 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning Structured Gaussians to Approximate Deep Ensembles
Mar 29, 2022
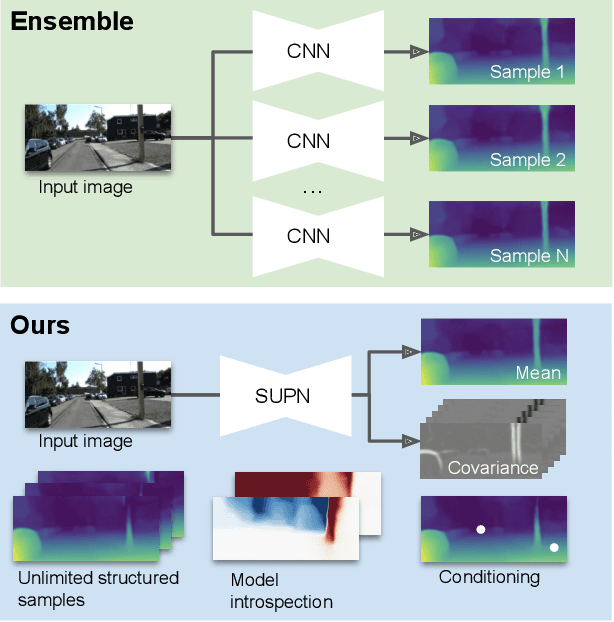

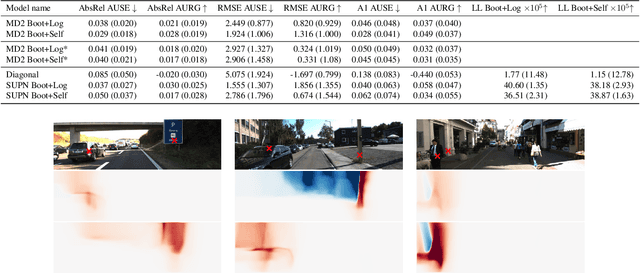
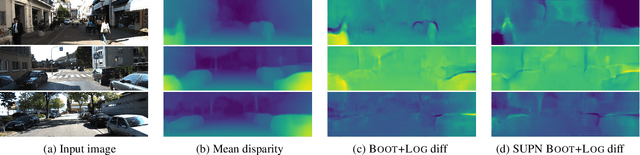
This paper proposes using a sparse-structured multivariate Gaussian to provide a closed-form approximator for the output of probabilistic ensemble models used for dense image prediction tasks. This is achieved through a convolutional neural network that predicts the mean and covariance of the distribution, where the inverse covariance is parameterised by a sparsely structured Cholesky matrix. Similarly to distillation approaches, our single network is trained to maximise the probability of samples from pre-trained probabilistic models, in this work we use a fixed ensemble of networks. Once trained, our compact representation can be used to efficiently draw spatially correlated samples from the approximated output distribution. Importantly, this approach captures the uncertainty and structured correlations in the predictions explicitly in a formal distribution, rather than implicitly through sampling alone. This allows direct introspection of the model, enabling visualisation of the learned structure. Moreover, this formulation provides two further benefits: estimation of a sample probability, and the introduction of arbitrary spatial conditioning at test time. We demonstrate the merits of our approach on monocular depth estimation and show that the advantages of our approach are obtained with comparable quantitative performance.
Intention as Commitment toward Time
Apr 17, 2020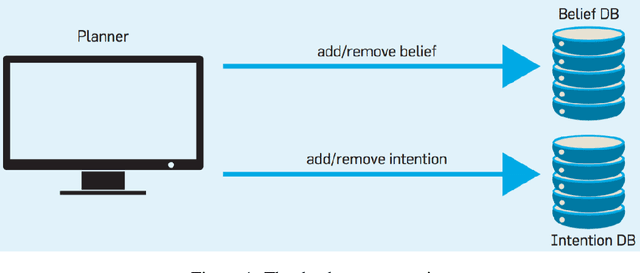
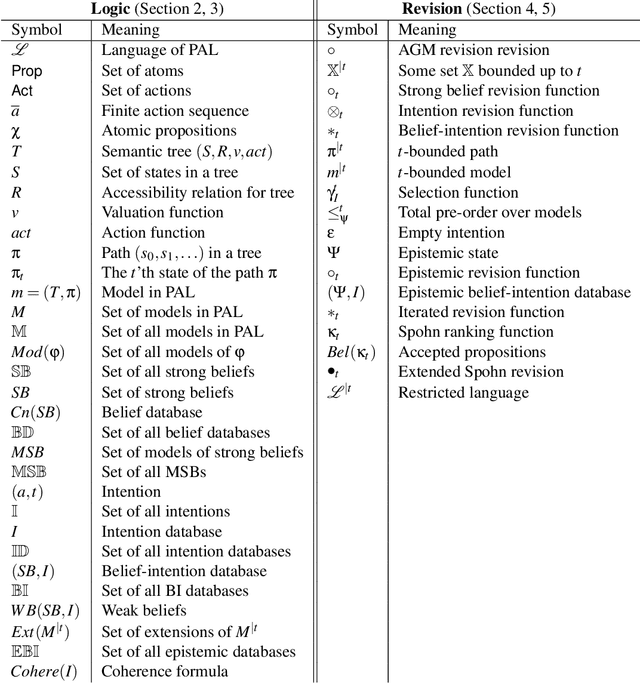
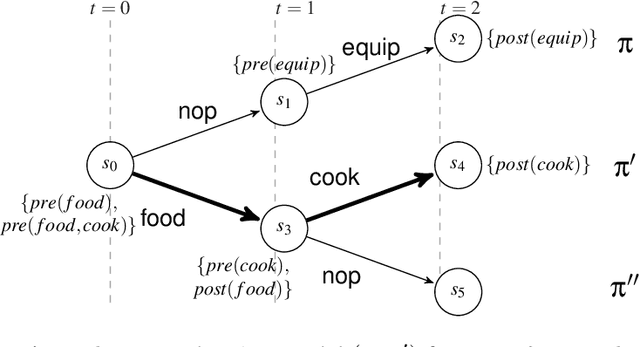
In this paper we address the interplay among intention, time, and belief in dynamic environments. The first contribution is a logic for reasoning about intention, time and belief, in which assumptions of intentions are represented by preconditions of intended actions. Intentions and beliefs are coherent as long as these assumptions are not violated, i.e. as long as intended actions can be performed such that their preconditions hold as well. The second contribution is the formalization of what-if scenarios: what happens with intentions and beliefs if a new (possibly conflicting) intention is adopted, or a new fact is learned? An agent is committed to its intended actions as long as its belief-intention database is coherent. We conceptualize intention as commitment toward time and we develop AGM-based postulates for the iterated revision of belief-intention databases, and we prove a Katsuno-Mendelzon-style representation theorem.
* 83 pages, 4 figures, Artificial Intelligence journal pre-print
Semi-supervised 3D Object Detection via Temporal Graph Neural Networks
Feb 01, 2022

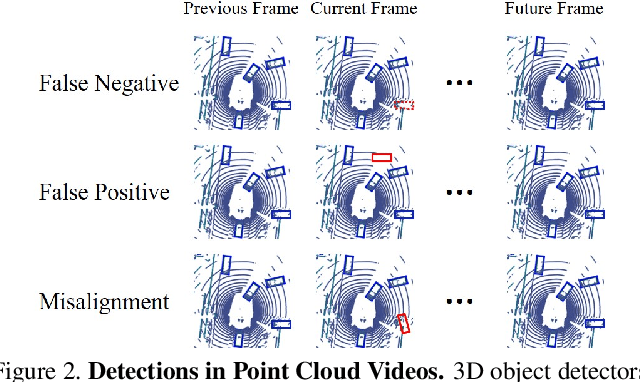
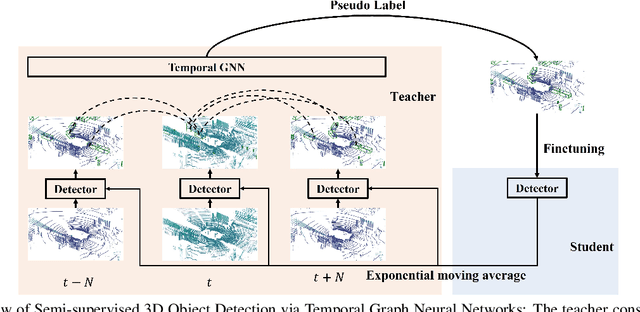
3D object detection plays an important role in autonomous driving and other robotics applications. However, these detectors usually require training on large amounts of annotated data that is expensive and time-consuming to collect. Instead, we propose leveraging large amounts of unlabeled point cloud videos by semi-supervised learning of 3D object detectors via temporal graph neural networks. Our insight is that temporal smoothing can create more accurate detection results on unlabeled data, and these smoothed detections can then be used to retrain the detector. We learn to perform this temporal reasoning with a graph neural network, where edges represent the relationship between candidate detections in different time frames. After semi-supervised learning, our method achieves state-of-the-art detection performance on the challenging nuScenes and H3D benchmarks, compared to baselines trained on the same amount of labeled data. Project and code are released at https://www.jianrenw.com/SOD-TGNN/.
Thermodynamics-informed graph neural networks
Mar 03, 2022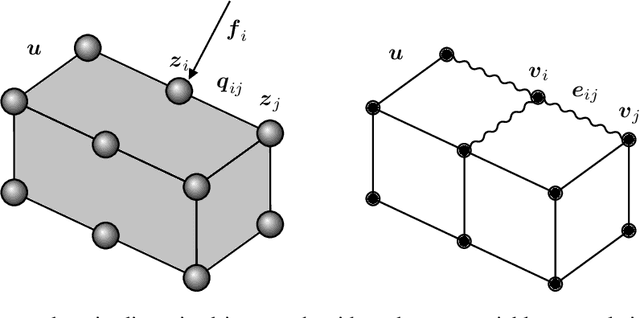
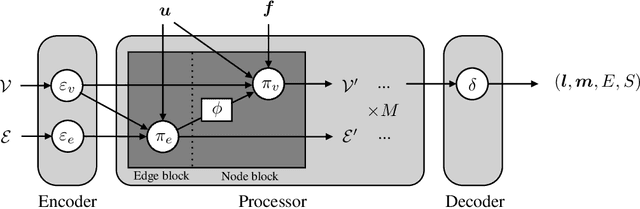
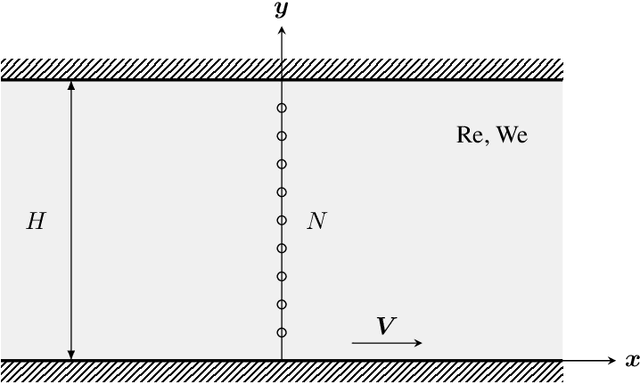
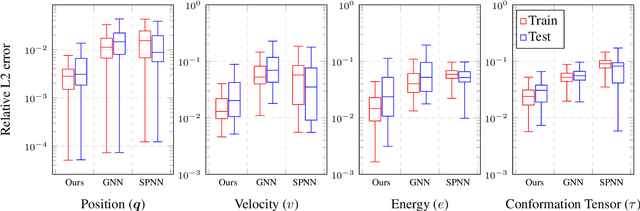
In this paper we present a deep learning method to predict the time evolution of dissipative dynamical systems. We propose using both geometric and thermodynamic inductive biases to improve accuracy and generalization of the resulting integration scheme. The first is achieved with Graph Neural Networks, which induces a non-Euclidean geometrical prior and permutation invariant node and edge update functions. The second bias is forced by learning the GENERIC structure of the problem, an extension of the Hamiltonian formalism, to model more general non-conservative dynamics. Several examples are provided in both Eulerian and Lagrangian description in the context of fluid and solid mechanics respectively.
Motion Correction via Locally Linear Embedding for Helical Photon-counting CT
Apr 05, 2022
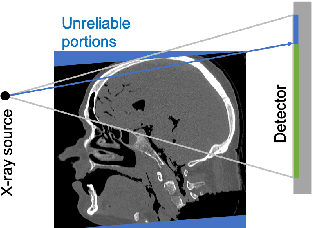
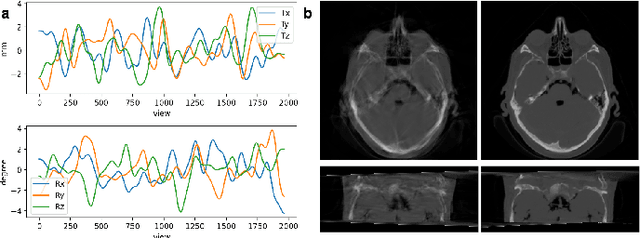
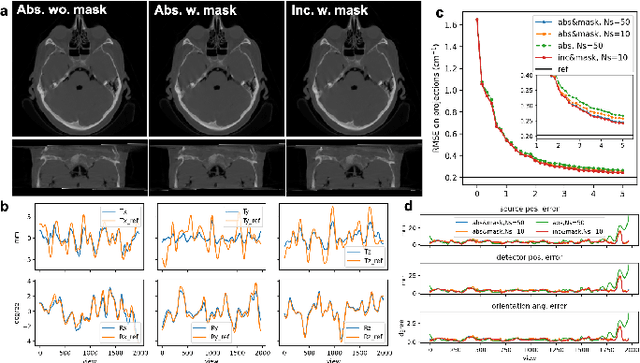
X-ray photon-counting detector (PCD) offers low noise, high resolution, and spectral characterization, representing a next generation of CT and enabling new biomedical applications. It is well known that involuntary patient motion may induce image artifacts with conventional CT scanning, and this problem becomes more serious with PCD due to its high detector pitch and extended scan time. Furthermore, PCD often comes with a substantial number of bad pixels, making analytic image reconstruction challenging and ruling out state-of-the-art motion correction methods that are based on analytical reconstruction. In this paper, we extend our previous locally linear embedding (LLE) cone-beam motion correction method to the helical scanning geometry, which is especially desirable given the high cost of large-area PCD. In addition to our adaption of LLE-based parametric searching to helical cone-beam photon-counting CT geometry, we introduce an unreliable-volume mask to improve the motion estimation accuracy and perform incremental updating on gradually refined sampling grids for optimization of both accuracy and efficiency. Our numerical results demonstrate that our method reduces the estimation errors near the two longitudinal ends of the reconstructed volume and overall image quality. The experimental results on clinical photon-counting scans of the patient extremities show significant resolution improvement after motion correction using our method, which reveals subtle fine structures previously hidden under motion blurring and artifacts.
Learning Whole Heart Mesh Generation From Patient Images For Computational Simulations
Mar 20, 2022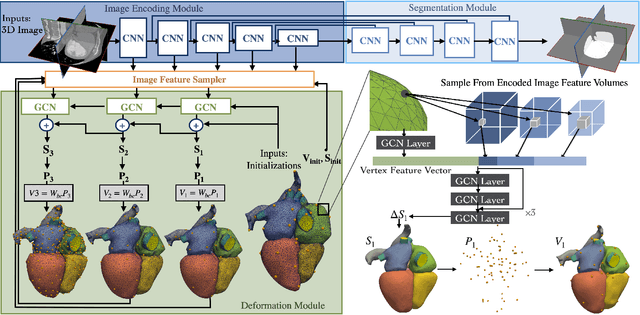
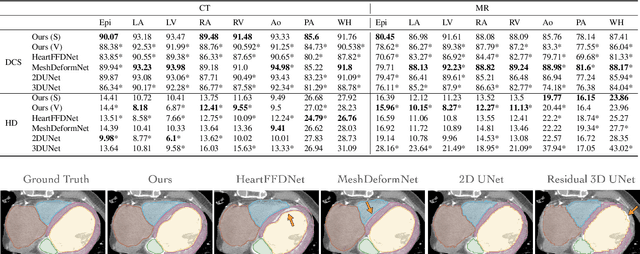
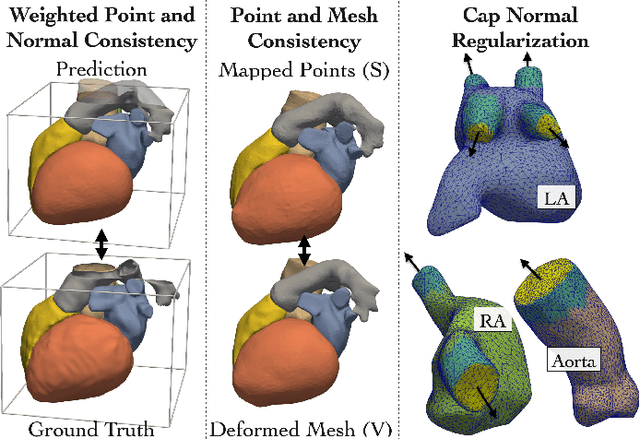
Patient-specific cardiac modeling combines geometries of the heart derived from medical images and biophysical simulations to predict various aspects of cardiac function. However, generating simulation-suitable models of the heart from patient image data often requires complicated procedures and significant human effort. We present a fast and automated deep-learning method to construct simulation-suitable models of the heart from medical images. The approach constructs meshes from 3D patient images by learning to deform a small set of deformation handles on a whole heart template. For both 3D CT and MR data, this method achieves promising accuracy for whole heart reconstruction, consistently outperforming prior methods in constructing simulation-suitable meshes of the heart. When evaluated on time-series CT data, this method produced more anatomically and temporally consistent geometries than prior methods, and was able to produce geometries that better satisfy modeling requirements for cardiac flow simulations. Our source code will be available on GitHub.
Music demixing with the sliCQ transform
Dec 09, 2021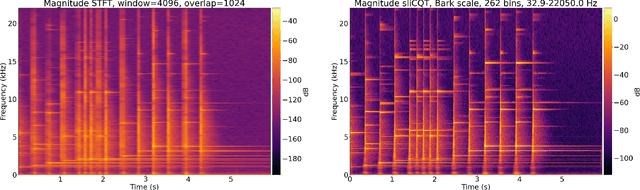
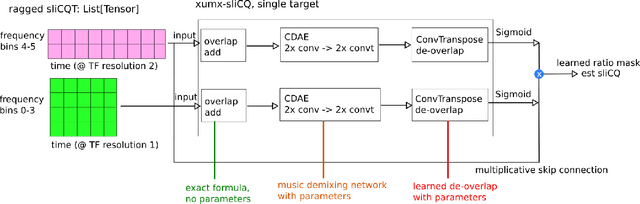
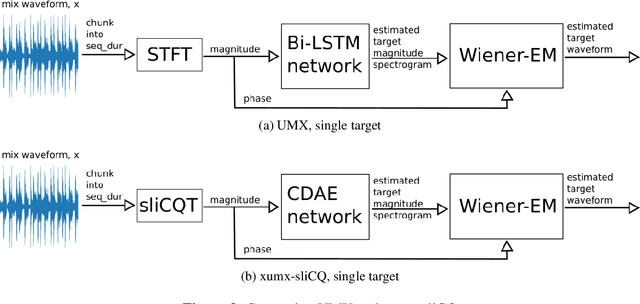
Music source separation is the task of extracting an estimate of one or more isolated sources or instruments (for example, drums or vocals) from musical audio. The task of music demixing or unmixing considers the case where the musical audio is separated into an estimate of all of its constituent sources that can be summed back to the original mixture. The Music Demixing Challenge was created to inspire new demixing research. Open-Unmix (UMX), and the improved variant CrossNet-Open-Unmix (X-UMX), were included in the challenge as the baselines. Both models use the Short-Time Fourier Transform (STFT) as the representation of music signals. The time-frequency uncertainty principle states that the STFT of a signal cannot have maximal resolution in both time and frequency. The tradeoff in time-frequency resolution can significantly affect music demixing results. Our proposed adaptation of UMX replaced the STFT with the sliCQT, a time-frequency transform with varying time-frequency resolution. Unfortunately, our model xumx-sliCQ achieved lower demixing scores than UMX.
Deep Learning the Shape of the Brain Connectome
Mar 06, 2022
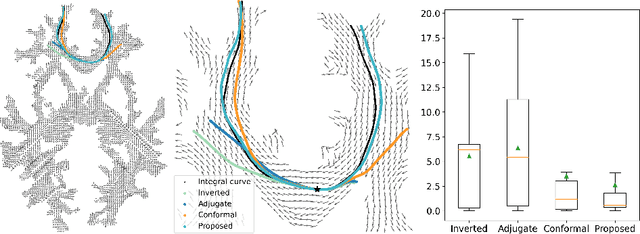
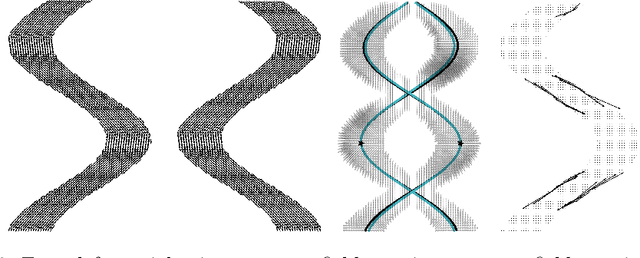
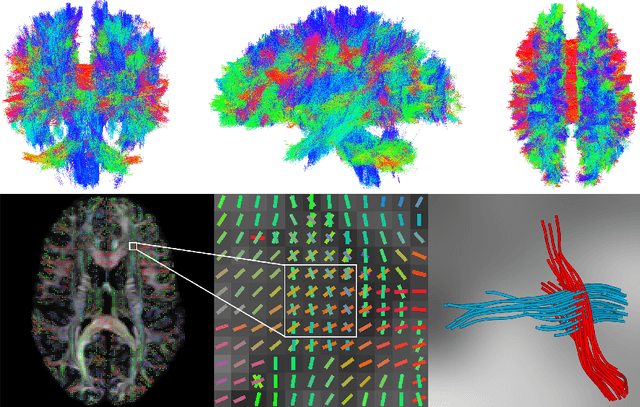
To statistically study the variability and differences between normal and abnormal brain connectomes, a mathematical model of the neural connections is required. In this paper, we represent the brain connectome as a Riemannian manifold, which allows us to model neural connections as geodesics. We show for the first time how one can leverage deep neural networks to estimate a Riemannian metric of the brain that can accommodate fiber crossings and is a natural modeling tool to infer the shape of the brain from DWMRI. Our method achieves excellent performance in geodesic-white-matter-pathway alignment and tackles the long-standing issue in previous methods: the inability to recover the crossing fibers with high fidelity.
Generating Task-specific Robotic Grasps
Mar 20, 2022

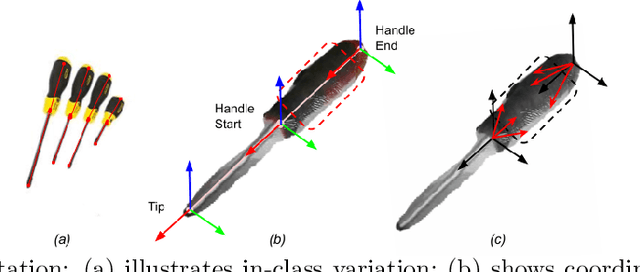
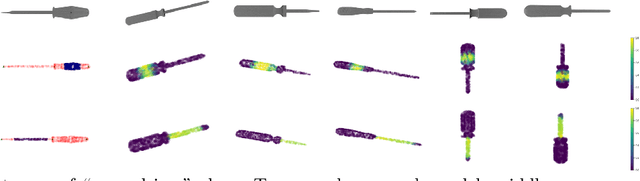
This paper describes a method for generating robot grasps by jointly considering stability and other task and object-specific constraints. We introduce a three-level representation that is acquired for each object class from a small number of exemplars of objects, tasks, and relevant grasps. The representation encodes task-specific knowledge for each object class as a relationship between a keypoint skeleton and suitable grasp points that is preserved despite intra-class variations in scale and orientation. The learned models are queried at run time by a simple sampling-based method to guide the generation of grasps that balance task and stability constraints. We ground and evaluate our method in the context of a Franka Emika Panda robot assisting a human in picking tabletop objects for which the robot does not have prior CAD models. Experimental results demonstrate that in comparison with a baseline method that only focuses on stability, our method is able to provide suitable grasps for different tasks.
NeuraGen-A Low-Resource Neural Network based approach for Gender Classification
Mar 29, 2022
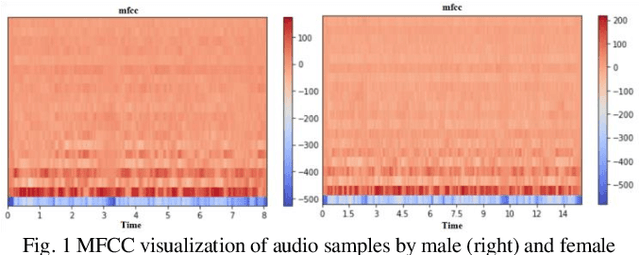
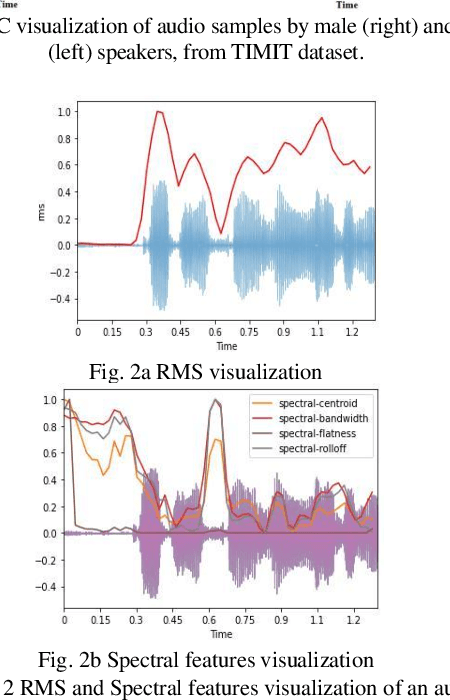
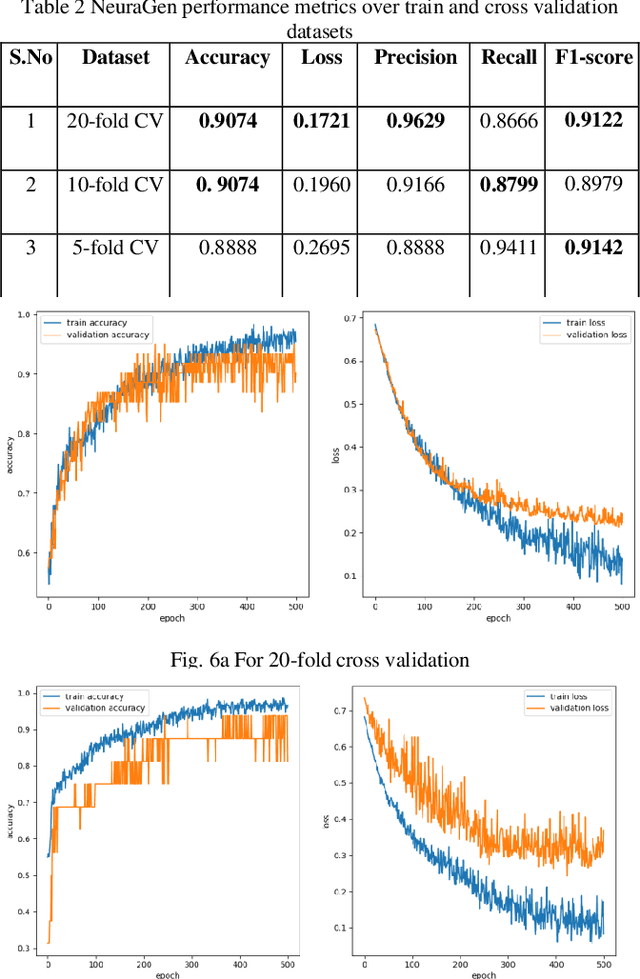
Human voice is the source of several important information. This is in the form of features. These Features help in interpreting various features associated with the speaker and speech. The speaker dependent work researchersare targeted towards speaker identification, Speaker verification, speaker biometric, forensics using feature, and cross-modal matching via speech and face images. In such context research, it is a very difficult task to come across clean, and well annotated publicly available speech corpus as data set. Acquiring volunteers to generate such dataset is also very expensive, not to mention the enormous amount of effort and time researchers spend to gather such data. The present paper work, a Neural Network proposal as NeuraGen focused which is a low-resource ANN architecture. The proposed tool used to classify gender of the speaker from the speech recordings. We have used speech recordings collected from the ELSDSR and limited TIMIT datasets, from which we extracted 8 speech features, which were pre-processed and then fed into NeuraGen to identify the gender. NeuraGen has successfully achieved accuracy of 90.7407% and F1 score of 91.227% in train and 20-fold cross validation dataset.