrent video decoder. As an intermediate step, we also design an efficient architecture that enables real-time single image deblurring and outperforms competing methods across all factors: accuracy, speed, and compactness. Experiments on real scenes and standard datasets demonstrate the superiority of our framework over the state-of-the-art and its ability to generate a plausible sequence of temporally consistent sharp frames.
Forecasting from LiDAR via Future Object Detection
Mar 31, 2022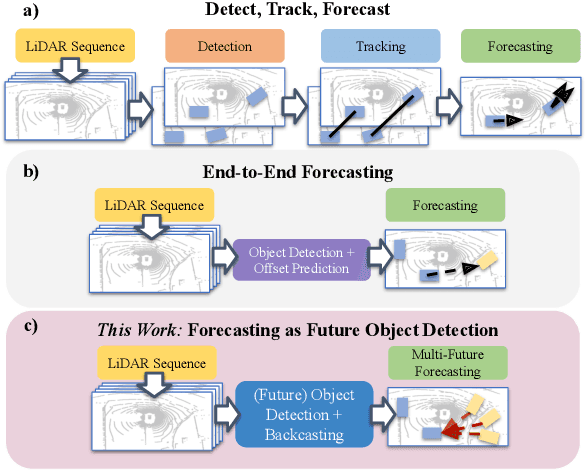

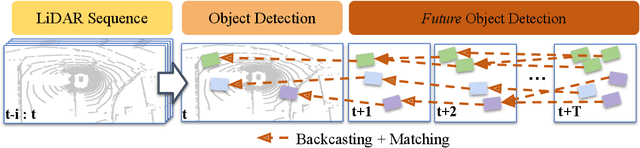
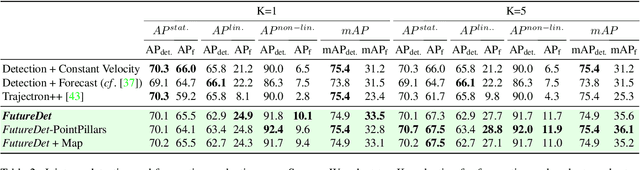
Object detection and forecasting are fundamental components of embodied perception. These two problems, however, are largely studied in isolation by the community. In this paper, we propose an end-to-end approach for detection and motion forecasting based on raw sensor measurement as opposed to ground truth tracks. Instead of predicting the current frame locations and forecasting forward in time, we directly predict future object locations and backcast to determine where each trajectory began. Our approach not only improves overall accuracy compared to other modular or end-to-end baselines, it also prompts us to rethink the role of explicit tracking for embodied perception. Additionally, by linking future and current locations in a many-to-one manner, our approach is able to reason about multiple futures, a capability that was previously considered difficult for end-to-end approaches. We conduct extensive experiments on the popular nuScenes dataset and demonstrate the empirical effectiveness of our approach. In addition, we investigate the appropriateness of reusing standard forecasting metrics for an end-to-end setup, and find a number of limitations which allow us to build simple baselines to game these metrics. We address this issue with a novel set of joint forecasting and detection metrics that extend the commonly used AP metrics from the detection community to measuring forecasting accuracy. Our code is available at https://github.com/neeharperi/FutureDet
Skydiver: A Spiking Neural Network Accelerator Exploiting Spatio-Temporal Workload Balance
Mar 14, 2022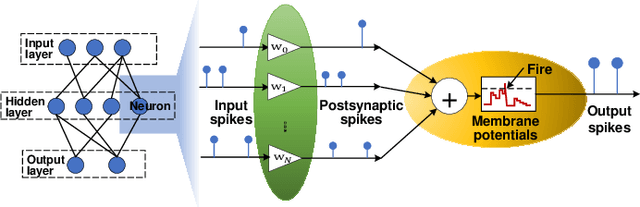
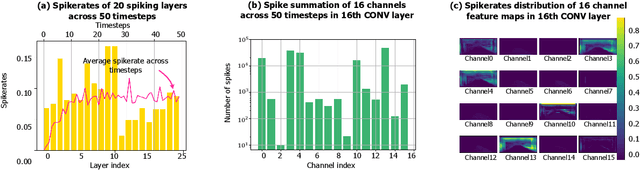
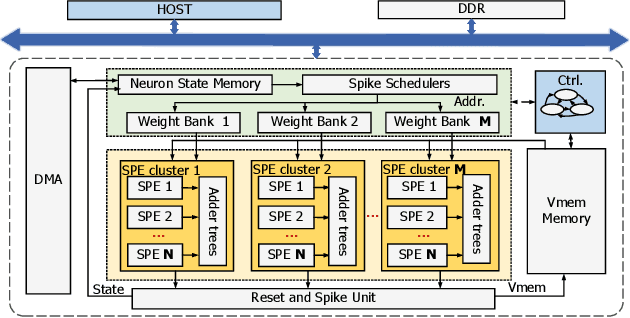
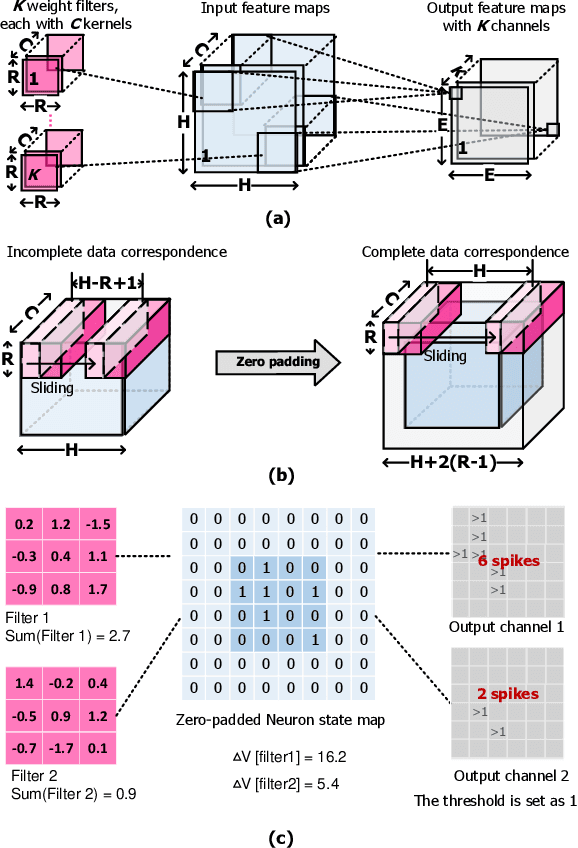
Spiking Neural Networks (SNNs) are developed as a promising alternative to Artificial Neural networks (ANNs) due to their more realistic brain-inspired computing models. SNNs have sparse neuron firing over time, i.e., spatio-temporal sparsity; thus, they are useful to enable energy-efficient hardware inference. However, exploiting spatio-temporal sparsity of SNNs in hardware leads to unpredictable and unbalanced workloads, degrading the energy efficiency. In this work, we propose an FPGA-based convolutional SNN accelerator called Skydiver that exploits spatio-temporal workload balance. We propose the Approximate Proportional Relation Construction (APRC) method that can predict the relative workload channel-wisely and a Channel-Balanced Workload Schedule (CBWS) method to increase the hardware workload balance ratio to over 90%. Skydiver was implemented on a Xilinx XC7Z045 FPGA and verified on image segmentation and MNIST classification tasks. Results show improved throughput by 1.4X and 1.2X for the two tasks. Skydiver achieved 22.6 KFPS throughput, and 42.4 uJ/Image prediction energy on the classification task with 98.5% accuracy.