 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Long Short-Term Memory for Spatial Encoding in Multi-Agent Path Planning
Mar 21, 2022
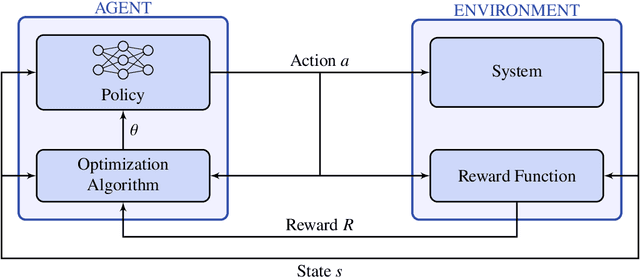
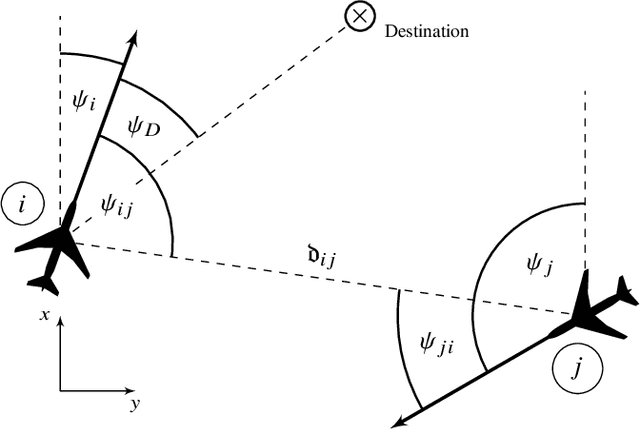
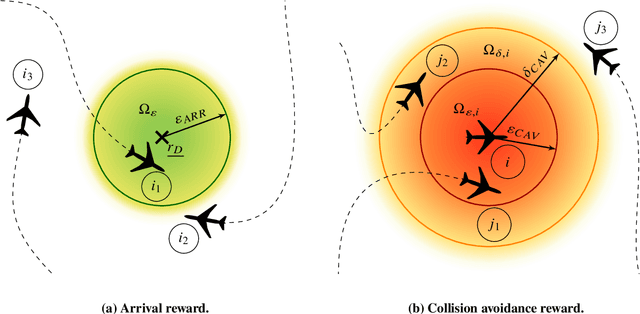
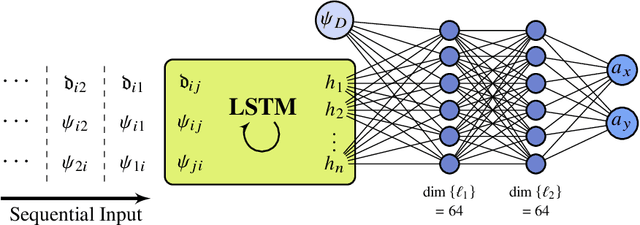
Reinforcement learning-based path planning for multi-agent systems of varying size constitutes a research topic with increasing significance as progress in domains such as urban air mobility and autonomous aerial vehicles continues. Reinforcement learning with continuous state and action spaces is used to train a policy network that accommodates desirable path planning behaviors and can be used for time-critical applications. A Long Short-Term Memory module is proposed to encode an unspecified number of states for a varying, indefinite number of agents. The described training strategies and policy architecture lead to a guidance that scales to an infinite number of agents and unlimited physical dimensions, although training takes place at a smaller scale. The guidance is implemented on a low-cost, off-the-shelf onboard computer. The feasibility of the proposed approach is validated by presenting flight test results of up to four drones, autonomously navigating collision-free in a real-world environment.
* For associated source code, see https://github.com/MarcSchlichting/LSTMSpatialEncoding , For associated video of flight test, see https://schlichting.page.link/lstm_flight_test , 17 pages, 11 figures
Optimal Sensor Placement for Hybrid Source Localization Using Fused TOA-RSS-AOA Measurements
Apr 13, 2022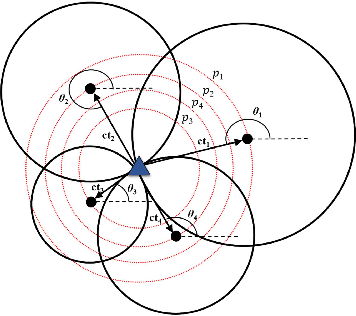
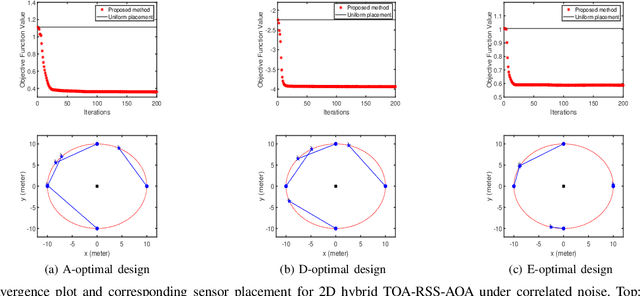
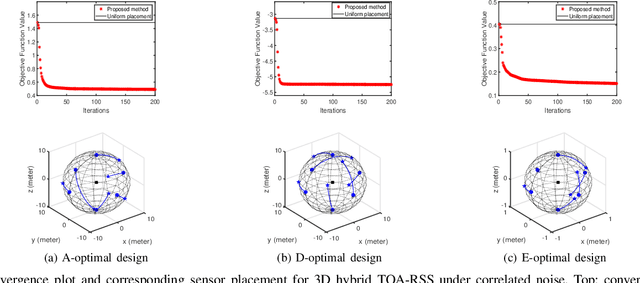
Source localization techniques incorporating hybrid measurements improve the reliability and accuracy of the location estimate. Given a set of hybrid sensors that can collect combined time of arrival (TOA), received signal strength (RSS) and angle of arrival (AOA) measurements, the localization accuracy can be enhanced further by optimally designing the placements of the hybrid sensors. In this paper, we present an optimal sensor placement methodology, which is based on the principle of majorization-minimization (MM), for hybrid localization technique. We first derive the Cramer-Rao lower bound (CRLB) of the hybrid measurement model, and formulate the design problem using the A-optimal criterion. Next, we introduce an auxiliary variable to reformulate the design problem into an equivalent saddle-point problem, and then construct simple surrogate functions (having closed form solutions) over both primal and dual variables. The application of MM in this paper is distinct from the conventional MM (that is usually developed only over the primal variable), and we believe that the MM framework developed in this paper can be employed to solve many optimization problems. The main advantage of our method over most of the existing state-of-the-art algorithms (which are mostly analytical in nature) is its ability to work for both uncorrelated and correlated noise in the measurements. We also discuss the extension of the proposed algorithm for the optimal placement designs based on D and E optimal criteria. Finally, the performance of the proposed method is studied under different noise conditions and different design parameters.
Circumventing the resolution-time tradeoff in Ultrasound Localization Microscopy by Velocity Filtering
Jan 23, 2021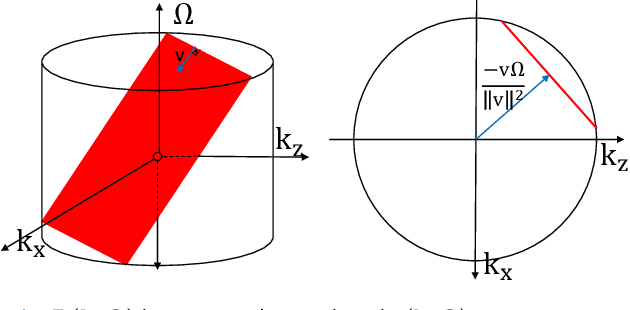
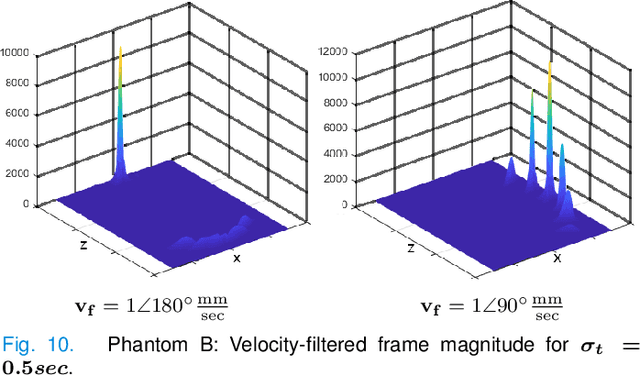
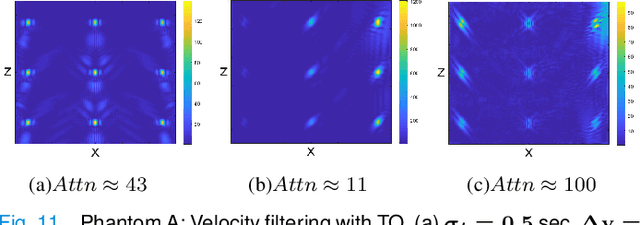
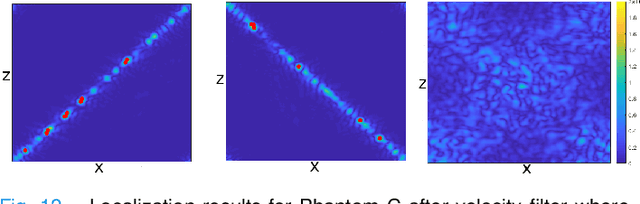
Ultrasound Localization Microscopy (ULM) offers a cost-effective modality for microvascular imaging by using intravascular contrast agents (microbubbles). However, ULM has a fundamental trade-off between acquisition time and spatial resolution, which makes clinical translation challenging. In this paper, in order to circumvent the trade-off, we introduce a spatiotemporal filtering operation dubbed velocity filtering, which is capable of separating contrast agents into different groups based on their vector velocities thus reducing interference in the localization step, while simultaneously offering blood velocity mapping at super resolution, without tracking individual microbubbles. As side benefit, the velocity filter provides noise suppression before microbubble localization that could enable substantially increased penetration depth in tissue typically by 4cm or more. We provide a theoretical analysis of the performance of velocity filter. Numerical experiments confirm that the proposed velocity filter is able to separate the microbubbles with respect to the speed and direction of their motion. In combination with subsequent localization of microbubble centers, e.g. by matched filtering, the velocity filter improves the quality of the reconstructed vasculature significantly and provides blood flow information. Overall, the proposed imaging pipeline in this paper enables the use of higher concentrations of microbubbles while preserving spatial resolution, thus helping circumvent the trade-off between acquisition time and spatial resolution. Conveniently, because the velocity filtering operation can be implemented by fast Fourier transforms(FFTs) it admits fast, and potentially real-time realization. We believe that the proposed velocity filtering method has the potential to pave the way to clinical translation of ULM.
Evaluating Elements of Web-based Data Enrichment for Pseudo-Relevance Feedback Retrieval
Mar 10, 2022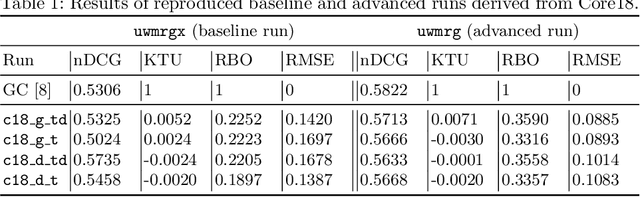
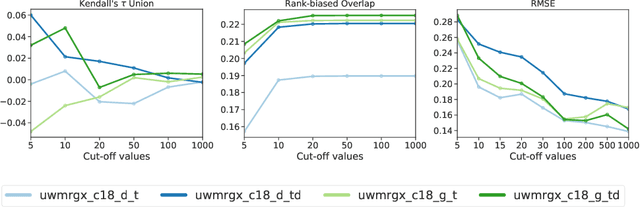
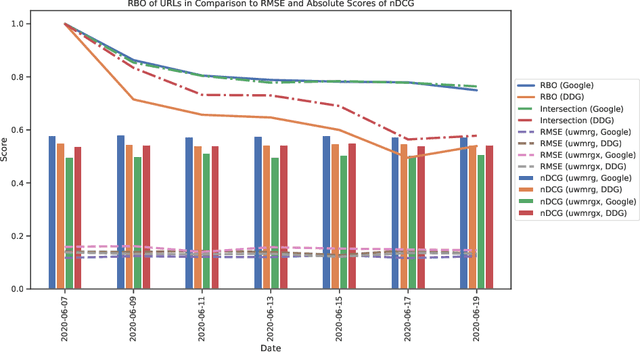
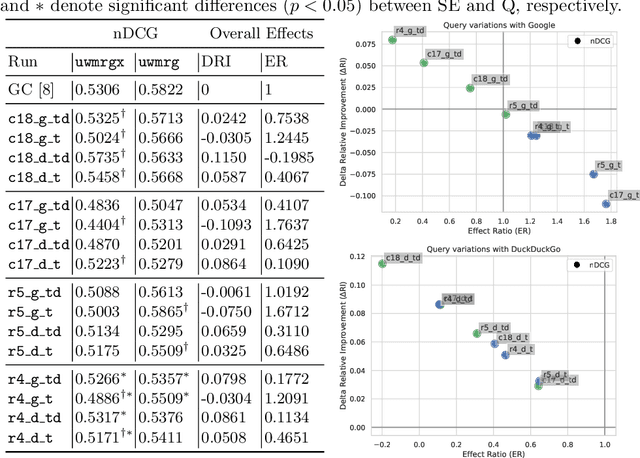
In this work, we analyze a pseudo-relevance retrieval method based on the results of web search engines. By enriching topics with text data from web search engine result pages and linked contents, we train topic-specific and cost-efficient classifiers that can be used to search test collections for relevant documents. Building upon attempts initially made at TREC Common Core 2018 by Grossman and Cormack, we address questions of system performance over time considering different search engines, queries, and test collections. Our experimental results show how and to which extent the considered components affect the retrieval performance. Overall, the analyzed method is robust in terms of average retrieval performance and a promising way to use web content for the data enrichment of relevance feedback methods.
Predictive Collision Management for Time and Risk Dependent Path Planning
Nov 26, 2020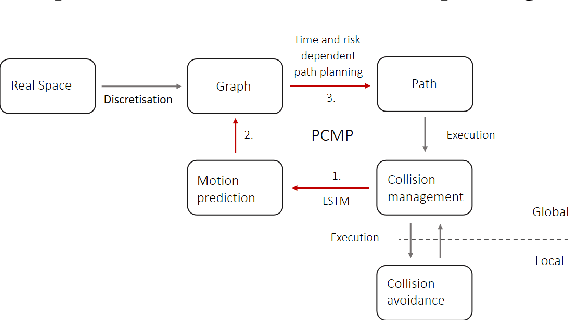
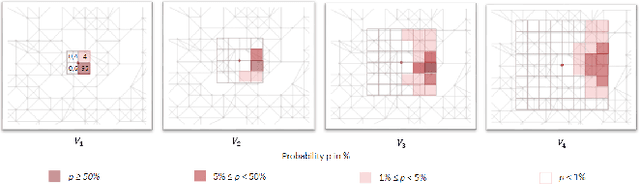
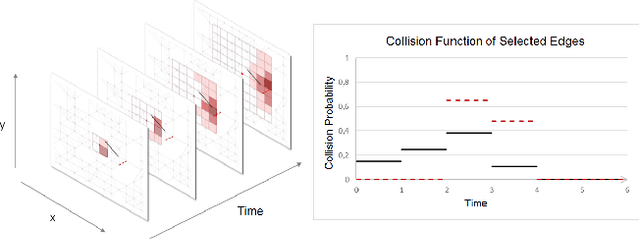
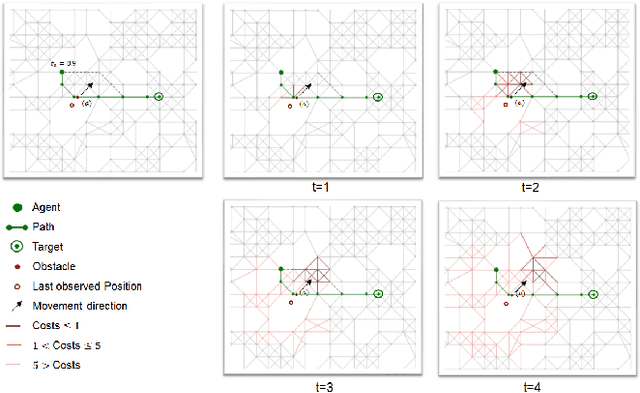
Autonomous agents such as self-driving cars or parcel robots need to recognize and avoid possible collisions with obstacles in order to move successfully in their environment. Humans, however, have learned to predict movements intuitively and to avoid obstacles in a forward-looking way. The task of collision avoidance can be divided into a global and a local level. Regarding the global level, we propose an approach called "Predictive Collision Management Path Planning" (PCMP). At the local level, solutions for collision avoidance are used that prevent an inevitable collision. Therefore, the aim of PCMP is to avoid unnecessary local collision scenarios using predictive collision management. PCMP is a graph-based algorithm with a focus on the time dimension consisting of three parts: (1) movement prediction, (2) integration of movement prediction into a time-dependent graph, and (3) time and risk-dependent path planning. The algorithm combines the search for a shortest path with the question: is the detour worth avoiding a possible collision scenario? We evaluate the evasion behavior in different simulation scenarios and the results show that a risk-sensitive agent can avoid 47.3% of the collision scenarios while making a detour of 1.3%. A risk-averse agent avoids up to 97.3% of the collision scenarios with a detour of 39.1%. Thus, an agent's evasive behavior can be controlled actively and risk-dependent using PCMP.
* Extended version of the SIGSPATIAL '20 paper
An STDP-Based Supervised Learning Algorithm for Spiking Neural Networks
Mar 07, 2022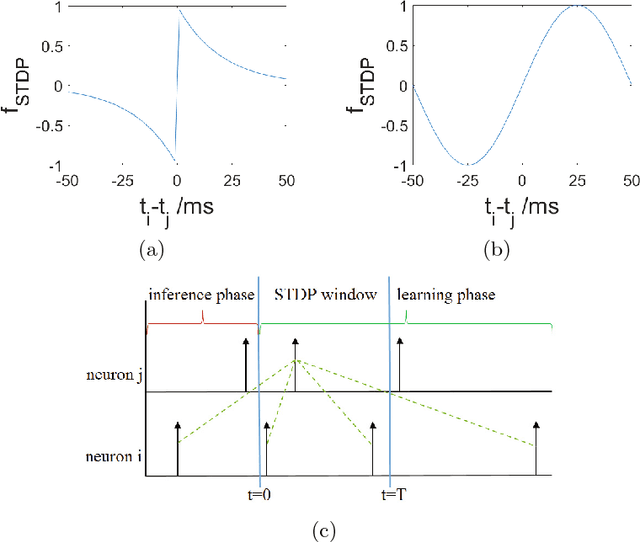
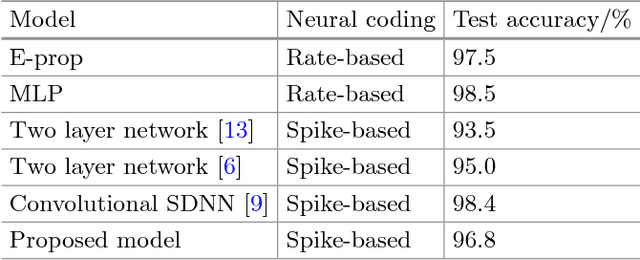
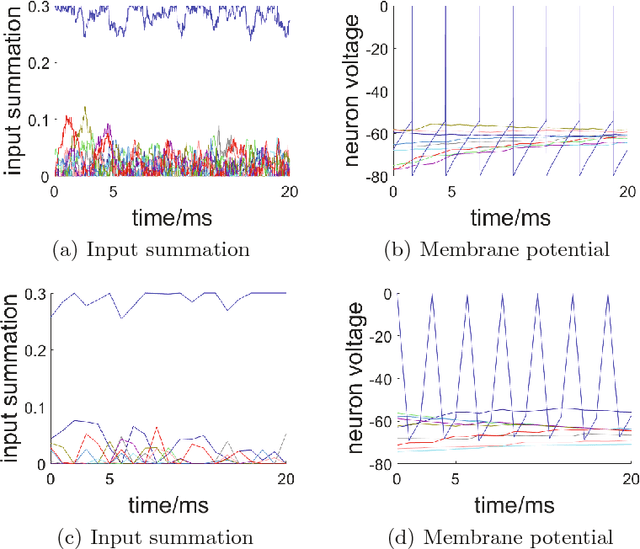
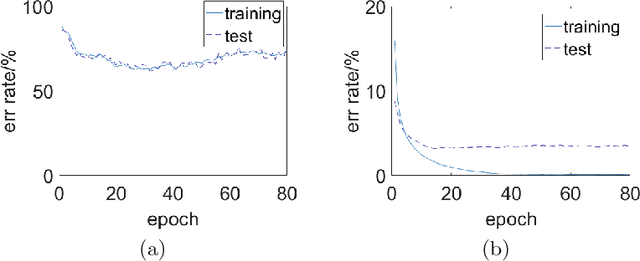
Compared with rate-based artificial neural networks, Spiking Neural Networks (SNN) provide a more biological plausible model for the brain. But how they perform supervised learning remains elusive. Inspired by recent works of Bengio et al., we propose a supervised learning algorithm based on Spike-Timing Dependent Plasticity (STDP) for a hierarchical SNN consisting of Leaky Integrate-and-fire (LIF) neurons. A time window is designed for the presynaptic neuron and only the spikes in this window take part in the STDP updating process. The model is trained on the MNIST dataset. The classification accuracy approach that of a Multilayer Perceptron (MLP) with similar architecture trained by the standard back-propagation algorithm.
A Survey on Using Gaze Behaviour for Natural Language Processing
Jan 03, 2022
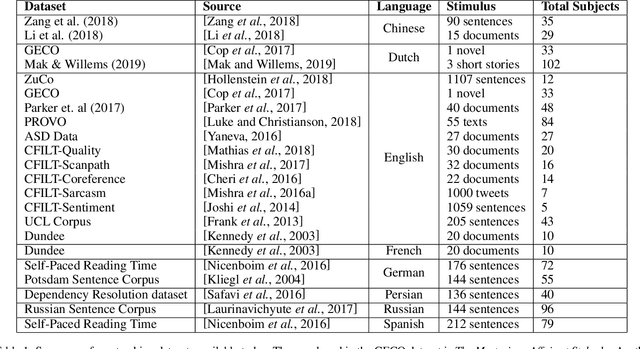

Gaze behaviour has been used as a way to gather cognitive information for a number of years. In this paper, we discuss the use of gaze behaviour in solving different tasks in natural language processing (NLP) without having to record it at test time. This is because the collection of gaze behaviour is a costly task, both in terms of time and money. Hence, in this paper, we focus on research done to alleviate the need for recording gaze behaviour at run time. We also mention different eye tracking corpora in multiple languages, which are currently available and can be used in natural language processing. We conclude our paper by discussing applications in a domain - education - and how learning gaze behaviour can help in solving the tasks of complex word identification and automatic essay grading.
What Makes RAFT Better Than PWC-Net?
Mar 21, 2022
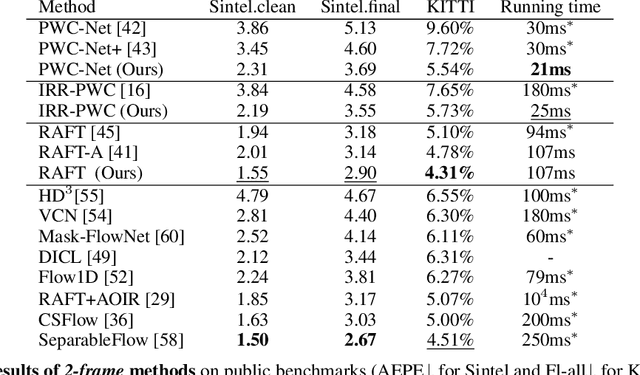

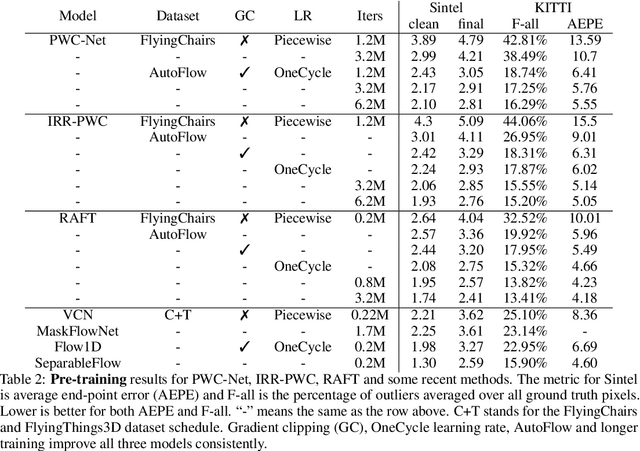
How important are training details and datasets to recent optical flow models like RAFT? And do they generalize? To explore these questions, rather than develop a new model, we revisit three prominent models, PWC-Net, IRR-PWC and RAFT, with a common set of modern training techniques and datasets, and observe significant performance gains, demonstrating the importance and generality of these training details. Our newly trained PWC-Net and IRR-PWC models show surprisingly large improvements, up to 30% versus original published results on Sintel and KITTI 2015 benchmarks. They outperform the more recent Flow1D on KITTI 2015 while being 3x faster during inference. Our newly trained RAFT achieves an Fl-all score of 4.31% on KITTI 2015, more accurate than all published optical flow methods at the time of writing. Our results demonstrate the benefits of separating the contributions of models, training techniques and datasets when analyzing performance gains of optical flow methods. Our source code will be publicly available.
Learning to Act with Affordance-Aware Multimodal Neural SLAM
Feb 04, 2022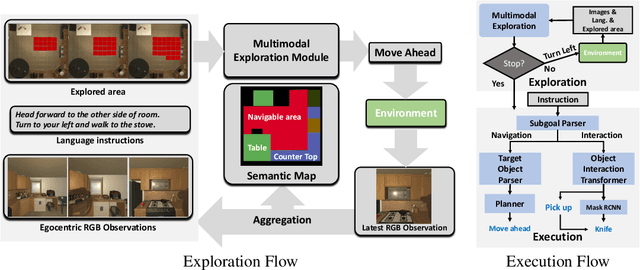

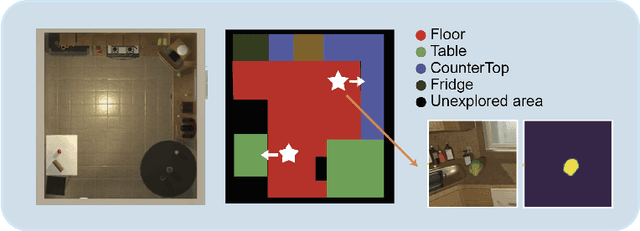
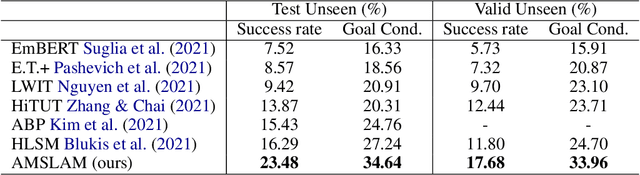
Recent years have witnessed an emerging paradigm shift toward embodied artificial intelligence, in which an agent must learn to solve challenging tasks by interacting with its environment. There are several challenges in solving embodied multimodal tasks, including long-horizon planning, vision-and-language grounding, and efficient exploration. We focus on a critical bottleneck, namely the performance of planning and navigation. To tackle this challenge, we propose a Neural SLAM approach that, for the first time, utilizes several modalities for exploration, predicts an affordance-aware semantic map, and plans over it at the same time. This significantly improves exploration efficiency, leads to robust long-horizon planning, and enables effective vision-and-language grounding. With the proposed Affordance-aware Multimodal Neural SLAM (AMSLAM) approach, we obtain more than $40\%$ improvement over prior published work on the ALFRED benchmark and set a new state-of-the-art generalization performance at a success rate of $23.48\%$ on the test unseen scenes.
Hierarchical Bayesian Mixture Models for Time Series Using Context Trees as State Space Partitions
Jun 06, 2021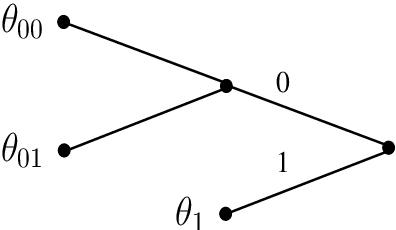

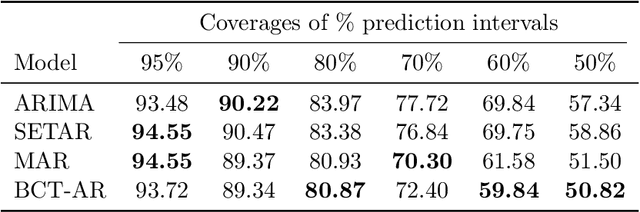
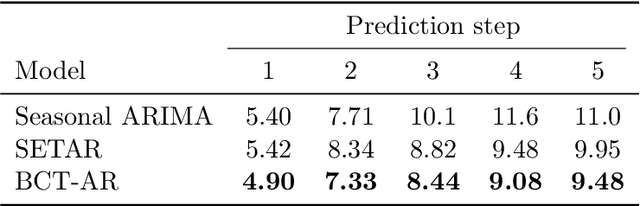
A general Bayesian framework is introduced for mixture modelling and inference with real-valued time series. At the top level, the state space is partitioned via the choice of a discrete context tree, so that the resulting partition depends on the values of some of the most recent samples. At the bottom level, a different model is associated with each region of the partition. This defines a very rich and flexible class of mixture models, for which we provide algorithms that allow for efficient, exact Bayesian inference. In particular, we show that the maximum a posteriori probability (MAP) model (including the relevant MAP context tree partition) can be precisely identified, along with its exact posterior probability. The utility of this general framework is illustrated in detail when a different autoregressive (AR) model is used in each state-space region, resulting in a mixture-of-AR model class. The performance of the associated algorithmic tools is demonstrated in the problems of model selection and forecasting on both simulated and real-world data, where they are found to provide results as good or better than state-of-the-art methods.