 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
NorDiaChange: Diachronic Semantic Change Dataset for Norwegian
Jan 13, 2022
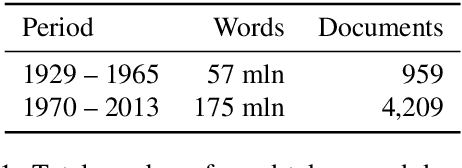
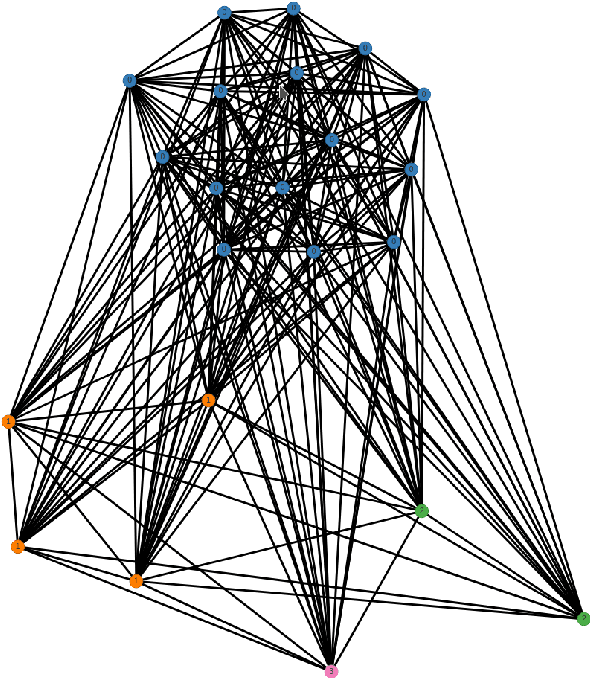
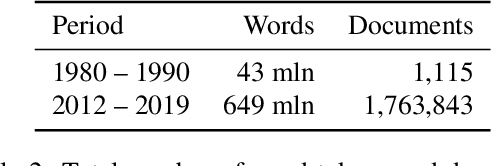
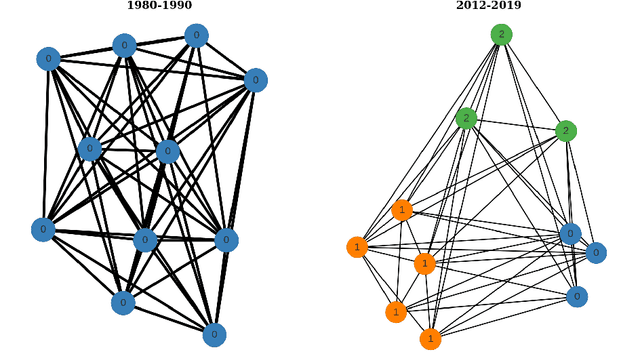
We describe NorDiaChange: the first diachronic semantic change dataset for Norwegian. NorDiaChange comprises two novel subsets, covering about 80 Norwegian nouns manually annotated with graded semantic change over time. Both datasets follow the same annotation procedure and can be used interchangeably as train and test splits for each other. NorDiaChange covers the time periods related to pre- and post-war events, oil and gas discovery in Norway, and technological developments. The annotation was done using the DURel framework and two large historical Norwegian corpora. NorDiaChange is published in full under a permissive license, complete with raw annotation data and inferred diachronic word usage graphs (DWUGs).
A Multi-Stage Duplex Fusion ConvNet for Aerial Scene Classification
Mar 29, 2022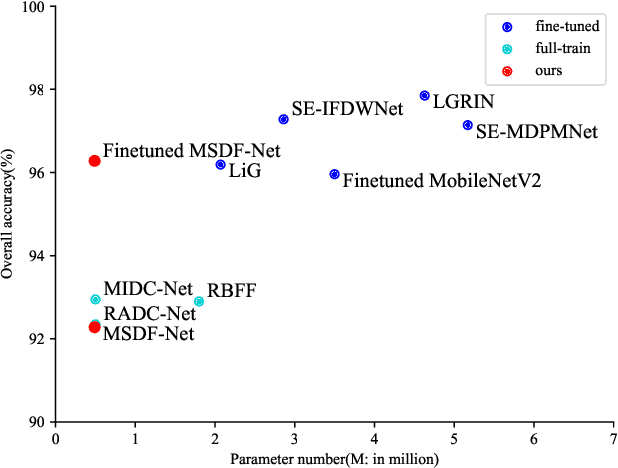

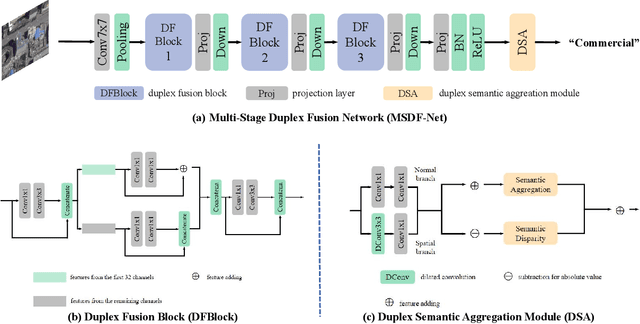

Existing deep learning based methods effectively prompt the performance of aerial scene classification. However, due to the large amount of parameters and computational cost, it is rather difficult to apply these methods to multiple real-time remote sensing applications such as on-board data preception on drones and satellites. In this paper, we address this task by developing a light-weight ConvNet named multi-stage duplex fusion network (MSDF-Net). The key idea is to use parameters as little as possible while obtaining as strong as possible scene representation capability. To this end, a residual-dense duplex fusion strategy is developed to enhance the feature propagation while re-using parameters as much as possible, and is realized by our duplex fusion block (DFblock). Specifically, our MSDF-Net consists of multi-stage structures with DFblock. Moreover, duplex semantic aggregation (DSA) module is developed to mine the remote sensing scene information from extracted convolutional features, which also contains two parallel branches for semantic description. Extensive experiments are conducted on three widely-used aerial scene classification benchmarks, and reflect that our MSDF-Net can achieve a competitive performance against the recent state-of-art while reducing up to 80% parameter numbers. Particularly, an accuracy of 92.96% is achieved on AID with only 0.49M parameters.
OctAttention: Octree-based Large-scale Contexts Model for Point Cloud Compression
Feb 12, 2022
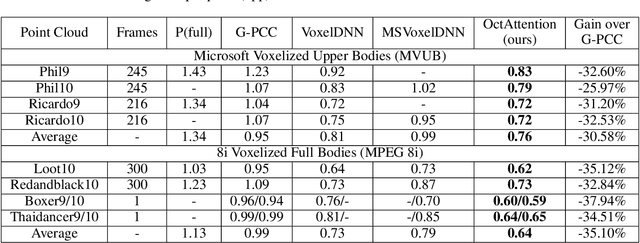
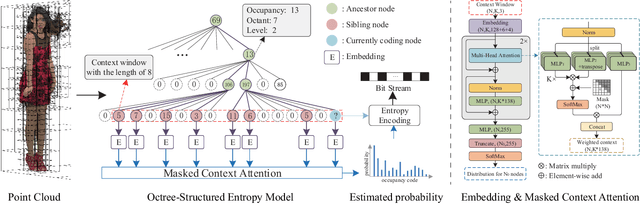
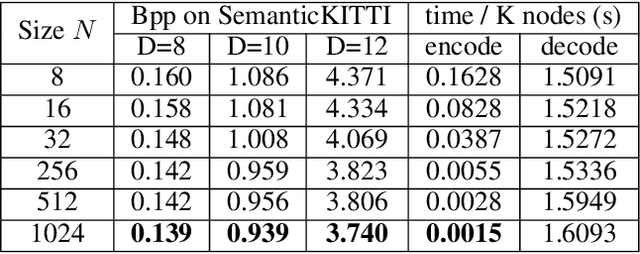
In point cloud compression, sufficient contexts are significant for modeling the point cloud distribution. However, the contexts gathered by the previous voxel-based methods decrease when handling sparse point clouds. To address this problem, we propose a multiple-contexts deep learning framework called OctAttention employing the octree structure, a memory-efficient representation for point clouds. Our approach encodes octree symbol sequences in a lossless way by gathering the information of sibling and ancestor nodes. Expressly, we first represent point clouds with octree to reduce spatial redundancy, which is robust for point clouds with different resolutions. We then design a conditional entropy model with a large receptive field that models the sibling and ancestor contexts to exploit the strong dependency among the neighboring nodes and employ an attention mechanism to emphasize the correlated nodes in the context. Furthermore, we introduce a mask operation during training and testing to make a trade-off between encoding time and performance. Compared to the previous state-of-the-art works, our approach obtains a 10%-35% BD-Rate gain on the LiDAR benchmark (e.g. SemanticKITTI) and object point cloud dataset (e.g. MPEG 8i, MVUB), and saves 95% coding time compared to the voxel-based baseline. The code is available at https://github.com/zb12138/OctAttention.
A 3D Positioning-based Channel Estimation Method for RIS-aided mmWave Communications
Mar 29, 2022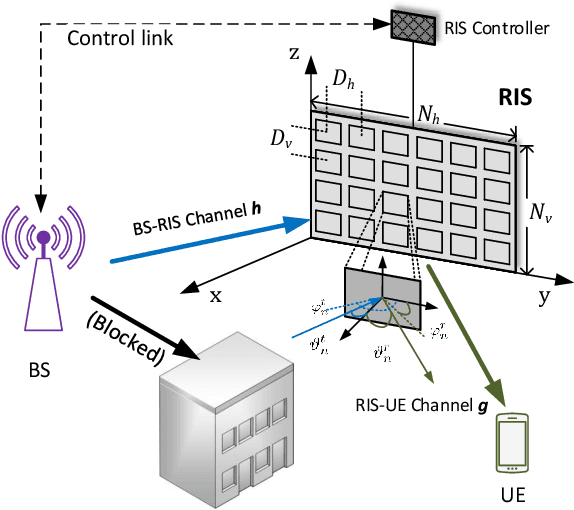
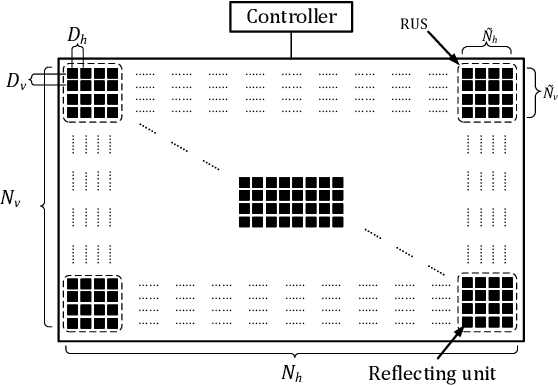
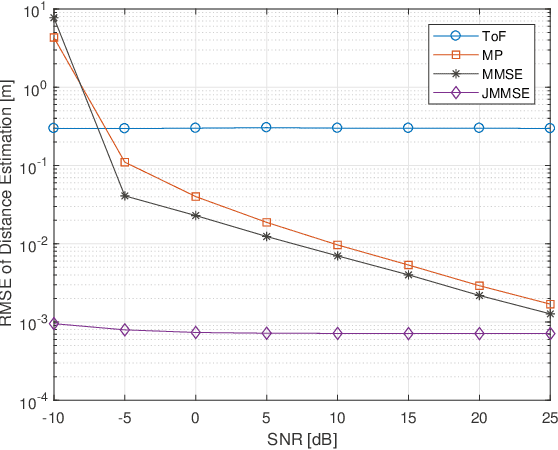
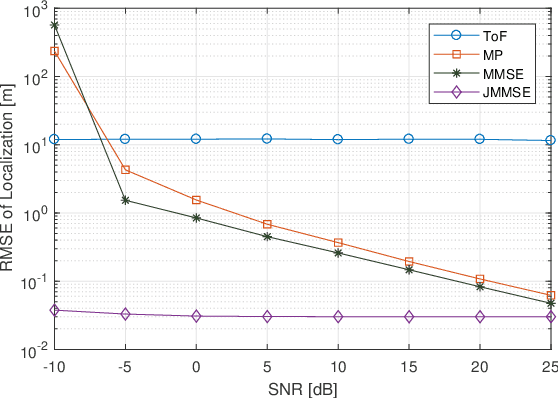
A fundamental challenge in millimeter-wave (mmWave) communication is the susceptibility to blocking objects. One way to alleviate this problem is the use of reconfigurable intelligent surfaces (RIS). Nevertheless, due to the large number of passive reflecting elements on RIS, channel estimation turns out to be a challenging task. In this paper, we address the channel estimation for RIS-aided mmWave communication systems based on a localization method. The proposed idea consists of exploiting the sparsity of the mmWave channel and the topology of the RIS. In particular, we first propose the concept of reflecting unit set (RUS) to improve the flexibility of RIS. We then propose a novel coplanar maximum likelihood-based (CML) 3D positioning method based on the RUS, and derive the Cramer-Rao lower bound (CRLB) for the positioning method. Furthermore, we develop an efficient positioning-based channel estimation scheme with low computational complexity. Compared to state-of-the-art methods, our proposed method requires less time-frequency resources in channel acquisition as the complexity is independent to the total size of the RIS but depends on the size of the RUSs, which is only a small portion of the RIS. Large performance gains are confirmed in simulations, which proves the effectiveness of the proposed method.
Differentiable DAG Sampling
Mar 16, 2022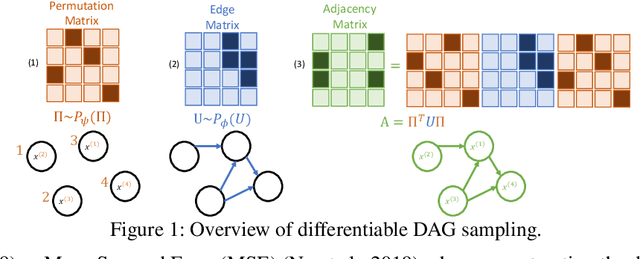

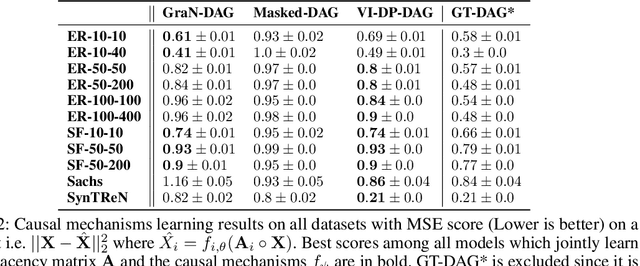
We propose a new differentiable probabilistic model over DAGs (DP-DAG). DP-DAG allows fast and differentiable DAG sampling suited to continuous optimization. To this end, DP-DAG samples a DAG by successively (1) sampling a linear ordering of the node and (2) sampling edges consistent with the sampled linear ordering. We further propose VI-DP-DAG, a new method for DAG learning from observational data which combines DP-DAG with variational inference. Hence,VI-DP-DAG approximates the posterior probability over DAG edges given the observed data. VI-DP-DAG is guaranteed to output a valid DAG at any time during training and does not require any complex augmented Lagrangian optimization scheme in contrast to existing differentiable DAG learning approaches. In our extensive experiments, we compare VI-DP-DAG to other differentiable DAG learning baselines on synthetic and real datasets. VI-DP-DAG significantly improves DAG structure and causal mechanism learning while training faster than competitors.
Monte Carlo PINNs: deep learning approach for forward and inverse problems involving high dimensional fractional partial differential equations
Mar 16, 2022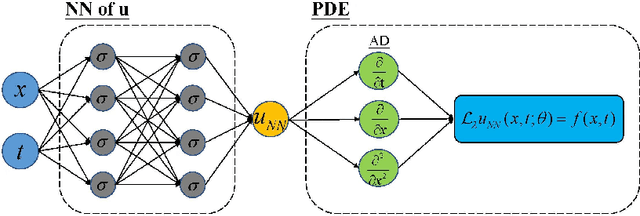

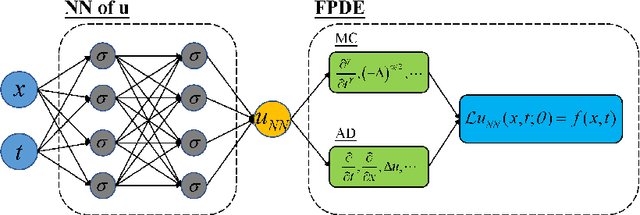
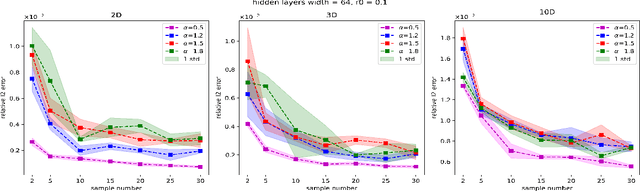
We introduce a sampling based machine learning approach, Monte Carlo physics informed neural networks (MC-PINNs), for solving forward and inverse fractional partial differential equations (FPDEs). As a generalization of physics informed neural networks (PINNs), our method relies on deep neural network surrogates in addition to a stochastic approximation strategy for computing the fractional derivatives of the DNN outputs. A key ingredient in our MC-PINNs is to construct an unbiased estimation of the physical soft constraints in the loss function. Our directly sampling approach can yield less overall computational cost compared to fPINNs proposed in \cite{pang2019fpinns} and thus provide an opportunity for solving high dimensional fractional PDEs. We validate the performance of MC-PINNs method via several examples that include high dimensional integral fractional Laplacian equations, parametric identification of time-space fractional PDEs, and fractional diffusion equation with random inputs. The results show that MC-PINNs is flexible and promising to tackle high-dimensional FPDEs.
Learning-based Point Cloud Registration for 6D Object Pose Estimation in the Real World
Mar 29, 2022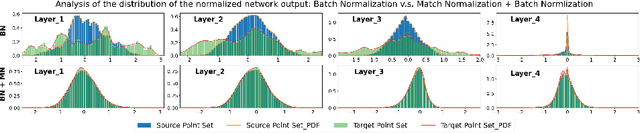
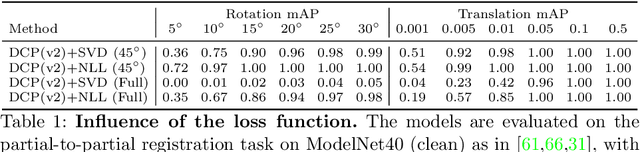
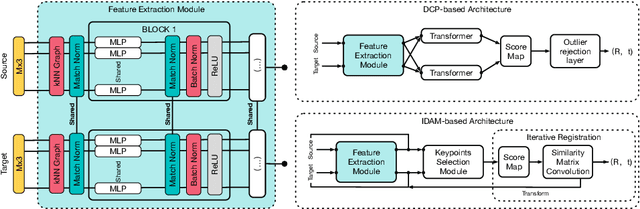
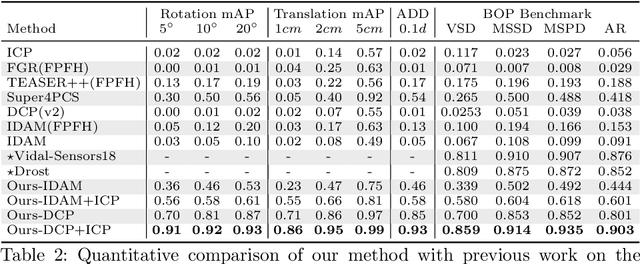
In this work, we tackle the task of estimating the 6D pose of an object from point cloud data. While recent learning-based approaches to addressing this task have shown great success on synthetic datasets, we have observed them to fail in the presence of real-world data. We thus analyze the causes of these failures, which we trace back to the difference between the feature distributions of the source and target point clouds, and the sensitivity of the widely-used SVD-based loss function to the range of rotation between the two point clouds. We address the first challenge by introducing a new normalization strategy, Match Normalization, and the second via the use of a loss function based on the negative log likelihood of point correspondences. Our two contributions are general and can be applied to many existing learning-based 3D object registration frameworks, which we illustrate by implementing them in two of them, DCP and IDAM. Our experiments on the real-scene TUD-L, LINEMOD and Occluded-LINEMOD datasets evidence the benefits of our strategies. They allow for the first time learning-based 3D object registration methods to achieve meaningful results on real-world data. We therefore expect them to be key to the future development of point cloud registration methods.
Requirements Elicitation in Cognitive Service for Recommendation
Mar 29, 2022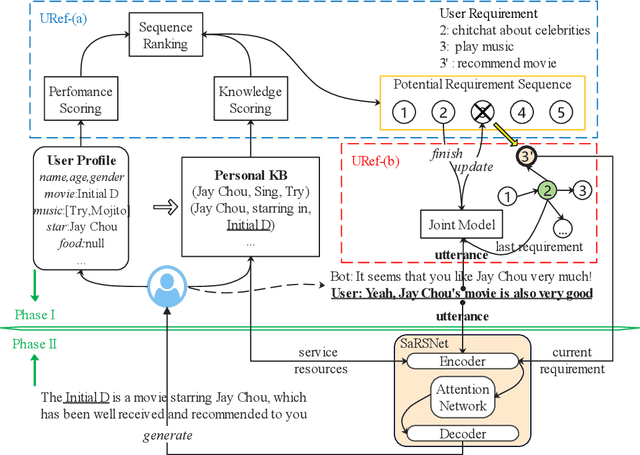

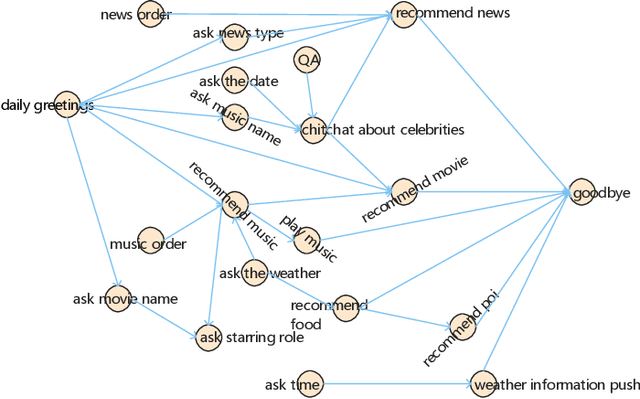
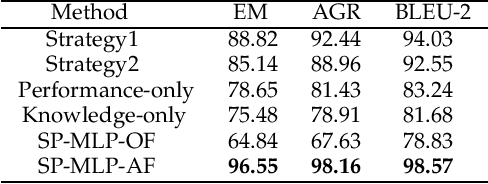
Nowadays, cognitive service provides more interactive way to understand users' requirements via human-machine conversation. In other words, it has to capture users' requirements from their utterance and respond them with the relevant and suitable service resources. To this end, two phases must be applied: I.Sequence planning and Real-time detection of user requirement, II.Service resource selection and Response generation. The existing works ignore the potential connection between these two phases. To model their connection, Two-Phase Requirement Elicitation Method is proposed. For the phase I, this paper proposes a user requirement elicitation framework (URef) to plan a potential requirement sequence grounded on user profile and personal knowledge base before the conversation. In addition, it can also predict user's true requirement and judge whether the requirement is completed based on the user's utterance during the conversation. For the phase II, this paper proposes a response generation model based on attention, SaRSNet. It can select the appropriate resource (i.e. knowledge triple) in line with the requirement predicted by URef, and then generates a suitable response for recommendation. The experimental results on the open dataset \emph{DuRecDial} have been significantly improved compared to the baseline, which proves the effectiveness of the proposed methods.
Using Multi-scale SwinTransformer-HTC with Data augmentation in CoNIC Challenge
Mar 02, 2022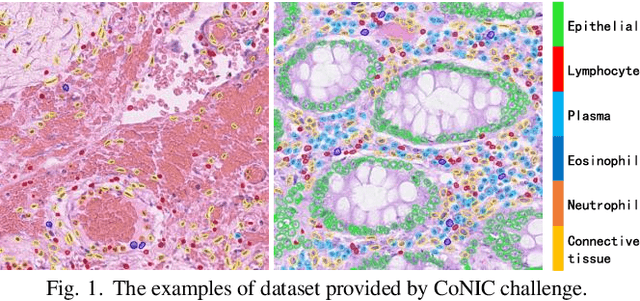
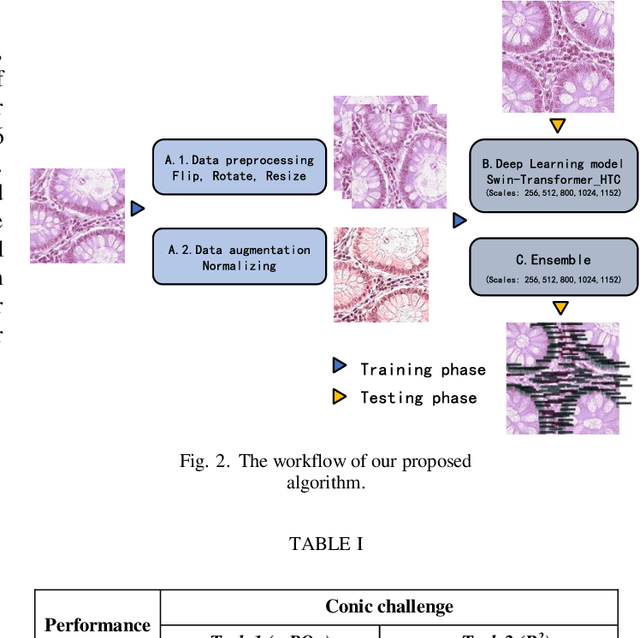
Colorectal cancer is one of the most common cancers worldwide, so early pathological examination is very important. However, it is time-consuming and labor-intensive to identify the number and type of cells on H&E images in clinical. Therefore, automatic segmentation and classification task and counting the cellular composition of H&E images from pathological sections is proposed by CoNIC Challenge 2022. We proposed a multi-scale Swin transformer with HTC for this challenge, and also applied the known normalization methods to generate more augmentation data. Finally, our strategy showed that the multi-scale played a crucial role to identify different scale features and the augmentation arose the recognition of model.
Event-Related Bias Removal for Real-time Disaster Events
Nov 02, 2020

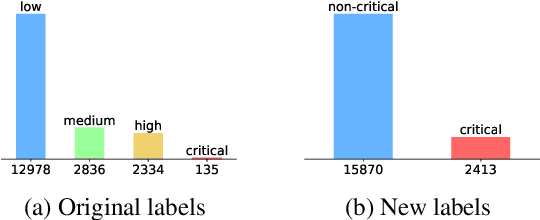
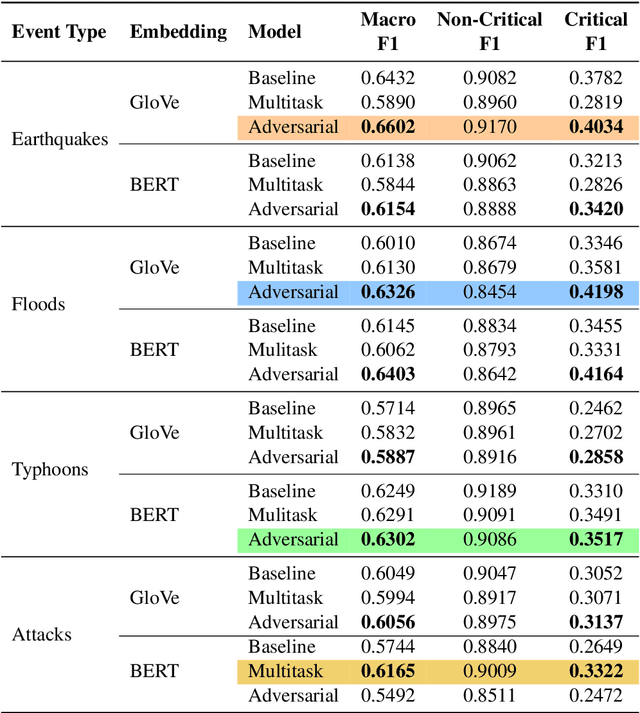
Social media has become an important tool to share information about crisis events such as natural disasters and mass attacks. Detecting actionable posts that contain useful information requires rapid analysis of huge volume of data in real-time. This poses a complex problem due to the large amount of posts that do not contain any actionable information. Furthermore, the classification of information in real-time systems requires training on out-of-domain data, as we do not have any data from a new emerging crisis. Prior work focuses on models pre-trained on similar event types. However, those models capture unnecessary event-specific biases, like the location of the event, which affect the generalizability and performance of the classifiers on new unseen data from an emerging new event. In our work, we train an adversarial neural model to remove latent event-specific biases and improve the performance on tweet importance classification.