 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ACDnet: An action detection network for real-time edge computing based on flow-guided feature approximation and memory aggregation
Feb 26, 2021
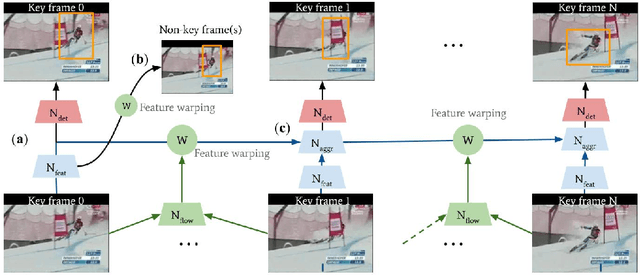
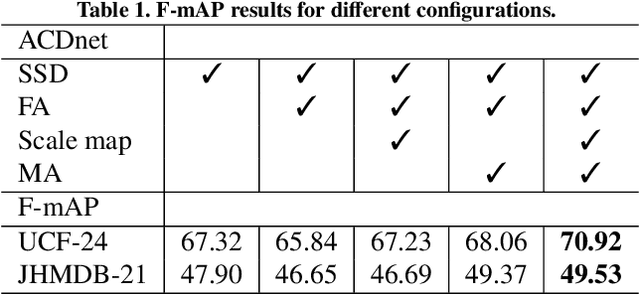
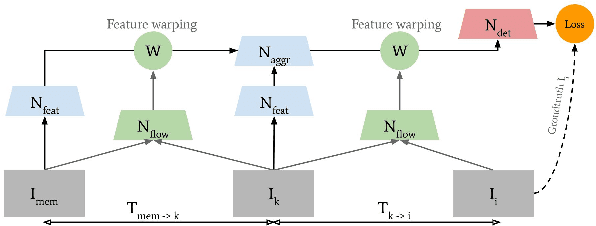
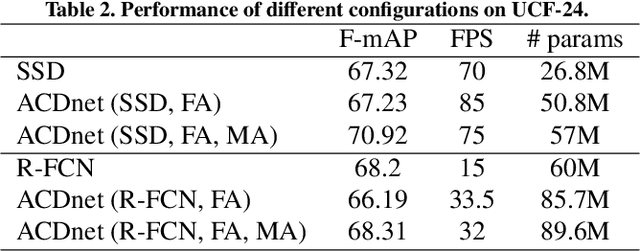
Interpreting human actions requires understanding the spatial and temporal context of the scenes. State-of-the-art action detectors based on Convolutional Neural Network (CNN) have demonstrated remarkable results by adopting two-stream or 3D CNN architectures. However, these methods typically operate in a non-real-time, ofline fashion due to system complexity to reason spatio-temporal information. Consequently, their high computational cost is not compliant with emerging real-world scenarios such as service robots or public surveillance where detection needs to take place at resource-limited edge devices. In this paper, we propose ACDnet, a compact action detection network targeting real-time edge computing which addresses both efficiency and accuracy. It intelligently exploits the temporal coherence between successive video frames to approximate their CNN features rather than naively extracting them. It also integrates memory feature aggregation from past video frames to enhance current detection stability, implicitly modeling long temporal cues over time. Experiments conducted on the public benchmark datasets UCF-24 and JHMDB-21 demonstrate that ACDnet, when integrated with the SSD detector, can robustly achieve detection well above real-time (75 FPS). At the same time, it retains reasonable accuracy (70.92 and 49.53 frame mAP) compared to other top-performing methods using far heavier configurations. Codes will be available at https://github.com/dginhac/ACDnet.
* Accepted for publication in Pattern Recognition Letters
Automated Surface Texture Analysis via Discrete Cosine Transform and Discrete Wavelet Transform
Apr 12, 2022


Surface roughness and texture are critical to the functional performance of engineering components. The ability to analyze roughness and texture effectively and efficiently is much needed to ensure surface quality in many surface generation processes, such as machining, surface mechanical treatment, etc. Discrete Wavelet Transform (DWT) and Discrete Cosine Transform (DCT) are two commonly used signal decomposition tools for surface roughness and texture analysis. Both methods require selecting a threshold to decompose a given surface into its three main components: form, waviness, and roughness. However, although DWT and DCT are part of the ISO surface finish standards, there exists no systematic guidance on how to compute these thresholds, and they are often manually selected on case by case basis. This makes utilizing these methods for studying surfaces dependent on the user's judgment and limits their automation potential. Therefore, we present two automatic threshold selection algorithms based on information theory and signal energy. We use machine learning to validate the success of our algorithms both using simulated surfaces as well as digital microscopy images of machined surfaces. Specifically, we generate feature vectors for each surface area or profile and apply supervised classification. Comparing our results with the heuristic threshold selection approach shows good agreement with mean accuracies as high as 95\%. We also compare our results with Gaussian filtering (GF) and show that while GF results for areas can yield slightly higher accuracies, our results outperform GF for surface profiles. We further show that our automatic threshold selection has significant advantages in terms of computational time as evidenced by decreasing the number of mode computations by an order of magnitude compared to the heuristic thresholding for DCT.
Network state Estimation using Raw Video Analysis: vQoS-GAN based non-intrusive Deep Learning Approach
Mar 22, 2022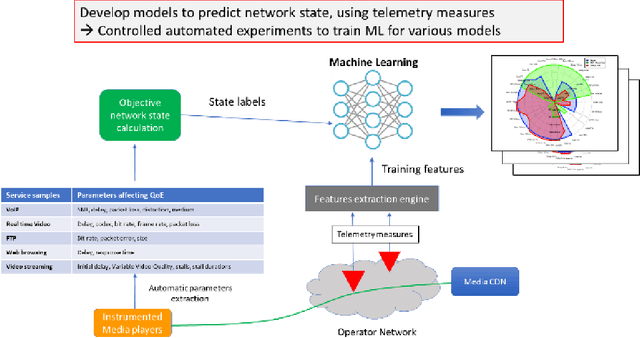

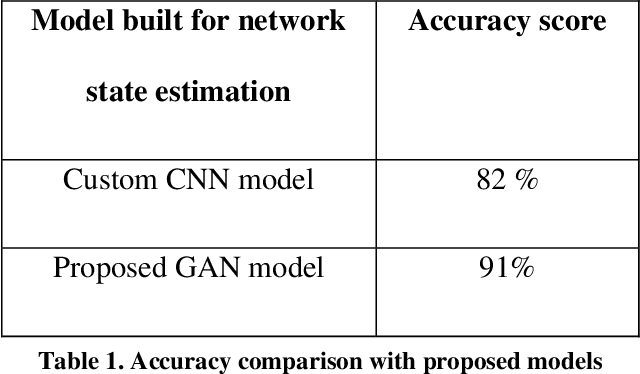

Content based providers transmits real time complex signal such as video data from one region to another. During this transmission process, the signals usually end up distorted or degraded where the actual information present in the video is lost. This normally happens in the streaming video services applications. Hence there is a need to know the level of degradation that happened in the receiver side. This video degradation can be estimated by network state parameters like data rate and packet loss values. Our proposed solution vQoS GAN (video Quality of Service Generative Adversarial Network) can estimate the network state parameters from the degraded received video data using a deep learning approach of semi supervised generative adversarial network algorithm. A robust and unique design of deep learning network model has been trained with the video data along with data rate and packet loss class labels and achieves over 95 percent of training accuracy. The proposed semi supervised generative adversarial network can additionally reconstruct the degraded video data to its original form for a better end user experience.
Look Outside the Room: Synthesizing A Consistent Long-Term 3D Scene Video from A Single Image
Mar 17, 2022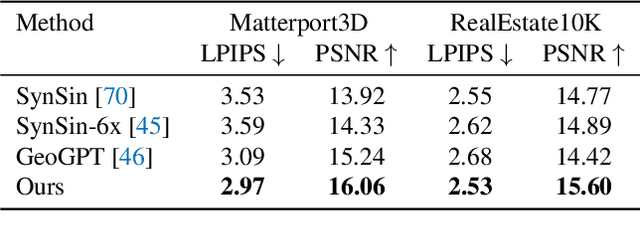
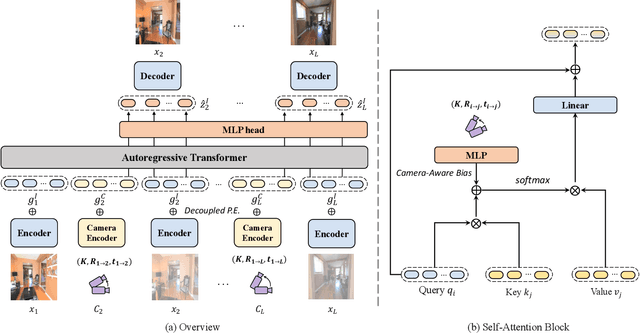
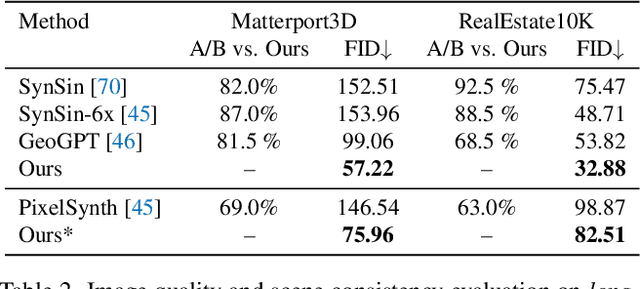
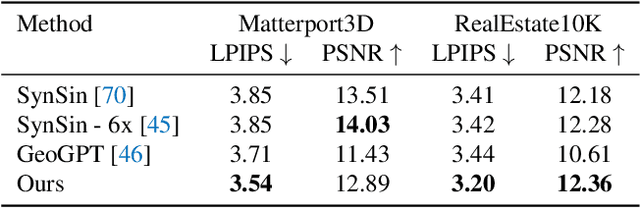
Novel view synthesis from a single image has recently attracted a lot of attention, and it has been primarily advanced by 3D deep learning and rendering techniques. However, most work is still limited by synthesizing new views within relatively small camera motions. In this paper, we propose a novel approach to synthesize a consistent long-term video given a single scene image and a trajectory of large camera motions. Our approach utilizes an autoregressive Transformer to perform sequential modeling of multiple frames, which reasons the relations between multiple frames and the corresponding cameras to predict the next frame. To facilitate learning and ensure consistency among generated frames, we introduce a locality constraint based on the input cameras to guide self-attention among a large number of patches across space and time. Our method outperforms state-of-the-art view synthesis approaches by a large margin, especially when synthesizing long-term future in indoor 3D scenes. Project page at https://xrenaa.github.io/look-outside-room/.
Research topic trend prediction of scientific papers based on spatial enhancement and dynamic graph convolution network
Mar 30, 2022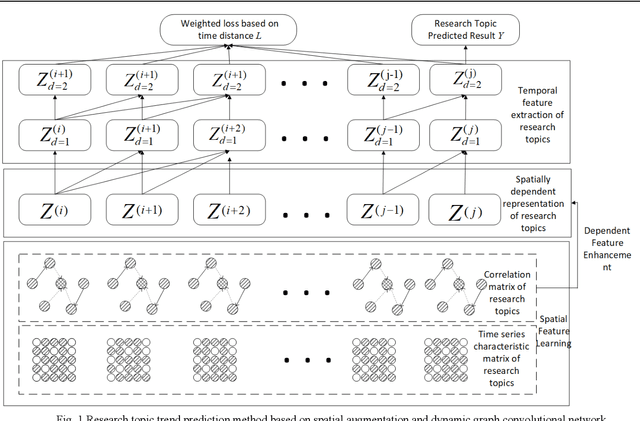
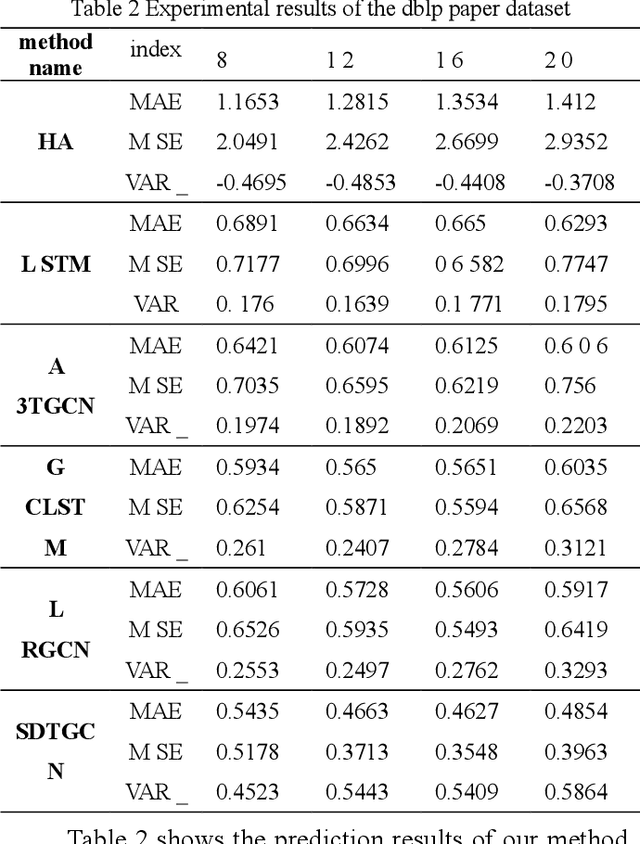
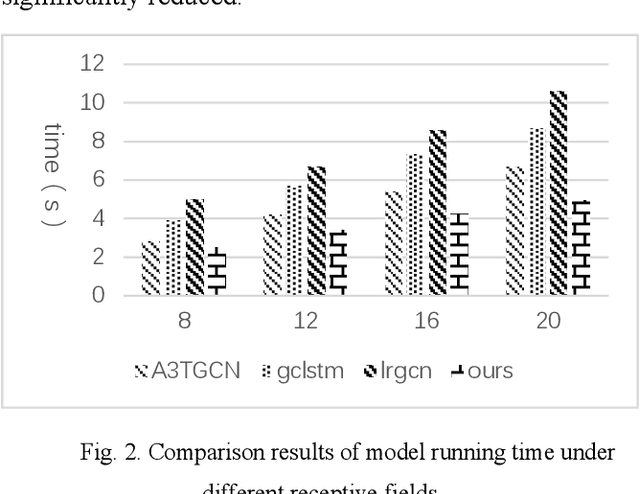
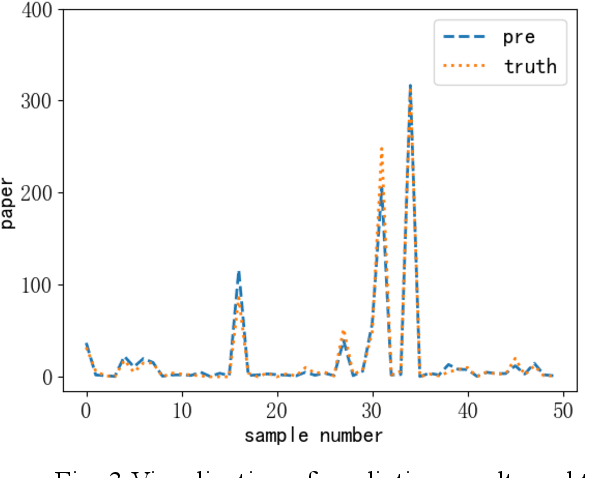
In recent years, with the increase of social investment in scientific research, the number of research results in various fields has increased significantly. Accurately and effectively predicting the trends of future research topics can help researchers discover future research hotspots. However, due to the increasingly close correlation between various research themes, there is a certain dependency relationship between a large number of research themes. Viewing a single research theme in isolation and using traditional sequence problem processing methods cannot effectively explore the spatial dependencies between these research themes. To simultaneously capture the spatial dependencies and temporal changes between research topics, we propose a deep neural network-based research topic hotness prediction algorithm, a spatiotemporal convolutional network model. Our model combines a graph convolutional neural network (GCN) and Temporal Convolutional Network (TCN), specifically, GCNs are used to learn the spatial dependencies of research topics a and use space dependence to strengthen spatial characteristics. TCN is used to learn the dynamics of research topics' trends. Optimization is based on the calculation of weighted losses based on time distance. Compared with the current mainstream sequence prediction models and similar spatiotemporal models on the paper datasets, experiments show that, in research topic prediction tasks, our model can effectively capture spatiotemporal relationships and the predictions outperform state-of-art baselines.
How Do Graph Networks Generalize to Large and Diverse Molecular Systems?
Apr 06, 2022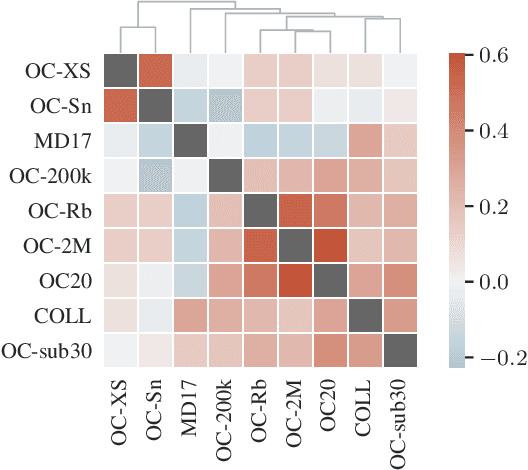
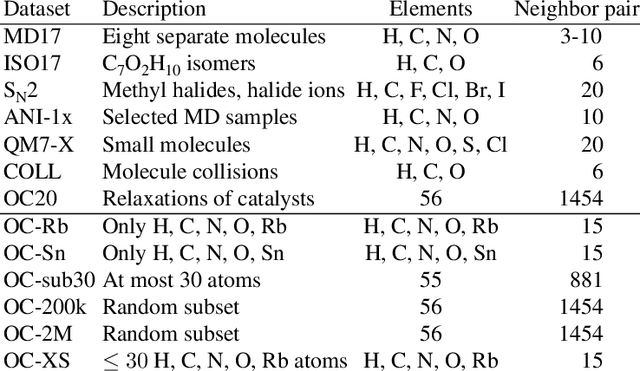
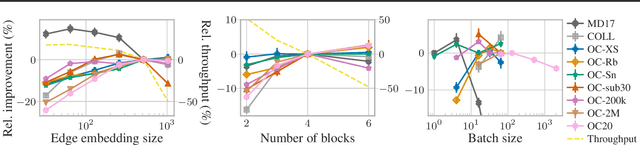
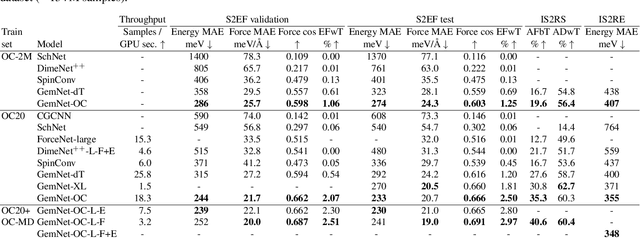
The predominant method of demonstrating progress of atomic graph neural networks are benchmarks on small and limited datasets. The implicit hypothesis behind this approach is that progress on these narrow datasets generalize to the large diversity of chemistry. This generalizability would be very helpful for research, but currently remains untested. In this work we test this assumption by identifying four aspects of complexity in which many datasets are lacking: 1. Chemical diversity (number of different elements), 2. system size (number of atoms per sample), 3. dataset size (number of data samples), and 4. domain shift (similarity of the training and test set). We introduce multiple subsets of the large Open Catalyst 2020 (OC20) dataset to independently investigate each of these aspects. We then perform 21 ablation studies and sensitivity analyses on 9 datasets testing both previously proposed and new model enhancements. We find that some improvements are consistent between datasets, but many are not and some even have opposite effects. Based on this analysis, we identify a smaller dataset that correlates well with the full OC20 dataset, and propose the GemNet-OC model, which outperforms the previous state-of-the-art on OC20 by 16%, while reducing training time by a factor of 10. Overall, our findings challenge the common belief that graph neural networks work equally well independent of dataset size and diversity, and suggest that caution must be exercised when making generalizations based on narrow datasets.
Modurec: Recommender Systems with Feature and Time Modulation
Oct 13, 2020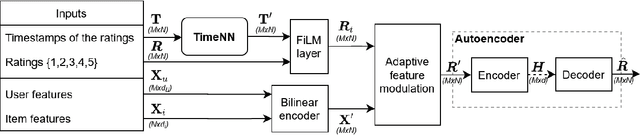
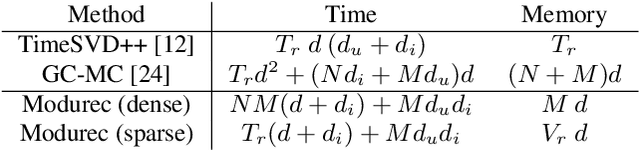

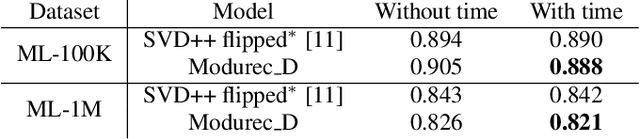
Current state of the art algorithms for recommender systems are mainly based on collaborative filtering, which exploits user ratings to discover latent factors in the data. These algorithms unfortunately do not make effective use of other features, which can help solve two well identified problems of collaborative filtering: cold start (not enough data is available for new users or products) and concept shift (the distribution of ratings changes over time). To address these problems, we propose Modurec: an autoencoder-based method that combines all available information using the feature-wise modulation mechanism, which has demonstrated its effectiveness in several fields. While time information helps mitigate the effects of concept shift, the combination of user and item features improve prediction performance when little data is available. We show on Movielens datasets that these modifications produce state-of-the-art results in most evaluated settings compared with standard autoencoder-based methods and other collaborative filtering approaches.
Perceptual cGAN for MRI Super-resolution
Jan 23, 2022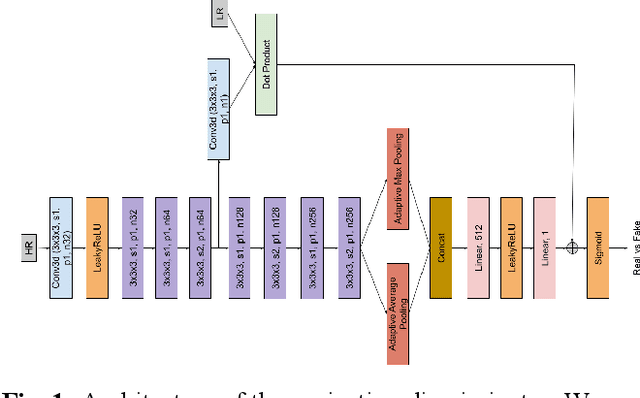
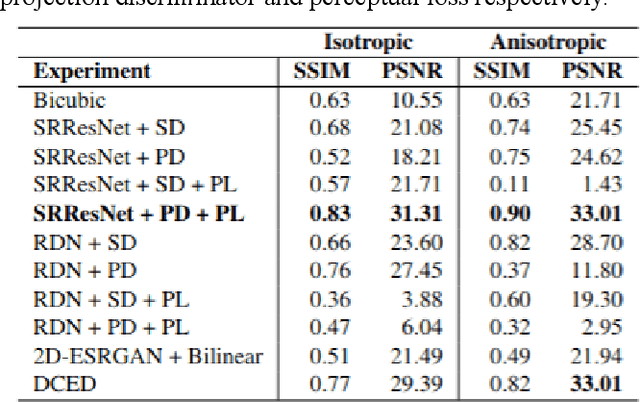
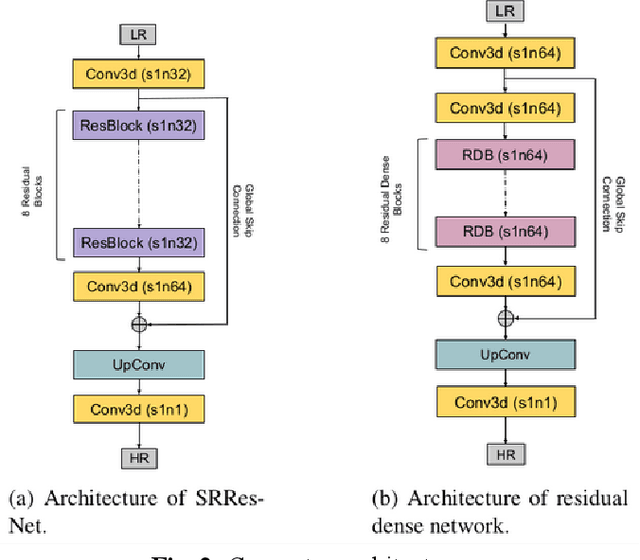
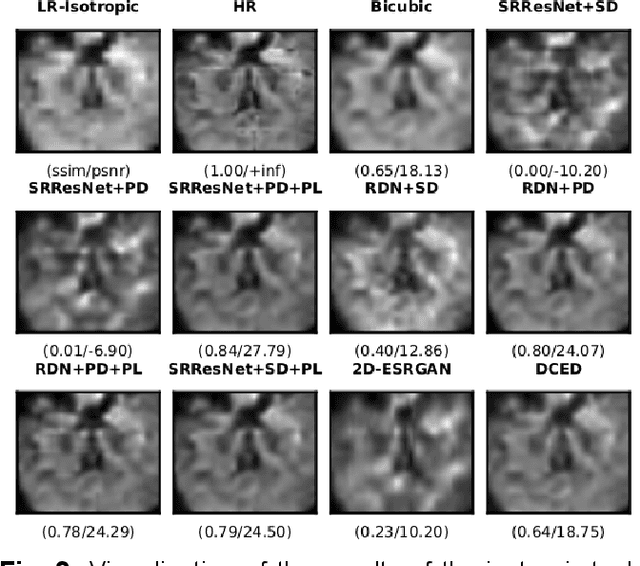
Capturing high-resolution magnetic resonance (MR) images is a time consuming process, which makes it unsuitable for medical emergencies and pediatric patients. Low-resolution MR imaging, by contrast, is faster than its high-resolution counterpart, but it compromises on fine details necessary for a more precise diagnosis. Super-resolution (SR), when applied to low-resolution MR images, can help increase their utility by synthetically generating high-resolution images with little additional time. In this paper, we present a SR technique for MR images that is based on generative adversarial networks (GANs), which have proven to be quite useful in generating sharp-looking details in SR. We introduce a conditional GAN with perceptual loss, which is conditioned upon the input low-resolution image, which improves the performance for isotropic and anisotropic MRI super-resolution.
Neural Part Priors: Learning to Optimize Part-Based Object Completion in RGB-D Scans
Mar 17, 2022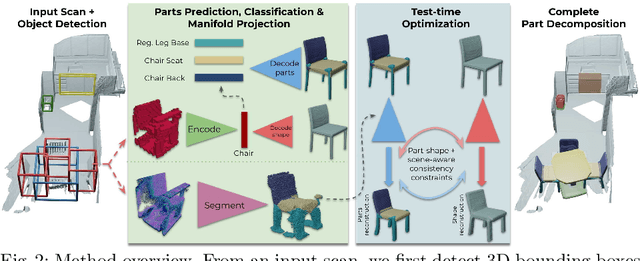
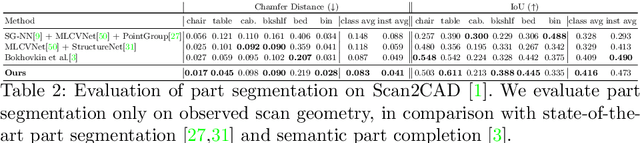
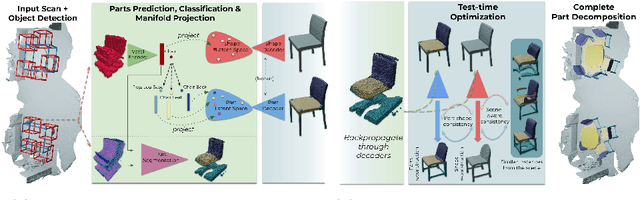
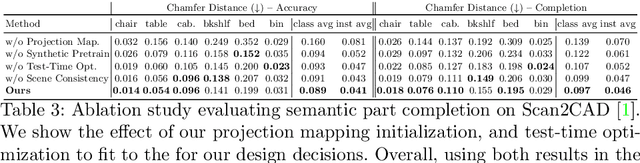
3D object recognition has seen significant advances in recent years, showing impressive performance on real-world 3D scan benchmarks, but lacking in object part reasoning, which is fundamental to higher-level scene understanding such as inter-object similarities or object functionality. Thus, we propose to leverage large-scale synthetic datasets of 3D shapes annotated with part information to learn Neural Part Priors (NPPs), optimizable spaces characterizing geometric part priors. Crucially, we can optimize over the learned part priors in order to fit to real-world scanned 3D scenes at test time, enabling robust part decomposition of the real objects in these scenes that also estimates the complete geometry of the object while fitting accurately to the observed real geometry. Moreover, this enables global optimization over geometrically similar detected objects in a scene, which often share strong geometric commonalities, enabling scene-consistent part decompositions. Experiments on the ScanNet dataset demonstrate that NPPs significantly outperforms state of the art in part decomposition and object completion in real-world scenes.
Phase-Aware Deep Speech Enhancement: It's All About The Frame Length
Mar 30, 2022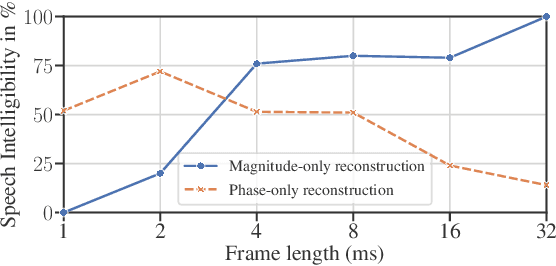
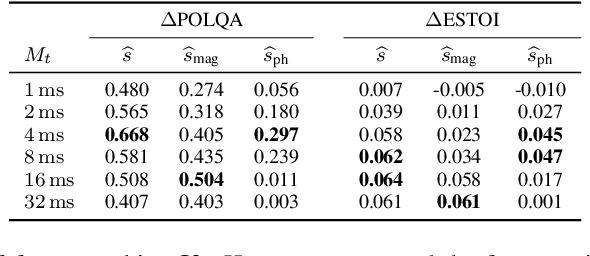
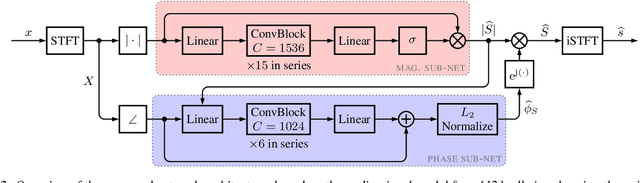
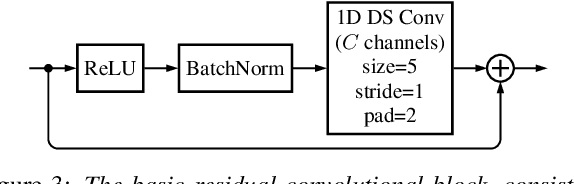
While phase-aware speech processing has been receiving increasing attention in recent years, most narrowband STFT approaches with frame lengths of about 32ms show a rather modest impact of phase on overall performance. At the same time, modern deep neural network (DNN)-based approaches, like Conv-TasNet, that implicitly modify both magnitude and phase yield great performance on very short frames (2ms). Motivated by this observation, in this paper we systematically investigate the role of phase and magnitude in DNN-based speech enhancement for different frame lengths. The results show that a phase-aware DNN can take advantage of what previous studies concerning reconstruction of clean speech have shown: When using short frames, the phase spectrum becomes more important while the importance of the magnitude spectrum decreases. Furthermore, our experiments show that when both magnitude and phase are estimated, shorter frames result in a considerably improved performance in a DNN with explicit phase estimation. Contrarily, in the phase-blind case, where only magnitudes are processed, 32ms frames lead to the best performance. We conclude that DNN-based phase estimation benefits from the use of shorter frames and recommend a frame length of about 4ms for future phase-aware deep speech enhancement methods.