 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
On the Fitness Landscapes of Interdependency Models in the Travelling Thief Problem
Feb 28, 2022
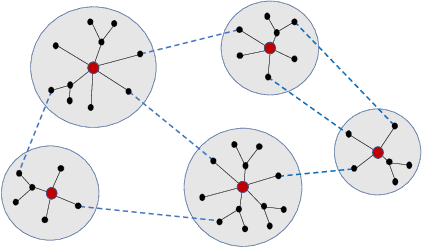
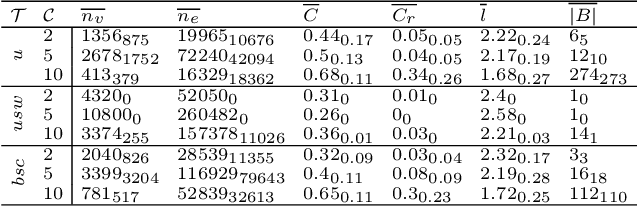
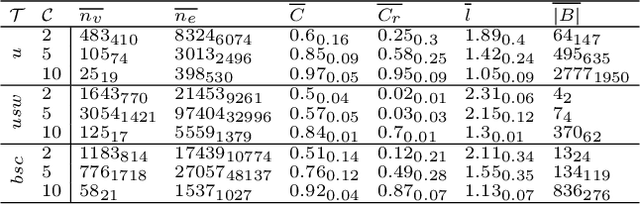
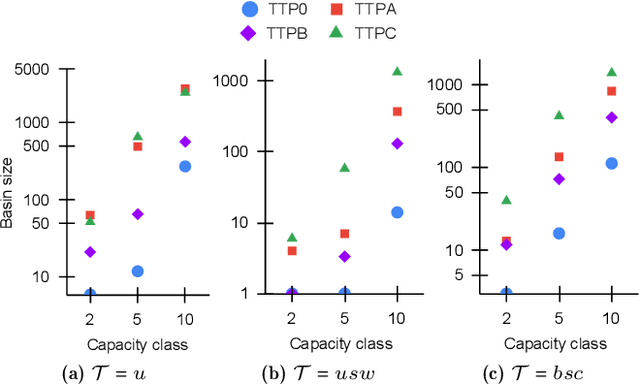
Since its inception in 2013, the Travelling Thief Problem (TTP) has been widely studied as an example of problems with multiple interconnected sub-problems. The dependency in this model arises when tying the travelling time of the "thief" to the weight of the knapsack. However, other forms of dependency as well as combinations of dependencies should be considered for investigation, as they are often found in complex real-world problems. Our goal is to study the impact of different forms of dependency in the TTP using a simple local search algorithm. To achieve this, we use Local Optima Networks, a technique for analysing the fitness landscape.
Enhanced Preamble Based MAC Mechanism for IIoT-oriented PLC Network
Mar 22, 2022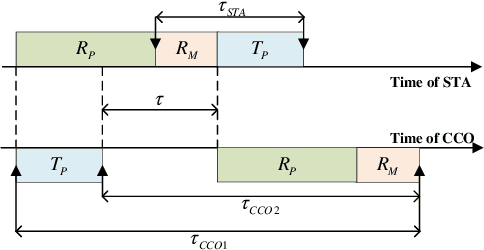
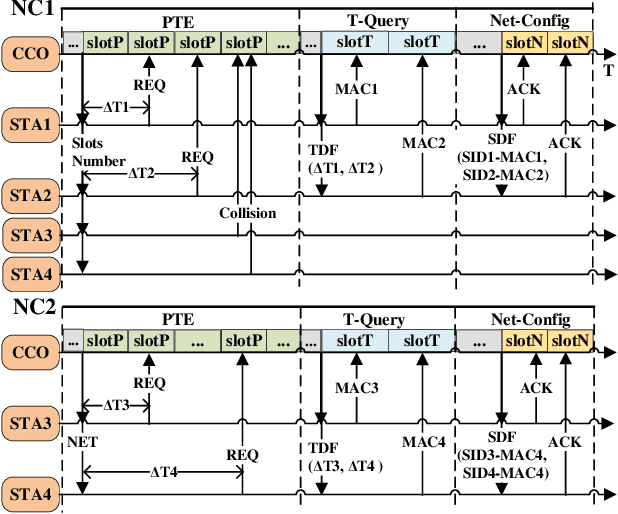
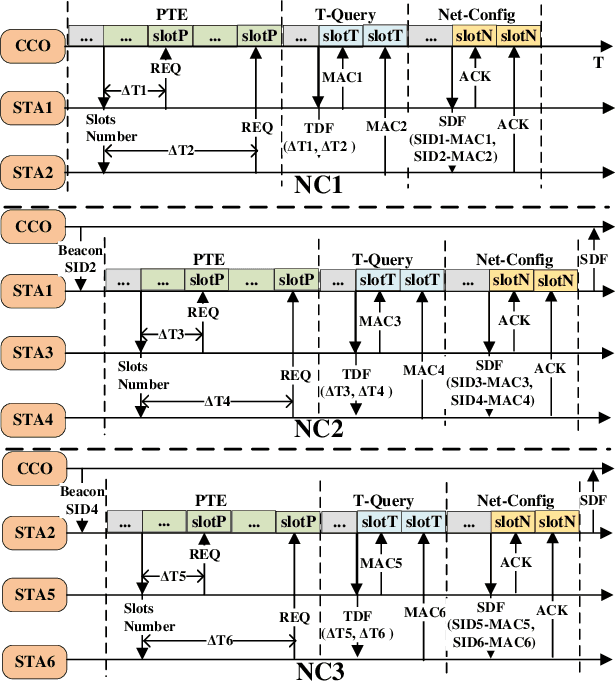
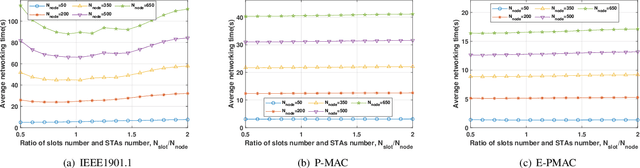
In this paper, we propose an enhanced preamble based media access control mechanism (E-PMAC), which can be applied in power line communication (PLC) network for Industrial Internet of Things (IIoT). We introduce detailed technologies used in E-PMAC, including delay calibration mechanism, preamble design, and slot allocation algorithm. With these technologies, E-PMAC is more robust than existing preamble based MAC mechanism (P-MAC). Besides, we analyze the disadvantage of P-MAC in multi-layer networking and design the networking process of E-PMAC to accelerate networking process. We analyze the complexity of networking process in P-MAC and E-PMAC and prove that E-PMAC has lower complexity than P-MAC. Finally, we simulate the single-layer networking and multi-layer networking of E-PMAC, P-MAC, and existing PLC protocol, i.e. , IEEE1901.1. The simulation results indicate that E-PMAC spends much less time in networking than IEEE1901.1 and P-MAC. Finally, with our work, a PLC network based on E-PMAC mechanism can be realized.
Achieving Conversational Goals with Unsupervised Post-hoc Knowledge Injection
Mar 22, 2022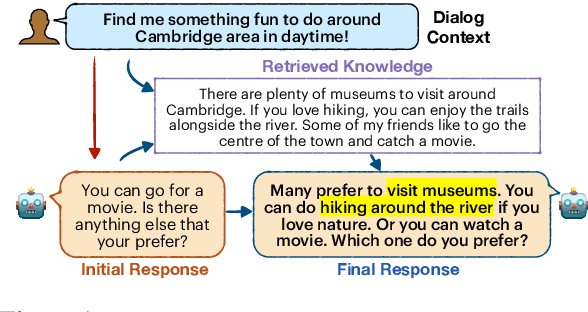
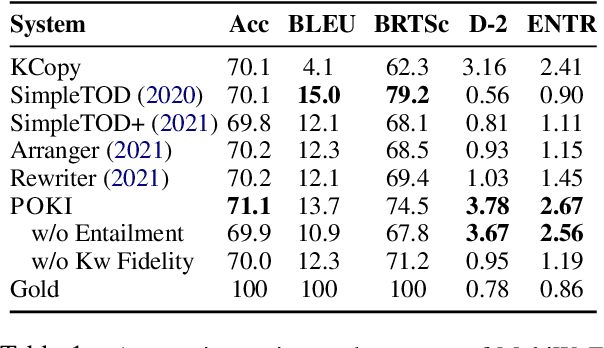
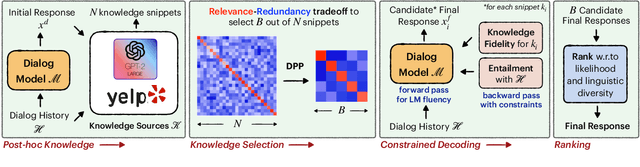
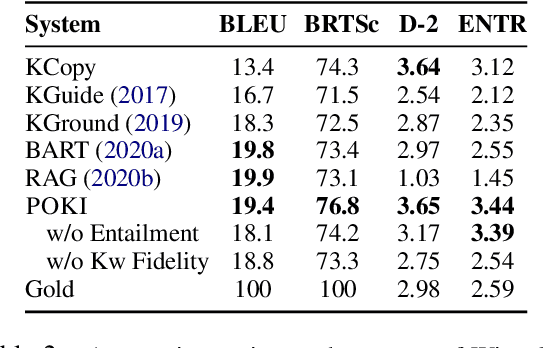
A limitation of current neural dialog models is that they tend to suffer from a lack of specificity and informativeness in generated responses, primarily due to dependence on training data that covers a limited variety of scenarios and conveys limited knowledge. One way to alleviate this issue is to extract relevant knowledge from external sources at decoding time and incorporate it into the dialog response. In this paper, we propose a post-hoc knowledge-injection technique where we first retrieve a diverse set of relevant knowledge snippets conditioned on both the dialog history and an initial response from an existing dialog model. We construct multiple candidate responses, individually injecting each retrieved snippet into the initial response using a gradient-based decoding method, and then select the final response with an unsupervised ranking step. Our experiments in goal-oriented and knowledge-grounded dialog settings demonstrate that human annotators judge the outputs from the proposed method to be more engaging and informative compared to responses from prior dialog systems. We further show that knowledge-augmentation promotes success in achieving conversational goals in both experimental settings.
On the complexity of All $\varepsilon$-Best Arms Identification
Feb 13, 2022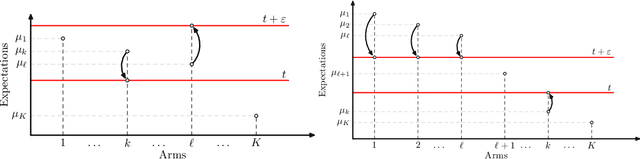
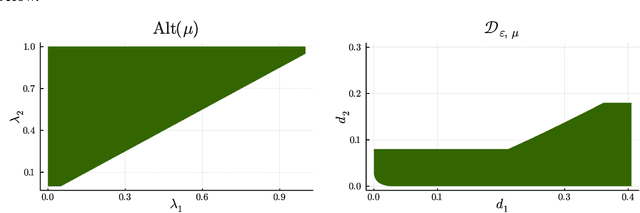
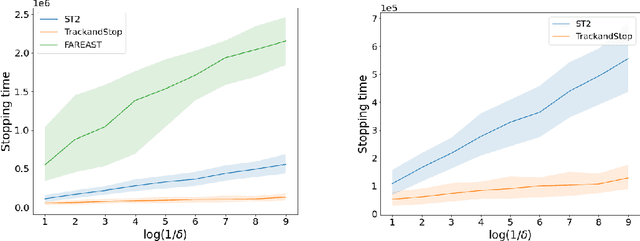
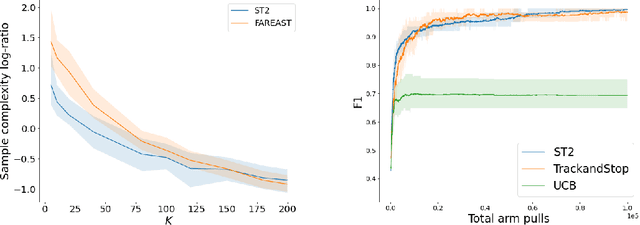
We consider the problem introduced by \cite{Mason2020} of identifying all the $\varepsilon$-optimal arms in a finite stochastic multi-armed bandit with Gaussian rewards. In the fixed confidence setting, we give a lower bound on the number of samples required by any algorithm that returns the set of $\varepsilon$-good arms with a failure probability less than some risk level $\delta$. This bound writes as $T_{\varepsilon}^*(\mu)\log(1/\delta)$, where $T_{\varepsilon}^*(\mu)$ is a characteristic time that depends on the vector of mean rewards $\mu$ and the accuracy parameter $\varepsilon$. We also provide an efficient numerical method to solve the convex max-min program that defines the characteristic time. Our method is based on a complete characterization of the alternative bandit instances that the optimal sampling strategy needs to rule out, thus making our bound tighter than the one provided by \cite{Mason2020}. Using this method, we propose a Track-and-Stop algorithm that identifies the set of $\varepsilon$-good arms w.h.p and enjoys asymptotic optimality (when $\delta$ goes to zero) in terms of the expected sample complexity. Finally, using numerical simulations, we demonstrate our algorithm's advantage over state-of-the-art methods, even for moderate values of the risk parameter.
Multiple Convex Objects Image Segmentation via Proximal Alternating Direction Method of Multipliers
Mar 22, 2022
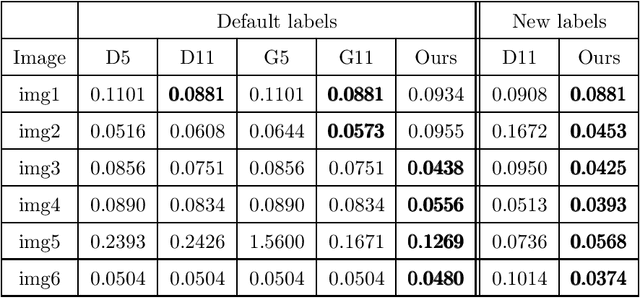

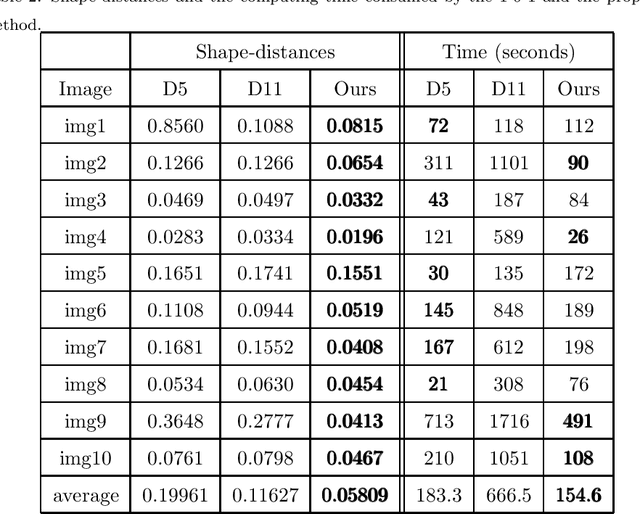
This paper focuses on the issue of image segmentation with convex shape prior. Firstly, we use binary function to represent convex object(s). The convex shape prior turns out to be a simple quadratic inequality constraint on the binary indicator function associated with each object. An image segmentation model incorporating convex shape prior into a probability-based method is proposed. Secondly, a new algorithm is designed to solve involved optimization problem, which is a challenging task because of the quadratic inequality constraint. To tackle this difficulty, we relax and linearize the quadratic inequality constraint to reduce it to solve a sequence of convex minimization problems. For each convex problem, an efficient proximal alternating direction method of multipliers is developed to solve it. The convergence of the algorithm follows some existing results in the optimization literature. Moreover, an interactive procedure is introduced to improve the accuracy of segmentation gradually. Numerical experiments on natural and medical images demonstrate that the proposed method is superior to some existing methods in terms of segmentation accuracy and computational time.
Mapping Temporary Slums from Satellite Imagery using a Semi-Supervised Approach
Apr 09, 2022



One billion people worldwide are estimated to be living in slums, and documenting and analyzing these regions is a challenging task. As compared to regular slums; the small, scattered and temporary nature of temporary slums makes data collection and labeling tedious and time-consuming. To tackle this challenging problem of temporary slums detection, we present a semi-supervised deep learning segmentation-based approach; with the strategy to detect initial seed images in the zero-labeled data settings. A small set of seed samples (32 in our case) are automatically discovered by analyzing the temporal changes, which are manually labeled to train a segmentation and representation learning module. The segmentation module gathers high dimensional image representations, and the representation learning module transforms image representations into embedding vectors. After that, a scoring module uses the embedding vectors to sample images from a large pool of unlabeled images and generates pseudo-labels for the sampled images. These sampled images with their pseudo-labels are added to the training set to update the segmentation and representation learning modules iteratively. To analyze the effectiveness of our technique, we construct a large geographically marked dataset of temporary slums. This dataset constitutes more than 200 potential temporary slum locations (2.28 square kilometers) found by sieving sixty-eight thousand images from 12 metropolitan cities of Pakistan covering 8000 square kilometers. Furthermore, our proposed method outperforms several competitive semi-supervised semantic segmentation baselines on a similar setting. The code and the dataset will be made publicly available.
Multi-Task Deep Residual Echo Suppression with Echo-aware Loss
Feb 21, 2022

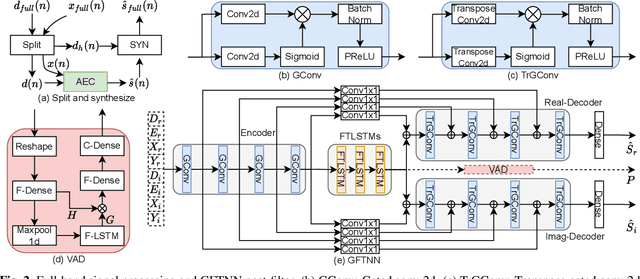
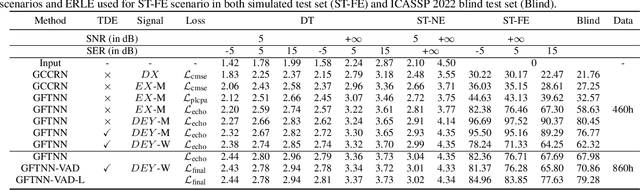
This paper introduces the NWPU Team's entry to the ICASSP 2022 AEC Challenge. We take a hybrid approach that cascades a linear AEC with a neural post-filter. The former is used to deal with the linear echo components while the latter suppresses the residual non-linear echo components. We use gated convolutional F-T-LSTM neural network (GFTNN) as the backbone and shape the post-filter by a multi-task learning (MTL) framework, where a voice activity detection (VAD) module is adopted as an auxiliary task along with echo suppression, with the aim to avoid over suppression that may cause speech distortion. Moreover, we adopt an echo-aware loss function, where the mean square error (MSE) loss can be optimized particularly for every time-frequency bin (TF-bin) according to the signal-to-echo ratio (SER), leading to further suppression on the echo. Extensive ablation study shows that the time delay estimation (TDE) module in neural post-filter leads to better perceptual quality, and an adaptive filter with better convergence will bring consistent performance gain for the post-filter. Besides, we find that using the linear echo as the input of our neural post-filter is a better choice than using the reference signal directly. In the ICASSP 2022 AEC-Challenge, our approach has ranked the 1st place on word accuracy (WAcc) (0.817) and the 3rd place on both mean opinion score (MOS) (4.502) and the final score (0.864).
Language modeling via stochastic processes
Mar 21, 2022
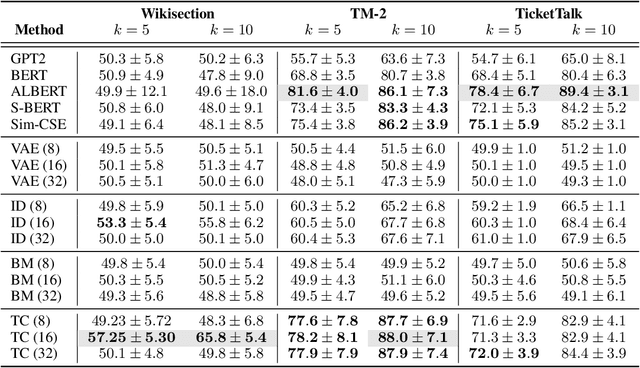
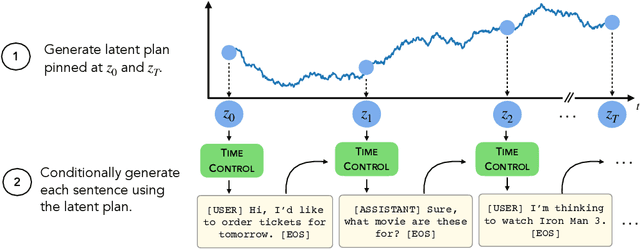
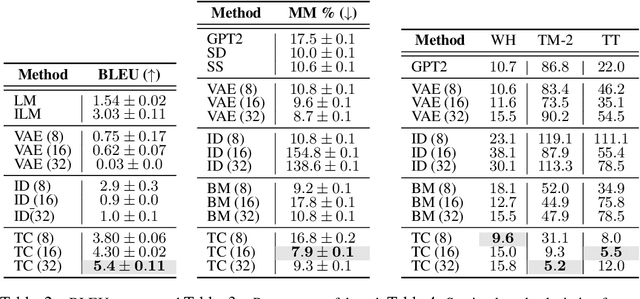
Modern language models can generate high-quality short texts. However, they often meander or are incoherent when generating longer texts. These issues arise from the next-token-only language modeling objective. To address these issues, we introduce Time Control (TC), a language model that implicitly plans via a latent stochastic process. TC does this by learning a representation which maps the dynamics of how text changes in a document to the dynamics of a stochastic process of interest. Using this representation, the language model can generate text by first implicitly generating a document plan via a stochastic process, and then generating text that is consistent with this latent plan. Compared to domain-specific methods and fine-tuning GPT2 across a variety of text domains, TC improves performance on text infilling and discourse coherence. On long text generation settings, TC preserves the text structure both in terms of ordering (up to +40% better) and text length consistency (up to +17% better). Human evaluators also prefer TC's output 28.6% more than the baselines.
3D-SiamRPN: An End-to-End Learning Method for Real-Time 3D Single Object Tracking Using Raw Point Cloud
Aug 12, 2021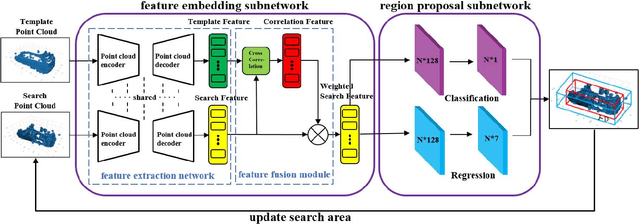


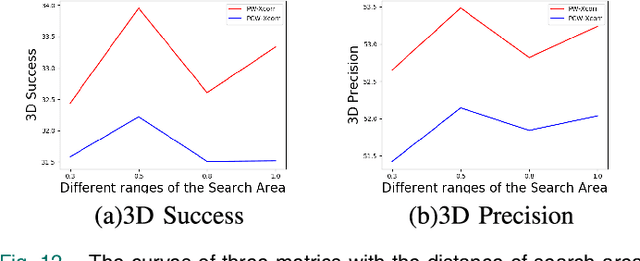
3D single object tracking is a key issue for autonomous following robot, where the robot should robustly track and accurately localize the target for efficient following. In this paper, we propose a 3D tracking method called 3D-SiamRPN Network to track a single target object by using raw 3D point cloud data. The proposed network consists of two subnetworks. The first subnetwork is feature embedding subnetwork which is used for point cloud feature extraction and fusion. In this subnetwork, we first use PointNet++ to extract features of point cloud from template and search branches. Then, to fuse the information of features in the two branches and obtain their similarity, we propose two cross correlation modules, named Pointcloud-wise and Point-wise respectively. The second subnetwork is region proposal network(RPN), which is used to get the final 3D bounding box of the target object based on the fusion feature from cross correlation modules. In this subnetwork, we utilize the regression and classification branches of a region proposal subnetwork to obtain proposals and scores, thus get the final 3D bounding box of the target object. Experimental results on KITTI dataset show that our method has a competitive performance in both Success and Precision compared to the state-of-the-art methods, and could run in real-time at 20.8 FPS. Additionally, experimental results on H3D dataset demonstrate that our method also has good generalization ability and could achieve good tracking performance in a new scene without re-training.
GERE: Generative Evidence Retrieval for Fact Verification
Apr 12, 2022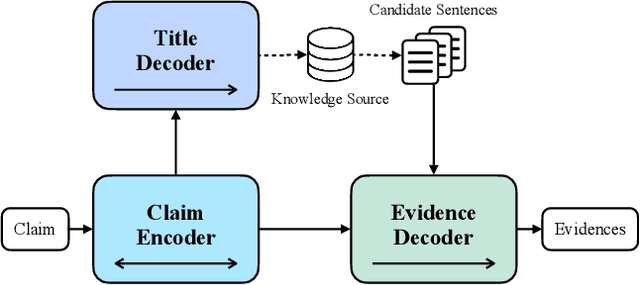
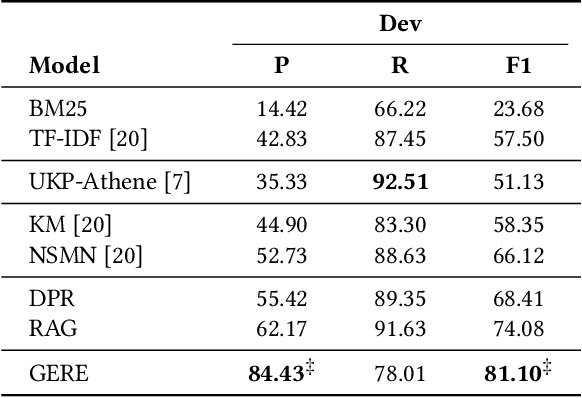
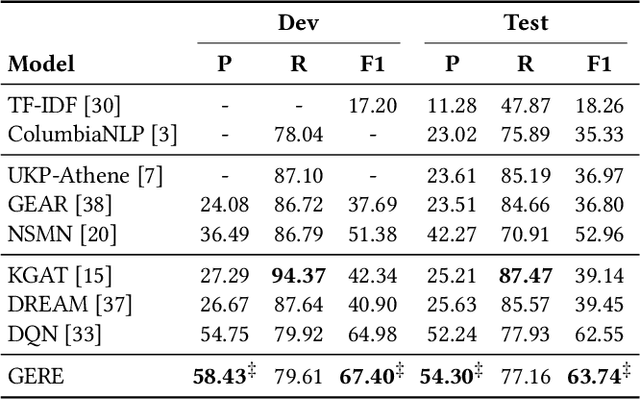
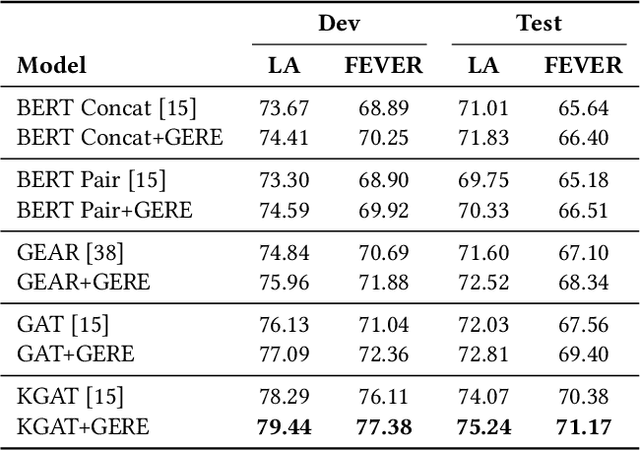
Fact verification (FV) is a challenging task which aims to verify a claim using multiple evidential sentences from trustworthy corpora, e.g., Wikipedia. Most existing approaches follow a three-step pipeline framework, including document retrieval, sentence retrieval and claim verification. High-quality evidences provided by the first two steps are the foundation of the effective reasoning in the last step. Despite being important, high-quality evidences are rarely studied by existing works for FV, which often adopt the off-the-shelf models to retrieve relevant documents and sentences in an "index-retrieve-then-rank" fashion. This classical approach has clear drawbacks as follows: i) a large document index as well as a complicated search process is required, leading to considerable memory and computational overhead; ii) independent scoring paradigms fail to capture the interactions among documents and sentences in ranking; iii) a fixed number of sentences are selected to form the final evidence set. In this work, we propose \textit{GERE}, the first system that retrieves evidences in a generative fashion, i.e., generating the document titles as well as evidence sentence identifiers. This enables us to mitigate the aforementioned technical issues since: i) the memory and computational cost is greatly reduced because the document index is eliminated and the heavy ranking process is replaced by a light generative process; ii) the dependency between documents and that between sentences could be captured via sequential generation process; iii) the generative formulation allows us to dynamically select a precise set of relevant evidences for each claim. The experimental results on the FEVER dataset show that GERE achieves significant improvements over the state-of-the-art baselines, with both time-efficiency and memory-efficiency.