 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Flexible Triggering Kernels for Hawkes Process Modeling
Feb 03, 2022
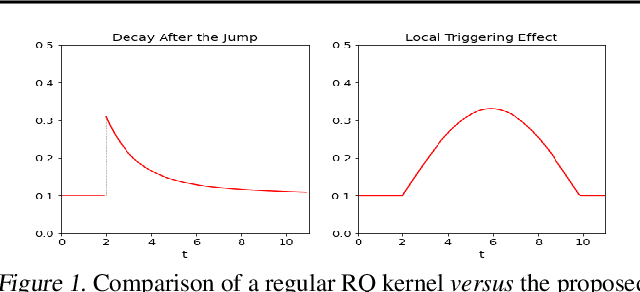
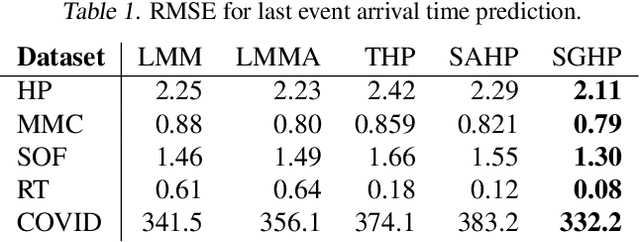
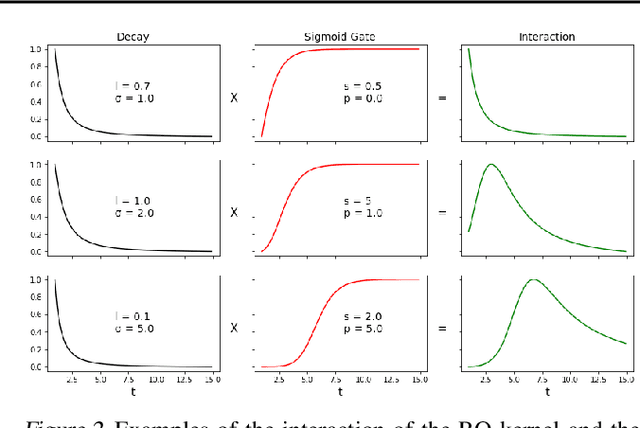
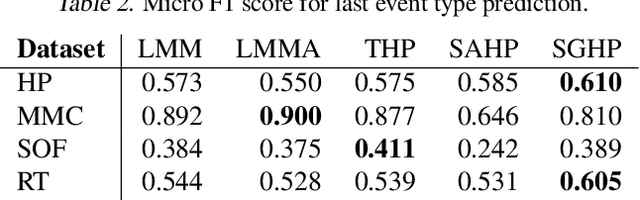
Recently proposed encoder-decoder structures for modeling Hawkes processes use transformer-inspired architectures, which encode the history of events via embeddings and self-attention mechanisms. These models deliver better prediction and goodness-of-fit than their RNN-based counterparts. However, they often require high computational and memory complexity requirements and sometimes fail to adequately capture the triggering function of the underlying process. So motivated, we introduce an efficient and general encoding of the historical event sequence by replacing the complex (multilayered) attention structures with triggering kernels of the observed data. Noting the similarity between the triggering kernels of a point process and the attention scores, we use a triggering kernel to replace the weights used to build history representations. Our estimate for the triggering function is equipped with a sigmoid gating mechanism that captures local-in-time triggering effects that are otherwise challenging with standard decaying-over-time kernels. Further, taking both event type representations and temporal embeddings as inputs, the model learns the underlying triggering type-time kernel parameters given pairs of event types. We present experiments on synthetic and real data sets widely used by competing models, while further including a COVID-19 dataset to illustrate a scenario where longitudinal covariates are available. Results show the proposed model outperforms existing approaches while being more efficient in terms of computational complexity and yielding interpretable results via direct application of the newly introduced kernel.
Learning to Predict RNA Sequence Expressions from Whole Slide Images with Applications for Search and Classification
Mar 26, 2022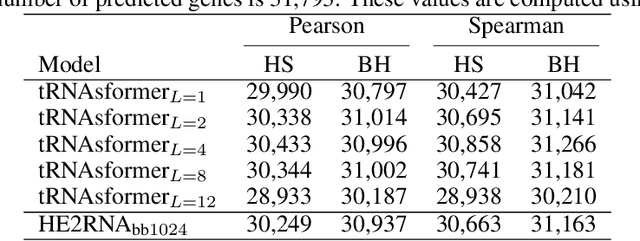
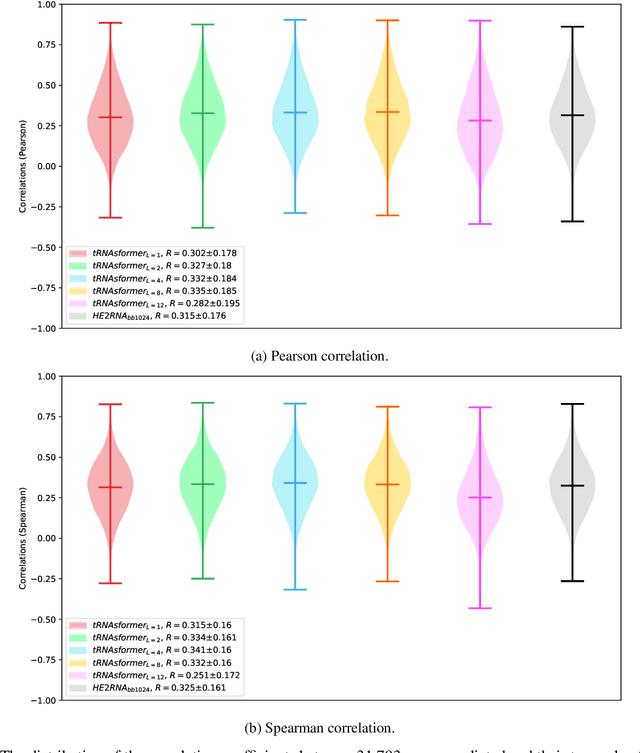
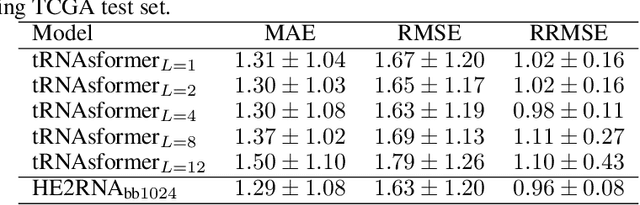
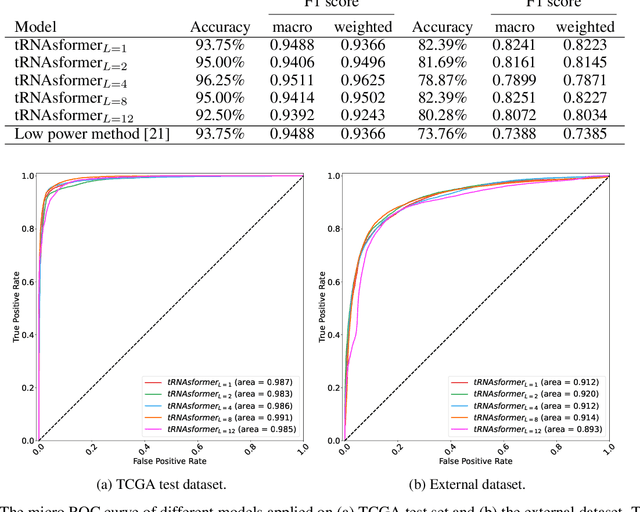
Deep learning methods are widely applied in digital pathology to address clinical challenges such as prognosis and diagnosis. As one of the most recent applications, deep models have also been used to extract molecular features from whole slide images. Although molecular tests carry rich information, they are often expensive, time-consuming, and require additional tissue to sample. In this paper, we propose tRNAsfomer, an attention-based topology that can learn both to predict the bulk RNA-seq from an image and represent the whole slide image of a glass slide simultaneously. The tRNAsfomer uses multiple instance learning to solve a weakly supervised problem while the pixel-level annotation is not available for an image. We conducted several experiments and achieved better performance and faster convergence in comparison to the state-of-the-art algorithms. The proposed tRNAsfomer can assist as a computational pathology tool to facilitate a new generation of search and classification methods by combining the tissue morphology and the molecular fingerprint of the biopsy samples.
R3M: A Universal Visual Representation for Robot Manipulation
Mar 23, 2022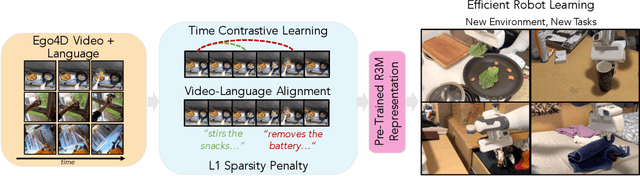
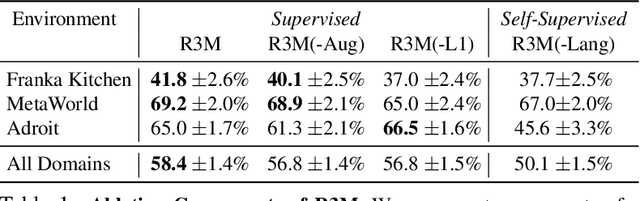
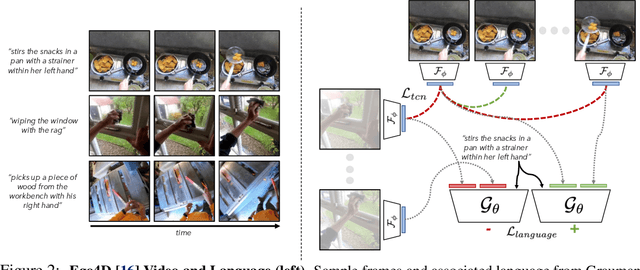
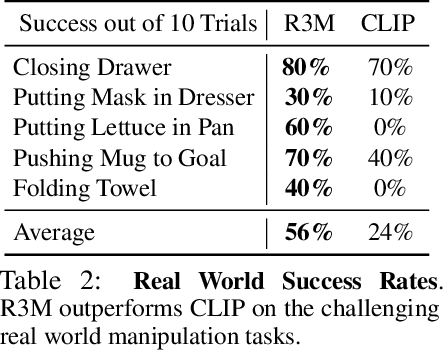
We study how visual representations pre-trained on diverse human video data can enable data-efficient learning of downstream robotic manipulation tasks. Concretely, we pre-train a visual representation using the Ego4D human video dataset using a combination of time-contrastive learning, video-language alignment, and an L1 penalty to encourage sparse and compact representations. The resulting representation, R3M, can be used as a frozen perception module for downstream policy learning. Across a suite of 12 simulated robot manipulation tasks, we find that R3M improves task success by over 20% compared to training from scratch and by over 10% compared to state-of-the-art visual representations like CLIP and MoCo. Furthermore, R3M enables a Franka Emika Panda arm to learn a range of manipulation tasks in a real, cluttered apartment given just 20 demonstrations. Code and pre-trained models are available at https://tinyurl.com/robotr3m.
Fast and Accurate Data-Driven Simulation Framework for Contact-Intensive Tight-Tolerance Robotic Assembly Tasks
Feb 26, 2022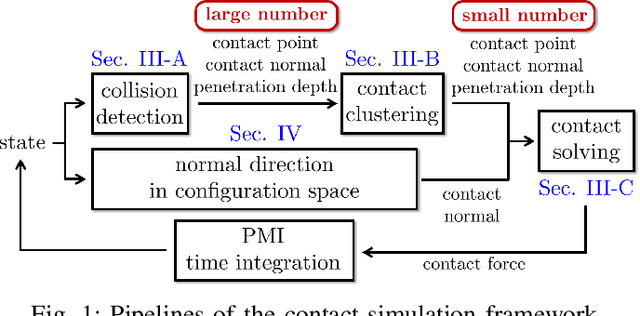
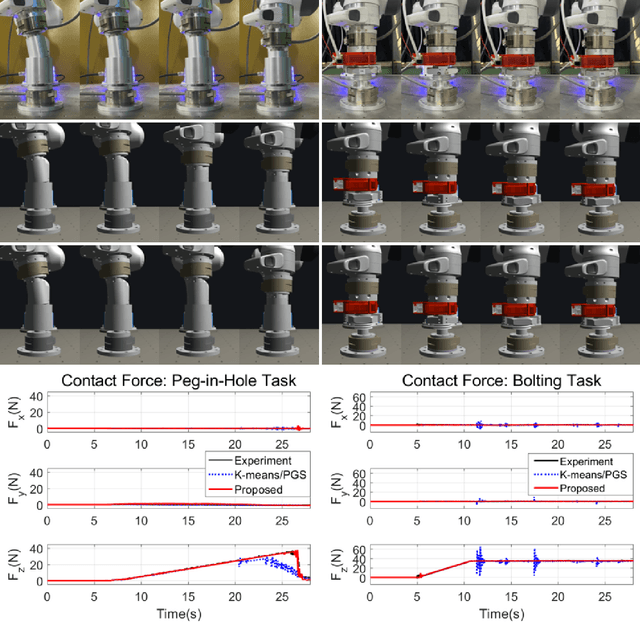
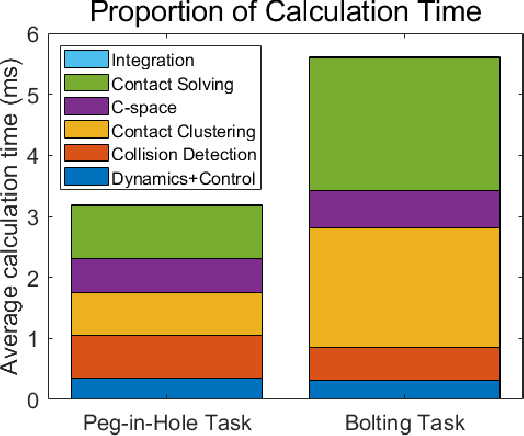
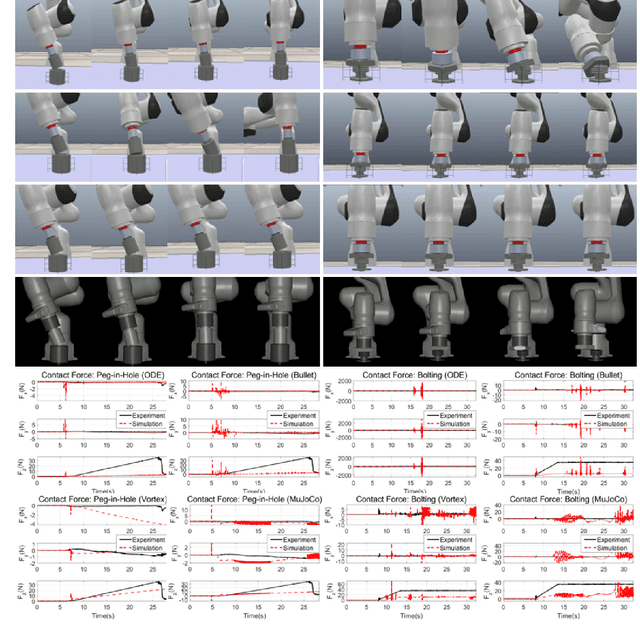
We propose a novel fast and accurate simulation framework for contact-intensive tight-tolerance robotic assembly tasks. The key components of our framework are as follows: 1) data-driven contact point clustering with a certain variable-input network, which is explicitly trained for simulation accuracy (with real experimental data) and able to accommodate complex/non-convex object shapes; 2) contact force solving, which precisely/robustly enforces physics of contact (i.e., no penetration, Coulomb friction, maximum energy dissipation) with contact mechanics of contact nodes augmented with that of their object; 3) contact detection with a neural network, which is parallelized for each contact point, thus, can be computed very quickly even for complex shape objects with no exhaust pair-wise test; and 4) time integration with PMI (passive mid-point integration), whose discrete-time passivity improves overall simulation accuracy, stability, and speed. We then implement our proposed framework for two widely-encountered/benchmarked contact-intensive tight-tolerance tasks, namely, peg-in-hole assembly and bolt-nut assembly, and validate its speed and accuracy against real experimental data. It is worthwhile to mention that our proposed simulation framework is applicable to other general contact-intensive tight-tolerance robotic assembly tasks as well. We also compare its performance with other physics engines and manifest its robustness via haptic rendering of virtual bolting task.
GriTS: Grid table similarity metric for table structure recognition
Mar 23, 2022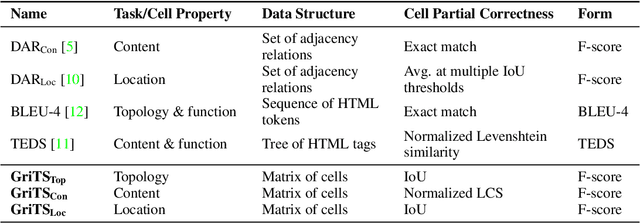
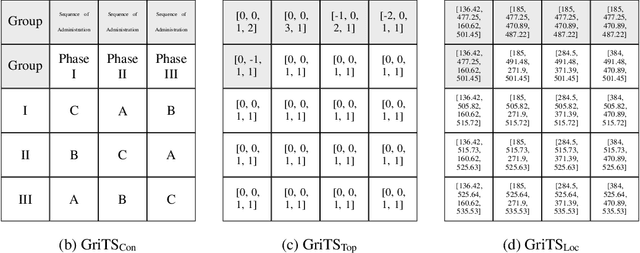
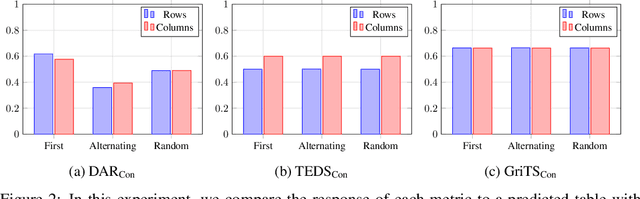
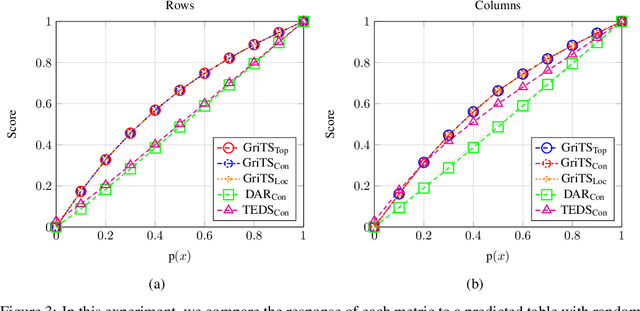
In this paper, we propose a new class of evaluation metric for table structure recognition, grid table similarity (GriTS). Unlike prior metrics, GriTS evaluates the correctness of a predicted table directly in its natural form as a matrix. To create a similarity measure between matrices, we generalize the two-dimensional largest common substructure (2D-LCS) problem, which is NP-hard, to the 2D most similar substructures (2D-MSS) problem and propose a polynomial-time heuristic for solving it. We validate empirically using the PubTables-1M dataset that comparison between matrices exhibits more desirable behavior than alternatives for table structure recognition evaluation. GriTS also unifies all three subtasks of cell topology recognition, cell location recognition, and cell content recognition within the same framework, which simplifies the evaluation and enables more meaningful comparisons across different types of structure recognition approaches. Code will be released at https://github.com/microsoft/table-transformer.
Data-driven Prediction of Relevant Scenarios for Robust Optimization
Mar 30, 2022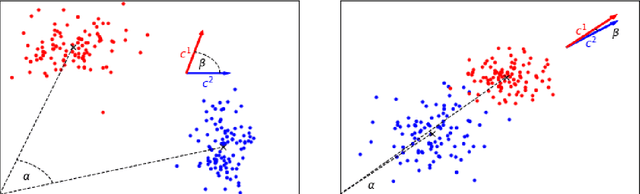
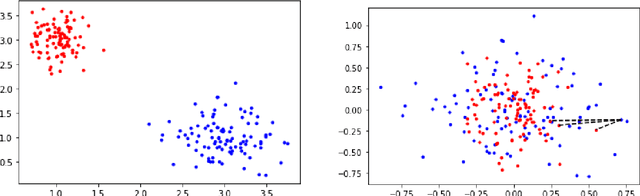
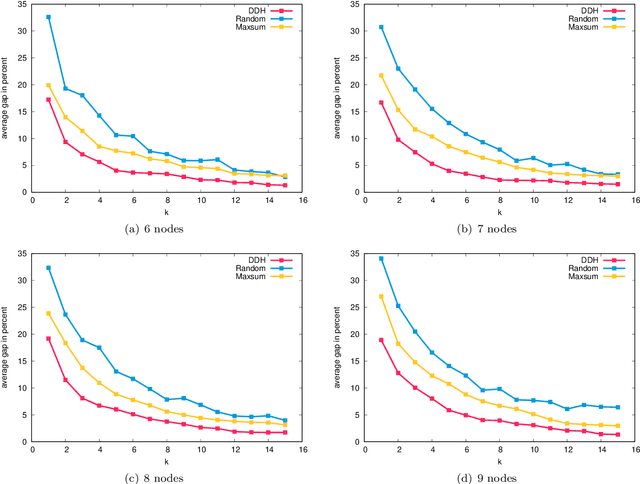
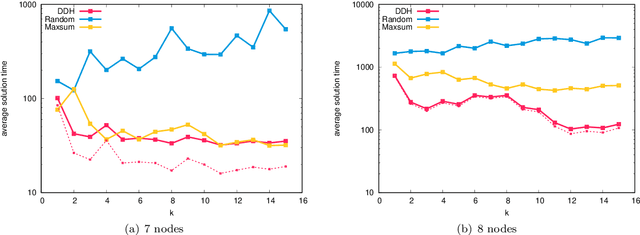
In this work we study robust one- and two-stage problems with discrete uncertainty sets which are known to be hard to solve even if the underlying deterministic problem is easy. Popular solution methods iteratively generate scenario constraints and possibly second-stage variables. This way, by solving a sequence of smaller problems, it is often possible to avoid the complexity of considering all scenarios simultaneously. A key ingredient for the performance of the iterative methods is a good selection of start scenarios. In this paper we propose a data-driven heuristic to seed the iterative solution method with a set of starting scenarios that provide a strong lower bound early in the process, and result in considerably smaller overall solution times compared to other benchmark methods. Our heuristic learns the relevance of a scenario by extracting information from training data based on a combined similarity measure between robust problem instances and single scenarios. Our experiments show that predicting even a small number of good start scenarios by our method can considerably reduce the computation time of the iterative methods.
Determining Joint Periodicities in Multi-time Data With Sampling Uncertainties
Oct 05, 2021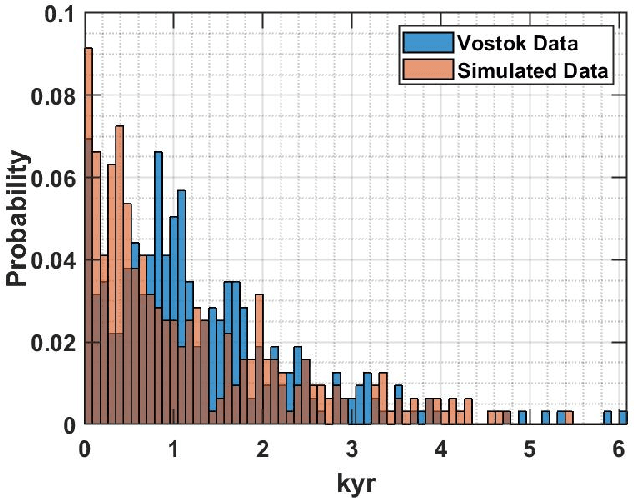
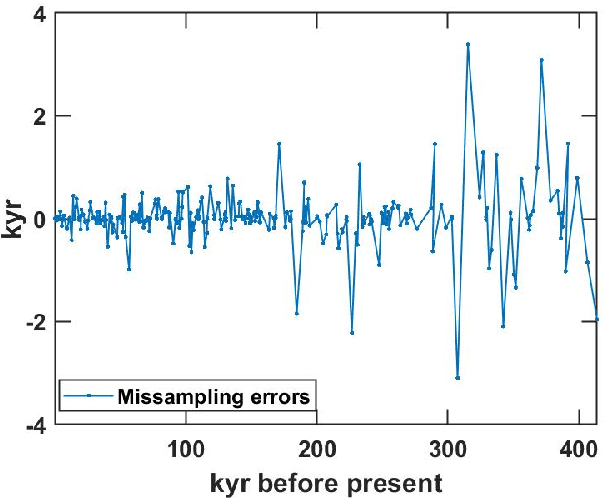
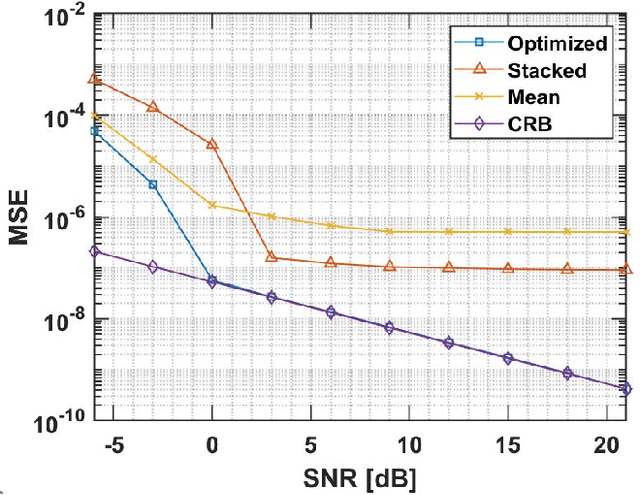
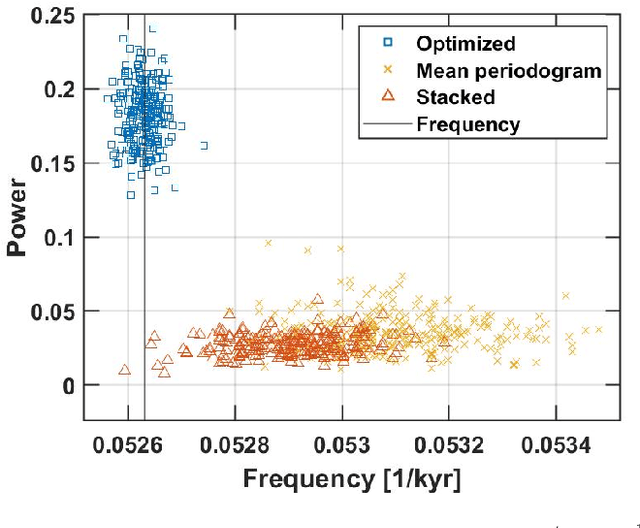
In this work, we introduce a novel approach for determining a joint sparse spectrum from several non-uniformly sampled data sets, where each data set is assumed to have its own, possibly disjoint, and only partially known, sampling times. The potential of the proposed approach is illustrated using a spectral estimation problem in paleoclimatology. In this problem, each data point derives from a separate ice core measurement, resulting in that even though all measurements reflect the same periodicities, the sampling times and phases differ among the data sets. In addition, sampling times are only approximately known. The resulting joint estimate exploiting all available data is formulated using a sparse reconstruction framework allowing for a reliable and robust estimate of the underlying periodicities. The corresponding misspecified Cram\'er-Rao lower bound, accounting for the expected sampling uncertainties, is derived and the proposed method is shown to attain the resulting bound when the signal to noise ratio is sufficiently high. The performance of the proposed method is illustrated as compared to other commonly used approaches using both simulated and measured ice core data sets.
HFT: Lifting Perspective Representations via Hybrid Feature Transformation
Apr 11, 2022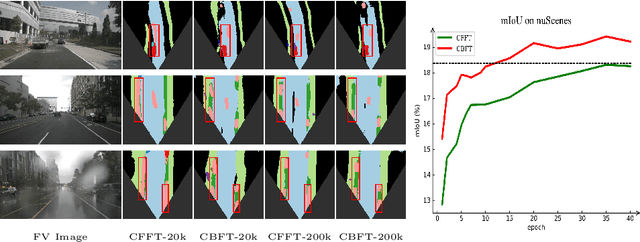
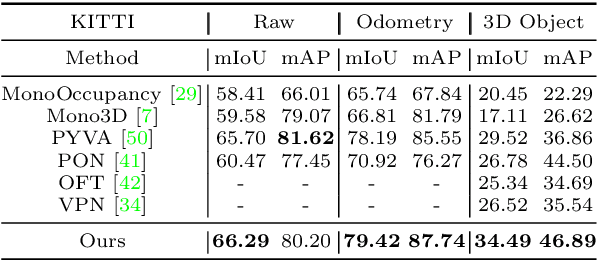
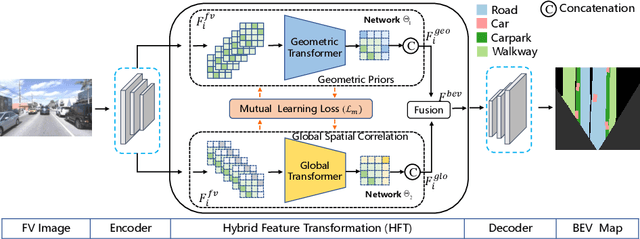
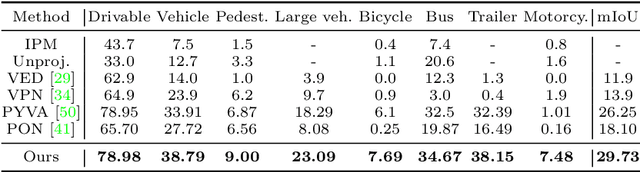
Autonomous driving requires accurate and detailed Bird's Eye View (BEV) semantic segmentation for decision making, which is one of the most challenging tasks for high-level scene perception. Feature transformation from frontal view to BEV is the pivotal technology for BEV semantic segmentation. Existing works can be roughly classified into two categories, i.e., Camera model-Based Feature Transformation (CBFT) and Camera model-Free Feature Transformation (CFFT). In this paper, we empirically analyze the vital differences between CBFT and CFFT. The former transforms features based on the flat-world assumption, which may cause distortion of regions lying above the ground plane. The latter is limited in the segmentation performance due to the absence of geometric priors and time-consuming computation. In order to reap the benefits and avoid the drawbacks of CBFT and CFFT, we propose a novel framework with a Hybrid Feature Transformation module (HFT). Specifically, we decouple the feature maps produced by HFT for estimating the layout of outdoor scenes in BEV. Furthermore, we design a mutual learning scheme to augment hybrid transformation by applying feature mimicking. Notably, extensive experiments demonstrate that with negligible extra overhead, HFT achieves a relative improvement of 13.3% on the Argoverse dataset and 16.8% on the KITTI 3D Object datasets compared to the best-performing existing method. The codes are available at https://github.com/JiayuZou2020/HFT.
RFNet-4D: Joint Object Reconstruction and Flow Estimation from 4D Point Clouds
Mar 30, 2022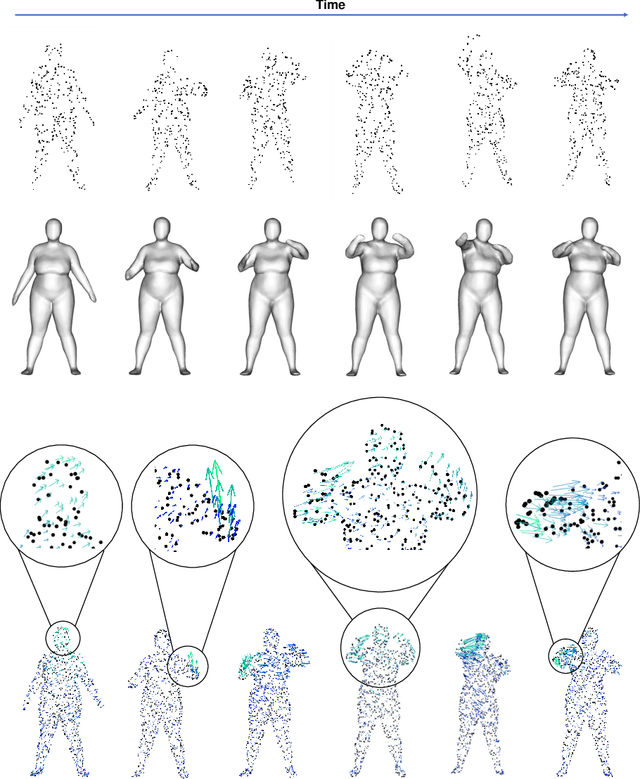
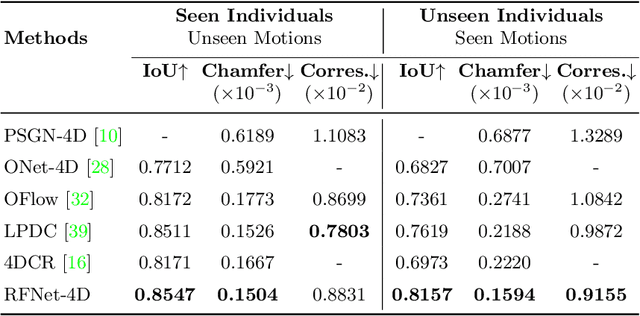
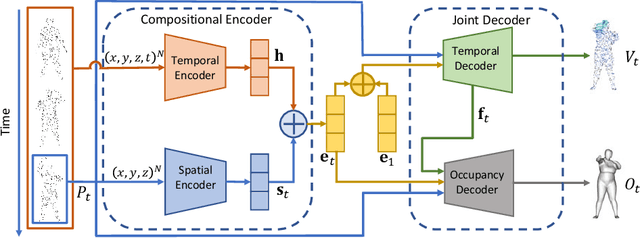
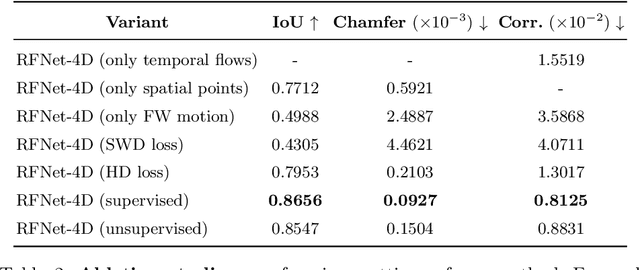
Object reconstruction from 3D point clouds has achieved impressive progress in the computer vision and computer graphics research field. However, reconstruction from time-varying point clouds (a.k.a. 4D point clouds) is generally overlooked. In this paper, we propose a new network architecture, namely RFNet-4D, that jointly reconstructs objects and their motion flows from 4D point clouds. The key insight is that simultaneously performing both tasks via learning spatial and temporal features from a sequence of point clouds can leverage individual tasks and lead to improved overall performance. The proposed network can be trained using both supervised and unsupervised learning. To prove this ability, we design a temporal vector field learning module using an unsupervised learning approach for flow estimation, leveraged by supervised learning of spatial structures for object reconstruction. Extensive experiments and analyses on benchmark dataset validated the effectiveness and efficiency of our method. As shown in experimental results, our method achieves state-of-the-art performance on both flow estimation and object reconstruction while performing much faster than existing methods in both training and inference.
Goal Recognition as Reinforcement Learning
Feb 13, 2022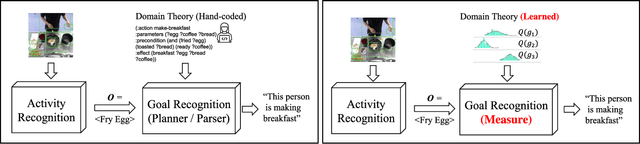
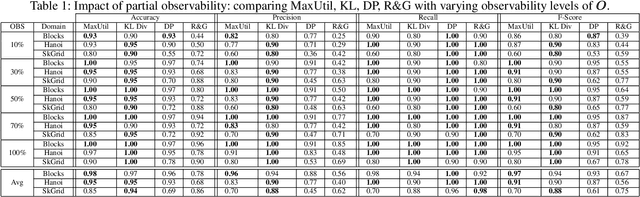
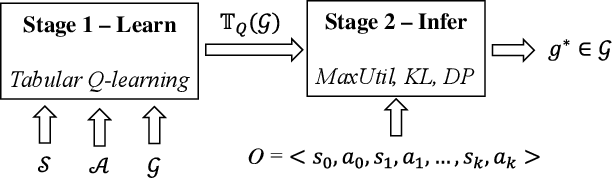

Most approaches for goal recognition rely on specifications of the possible dynamics of the actor in the environment when pursuing a goal. These specifications suffer from two key issues. First, encoding these dynamics requires careful design by a domain expert, which is often not robust to noise at recognition time. Second, existing approaches often need costly real-time computations to reason about the likelihood of each potential goal. In this paper, we develop a framework that combines model-free reinforcement learning and goal recognition to alleviate the need for careful, manual domain design, and the need for costly online executions. This framework consists of two main stages: Offline learning of policies or utility functions for each potential goal, and online inference. We provide a first instance of this framework using tabular Q-learning for the learning stage, as well as three measures that can be used to perform the inference stage. The resulting instantiation achieves state-of-the-art performance against goal recognizers on standard evaluation domains and superior performance in noisy environments.