 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Non-Parametric Stochastic Policy Gradient with Strategic Retreat for Non-Stationary Environment
Mar 24, 2022
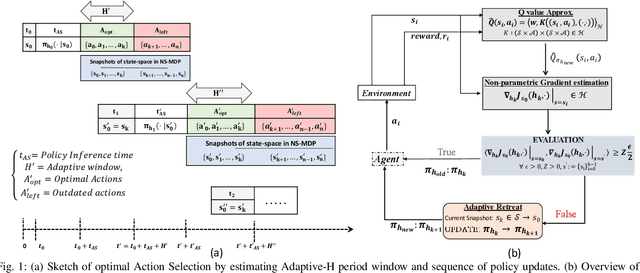
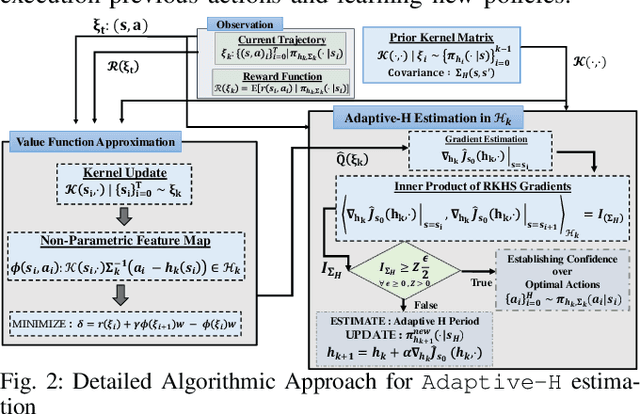
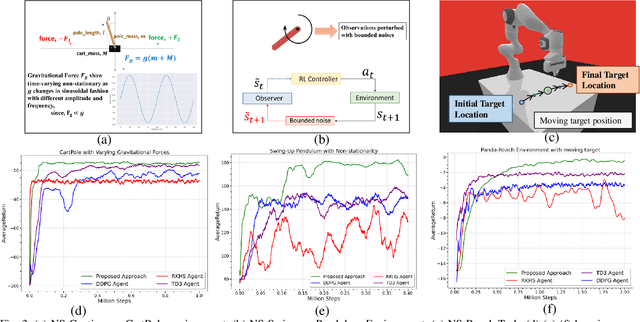

In modern robotics, effectively computing optimal control policies under dynamically varying environments poses substantial challenges to the off-the-shelf parametric policy gradient methods, such as the Deep Deterministic Policy Gradient (DDPG) and Twin Delayed Deep Deterministic policy gradient (TD3). In this paper, we propose a systematic methodology to dynamically learn a sequence of optimal control policies non-parametrically, while autonomously adapting with the constantly changing environment dynamics. Specifically, our non-parametric kernel-based methodology embeds a policy distribution as the features in a non-decreasing Euclidean space, therefore allowing its search space to be defined as a very high (possible infinite) dimensional RKHS (Reproducing Kernel Hilbert Space). Moreover, by leveraging the similarity metric computed in RKHS, we augmented our non-parametric learning with the technique of AdaptiveH- adaptively selecting a time-frame window of finishing the optimal part of whole action-sequence sampled on some preceding observed state. To validate our proposed approach, we conducted extensive experiments with multiple classic benchmarks and one simulated robotics benchmark equipped with dynamically changing environments. Overall, our methodology has outperformed the well-established DDPG and TD3 methodology by a sizeable margin in terms of learning performance.
A Novel Anomaly Detection Method for Multimodal WSN Data Flow via a Dynamic Graph Neural Network
Feb 19, 2022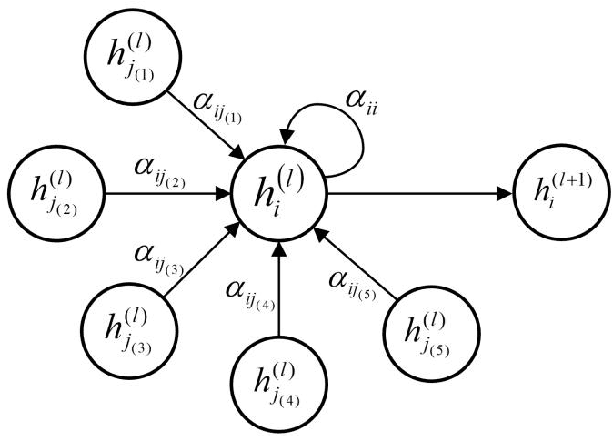

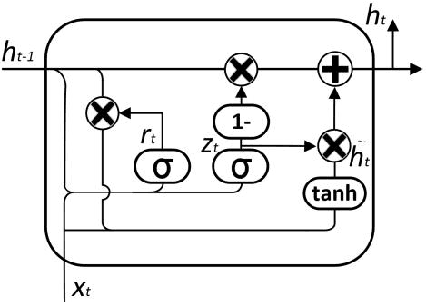
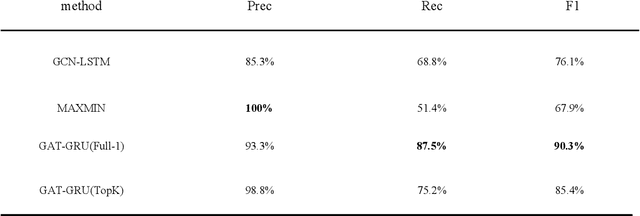
Anomaly detection is widely used to distinguish system anomalies by analyzing the temporal and spatial features of wireless sensor network (WSN) data streams; it is one of critical technique that ensures the reliability of WSNs. Currently, graph neural networks (GNNs) have become popular state-of-the-art methods for conducting anomaly detection on WSN data streams. However, the existing anomaly detection methods based on GNNs do not consider the temporal and spatial features of WSN data streams simultaneously, such as multi-node, multi-modal and multi-time features, seriously impacting their effectiveness. In this paper, a novel anomaly detection model is proposed for multimodal WSN data flows, where three GNNs are used to separately extract the temporal features of WSN data flows, the correlation features between different modes and the spatial features between sensor node positions. Specifically, first, the temporal features and modal correlation features extracted from each sensor node are fused into one vector representation, which is further aggregated with the spatial features, i.e., the spatial position relationships of the nodes; finally, the current time-series data of WSN nodes are predicted, and abnormal states are identified according to the fusion features. The simulation results obtained on a public dataset show that the proposed approach is able to significantly improve upon the existing methods in terms of its robustness, and its F1 score reaches 0.90, which is 14.2% higher than that of the graph convolution network (GCN) with long short-term memory (LSTM).
Time-Scale-Chirp_rate Operator for Recovery of Non-stationary Signal Components with Crossover Instantaneous Frequency Curves
Dec 27, 2020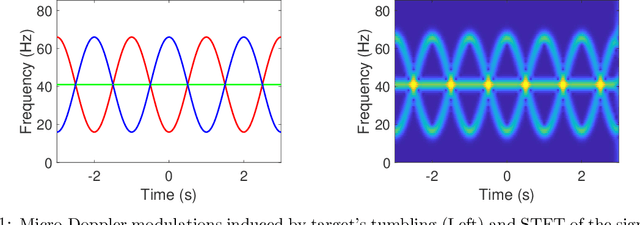
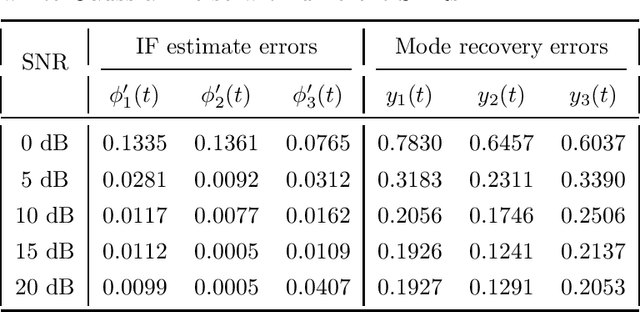
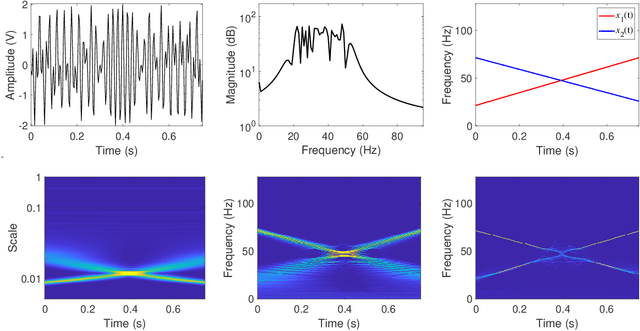
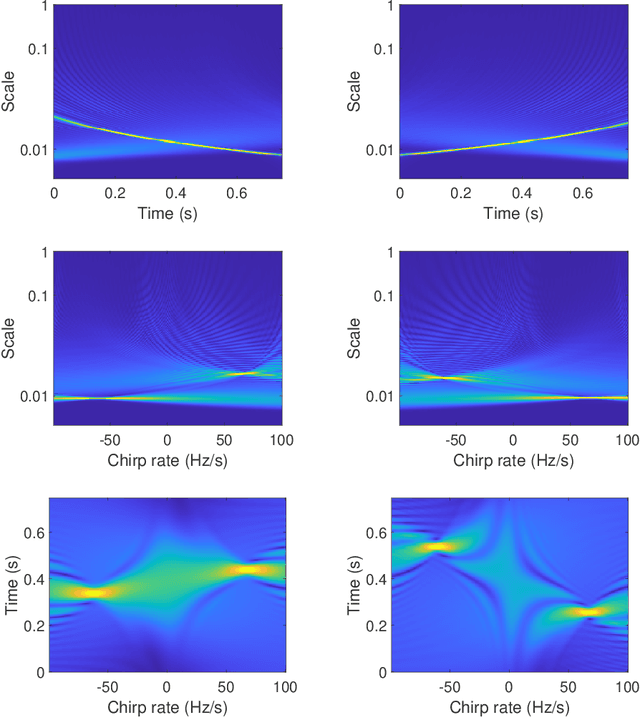
The objective of this paper is to introduce an innovative approach for the recovery of non-stationary signal components with possibly cross-over instantaneous frequency (IF) curves from a multi-component blind-source signal. The main idea is to incorporate a chirp rate parameter with the time-scale continuous wavelet-like transformation, by considering the quadratic phase representation of the signal components. Hence-forth, even if two IF curves cross, the two corresponding signal components can still be separated and recovered, provided that their chirp rates are different. In other words, signal components with the same IF value at any time instant could still be recovered. To facilitate our presentation, we introduce the notion of time-scale-chirp_rate (TSC-R) recovery transform or TSC-R recovery operator to develop a TSC-R theory for the 3-dimensional space of time, scale, chirp rate. Our theoretical development is based on the approximation of the non-stationary signal components with linear chirps and applying the proposed adaptive TSC-R transform to the multi-component blind-source signal to obtain fairly accurate error bounds of IF estimations and signal components recovery. Several numerical experimental results are presented to demonstrate the out-performance of the proposed method over all existing time-frequency and time-scale approaches in the published literature, particularly for non-stationary source signals with crossover IFs.
Towards a Perceptual Model for Estimating the Quality of Visual Speech
Mar 24, 2022
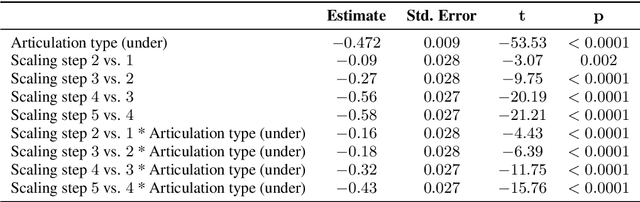
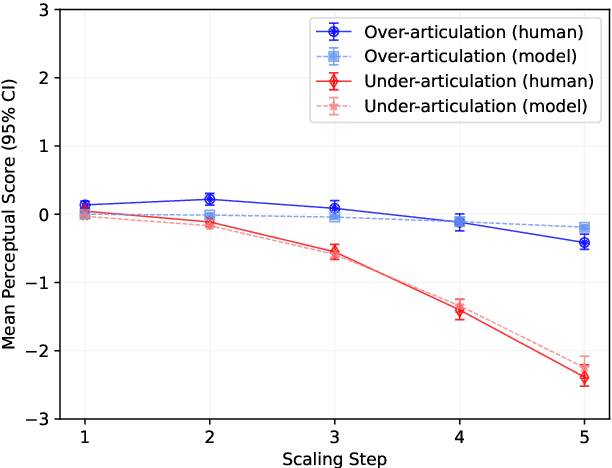
Generating realistic lip motions to simulate speech production is key for driving natural character animations from audio. Previous research has shown that traditional metrics used to optimize and assess models for generating lip motions from speech are not a good indicator of subjective opinion of animation quality. Yet, running repetitive subjective studies for assessing the quality of animations can be time-consuming and difficult to replicate. In this work, we seek to understand the relationship between perturbed lip motion and subjective opinion of lip motion quality. Specifically, we adjust the degree of articulation for lip motion sequences and run a user-study to examine how this adjustment impacts the perceived quality of lip motion. We then train a model using the scores collected from our user-study to automatically predict the subjective quality of an animated sequence. Our results show that (1) users score lip motions with slight over-articulation the highest in terms of perceptual quality; (2) under-articulation had a more detrimental effect on perceived quality of lip motion compared to the effect of over-articulation; and (3) we can automatically estimate the subjective perceptual score for a given lip motion sequences with low error rates.
Learning via nonlinear conjugate gradients and depth-varying neural ODEs
Feb 11, 2022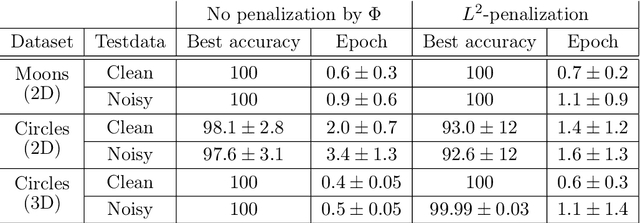
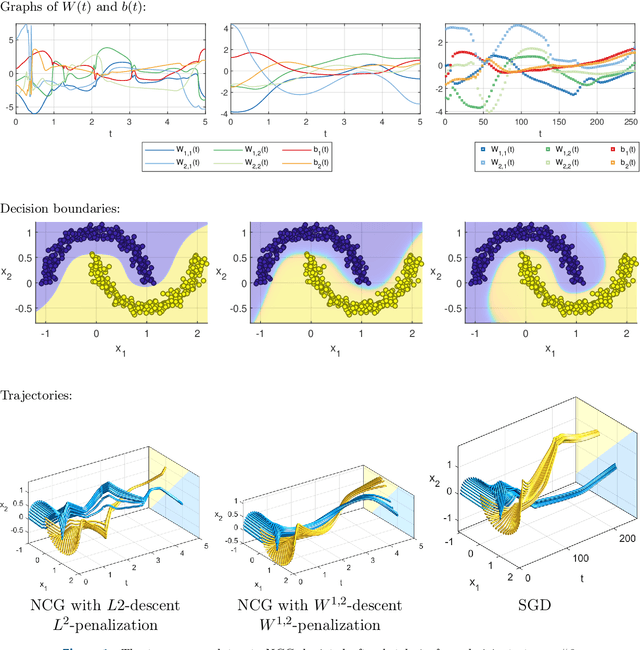
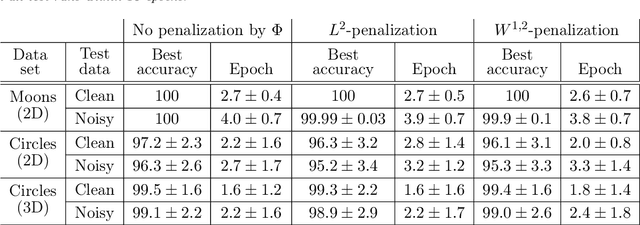
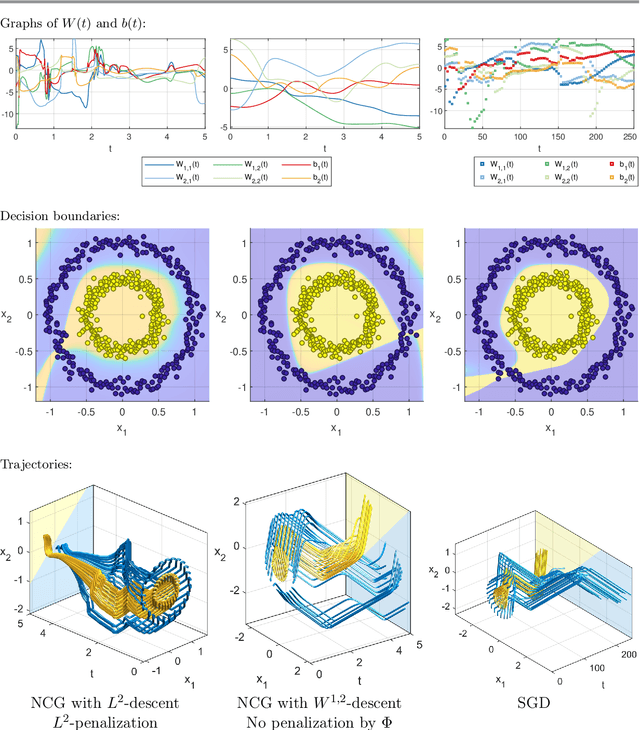
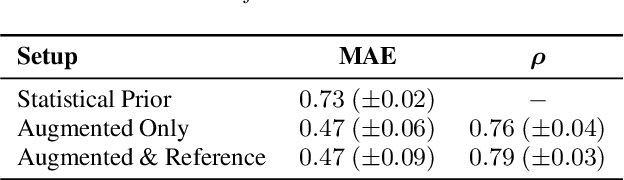
The inverse problem of supervised reconstruction of depth-variable (time-dependent) parameters in a neural ordinary differential equation (NODE) is considered, that means finding the weights of a residual network with time continuous layers. The NODE is treated as an isolated entity describing the full network as opposed to earlier research, which embedded it between pre- and post-appended layers trained by conventional methods. The proposed parameter reconstruction is done for a general first order differential equation by minimizing a cost functional covering a variety of loss functions and penalty terms. A nonlinear conjugate gradient method (NCG) is derived for the minimization. Mathematical properties are stated for the differential equation and the cost functional. The adjoint problem needed is derived together with a sensitivity problem. The sensitivity problem can estimate changes in the network output under perturbation of the trained parameters. To preserve smoothness during the iterations the Sobolev gradient is calculated and incorporated. As a proof-of-concept, numerical results are included for a NODE and two synthetic datasets, and compared with standard gradient approaches (not based on NODEs). The results show that the proposed method works well for deep learning with infinite numbers of layers, and has built-in stability and smoothness.
Race Driver Evaluation at a Driving Simulator using a physical Model and a Machine Learning Approach
Jan 27, 2022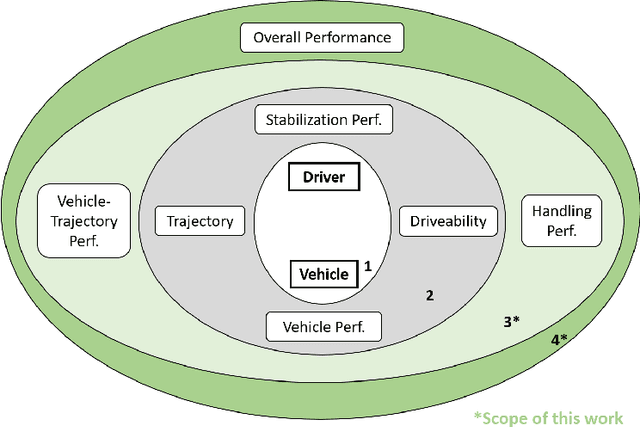
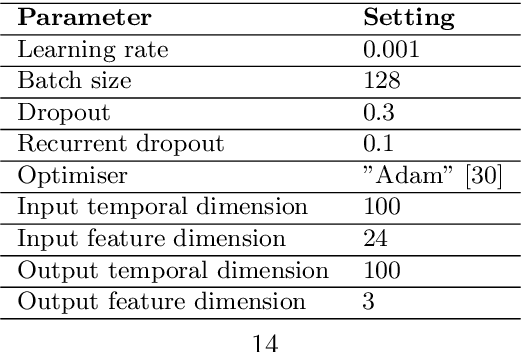
Professional race drivers are still superior to automated systems at controlling a vehicle at its dynamic limit. Gaining insight into race drivers' vehicle handling process might lead to further development in the areas of automated driving systems. We present a method to study and evaluate race drivers on a driver-in-the-loop simulator by analysing tire grip potential exploitation. Given initial data from a simulator run, two optimiser based on physical models maximise the horizontal vehicle acceleration or the tire forces, respectively. An overall performance score, a vehicle-trajectory score and a handling score are introduced to evaluate drivers. Our method is thereby completely track independent and can be used from one single corner up to a large data set. We apply the proposed method to a motorsport data set containing over 1200 laps from seven professional race drivers and two amateur drivers whose lap times are 10-20% slower. The difference to the professional drivers comes mainly from their inferior handling skills and not their choice of driving line. A downside of the presented method for certain applications is an extensive computation time. Therefore, we propose a Long-short-term memory (LSTM) neural network to estimate the driver evaluation scores. We show that the neural network is accurate and robust with a root-mean-square error between 2-5% and can replace the optimisation based method. The time for processing the data set considered in this work is reduced from 68 hours to 12 seconds, making the neural network suitable for real-time application.
Tackling Online One-Class Incremental Learning by Removing Negative Contrasts
Mar 24, 2022


Recent work studies the supervised online continual learning setting where a learner receives a stream of data whose class distribution changes over time. Distinct from other continual learning settings the learner is presented new samples only once and must distinguish between all seen classes. A number of successful methods in this setting focus on storing and replaying a subset of samples alongside incoming data in a computationally efficient manner. One recent proposal ER-AML achieved strong performance in this setting by applying an asymmetric loss based on contrastive learning to the incoming data and replayed data. However, a key ingredient of the proposed method is avoiding contrasts between incoming data and stored data, which makes it impractical for the setting where only one new class is introduced in each phase of the stream. In this work we adapt a recently proposed approach (\textit{BYOL}) from self-supervised learning to the supervised learning setting, unlocking the constraint on contrasts. We then show that supplementing this with additional regularization on class prototypes yields a new method that achieves strong performance in the one-class incremental learning setting and is competitive with the top performing methods in the multi-class incremental setting.
Multimodal Machine Learning in Precision Health
Apr 10, 2022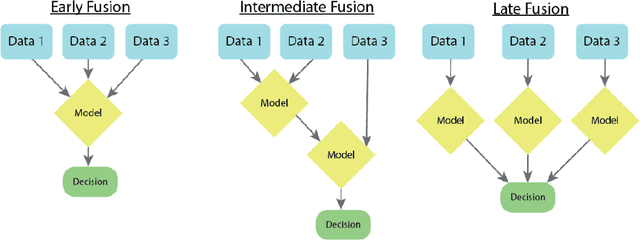
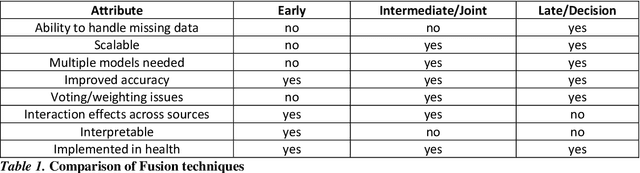

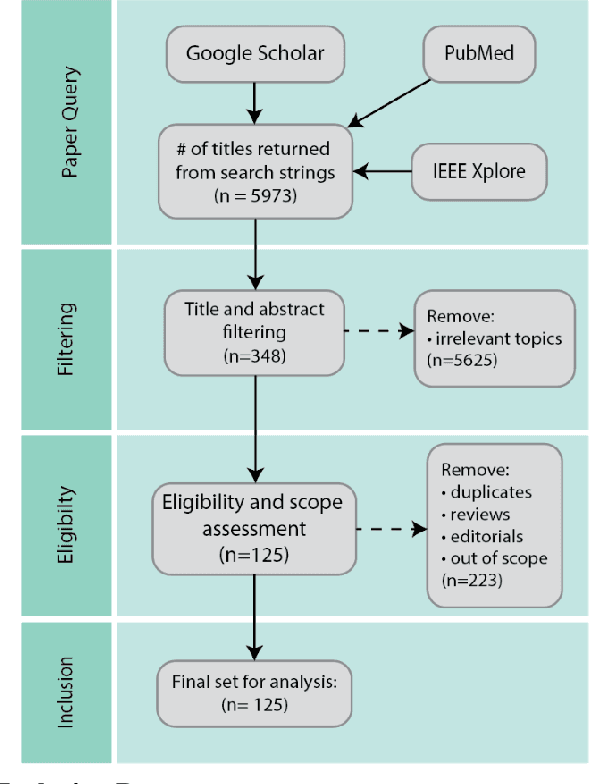
As machine learning and artificial intelligence are more frequently being leveraged to tackle problems in the health sector, there has been increased interest in utilizing them in clinical decision-support. This has historically been the case in single modal data such as electronic health record data. Attempts to improve prediction and resemble the multimodal nature of clinical expert decision-making this has been met in the computational field of machine learning by a fusion of disparate data. This review was conducted to summarize this field and identify topics ripe for future research. We conducted this review in accordance with the PRISMA (Preferred Reporting Items for Systematic reviews and Meta-Analyses) extension for Scoping Reviews to characterize multi-modal data fusion in health. We used a combination of content analysis and literature searches to establish search strings and databases of PubMed, Google Scholar, and IEEEXplore from 2011 to 2021. A final set of 125 articles were included in the analysis. The most common health areas utilizing multi-modal methods were neurology and oncology. However, there exist a wide breadth of current applications. The most common form of information fusion was early fusion. Notably, there was an improvement in predictive performance performing heterogeneous data fusion. Lacking from the papers were clear clinical deployment strategies and pursuit of FDA-approved tools. These findings provide a map of the current literature on multimodal data fusion as applied to health diagnosis/prognosis problems. Multi-modal machine learning, while more robust in its estimations over unimodal methods, has drawbacks in its scalability and the time-consuming nature of information concatenation.
WSSS4LUAD: Grand Challenge on Weakly-supervised Tissue Semantic Segmentation for Lung Adenocarcinoma
Apr 13, 2022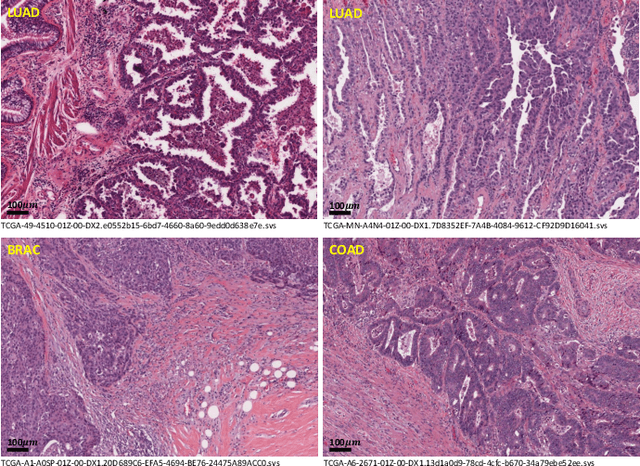
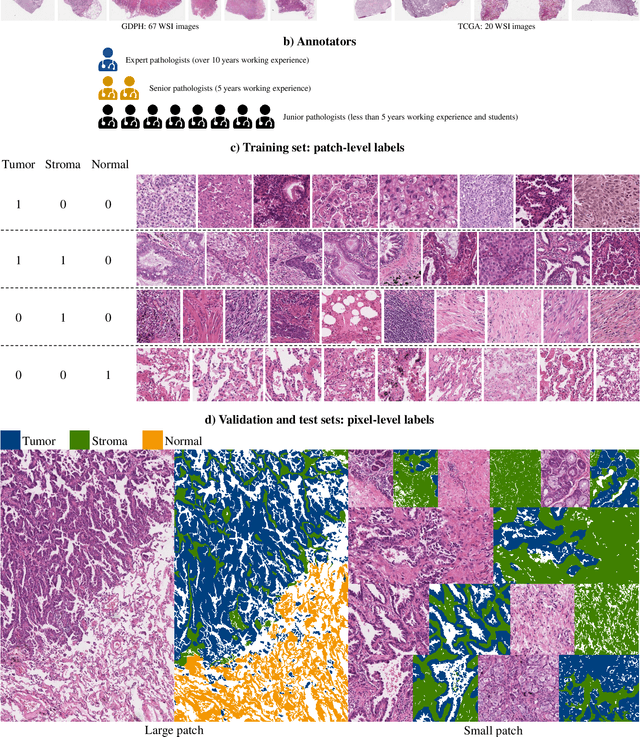
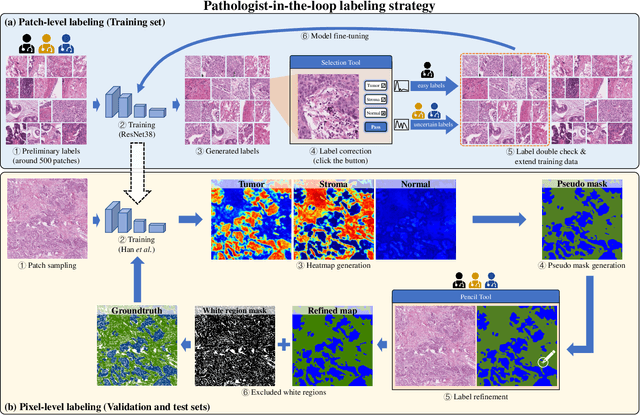
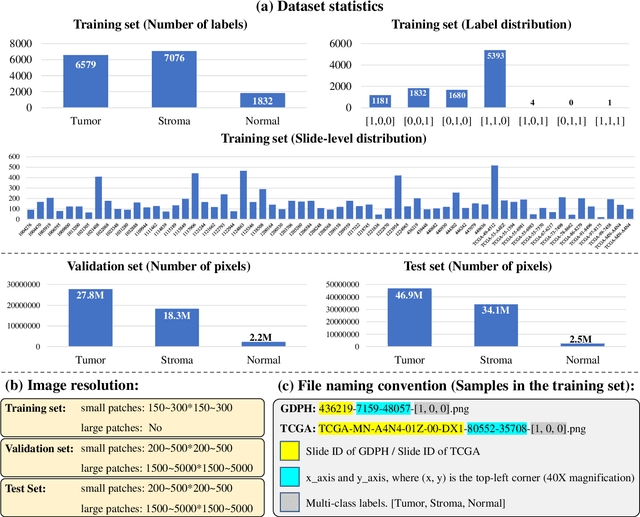
Lung cancer is the leading cause of cancer death worldwide, and adenocarcinoma (LUAD) is the most common subtype. Exploiting the potential value of the histopathology images can promote precision medicine in oncology. Tissue segmentation is the basic upstream task of histopathology image analysis. Existing deep learning models have achieved superior segmentation performance but require sufficient pixel-level annotations, which is time-consuming and expensive. To enrich the label resources of LUAD and to alleviate the annotation efforts, we organize this challenge WSSS4LUAD to call for the outstanding weakly-supervised semantic segmentation techniques for histopathology images of LUAD. Participants have to design the algorithm to segment tumor epithelial, tumor-associated stroma and normal tissue with only patch-level labels. This challenge includes 10,091 patch-level annotations (the training set) and over 130 million labeled pixels (the validation and test sets), from 67 WSIs (47 from GDPH, 20 from TCGA). All the labels were generated by a pathologist-in-the-loop pipeline with the help of AI models and checked by the label review board. Among 532 registrations, 28 teams submitted the results in the test phase with over 1,000 submissions. Finally, the first place team achieved mIoU of 0.8413 (tumor: 0.8389, stroma: 0.7931, normal: 0.8919). According to the technical reports of the top-tier teams, CAM is still the most popular approach in WSSS. Cutmix data augmentation has been widely adopted to generate more reliable samples. With the success of this challenge, we believe that WSSS approaches with patch-level annotations can replace the traditional pixel annotations while reducing the annotation efforts. The entire dataset has been released to encourage more researches on computational pathology in LUAD and more novel WSSS techniques.
Global ECG Classification by Self-Operational Neural Networks with Feature Injection
Apr 07, 2022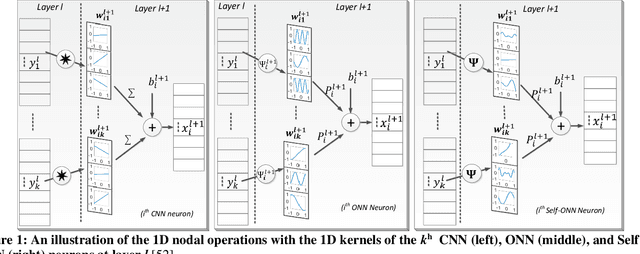
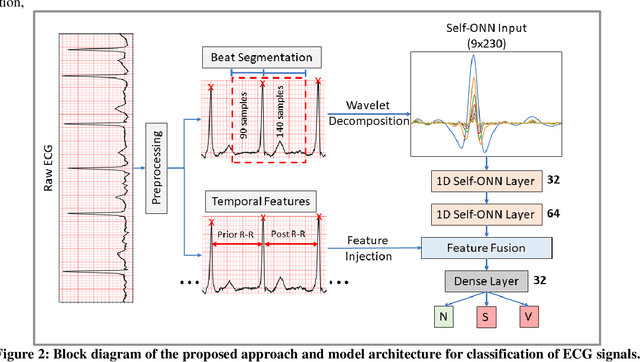
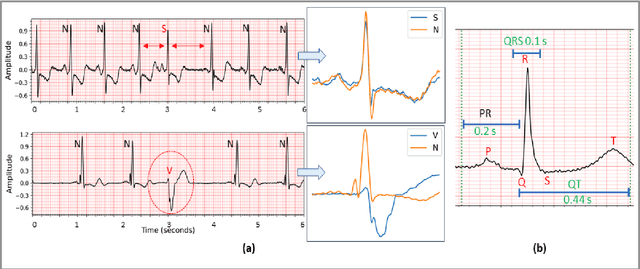
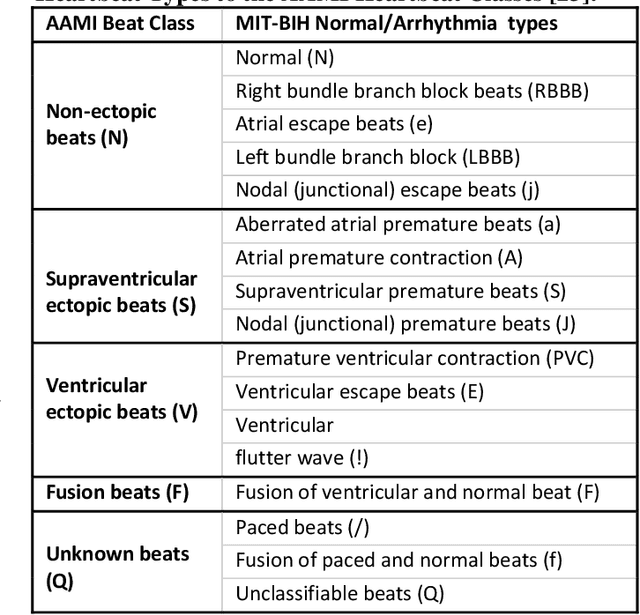
Objective: Global (inter-patient) ECG classification for arrhythmia detection over Electrocardiogram (ECG) signal is a challenging task for both humans and machines. The main reason is the significant variations of both normal and arrhythmic ECG patterns among patients. Automating this process with utmost accuracy is, therefore, highly desirable due to the advent of wearable ECG sensors. However, even with numerous deep learning approaches proposed recently, there is still a notable gap in the performance of global and patient-specific ECG classification performances. This study proposes a novel approach to narrow this gap and propose a real-time solution with shallow and compact 1D Self-Organized Operational Neural Networks (Self-ONNs). Methods: In this study, we propose a novel approach for inter-patient ECG classification using a compact 1D Self-ONN by exploiting morphological and timing information in heart cycles. We used 1D Self-ONN layers to automatically learn morphological representations from ECG data, enabling us to capture the shape of the ECG waveform around the R peaks. We further inject temporal features based on RR interval for timing characterization. The classification layers can thus benefit from both temporal and learned features for the final arrhythmia classification. Results: Using the MIT-BIH arrhythmia benchmark database, the proposed method achieves the highest classification performance ever achieved, i.e., 99.21% precision, 99.10% recall, and 99.15% F1-score for normal (N) segments; 82.19% precision, 82.50% recall, and 82.34% F1-score for the supra-ventricular ectopic beat (SVEBs); and finally, 94.41% precision, 96.10% recall, and 95.2% F1-score for the ventricular-ectopic beats (VEBs).