 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Estimating Structural Disparities for Face Models
Apr 13, 2022
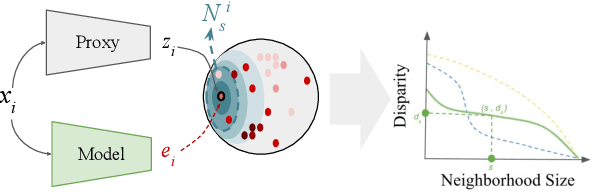
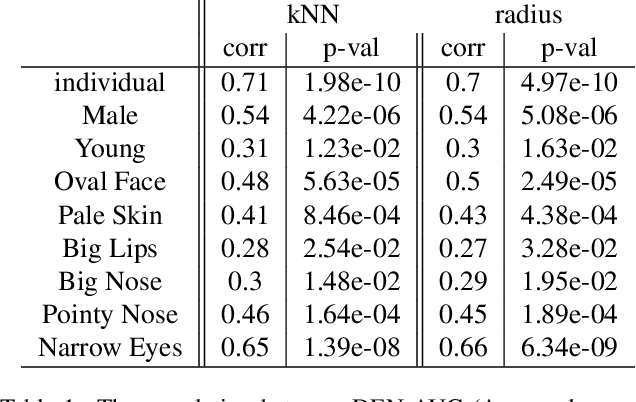

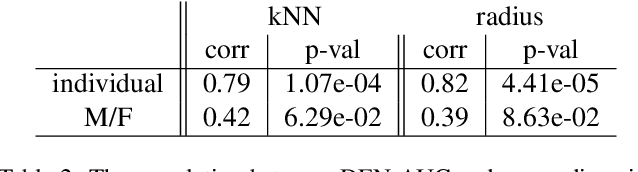
In machine learning, disparity metrics are often defined by measuring the difference in the performance or outcome of a model, across different sub-populations (groups) of datapoints. Thus, the inputs to disparity quantification consist of a model's predictions $\hat{y}$, the ground-truth labels for the predictions $y$, and group labels $g$ for the data points. Performance of the model for each group is calculated by comparing $\hat{y}$ and $y$ for the datapoints within a specific group, and as a result, disparity of performance across the different groups can be calculated. In many real world scenarios however, group labels ($g$) may not be available at scale during training and validation time, or collecting them might not be feasible or desirable as they could often be sensitive information. As a result, evaluating disparity metrics across categorical groups would not be feasible. On the other hand, in many scenarios noisy groupings may be obtainable using some form of a proxy, which would allow measuring disparity metrics across sub-populations. Here we explore performing such analysis on computer vision models trained on human faces, and on tasks such as face attribute prediction and affect estimation. Our experiments indicate that embeddings resulting from an off-the-shelf face recognition model, could meaningfully serve as a proxy for such estimation.
Nearly minimax robust estimator of the mean vector by iterative spectral dimension reduction
Apr 05, 2022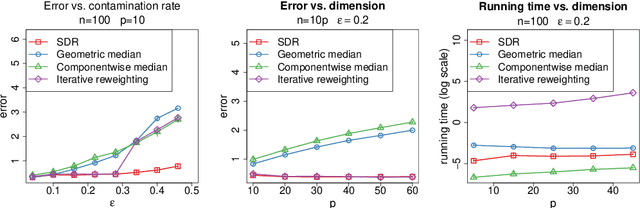
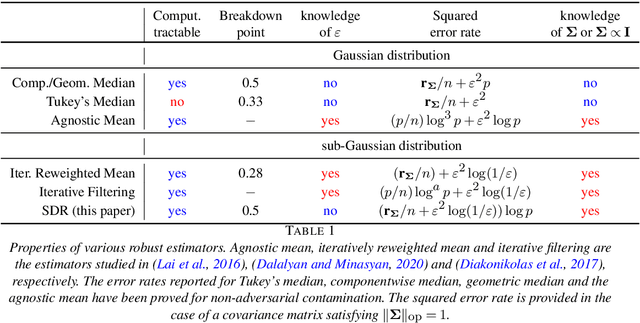
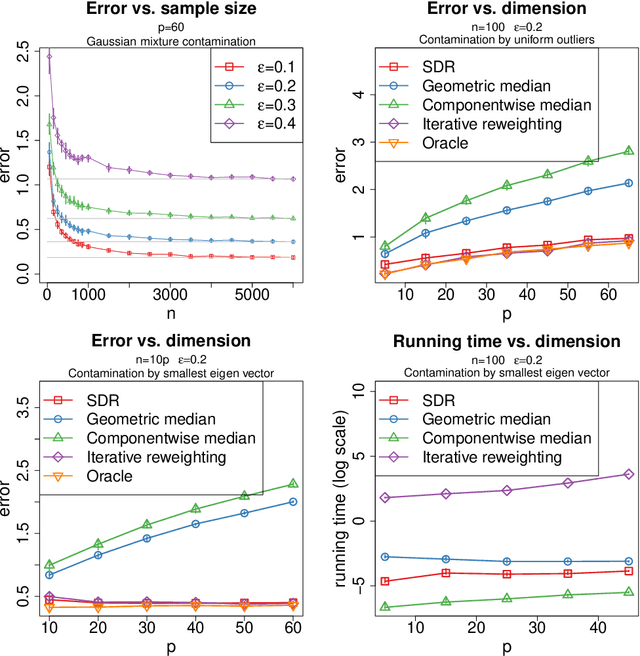
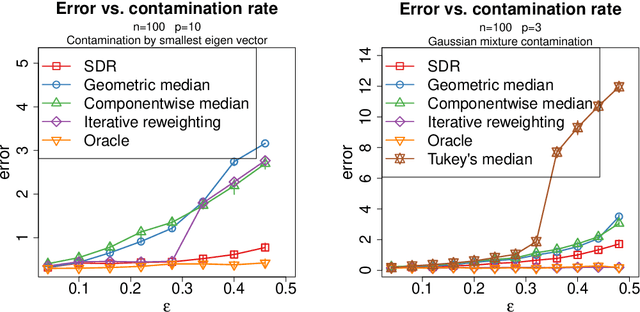
We study the problem of robust estimation of the mean vector of a sub-Gaussian distribution. We introduce an estimator based on spectral dimension reduction (SDR) and establish a finite sample upper bound on its error that is minimax-optimal up to a logarithmic factor. Furthermore, we prove that the breakdown point of the SDR estimator is equal to $1/2$, the highest possible value of the breakdown point. In addition, the SDR estimator is equivariant by similarity transforms and has low computational complexity. More precisely, in the case of $n$ vectors of dimension $p$ -- at most $\varepsilon n$ out of which are adversarially corrupted -- the SDR estimator has a squared error of order $\big(\frac{r_\Sigma}{n} + \varepsilon^2\log(1/\varepsilon)\big){\log p}$ and a running time of order $p^3 + n p^2$. Here, $r_\Sigma\le p$ is the effective rank of the covariance matrix of the reference distribution. Another advantage of the SDR estimator is that it does not require knowledge of the contamination rate and does not involve sample splitting. We also investigate extensions of the proposed algorithm and of the obtained results in the case of (partially) unknown covariance matrix.
Sionna: An Open-Source Library for Next-Generation Physical Layer Research
Mar 22, 2022
Sionna is a GPU-accelerated open-source library for link-level simulations based on TensorFlow. It enables the rapid prototyping of complex communication system architectures and provides native support for the integration of neural networks. Sionna implements a wide breadth of carefully tested state-of-the-art algorithms that can be used for benchmarking and end-to-end performance evaluation. This allows researchers to focus on their research, making it more impactful and reproducible, while saving time implementing components outside their area of expertise. This white paper provides a brief introduction to Sionna, explains its design principles and features, as well as future extensions, such as integrated ray tracing and custom CUDA kernels. We believe that Sionna is a valuable tool for research on next-generation communication systems, such as 6G, and we welcome contributions from our community.
Automatic event detection in football using tracking data
Feb 01, 2022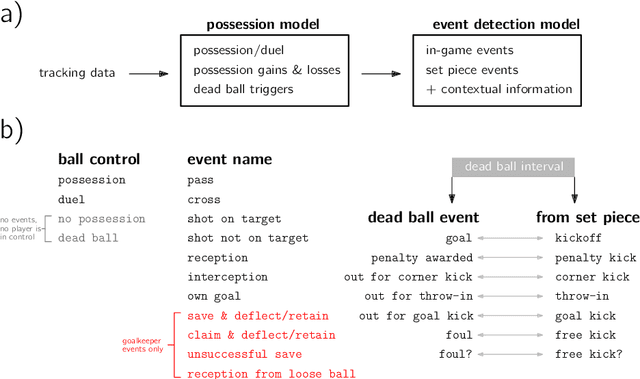
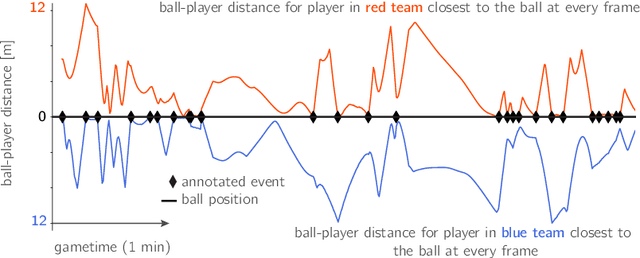
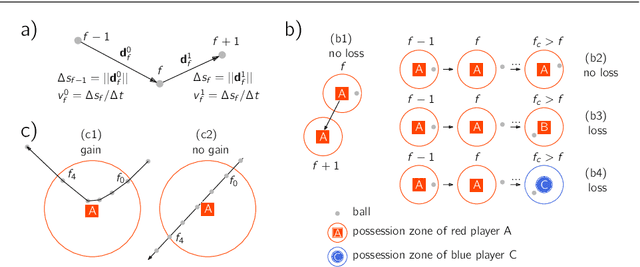
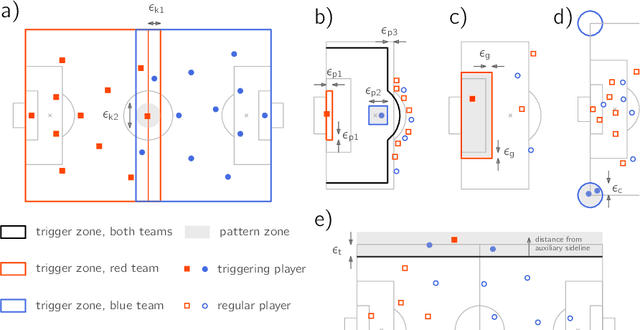
One of the main shortcomings of event data in football, which has been extensively used for analytics in the recent years, is that it still requires manual collection, thus limiting its availability to a reduced number of tournaments. In this work, we propose a computational framework to automatically extract football events using tracking data, namely the coordinates of all players and the ball. Our approach consists of two models: (1) the possession model evaluates which player was in possession of the ball at each time, as well as the distinct player configurations in the time intervals where the ball is not in play; (2) the event detection model relies on the changes in ball possession to determine in-game events, namely passes, shots, crosses, saves, receptions and interceptions, as well as set pieces. First, analyze the accuracy of tracking data for determining ball possession, as well as the accuracy of the time annotations for the manually collected events. Then, we benchmark the auto-detected events with a dataset of manually annotated events to show that in most categories the proposed method achieves $+90\%$ detection rate. Lastly, we demonstrate how the contextual information offered by tracking data can be leveraged to increase the granularity of auto-detected events, and exhibit how the proposed framework may be used to conduct a myriad of data analyses in football.
National Radio Dynamic Zone Concept with Autonomous Aerial and Ground Spectrum Sensors
Mar 17, 2022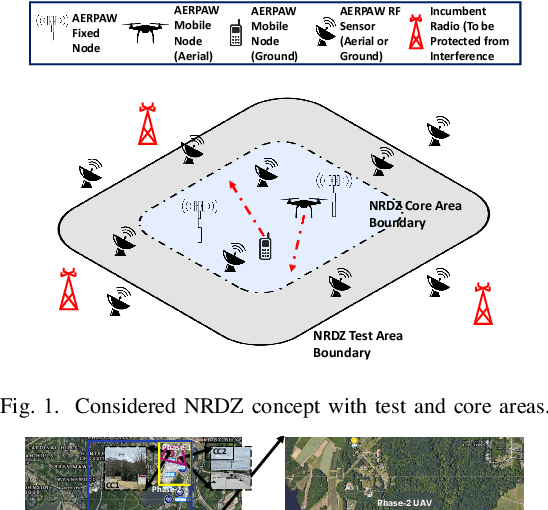
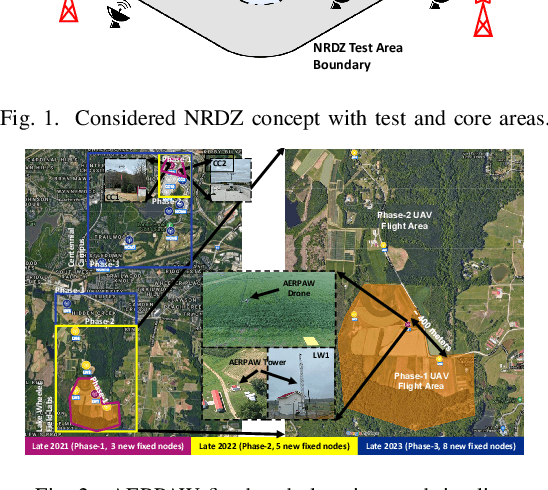
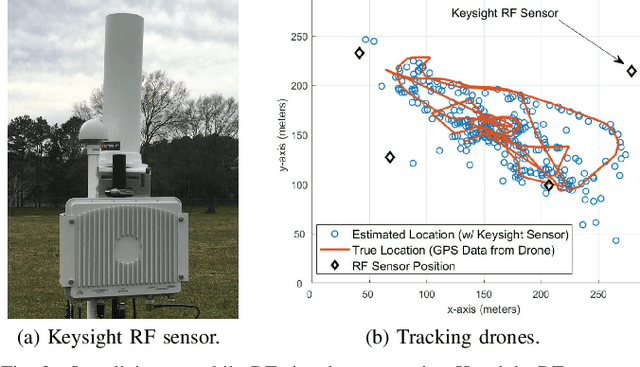
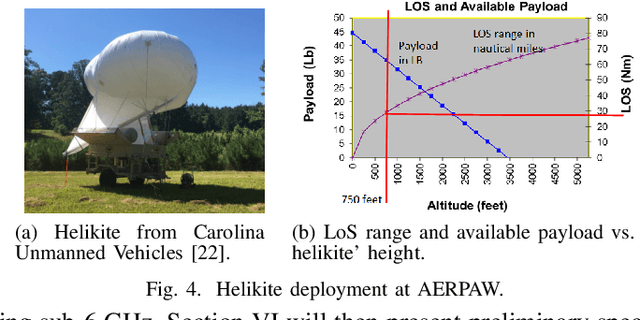
National radio dynamic zone (NRDZs) are intended to be geographically bounded areas within which controlled experiments can be carried out while protecting the nearby licensed users of the spectrum. An NRDZ will facilitate research and development of new spectrum technologies, waveforms, and protocols, in typical outdoor operational environments of such technologies. In this paper, we introduce and describe an NRDZ concept that relies on a combination of autonomous aerial and ground sensor nodes for spectrum sensing and radio environment monitoring (REM). We elaborate on key characteristics and features of an NRDZ to enable advanced wireless experimentation while also coexisting with licensed users. Some preliminary results based on simulation and experimental evaluations are also provided on out-of-zone leakage monitoring and real-time REMs.
Yes, Topology Matters in Decentralized Optimization: Refined Convergence and Topology Learning under Heterogeneous Data
Apr 09, 2022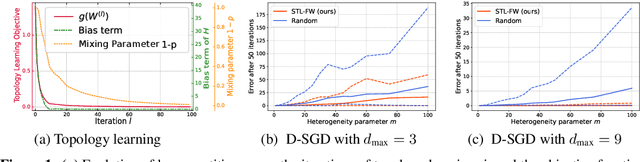
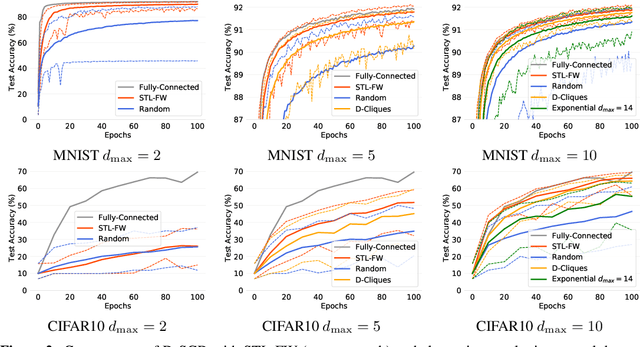
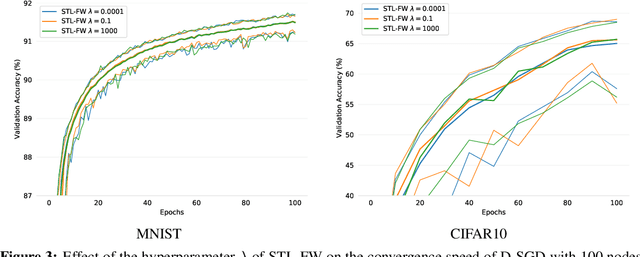
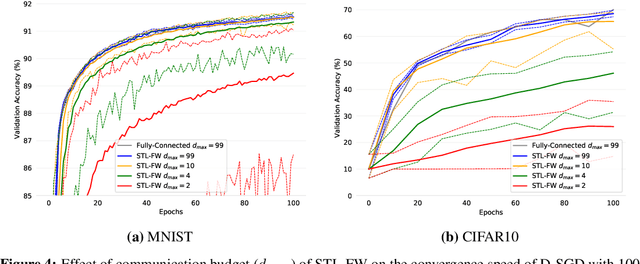
One of the key challenges in federated and decentralized learning is to design algorithms that efficiently deal with highly heterogeneous data distributions across agents. In this paper, we revisit the analysis of Decentralized Stochastic Gradient Descent algorithm (D-SGD), a popular decentralized learning algorithm, under data heterogeneity. We exhibit the key role played by a new quantity, that we call neighborhood heterogeneity, on the convergence rate of D-SGD. Unlike prior work, neighborhood heterogeneity is measured at the level of the neighborhood of an agent in the graph topology. By coupling the topology and the heterogeneity of the agents' distributions, our analysis sheds light on the poorly understood interplay between these two concepts in decentralized learning. We then argue that neighborhood heterogeneity provides a natural criterion to learn sparse data-dependent topologies that reduce (and can even eliminate) the otherwise detrimental effect of data heterogeneity on the convergence time of D-SGD. For the important case of classification with label skew, we formulate the problem of learning such a good topology as a tractable optimization problem that we solve with a Frank-Wolfe algorithm. Our approach provides a principled way to design a sparse topology that balances the number of iterations and the per-iteration communication costs of D-SGD under data heterogeneity.
StyleMapGAN: Exploiting Spatial Dimensions of Latent in GAN for Real-time Image Editing
Apr 30, 2021
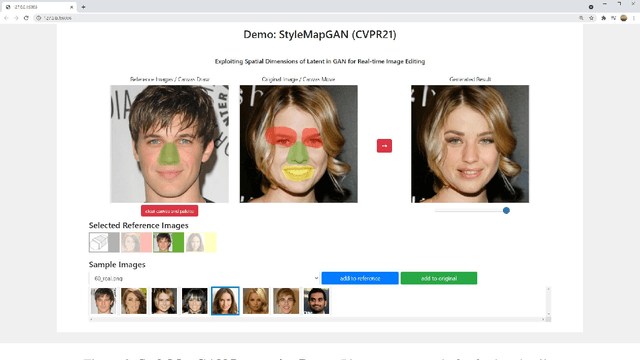
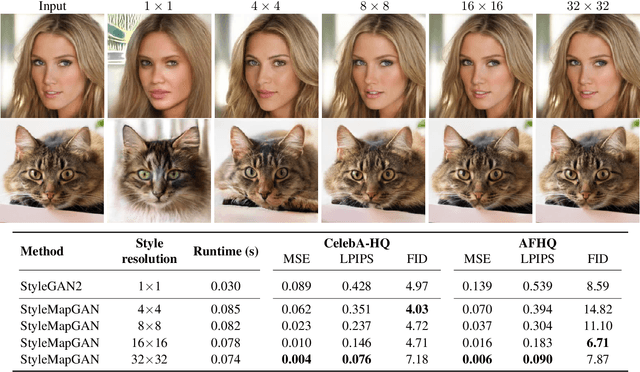
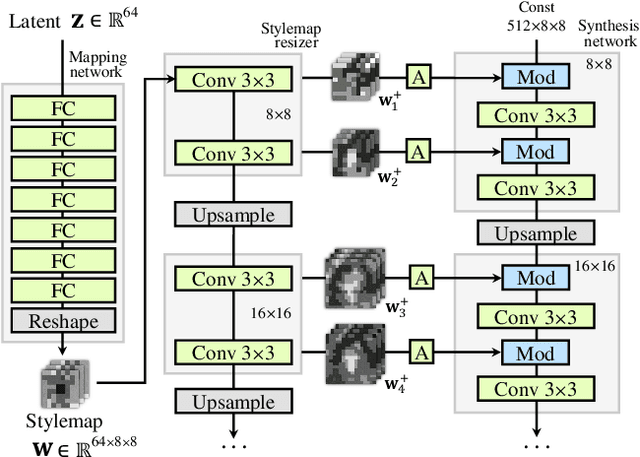
Generative adversarial networks (GANs) synthesize realistic images from random latent vectors. Although manipulating the latent vectors controls the synthesized outputs, editing real images with GANs suffers from i) time-consuming optimization for projecting real images to the latent vectors, ii) or inaccurate embedding through an encoder. We propose StyleMapGAN: the intermediate latent space has spatial dimensions, and a spatially variant modulation replaces AdaIN. It makes the embedding through an encoder more accurate than existing optimization-based methods while maintaining the properties of GANs. Experimental results demonstrate that our method significantly outperforms state-of-the-art models in various image manipulation tasks such as local editing and image interpolation. Last but not least, conventional editing methods on GANs are still valid on our StyleMapGAN. Source code is available at https://github.com/naver-ai/StyleMapGAN.
GERE: Generative Evidence Retrieval for Fact Verification
Apr 22, 2022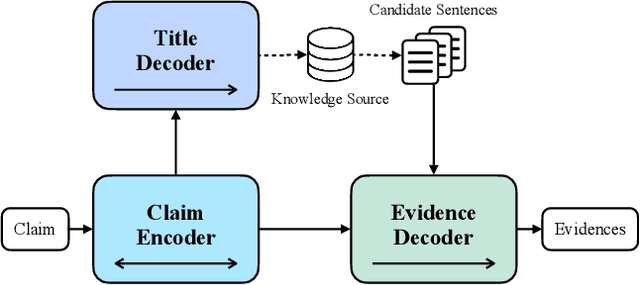
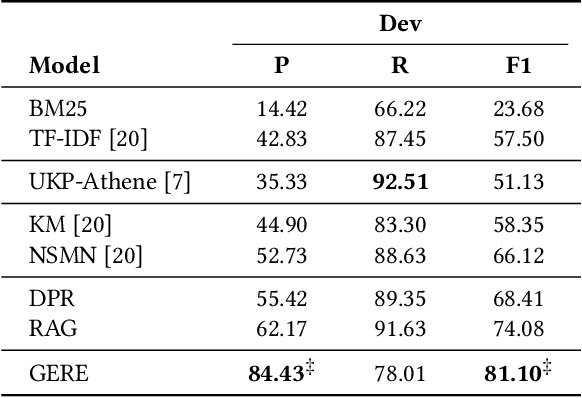
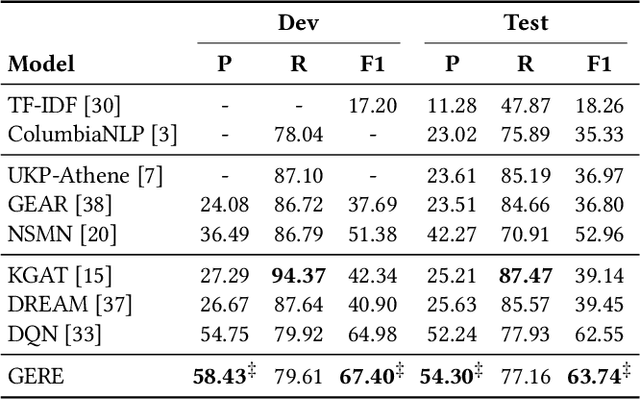
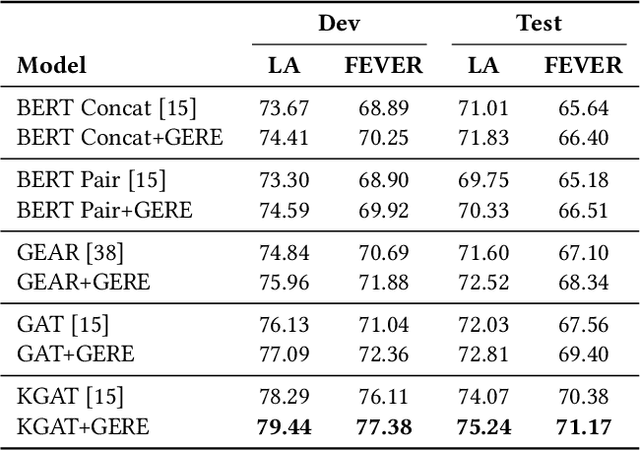
Fact verification (FV) is a challenging task which aims to verify a claim using multiple evidential sentences from trustworthy corpora, e.g., Wikipedia. Most existing approaches follow a three-step pipeline framework, including document retrieval, sentence retrieval and claim verification. High-quality evidences provided by the first two steps are the foundation of the effective reasoning in the last step. Despite being important, high-quality evidences are rarely studied by existing works for FV, which often adopt the off-the-shelf models to retrieve relevant documents and sentences in an "index-retrieve-then-rank" fashion. This classical approach has clear drawbacks as follows: i) a large document index as well as a complicated search process is required, leading to considerable memory and computational overhead; ii) independent scoring paradigms fail to capture the interactions among documents and sentences in ranking; iii) a fixed number of sentences are selected to form the final evidence set. In this work, we propose GERE, the first system that retrieves evidences in a generative fashion, i.e., generating the document titles as well as evidence sentence identifiers. This enables us to mitigate the aforementioned technical issues since: i) the memory and computational cost is greatly reduced because the document index is eliminated and the heavy ranking process is replaced by a light generative process; ii) the dependency between documents and that between sentences could be captured via sequential generation process; iii) the generative formulation allows us to dynamically select a precise set of relevant evidences for each claim. The experimental results on the FEVER dataset show that GERE achieves significant improvements over the state-of-the-art baselines, with both time-efficiency and memory-efficiency.
Multi-task nonparallel support vector machine for classification
Apr 05, 2022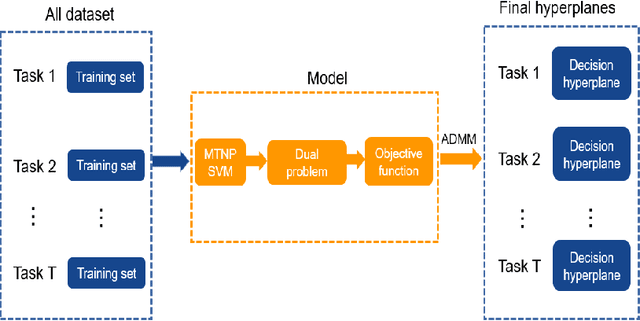
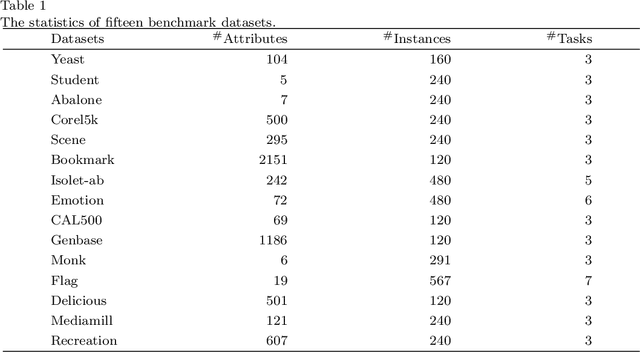
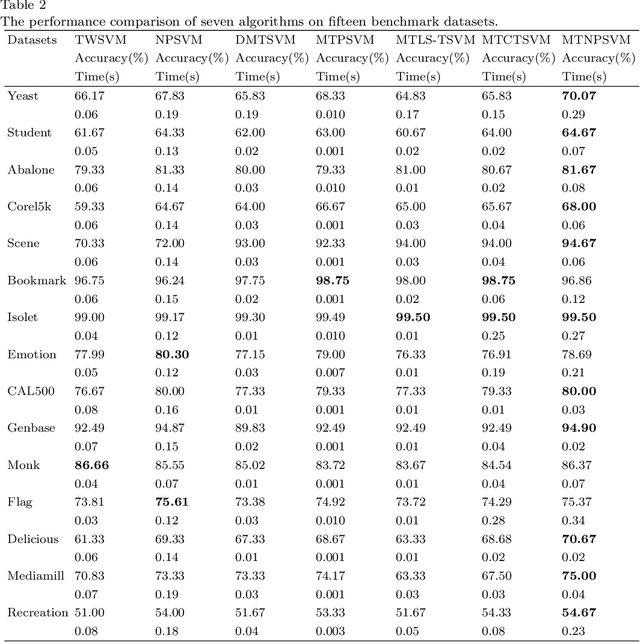
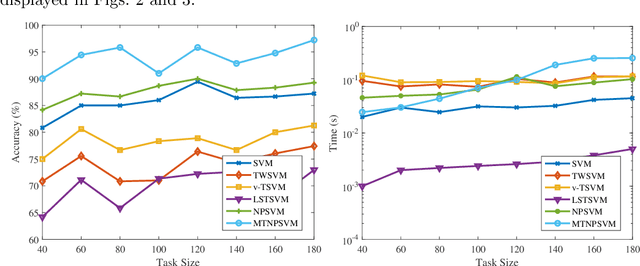
Direct multi-task twin support vector machine (DMTSVM) explores the shared information between multiple correlated tasks, then it produces better generalization performance. However, it contains matrix inversion operation when solving the dual problems, so it costs much running time. Moreover, kernel trick cannot be directly utilized in the nonlinear case. To effectively avoid above problems, a novel multi-task nonparallel support vector machine (MTNPSVM) including linear and nonlinear cases is proposed in this paper. By introducing epsilon-insensitive loss instead of square loss in DMTSVM, MTNPSVM effectively avoids matrix inversion operation and takes full advantage of the kernel trick. Theoretical implication of the model is further discussed. To further improve the computational efficiency, the alternating direction method of multipliers (ADMM) is employed when solving the dual problem. The computational complexity and convergence of the algorithm are provided. In addition, the property and sensitivity of the parameter in model are further explored. The experimental results on fifteen benchmark datasets and twelve image datasets demonstrate the validity of MTNPSVM in comparison with the state-of-the-art algorithms. Finally, it is applied to real Chinese Wine dataset, and also verifies its effectiveness.
Disentangled Speech Representation Learning Based on Factorized Hierarchical Variational Autoencoder with Self-Supervised Objective
Apr 05, 2022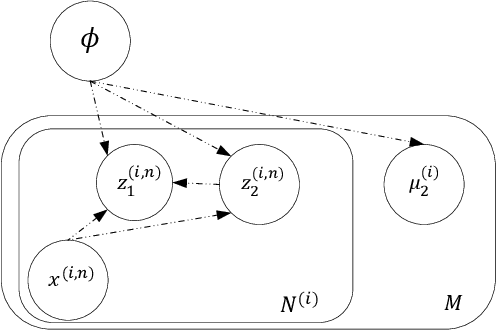

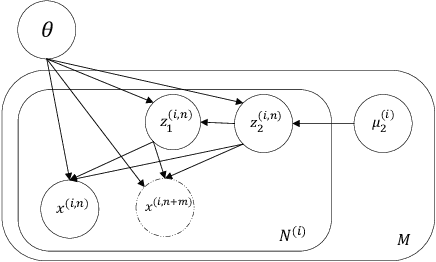
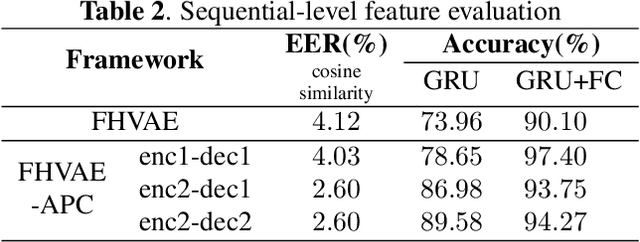
Disentangled representation learning aims to extract explanatory features or factors and retain salient information. Factorized hierarchical variational autoencoder (FHVAE) presents a way to disentangle a speech signal into sequential-level and segmental-level features, which represent speaker identity and speech content information, respectively. As a self-supervised objective, autoregressive predictive coding (APC), on the other hand, has been used in extracting meaningful and transferable speech features for multiple downstream tasks. Inspired by the success of these two representation learning methods, this paper proposes to integrate the APC objective into the FHVAE framework aiming at benefiting from the additional self-supervision target. The main proposed method requires neither more training data nor more computational cost at test time, but obtains improved meaningful representations while maintaining disentanglement. The experiments were conducted on the TIMIT dataset. Results demonstrate that FHVAE equipped with the additional self-supervised objective is able to learn features providing superior performance for tasks including speech recognition and speaker recognition. Furthermore, voice conversion, as one application of disentangled representation learning, has been applied and evaluated. The results show performance similar to baseline of the new framework on voice conversion.