 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Machine Learning-Based CSI Feedback With Variable Length in FDD Massive MIMO
Apr 10, 2022
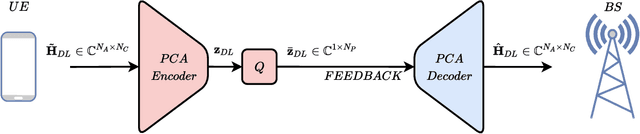
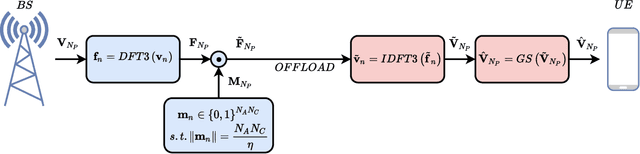
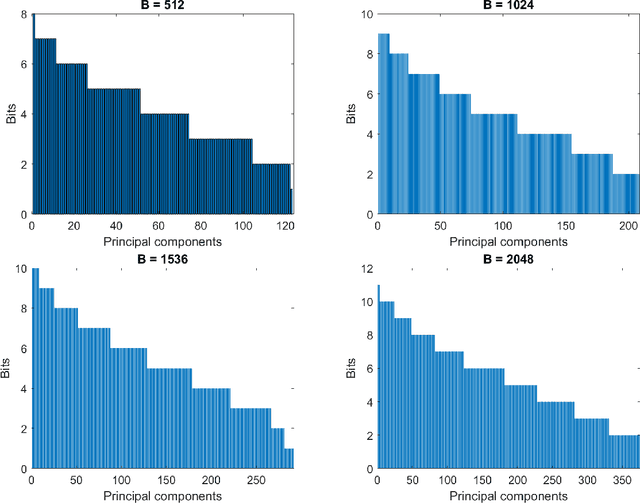
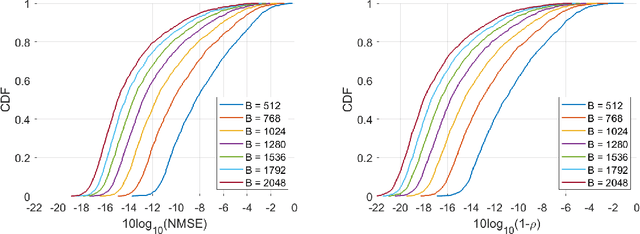
To fully unlock the benefits of multiple-input multiple-output (MIMO) networks, downlink channel state information (CSI) is required at the base station (BS). In frequency division duplex (FDD) systems, the CSI is acquired through a feedback signal from the user equipment (UE). However, this may lead to an important overhead in FDD massive MIMO systems. Focusing on these systems, in this study, we propose a novel strategy to design the CSI feedback. Our strategy allows to optimally design the feedback with variable length, while reducing the parameter number at the UE. Specifically, principal component analysis (PCA) is used to compress the channel into a latent space with adaptive dimensionality. To quantize this compressed channel, the feedback bits are smartly allocated to the latent space dimensions by minimizing the normalized mean squared error (NMSE) distortion. Finally, the quantization codebook is determined with k-means clustering. Numerical simulations show that our strategy improves the zeroforcing beamforming sum rate by 26.8%, compared with the popular CsiNet. The number of model parameters is reduced by 24.9 times, thus causing a significantly smaller offloading overhead. At the same time, PCA is characterized by a lightweight unsupervised training, requiring eight times fewer training samples than CsiNet.
Safe Interactive Industrial Robots using Jerk-based Safe Set Algorithm
Apr 06, 2022
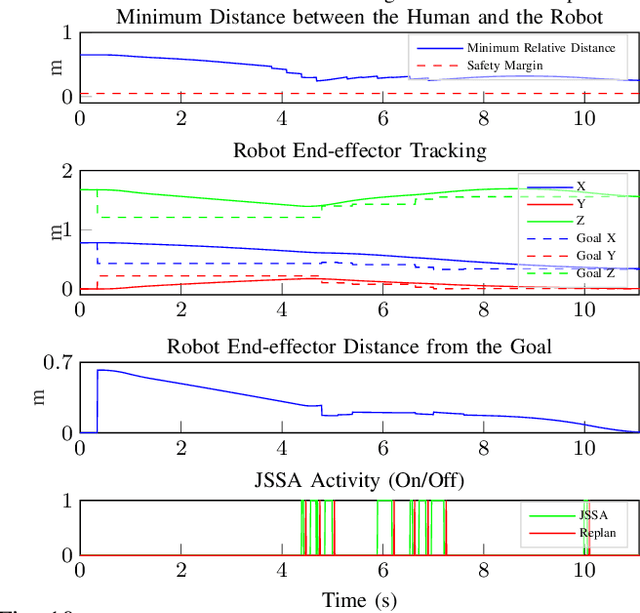
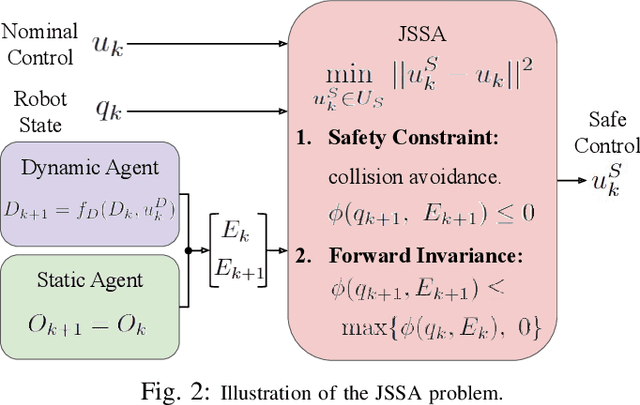
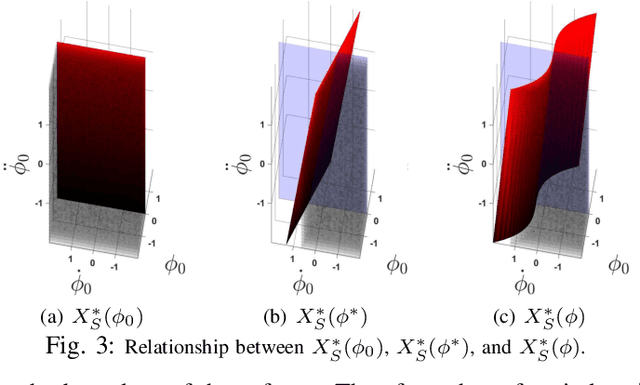
The need to increase the flexibility of production lines is calling for robots to collaborate with human workers. However, existing interactive industrial robots only guarantee intrinsic safety (reduce collision impact), but not interactive safety (collision avoidance), which greatly limited their flexibility. The issue arises from two limitations in existing control software for industrial robots: 1) lack of support for real-time trajectory modification; 2) lack of intelligent safe control algorithms with guaranteed collision avoidance under robot dynamics constraints. To address the first issue, a jerk-bounded position controller (JPC) was developed previously. This paper addresses the second limitation, on top of the JPC. Specifically, we introduce a jerk-based safe set algorithm (JSSA) to ensure collision avoidance while considering the robot dynamics constraints. The JSSA greatly extends the scope of the original safe set algorithm, which has only been applied for second-order systems with unbounded accelerations. The JSSA is implemented on the FANUC LR Mate 200id/7L robot and validated with HRI tasks. Experiments show that the JSSA can consistently keep the robot at a safe distance from the human while executing the designated task.
Approach to Predicting News -- A Precise Multi-LSTM Network With BERT
Apr 26, 2022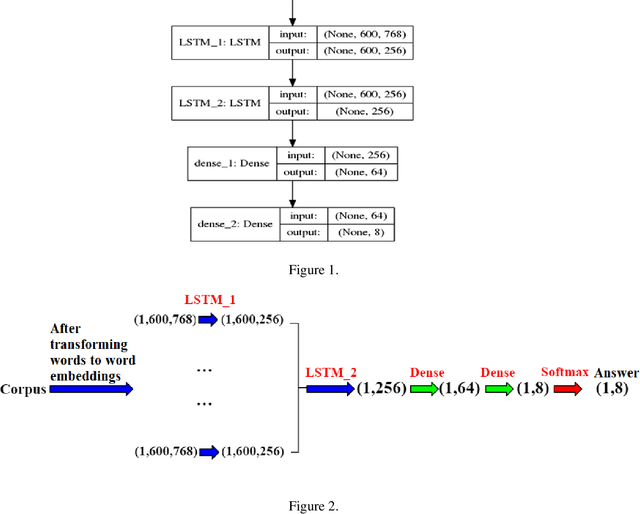
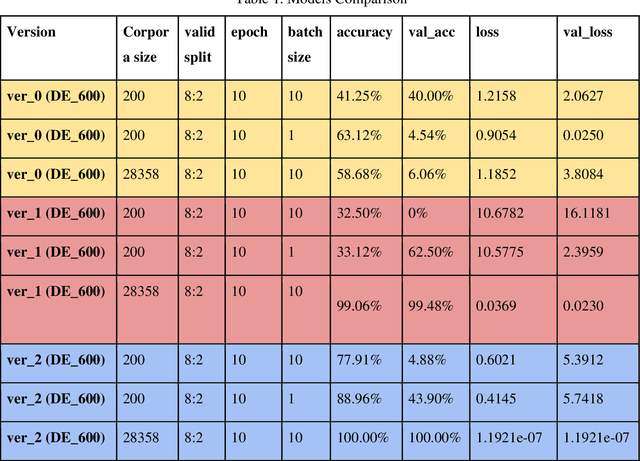
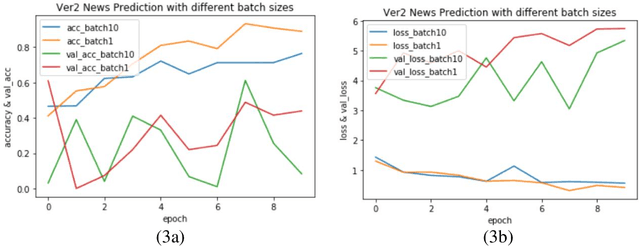
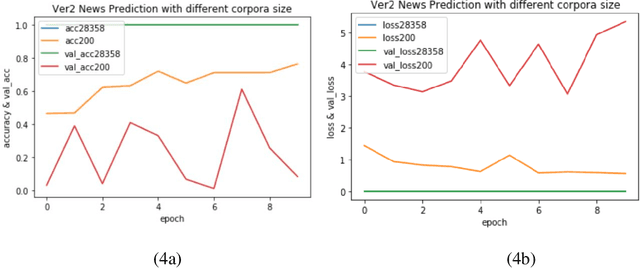
Varieties of Democracy (V-Dem) is a new approach to conceptualizing and measuring democracy and politics. It has information for 200 countries and is one of the biggest databases for political science. According to the V-Dem annual democracy report 2019, Taiwan is one of the two countries that got disseminated false information from foreign governments the most. It also shows that the "made-up news" has caused a great deal of confusion in Taiwanese society and has serious impacts on global stability. Although there are several applications helping distinguish the false information, we found out that the pre-processing of categorizing the news is still done by human labor. However, human labor may cause mistakes and cannot work for a long time. The growing demands for automatic machines in the near decades show that while the machine can do as good as humans or even better, using machines can reduce humans' burden and cut down costs. Therefore, in this work, we build a predictive model to classify the category of news. The corpora we used contains 28358 news and 200 news scraped from the online newspaper Liberty Times Net (LTN) website and includes 8 categories: Technology, Entertainment, Fashion, Politics, Sports, International, Finance, and Health. At first, we use Bidirectional Encoder Representations from Transformers (BERT) for word embeddings which transform each Chinese character into a (1,768) vector. Then, we use a Long Short-Term Memory (LSTM) layer to transform word embeddings into sentence embeddings and add another LSTM layer to transform them into document embeddings. Each document embedding is an input for the final predicting model, which contains two Dense layers and one Activation layer. And each document embedding is transformed into 1 vector with 8 real numbers, then the highest one will correspond to the 8 news categories with up to 99% accuracy.
* Accepted by The 25th International Conference on Information Management & Practice (IMP) 2019
Active IRS Aided Multiple Access for Energy-Constrained IoT Systems
Jan 29, 2022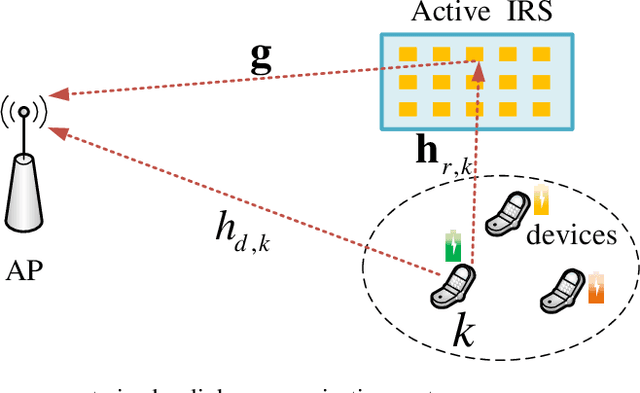
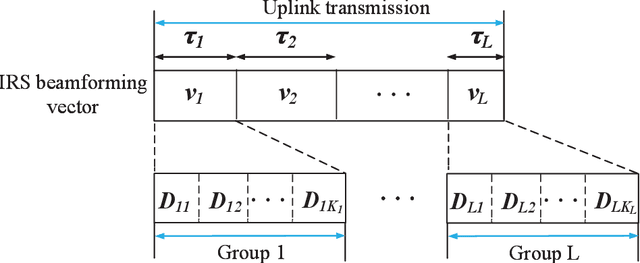
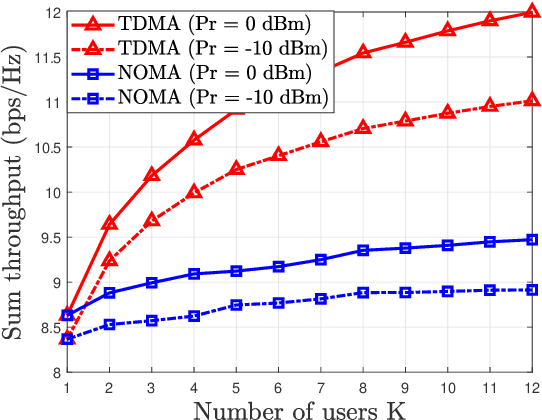
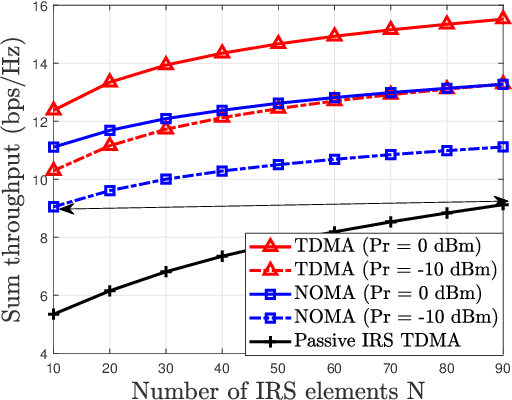
We investigate the fundamental multiple access (MA) scheme in an active intelligent reflecting surface (IRS) aided energy-constrained Internet-of-Things (IoT) system, where an active IRS is deployed to assist the uplink transmission from multiple IoT devices to an access point (AP). Our goal is to maximize the sum throughput by optimizing the IRS beamforming vectors across time and resource allocation. To this end, we first study two typical active IRS aided MA schemes, namely time division multiple access (TDMA) and non-orthogonal multiple access (NOMA), by analytically comparing their achievable sum throughput and proposing corresponding algorithms. Interestingly, we prove that given only one available IRS beamforming vector, the NOMA-based scheme generally achieves a larger throughput than the TDMA-based scheme, whereas the latter can potentially outperform the former if multiple IRS beamforming vectors are available to harness the favorable time selectivity of the IRS. To strike a flexible balance between the system performance and the associated signaling overhead incurred by more IRS beamforming vectors, we then propose a general hybrid TDMA-NOMA scheme with user grouping, where the devices in the same group transmit simultaneously via NOMA while devices in different groups occupy orthogonal time slots. By controlling the number of groups, the hybrid TDMA-NOMA scheme is applicable for any given number of IRS beamforming vectors available. Despite of the non-convexity of the considered optimization problem, we propose an efficient algorithm based on alternating optimization. Simulation results illustrate the practical superiorities of the active IRS over the passive IRS in terms of the coverage extension and supporting multiple energy-limited devices, and demonstrate the effectiveness of our proposed hybrid MA scheme for flexibly balancing the performance-cost tradeoff.
Real-Time Multi-View 3D Human Pose Estimation using Semantic Feedback to Smart Edge Sensors
Jun 28, 2021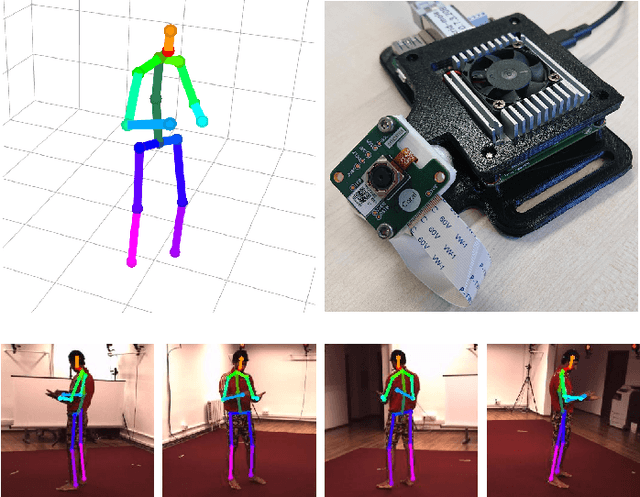
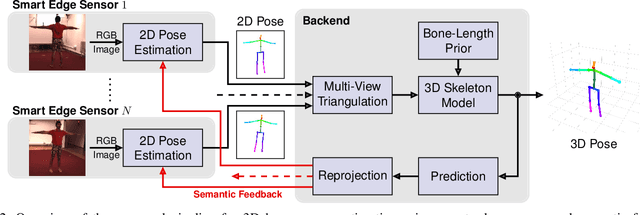
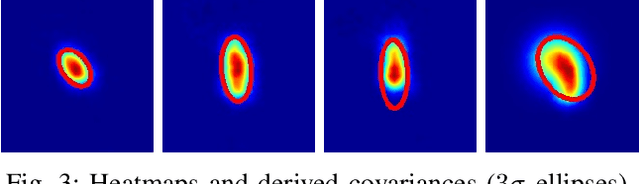

We present a novel method for estimation of 3D human poses from a multi-camera setup, employing distributed smart edge sensors coupled with a backend through a semantic feedback loop. 2D joint detection for each camera view is performed locally on a dedicated embedded inference processor. Only the semantic skeleton representation is transmitted over the network and raw images remain on the sensor board. 3D poses are recovered from 2D joints on a central backend, based on triangulation and a body model which incorporates prior knowledge of the human skeleton. A feedback channel from backend to individual sensors is implemented on a semantic level. The allocentric 3D pose is backprojected into the sensor views where it is fused with 2D joint detections. The local semantic model on each sensor can thus be improved by incorporating global context information. The whole pipeline is capable of real-time operation. We evaluate our method on three public datasets, where we achieve state-of-the-art results and show the benefits of our feedback architecture, as well as in our own setup for multi-person experiments. Using the feedback signal improves the 2D joint detections and in turn the estimated 3D poses.
Improving Top-K Decoding for Non-Autoregressive Semantic Parsing via Intent Conditioning
Apr 14, 2022
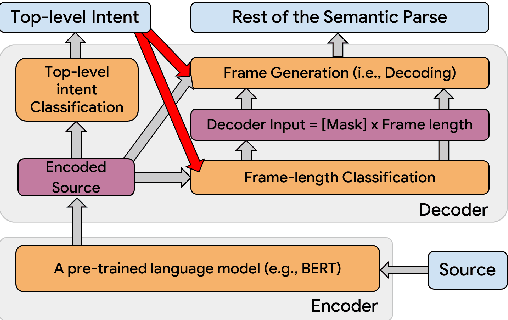

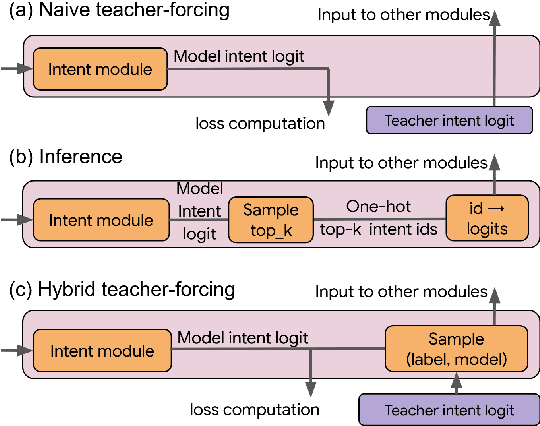
Semantic parsing (SP) is a core component of modern virtual assistants like Google Assistant and Amazon Alexa. While sequence-to-sequence-based auto-regressive (AR) approaches are common for conversational semantic parsing, recent studies employ non-autoregressive (NAR) decoders and reduce inference latency while maintaining competitive parsing quality. However, a major drawback of NAR decoders is the difficulty of generating top-k (i.e., k-best) outputs with approaches such as beam search. To address this challenge, we propose a novel NAR semantic parser that introduces intent conditioning on the decoder. Inspired by the traditional intent and slot tagging parsers, we decouple the top-level intent prediction from the rest of a parse. As the top-level intent largely governs the syntax and semantics of a parse, the intent conditioning allows the model to better control beam search and improves the quality and diversity of top-k outputs. We introduce a hybrid teacher-forcing approach to avoid training and inference mismatch. We evaluate the proposed NAR on conversational SP datasets, TOP & TOPv2. Like the existing NAR models, we maintain the O(1) decoding time complexity while generating more diverse outputs and improving the top-3 exact match (EM) by 2.4 points. In comparison with AR models, our model speeds up beam search inference by 6.7 times on CPU with competitive top-k EM.
Multi-Modal Causal Inference with Deep Structural Equation Models
Mar 21, 2022
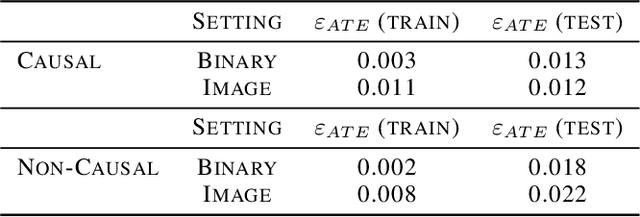
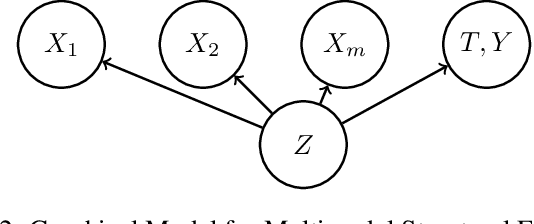

Accounting for the effects of confounders is one of the central challenges in causal inference. Unstructured multi-modal data (images, time series, text) contains valuable information about diverse types of confounders, yet it is typically left unused by most existing methods. This paper seeks to develop techniques that leverage this unstructured data within causal inference to correct for additional confounders that may otherwise not be accounted for. We formalize this task and we propose algorithms based on deep structural equations that treat multi-modal unstructured data as proxy variables. We empirically demonstrate on tasks in genomics and healthcare that unstructured data can be used to correct for diverse sources of confounding, potentially enabling the use of large amounts of data that were previously not used in causal inference.
Per-run Algorithm Selection with Warm-starting using Trajectory-based Features
Apr 20, 2022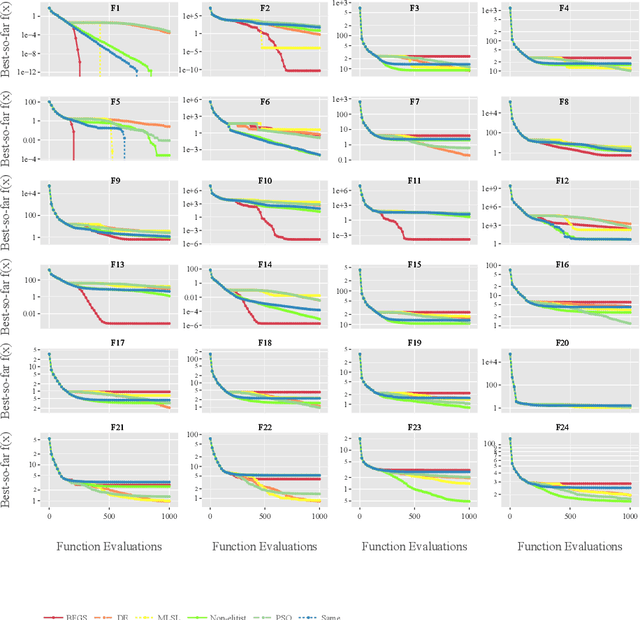

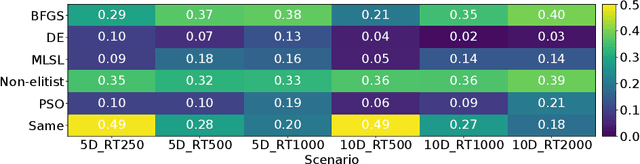
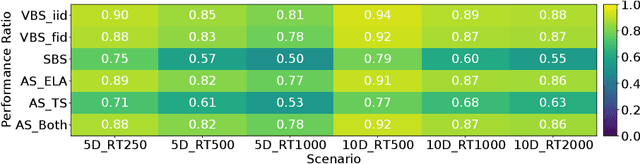
Per-instance algorithm selection seeks to recommend, for a given problem instance and a given performance criterion, one or several suitable algorithms that are expected to perform well for the particular setting. The selection is classically done offline, using openly available information about the problem instance or features that are extracted from the instance during a dedicated feature extraction step. This ignores valuable information that the algorithms accumulate during the optimization process. In this work, we propose an alternative, online algorithm selection scheme which we coin per-run algorithm selection. In our approach, we start the optimization with a default algorithm, and, after a certain number of iterations, extract instance features from the observed trajectory of this initial optimizer to determine whether to switch to another optimizer. We test this approach using the CMA-ES as the default solver, and a portfolio of six different optimizers as potential algorithms to switch to. In contrast to other recent work on online per-run algorithm selection, we warm-start the second optimizer using information accumulated during the first optimization phase. We show that our approach outperforms static per-instance algorithm selection. We also compare two different feature extraction principles, based on exploratory landscape analysis and time series analysis of the internal state variables of the CMA-ES, respectively. We show that a combination of both feature sets provides the most accurate recommendations for our test cases, taken from the BBOB function suite from the COCO platform and the YABBOB suite from the Nevergrad platform.
Active millimeter wave three-dimensional scan real-time imaging mechanism with a line antenna array
Feb 08, 2021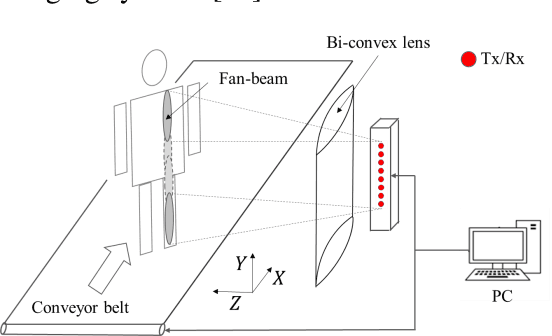
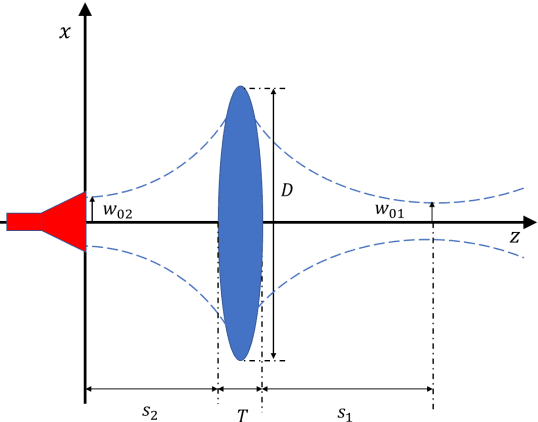
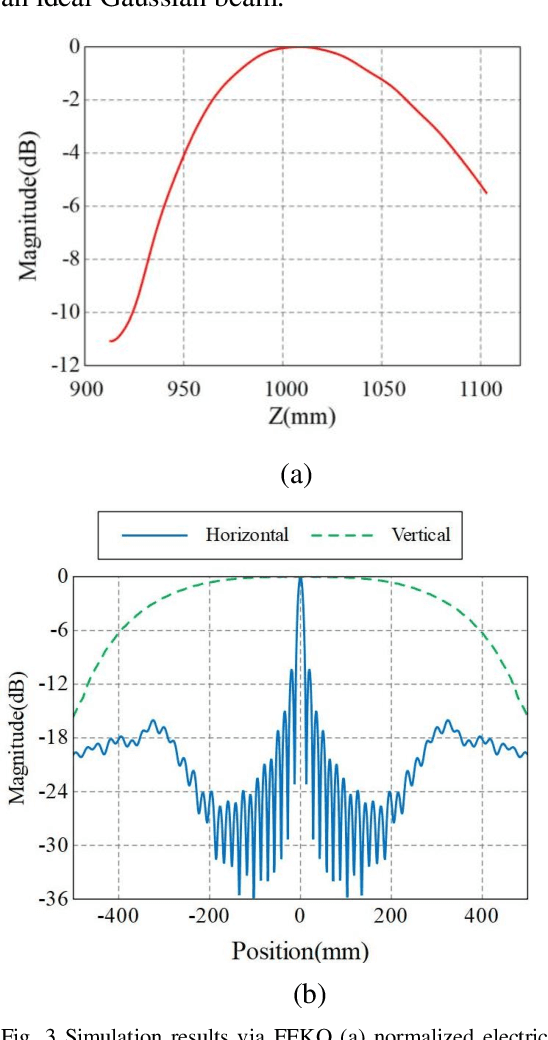
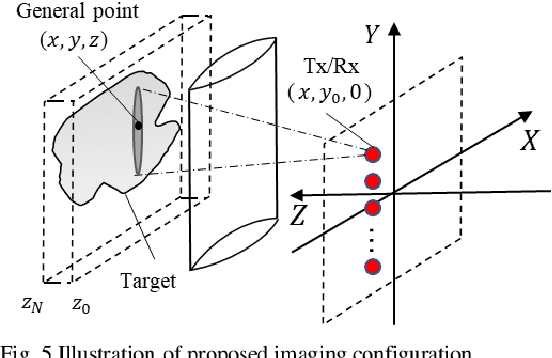
Active Millimeter wave (AMMW) imaging is of interest as it has played important roles in wide variety of applications, from nondestructive test to medical diagnosis. Current AMMW imaging systems have a high spatial resolution and can realize three-dimensional (3D) imaging. However, conventional AMMW imaging systems based on the synthetic aperture require either time-consume acquisition or reconstruction. The AMMW imaging systems based on real-aperture are able to real-time imaging but they need a large aperture and a complex two-dimensional (2D) scan structure to get 3D images. Besides, most AMMW imaging systems need the targets keep still and hold a special posture while screening, limiting the throughput. Here, by using beam control techniques and fast post-processing algorithms, we demonstrate the AMMW 3D scan real-time imaging mechanism with a line antenna array, which can realize 3D real-time imaging by a simple one-dimensional (1D) linear moving, simultaneously, with a satisfactory throughput (over 2000 people per-hour, 10 times than the commercial AMMW imaging systems) and a low system cost. First, the original spherical beam lines generated by the linear antenna array are modulated to fan beam lines via a bi-convex cylindrical lens. Then the holographic imaging algorithm is used to primarily focus the echo data of the imaged object. Finally, the defocus blur is corrected rapidly to get high resolution images by deconvolution. Since our method does not need targets to keep still, has a low system cost, can achieve 3D real-time imaging with a satisfactory throughput simultaneously, this work has the potential to serve as a foundation for future short-range AMMW imaging systems, which can be used in a variety of fields such as security inspection, medical diagnosis, etc.
Offline-Online Learning of Deformation Model for Cable Manipulation with Graph Neural Networks
Mar 28, 2022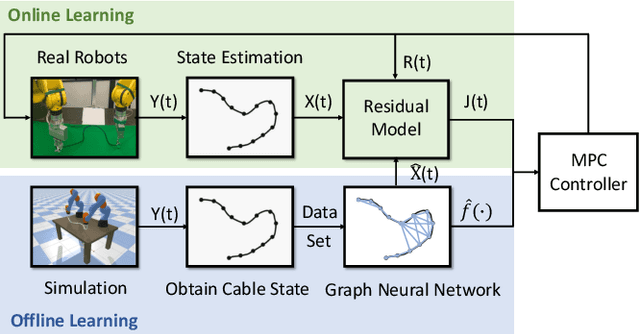
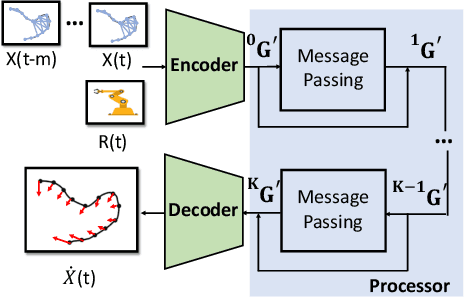
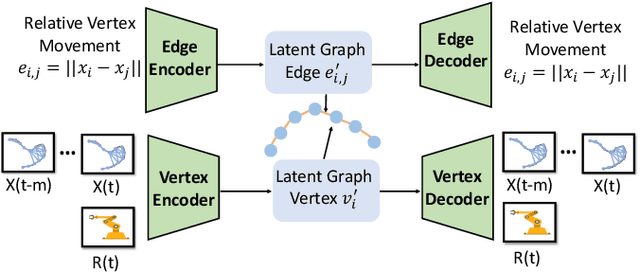
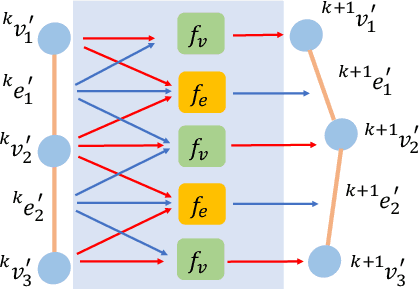
Manipulating deformable linear objects by robots has a wide range of applications, e.g., manufacturing and medical surgery. To complete such tasks, an accurate dynamics model for predicting the deformation is critical for robust control. In this work, we deal with this challenge by proposing a hybrid offline-online method to learn the dynamics of cables in a robust and data-efficient manner. In the offline phase, we adopt Graph Neural Network (GNN) to learn the deformation dynamics purely from the simulation data. Then a linear residual model is learned in real-time to bridge the sim-to-real gap. The learned model is then utilized as the dynamics constraint of a trust region based Model Predictive Controller (MPC) to calculate the optimal robot movements. The online learning and MPC run in a closed-loop manner to robustly accomplish the task. Finally, comparative results with existing methods are provided to quantitatively show the effectiveness and robustness.