 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Class of Two-Timescale Stochastic EM Algorithms for Nonconvex Latent Variable Models
Mar 18, 2022

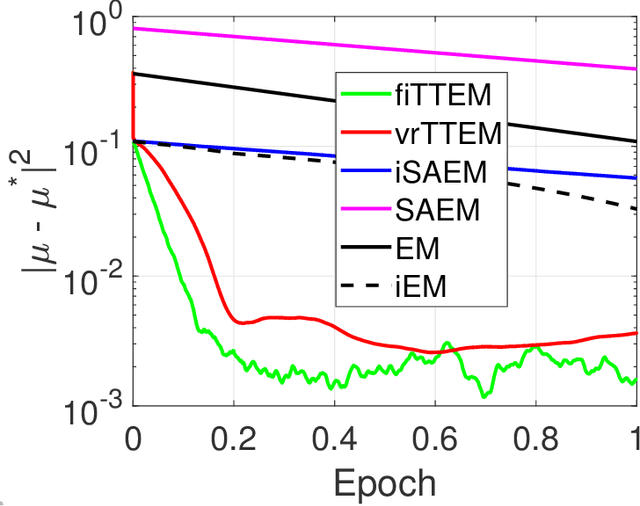


The Expectation-Maximization (EM) algorithm is a popular choice for learning latent variable models. Variants of the EM have been initially introduced, using incremental updates to scale to large datasets, and using Monte Carlo (MC) approximations to bypass the intractable conditional expectation of the latent data for most nonconvex models. In this paper, we propose a general class of methods called Two-Timescale EM Methods based on a two-stage approach of stochastic updates to tackle an essential nonconvex optimization task for latent variable models. We motivate the choice of a double dynamic by invoking the variance reduction virtue of each stage of the method on both sources of noise: the index sampling for the incremental update and the MC approximation. We establish finite-time and global convergence bounds for nonconvex objective functions. Numerical applications on various models such as deformable template for image analysis or nonlinear models for pharmacokinetics are also presented to illustrate our findings.
A deep residual learning implementation of Metamorphosis
Feb 01, 2022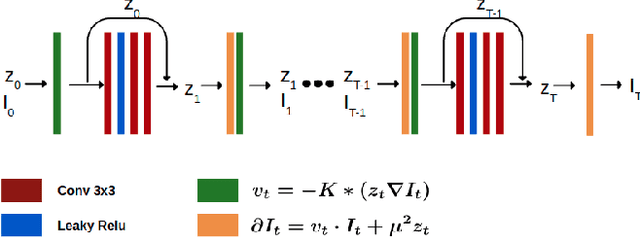
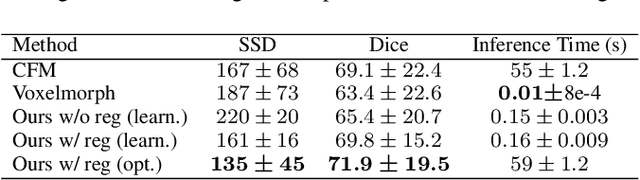
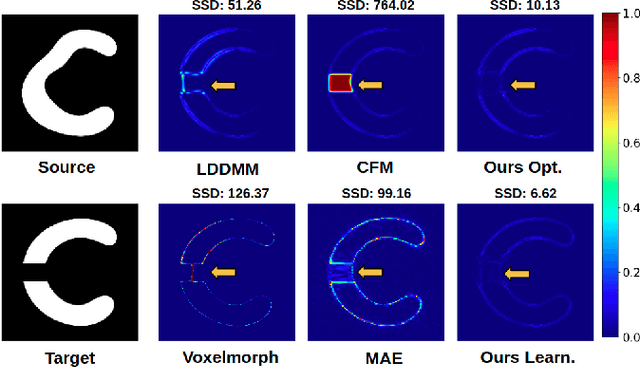
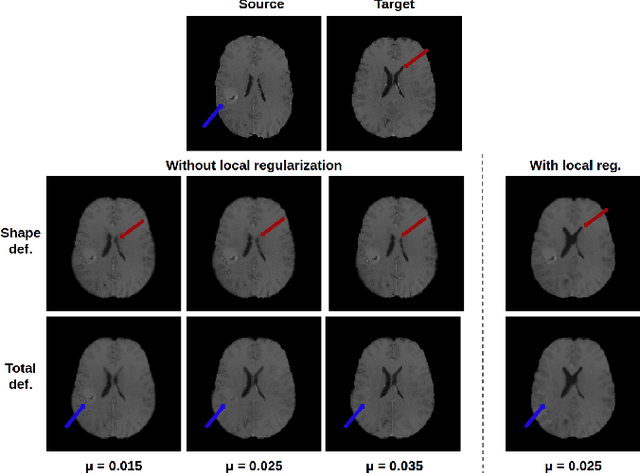
In medical imaging, most of the image registration methods implicitly assume a one-to-one correspondence between the source and target images (i.e., diffeomorphism). However, this is not necessarily the case when dealing with pathological medical images (e.g., presence of a tumor, lesion, etc.). To cope with this issue, the Metamorphosis model has been proposed. It modifies both the shape and the appearance of an image to deal with the geometrical and topological differences. However, the high computational time and load have hampered its applications so far. Here, we propose a deep residual learning implementation of Metamorphosis that drastically reduces the computational time at inference. Furthermore, we also show that the proposed framework can easily integrate prior knowledge of the localization of topological changes (e.g., segmentation masks) that can act as spatial regularization to correctly disentangle appearance and shape changes. We test our method on the BraTS 2021 dataset, showing that it outperforms current state-of-the-art methods in the alignment of images with brain tumors.
R2L: Distilling Neural Radiance Field to Neural Light Field for Efficient Novel View Synthesis
Mar 31, 2022
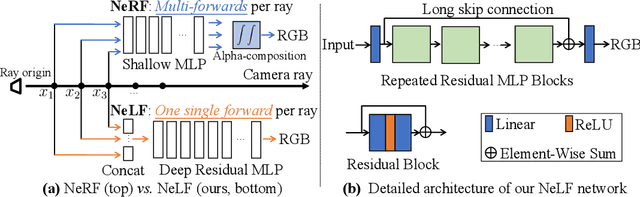
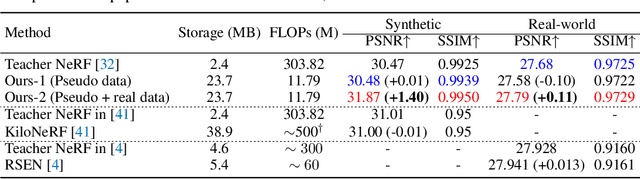
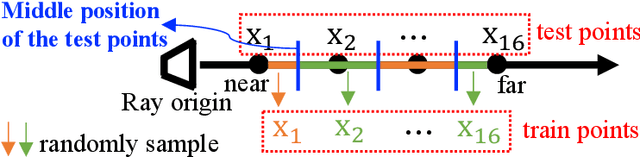
Recent research explosion on Neural Radiance Field (NeRF) shows the encouraging potential to represent complex scenes with neural networks. One major drawback of NeRF is its prohibitive inference time: Rendering a single pixel requires querying the NeRF network hundreds of times. To resolve it, existing efforts mainly attempt to reduce the number of required sampled points. However, the problem of iterative sampling still exists. On the other hand, Neural Light Field (NeLF) presents a more straightforward representation over NeRF in novel view synthesis -- the rendering of a pixel amounts to one single forward pass without ray-marching. In this work, we present a deep residual MLP network (88 layers) to effectively learn the light field. We show the key to successfully learning such a deep NeLF network is to have sufficient data, for which we transfer the knowledge from a pre-trained NeRF model via data distillation. Extensive experiments on both synthetic and real-world scenes show the merits of our method over other counterpart algorithms. On the synthetic scenes, we achieve 26-35x FLOPs reduction (per camera ray) and 28-31x runtime speedup, meanwhile delivering significantly better (1.4-2.8 dB average PSNR improvement) rendering quality than NeRF without any customized implementation tricks.
AI system for fetal ultrasound in low-resource settings
Mar 18, 2022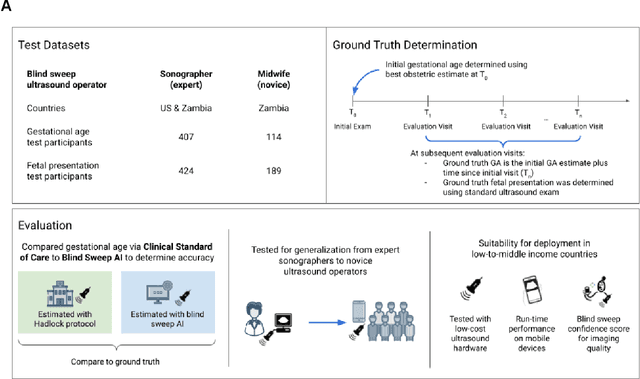
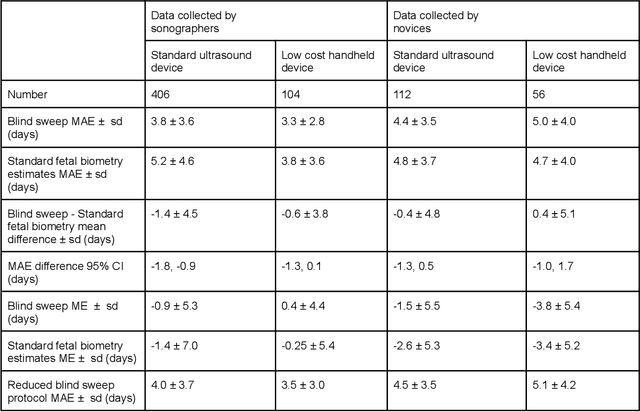
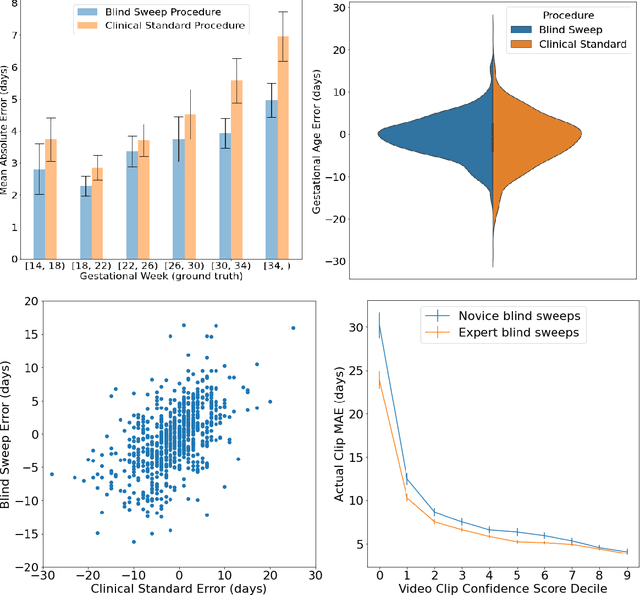
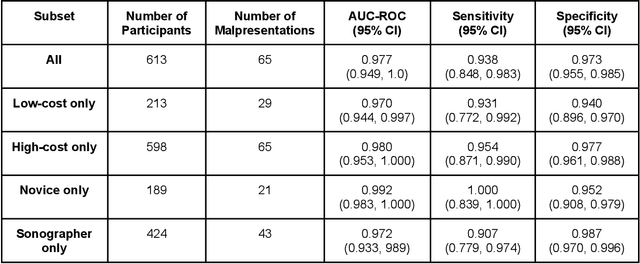
Despite considerable progress in maternal healthcare, maternal and perinatal deaths remain high in low-to-middle income countries. Fetal ultrasound is an important component of antenatal care, but shortage of adequately trained healthcare workers has limited its adoption. We developed and validated an artificial intelligence (AI) system that uses novice-acquired "blind sweep" ultrasound videos to estimate gestational age (GA) and fetal malpresentation. We further addressed obstacles that may be encountered in low-resourced settings. Using a simplified sweep protocol with real-time AI feedback on sweep quality, we have demonstrated the generalization of model performance to minimally trained novice ultrasound operators using low cost ultrasound devices with on-device AI integration. The GA model was non-inferior to standard fetal biometry estimates with as few as two sweeps, and the fetal malpresentation model had high AUC-ROCs across operators and devices. Our AI models have the potential to assist in upleveling the capabilities of lightly trained ultrasound operators in low resource settings.
CholecTriplet2021: A benchmark challenge for surgical action triplet recognition
Apr 10, 2022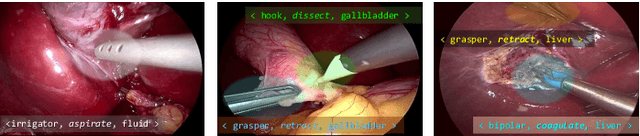

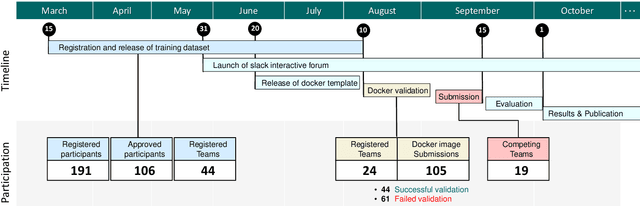
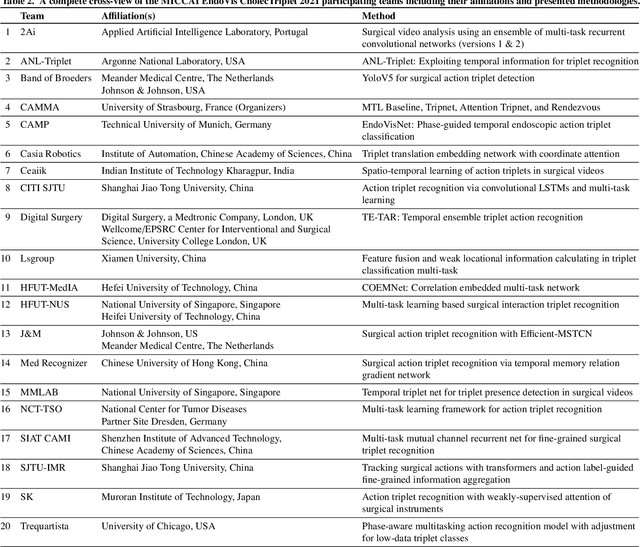
Context-aware decision support in the operating room can foster surgical safety and efficiency by leveraging real-time feedback from surgical workflow analysis. Most existing works recognize surgical activities at a coarse-grained level, such as phases, steps or events, leaving out fine-grained interaction details about the surgical activity; yet those are needed for more helpful AI assistance in the operating room. Recognizing surgical actions as triplets of <instrument, verb, target> combination delivers comprehensive details about the activities taking place in surgical videos. This paper presents CholecTriplet2021: an endoscopic vision challenge organized at MICCAI 2021 for the recognition of surgical action triplets in laparoscopic videos. The challenge granted private access to the large-scale CholecT50 dataset, which is annotated with action triplet information. In this paper, we present the challenge setup and assessment of the state-of-the-art deep learning methods proposed by the participants during the challenge. A total of 4 baseline methods from the challenge organizers and 19 new deep learning algorithms by competing teams are presented to recognize surgical action triplets directly from surgical videos, achieving mean average precision (mAP) ranging from 4.2% to 38.1%. This study also analyzes the significance of the results obtained by the presented approaches, performs a thorough methodological comparison between them, in-depth result analysis, and proposes a novel ensemble method for enhanced recognition. Our analysis shows that surgical workflow analysis is not yet solved, and also highlights interesting directions for future research on fine-grained surgical activity recognition which is of utmost importance for the development of AI in surgery.
Coordinated Power Control for Network Integrated Sensing and Communication
Mar 23, 2022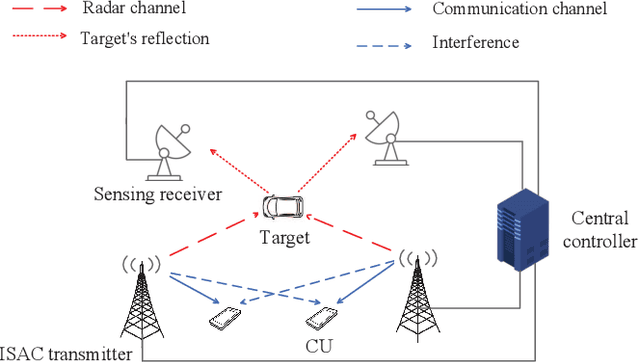
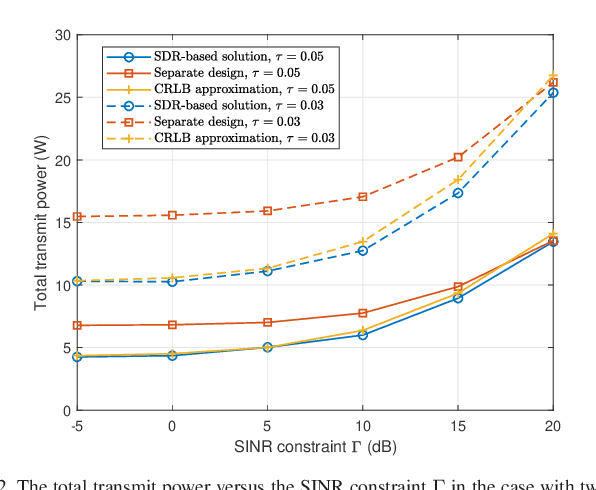
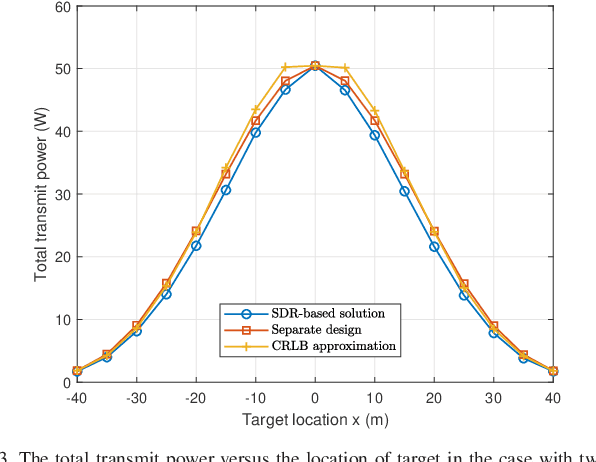
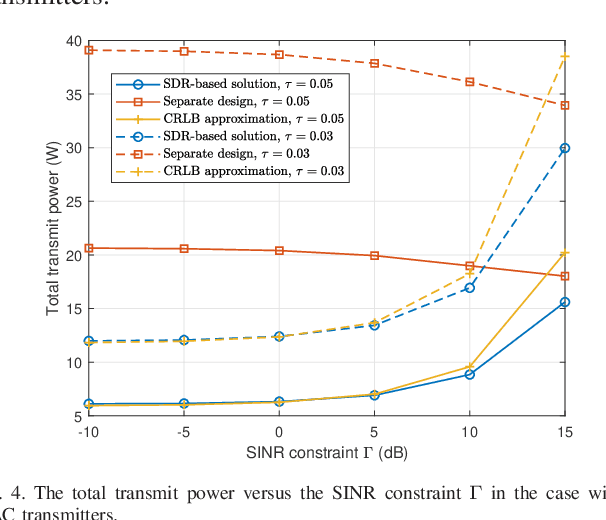
This correspondence paper studies a network integrated sensing and communication (ISAC) system that unifies the interference channel for communication and distributed radar sensing. In this system, a set of distributed ISAC transmitters send individual messages to their respective communication users (CUs), and at the same time cooperate with multiple sensing receivers to estimate the location of one target. We exploit the coordinated power control among ISAC transmitters to minimize their total transmit power while ensuring the minimum signal-to-interference-plus-noise ratio (SINR) constraints at individual CUs and the maximum Cram\'{e}r-Rao lower bound (CRLB) requirement for target location estimation. Although the formulated coordinated power control problem is non-convex and difficult to solve in general, we propose two efficient algorithms to obtain high-quality solutions based on the semi-definite relaxation (SDR) and CRLB approximation, respectively. Numerical results show that the proposed designs achieve substantial performance gains in terms of power reduction, as compared to the benchmark with a heuristic separate communication-sensing design.
Machine-learning-based arc selection for constrained shortest path problems in column generation
Jan 07, 2022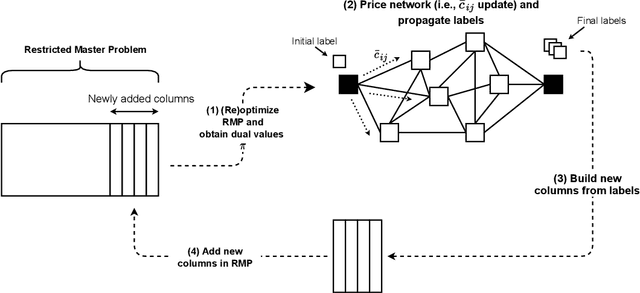


Column generation is an iterative method used to solve a variety of optimization problems. It decomposes the problem into two parts: a master problem, and one or more pricing problems (PP). The total computing time taken by the method is divided between these two parts. In routing or scheduling applications, the problems are mostly defined on a network, and the PP is usually an NP-hard shortest path problem with resource constraints. In this work, we propose a new heuristic pricing algorithm based on machine learning. By taking advantage of the data collected during previous executions, the objective is to reduce the size of the network and accelerate the PP, keeping only the arcs that have a high chance to be part of the linear relaxation solution. The method has been applied to two specific problems: the vehicle and crew scheduling problem in public transit and the vehicle routing problem with time windows. Reductions in computational time of up to 40% can be obtained.
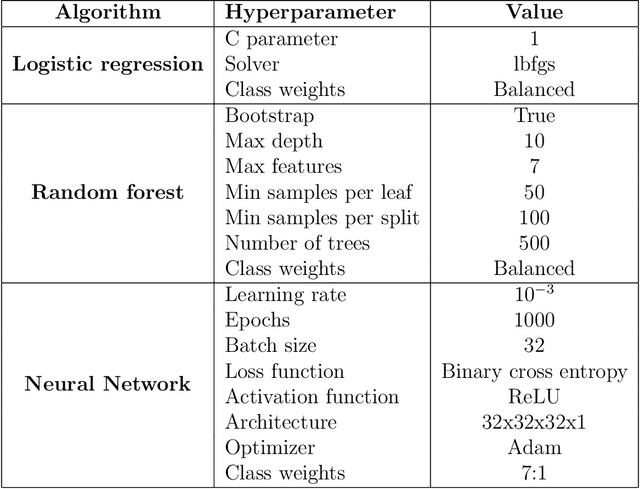
Multi-input segmentation of damaged brain in acute ischemic stroke patients using slow fusion with skip connection
Mar 18, 2022
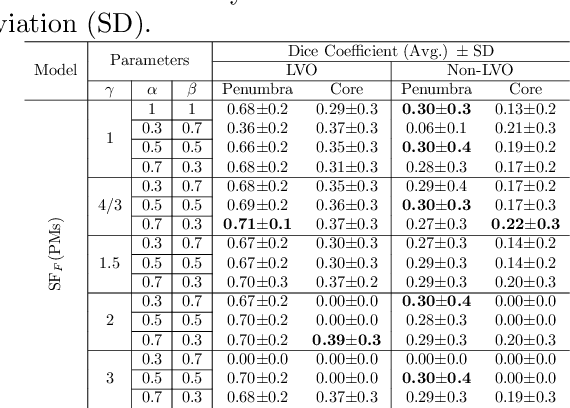
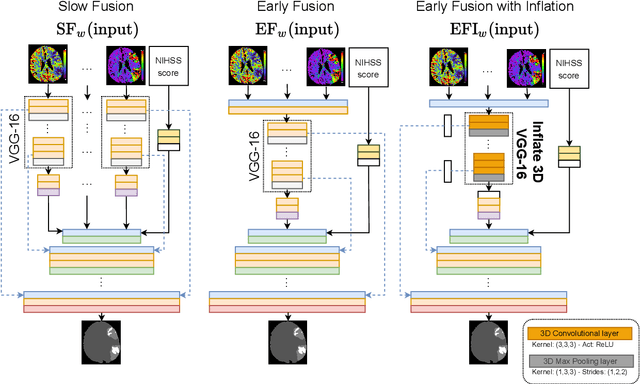
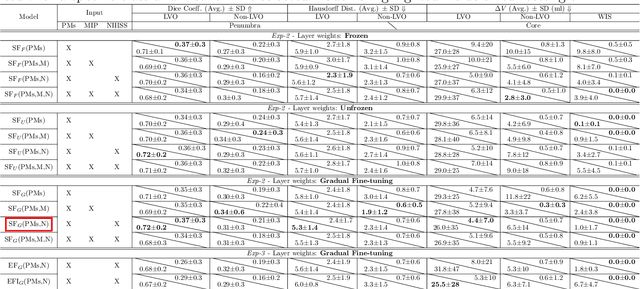
Time is a fundamental factor during stroke treatments. A fast, automatic approach that segments the ischemic regions helps treatment decisions. In clinical use today, a set of color-coded parametric maps generated from computed tomography perfusion (CTP) images are investigated manually to decide a treatment plan. We propose an automatic method based on a neural network using a set of parametric maps to segment the two ischemic regions (core and penumbra) in patients affected by acute ischemic stroke. Our model is based on a convolution-deconvolution bottleneck structure with multi-input and slow fusion. A loss function based on the focal Tversky index addresses the data imbalance issue. The proposed architecture demonstrates effective performance and results comparable to the ground truth annotated by neuroradiologists. A Dice coefficient of 0.81 for penumbra and 0.52 for core over the large vessel occlusion test set is achieved. The full implementation is available at: https://git.io/JtFGb.
A Framework for Real-time Traffic Trajectory Tracking, Speed Estimation, and Driver Behavior Calibration at Urban Intersections Using Virtual Traffic Lanes
Jun 18, 2021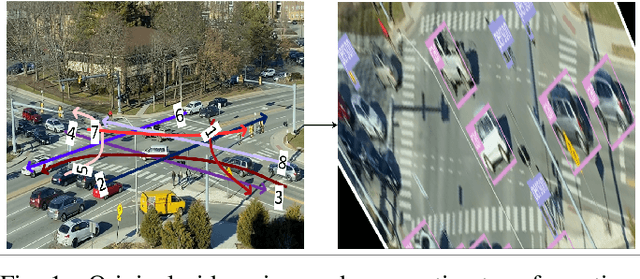


In a previous study, we presented VT-Lane, a three-step framework for real-time vehicle detection, tracking, and turn movement classification at urban intersections. In this study, we present a case study incorporating the highly accurate trajectories and movement classification obtained via VT-Lane for the purpose of speed estimation and driver behavior calibration for traffic at urban intersections. First, we use a highly instrumented vehicle to verify the estimated speeds obtained from video inference. The results of the speed validation show that our method can estimate the average travel speed of detected vehicles in real-time with an error of 0.19 m/sec, which is equivalent to 2% of the average observed travel speeds in the intersection of the study. Instantaneous speeds (at the resolution of 30 Hz) were found to be estimated with an average error of 0.21 m/sec and 0.86 m/sec respectively for free-flowing and congested traffic conditions. We then use the estimated speeds to calibrate the parameters of a driver behavior model for the vehicles in the area of study. The results show that the calibrated model replicates the driving behavior with an average error of 0.45 m/sec, indicating the high potential for using this framework for automated, large-scale calibration of car-following models from roadside traffic video data, which can lead to substantial improvements in traffic modeling via microscopic simulation.
EvoJAX: Hardware-Accelerated Neuroevolution
Feb 10, 2022

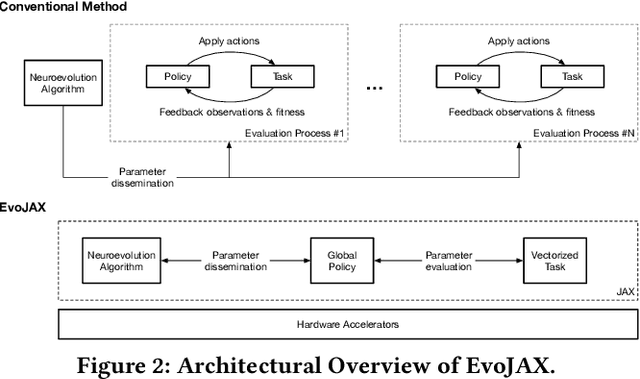
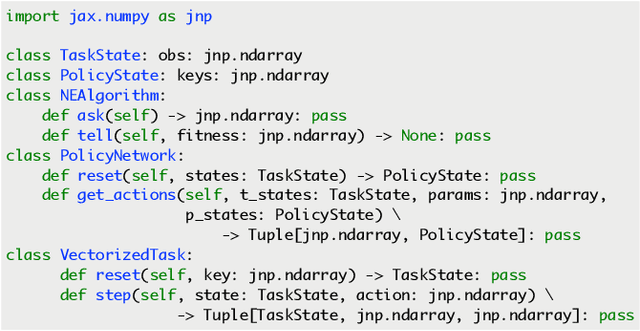
Evolutionary computation has been shown to be a highly effective method for training neural networks, particularly when employed at scale on CPU clusters. Recent work have also showcased their effectiveness on hardware accelerators, such as GPUs, but so far such demonstrations are tailored for very specific tasks, limiting applicability to other domains. We present EvoJAX, a scalable, general purpose, hardware-accelerated neuroevolution toolkit. Building on top of the JAX library, our toolkit enables neuroevolution algorithms to work with neural networks running in parallel across multiple TPU/GPUs. EvoJAX achieves very high performance by implementing the evolution algorithm, neural network and task all in NumPy, which is compiled just-in-time to run on accelerators. We provide extensible examples of EvoJAX for a wide range of tasks, including supervised learning, reinforcement learning and generative art. Since EvoJAX can find solutions to most of these tasks within minutes on a single accelerator, compared to hours or days when using CPUs, we believe our toolkit can significantly shorten the iteration time of conducting experiments for researchers working with evolutionary computation. Our project is available at https://github.com/google/evojax