 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fair ranking: a critical review, challenges, and future directions
Jan 29, 2022
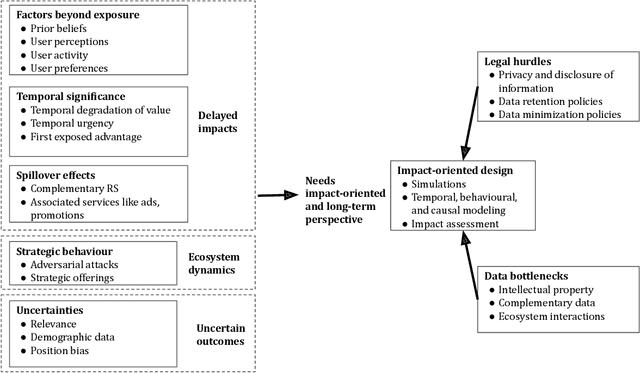



Ranking, recommendation, and retrieval systems are widely used in online platforms and other societal systems, including e-commerce, media-streaming, admissions, gig platforms, and hiring. In the recent past, a large "fair ranking" research literature has been developed around making these systems fair to the individuals, providers, or content that are being ranked. Most of this literature defines fairness for a single instance of retrieval, or as a simple additive notion for multiple instances of retrievals over time. This work provides a critical overview of this literature, detailing the often context-specific concerns that such an approach misses: the gap between high ranking placements and true provider utility, spillovers and compounding effects over time, induced strategic incentives, and the effect of statistical uncertainty. We then provide a path forward for a more holistic and impact-oriented fair ranking research agenda, including methodological lessons from other fields and the role of the broader stakeholder community in overcoming data bottlenecks and designing effective regulatory environments.
Exploring Intra- and Inter-Video Relation for Surgical Semantic Scene Segmentation
Mar 29, 2022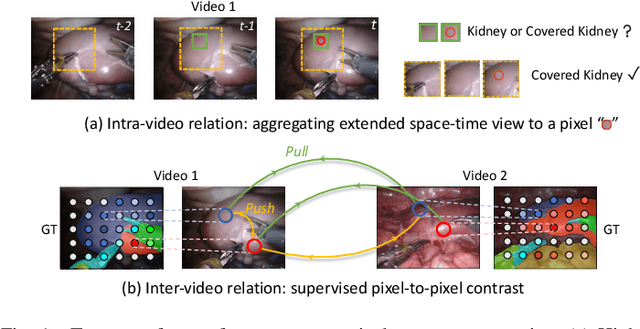
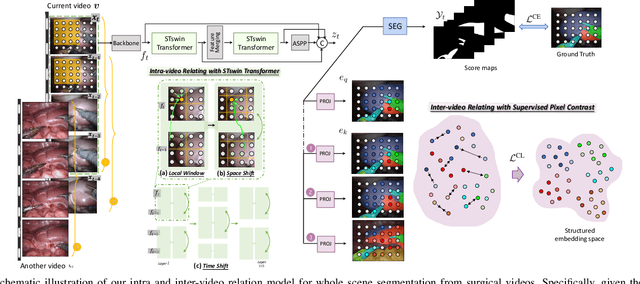
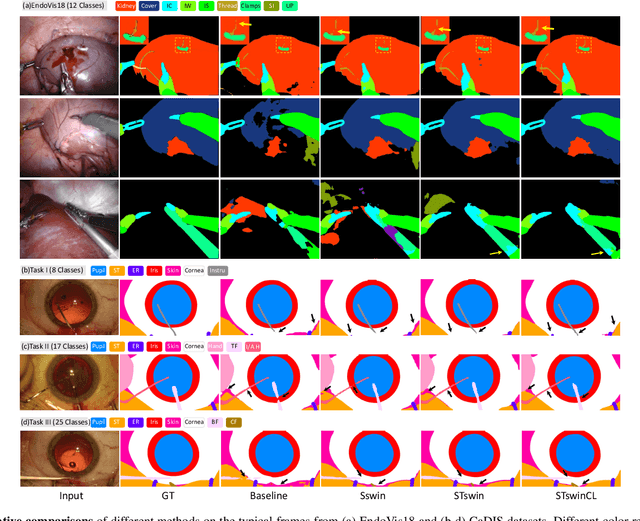

Automatic surgical scene segmentation is fundamental for facilitating cognitive intelligence in the modern operating theatre. Previous works rely on conventional aggregation modules (e.g., dilated convolution, convolutional LSTM), which only make use of the local context. In this paper, we propose a novel framework STswinCL that explores the complementary intra- and inter-video relations to boost segmentation performance, by progressively capturing the global context. We firstly develop a hierarchy Transformer to capture intra-video relation that includes richer spatial and temporal cues from neighbor pixels and previous frames. A joint space-time window shift scheme is proposed to efficiently aggregate these two cues into each pixel embedding. Then, we explore inter-video relation via pixel-to-pixel contrastive learning, which well structures the global embedding space. A multi-source contrast training objective is developed to group the pixel embeddings across videos with the ground-truth guidance, which is crucial for learning the global property of the whole data. We extensively validate our approach on two public surgical video benchmarks, including EndoVis18 Challenge and CaDIS dataset. Experimental results demonstrate the promising performance of our method, which consistently exceeds previous state-of-the-art approaches. Code will be available at https://github.com/YuemingJin/STswinCL.
Enabling hand gesture customization on wrist-worn devices
Mar 29, 2022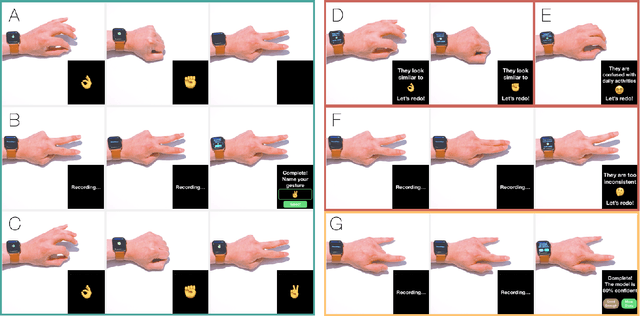
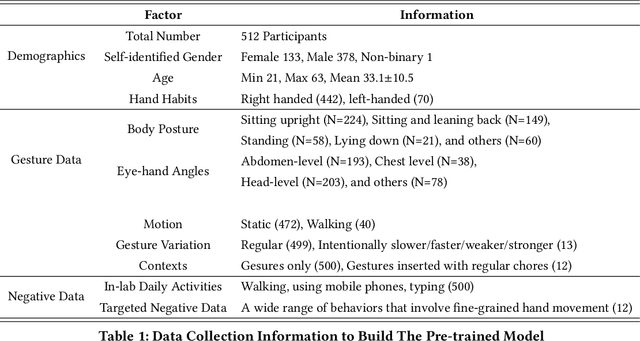
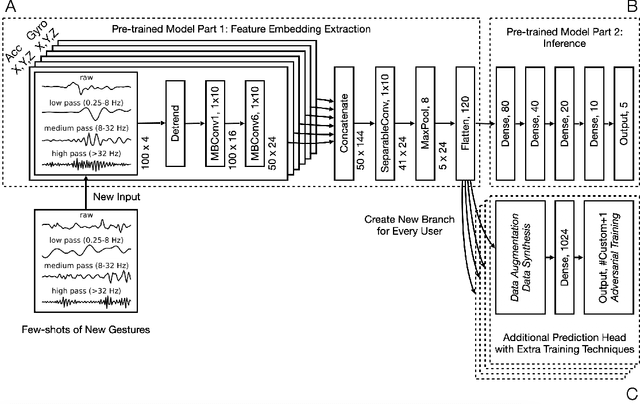
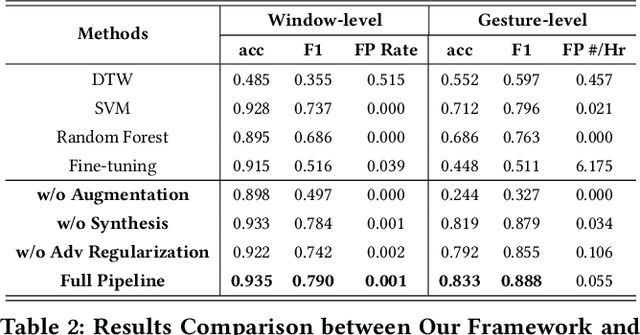
We present a framework for gesture customization requiring minimal examples from users, all without degrading the performance of existing gesture sets. To achieve this, we first deployed a large-scale study (N=500+) to collect data and train an accelerometer-gyroscope recognition model with a cross-user accuracy of 95.7% and a false-positive rate of 0.6 per hour when tested on everyday non-gesture data. Next, we design a few-shot learning framework which derives a lightweight model from our pre-trained model, enabling knowledge transfer without performance degradation. We validate our approach through a user study (N=20) examining on-device customization from 12 new gestures, resulting in an average accuracy of 55.3%, 83.1%, and 87.2% on using one, three, or five shots when adding a new gesture, while maintaining the same recognition accuracy and false-positive rate from the pre-existing gesture set. We further evaluate the usability of our real-time implementation with a user experience study (N=20). Our results highlight the effectiveness, learnability, and usability of our customization framework. Our approach paves the way for a future where users are no longer bound to pre-existing gestures, freeing them to creatively introduce new gestures tailored to their preferences and abilities.
WSSS4LUAD: Grand Challenge on Weakly-supervised Tissue Semantic Segmentation for Lung Adenocarcinoma
Apr 14, 2022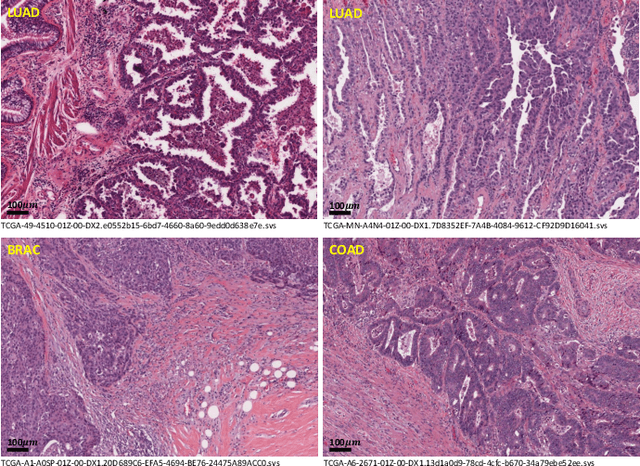
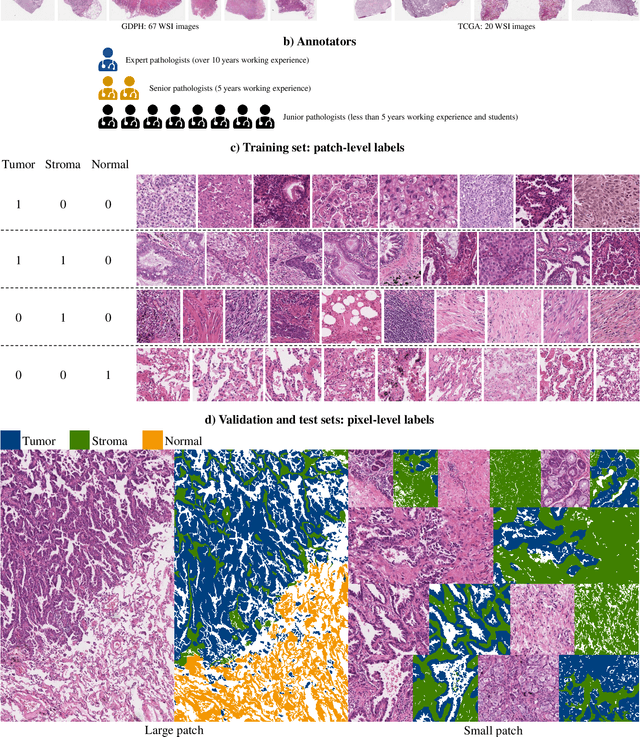
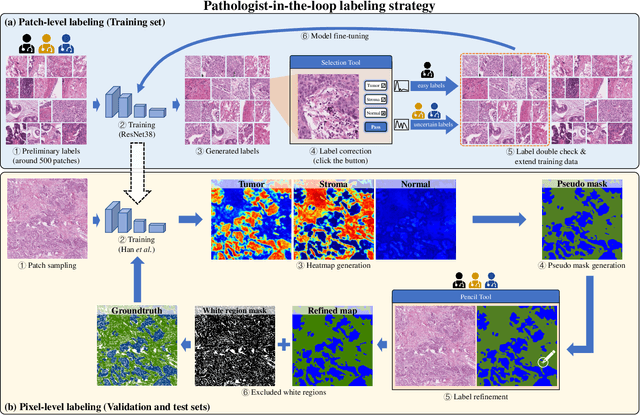
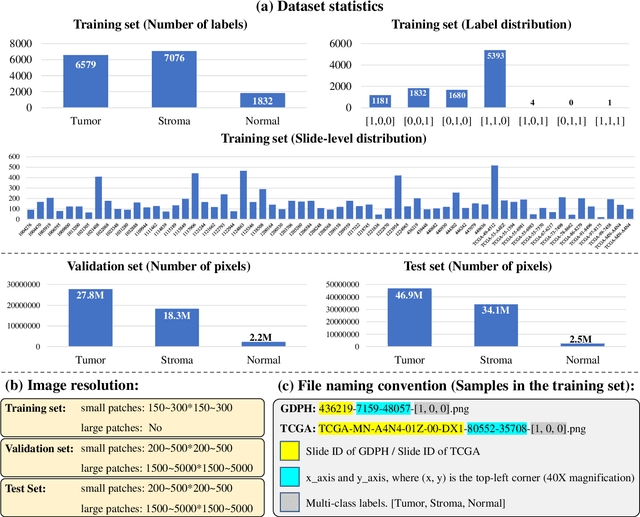
Lung cancer is the leading cause of cancer death worldwide, and adenocarcinoma (LUAD) is the most common subtype. Exploiting the potential value of the histopathology images can promote precision medicine in oncology. Tissue segmentation is the basic upstream task of histopathology image analysis. Existing deep learning models have achieved superior segmentation performance but require sufficient pixel-level annotations, which is time-consuming and expensive. To enrich the label resources of LUAD and to alleviate the annotation efforts, we organize this challenge WSSS4LUAD to call for the outstanding weakly-supervised semantic segmentation (WSSS) techniques for histopathology images of LUAD. Participants have to design the algorithm to segment tumor epithelial, tumor-associated stroma and normal tissue with only patch-level labels. This challenge includes 10,091 patch-level annotations (the training set) and over 130 million labeled pixels (the validation and test sets), from 87 WSIs (67 from GDPH, 20 from TCGA). All the labels were generated by a pathologist-in-the-loop pipeline with the help of AI models and checked by the label review board. Among 532 registrations, 28 teams submitted the results in the test phase with over 1,000 submissions. Finally, the first place team achieved mIoU of 0.8413 (tumor: 0.8389, stroma: 0.7931, normal: 0.8919). According to the technical reports of the top-tier teams, CAM is still the most popular approach in WSSS. Cutmix data augmentation has been widely adopted to generate more reliable samples. With the success of this challenge, we believe that WSSS approaches with patch-level annotations can be a complement to the traditional pixel annotations while reducing the annotation efforts. The entire dataset has been released to encourage more researches on computational pathology in LUAD and more novel WSSS techniques.
On-Device Learning: A Neural Network Based Field-Trainable Edge AI
Mar 02, 2022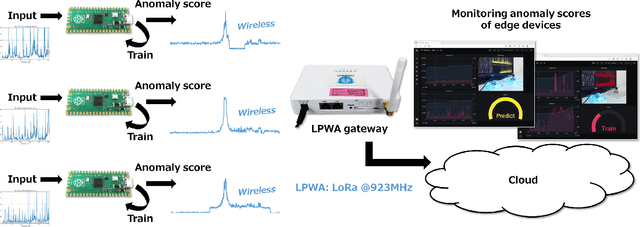
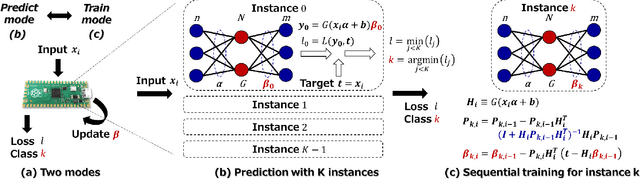
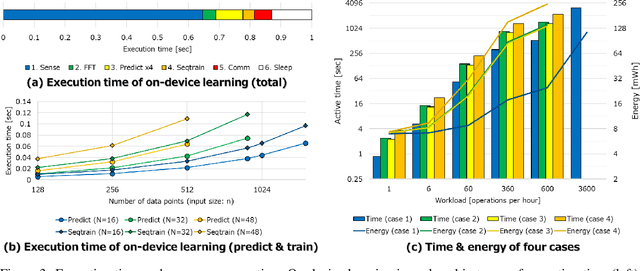
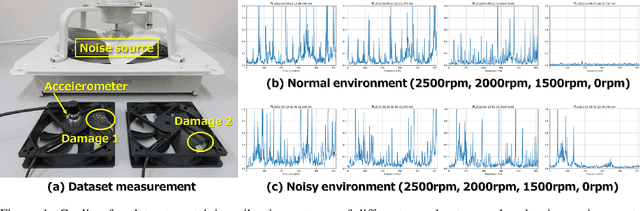
In real-world edge AI applications, their accuracy is often affected by various environmental factors, such as noises, location/calibration of sensors, and time-related changes. This article introduces a neural network based on-device learning approach to address this issue without going deep. Our approach is quite different from de facto backpropagation based training but tailored for low-end edge devices. This article introduces its algorithm and implementation on a wireless sensor node consisting of Raspberry Pi Pico and low-power wireless module. Experiments using vibration patterns of rotating machines demonstrate that retraining by the on-device learning significantly improves an anomaly detection accuracy at a noisy environment while saving computation and communication costs for low power.
Coordinate Invariant User-Guided Constrained Path Planning with Reactive Rapidly Expanding Plane-Oriented Escaping Trees
Mar 20, 2022

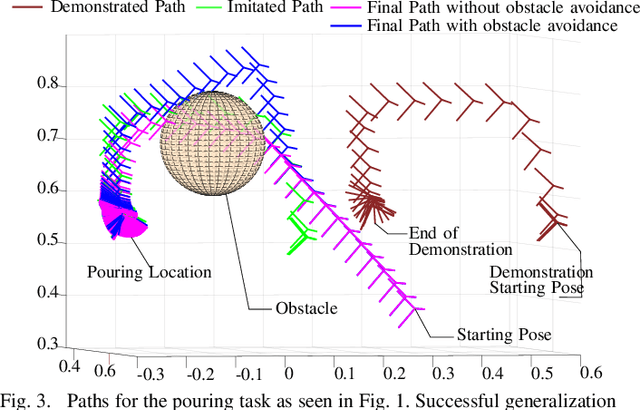
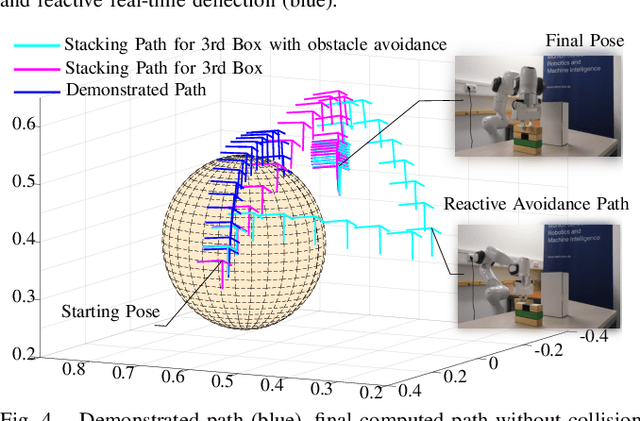
As collaborative robots move closer to human environments, motion generation and reactive planning strategies that allow for elaborate task execution with minimal easy-to-implement guidance whilst coping with changes in the environment is of paramount importance. In this paper, we present a novel approach for generating real-time motion plans for point-to-point tasks using a single successful human demonstration. Our approach is based on screw linear interpolation,which allows us to respect the underlying geometric constraints that characterize the task and are implicitly present in the demonstration. We also integrate an original reactive collision avoidance approach with our planner. We present extensive experimental results to demonstrate that with our approach,by using a single demonstration of moving one block, we can generate motion plans for complex tasks like stacking multiple blocks (in a dynamic environment). Analogous generalization abilities are also shown for tasks like pouring and loading shelves. For the pouring task, we also show that a demonstration given for one-armed pouring can be used for planning pouring with a dual-armed manipulator of different kinematic structure.
SPAct: Self-supervised Privacy Preservation for Action Recognition
Mar 29, 2022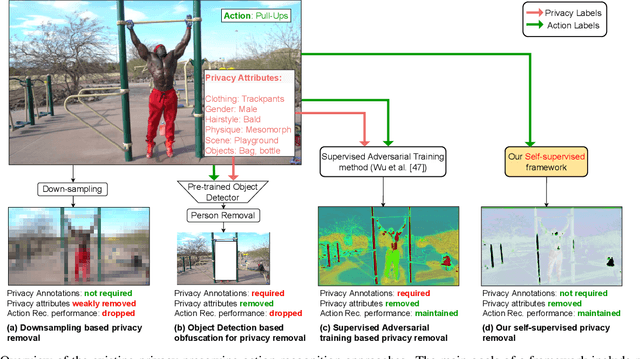
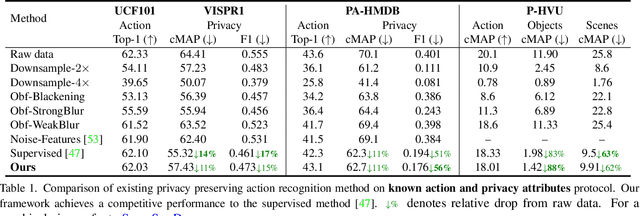
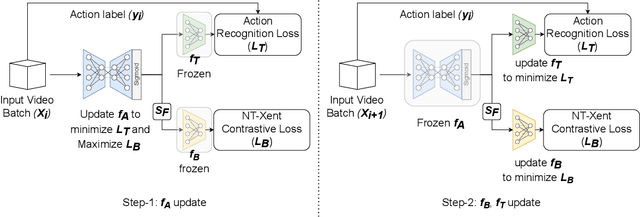
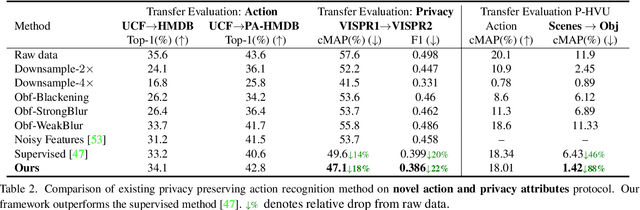
Visual private information leakage is an emerging key issue for the fast growing applications of video understanding like activity recognition. Existing approaches for mitigating privacy leakage in action recognition require privacy labels along with the action labels from the video dataset. However, annotating frames of video dataset for privacy labels is not feasible. Recent developments of self-supervised learning (SSL) have unleashed the untapped potential of the unlabeled data. For the first time, we present a novel training framework which removes privacy information from input video in a self-supervised manner without requiring privacy labels. Our training framework consists of three main components: anonymization function, self-supervised privacy removal branch, and action recognition branch. We train our framework using a minimax optimization strategy to minimize the action recognition cost function and maximize the privacy cost function through a contrastive self-supervised loss. Employing existing protocols of known-action and privacy attributes, our framework achieves a competitive action-privacy trade-off to the existing state-of-the-art supervised methods. In addition, we introduce a new protocol to evaluate the generalization of learned the anonymization function to novel-action and privacy attributes and show that our self-supervised framework outperforms existing supervised methods. Code available at: https://github.com/DAVEISHAN/SPAct
Model-Based Control of Planar Piezoelectric Inchworm Soft Robot for Crawling in Constrained Environments
Mar 29, 2022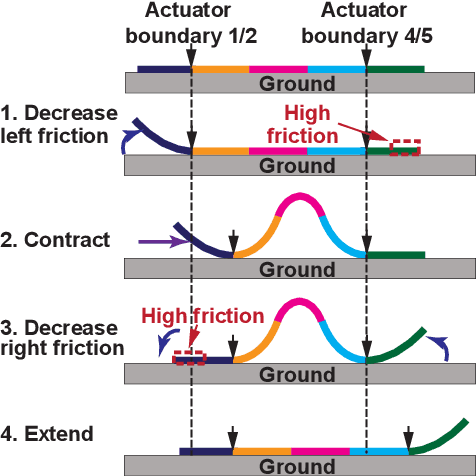
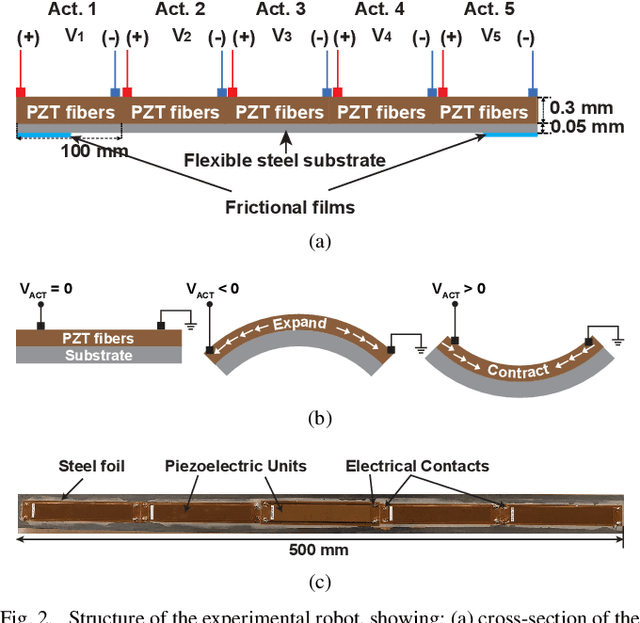
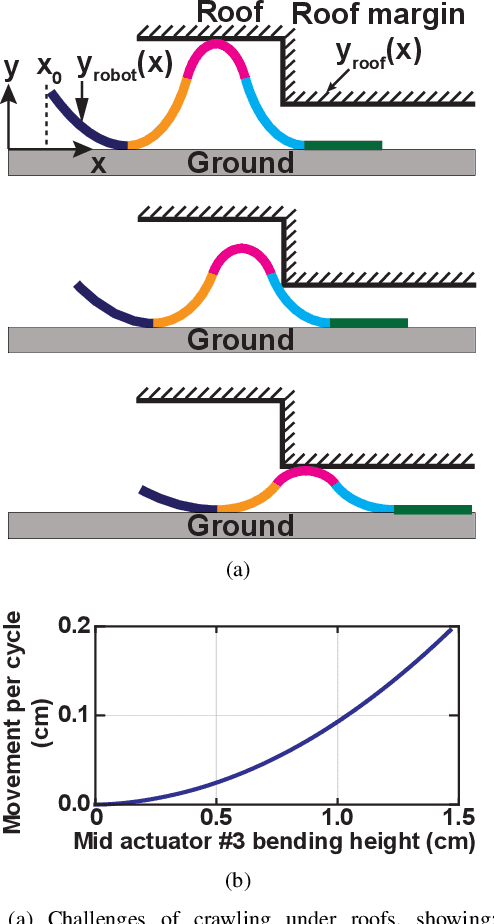
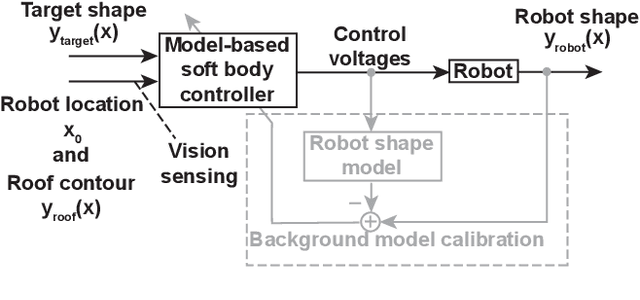
Soft robots have drawn significant attention recently for their ability to achieve rich shapes when interacting with complex environments. However, their elasticity and flexibility compared to rigid robots also pose significant challenges for precise and robust shape control in real-time. Motivated by their potential to operate in highly-constrained environments, as in search-and-rescue operations, this work addresses these challenges of soft robots by developing a model-based full-shape controller, validated and demonstrated by experiments. A five-actuator planar soft robot was constructed with planar piezoelectric layers bonded to a steel foil substrate, enabling inchworm-like motion. The controller uses a soft-body continuous model for shape planning and control, given target shapes and/or environmental constraints, such as crawling under overhead barriers or "roof" safety lines. An approach to background model calibrations is developed to address deviations of actual robot shape due to material parameter variations and drift. Full experimental shape control and optimal movement under a roof safety line are demonstrated, where the robot maximizes its speed within the overhead constraint. The mean-squared error between the measured and target shapes improves from ~0.05 cm$^{2}$ without calibration to ~0.01 cm$^{2}$ with calibration. Simulation-based validation is also performed with various different roof shapes.
Event-Related Bias Removal for Real-time Disaster Events
Nov 02, 2020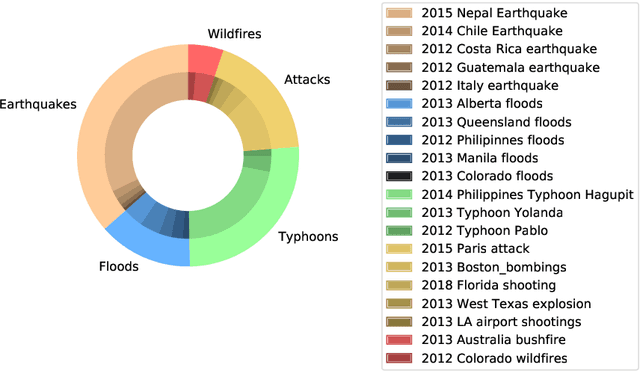

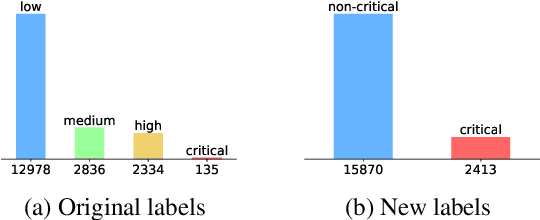
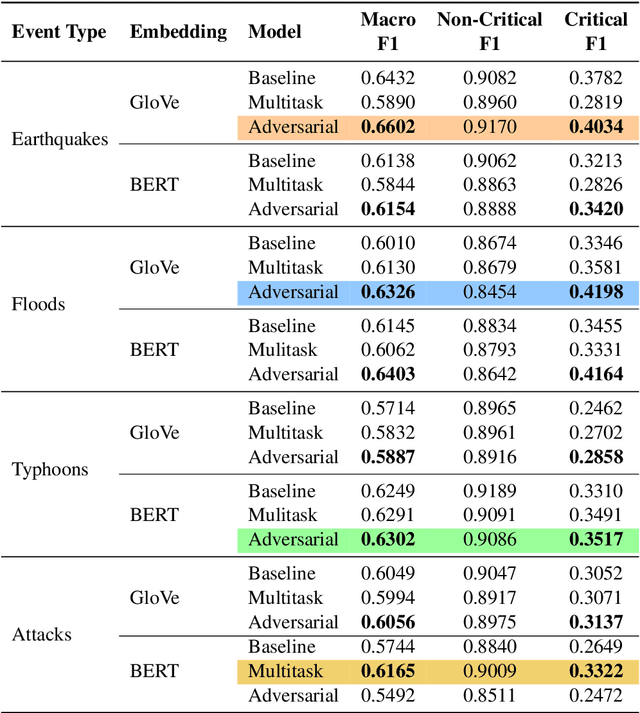
Social media has become an important tool to share information about crisis events such as natural disasters and mass attacks. Detecting actionable posts that contain useful information requires rapid analysis of huge volume of data in real-time. This poses a complex problem due to the large amount of posts that do not contain any actionable information. Furthermore, the classification of information in real-time systems requires training on out-of-domain data, as we do not have any data from a new emerging crisis. Prior work focuses on models pre-trained on similar event types. However, those models capture unnecessary event-specific biases, like the location of the event, which affect the generalizability and performance of the classifiers on new unseen data from an emerging new event. In our work, we train an adversarial neural model to remove latent event-specific biases and improve the performance on tweet importance classification.
Multi-scale temporal network for continuous sign language recognition
Apr 08, 2022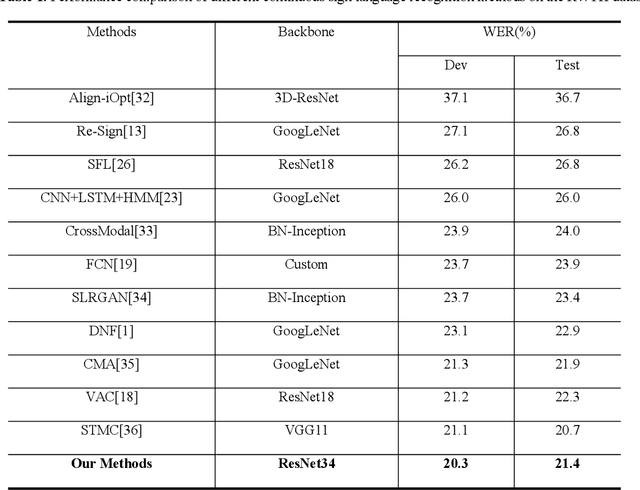
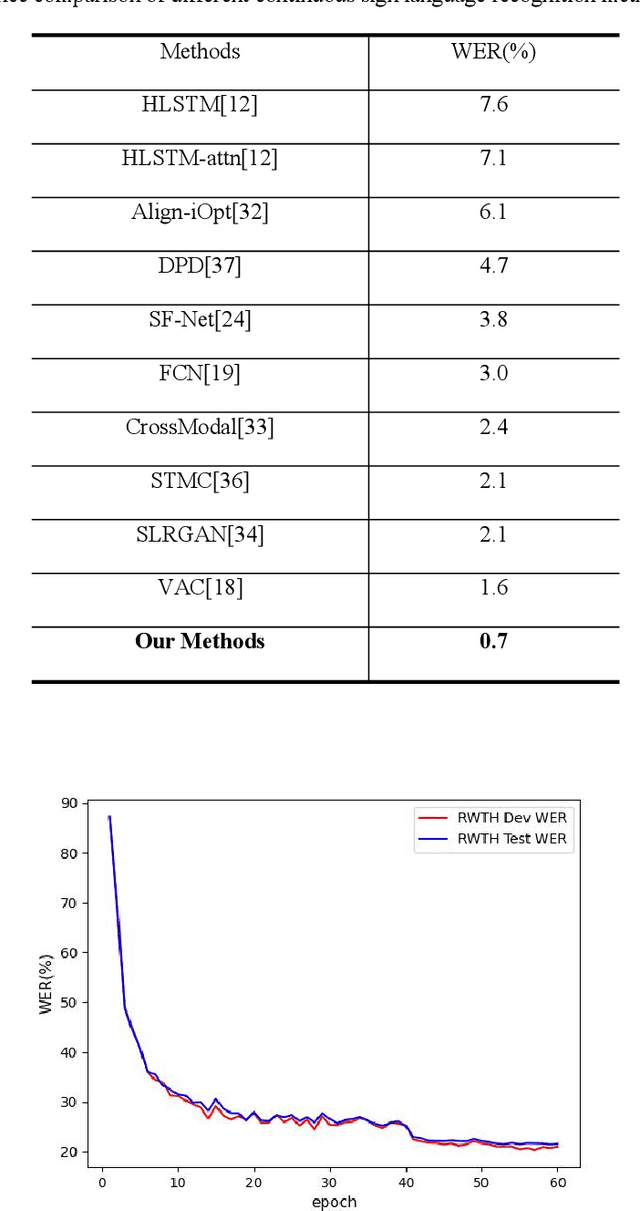
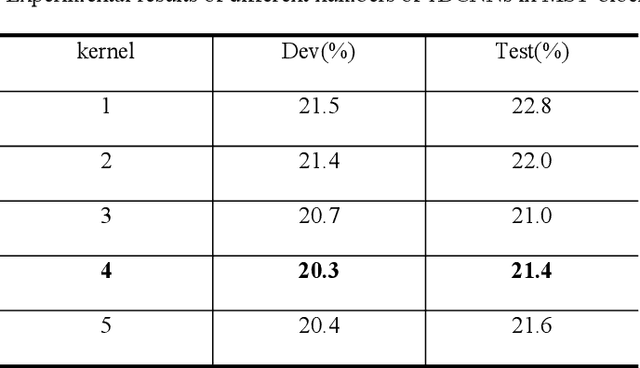
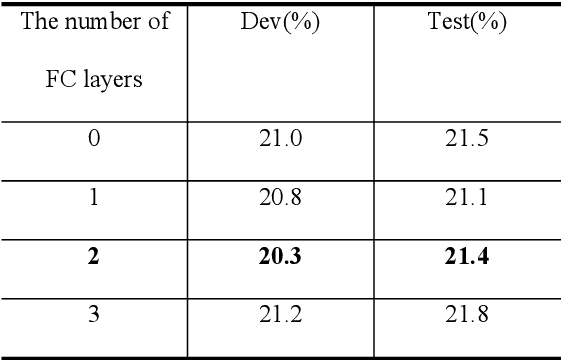
Continuous Sign Language Recognition (CSLR) is a challenging research task due to the lack of accurate annotation on the temporal sequence of sign language data. The recent popular usage is a hybrid model based on "CNN + RNN" for CSLR. However, when extracting temporal features in these works, most of the methods using a fixed temporal receptive field and cannot extract the temporal features well for each sign language word. In order to obtain more accurate temporal features, this paper proposes a multi-scale temporal network (MSTNet). The network mainly consists of three parts. The Resnet and two fully connected (FC) layers constitute the frame-wise feature extraction part. The time-wise feature extraction part performs temporal feature learning by first extracting temporal receptive field features of different scales using the proposed multi-scale temporal block (MST-block) to improve the temporal modeling capability, and then further encoding the temporal features of different scales by the transformers module to obtain more accurate temporal features. Finally, the proposed multi-level Connectionist Temporal Classification (CTC) loss part is used for training to obtain recognition results. The multi-level CTC loss enables better learning and updating of the shallow network parameters in CNN, and the method has no parameter increase and can be flexibly embedded in other models. Experimental results on two publicly available datasets demonstrate that our method can effectively extract sign language features in an end-to-end manner without any prior knowledge, improving the accuracy of CSLR and reaching the state-of-the-art.