 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A survey of neural models for the automatic analysis of conversation: Towards a better integration of the social sciences
Mar 31, 2022
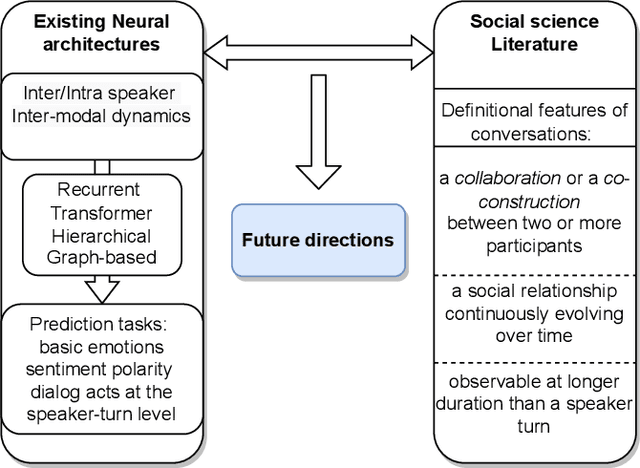
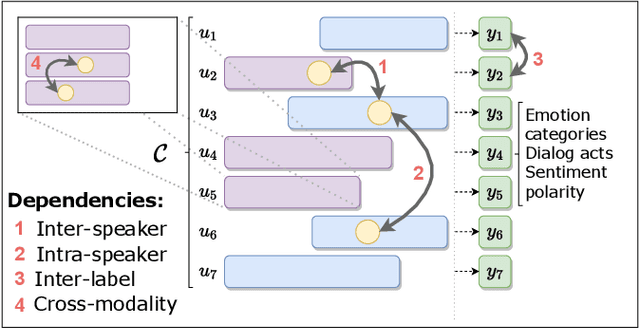
Some exciting new approaches to neural architectures for the analysis of conversation have been introduced over the past couple of years. These include neural architectures for detecting emotion, dialogue acts, and sentiment polarity. They take advantage of some of the key attributes of contemporary machine learning, such as recurrent neural networks with attention mechanisms and transformer-based approaches. However, while the architectures themselves are extremely promising, the phenomena they have been applied to to date are but a small part of what makes conversation engaging. In this paper we survey these neural architectures and what they have been applied to. On the basis of the social science literature, we then describe what we believe to be the most fundamental and definitional feature of conversation, which is its co-construction over time by two or more interlocutors. We discuss how neural architectures of the sort surveyed could profitably be applied to these more fundamental aspects of conversation, and what this buys us in terms of a better analysis of conversation and even, in the longer term, a better way of generating conversation for a conversational system.
T4PdM: a Deep Neural Network based on the Transformer Architecture for Fault Diagnosis of Rotating Machinery
Apr 07, 2022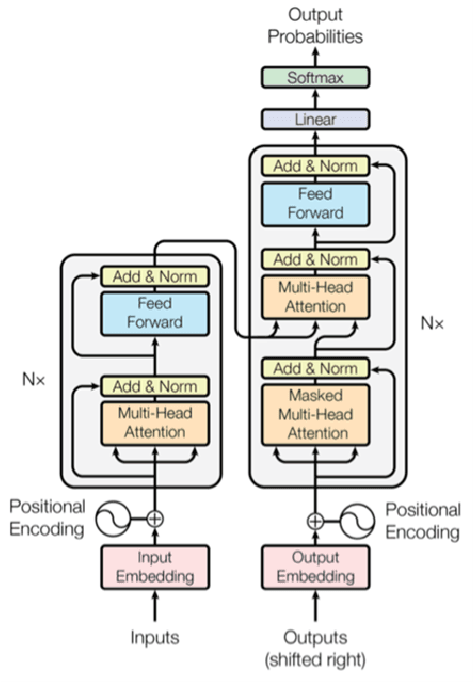

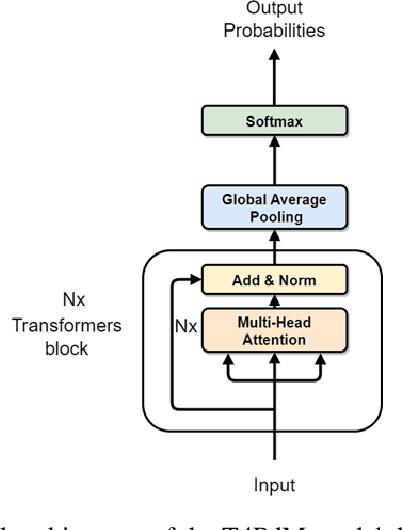
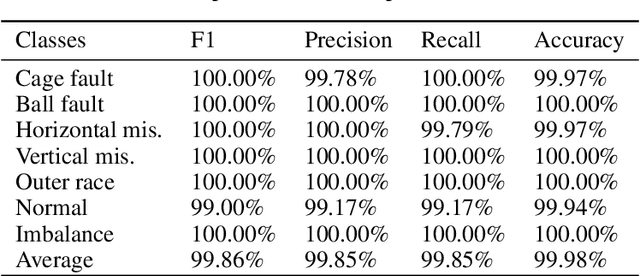
Deep learning and big data algorithms have become widely used in industrial applications to optimize several tasks in many complex systems. Particularly, deep learning model for diagnosing and prognosing machinery health has leveraged predictive maintenance (PdM) to be more accurate and reliable in decision making, in this way avoiding unnecessary interventions, machinery accidents, and environment catastrophes. Recently, Transformer Neural Networks have gained notoriety and have been increasingly the favorite choice for Natural Language Processing (NLP) tasks. Thus, given their recent major achievements in NLP, this paper proposes the development of an automatic fault classifier model for predictive maintenance based on a modified version of the Transformer architecture, namely T4PdM, to identify multiple types of faults in rotating machinery. Experimental results are developed and presented for the MaFaulDa and CWRU databases. T4PdM was able to achieve an overall accuracy of 99.98% and 98% for both datasets, respectively. In addition, the performance of the proposed model is compared to other previously published works. It has demonstrated the superiority of the model in detecting and classifying faults in rotating industrial machinery. Therefore, the proposed Transformer-based model can improve the performance of machinery fault analysis and diagnostic processes and leverage companies to a new era of the Industry 4.0. In addition, this methodology can be adapted to any other task of time series classification.
Temporal Latent Auto-Encoder: A Method for Probabilistic Multivariate Time Series Forecasting
Jan 25, 2021
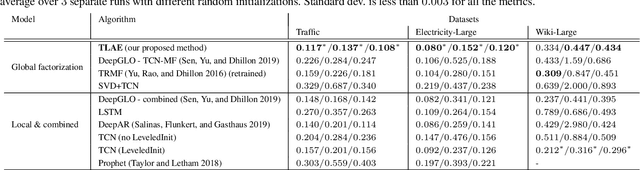
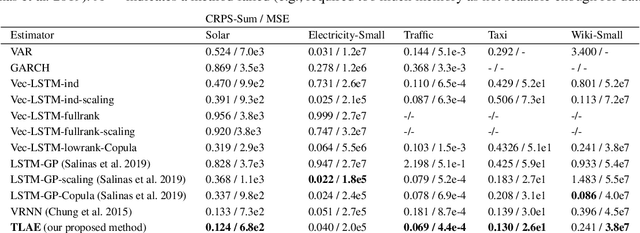
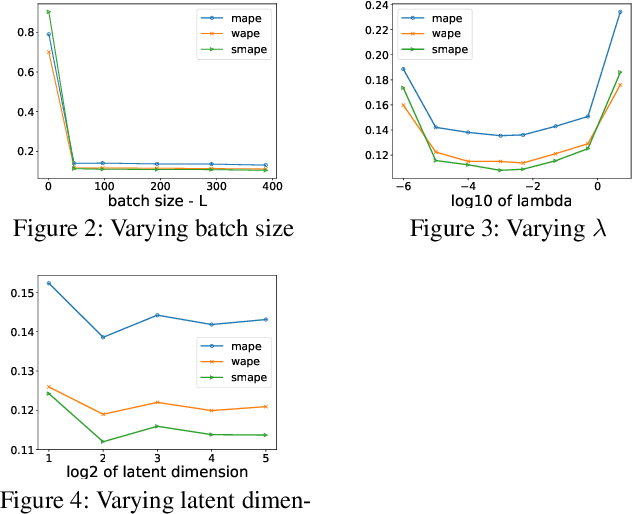
Probabilistic forecasting of high dimensional multivariate time series is a notoriously challenging task, both in terms of computational burden and distribution modeling. Most previous work either makes simple distribution assumptions or abandons modeling cross-series correlations. A promising line of work exploits scalable matrix factorization for latent-space forecasting, but is limited to linear embeddings, unable to model distributions, and not trainable end-to-end when using deep learning forecasting. We introduce a novel temporal latent auto-encoder method which enables nonlinear factorization of multivariate time series, learned end-to-end with a temporal deep learning latent space forecast model. By imposing a probabilistic latent space model, complex distributions of the input series are modeled via the decoder. Extensive experiments demonstrate that our model achieves state-of-the-art performance on many popular multivariate datasets, with gains sometimes as high as $50\%$ for several standard metrics.
Forgery Attack Detection in Surveillance Video Streams Using Wi-Fi Channel State Information
Jan 24, 2022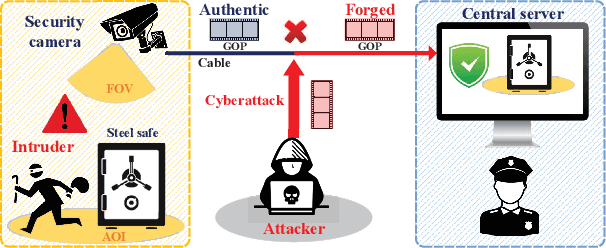
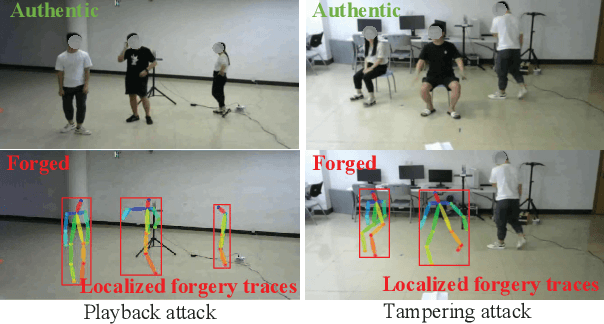
The cybersecurity breaches expose surveillance video streams to forgery attacks, under which authentic streams are falsified to hide unauthorized activities. Traditional video forensics approaches can localize forgery traces using spatial-temporal analysis on relatively long video clips, while falling short in real-time forgery detection. The recent work correlates time-series camera and wireless signals to detect looped videos but cannot realize fine-grained forgery localization. To overcome these limitations, we propose Secure-Pose, which exploits the pervasive coexistence of surveillance and Wi-Fi infrastructures to defend against video forgery attacks in a real-time and fine-grained manner. We observe that coexisting camera and Wi-Fi signals convey common human semantic information and forgery attacks on video streams will decouple such information correspondence. Particularly, retrievable human pose features are first extracted from concurrent video and Wi-Fi channel state information (CSI) streams. Then, a lightweight detection network is developed to accurately discover forgery attacks and an efficient localization algorithm is devised to seamlessly track forgery traces in video streams. We implement Secure-Pose using one Logitech camera and two Intel 5300 NICs and evaluate it in different environments. Secure-Pose achieves a high detection accuracy of 98.7% and localizes abnormal objects under playback and tampering attacks.
Forecasting new diseases in low-data settings using transfer learning
Apr 07, 2022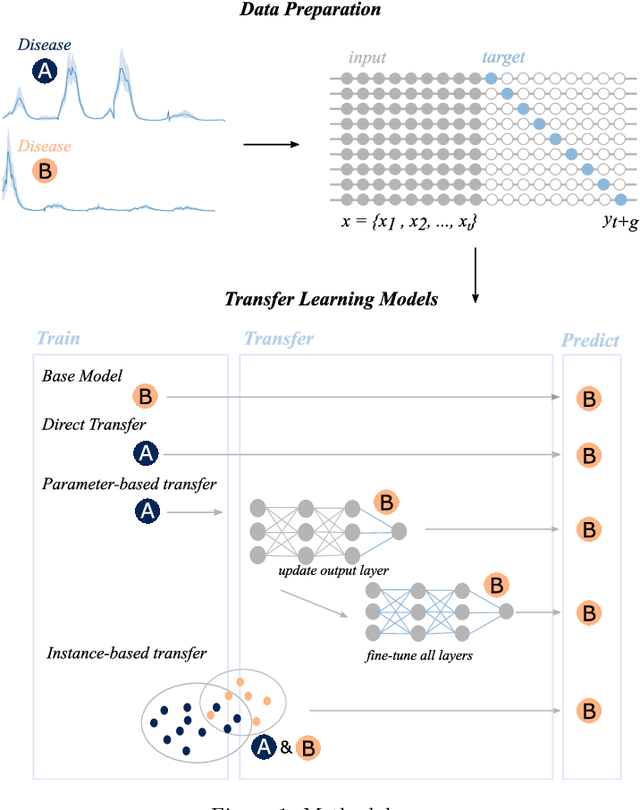
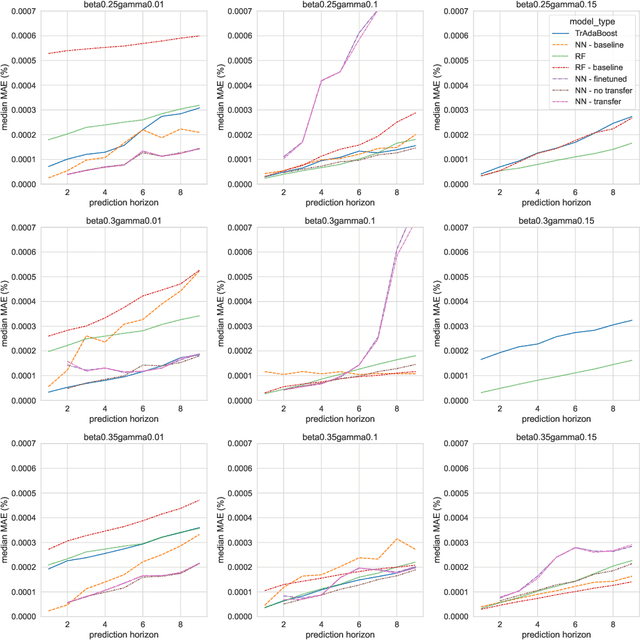
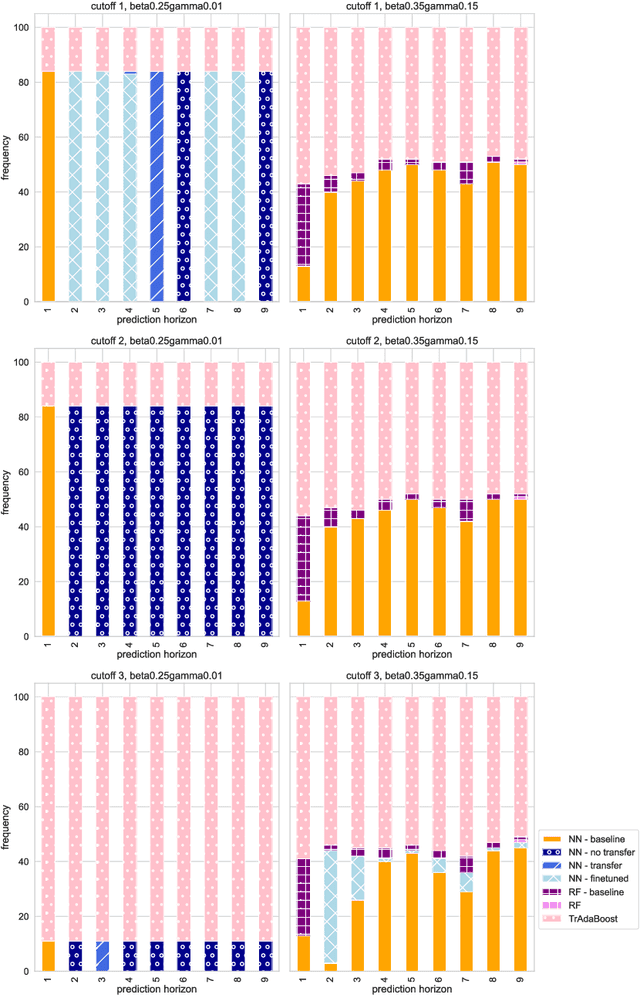
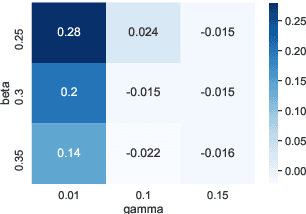
Recent infectious disease outbreaks, such as the COVID-19 pandemic and the Zika epidemic in Brazil, have demonstrated both the importance and difficulty of accurately forecasting novel infectious diseases. When new diseases first emerge, we have little knowledge of the transmission process, the level and duration of immunity to reinfection, or other parameters required to build realistic epidemiological models. Time series forecasts and machine learning, while less reliant on assumptions about the disease, require large amounts of data that are also not available in early stages of an outbreak. In this study, we examine how knowledge of related diseases can help make predictions of new diseases in data-scarce environments using transfer learning. We implement both an empirical and a theoretical approach. Using empirical data from Brazil, we compare how well different machine learning models transfer knowledge between two different disease pairs: (i) dengue and Zika, and (ii) influenza and COVID-19. In the theoretical analysis, we generate data using different transmission and recovery rates with an SIR compartmental model, and then compare the effectiveness of different transfer learning methods. We find that transfer learning offers the potential to improve predictions, even beyond a model based on data from the target disease, though the appropriate source disease must be chosen carefully. While imperfect, these models offer an additional input for decision makers during pandemic response.
Image analysis for automatic measurement of crustose lichens
Mar 01, 2022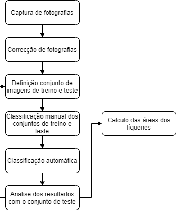
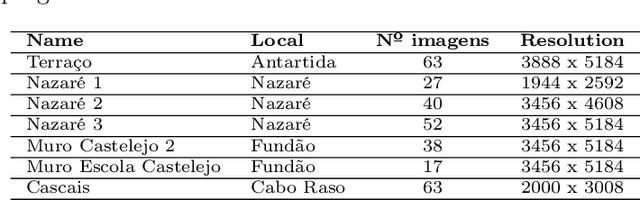


Lichens, organisms resulting from a symbiosis between a fungus and an algae, are frequently used as age estimators, especially in recent geological deposits and archaeological structures, using the correlation between lichen size and age. Current non-automated manual lichen and measurement (with ruler, calipers or using digital image processing tools) is a time-consuming and laborious process, especially when the number of samples is high. This work presents a workflow and set of image acquisition and processing tools developed to efficiently identify lichen thalli in flat rocky surfaces, and to produce relevant lichen size statistics (percentage cover, number of thalli, their area and perimeter). The developed workflow uses a regular digital camera for image capture along with specially designed targets to allow for automatic image correction and scale assignment. After this step, lichen identification is done in a flow comprising assisted image segmentation and classification based on interactive foreground extraction tool (GrabCut) and automatic classification of images using Simple Linear Iterative Clustering (SLIC) for image segmentation and Support Vector Machines (SV) and Random Forest classifiers. Initial evaluation shows promising results. The manual classification of images (for training) using GrabCut show an average speedup of 4 if compared with currently used techniques and presents an average precision of 95\%. The automatic classification using SLIC and SVM with default parameters produces results with average precision higher than 70\%. The developed system is flexible and allows a considerable reduction of processing time, the workflow allows it applicability to data sets of new lichen populations.
Near Real-Time Social Distancing in London
Dec 07, 2020
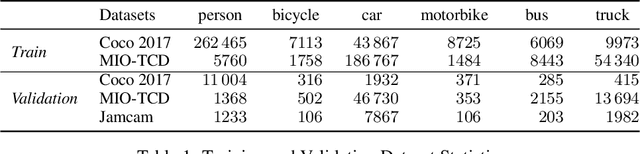
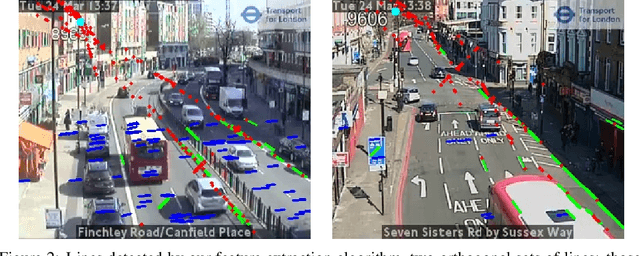
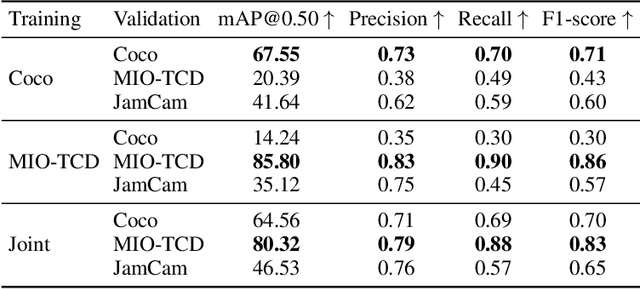
During the COVID-19 pandemic, policy makers at the Greater London Authority, the regional governance body of London, UK, are reliant upon prompt and accurate data sources. Large well-defined heterogeneous compositions of activity throughout the city are sometimes difficult to acquire, yet are a necessity in order to learn 'busyness' and consequently make safe policy decisions. One component of our project within this space is to utilise existing infrastructure to estimate social distancing adherence by the general public. Our method enables near immediate sampling and contextualisation of activity and physical distancing on the streets of London via live traffic camera feeds. We introduce a framework for inspecting and improving upon existing methods, whilst also describing its active deployment on over 900 real-time feeds.
Explaining Reinforcement Learning Policies through Counterfactual Trajectories
Jan 29, 2022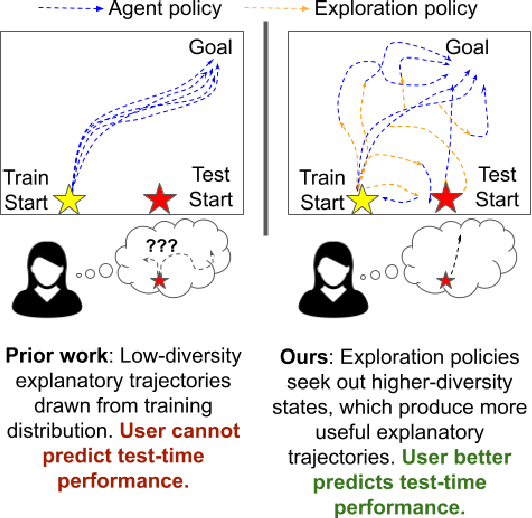
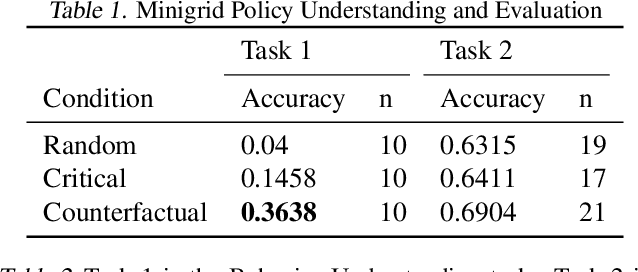
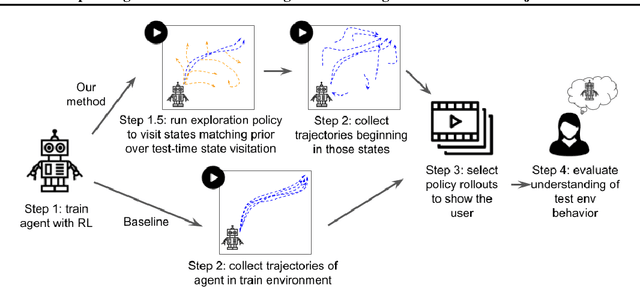
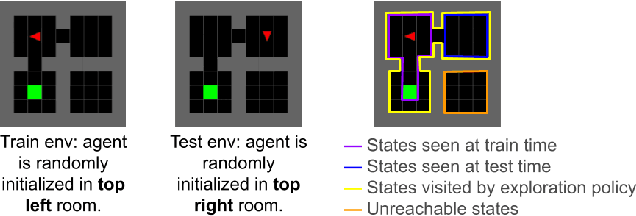
In order for humans to confidently decide where to employ RL agents for real-world tasks, a human developer must validate that the agent will perform well at test-time. Some policy interpretability methods facilitate this by capturing the policy's decision making in a set of agent rollouts. However, even the most informative trajectories of training time behavior may give little insight into the agent's behavior out of distribution. In contrast, our method conveys how the agent performs under distribution shifts by showing the agent's behavior across a wider trajectory distribution. We generate these trajectories by guiding the agent to more diverse unseen states and showing the agent's behavior there. In a user study, we demonstrate that our method enables users to score better than baseline methods on one of two agent validation tasks.
Deformable Video Transformer
Mar 31, 2022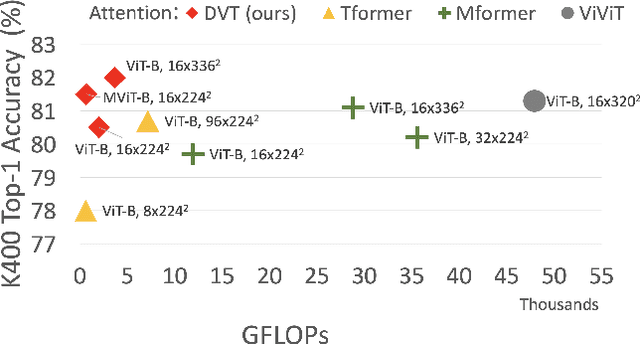

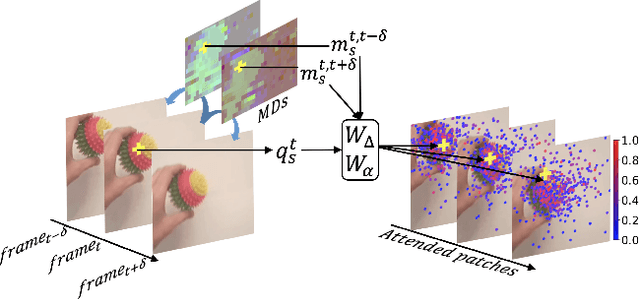
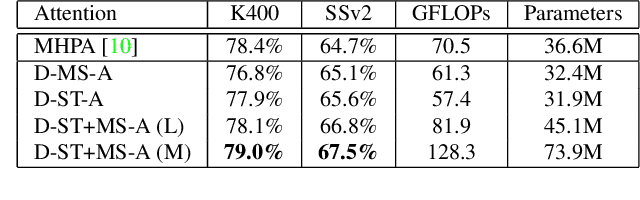
Video transformers have recently emerged as an effective alternative to convolutional networks for action classification. However, most prior video transformers adopt either global space-time attention or hand-defined strategies to compare patches within and across frames. These fixed attention schemes not only have high computational cost but, by comparing patches at predetermined locations, they neglect the motion dynamics in the video. In this paper, we introduce the Deformable Video Transformer (DVT), which dynamically predicts a small subset of video patches to attend for each query location based on motion information, thus allowing the model to decide where to look in the video based on correspondences across frames. Crucially, these motion-based correspondences are obtained at zero-cost from information stored in the compressed format of the video. Our deformable attention mechanism is optimised directly with respect to classification performance, thus eliminating the need for suboptimal hand-design of attention strategies. Experiments on four large-scale video benchmarks (Kinetics-400, Something-Something-V2, EPIC-KITCHENS and Diving-48) demonstrate that, compared to existing video transformers, our model achieves higher accuracy at the same or lower computational cost, and it attains state-of-the-art results on these four datasets.
Video-Text Representation Learning via Differentiable Weak Temporal Alignment
Mar 31, 2022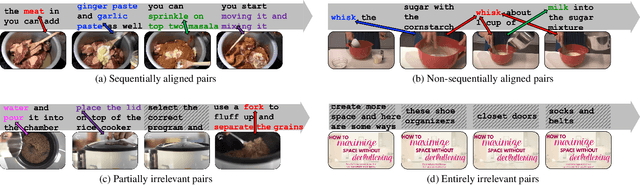
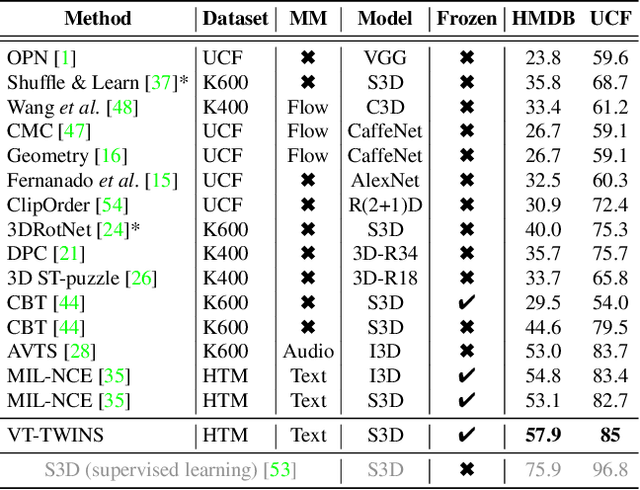
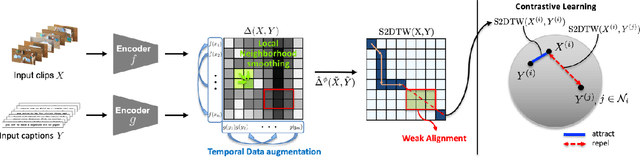
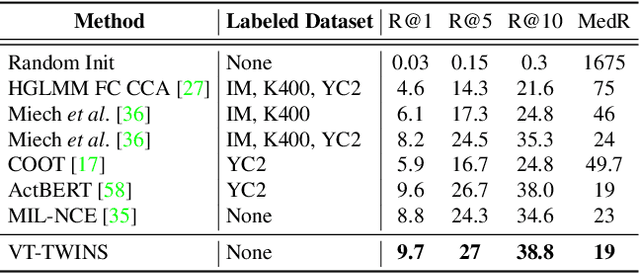
Learning generic joint representations for video and text by a supervised method requires a prohibitively substantial amount of manually annotated video datasets. As a practical alternative, a large-scale but uncurated and narrated video dataset, HowTo100M, has recently been introduced. But it is still challenging to learn joint embeddings of video and text in a self-supervised manner, due to its ambiguity and non-sequential alignment. In this paper, we propose a novel multi-modal self-supervised framework Video-Text Temporally Weak Alignment-based Contrastive Learning (VT-TWINS) to capture significant information from noisy and weakly correlated data using a variant of Dynamic Time Warping (DTW). We observe that the standard DTW inherently cannot handle weakly correlated data and only considers the globally optimal alignment path. To address these problems, we develop a differentiable DTW which also reflects local information with weak temporal alignment. Moreover, our proposed model applies a contrastive learning scheme to learn feature representations on weakly correlated data. Our extensive experiments demonstrate that VT-TWINS attains significant improvements in multi-modal representation learning and outperforms various challenging downstream tasks. Code is available at https://github.com/mlvlab/VT-TWINS.