 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Backward Reachability Analysis for Neural Feedback Loops
Apr 14, 2022
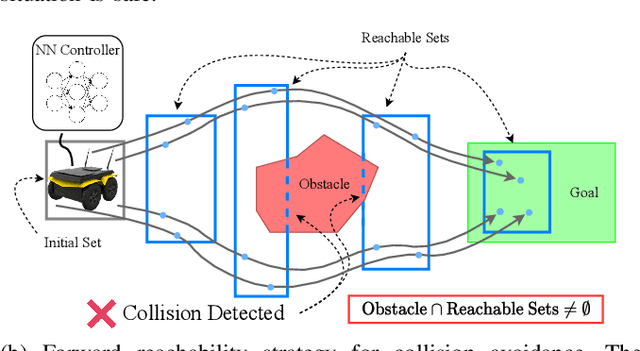
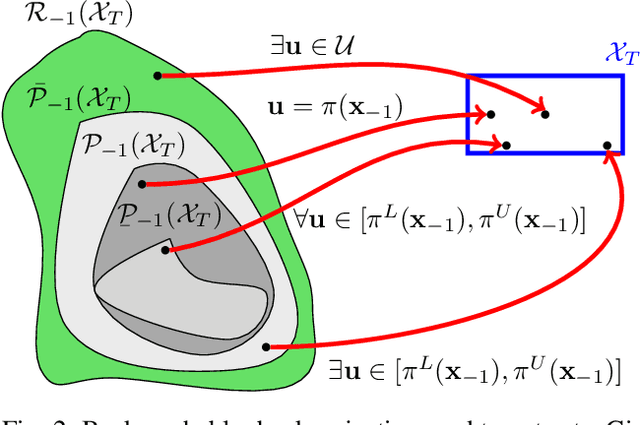
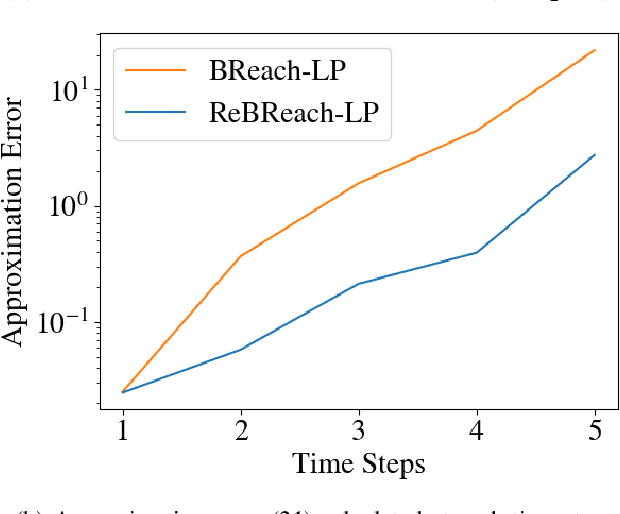
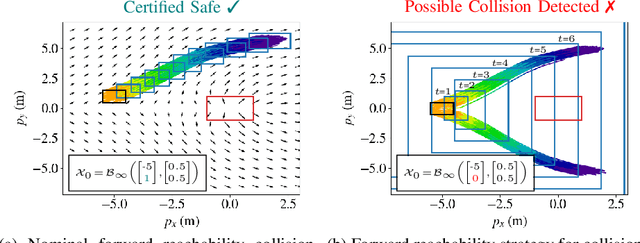
The increasing prevalence of neural networks (NNs) in safety-critical applications calls for methods to certify their behavior and guarantee safety. This paper presents a backward reachability approach for safety verification of neural feedback loops (NFLs), i.e., closed-loop systems with NN control policies. While recent works have focused on forward reachability as a strategy for safety certification of NFLs, backward reachability offers advantages over the forward strategy, particularly in obstacle avoidance scenarios. Prior works have developed techniques for backward reachability analysis for systems without NNs, but the presence of NNs in the feedback loop presents a unique set of problems due to the nonlinearities in their activation functions and because NN models are generally not invertible. To overcome these challenges, we use existing forward NN analysis tools to find affine bounds on the control inputs and solve a series of linear programs (LPs) to efficiently find an approximation of the backprojection (BP) set, i.e., the set of states for which the NN control policy will drive the system to a given target set. We present an algorithm to iteratively find BP set estimates over a given time horizon and demonstrate the ability to reduce conservativeness in the BP set estimates by up to 88% with low additional computational cost. We use numerical results from a double integrator model to verify the efficacy of these algorithms and demonstrate the ability to certify safety for a linearized ground robot model in a collision avoidance scenario where forward reachability fails.
Expression-preserving face frontalization improves visually assisted speech processing
Apr 07, 2022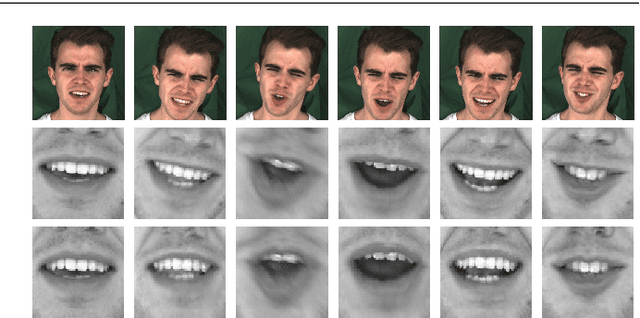

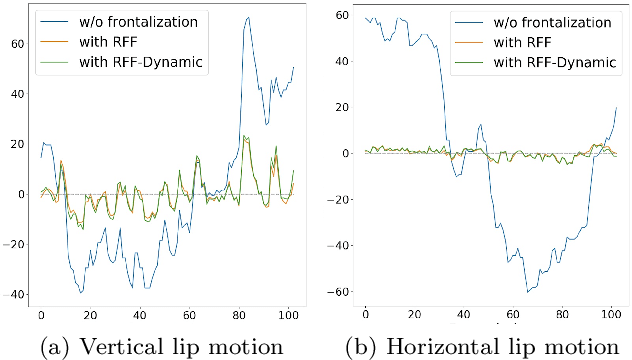
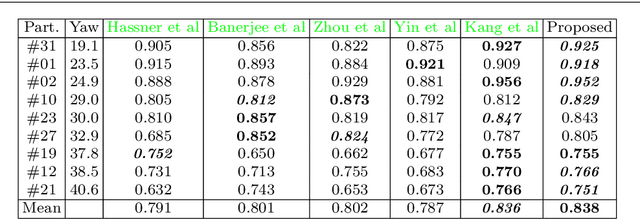
Face frontalization consists of synthesizing a frontally-viewed face from an arbitrarily-viewed one. The main contribution of this paper is a frontalization methodology that preserves non-rigid facial deformations in order to boost the performance of visually assisted speech communication. The method alternates between the estimation of (i)~the rigid transformation (scale, rotation, and translation) and (ii)~the non-rigid deformation between an arbitrarily-viewed face and a face model. The method has two important merits: it can deal with non-Gaussian errors in the data and it incorporates a dynamical face deformation model. For that purpose, we use the generalized Student t-distribution in combination with a linear dynamic system in order to account for both rigid head motions and time-varying facial deformations caused by speech production. We propose to use the zero-mean normalized cross-correlation (ZNCC) score to evaluate the ability of the method to preserve facial expressions. The method is thoroughly evaluated and compared with several state of the art methods, either based on traditional geometric models or on deep learning. Moreover, we show that the method, when incorporated into deep learning pipelines, namely lip reading and speech enhancement, improves word recognition and speech intelligibilty scores by a considerable margin. Supplemental material is accessible at https://team.inria.fr/robotlearn/research/facefrontalization-benchmark/
Communication-Efficient Device Scheduling for Federated Learning Using Stochastic Optimization
Jan 19, 2022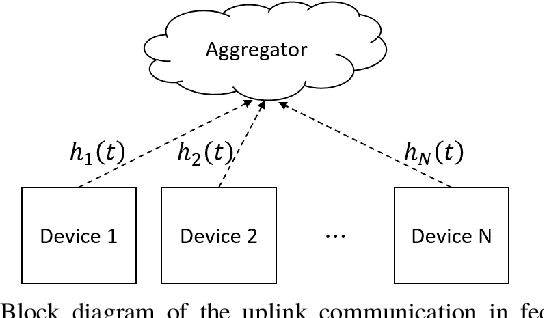
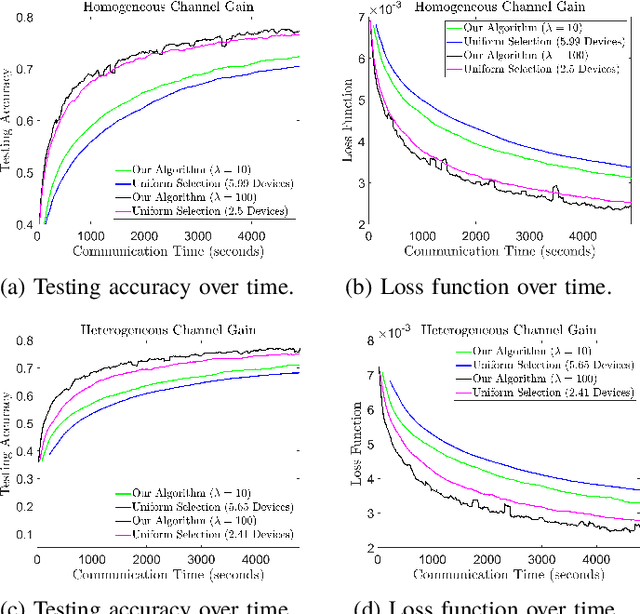
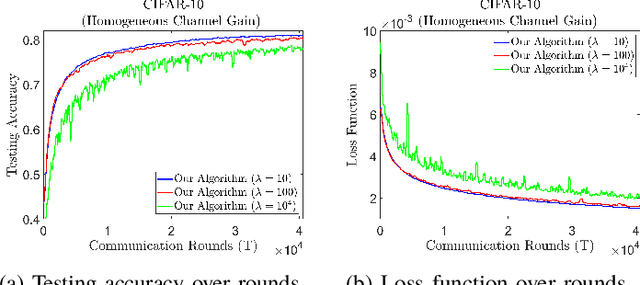
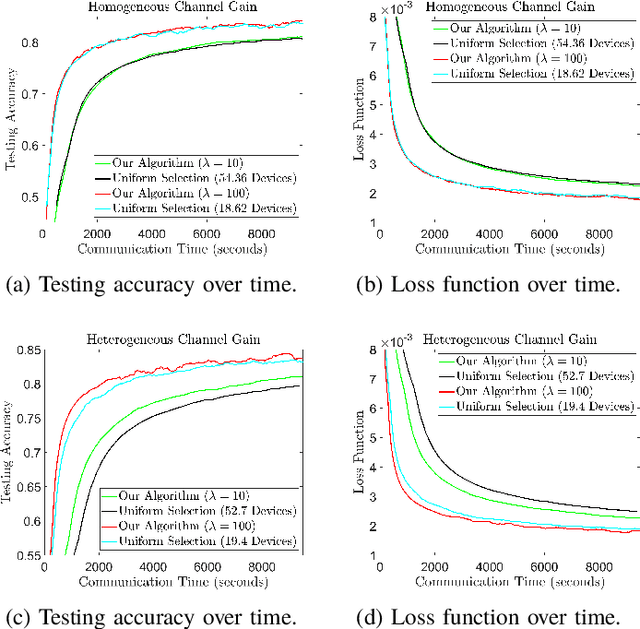
Federated learning (FL) is a useful tool in distributed machine learning that utilizes users' local datasets in a privacy-preserving manner. When deploying FL in a constrained wireless environment; however, training models in a time-efficient manner can be a challenging task due to intermittent connectivity of devices, heterogeneous connection quality, and non-i.i.d. data. In this paper, we provide a novel convergence analysis of non-convex loss functions using FL on both i.i.d. and non-i.i.d. datasets with arbitrary device selection probabilities for each round. Then, using the derived convergence bound, we use stochastic optimization to develop a new client selection and power allocation algorithm that minimizes a function of the convergence bound and the average communication time under a transmit power constraint. We find an analytical solution to the minimization problem. One key feature of the algorithm is that knowledge of the channel statistics is not required and only the instantaneous channel state information needs to be known. Using the FEMNIST and CIFAR-10 datasets, we show through simulations that the communication time can be significantly decreased using our algorithm, compared to uniformly random participation.
Tree Energy Loss: Towards Sparsely Annotated Semantic Segmentation
Mar 22, 2022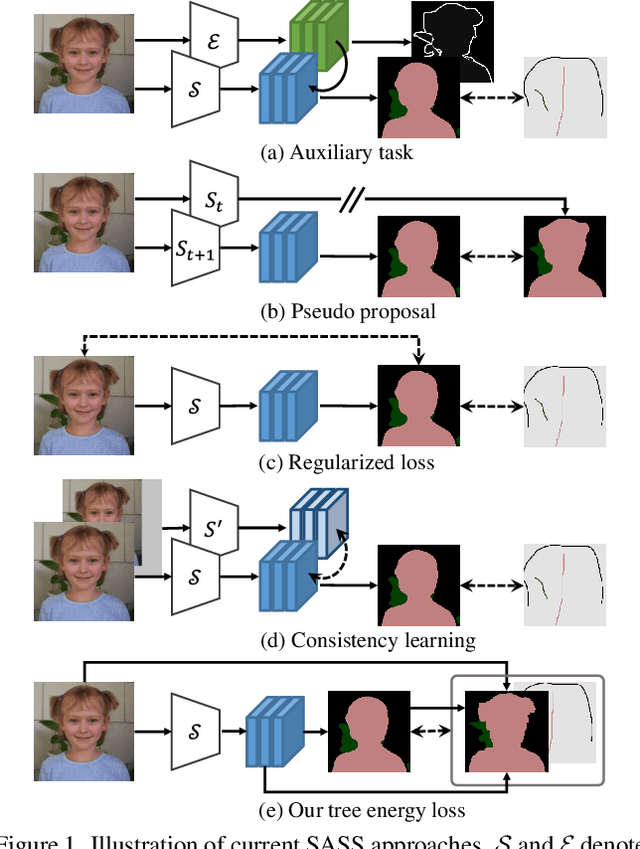
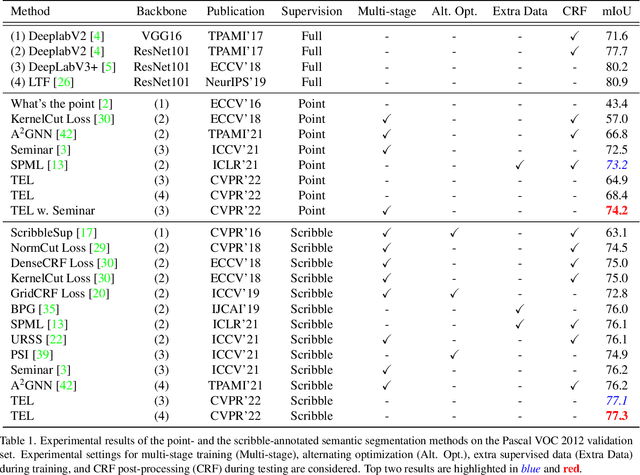

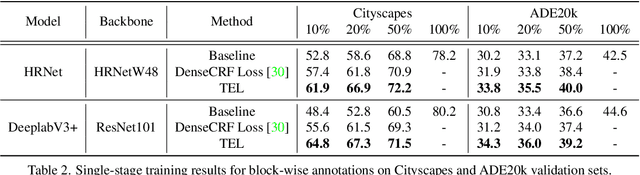
Sparsely annotated semantic segmentation (SASS) aims to train a segmentation network with coarse-grained (i.e., point-, scribble-, and block-wise) supervisions, where only a small proportion of pixels are labeled in each image. In this paper, we propose a novel tree energy loss for SASS by providing semantic guidance for unlabeled pixels. The tree energy loss represents images as minimum spanning trees to model both low-level and high-level pair-wise affinities. By sequentially applying these affinities to the network prediction, soft pseudo labels for unlabeled pixels are generated in a coarse-to-fine manner, achieving dynamic online self-training. The tree energy loss is effective and easy to be incorporated into existing frameworks by combining it with a traditional segmentation loss. Compared with previous SASS methods, our method requires no multistage training strategies, alternating optimization procedures, additional supervised data, or time-consuming post-processing while outperforming them in all SASS settings. Code is available at https://github.com/megvii-research/TreeEnergyLoss.
Speeding up deep neural network-based planning of local car maneuvers via efficient B-spline path construction
Mar 14, 2022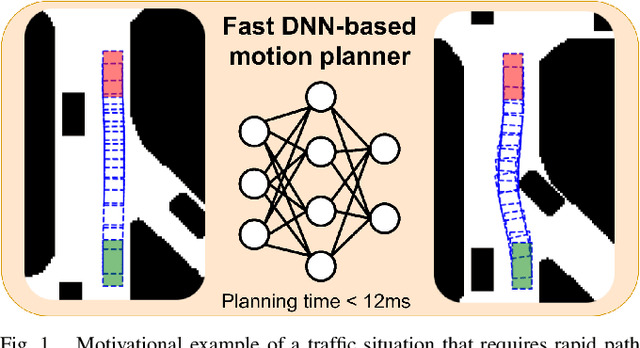
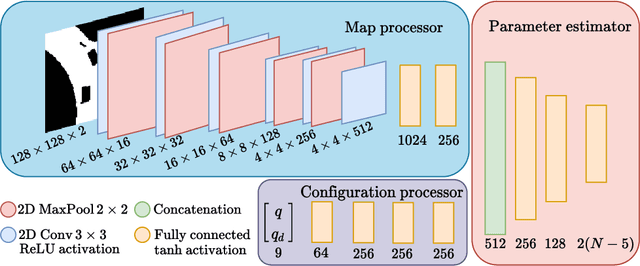
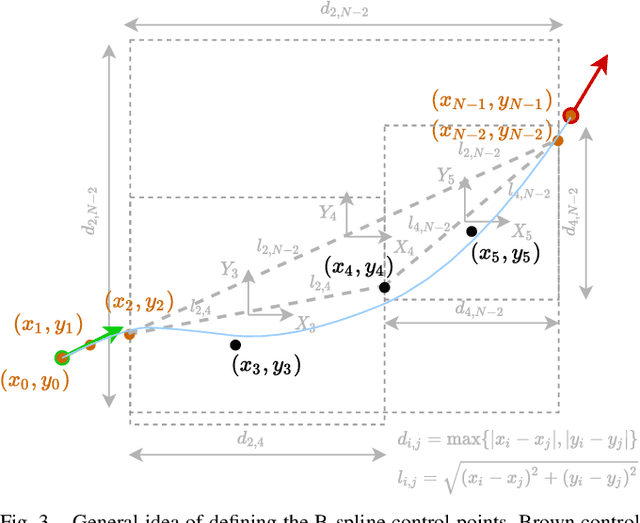
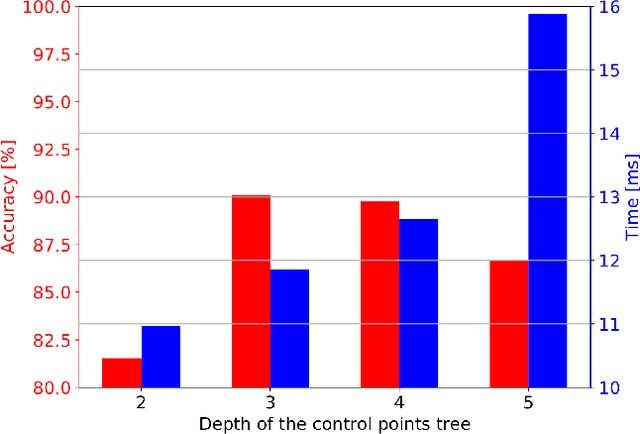
This paper demonstrates how an efficient representation of the planned path using B-splines, and a construction procedure that takes advantage of the neural network's inductive bias, speed up both the inference and training of a DNN-based motion planner. We build upon our recent work on learning local car maneuvers from past experience using a DNN architecture, introducing a novel B-spline path construction method, making it possible to generate local maneuvers in almost constant time of about 11 ms, respecting a number of constraints imposed by the environment map and the kinematics of a car-like vehicle. We evaluate thoroughly the new planner employing the recent Bench-MR framework to obtain quantitative results showing that our method outperforms state-of-the-art planners by a large margin in the considered task.
Matching Writers to Content Writing Tasks
Apr 07, 2022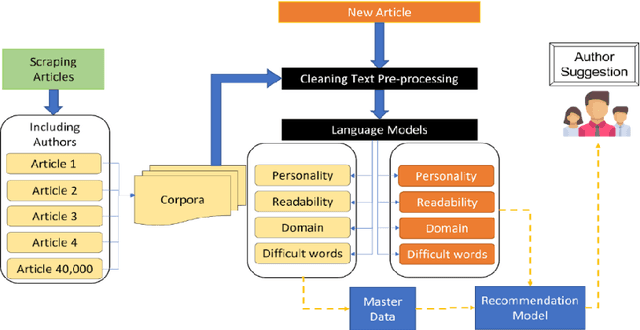
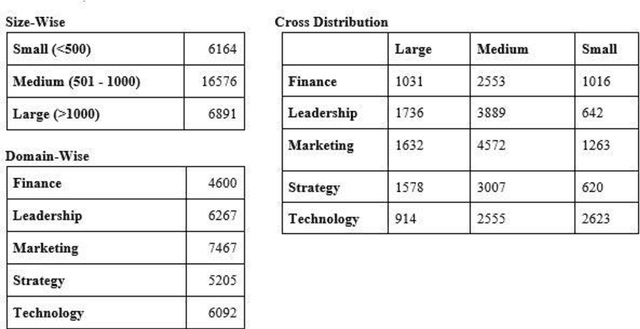
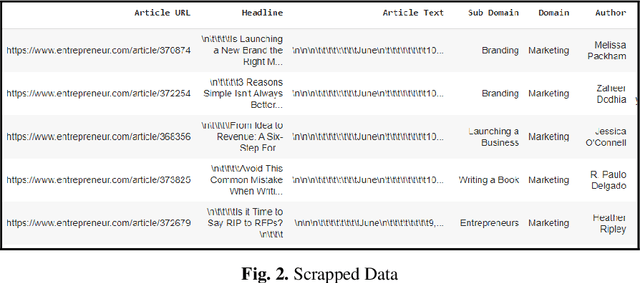
Businesses need content. In various forms and formats and for varied purposes. In fact, the content marketing industry is set to be worth $412.88 billion by the end of 2021. However, according to the Content Marketing Institute, creating engaging content is the #1 challenge that marketers face today. We under-stand that producing great content requires great writers who understand the business and can weave their message into reader (and search engine) friendly content. In this project, the team has attempted to bridge the gap between writers and projects by using AI and ML tools. We used NLP techniques to analyze thou-sands of publicly available business articles (corpora) to extract various defining factors for each writing sample. Through this project we aim to automate the highly time-consuming, and often biased task of manually shortlisting the most suitable writer for a given content writing requirement. We believe that a tool like this will have far reaching positive implications for both parties - businesses looking for suitable talent for niche writing jobs as well as experienced writers and Subject Matter Experts (SMEs) wanting to lend their services to content marketing projects. The business gets the content they need, the content writer/ SME gets a chance to leverage his or her talent, while the reader gets authentic content that adds real value.
Hybrid Transformer Network for Different Horizons-based Enriched Wind Speed Forecasting
Apr 07, 2022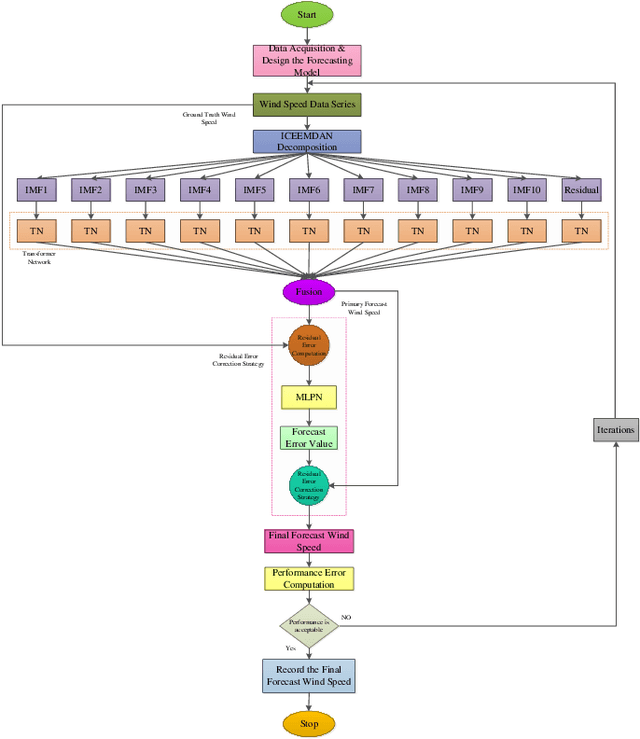
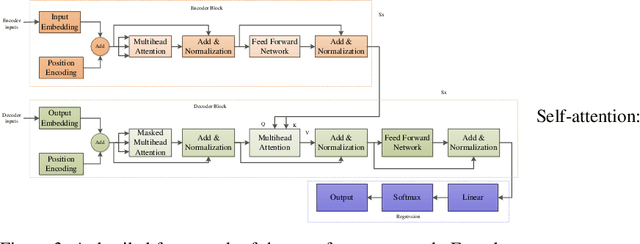
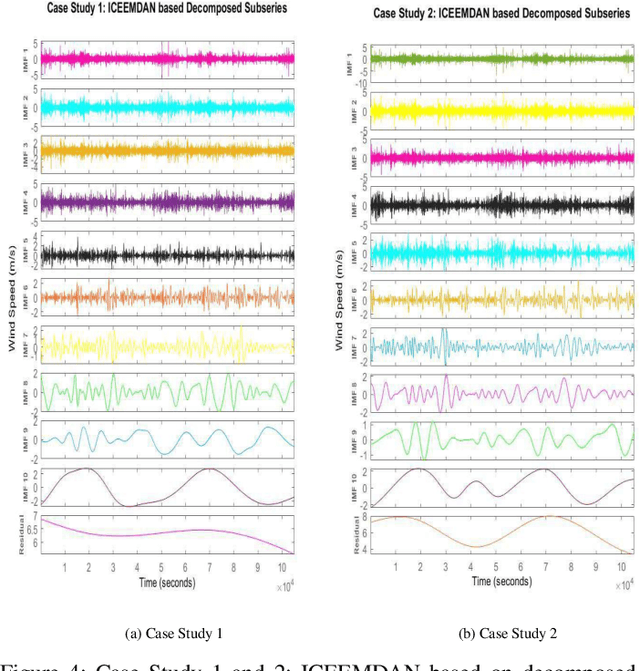
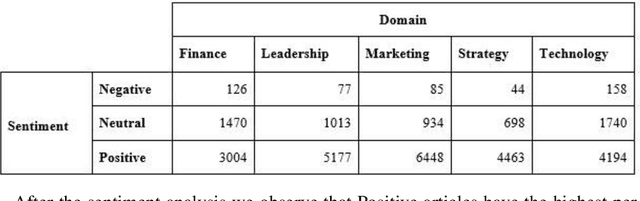
Highly accurate different horizon-based wind speed forecasting facilitates a better modern power system. This paper proposed a novel astute hybrid wind speed forecasting model and applied it to different horizons. The proposed hybrid forecasting model decomposes the original wind speed data into IMFs (Intrinsic Mode Function) using Improved Complete Ensemble Empirical Mode Decomposition with Adaptive Noise (ICEEMDAN). We fed the obtained subseries from ICEEMDAN to the transformer network. Each transformer network computes the forecast subseries and then passes to the fusion phase. Get the primary wind speed forecasting from the fusion of individual transformer network forecast subseries. Estimate the residual error values and predict errors using a multilayer perceptron neural network. The forecast error is added to the primary forecast wind speed to leverage the high accuracy of wind speed forecasting. Comparative analysis with real-time Kethanur, India wind farm dataset results reveals the proposed ICEEMDAN-TNF-MLPN-RECS hybrid model's superior performance with MAE=1.7096*10^-07, MAPE=2.8416*10^-06, MRE=2.8416*10^-08, MSE=5.0206*10^-14, and RMSE=2.2407*10^-07 for case study 1 and MAE=6.1565*10^-07, MAPE=9.5005*10^-06, MRE=9.5005*10^-08, MSE=8.9289*10^-13, and RMSE=9.4493*10^-07 for case study 2 enriched wind speed forecasting than state-of-the-art methods and reduces the burden on the power system engineer.
The Proof is in the Pudding: Using Automated Theorem Proving to Generate Cooking Recipes
Mar 05, 2022


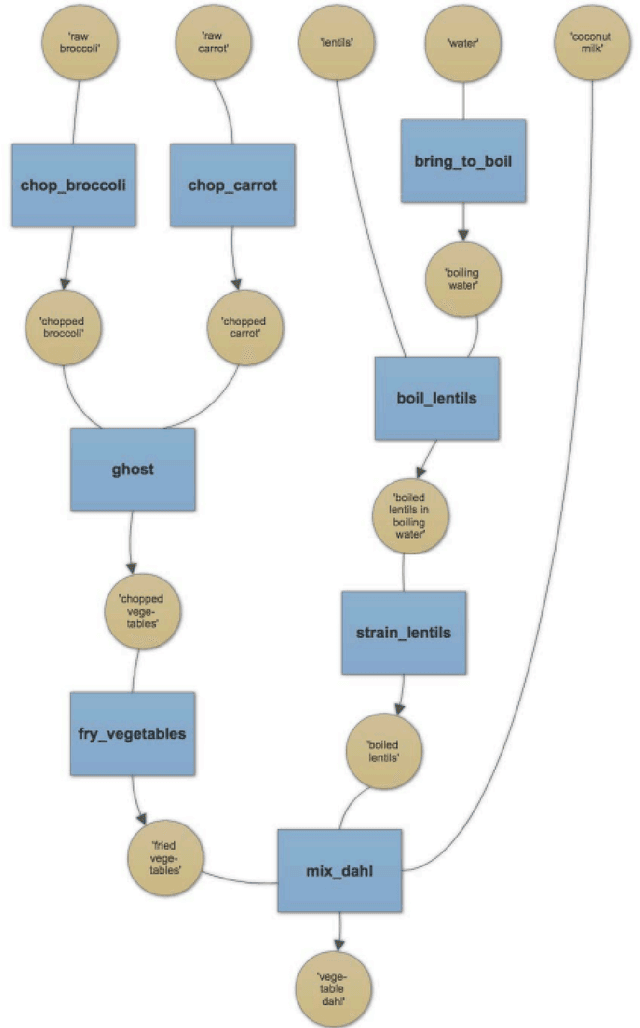
This paper presents FASTFOOD, a rule-based Natural Language Generation Program for cooking recipes. Recipes are generated by using an Automated Theorem Proving procedure to select the ingredients and instructions, with ingredients corresponding to axioms and instructions to implications. FASTFOOD also contains a temporal optimization module which can rearrange the recipe to make it more time-efficient for the user, e.g. the recipe specifies to chop the vegetables while the rice is boiling. The system is described in detail, using a framework which divides Natural Language Generation into 4 phases: content production, content selection, content organisation and content realisation. A comparison is then made with similar existing systems and techniques.
Time-Domain Hybrid PAM for Data-Rate and Distance Adaptive UWOC System
Mar 08, 2021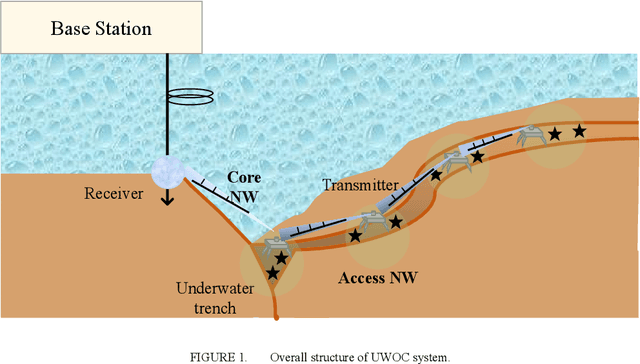
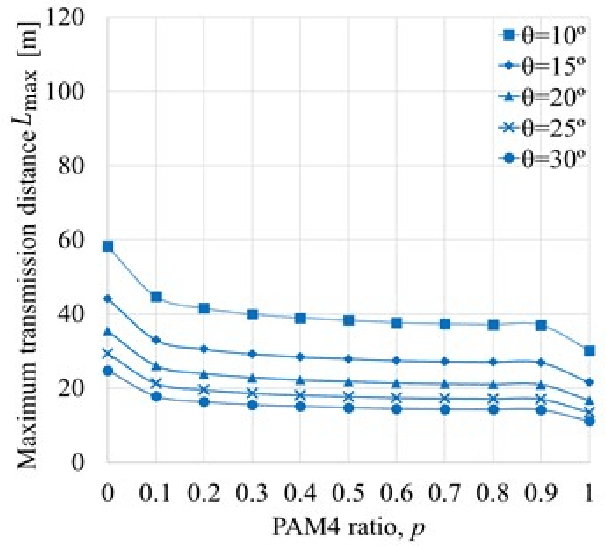
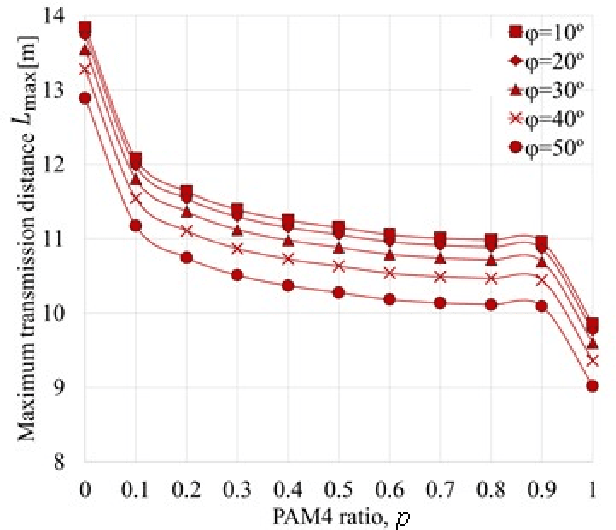
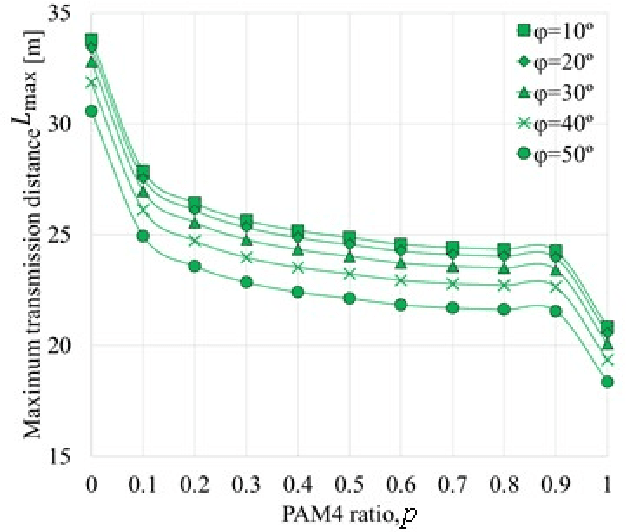
The challenge for next-generation underwater optical wireless communication systems is to develop optical transceivers that can operate with low power consumption by maximizing the transmission capacity according to the transmission distance between transmitters and receivers. This study proposes an underwater wireless optical communication (UWOC) system using an optical transceiver with an optimum transmission rate for the deep sea with near-pure water properties. As a method for actualizing an optical transceiver with an optimum transmission rate in a UWOC system, time-domain hybrid pulse amplitude modulation (PAM) (TDHP) using a transmission rate and distance-adaptive intensity modulation/direct detection optical transceiver is considered. In the TDHP method, variable transmission capacity is actualized while changing the generation ratio of two intensity-modulated signals with different noise immunities in the time domain. Three different color laser diodes (LDs), red, blue, and green are used in an underwater channel transmission transceiver that comprises the LD and a photodiode. The maximum transmission distance while changing the incidence of PAM 2 and PAM 4 signals that calibrate the TDHP in a pure transmission line and how the maximum transmission distance changes when the optical transmitter/receiver spatial optical system is altered from the optimum conditions are clarified based on numerical calculation and simulation. To the best knowledge of the authors, there is no other research on data-rate and distance adaptive UWOC system that applies the TDHP signal with power optimization between two modulation formats.
Reproducibility Issues for BERT-based Evaluation Metrics
Mar 30, 2022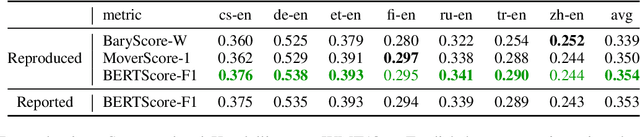
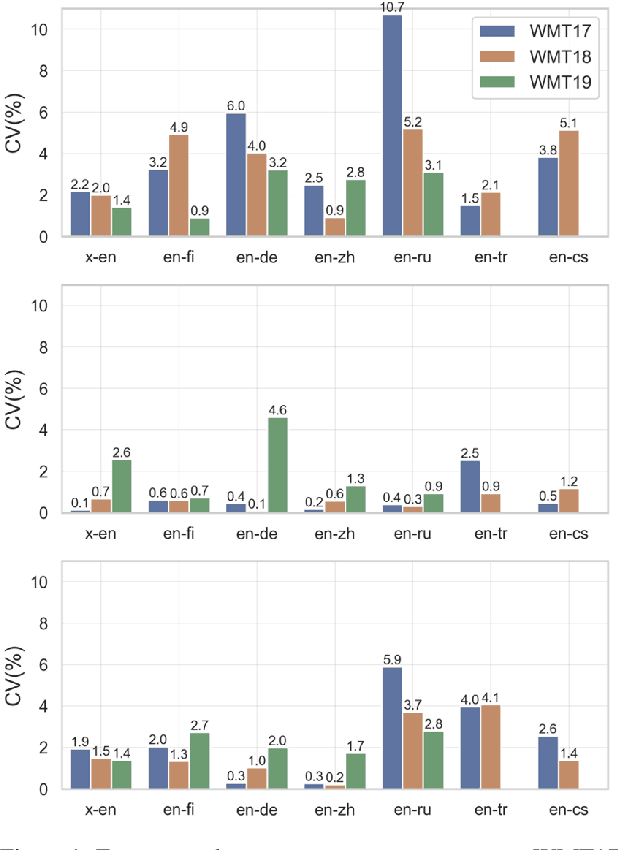
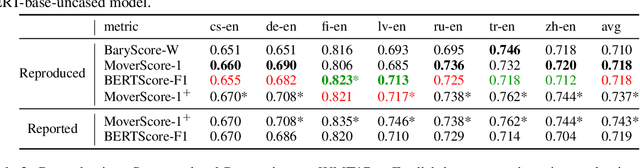
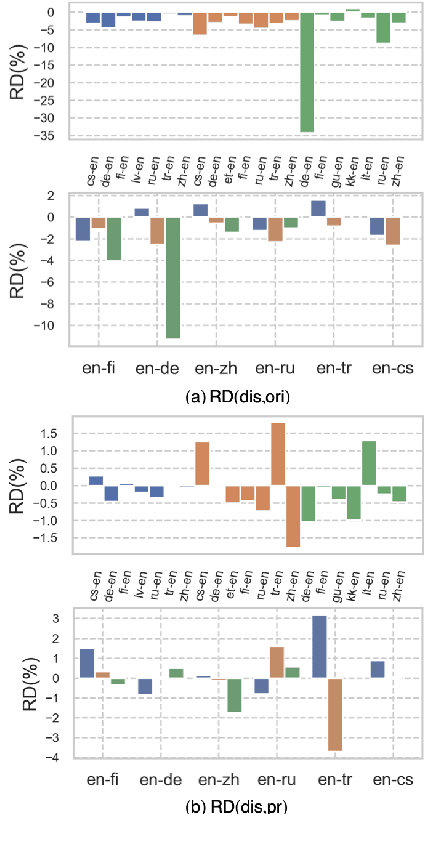
Reproducibility is of utmost concern in machine learning and natural language processing (NLP). In the field of natural language generation (especially machine translation), the seminal paper of Post (2018) has pointed out problems of reproducibility of the dominant metric, BLEU, at the time of publication. Nowadays, BERT-based evaluation metrics considerably outperform BLEU. In this paper, we ask whether results and claims from four recent BERT-based metrics can be reproduced. We find that reproduction of claims and results often fails because of (i) heavy undocumented preprocessing involved in the metrics, (ii) missing code and (iii) reporting weaker results for the baseline metrics. (iv) In one case, the problem stems from correlating not to human scores but to a wrong column in the csv file, inflating scores by 5 points. Motivated by the impact of preprocessing, we then conduct a second study where we examine its effects more closely (for one of the metrics). We find that preprocessing can have large effects, especially for highly inflectional languages. In this case, the effect of preprocessing may be larger than the effect of the aggregation mechanism (e.g., greedy alignment vs. Word Mover Distance).