 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Stack Index Prediction Using Time-Series Analysis
Aug 18, 2021
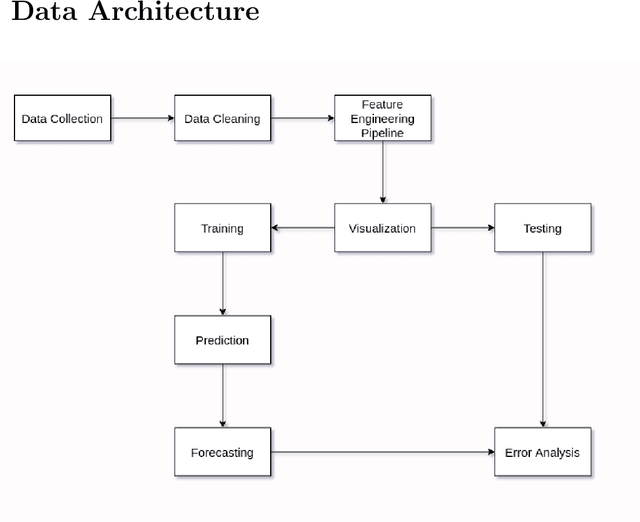
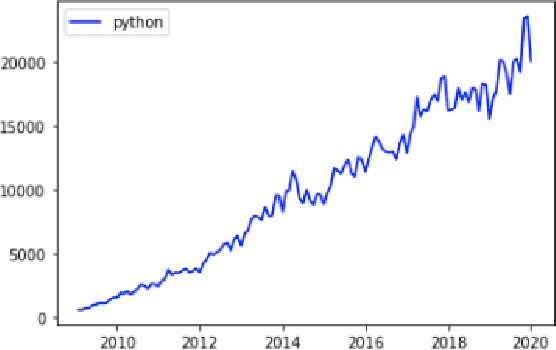
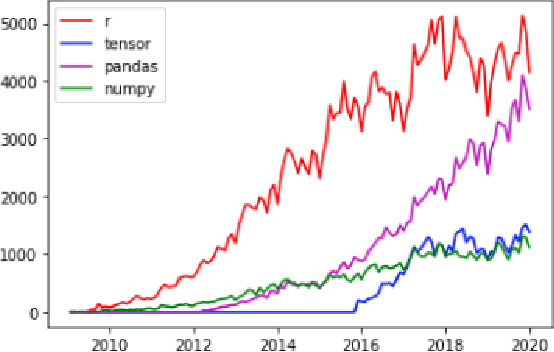
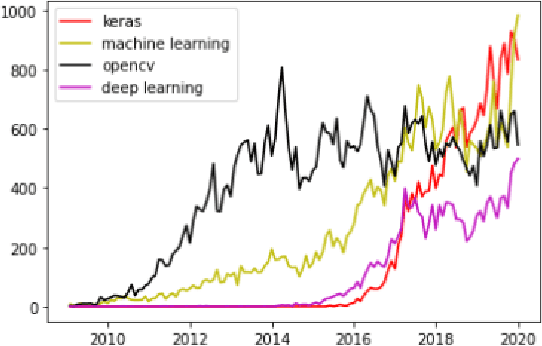
The Prevalence of Community support and engagement for different domains in the tech industry has changed and evolved throughout the years. In this study, we aim to understand, analyze and predict the trends of technology in a scientific manner, having collected data on numerous topics and their growth throughout the years in the past decade. We apply machine learning models on collected data, to understand, analyze and forecast the trends in the advancement of different fields. We show that certain technical concepts such as python, machine learning, and Keras have an undisputed uptrend, finally concluding that the Stackindex model forecasts with high accuracy and can be a viable tool for forecasting different tech domains.
Capturing Delayed Feedback in Conversion Rate Prediction via Elapsed-Time Sampling
Dec 06, 2020

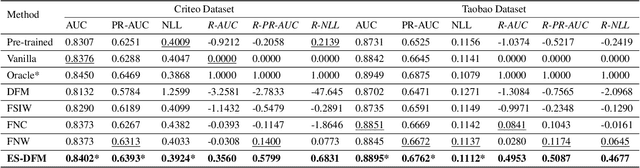

Capturing Delayed Feedback in Conversion Rate Prediction via Elapsed-Time Sampling Hide abstract Conversion rate (CVR) prediction is one of the most critical tasks for digital display advertising. Commercial systems often require to update models in an online learning manner to catch up with the evolving data distribution. However, conversions usually do not happen immediately after a user click. This may result in inaccurate labeling, which is called delayed feedback problem. In previous studies, delayed feedback problem is handled either by waiting positive label for a long period of time, or by consuming the negative sample on its arrival and then insert a positive duplicate when a conversion happens later. Indeed, there is a trade-off between waiting for more accurate labels and utilizing fresh data, which is not considered in existing works. To strike a balance in this trade-off, we propose Elapsed-Time Sampling Delayed Feedback Model (ES-DFM), which models the relationship between the observed conversion distribution and the true conversion distribution. Then we optimize the expectation of true conversion distribution via importance sampling under the elapsed-time sampling distribution. We further estimate the importance weight for each instance, which is used as the weight of loss function in CVR prediction. To demonstrate the effectiveness of ES-DFM, we conduct extensive experiments on a public data and a private industrial dataset. Experimental results confirm that our method consistently outperforms the previous state-of-the-art results.
Multiple Time Series Fusion Based on LSTM An Application to CAP A Phase Classification Using EEG
Dec 18, 2021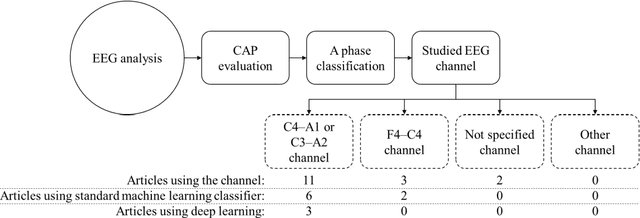

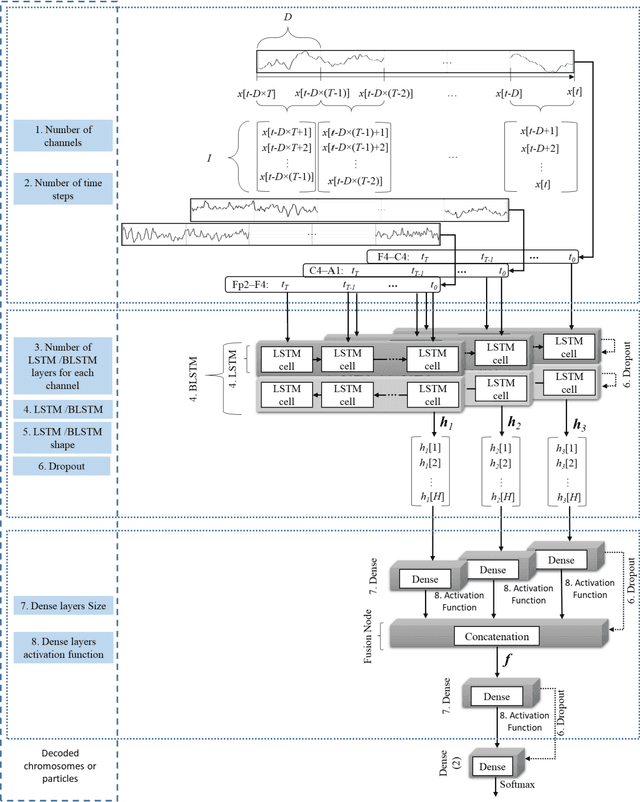

Biomedical decision making involves multiple signal processing, either from different sensors or from different channels. In both cases, information fusion plays a significant role. A deep learning based electroencephalogram channels' feature level fusion is carried out in this work for the electroencephalogram cyclic alternating pattern A phase classification. Channel selection, fusion, and classification procedures were optimized by two optimization algorithms, namely, Genetic Algorithm and Particle Swarm Optimization. The developed methodologies were evaluated by fusing the information from multiple electroencephalogram channels for patients with nocturnal frontal lobe epilepsy and patients without any neurological disorder, which was significantly more challenging when compared to other state of the art works. Results showed that both optimization algorithms selected a comparable structure with similar feature level fusion, consisting of three electroencephalogram channels, which is in line with the CAP protocol to ensure multiple channels' arousals for CAP detection. Moreover, the two optimized models reached an area under the receiver operating characteristic curve of 0.82, with average accuracy ranging from 77% to 79%, a result which is in the upper range of the specialist agreement. The proposed approach is still in the upper range of the best state of the art works despite a difficult dataset, and has the advantage of providing a fully automatic analysis without requiring any manual procedure. Ultimately, the models revealed to be noise resistant and resilient to multiple channel loss.
Automated Isovist Computation for Minecraft
Apr 07, 2022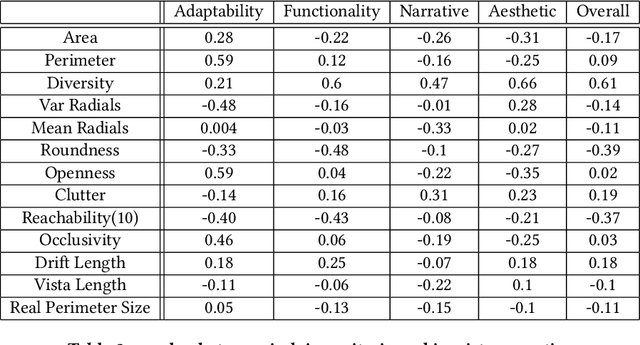
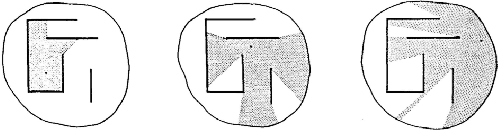
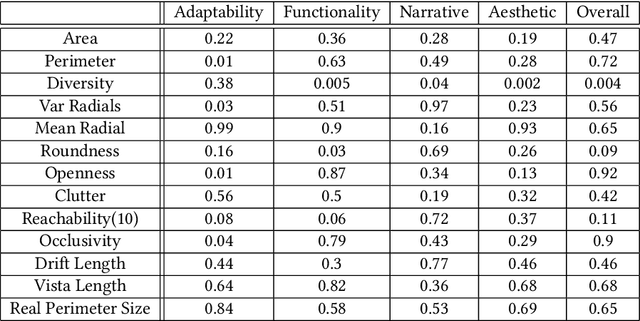
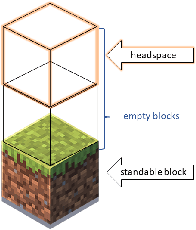
Procedural content generation for games is a growing trend in both research and industry, even though there is no consensus of how good content looks, nor how to automatically evaluate it. A number of metrics have been developed in the past, usually focused on the artifact as a whole, and mostly lacking grounding in human experience. In this study we develop a new set of automated metrics, motivated by ideas from architecture, namely isovists and space syntax, which have a track record of capturing human experience of space. These metrics can be computed for a specific game state, from the player's perspective, and take into account their embodiment in the game world. We show how to apply those metrics to the 3d blockworld of Minecraft. We use a dataset of generated settlements from the GDMC Settlement Generation Challenge in Minecraft and establish several rank-based correlations between the isovist properties and the rating human judges gave those settelements. We also produce a range of heat maps that demonstrate the location based applicability of the approach, which allows for development of those metrics as measures for a game experience at a specific time and space.
Recursive 3D Segmentation of Shoulder Joint with Coarse-scanned MR Image
Mar 13, 2022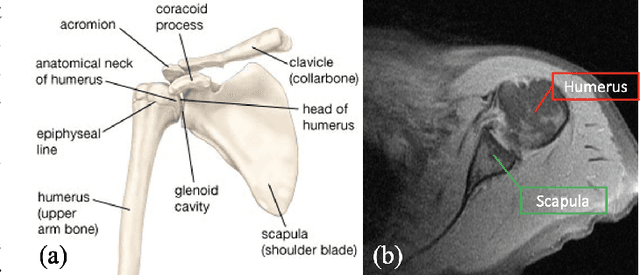
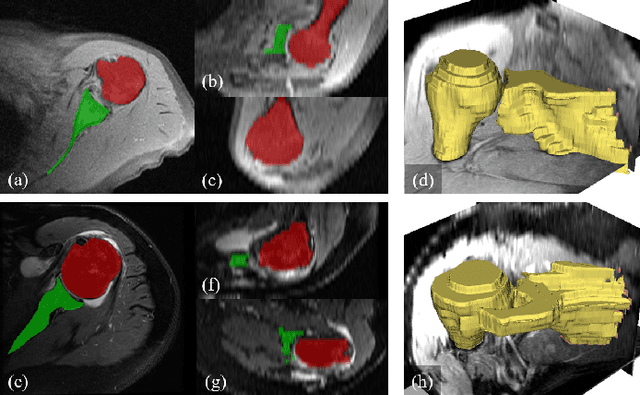
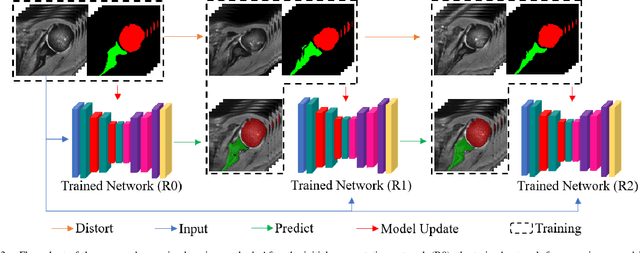
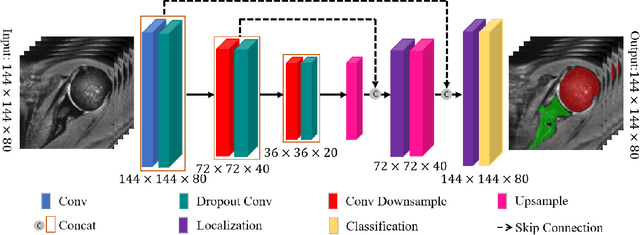
For diagnosis of shoulder illness, it is essential to look at the morphology deviation of scapula and humerus from the medical images that are acquired from Magnetic Resonance (MR) imaging. However, taking high-resolution MR images is time-consuming and costly because the reduction of the physical distance between image slices causes prolonged scanning time. Moreover, due to the lack of training images, images from various sources must be utilized, which creates the issue of high variance across the dataset. Also, there are human errors among the images due to the fact that it is hard to take the spatial relationship into consideration when labeling the 3D image in low resolution. In order to combat all obstacles stated above, we develop a fully automated algorithm for segmenting the humerus and scapula bone from coarsely scanned and low-resolution MR images and a recursive learning framework that iterative utilize the generated labels for reducing the errors among segmentations and increase our dataset set for training the next round network. In this study, 50 MR images are collected from several institutions and divided into five mutually exclusive sets for carrying five-fold cross-validation. Contours that are generated by the proposed method demonstrated a high level of accuracy when compared with ground truth and the traditional method. The proposed neural network and the recursive learning scheme improve the overall quality of the segmentation on humerus and scapula on the low-resolution dataset and reduced incorrect segmentation in the ground truth, which could have a positive impact on finding the cause of shoulder pain and patient's early relief.
CenterNet++ for Object Detection
Apr 18, 2022

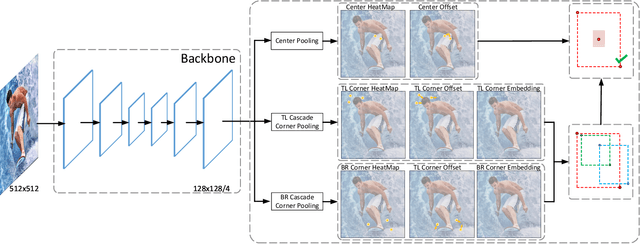
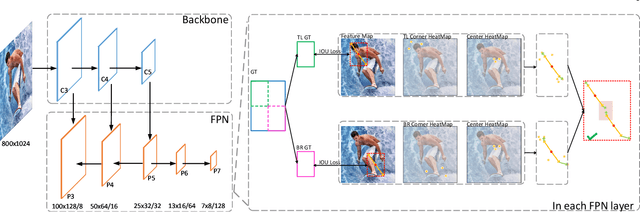
There are two mainstreams for object detection: top-down and bottom-up. The state-of-the-art approaches mostly belong to the first category. In this paper, we demonstrate that the bottom-up approaches are as competitive as the top-down and enjoy higher recall. Our approach, named CenterNet, detects each object as a triplet keypoints (top-left and bottom-right corners and the center keypoint). We firstly group the corners by some designed cues and further confirm the objects by the center keypoints. The corner keypoints equip the approach with the ability to detect objects of various scales and shapes and the center keypoint avoids the confusion brought by a large number of false-positive proposals. Our approach is a kind of anchor-free detector because it does not need to define explicit anchor boxes. We adapt our approach to the backbones with different structures, i.e., the 'hourglass' like networks and the the 'pyramid' like networks, which detect objects on a single-resolution feature map and multi-resolution feature maps, respectively. On the MS-COCO dataset, CenterNet with Res2Net-101 and Swin-Transformer achieves APs of 53.7% and 57.1%, respectively, outperforming all existing bottom-up detectors and achieving state-of-the-art. We also design a real-time CenterNet, which achieves a good trade-off between accuracy and speed with an AP of 43.6% at 30.5 FPS. https://github.com/Duankaiwen/PyCenterNet.
Using Active Speaker Faces for Diarization in TV shows
Mar 30, 2022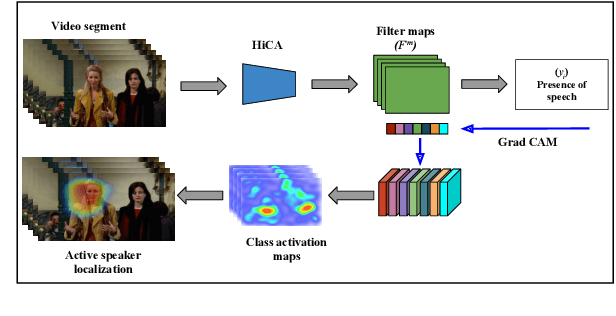
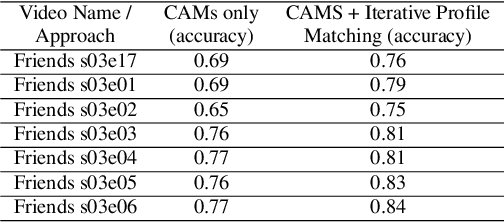
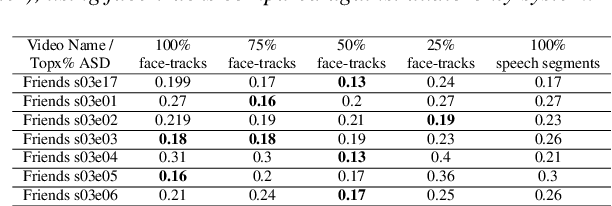
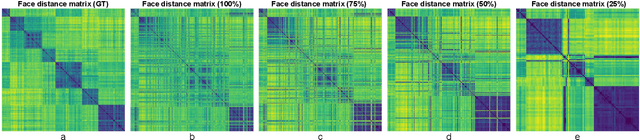
Speaker diarization is one of the critical components of computational media intelligence as it enables a character-level analysis of story portrayals and media content understanding. Automated audio-based speaker diarization of entertainment media poses challenges due to the diverse acoustic conditions present in media content, be it background music, overlapping speakers, or sound effects. At the same time, speaking faces in the visual modality provide complementary information and not prone to the errors seen in the audio modality. In this paper, we address the problem of speaker diarization in TV shows using the active speaker faces. We perform face clustering on the active speaker faces and show superior speaker diarization performance compared to the state-of-the-art audio-based diarization methods. We additionally report a systematic analysis of the impact of active speaker face detection quality on the diarization performance. We also observe that a moderately well-performing active speaker system could outperform the audio-based diarization systems.
Resource Allocation for Multiuser Edge Inference with Batching and Early Exiting (Extended Version)
Apr 11, 2022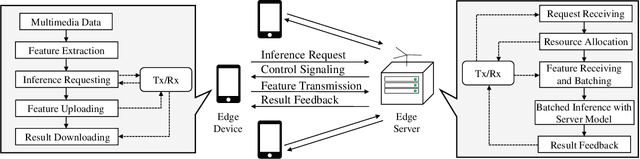

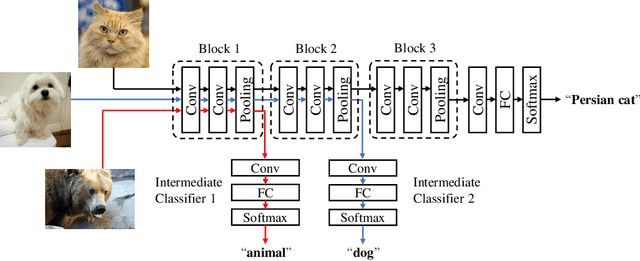
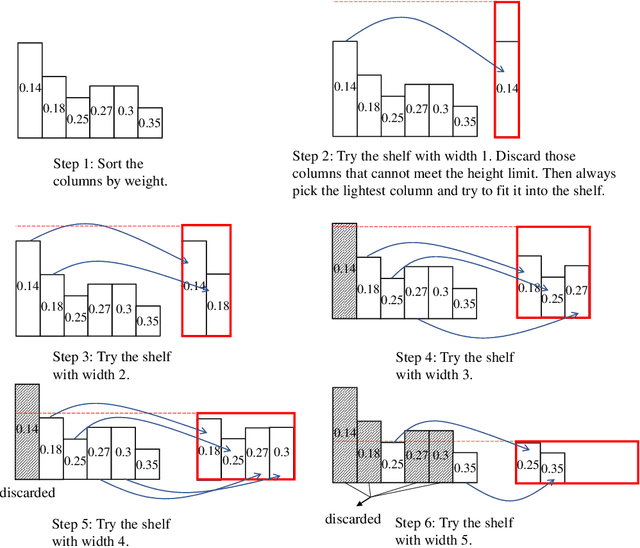
The deployment of inference services at the network edge, called edge inference, offloads computation-intensive inference tasks from mobile devices to edge servers, thereby enhancing the former's capabilities and battery lives. In a multiuser system, the joint allocation of communication-and-computation ($\text{C}^\text{2}$) resources (i.e., scheduling and bandwidth allocation) is made challenging by adopting efficient inference techniques, batching and early exiting, and further complicated by the heterogeneity in users' requirements on accuracy and latency. Batching groups multiple tasks into one batch for parallel processing to reduce time-consuming memory access and thereby boosts the throughput (i.e., completed task per second). On the other hand, early exiting allows a task to exit from a deep-neural network without traversing the whole network to support a tradeoff between accuracy and latency. In this work, we study optimal $\text{C}^\text{2}$ resource allocation with batching and early exiting, which is an NP-complete integer program. A set of efficient algorithms are designed under the criterion of maximum throughput by tackling the challenge. Experimental results demonstrate that both optimal and sub-optimal $\text{C}^\text{2}$ resource allocation algorithms can leverage integrated batching and early exiting to achieve 200% throughput gain over conventional schemes.
TGCN: Time Domain Graph Convolutional Network for Multiple Objects Tracking
Jan 06, 2021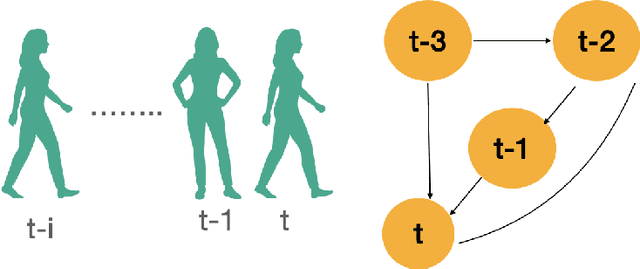

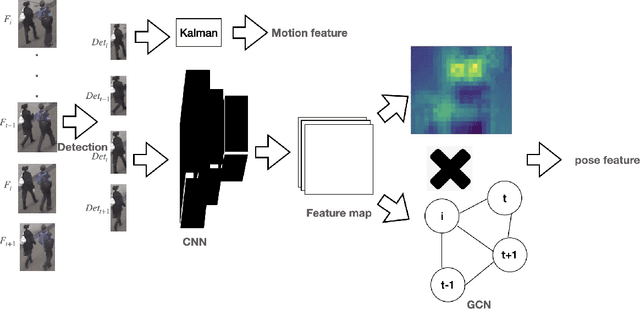

Multiple object tracking is to give each object an id in the video. The difficulty is how to match the predicted objects and detected objects in same frames. Matching features include appearance features, location features, etc. These features of the predicted object are basically based on some previous frames. However, few papers describe the relationship in the time domain between the previous frame features and the current frame features.In this paper, we proposed a time domain graph convolutional network for multiple objects tracking.The model is mainly divided into two parts, we first use convolutional neural network (CNN) to extract pedestrian appearance feature, which is a normal operation processing image in deep learning, then we use GCN to model some past frames' appearance feature to get the prediction appearance feature of the current frame. Due to this extension, we can get the pose features of the current frame according to the relationship between some frames in the past. Experimental evaluation shows that our extensions improve the MOTA by 1.3 on the MOT16, achieving overall competitive performance at high frame rates.
Human vs Objective Evaluation of Colourisation Performance
Apr 11, 2022
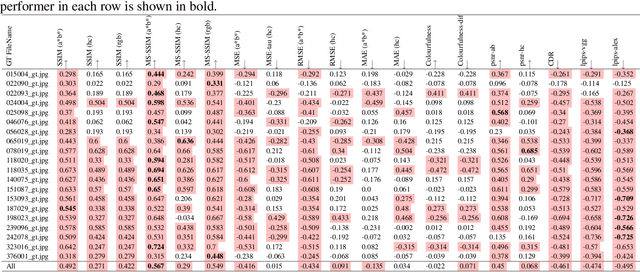
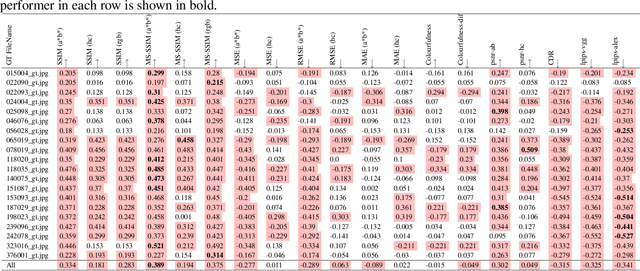
Automatic colourisation of grey-scale images is the process of creating a full-colour image from the grey-scale prior. It is an ill-posed problem, as there are many plausible colourisations for a given grey-scale prior. The current SOTA in auto-colourisation involves image-to-image type Deep Convolutional Neural Networks with Generative Adversarial Networks showing the greatest promise. The end goal of colourisation is to produce full colour images that appear plausible to the human viewer, but human assessment is costly and time consuming. This work assesses how well commonly used objective measures correlate with human opinion. We also attempt to determine what facets of colourisation have the most significant effect on human opinion. For each of 20 images from the BSD dataset, we create 65 recolourisations made up of local and global changes. Opinion scores are then crowd sourced using the Amazon Mechanical Turk and together with the images this forms an extensible dataset called the Human Evaluated Colourisation Dataset (HECD). While we find statistically significant correlations between human-opinion scores and a small number of objective measures, the strength of the correlations is low. There is also evidence that human observers are most intolerant to an incorrect hue of naturally occurring objects.