 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards Everyday Virtual Reality through Eye Tracking
Mar 29, 2022
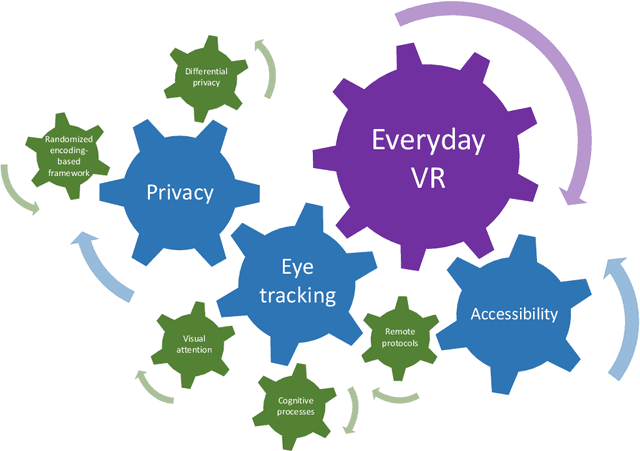

With developments in computer graphics, hardware technology, perception engineering, and human-computer interaction, virtual reality and virtual environments are becoming more integrated into our daily lives. Head-mounted displays, however, are still not used as frequently as other mobile devices such as smart phones and watches. With increased usage of this technology and the acclimation of humans to virtual application scenarios, it is possible that in the near future an everyday virtual reality paradigm will be realized. When considering the marriage of everyday virtual reality and head-mounted displays, eye tracking is an emerging technology that helps to assess human behaviors in a real time and non-intrusive way. Still, multiple aspects need to be researched before these technologies become widely available in daily life. Firstly, attention and cognition models in everyday scenarios should be thoroughly understood. Secondly, as eyes are related to visual biometrics, privacy preserving methodologies are necessary. Lastly, instead of studies or applications utilizing limited human participants with relatively homogeneous characteristics, protocols and use-cases for making such technology more accessible should be essential. In this work, taking the aforementioned points into account, a significant scientific push towards everyday virtual reality has been completed with three main research contributions.
Less is More: Surgical Phase Recognition from Timestamp Supervision
Feb 16, 2022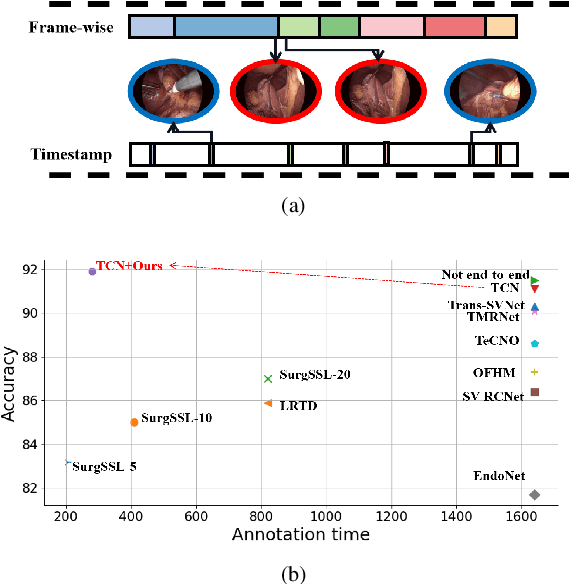
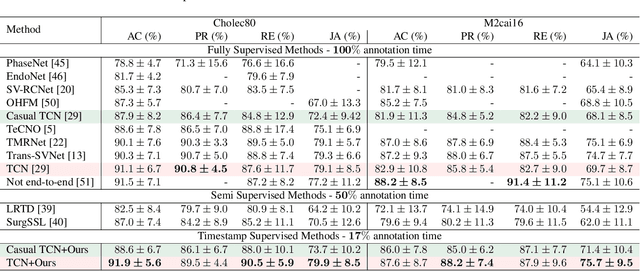
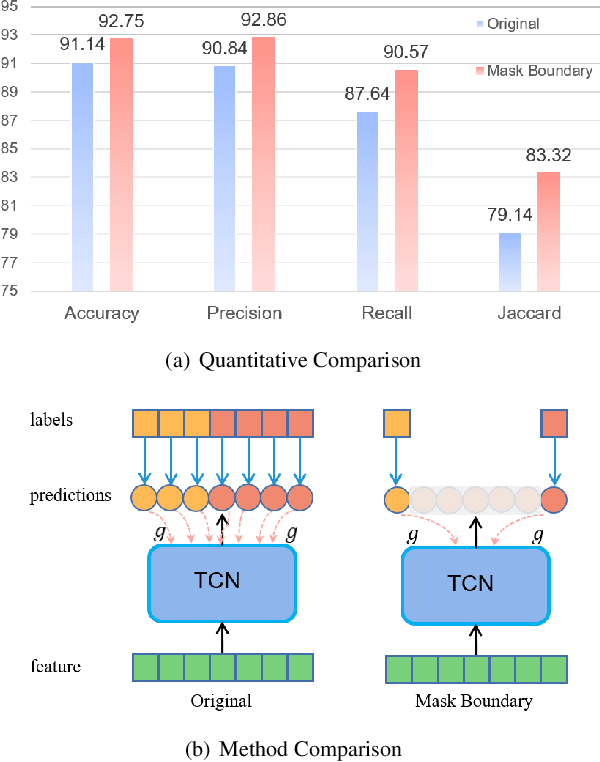
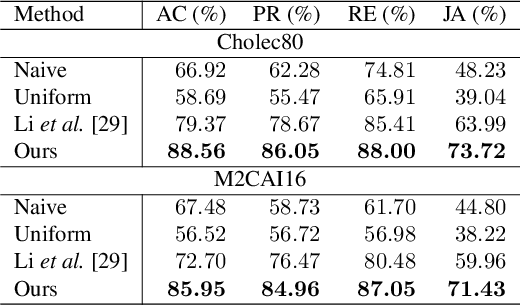
Surgical phase recognition is a fundamental task in computer-assisted surgery systems. Most existing works require expensive frame-wise annotations, which is very time-consuming. In this paper, we introduce timestamp supervision to surgical phase recognition for the first time, which only requires randomly labeling one frame for each phase in a video. With timestamp supervision, current methods in natural videos aim to generate pseudo labels of full frames. However, due to the surgical videos containing ambiguous boundaries, these methods would generate many noisy and inconsistent pseudo labels, leading to limited performance. We argue that less is more in surgical phase recognition,~\ie, less but discriminative pseudo labels outperform full but ambiguous frames. To this end, we propose a novel method called uncertainty-aware temporal diffusion to generate trustworthy pseudo labels. Our approach evaluates the confidence of generated pseudo labels based on uncertainty estimation. Then, we treat the annotated frames as anchors and make pseudo labels diffuse to both sides, starting from anchors and stopping at the high-uncertainty frames. In this way, our proposed method can generate contiguous confident pseudo labels while discarding the uncertain ones. Extensive experiments demonstrate that our method not only significantly save annotation cost, but also outperforms fully supervised methods. Moreover, our proposed approach can be used to clean noisy labels near boundaries and improve the performance of the current surgical phase recognition methods.
Online Graph Learning from Social Interactions
Mar 11, 2022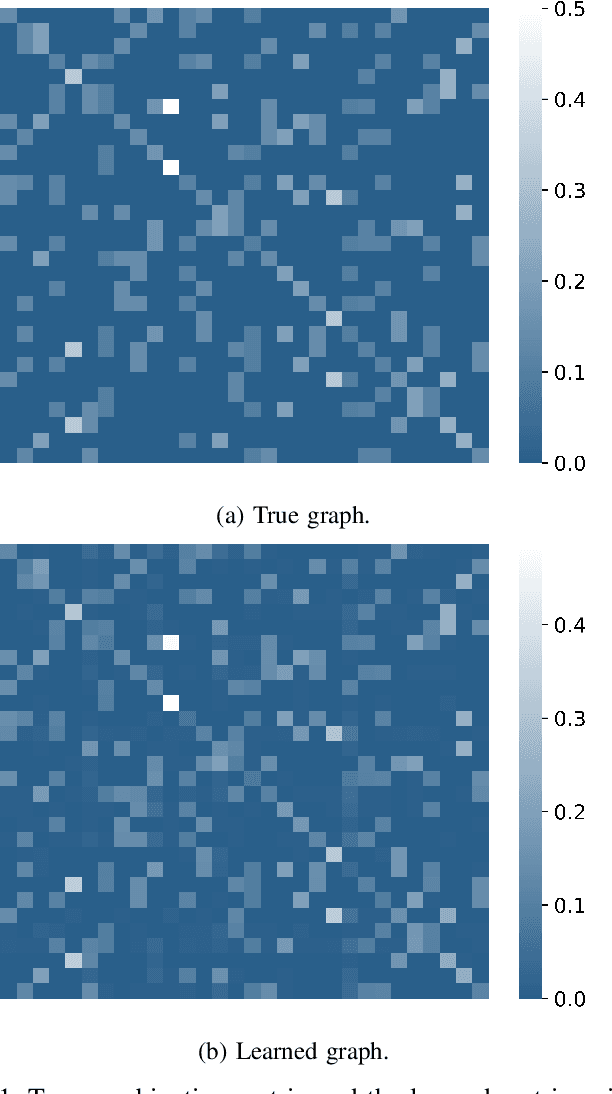
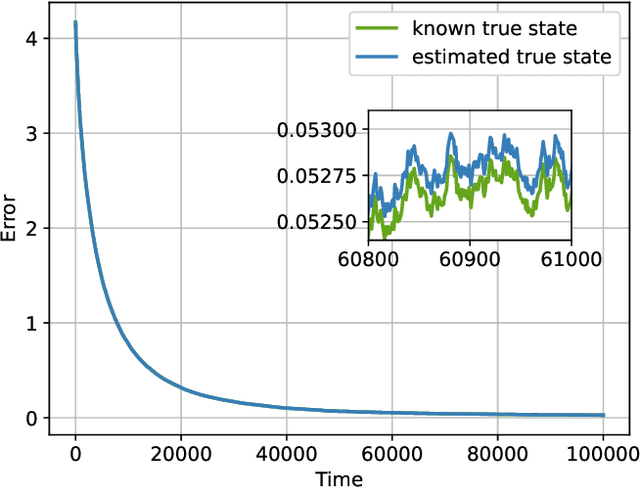
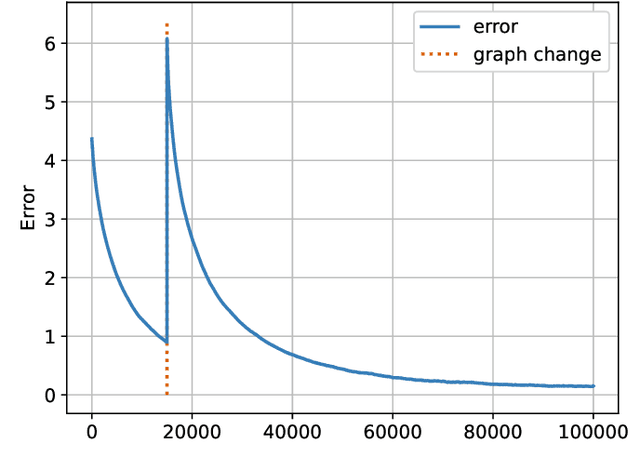
Social learning algorithms provide models for the formation of opinions over social networks resulting from local reasoning and peer-to-peer exchanges. Interactions occur over an underlying graph topology, which describes the flow of information and relative influence between pairs of agents. For a given graph topology, these algorithms allow for the prediction of formed opinions. In this work, we study the inverse problem. Given a social learning model and observations of the evolution of beliefs over time, we aim at identifying the underlying graph topology. The learned graph allows for the inference of pairwise influence between agents, the overall influence agents have over the behavior of the network, as well as the flow of information through the social network. The proposed algorithm is online in nature and can adapt dynamically to changes in the graph topology or the true hypothesis.
An Audit of Misinformation Filter Bubbles on YouTube: Bubble Bursting and Recent Behavior Changes
Mar 25, 2022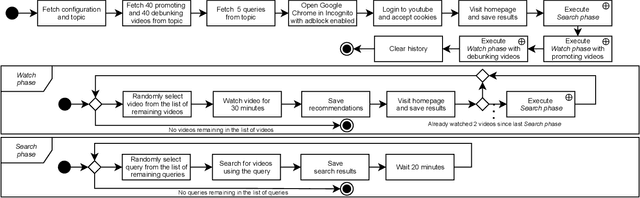


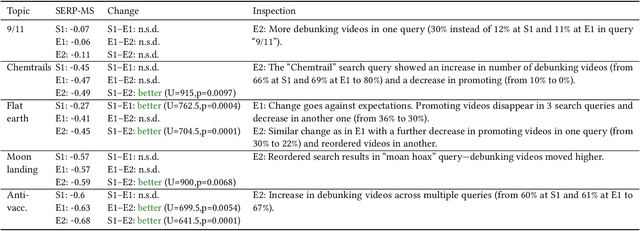
The negative effects of misinformation filter bubbles in adaptive systems have been known to researchers for some time. Several studies investigated, most prominently on YouTube, how fast a user can get into a misinformation filter bubble simply by selecting wrong choices from the items offered. Yet, no studies so far have investigated what it takes to burst the bubble, i.e., revert the bubble enclosure. We present a study in which pre-programmed agents (acting as YouTube users) delve into misinformation filter bubbles by watching misinformation promoting content (for various topics). Then, by watching misinformation debunking content, the agents try to burst the bubbles and reach more balanced recommendation mixes. We recorded the search results and recommendations, which the agents encountered, and analyzed them for the presence of misinformation. Our key finding is that bursting of a filter bubble is possible, albeit it manifests differently from topic to topic. Moreover, we observe that filter bubbles do not truly appear in some situations. We also draw a direct comparison with a previous study. Sadly, we did not find much improvements in misinformation occurrences, despite recent pledges by YouTube.
* RecSys '21: Fifteenth ACM Conference on Recommender System
SAFARI: Sparsity enabled Federated Learning with Limited and Unreliable Communications
Apr 05, 2022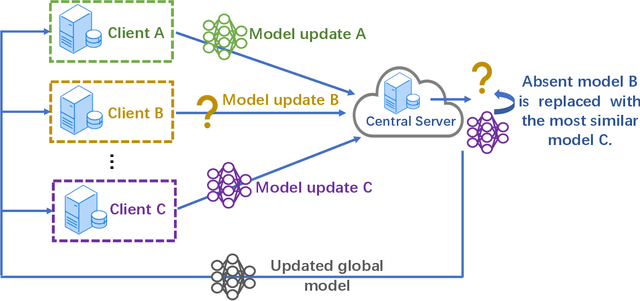
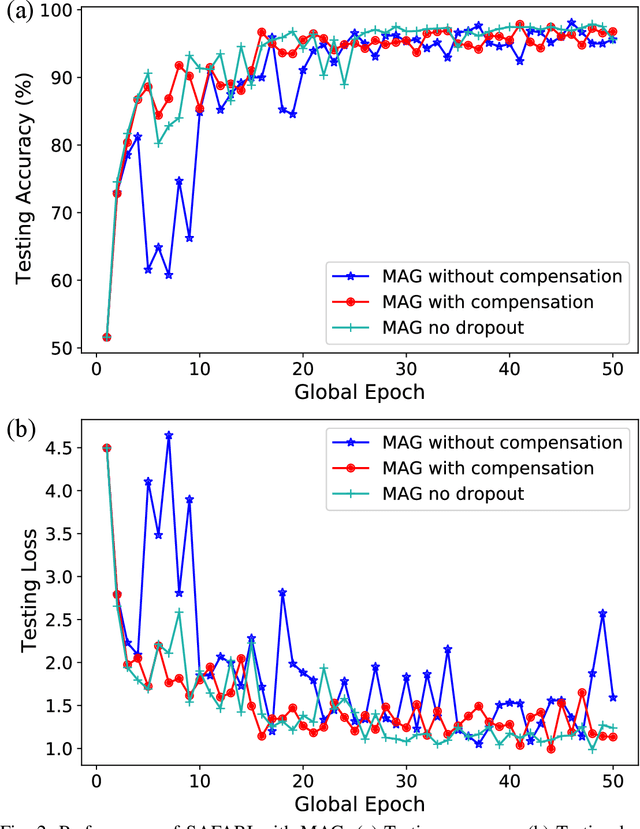
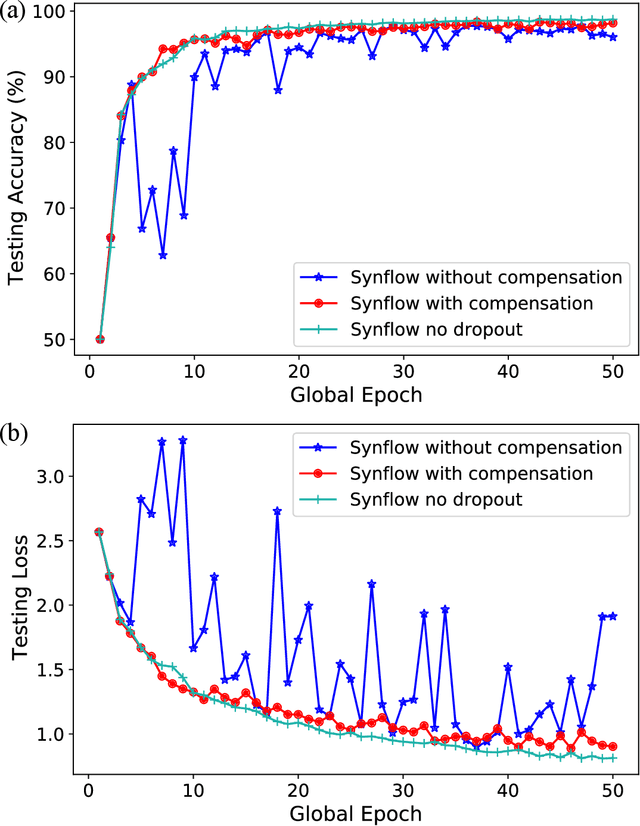
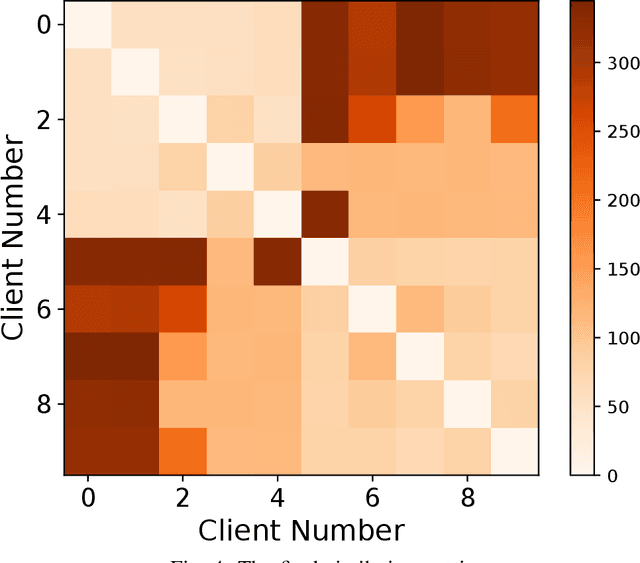
Federated learning (FL) enables edge devices to collaboratively learn a model in a distributed fashion. Many existing researches have focused on improving communication efficiency of high-dimensional models and addressing bias caused by local updates. However, most of FL algorithms are either based on reliable communications or assume fixed and known unreliability characteristics. In practice, networks could suffer from dynamic channel conditions and non-deterministic disruptions, with time-varying and unknown characteristics. To this end, in this paper we propose a sparsity enabled FL framework with both communication efficiency and bias reduction, termed as SAFARI. It makes novel use of a similarity among client models to rectify and compensate for bias that is resulted from unreliable communications. More precisely, sparse learning is implemented on local clients to mitigate communication overhead, while to cope with unreliable communications, a similarity-based compensation method is proposed to provide surrogates for missing model updates. We analyze SAFARI under bounded dissimilarity and with respect to sparse models. It is demonstrated that SAFARI under unreliable communications is guaranteed to converge at the same rate as the standard FedAvg with perfect communications. Implementations and evaluations on CIFAR-10 dataset validate the effectiveness of SAFARI by showing that it can achieve the same convergence speed and accuracy as FedAvg with perfect communications, with up to 80% of the model weights being pruned and a high percentage of client updates missing in each round.
Reinforcement Learning Based Query Vertex Ordering Model for Subgraph Matching
Jan 25, 2022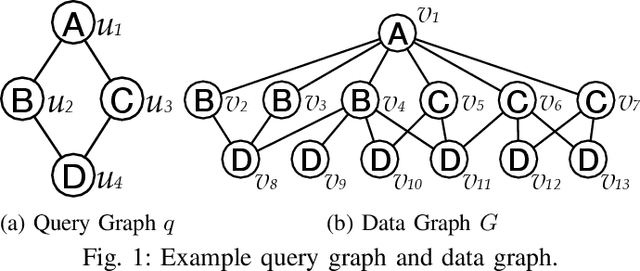
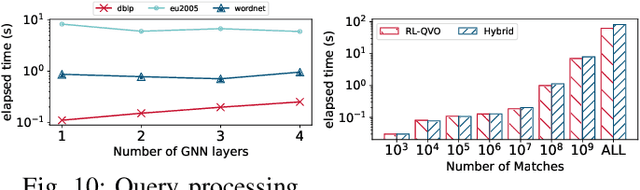
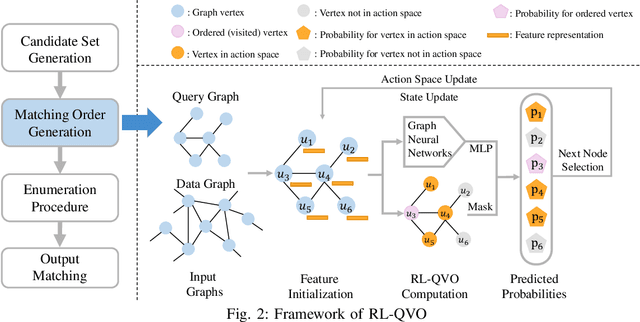
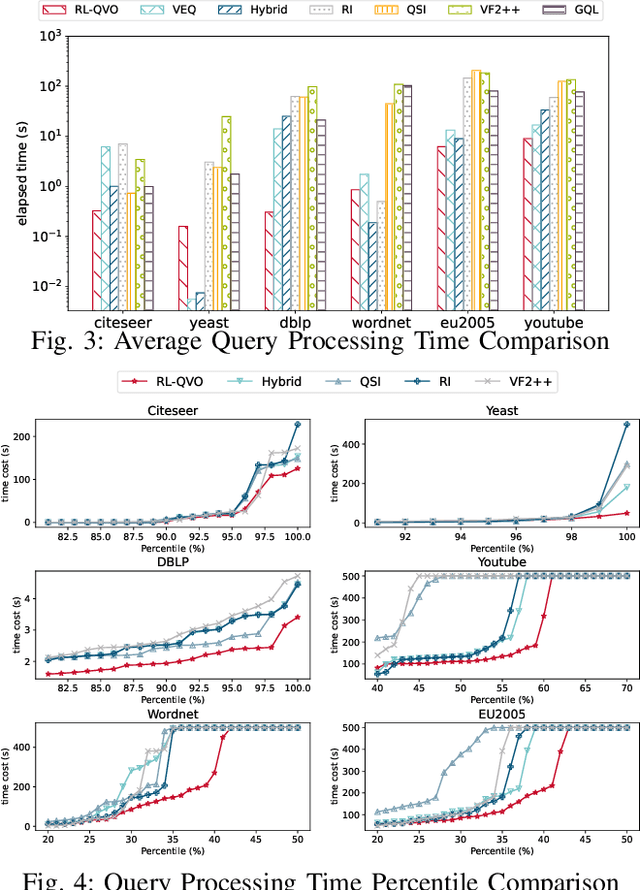
Subgraph matching is a fundamental problem in various fields that use graph structured data. Subgraph matching algorithms enumerate all isomorphic embeddings of a query graph q in a data graph G. An important branch of matching algorithms exploit the backtracking search approach which recursively extends intermediate results following a matching order of query vertices. It has been shown that the matching order plays a critical role in time efficiency of these backtracking based subgraph matching algorithms. In recent years, many advanced techniques for query vertex ordering (i.e., matching order generation) have been proposed to reduce the unpromising intermediate results according to the preset heuristic rules. In this paper, for the first time we apply the Reinforcement Learning (RL) and Graph Neural Networks (GNNs) techniques to generate the high-quality matching order for subgraph matching algorithms. Instead of using the fixed heuristics to generate the matching order, our model could capture and make full use of the graph information, and thus determine the query vertex order with the adaptive learning-based rule that could significantly reduces the number of redundant enumerations. With the help of the reinforcement learning framework, our model is able to consider the long-term benefits rather than only consider the local information at current ordering step.Extensive experiments on six real-life data graphs demonstrate that our proposed matching order generation technique could reduce up to two orders of magnitude of query processing time compared to the state-of-the-art algorithms.
NL-FCOS: Improving FCOS through Non-Local Modules for Object Detection
Mar 29, 2022


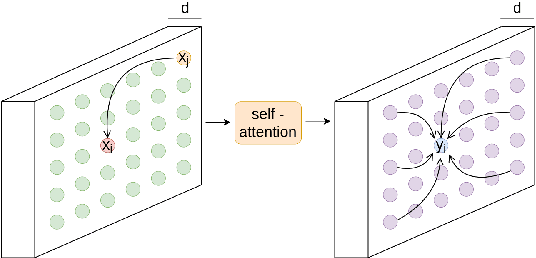
During the last years, we have seen significant advances in the object detection task, mainly due to the outperforming results of convolutional neural networks. In this vein, anchor-based models have achieved the best results. However, these models require prior information about the aspect and scales of target objects, needing more hyperparameters to fit. In addition, using anchors to fit bounding boxes seems far from how our visual system does the same visual task. Instead, our visual system uses the interactions of different scene parts to semantically identify objects, called perceptual grouping. An object detection methodology closer to the natural model is anchor-free detection, where models like FCOS or Centernet have shown competitive results, but these have not yet exploited the concept of perceptual grouping. Therefore, to increase the effectiveness of anchor-free models keeping the inference time low, we propose to add non-local attention (NL modules) modules to boost the feature map of the underlying backbone. NL modules implement the perceptual grouping mechanism, allowing receptive fields to cooperate in visual representation learning. We show that non-local modules combined with an FCOS head (NL-FCOS) are practical and efficient. Thus, we establish state-of-the-art performance in clothing detection and handwritten amount recognition problems.
Label Augmentation via Time-based Knowledge Distillation for Financial Anomaly Detection
Jan 05, 2021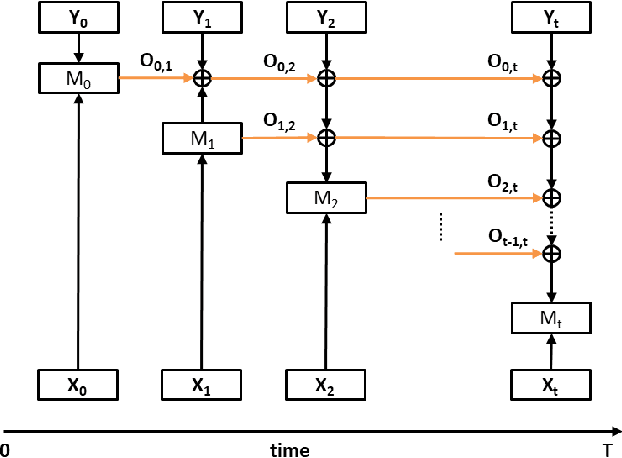

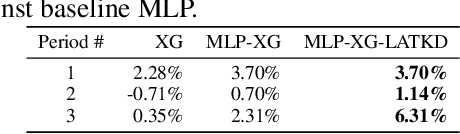
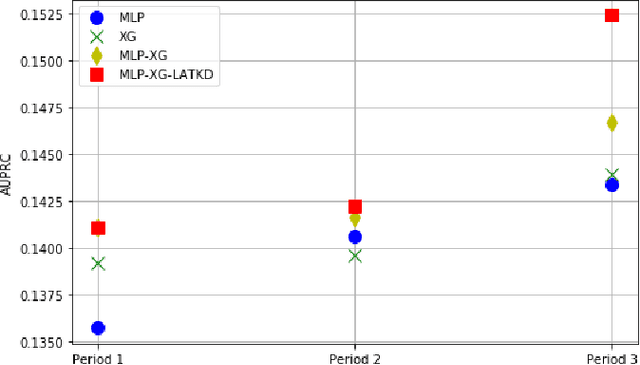
Detecting anomalies has become increasingly critical to the financial service industry. Anomalous events are often indicative of illegal activities such as fraud, identity theft, network intrusion, account takeover, and money laundering. Financial anomaly detection use cases face serious challenges due to the dynamic nature of the underlying patterns especially in adversarial environments such as constantly changing fraud tactics. While retraining the models with the new patterns is absolutely essential; keeping up with the rapid changes introduces other challenges as it moves the model away from older patterns or continuously grows the size of the training data. The resulting data growth is hard to manage and it reduces the agility of the models' response to the latest attacks. Due to the data size limitations and the need to track the latest patterns, older time periods are often dropped in practice, which in turn, causes vulnerabilities. In this study, we propose a label augmentation approach to utilize the learning from older models to boost the latest. Experimental results show that the proposed approach provides a significant reduction in training time, while providing potential performance improvement.
Optimizing Short-Time Fourier Transform Parameters via Gradient Descent
Oct 28, 2020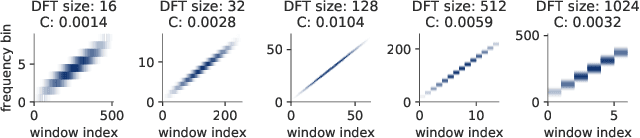
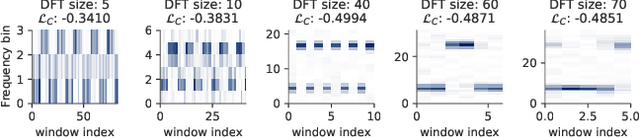
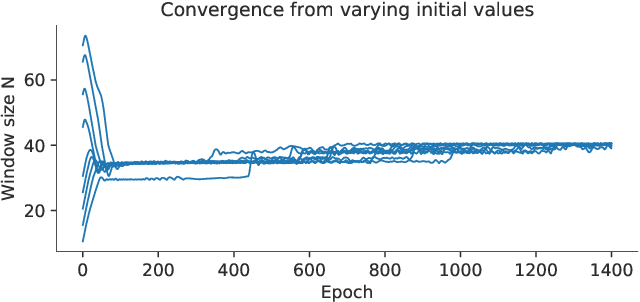
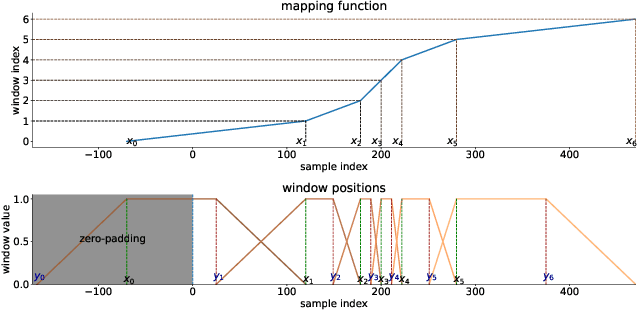
The Short-Time Fourier Transform (STFT) has been a staple of signal processing, often being the first step for many audio tasks. A very familiar process when using the STFT is the search for the best STFT parameters, as they often have significant side effects if chosen poorly. These parameters are often defined in terms of an integer number of samples, which makes their optimization non-trivial. In this paper we show an approach that allows us to obtain a gradient for STFT parameters with respect to arbitrary cost functions, and thus enable the ability to employ gradient descent optimization of quantities like the STFT window length, or the STFT hop size. We do so for parameter values that stay constant throughout an input, but also for cases where these parameters have to dynamically change over time to accommodate varying signal characteristics.
Lower Bounds and Optimal Algorithms for Smooth and Strongly Convex Decentralized Optimization Over Time-Varying Networks
Jun 08, 2021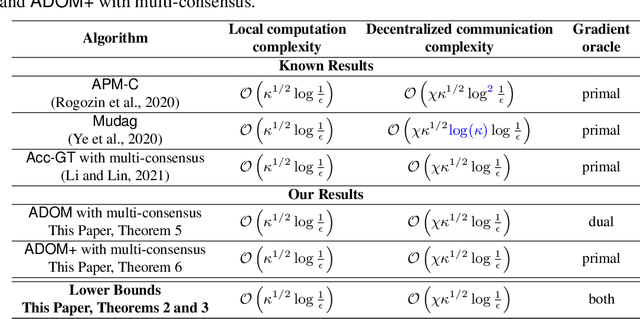
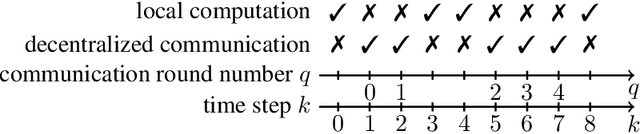

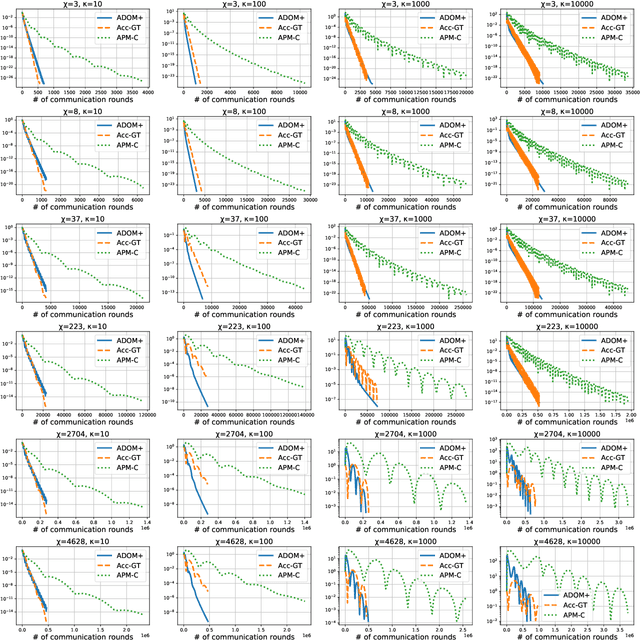
We consider the task of minimizing the sum of smooth and strongly convex functions stored in a decentralized manner across the nodes of a communication network whose links are allowed to change in time. We solve two fundamental problems for this task. First, we establish the first lower bounds on the number of decentralized communication rounds and the number of local computations required to find an $\epsilon$-accurate solution. Second, we design two optimal algorithms that attain these lower bounds: (i) a variant of the recently proposed algorithm ADOM (Kovalev et al., 2021) enhanced via a multi-consensus subroutine, which is optimal in the case when access to the dual gradients is assumed, and (ii) a novel algorithm, called ADOM+, which is optimal in the case when access to the primal gradients is assumed. We corroborate the theoretical efficiency of these algorithms by performing an experimental comparison with existing state-of-the-art methods.