 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Digital synchronization for continuous-variable quantum key distribution
Mar 17, 2022
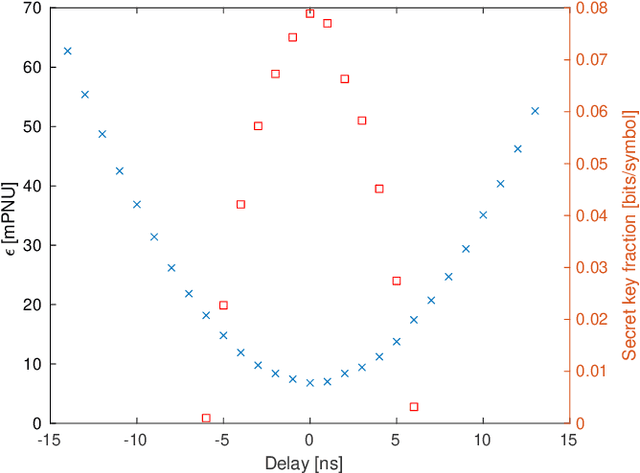
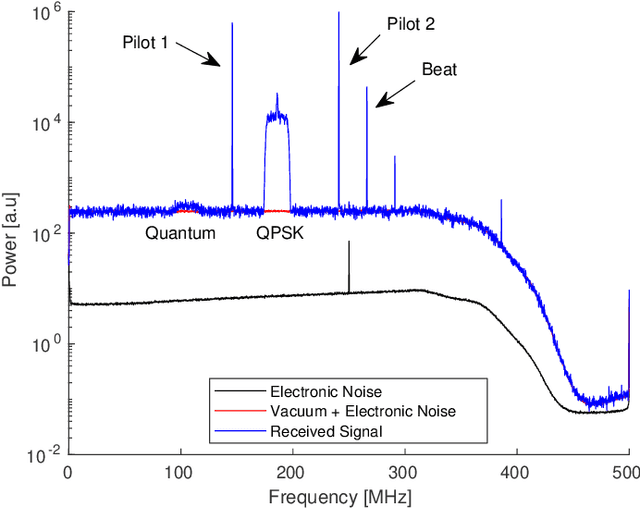
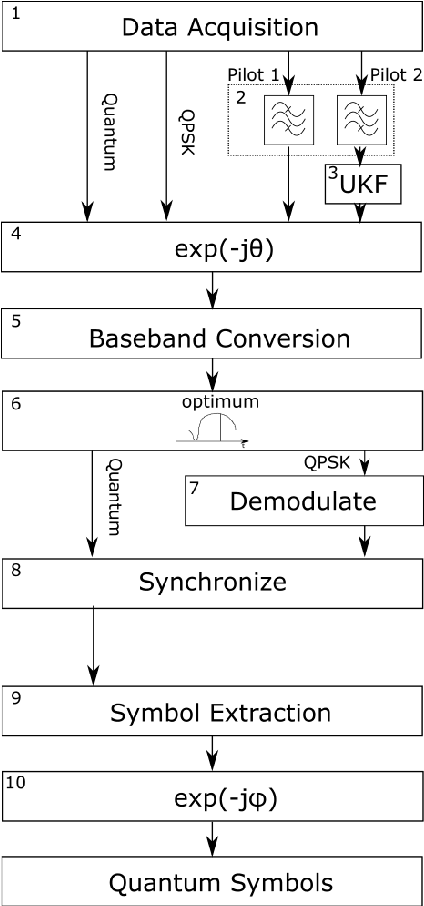

Continuous variable quantum key distribution (CV-QKD) is a promising emerging technology for the distribution of secure keys for symmetric encryption. It can be readily implemented using commercial off-the-shelf optical telecommunications components. A key requirement of the CV-QKD receiver is the ability to measure the quantum states at the correct time instance and rate using the correct orthogonal observables, referred to as synchronization. We propose a digital synchronization procedure for a modern CV-QKD system with locally generated local oscillator for coherent reception. Our proposed method is modulation format independent allowing it to be used in a variety of CV-QKD systems. We experimentally investigate its performance with a Gaussian modulated CV-QKD system operating over a 10-20 km span of standard single mode fibre. Since the procedure does not require hardware modifications it paves the way for cost-effective QKD solutions that can adapt rapidly to changing environmental conditions.
FLOAT: Factorized Learning of Object Attributes for Improved Multi-object Multi-part Scene Parsing
Mar 30, 2022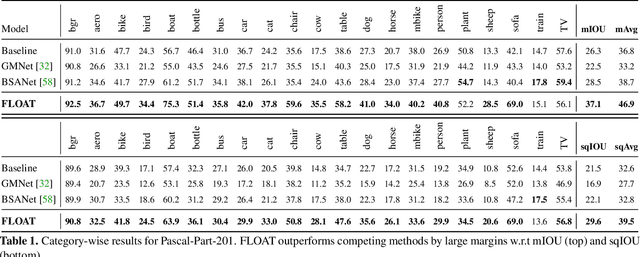
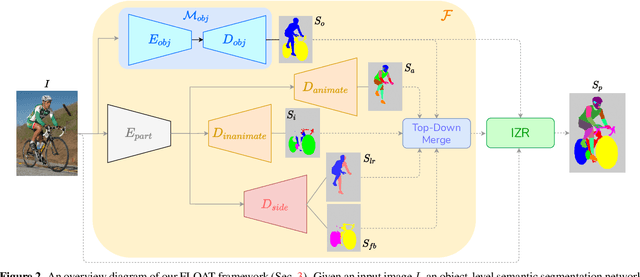
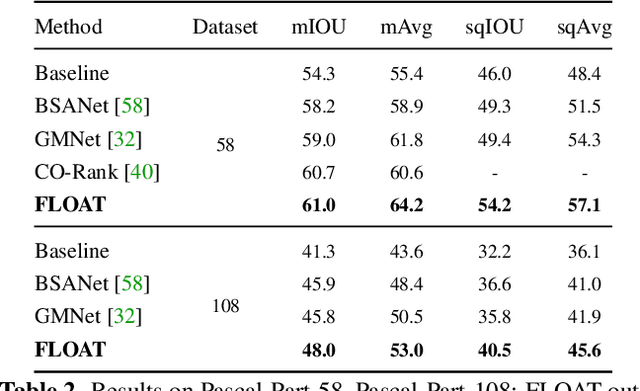
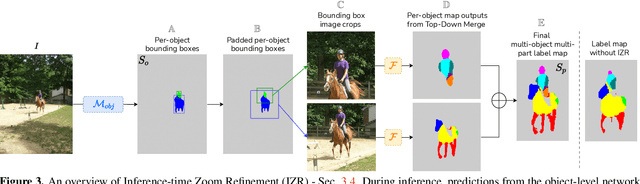
Multi-object multi-part scene parsing is a challenging task which requires detecting multiple object classes in a scene and segmenting the semantic parts within each object. In this paper, we propose FLOAT, a factorized label space framework for scalable multi-object multi-part parsing. Our framework involves independent dense prediction of object category and part attributes which increases scalability and reduces task complexity compared to the monolithic label space counterpart. In addition, we propose an inference-time 'zoom' refinement technique which significantly improves segmentation quality, especially for smaller objects/parts. Compared to state of the art, FLOAT obtains an absolute improvement of 2.0% for mean IOU (mIOU) and 4.8% for segmentation quality IOU (sqIOU) on the Pascal-Part-58 dataset. For the larger Pascal-Part-108 dataset, the improvements are 2.1% for mIOU and 3.9% for sqIOU. We incorporate previously excluded part attributes and other minor parts of the Pascal-Part dataset to create the most comprehensive and challenging version which we dub Pascal-Part-201. FLOAT obtains improvements of 8.6% for mIOU and 7.5% for sqIOU on the new dataset, demonstrating its parsing effectiveness across a challenging diversity of objects and parts. The code and datasets are available at floatseg.github.io.
Exemplar Learning for Medical Image Segmentation
Apr 03, 2022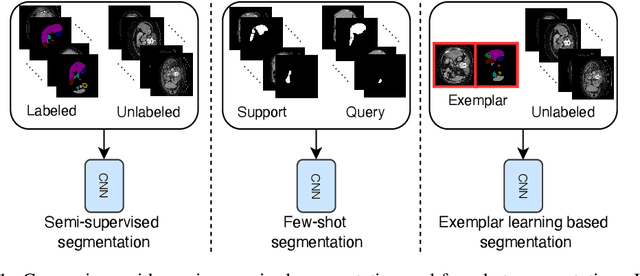

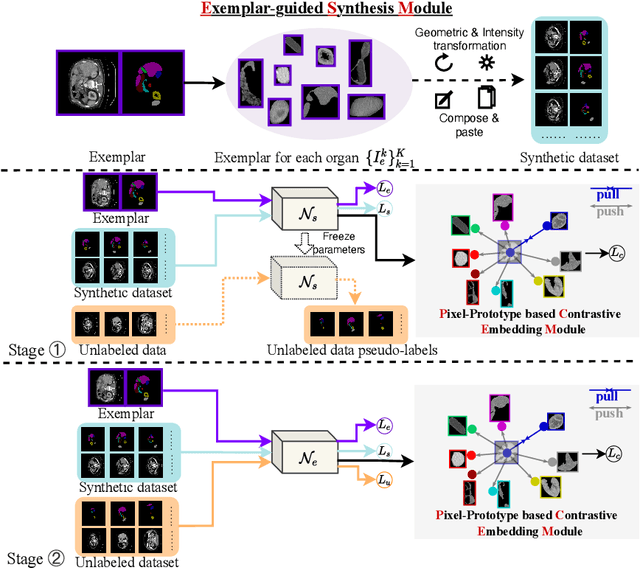
Medical image annotation typically requires expert knowledge and hence incurs time-consuming and expensive data annotation costs. To reduce this burden, we propose a novel learning scenario, Exemplar Learning (EL), to explore automated learning processes for medical image segmentation from a single annotated image example. This innovative learning task is particularly suitable for medical image segmentation, where all categories of organs can be presented in one single image for annotation all at once. To address this challenging EL task, we propose an Exemplar Learning-based Synthesis Net (ELSNet) framework for medical image segmentation that enables innovative exemplar-based data synthesis, pixel-prototype based contrastive embedding learning, and pseudo-label based exploitation of the unlabeled data. Specifically, ELSNet introduces two new modules for image segmentation: an exemplar-guided synthesis module, which enriches and diversifies the training set by synthesizing annotated samples from the given exemplar, and a pixel-prototype based contrastive embedding module, which enhances the discriminative capacity of the base segmentation model via contrastive self-supervised learning. Moreover, we deploy a two-stage process for segmentation model training, which exploits the unlabeled data with predicted pseudo segmentation labels. To evaluate this new learning framework, we conduct extensive experiments on several organ segmentation datasets and present an in-depth analysis. The empirical results show that the proposed exemplar learning framework produces effective segmentation results.
CenterLoc3D: Monocular 3D Vehicle Localization Network for Roadside Surveillance Cameras
Apr 06, 2022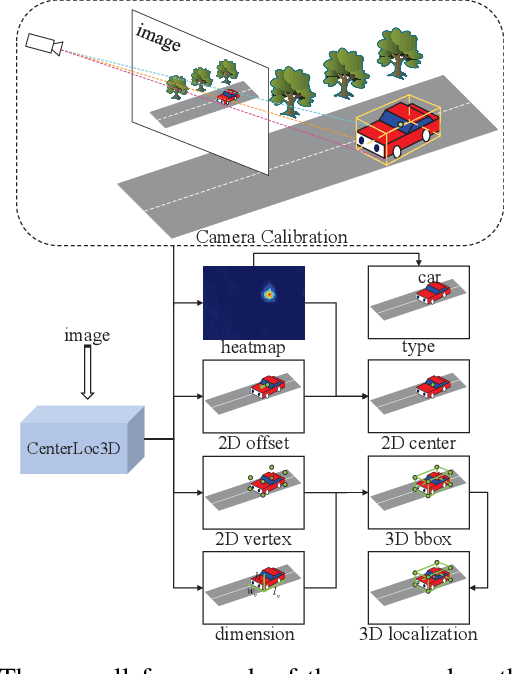
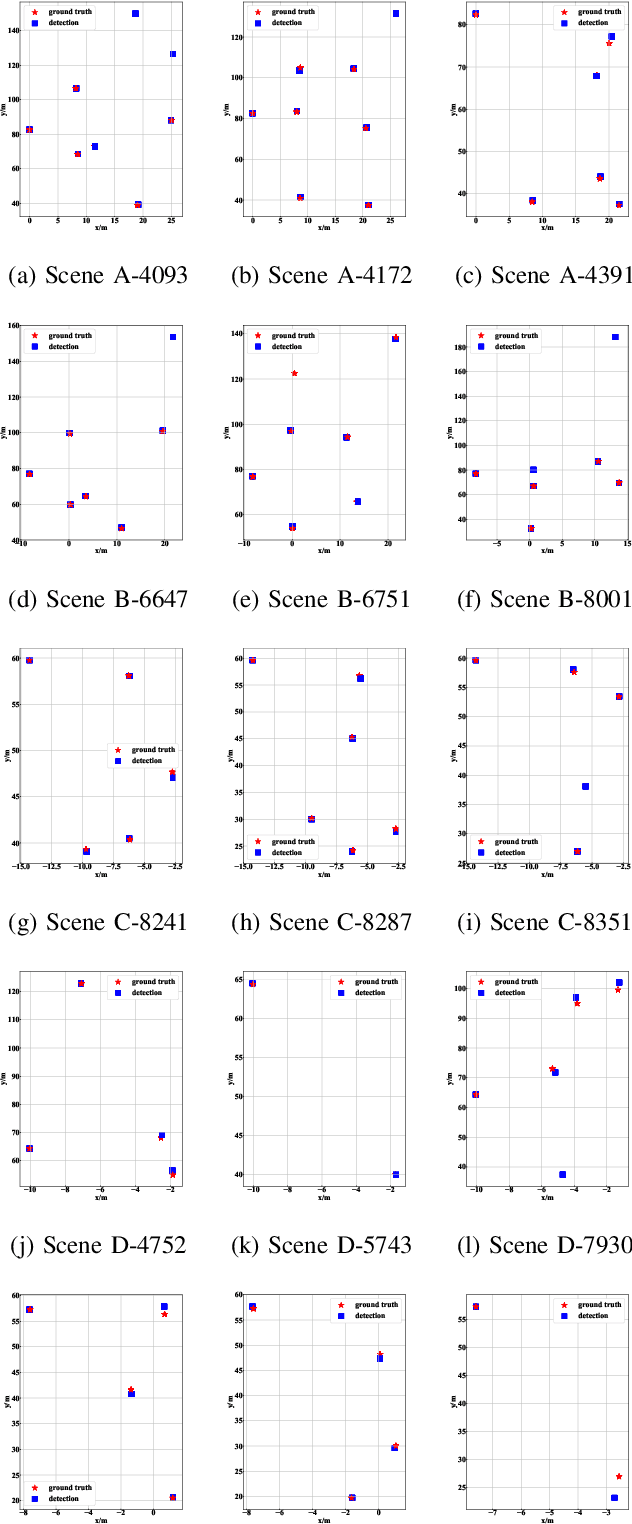
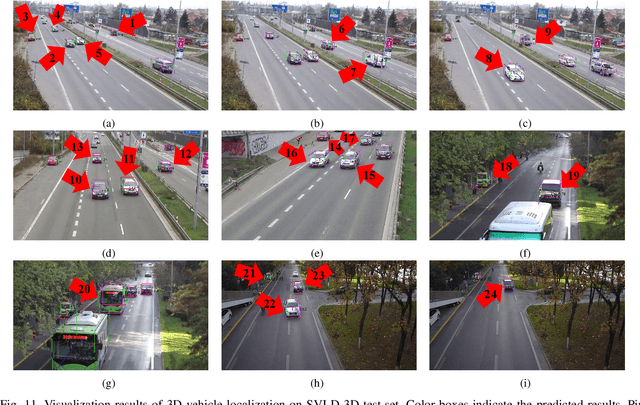
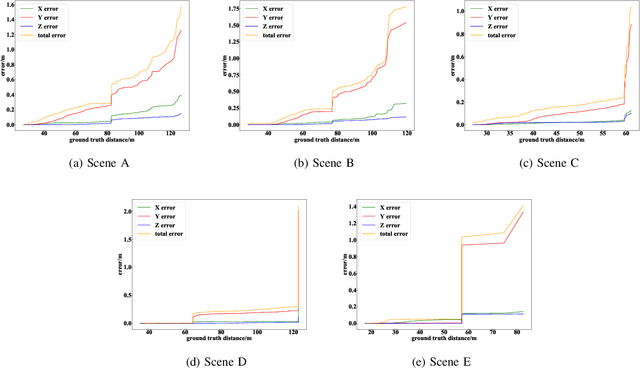
Monocular 3D vehicle localization is an important task in Intelligent Transportation System (ITS) and Cooperative Vehicle Infrastructure System (CVIS), which is usually achieved by monocular 3D vehicle detection. However, depth information cannot be obtained directly by monocular cameras due to the inherent imaging mechanism, resulting in more challenging monocular 3D tasks. Most of the current monocular 3D vehicle detection methods leverage 2D detectors and additional geometric modules, which reduces the efficiency. In this paper, we propose a 3D vehicle localization network CenterLoc3D for roadside monocular cameras, which directly predicts centroid and eight vertexes in image space, and the dimension of 3D bounding boxes without 2D detectors. To improve the precision of 3D vehicle localization, we propose a weighted-fusion module and a loss with spatial constraints embedded in CenterLoc3D. Firstly, the transformation matrix between 2D image space and 3D world space is solved by camera calibration. Secondly, vehicle type, centroid, eight vertexes, and the dimension of 3D vehicle bounding boxes are obtained by CenterLoc3D. Finally, centroid in 3D world space can be obtained by camera calibration and CenterLoc3D for 3D vehicle localization. To the best of our knowledge, this is the first application of 3D vehicle localization for roadside monocular cameras. Hence, we also propose a benchmark for this application including a dataset (SVLD-3D), an annotation tool (LabelImg-3D), and evaluation metrics. Through experimental validation, the proposed method achieves high accuracy and real-time performance.
Noise-based Enhancement for Foveated Rendering
Apr 09, 2022
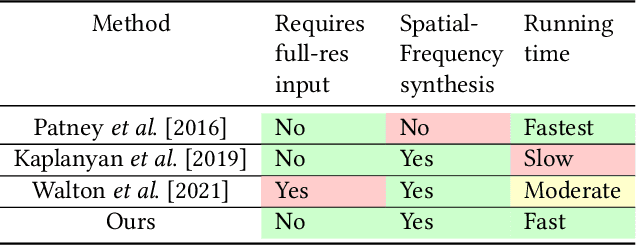
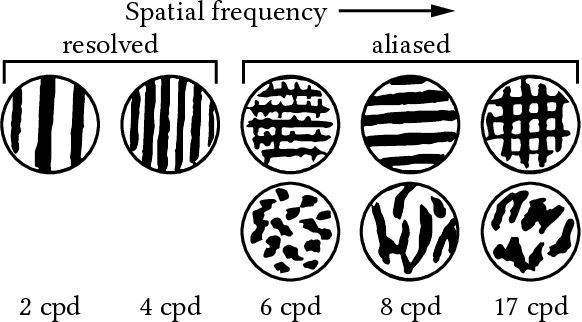
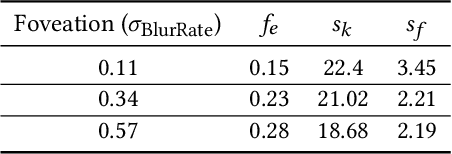
Human visual sensitivity to spatial details declines towards the periphery. Novel image synthesis techniques, so-called foveated rendering, exploit this observation and reduce the spatial resolution of synthesized images for the periphery, avoiding the synthesis of high-spatial-frequency details that are costly to generate but not perceived by a viewer. However, contemporary techniques do not make a clear distinction between the range of spatial frequencies that must be reproduced and those that can be omitted. For a given eccentricity, there is a range of frequencies that are detectable but not resolvable. While the accurate reproduction of these frequencies is not required, an observer can detect their absence if completely omitted. We use this observation to improve the performance of existing foveated rendering techniques. We demonstrate that this specific range of frequencies can be efficiently replaced with procedural noise whose parameters are carefully tuned to image content and human perception. Consequently, these frequencies do not have to be synthesized during rendering, allowing more aggressive foveation, and they can be replaced by noise generated in a less expensive post-processing step, leading to improved performance of the rendering system. Our main contribution is a perceptually-inspired technique for deriving the parameters of the noise required for the enhancement and its calibration. The method operates on rendering output and runs at rates exceeding 200FPS at 4K resolution, making it suitable for integration with real-time foveated rendering systems for VR and AR devices. We validate our results and compare them to the existing contrast enhancement technique in user experiments.
Vision-based Autonomous Driving for Unstructured Environments Using Imitation Learning
Feb 21, 2022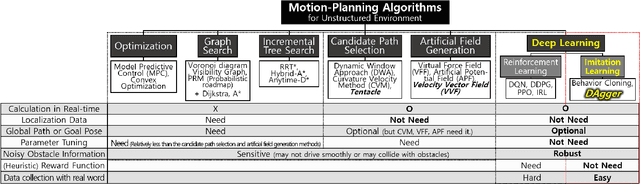

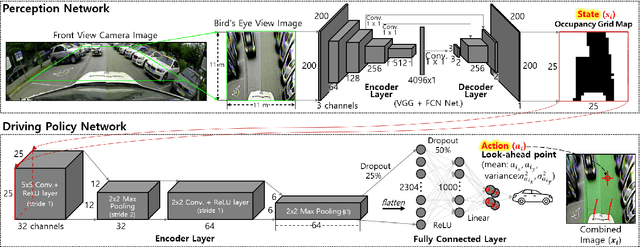

Unstructured environments are difficult for autonomous driving. This is because various unknown obstacles are lied in drivable space without lanes, and its width and curvature change widely. In such complex environments, searching for a path in real-time is difficult. Also, inaccurate localization data reduce the path tracking accuracy, increasing the risk of collision. Instead of searching and tracking the path, an alternative approach has been proposed that reactively avoids obstacles in real-time. Some methods are available for tracking global path while avoiding obstacles using the candidate paths and the artificial potential field. However, these methods require heuristics to find specific parameters for handling various complex environments. In addition, it is difficult to track the global path accurately in practice because of inaccurate localization data. If the drivable space is not accurately recognized (i.e., noisy state), the vehicle may not smoothly drive or may collide with obstacles. In this study, a method in which the vehicle drives toward drivable space only using a vision-based occupancy grid map is proposed. The proposed method uses imitation learning, where a deep neural network is trained with expert driving data. The network can learn driving patterns suited for various complex and noisy situations because these situations are contained in the training data. Experiments with a vehicle in actual parking lots demonstrated the limitations of general model-based methods and the effectiveness of the proposed imitation learning method.
On the Fitness Landscapes of Interdependency Models in the Travelling Thief Problem
Feb 28, 2022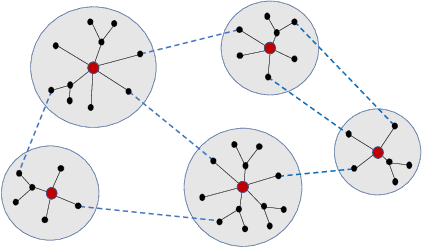
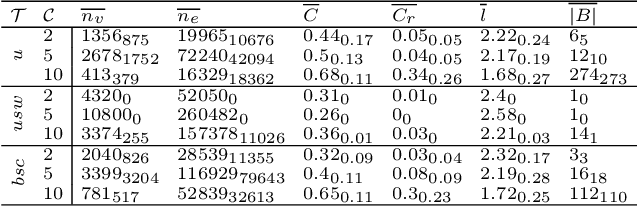
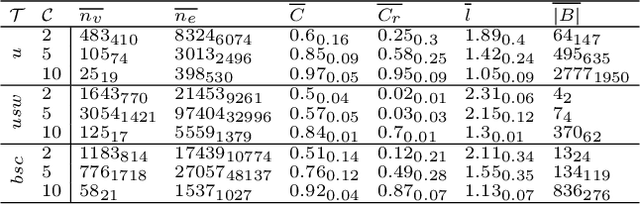
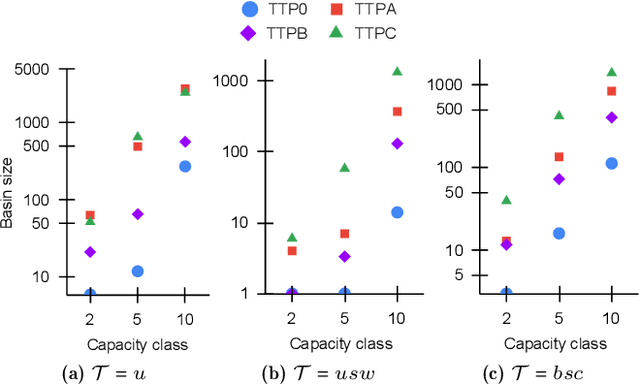
Since its inception in 2013, the Travelling Thief Problem (TTP) has been widely studied as an example of problems with multiple interconnected sub-problems. The dependency in this model arises when tying the travelling time of the "thief" to the weight of the knapsack. However, other forms of dependency as well as combinations of dependencies should be considered for investigation, as they are often found in complex real-world problems. Our goal is to study the impact of different forms of dependency in the TTP using a simple local search algorithm. To achieve this, we use Local Optima Networks, a technique for analysing the fitness landscape.
TiltedBERT: Resource Adjustable Version of BERT
Jan 14, 2022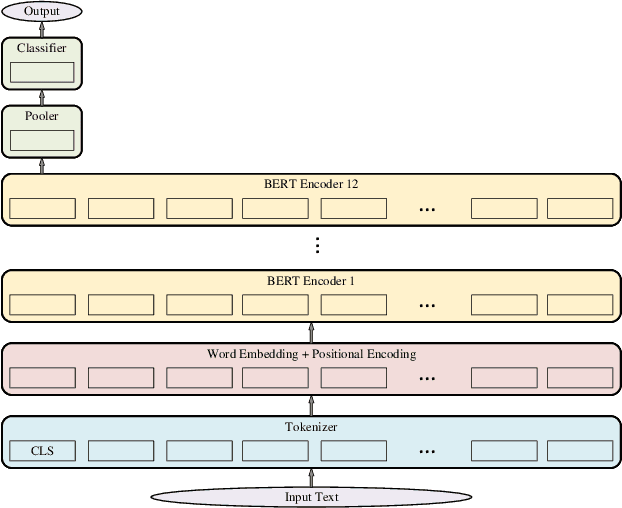
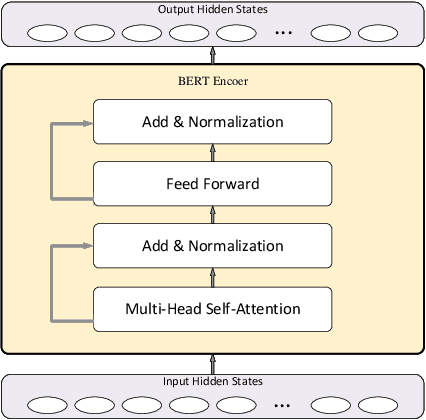
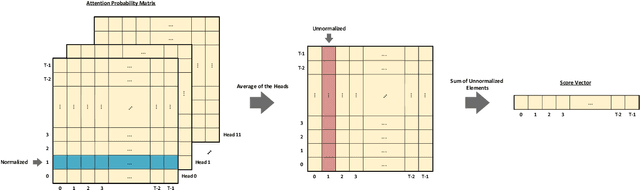
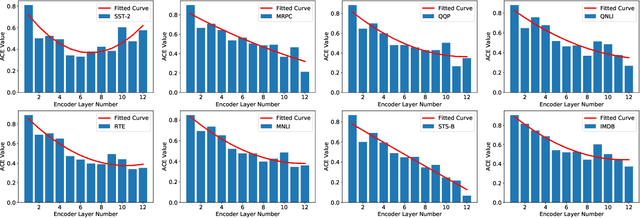
In this paper, we proposed a novel adjustable finetuning method that improves the training and inference time of the BERT model on downstream tasks. In the proposed method, we first detect more important word vectors in each layer by our proposed redundancy metric and then eliminate the less important word vectors with our proposed strategy. In our method, the word vector elimination rate in each layer is controlled by the Tilt-Rate hyper-parameter, and the model learns to work with a considerably lower number of Floating Point Operations (FLOPs) than the original BERTbase model. Our proposed method does not need any extra training steps, and also it can be generalized to other transformer-based models. We perform extensive experiments that show the word vectors in higher layers have an impressive amount of redundancy that can be eliminated and decrease the training and inference time. Experimental results on extensive sentiment analysis, classification and regression datasets, and benchmarks like IMDB and GLUE showed that our proposed method is effective in various datasets. By applying our method on the BERTbase model, we decrease the inference time up to 5.3 times with less than 0.85% accuracy degradation on average. After the fine-tuning stage, the inference time of our model can be adjusted with our method offline-tuning property for a wide range of the Tilt-Rate value selections. Also, we propose a mathematical speedup analysis that can estimate the speedup of our method accurately. With the help of this analysis, the proper Tilt-Rate value can be selected before fine-tuning or while offline-tuning stages.
Enhanced Preamble Based MAC Mechanism for IIoT-oriented PLC Network
Mar 22, 2022
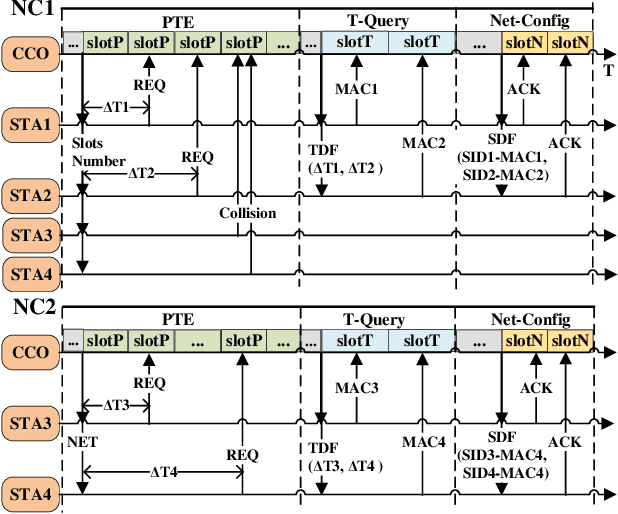
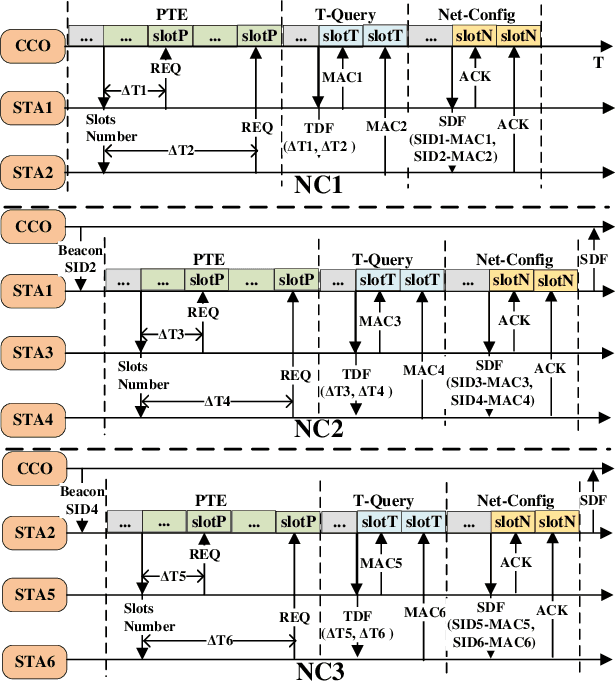
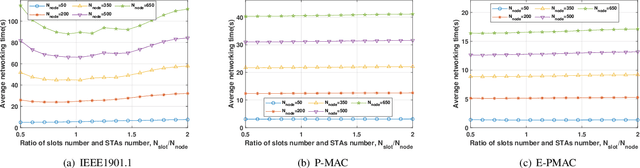
In this paper, we propose an enhanced preamble based media access control mechanism (E-PMAC), which can be applied in power line communication (PLC) network for Industrial Internet of Things (IIoT). We introduce detailed technologies used in E-PMAC, including delay calibration mechanism, preamble design, and slot allocation algorithm. With these technologies, E-PMAC is more robust than existing preamble based MAC mechanism (P-MAC). Besides, we analyze the disadvantage of P-MAC in multi-layer networking and design the networking process of E-PMAC to accelerate networking process. We analyze the complexity of networking process in P-MAC and E-PMAC and prove that E-PMAC has lower complexity than P-MAC. Finally, we simulate the single-layer networking and multi-layer networking of E-PMAC, P-MAC, and existing PLC protocol, i.e. , IEEE1901.1. The simulation results indicate that E-PMAC spends much less time in networking than IEEE1901.1 and P-MAC. Finally, with our work, a PLC network based on E-PMAC mechanism can be realized.
Achieving Conversational Goals with Unsupervised Post-hoc Knowledge Injection
Mar 22, 2022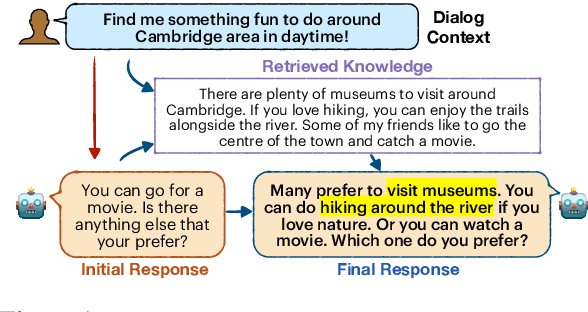
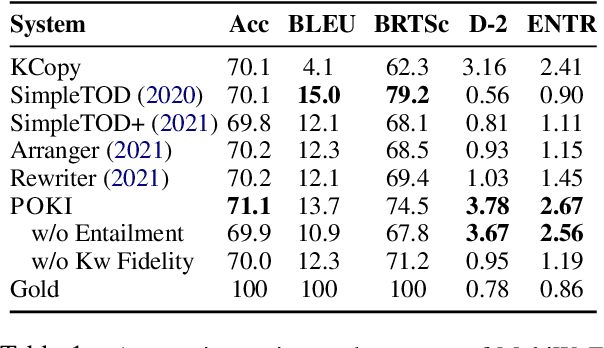
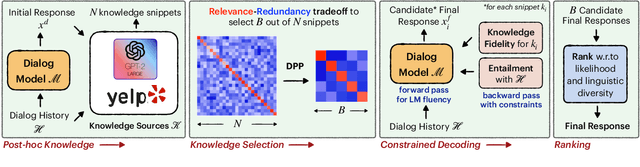
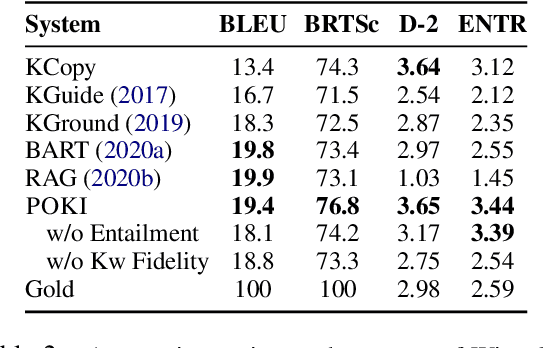
A limitation of current neural dialog models is that they tend to suffer from a lack of specificity and informativeness in generated responses, primarily due to dependence on training data that covers a limited variety of scenarios and conveys limited knowledge. One way to alleviate this issue is to extract relevant knowledge from external sources at decoding time and incorporate it into the dialog response. In this paper, we propose a post-hoc knowledge-injection technique where we first retrieve a diverse set of relevant knowledge snippets conditioned on both the dialog history and an initial response from an existing dialog model. We construct multiple candidate responses, individually injecting each retrieved snippet into the initial response using a gradient-based decoding method, and then select the final response with an unsupervised ranking step. Our experiments in goal-oriented and knowledge-grounded dialog settings demonstrate that human annotators judge the outputs from the proposed method to be more engaging and informative compared to responses from prior dialog systems. We further show that knowledge-augmentation promotes success in achieving conversational goals in both experimental settings.