 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Bipedal Locomotion with Nonlinear Model Predictive Control: Online Gait Generation using Whole-Body Dynamics
Mar 14, 2022

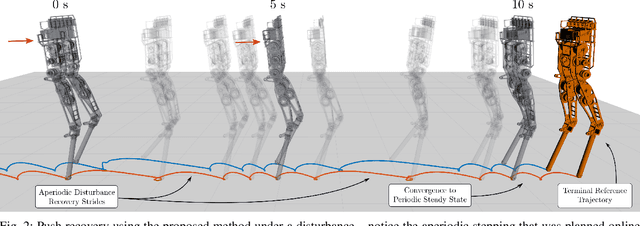
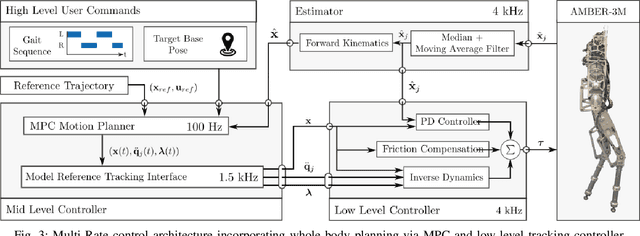
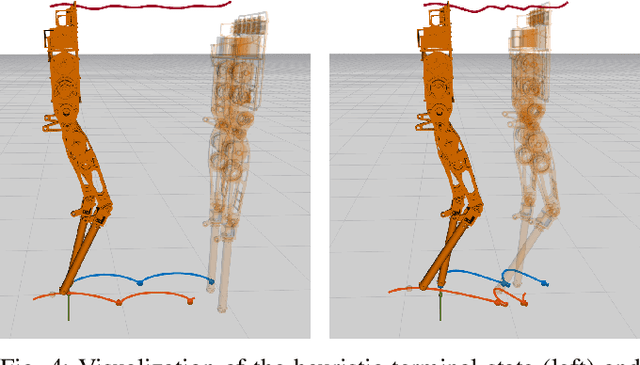
The ability to generate dynamic walking in real-time for bipedal robots with compliance and underactuation has the potential to enable locomotion in complex and unstructured environments. Yet, the high-dimensional nature of bipedal robots has limited the use of full-order rigid body dynamics to gaits which are synthesized offline and then tracked online, e.g., via whole-body controllers. In this work we develop an online nonlinear model predictive control approach that leverages the full-order dynamics to realize diverse walking behaviors. Additionally, this approach can be coupled with gaits synthesized offline via a terminal cost that enables a shorter prediction horizon; this makes rapid online re-planning feasible and bridges the gap between online reactive control and offline gait planning. We demonstrate the proposed method on the planar robot AMBER-3M, both in simulation and on hardware.
Bi-directional Loop Closure for Visual SLAM
Apr 01, 2022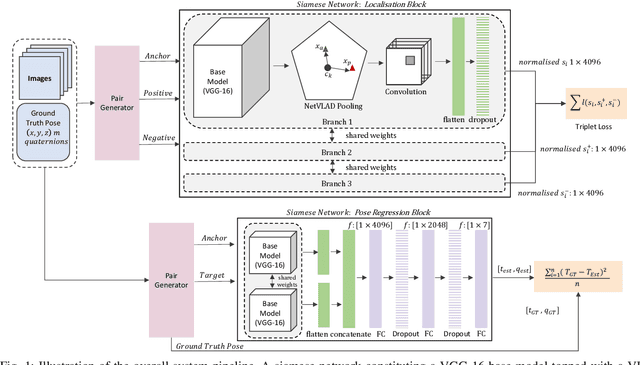
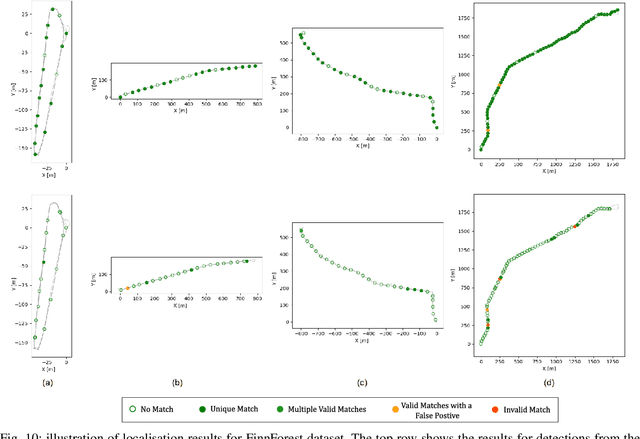
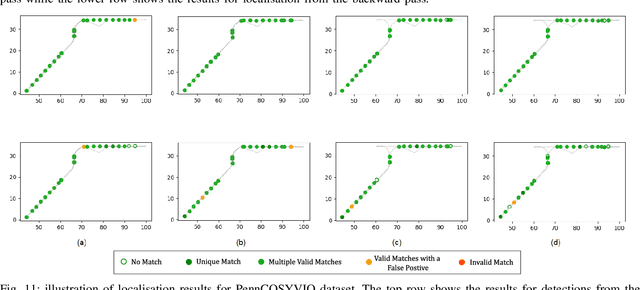
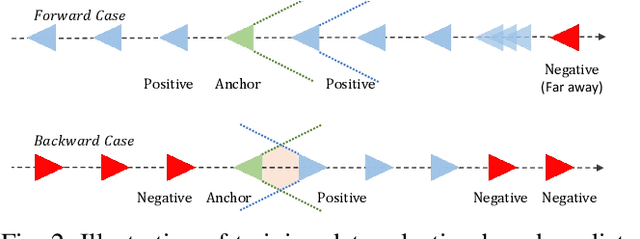
A key functional block of visual navigation system for intelligent autonomous vehicles is Loop Closure detection and subsequent relocalisation. State-of-the-Art methods still approach the problem as uni-directional along the direction of the previous motion. As a result, most of the methods fail in the absence of a significantly similar overlap of perspectives. In this study, we propose an approach for bi-directional loop closure. This will, for the first time, provide us with the capability to relocalize to a location even when traveling in the opposite direction, thus significantly reducing long-term odometry drift in the absence of a direct loop. We present a technique to select training data from large datasets in order to make them usable for the bi-directional problem. The data is used to train and validate two different CNN architectures for loop closure detection and subsequent regression of 6-DOF camera pose between the views in an end-to-end manner. The outcome packs a considerable impact and aids significantly to real-world scenarios that do not offer direct loop closure opportunities. We provide a rigorous empirical comparison against other established approaches and evaluate our method on both outdoor and indoor data from the FinnForest dataset and PennCOSYVIO dataset.
Learning Sketches for Decomposing Planning Problems into Subproblems of Bounded Width: Extended Version
Mar 28, 2022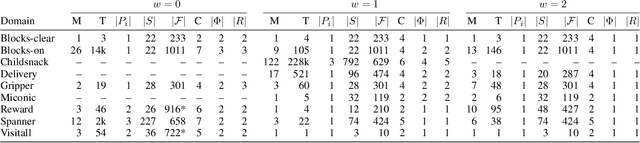
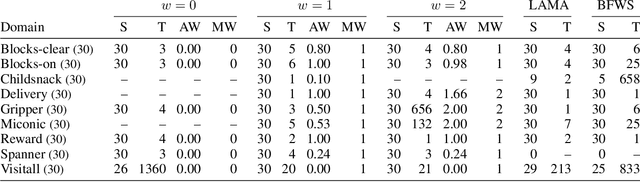
Recently, sketches have been introduced as a general language for representing the subgoal structure of instances drawn from the same domain. Sketches are collections of rules of the form C -> E over a given set of features where C expresses Boolean conditions and E expresses qualitative changes. Each sketch rule defines a subproblem: going from a state that satisfies C to a state that achieves the change expressed by E or a goal state. Sketches can encode simple goal serializations, general policies, or decompositions of bounded width that can be solved greedily, in polynomial time, by the SIW_R variant of the SIW algorithm. Previous work has shown the computational value of sketches over benchmark domains that, while tractable, are challenging for domain-independent planners. In this work, we address the problem of learning sketches automatically given a planning domain, some instances of the target class of problems, and the desired bound on the sketch width. We present a logical formulation of the problem, an implementation using the ASP solver Clingo, and experimental results. The sketch learner and the SIW_R planner yield a domain-independent planner that learns and exploits domain structure in a crisp and explicit form.
Visual Forecasting of Time Series with Image-to-Image Regression
Nov 18, 2020
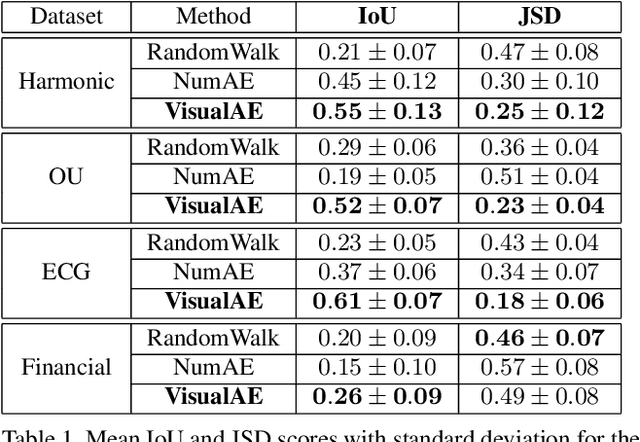
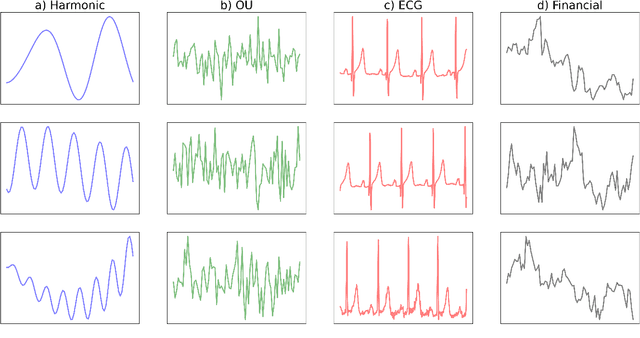
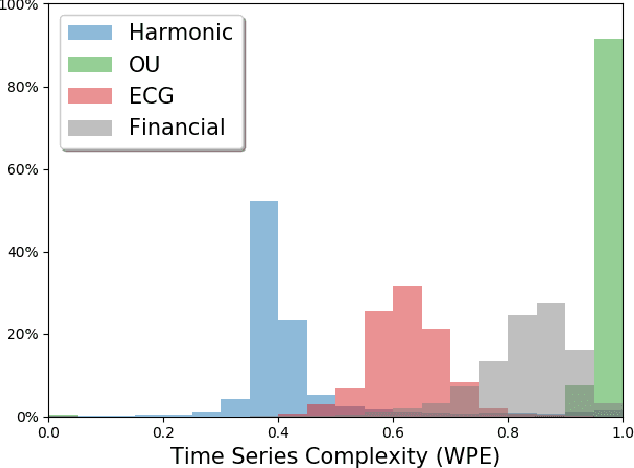
Time series forecasting is essential for agents to make decisions in many domains. Existing models rely on classical statistical methods to predict future values based on previously observed numerical information. Yet, practitioners often rely on visualizations such as charts and plots to reason about their predictions. Inspired by the end-users, we re-imagine the topic by creating a framework to produce visual forecasts, similar to the way humans intuitively do. In this work, we take a novel approach by leveraging advances in deep learning to extend the field of time series forecasting to a visual setting. We do this by transforming the numerical analysis problem into the computer vision domain. Using visualizations of time series data as input, we train a convolutional autoencoder to produce corresponding visual forecasts. We examine various synthetic and real datasets with diverse degrees of complexity. Our experiments show that visual forecasting is effective for cyclic data but somewhat less for irregular data such as stock price. Importantly, we find the proposed visual forecasting method to outperform numerical baselines. We attribute the success of the visual forecasting approach to the fact that we convert the continuous numerical regression problem into a discrete domain with quantization of the continuous target signal into pixel space.
Sketching without Worrying: Noise-Tolerant Sketch-Based Image Retrieval
Mar 28, 2022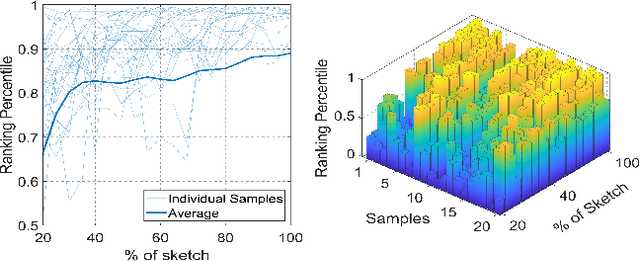
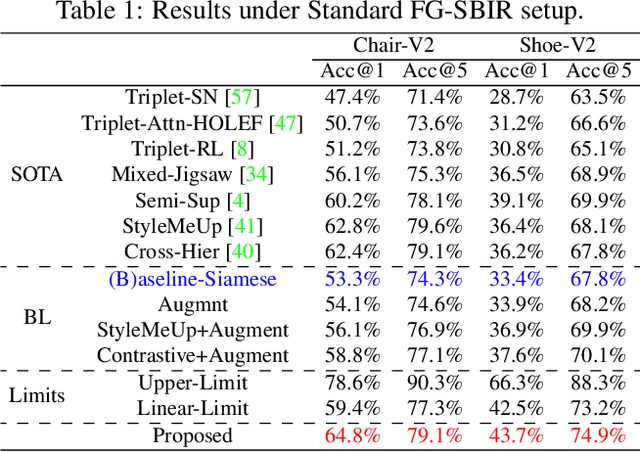
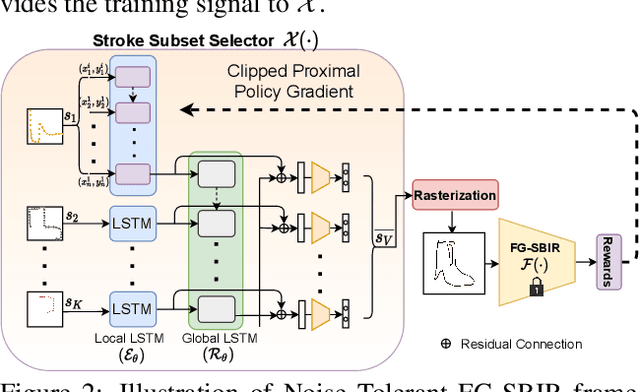
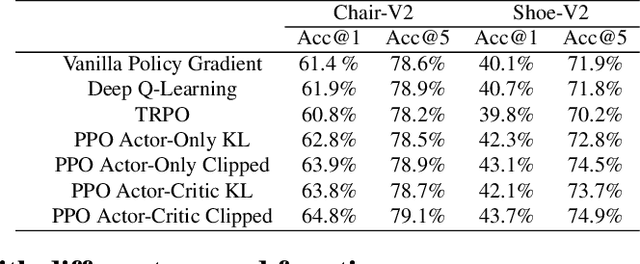
Sketching enables many exciting applications, notably, image retrieval. The fear-to-sketch problem (i.e., "I can't sketch") has however proven to be fatal for its widespread adoption. This paper tackles this "fear" head on, and for the first time, proposes an auxiliary module for existing retrieval models that predominantly lets the users sketch without having to worry. We first conducted a pilot study that revealed the secret lies in the existence of noisy strokes, but not so much of the "I can't sketch". We consequently design a stroke subset selector that {detects noisy strokes, leaving only those} which make a positive contribution towards successful retrieval. Our Reinforcement Learning based formulation quantifies the importance of each stroke present in a given subset, based on the extent to which that stroke contributes to retrieval. When combined with pre-trained retrieval models as a pre-processing module, we achieve a significant gain of 8%-10% over standard baselines and in turn report new state-of-the-art performance. Last but not least, we demonstrate the selector once trained, can also be used in a plug-and-play manner to empower various sketch applications in ways that were not previously possible.
StyleGAN-V: A Continuous Video Generator with the Price, Image Quality and Perks of StyleGAN2
Dec 29, 2021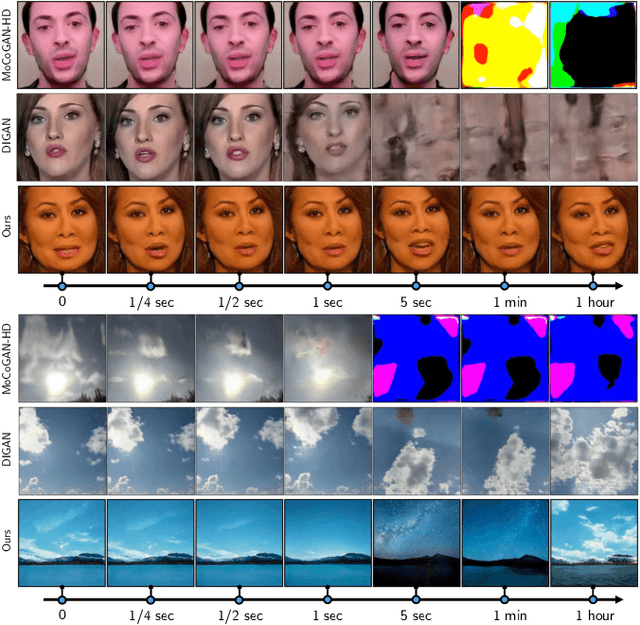
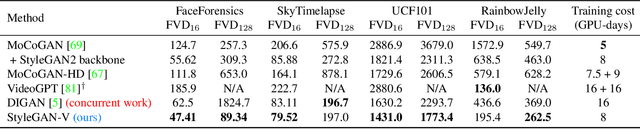

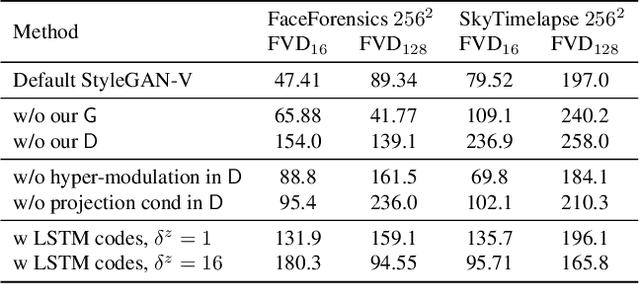
Videos show continuous events, yet most - if not all - video synthesis frameworks treat them discretely in time. In this work, we think of videos of what they should be - time-continuous signals, and extend the paradigm of neural representations to build a continuous-time video generator. For this, we first design continuous motion representations through the lens of positional embeddings. Then, we explore the question of training on very sparse videos and demonstrate that a good generator can be learned by using as few as 2 frames per clip. After that, we rethink the traditional image and video discriminators pair and propose to use a single hypernetwork-based one. This decreases the training cost and provides richer learning signal to the generator, making it possible to train directly on 1024$^2$ videos for the first time. We build our model on top of StyleGAN2 and it is just 5% more expensive to train at the same resolution while achieving almost the same image quality. Moreover, our latent space features similar properties, enabling spatial manipulations that our method can propagate in time. We can generate arbitrarily long videos at arbitrary high frame rate, while prior work struggles to generate even 64 frames at a fixed rate. Our model achieves state-of-the-art results on four modern 256$^2$ video synthesis benchmarks and one 1024$^2$ resolution one. Videos and the source code are available at the project website: https://universome.github.io/stylegan-v.
XMP-Font: Self-Supervised Cross-Modality Pre-training for Few-Shot Font Generation
Apr 11, 2022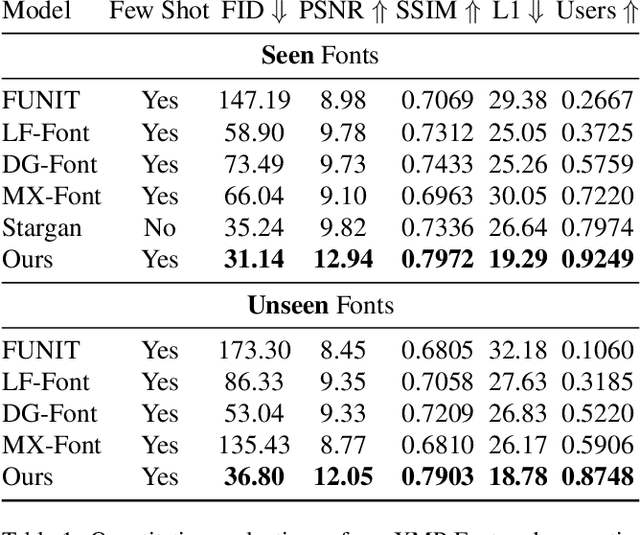
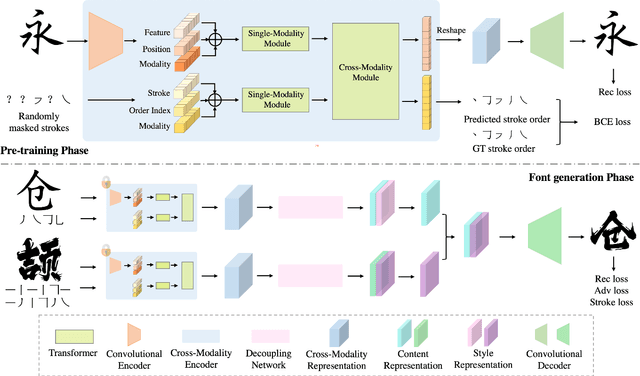
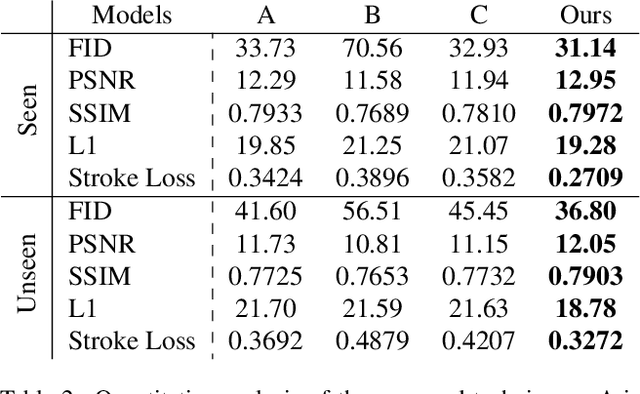
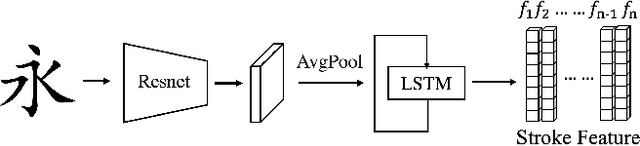
Generating a new font library is a very labor-intensive and time-consuming job for glyph-rich scripts. Few-shot font generation is thus required, as it requires only a few glyph references without fine-tuning during test. Existing methods follow the style-content disentanglement paradigm and expect novel fonts to be produced by combining the style codes of the reference glyphs and the content representations of the source. However, these few-shot font generation methods either fail to capture content-independent style representations, or employ localized component-wise style representations, which is insufficient to model many Chinese font styles that involve hyper-component features such as inter-component spacing and "connected-stroke". To resolve these drawbacks and make the style representations more reliable, we propose a self-supervised cross-modality pre-training strategy and a cross-modality transformer-based encoder that is conditioned jointly on the glyph image and the corresponding stroke labels. The cross-modality encoder is pre-trained in a self-supervised manner to allow effective capture of cross- and intra-modality correlations, which facilitates the content-style disentanglement and modeling style representations of all scales (stroke-level, component-level and character-level). The pre-trained encoder is then applied to the downstream font generation task without fine-tuning. Experimental comparisons of our method with state-of-the-art methods demonstrate our method successfully transfers styles of all scales. In addition, it only requires one reference glyph and achieves the lowest rate of bad cases in the few-shot font generation task 28% lower than the second best
Online No-regret Model-Based Meta RL for Personalized Navigation
Apr 05, 2022
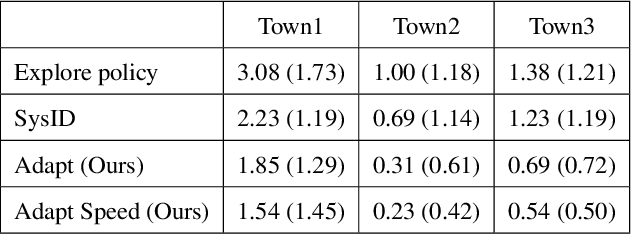
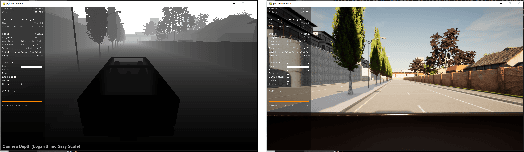
The interaction between a vehicle navigation system and the driver of the vehicle can be formulated as a model-based reinforcement learning problem, where the navigation systems (agent) must quickly adapt to the characteristics of the driver (environmental dynamics) to provide the best sequence of turn-by-turn driving instructions. Most modern day navigation systems (e.g, Google maps, Waze, Garmin) are not designed to personalize their low-level interactions for individual users across a wide range of driving styles (e.g., vehicle type, reaction time, level of expertise). Towards the development of personalized navigation systems that adapt to a variety of driving styles, we propose an online no-regret model-based RL method that quickly conforms to the dynamics of the current user. As the user interacts with it, the navigation system quickly builds a user-specific model, from which navigation commands are optimized using model predictive control. By personalizing the policy in this way, our method is able to give well-timed driving instructions that match the user's dynamics. Our theoretical analysis shows that our method is a no-regret algorithm and we provide the convergence rate in the agnostic setting. Our empirical analysis with 60+ hours of real-world user data using a driving simulator shows that our method can reduce the number of collisions by more than 60%.
Increasing the skill of short-term wind speed ensemble forecasts combining forecasts and observations via a new dynamic calibration
Jan 28, 2022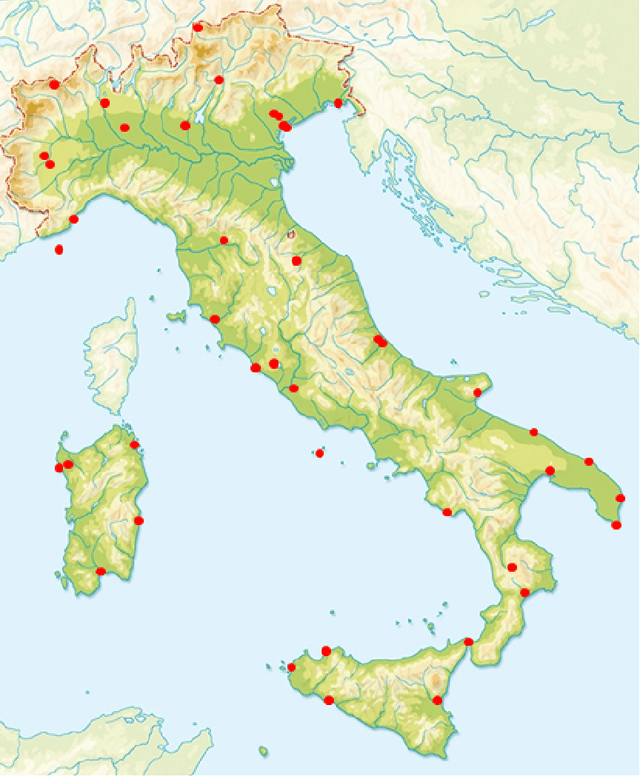
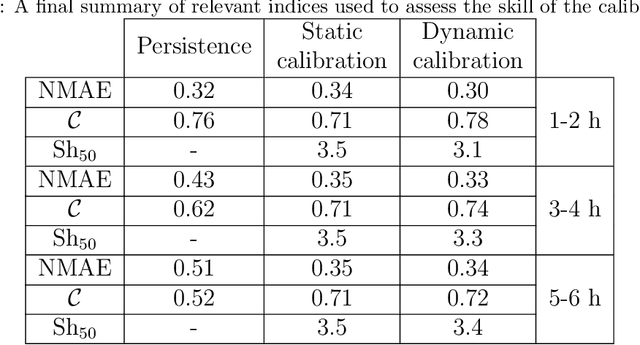
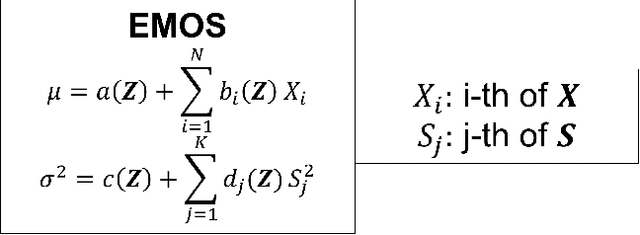
All numerical weather prediction models used for the wind industry need to produce their forecasts starting from the main synoptic hours 00, 06, 12, and 18 UTC, once the analysis becomes available. The six-hour latency time between two consecutive model runs calls for strategies to fill the gap by providing new accurate predictions having, at least, hourly frequency. This is done to accommodate the request of frequent, accurate and fresh information from traders and system regulators to continuously adapt their work strategies. Here, we propose a strategy where quasi-real time observed wind speed and weather model predictions are combined by means of a novel Ensemble Model Output Statistics (EMOS) strategy. The success of our strategy is measured by comparisons against observed wind speed from SYNOP stations over Italy in the years 2018 and 2019.
Brain-inspired Multilayer Perceptron with Spiking Neurons
Mar 28, 2022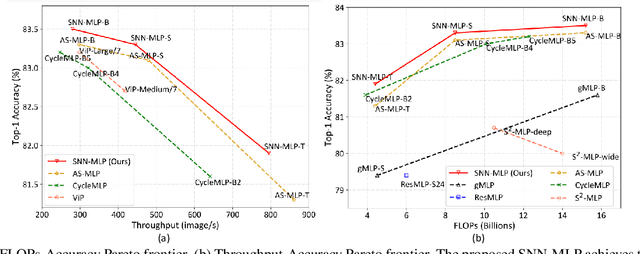
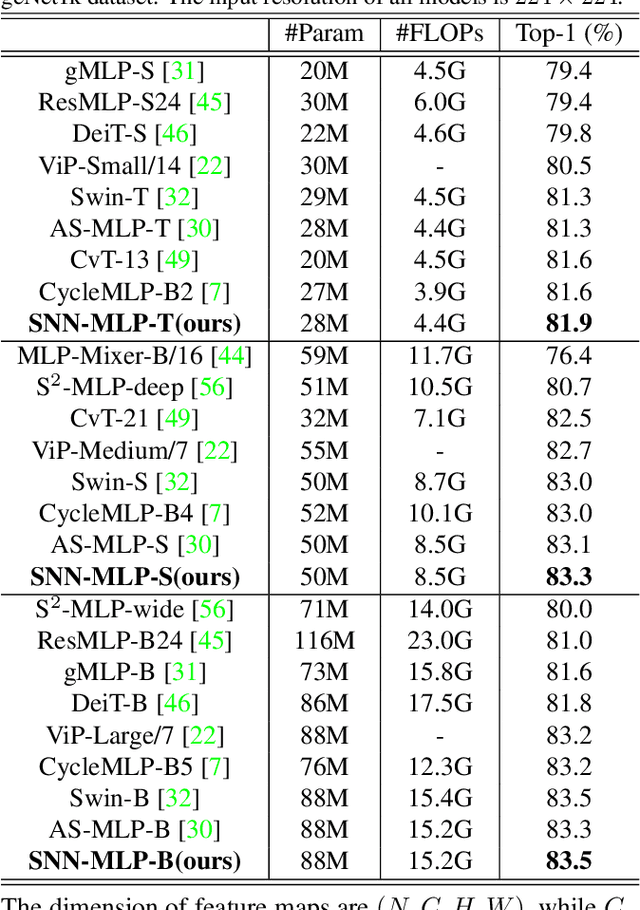
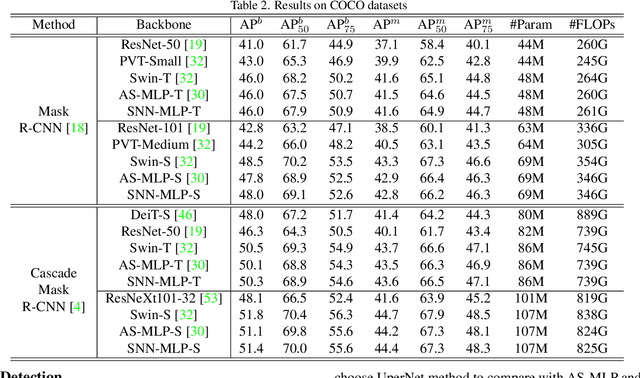
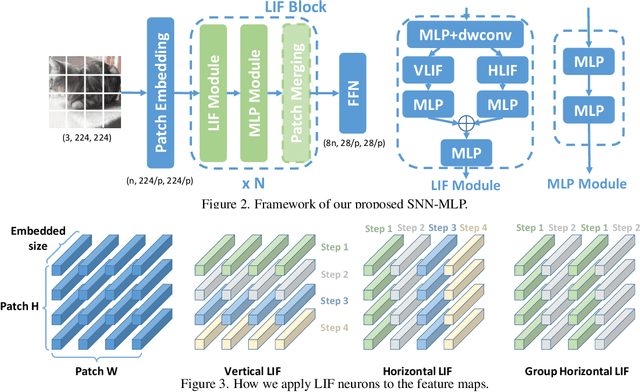
Recently, Multilayer Perceptron (MLP) becomes the hotspot in the field of computer vision tasks. Without inductive bias, MLPs perform well on feature extraction and achieve amazing results. However, due to the simplicity of their structures, the performance highly depends on the local features communication machenism. To further improve the performance of MLP, we introduce information communication mechanisms from brain-inspired neural networks. Spiking Neural Network (SNN) is the most famous brain-inspired neural network, and achieve great success on dealing with sparse data. Leaky Integrate and Fire (LIF) neurons in SNNs are used to communicate between different time steps. In this paper, we incorporate the machanism of LIF neurons into the MLP models, to achieve better accuracy without extra FLOPs. We propose a full-precision LIF operation to communicate between patches, including horizontal LIF and vertical LIF in different directions. We also propose to use group LIF to extract better local features. With LIF modules, our SNN-MLP model achieves 81.9%, 83.3% and 83.5% top-1 accuracy on ImageNet dataset with only 4.4G, 8.5G and 15.2G FLOPs, respectively, which are state-of-the-art results as far as we know.