 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Race Driver Evaluation at a Driving Simulator using a physical Model and a Machine Learning Approach
Jan 27, 2022
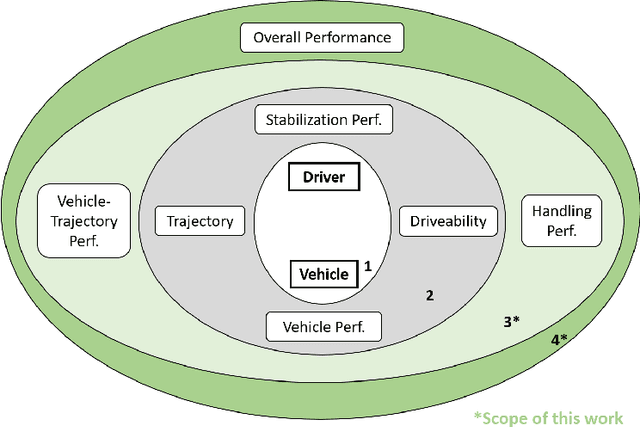
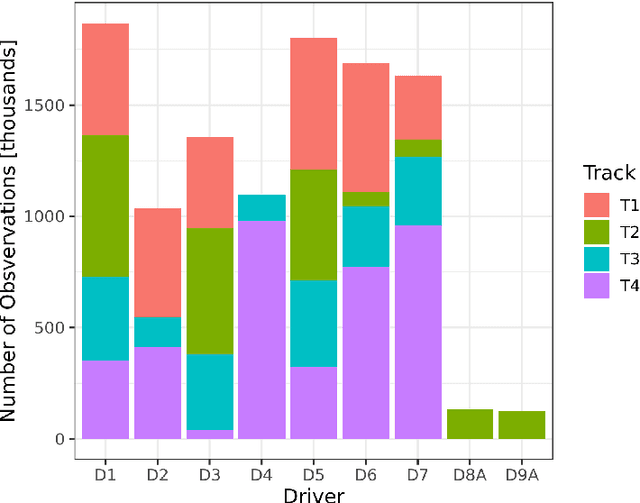
Professional race drivers are still superior to automated systems at controlling a vehicle at its dynamic limit. Gaining insight into race drivers' vehicle handling process might lead to further development in the areas of automated driving systems. We present a method to study and evaluate race drivers on a driver-in-the-loop simulator by analysing tire grip potential exploitation. Given initial data from a simulator run, two optimiser based on physical models maximise the horizontal vehicle acceleration or the tire forces, respectively. An overall performance score, a vehicle-trajectory score and a handling score are introduced to evaluate drivers. Our method is thereby completely track independent and can be used from one single corner up to a large data set. We apply the proposed method to a motorsport data set containing over 1200 laps from seven professional race drivers and two amateur drivers whose lap times are 10-20% slower. The difference to the professional drivers comes mainly from their inferior handling skills and not their choice of driving line. A downside of the presented method for certain applications is an extensive computation time. Therefore, we propose a Long-short-term memory (LSTM) neural network to estimate the driver evaluation scores. We show that the neural network is accurate and robust with a root-mean-square error between 2-5% and can replace the optimisation based method. The time for processing the data set considered in this work is reduced from 68 hours to 12 seconds, making the neural network suitable for real-time application.
Learning Expanding Graphs for Signal Interpolation
Mar 15, 2022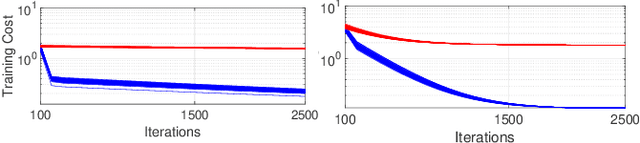
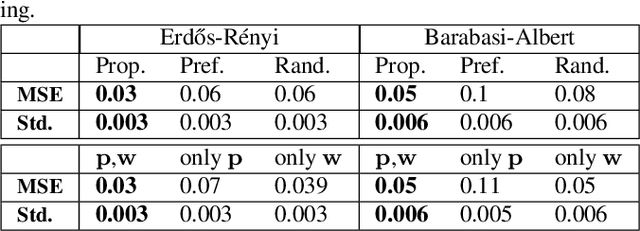
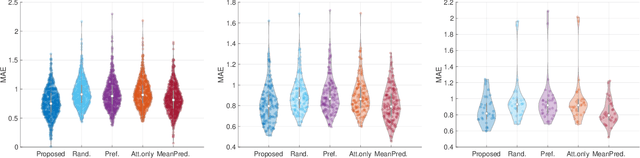
Performing signal processing over graphs requires knowledge of the underlying fixed topology. However, graphs often grow in size with new nodes appearing over time, whose connectivity is typically unknown; hence, making more challenging the downstream tasks in applications like cold start recommendation. We address such a challenge for signal interpolation at the incoming nodes blind to the topological connectivity of the specific node. Specifically, we propose a stochastic attachment model for incoming nodes parameterized by the attachment probabilities and edge weights. We estimate these parameters in a data-driven fashion by relying only on the attachment behaviour of earlier incoming nodes with the goal of interpolating the signal value. We study the non-convexity of the problem at hand, derive conditions when it can be marginally convexified, and propose an alternating projected descent approach between estimating the attachment probabilities and the edge weights. Numerical experiments with synthetic and real data dealing in cold start collaborative filtering corroborate our findings.
Extending MAPE-K to support Human-Machine Teaming
Mar 24, 2022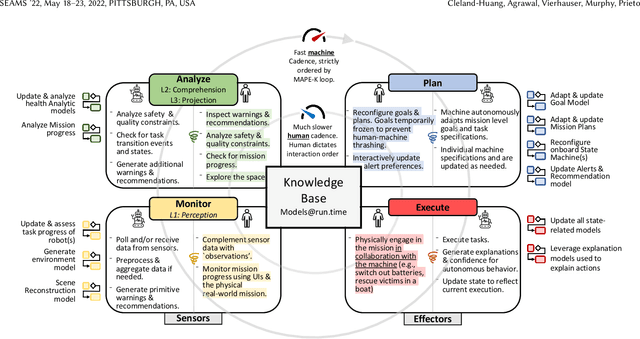
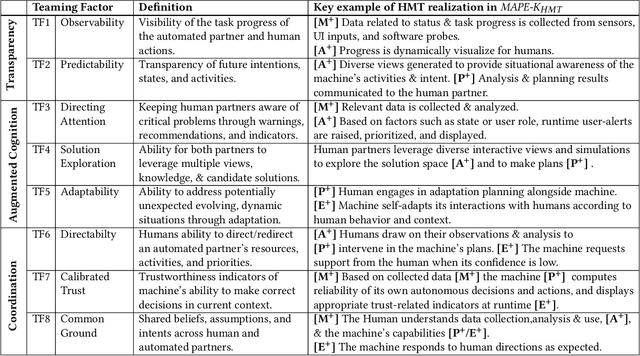
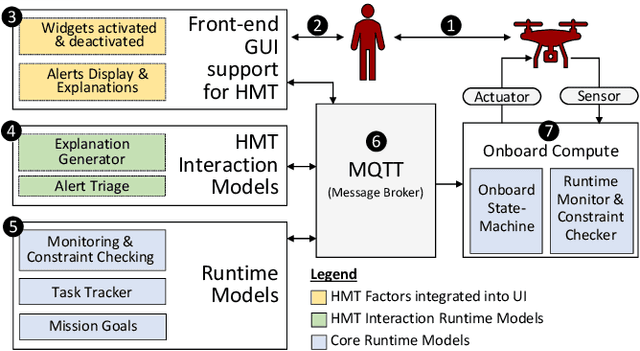

The MAPE-K feedback loop has been established as the primary reference model for self-adaptive and autonomous systems in domains such as autonomous driving, robotics, and Cyber-Physical Systems. At the same time, the Human Machine Teaming (HMT) paradigm is designed to promote partnerships between humans and autonomous machines. It goes far beyond the degree of collaboration expected in human-on-the-loop and human-in-the-loop systems and emphasizes interactions, partnership, and teamwork between humans and machines. However, while MAPE-K enables fully autonomous behavior, it does not explicitly address the interactions between humans and machines as intended by HMT. In this paper, we present the MAPE-K-HMT framework which augments the traditional MAPE-K loop with support for HMT. We identify critical human-machine teaming factors and describe the infrastructure needed across the various phases of the MAPE-K loop in order to effectively support HMT. This includes runtime models that are constructed and populated dynamically across monitoring, analysis, planning, and execution phases to support human-machine partnerships. We illustrate MAPE-K-HMT using examples from an autonomous multi-UAV emergency response system, and present guidelines for integrating HMT into MAPE-K.
AI-augmented histopathologic review using image analysis to optimize DNA yield and tumor purity from FFPE slides
Apr 07, 2022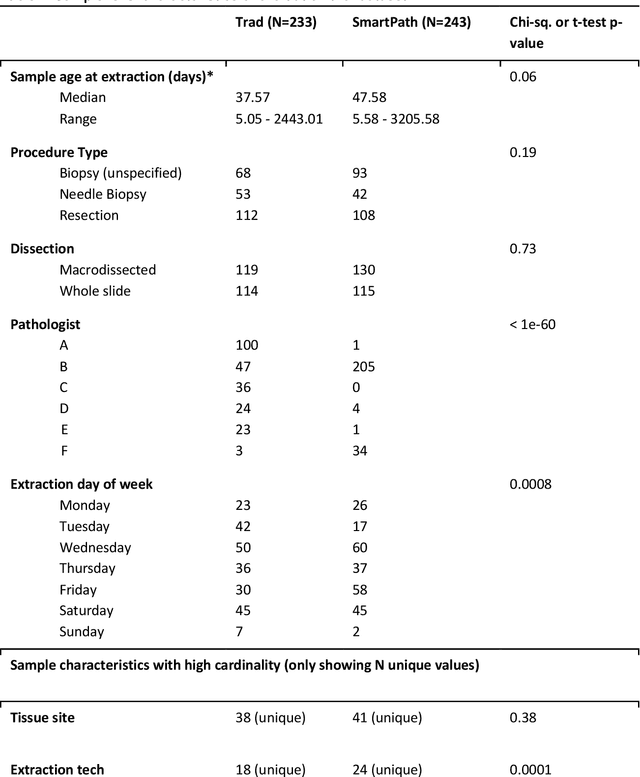
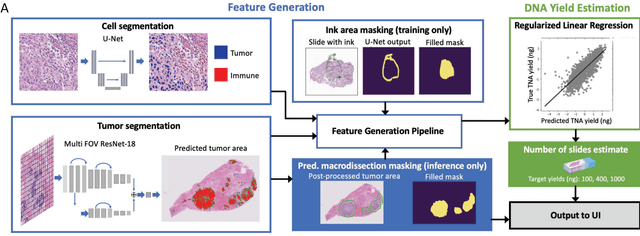
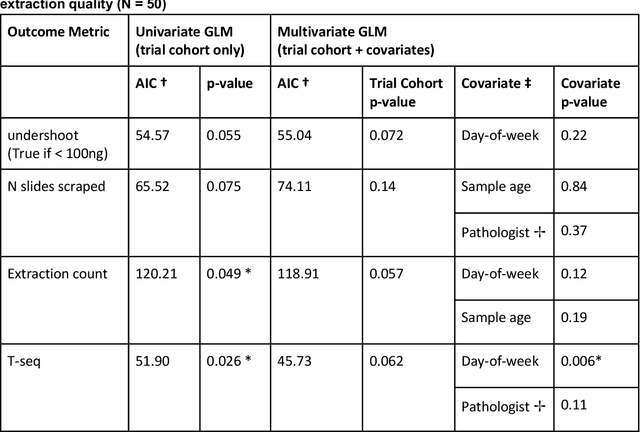
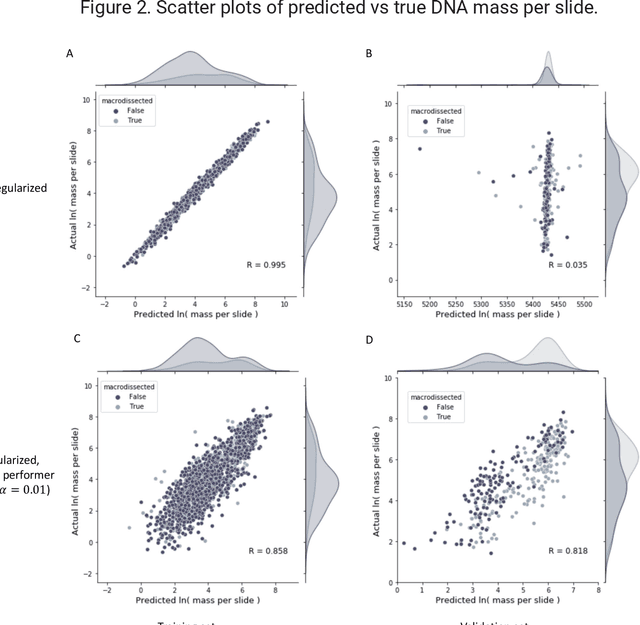
To achieve minimum DNA input and tumor purity requirements for next-generation sequencing (NGS), pathologists visually estimate macrodissection and slide count decisions. Misestimation may cause tissue waste and increased laboratory costs. We developed an AI-augmented smart pathology review system (SmartPath) to empower pathologists with quantitative metrics for determining tissue extraction parameters. Using digitized H&E-stained FFPE slides as inputs, SmartPath segments tumors, extracts cell-based features, and suggests macrodissection areas. To predict DNA yield per slide, the extracted features are correlated with known DNA yields. Then, a pathologist-defined target yield divided by the predicted DNA yield/slide gives the number of slides to scrape. Following model development, an internal validation trial was conducted within the Tempus Labs molecular sequencing laboratory. We evaluated our system on 501 clinical colorectal cancer slides, where half received SmartPath-augmented review and half traditional pathologist review. The SmartPath cohort had 25% more DNA yields within a desired target range of 100-2000ng. The SmartPath system recommended fewer slides to scrape for large tissue sections, saving tissue in these cases. Conversely, SmartPath recommended more slides to scrape for samples with scant tissue sections, helping prevent costly re-extraction due to insufficient extraction yield. A statistical analysis was performed to measure the impact of covariates on the results, offering insights on how to improve future applications of SmartPath. Overall, the study demonstrated that AI-augmented histopathologic review using SmartPath could decrease tissue waste, sequencing time, and laboratory costs by optimizing DNA yields and tumor purity.
Hierarchical Sketch Induction for Paraphrase Generation
Mar 07, 2022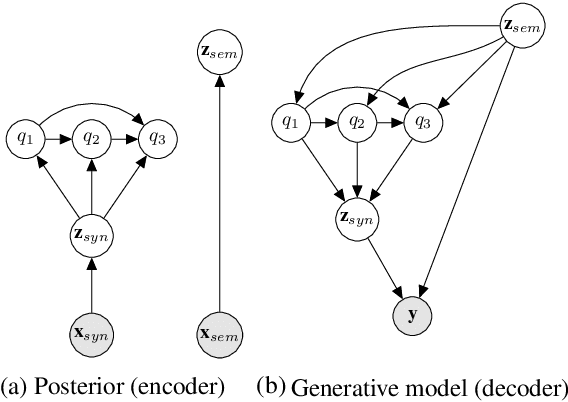
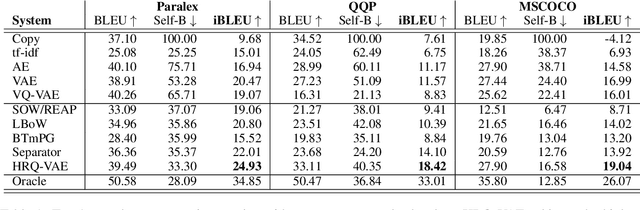
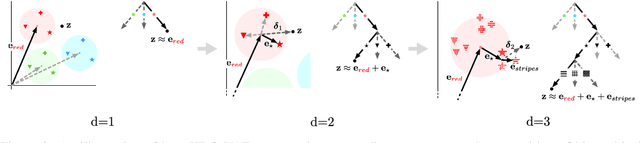

We propose a generative model of paraphrase generation, that encourages syntactic diversity by conditioning on an explicit syntactic sketch. We introduce Hierarchical Refinement Quantized Variational Autoencoders (HRQ-VAE), a method for learning decompositions of dense encodings as a sequence of discrete latent variables that make iterative refinements of increasing granularity. This hierarchy of codes is learned through end-to-end training, and represents fine-to-coarse grained information about the input. We use HRQ-VAE to encode the syntactic form of an input sentence as a path through the hierarchy, allowing us to more easily predict syntactic sketches at test time. Extensive experiments, including a human evaluation, confirm that HRQ-VAE learns a hierarchical representation of the input space, and generates paraphrases of higher quality than previous systems.
A Survey on Principles, Models and Methods for Learning from Irregularly Sampled Time Series
Jan 05, 2021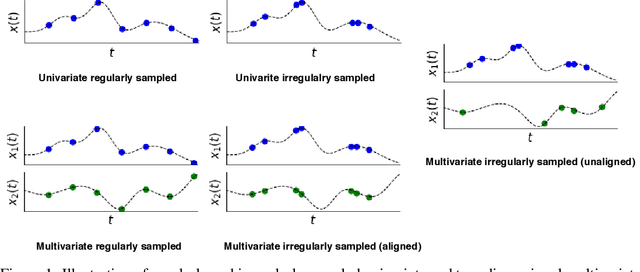
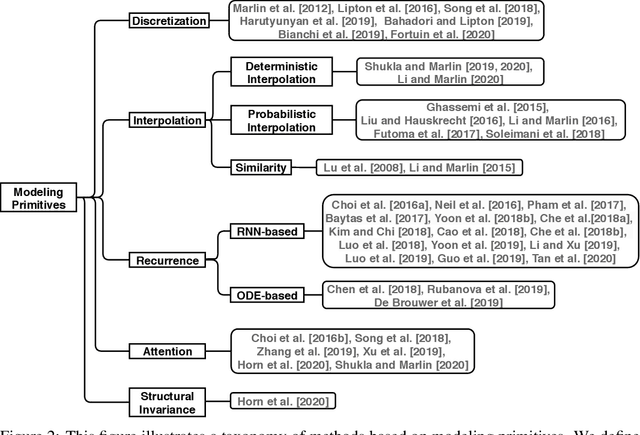
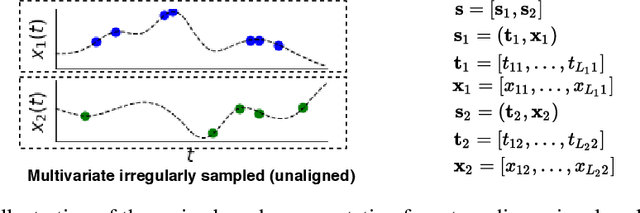
Irregularly sampled time series data arise naturally in many application domains including biology, ecology, climate science, astronomy, and health. Such data represent fundamental challenges to many classical models from machine learning and statistics due to the presence of non-uniform intervals between observations. However, there has been significant progress within the machine learning community over the last decade on developing specialized models and architectures for learning from irregularly sampled univariate and multivariate time series data. In this survey, we first describe several axes along which approaches to learning from irregularly sampled time series differ including what data representations they are based on, what modeling primitives they leverage to deal with the fundamental problem of irregular sampling, and what inference tasks they are designed to perform. We then survey the recent literature organized primarily along the axis of modeling primitives. We describe approaches based on temporal discretization, interpolation, recurrence, attention and structural invariance. We discuss similarities and differences between approaches and highlight primary strengths and weaknesses.
Roomsemble: Progressive web application for intuitive property search
Feb 15, 2022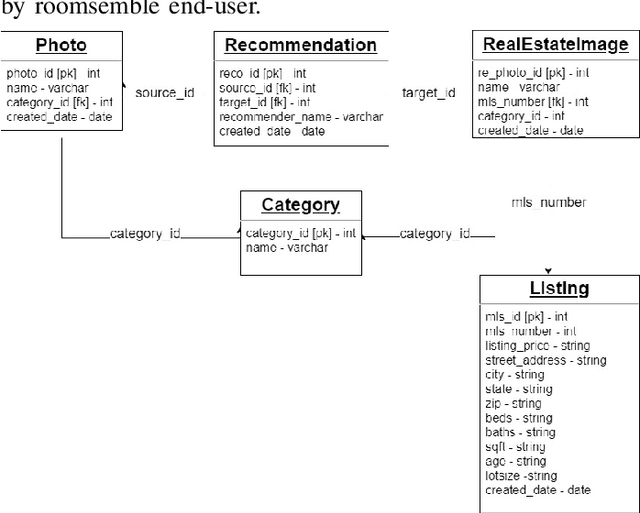

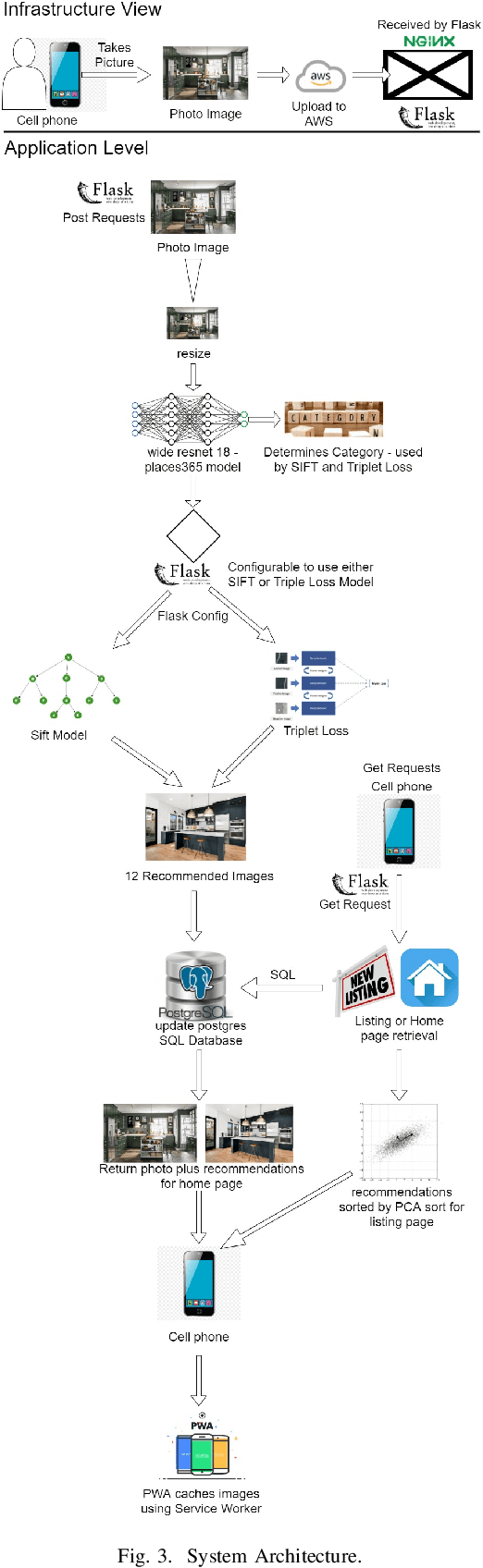
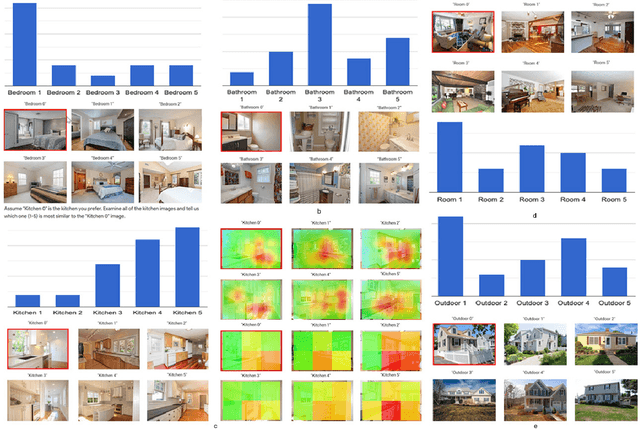
A successful real estate search process involves locating a property that meets a user's search criteria subject to an allocated budget and time constraints. Many studies have investigated modeling housing prices over time. However, little is known about how a user's tastes influence their real estate search and purchase decisions. It is unknown what house a user would choose taking into account an individual's personal tastes, behaviors, and constraints, and, therefore, creating an algorithm that finds the perfect match. In this paper, we investigate the first step in understanding a user's tastes by building a system to capture personal preferences. We concentrated our research on real estate photos, being inspired by house aesthetics, which often motivates prospective buyers into considering a property as a candidate for purchase. We designed a system that takes a user-provided photo representing that person's personal taste and recommends properties similar to the photo available on the market. The user can additionally filter the recommendations by budget and location when conducting a property search. The paper describes the application's overall layout including frontend design and backend processes for locating a desired property. The proposed model, which serves as the application's core, was tested with 25 users, and the study's findings, as well as some key conclusions, are detailed in this paper.
Distribution Agnostic Symbolic Representations for Time Series Dimensionality Reduction and Online Anomaly Detection
May 20, 2021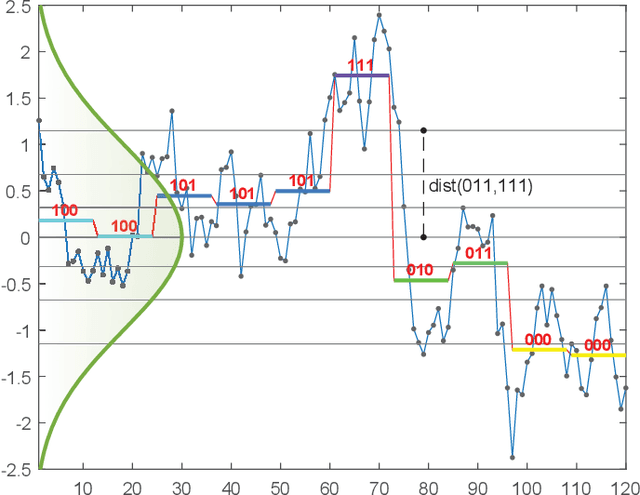
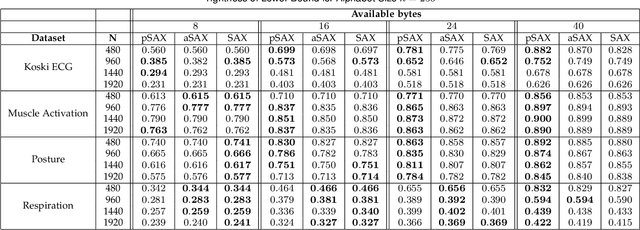
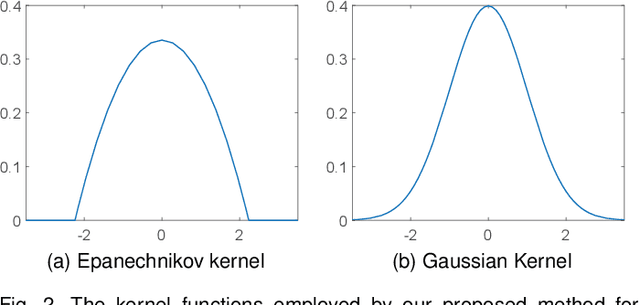
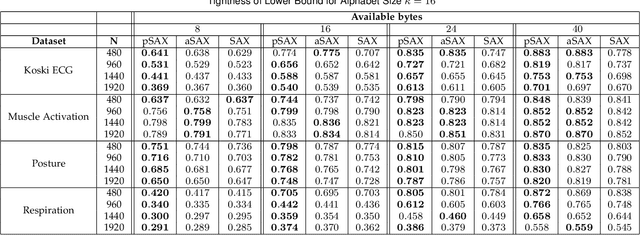
Due to the importance of the lower bounding distances and the attractiveness of symbolic representations, the family of symbolic aggregate approximations (SAX) has been used extensively for encoding time series data. However, typical SAX-based methods rely on two restrictive assumptions; the Gaussian distribution and equiprobable symbols. This paper proposes two novel data-driven SAX-based symbolic representations, distinguished by their discretization steps. The first representation, oriented for general data compaction and indexing scenarios, is based on the combination of kernel density estimation and Lloyd-Max quantization to minimize the information loss and mean squared error in the discretization step. The second method, oriented for high-level mining tasks, employs the Mean-Shift clustering method and is shown to enhance anomaly detection in the lower-dimensional space. Besides, we verify on a theoretical basis a previously observed phenomenon of the intrinsic process that results in a lower than the expected variance of the intermediate piecewise aggregate approximation. This phenomenon causes an additional information loss but can be avoided with a simple modification. The proposed representations possess all the attractive properties of the conventional SAX method. Furthermore, experimental evaluation on real-world datasets demonstrates their superiority compared to the traditional SAX and an alternative data-driven SAX variant.
Visual-Tactile Multimodality for Following Deformable Linear Objects Using Reinforcement Learning
Mar 31, 2022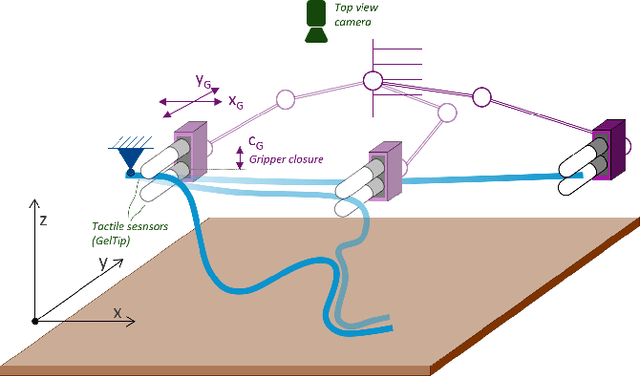
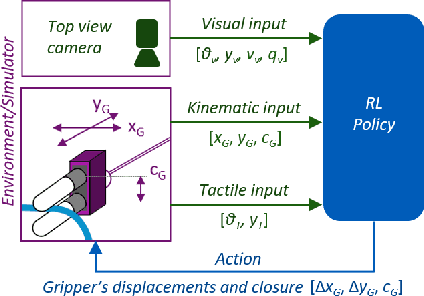
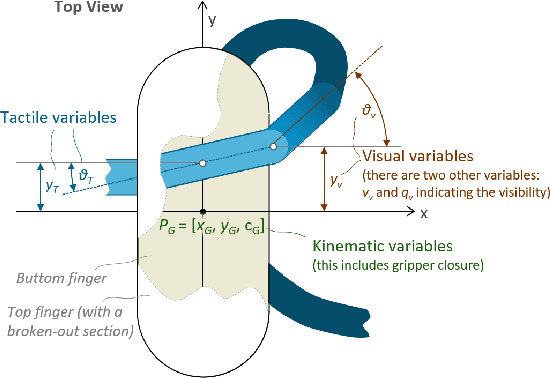

Manipulation of deformable objects is a challenging task for a robot. It will be problematic to use a single sensory input to track the behaviour of such objects: vision can be subjected to occlusions, whereas tactile inputs cannot capture the global information that is useful for the task. In this paper, we study the problem of using vision and tactile inputs together to complete the task of following deformable linear objects, for the first time. We create a Reinforcement Learning agent using different sensing modalities and investigate how its behaviour can be boosted using visual-tactile fusion, compared to using a single sensing modality. To this end, we developed a benchmark in simulation for manipulating the deformable linear objects using multimodal sensing inputs. The policy of the agent uses distilled information, e.g., the pose of the object in both visual and tactile perspectives, instead of the raw sensing signals, so that it can be directly transferred to real environments. In this way, we disentangle the perception system and the learned control policy. Our extensive experiments show that the use of both vision and tactile inputs, together with proprioception, allows the agent to complete the task in up to 92% of cases, compared to 77% when only one of the signals is given. Our results can provide valuable insights for the future design of tactile sensors and for deformable objects manipulation.
PAC-Bayesian Lifelong Learning For Multi-Armed Bandits
Mar 07, 2022
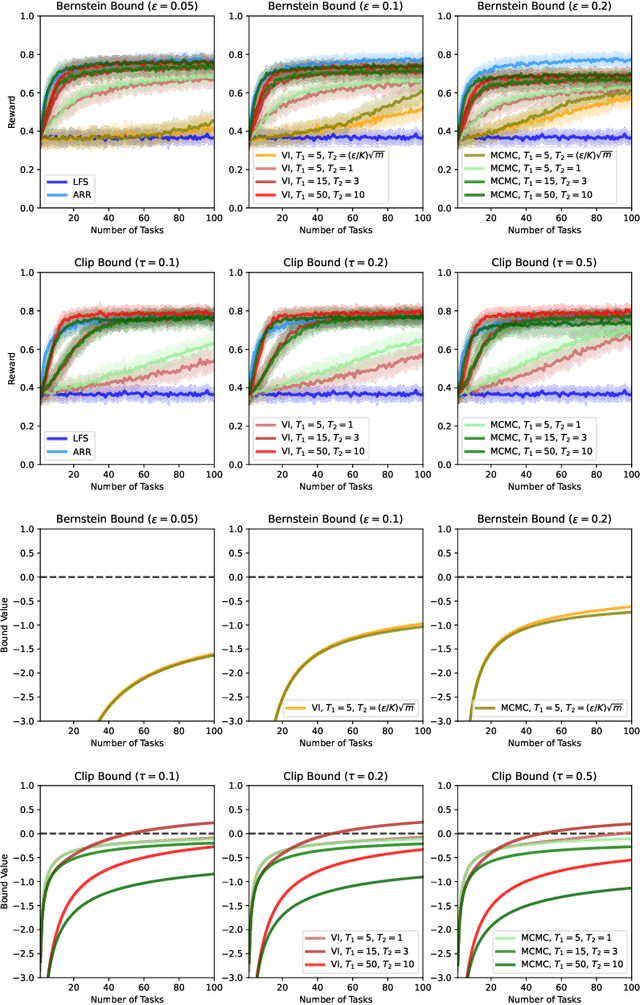
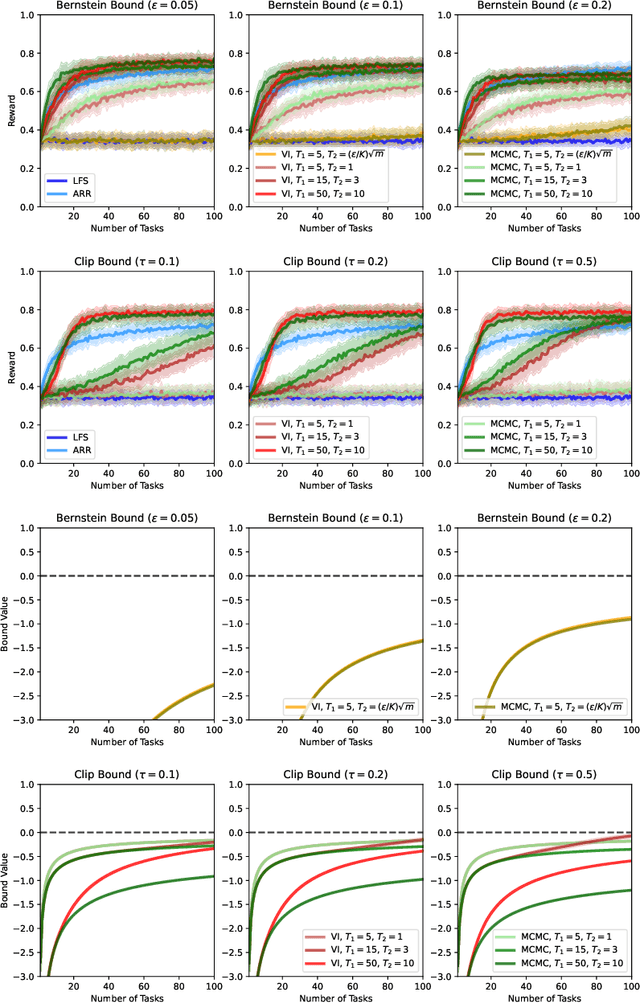
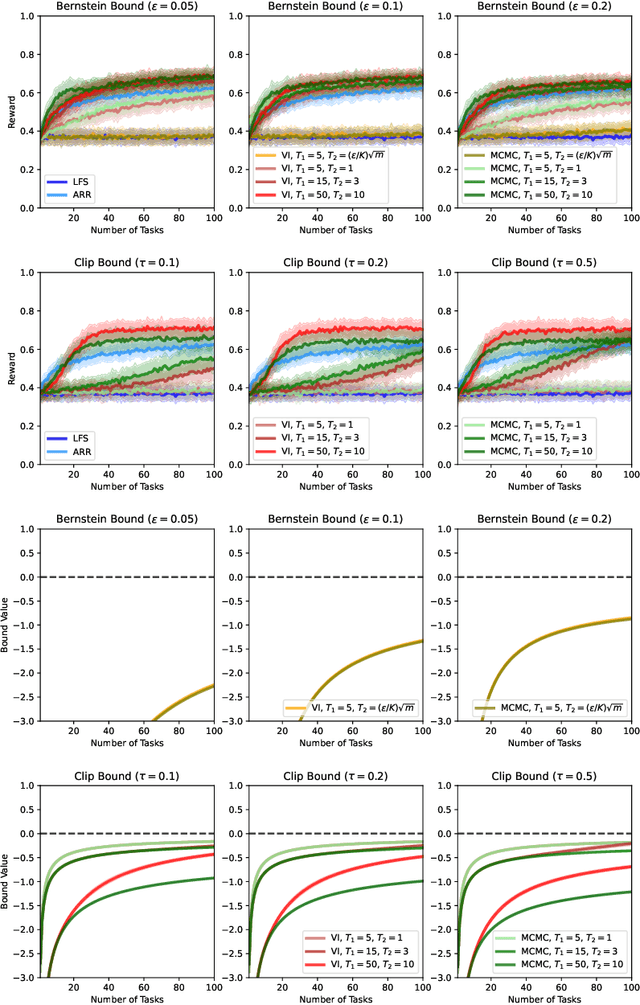
We present a PAC-Bayesian analysis of lifelong learning. In the lifelong learning problem, a sequence of learning tasks is observed one-at-a-time, and the goal is to transfer information acquired from previous tasks to new learning tasks. We consider the case when each learning task is a multi-armed bandit problem. We derive lower bounds on the expected average reward that would be obtained if a given multi-armed bandit algorithm was run in a new task with a particular prior and for a set number of steps. We propose lifelong learning algorithms that use our new bounds as learning objectives. Our proposed algorithms are evaluated in several lifelong multi-armed bandit problems and are found to perform better than a baseline method that does not use generalisation bounds.
* 29 pages, 5 figures