 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TALLFormer: Temporal Action Localization with Long-memory Transformer
Apr 04, 2022
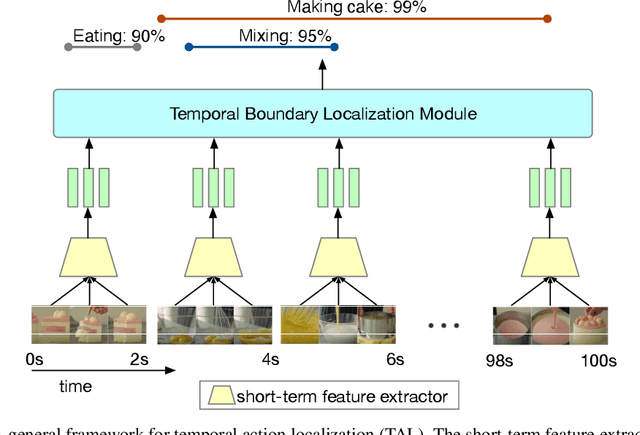
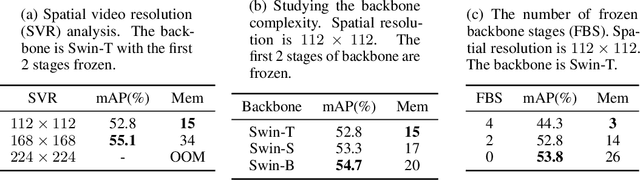
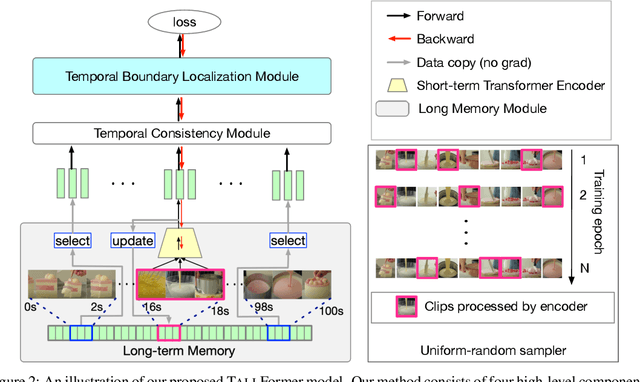
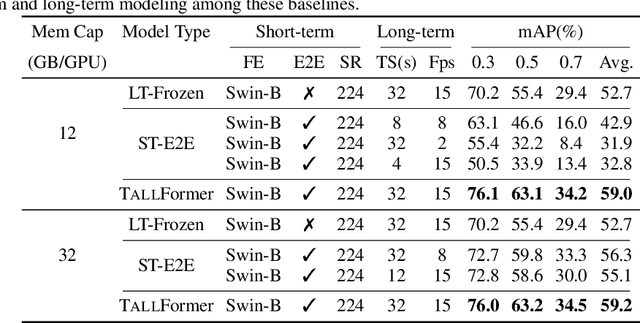
Most modern approaches in temporal action localization divide this problem into two parts: (i) short-term feature extraction and (ii) long-range temporal boundary localization. Due to the high GPU memory cost caused by processing long untrimmed videos, many methods sacrifice the representational power of the short-term feature extractor by either freezing the backbone or using a very small spatial video resolution. This issue becomes even worse with the recent video transformer models, many of which have quadratic memory complexity. To address these issues, we propose TALLFormer, a memory-efficient and end-to-end trainable Temporal Action Localization transformer with Long-term memory. Our long-term memory mechanism eliminates the need for processing hundreds of redundant video frames during each training iteration, thus, significantly reducing the GPU memory consumption and training time. These efficiency savings allow us (i) to use a powerful video transformer-based feature extractor without freezing the backbone or reducing the spatial video resolution, while (ii) also maintaining long-range temporal boundary localization capability. With only RGB frames as input and no external action recognition classifier, TALLFormer outperforms previous state-of-the-art methods by a large margin, achieving an average mAP of 59.1% on THUMOS14 and 35.6% on ActivityNet-1.3. The code will be available in https://github.com/klauscc/TALLFormer.
Resonance in Weight Space: Covariate Shift Can Drive Divergence of SGD with Momentum
Mar 22, 2022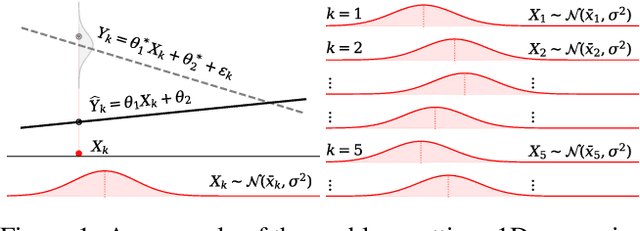
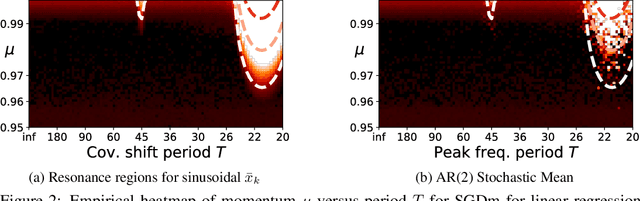

Most convergence guarantees for stochastic gradient descent with momentum (SGDm) rely on iid sampling. Yet, SGDm is often used outside this regime, in settings with temporally correlated input samples such as continual learning and reinforcement learning. Existing work has shown that SGDm with a decaying step-size can converge under Markovian temporal correlation. In this work, we show that SGDm under covariate shift with a fixed step-size can be unstable and diverge. In particular, we show SGDm under covariate shift is a parametric oscillator, and so can suffer from a phenomenon known as resonance. We approximate the learning system as a time varying system of ordinary differential equations, and leverage existing theory to characterize the system's divergence/convergence as resonant/nonresonant modes. The theoretical result is limited to the linear setting with periodic covariate shift, so we empirically supplement this result to show that resonance phenomena persist even under non-periodic covariate shift, nonlinear dynamics with neural networks, and optimizers other than SGDm.
APP: Anytime Progressive Pruning
Apr 04, 2022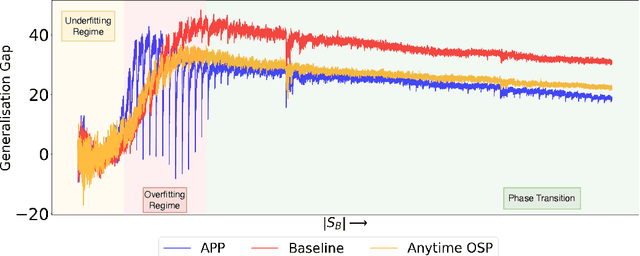
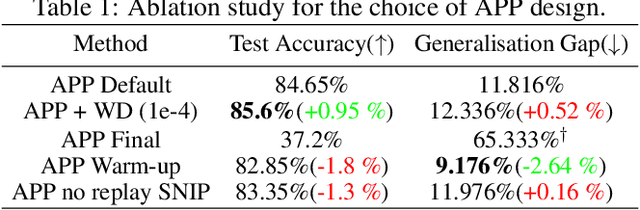
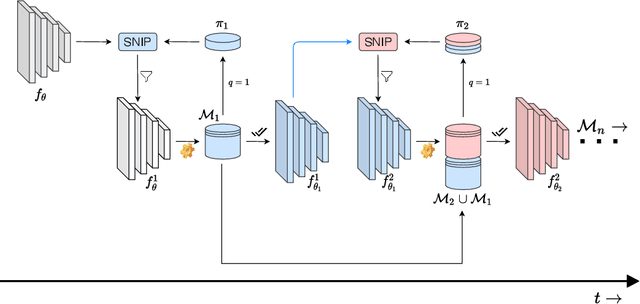
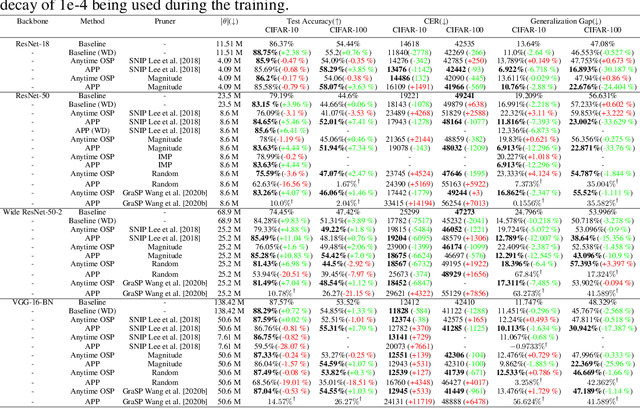
With the latest advances in deep learning, there has been a lot of focus on the online learning paradigm due to its relevance in practical settings. Although many methods have been investigated for optimal learning settings in scenarios where the data stream is continuous over time, sparse networks training in such settings have often been overlooked. In this paper, we explore the problem of training a neural network with a target sparsity in a particular case of online learning: the anytime learning at macroscale paradigm (ALMA). We propose a novel way of progressive pruning, referred to as \textit{Anytime Progressive Pruning} (APP); the proposed approach significantly outperforms the baseline dense and Anytime OSP models across multiple architectures and datasets under short, moderate, and long-sequence training. Our method, for example, shows an improvement in accuracy of $\approx 7\%$ and a reduction in the generalization gap by $\approx 22\%$, while being $\approx 1/3$ rd the size of the dense baseline model in few-shot restricted imagenet training. We further observe interesting nonmonotonic transitions in the generalization gap in the high number of megabatches-based ALMA. The code and experiment dashboards can be accessed at \url{https://github.com/landskape-ai/Progressive-Pruning} and \url{https://wandb.ai/landskape/APP}, respectively.
Search-based Methods for Multi-Cloud Configuration
Apr 20, 2022
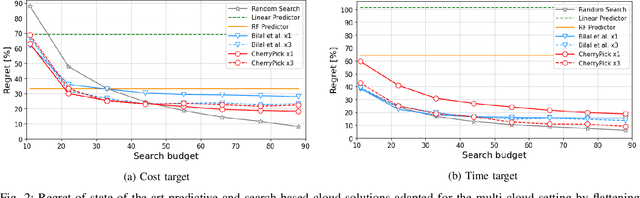
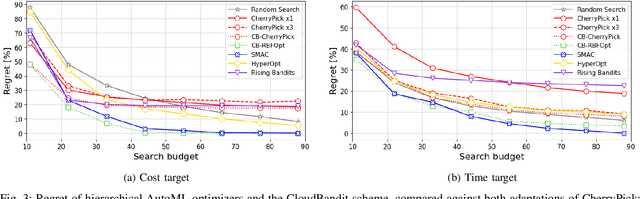
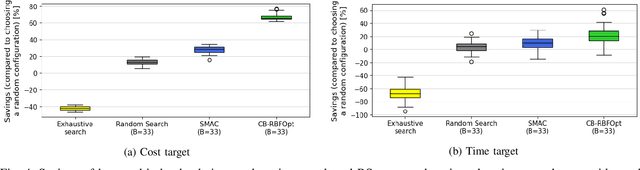
Multi-cloud computing has become increasingly popular with enterprises looking to avoid vendor lock-in. While most cloud providers offer similar functionality, they may differ significantly in terms of performance and/or cost. A customer looking to benefit from such differences will naturally want to solve the multi-cloud configuration problem: given a workload, which cloud provider should be chosen and how should its nodes be configured in order to minimize runtime or cost? In this work, we consider solutions to this optimization problem. We develop and evaluate possible adaptations of state-of-the-art cloud configuration solutions to the multi-cloud domain. Furthermore, we identify an analogy between multi-cloud configuration and the selection-configuration problems commonly studied in the automated machine learning (AutoML) field. Inspired by this connection, we utilize popular optimizers from AutoML to solve multi-cloud configuration. Finally, we propose a new algorithm for solving multi-cloud configuration, CloudBandit (CB). It treats the outer problem of cloud provider selection as a best-arm identification problem, in which each arm pull corresponds to running an arbitrary black-box optimizer on the inner problem of node configuration. Our experiments indicate that (a) many state-of-the-art cloud configuration solutions can be adapted to multi-cloud, with best results obtained for adaptations which utilize the hierarchical structure of the multi-cloud configuration domain, (b) hierarchical methods from AutoML can be used for the multi-cloud configuration task and can outperform state-of-the-art cloud configuration solutions and (c) CB achieves competitive or lower regret relative to other tested algorithms, whilst also identifying configurations that have 65% lower median cost and 20% lower median time in production, compared to choosing a random provider and configuration.
A Lower-bound for Variable-length Source Coding in LQG Feedback Control
Mar 31, 2022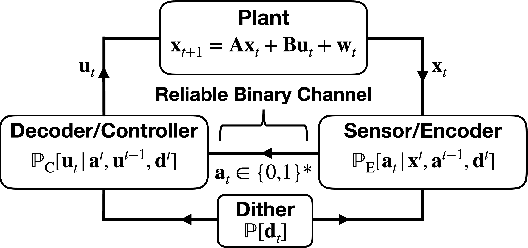
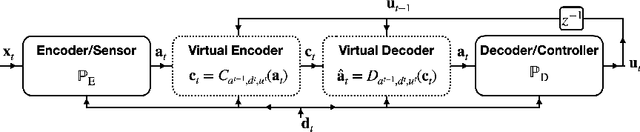
In this letter, we consider a Linear Quadratic Gaussian (LQG) control system where feedback occurs over a noiseless binary channel and derive lower bounds on the minimum communication cost (quantified via the channel bitrate) required to attain a given control performance. We assume that at every time step an encoder can convey a packet containing a variable number of bits over the channel to a decoder at the controller. Our system model provides for the possibility that the encoder and decoder have shared randomness, as is the case in systems using dithered quantizers. We define two extremal prefix-free requirements that may be imposed on the message packets; such constraints are useful in that they allow the decoder, and potentially other agents to uniquely identify the end of a transmission in an online fashion. We then derive a lower bound on the rate of prefix-free coding in terms of directed information; in particular we show that a previously known bound still holds in the case with shared randomness. We also provide a generalization of the bound that applies if prefix-free requirements are relaxed. We conclude with a rate-distortion formulation.
Monocular Real-time Full Body Capture with Inter-part Correlations
Dec 11, 2020
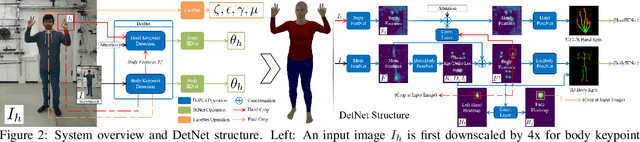
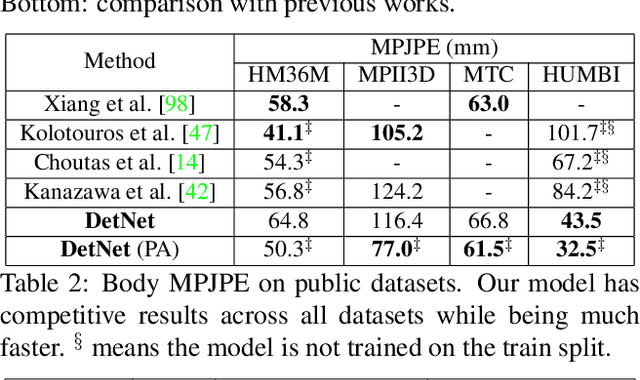
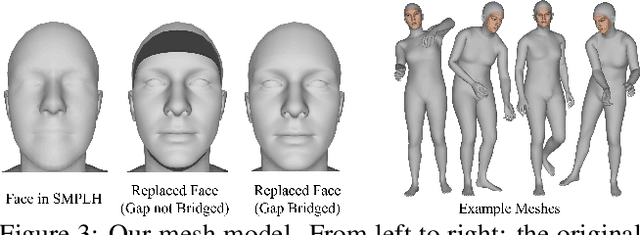
We present the first method for real-time full body capture that estimates shape and motion of body and hands together with a dynamic 3D face model from a single color image. Our approach uses a new neural network architecture that exploits correlations between body and hands at high computational efficiency. Unlike previous works, our approach is jointly trained on multiple datasets focusing on hand, body or face separately, without requiring data where all the parts are annotated at the same time, which is much more difficult to create at sufficient variety. The possibility of such multi-dataset training enables superior generalization ability. In contrast to earlier monocular full body methods, our approach captures more expressive 3D face geometry and color by estimating the shape, expression, albedo and illumination parameters of a statistical face model. Our method achieves competitive accuracy on public benchmarks, while being significantly faster and providing more complete face reconstructions.
Neural Q-learning for solving elliptic PDEs
Mar 31, 2022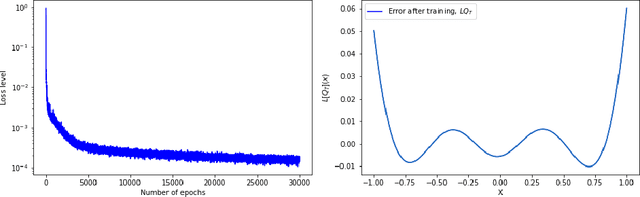
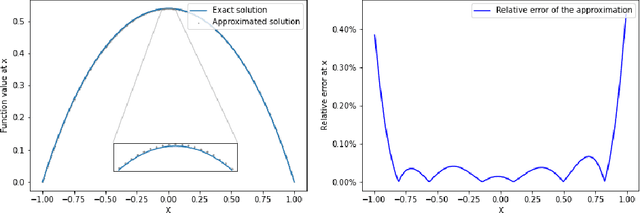
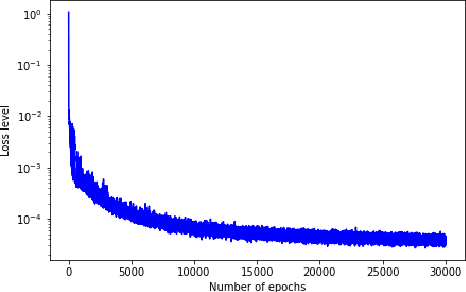
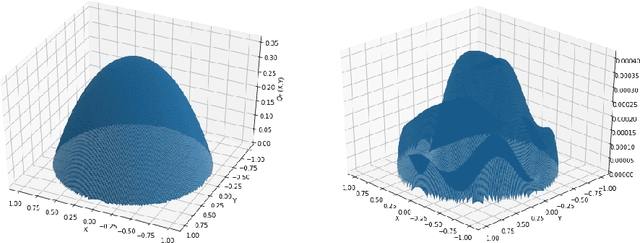
Solving high-dimensional partial differential equations (PDEs) is a major challenge in scientific computing. We develop a new numerical method for solving elliptic-type PDEs by adapting the Q-learning algorithm in reinforcement learning. Our "Q-PDE" algorithm is mesh-free and therefore has the potential to overcome the curse of dimensionality. Using a neural tangent kernel (NTK) approach, we prove that the neural network approximator for the PDE solution, trained with the Q-PDE algorithm, converges to the trajectory of an infinite-dimensional ordinary differential equation (ODE) as the number of hidden units $\rightarrow \infty$. For monotone PDE (i.e. those given by monotone operators, which may be nonlinear), despite the lack of a spectral gap in the NTK, we then prove that the limit neural network, which satisfies the infinite-dimensional ODE, converges in $L^2$ to the PDE solution as the training time $\rightarrow \infty$. More generally, we can prove that any fixed point of the wide-network limit for the Q-PDE algorithm is a solution of the PDE (not necessarily under the monotone condition). The numerical performance of the Q-PDE algorithm is studied for several elliptic PDEs.
Image analysis for automatic measurement of crustose lichens
Mar 01, 2022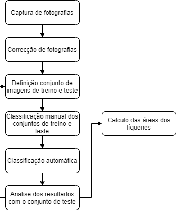
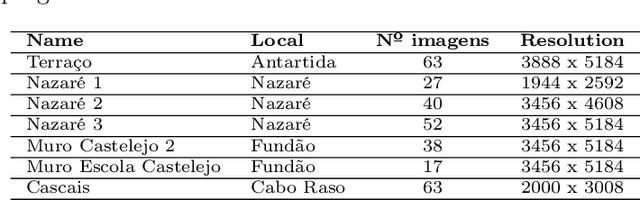


Lichens, organisms resulting from a symbiosis between a fungus and an algae, are frequently used as age estimators, especially in recent geological deposits and archaeological structures, using the correlation between lichen size and age. Current non-automated manual lichen and measurement (with ruler, calipers or using digital image processing tools) is a time-consuming and laborious process, especially when the number of samples is high. This work presents a workflow and set of image acquisition and processing tools developed to efficiently identify lichen thalli in flat rocky surfaces, and to produce relevant lichen size statistics (percentage cover, number of thalli, their area and perimeter). The developed workflow uses a regular digital camera for image capture along with specially designed targets to allow for automatic image correction and scale assignment. After this step, lichen identification is done in a flow comprising assisted image segmentation and classification based on interactive foreground extraction tool (GrabCut) and automatic classification of images using Simple Linear Iterative Clustering (SLIC) for image segmentation and Support Vector Machines (SV) and Random Forest classifiers. Initial evaluation shows promising results. The manual classification of images (for training) using GrabCut show an average speedup of 4 if compared with currently used techniques and presents an average precision of 95\%. The automatic classification using SLIC and SVM with default parameters produces results with average precision higher than 70\%. The developed system is flexible and allows a considerable reduction of processing time, the workflow allows it applicability to data sets of new lichen populations.
The Group Loss++: A deeper look into group loss for deep metric learning
Apr 04, 2022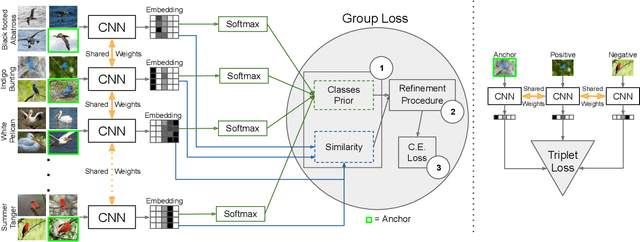
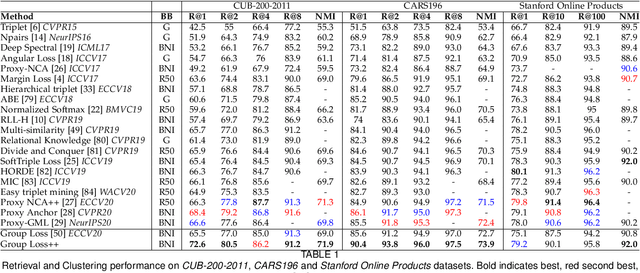
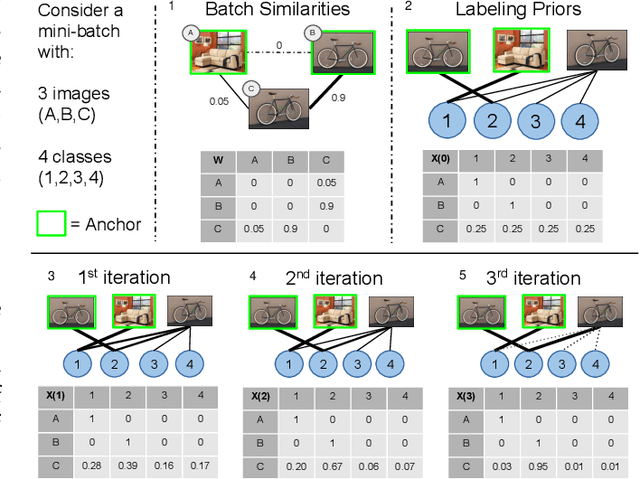
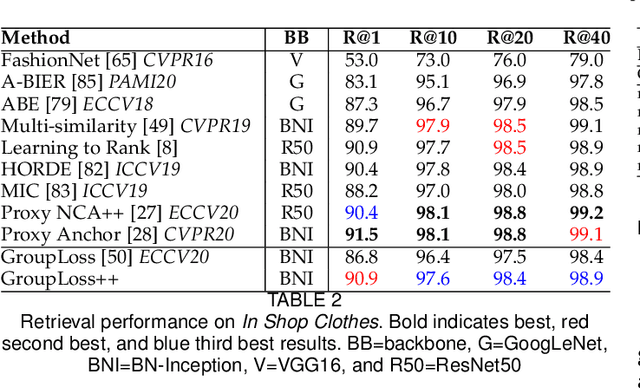
Deep metric learning has yielded impressive results in tasks such as clustering and image retrieval by leveraging neural networks to obtain highly discriminative feature embeddings, which can be used to group samples into different classes. Much research has been devoted to the design of smart loss functions or data mining strategies for training such networks. Most methods consider only pairs or triplets of samples within a mini-batch to compute the loss function, which is commonly based on the distance between embeddings. We propose Group Loss, a loss function based on a differentiable label-propagation method that enforces embedding similarity across all samples of a group while promoting, at the same time, low-density regions amongst data points belonging to different groups. Guided by the smoothness assumption that "similar objects should belong to the same group", the proposed loss trains the neural network for a classification task, enforcing a consistent labelling amongst samples within a class. We design a set of inference strategies tailored towards our algorithm, named Group Loss++ that further improve the results of our model. We show state-of-the-art results on clustering and image retrieval on four retrieval datasets, and present competitive results on two person re-identification datasets, providing a unified framework for retrieval and re-identification.
Interactive Object Segmentation in 3D Point Clouds
Apr 14, 2022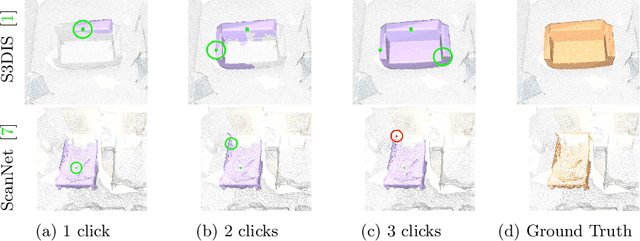
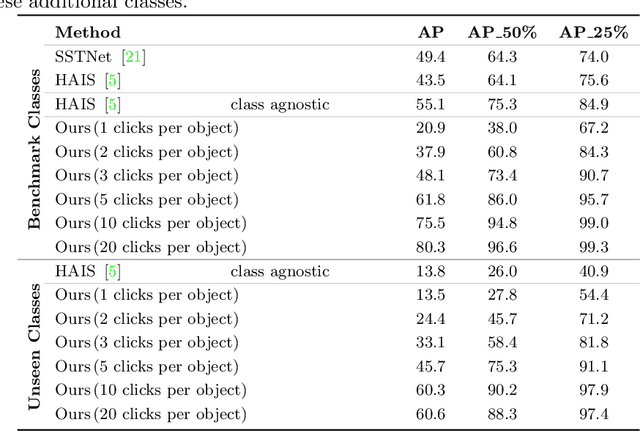
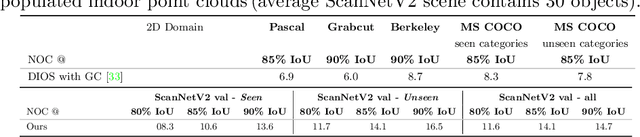
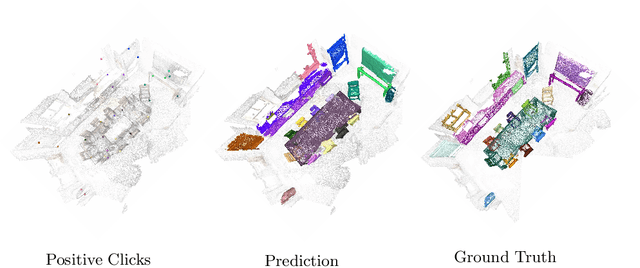
Deep learning depends on large amounts of labeled training data. Manual labeling is expensive and represents a bottleneck, especially for tasks such as segmentation, where labels must be assigned down to the level of individual points. That challenge is even more daunting for 3D data: 3D point clouds contain millions of points per scene, and their accurate annotation is markedly more time-consuming. The situation is further aggravated by the added complexity of user interfaces for 3D point clouds, which slows down annotation even more. For the case of 2D image segmentation, interactive techniques have become common, where user feedback in the form of a few clicks guides a segmentation algorithm -- nowadays usually a neural network -- to achieve an accurate labeling with minimal effort. Surprisingly, interactive segmentation of 3D scenes has not been explored much. Previous work has attempted to obtain accurate 3D segmentation masks using human feedback from the 2D domain, which is only possible if correctly aligned images are available together with the 3D point cloud, and it involves switching between the 2D and 3D domains. Here, we present an interactive 3D object segmentation method in which the user interacts directly with the 3D point cloud. Importantly, our model does not require training data from the target domain: when trained on ScanNet, it performs well on several other datasets with different data characteristics as well as different object classes. Moreover, our method is orthogonal to supervised (instance) segmentation methods and can be combined with them to refine automatic segmentations with minimal human effort.