 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
The self-learning AI controller for adaptive power beaming with fiber-array laser transmitter system
Apr 08, 2022
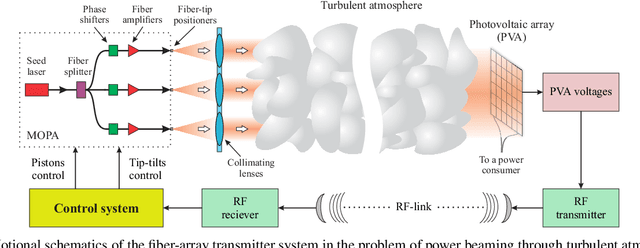
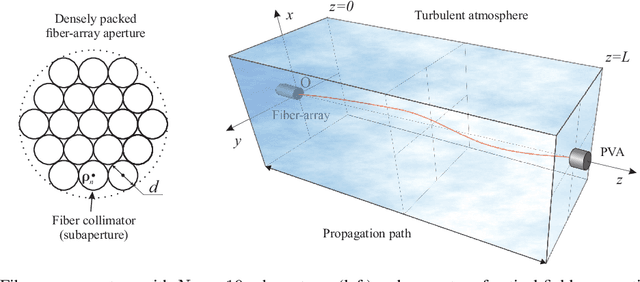
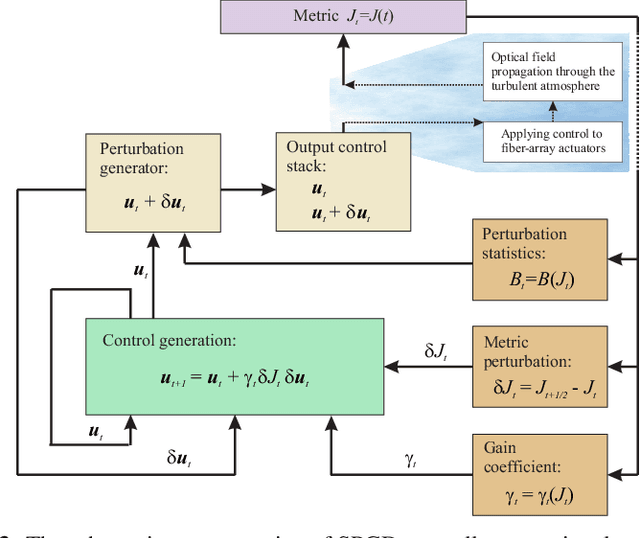
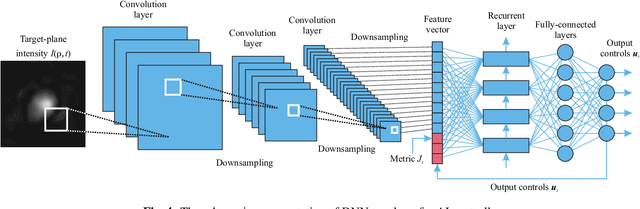
In this study we consider adaptive power beaming with fiber-array laser transmitter system in presence of atmospheric turbulence. For optimization of power transition through the atmosphere fiber-array is traditionally controlled by stochastic parallel gradient descent (SPGD) algorithm where control feedback is provided via radio frequency link by an optical-to-electrical power conversion sensor, attached to a cooperative target. The SPGD algorithm continuously and randomly perturbs voltages applied to fiber-array phase shifters and fiber tip positioners in order to maximize sensor signal, i.e. uses, so-called, "blind" optimization principle. In opposite to this approach a perspective artificially intelligent (AI) control systems for synthesis of optimal control can utilize various pupil- or target-plane data available for the analysis including wavefront sensor data, photo-voltaic array (PVA) data, other optical or atmospheric parameters, and potentially can eliminate well-known drawbacks of SPGD-based controllers. In this study an optimal control is synthesized by a deep neural network (DNN) using target-plane PVA sensor data as its input. A DNN training is occurred online in sync with control system operation and is performed by applying of small perturbations to DNN's outputs. This approach does not require initial DNN's pre-training as well as guarantees optimization of system performance in time. All theoretical results are verified by numerical experiments.
Fast and accurate waveform modeling of long-haul multi-channel optical fiber transmission using a hybrid model-data driven scheme
Jan 18, 2022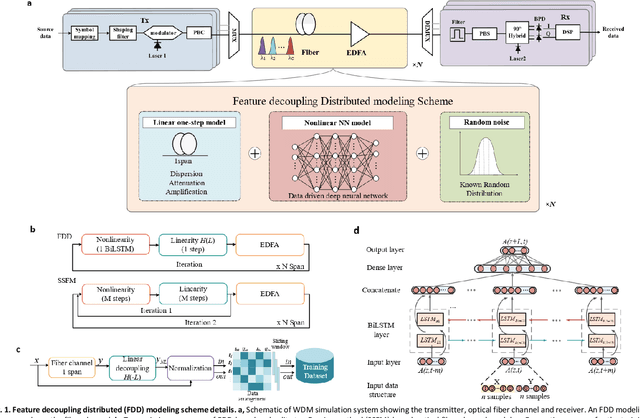
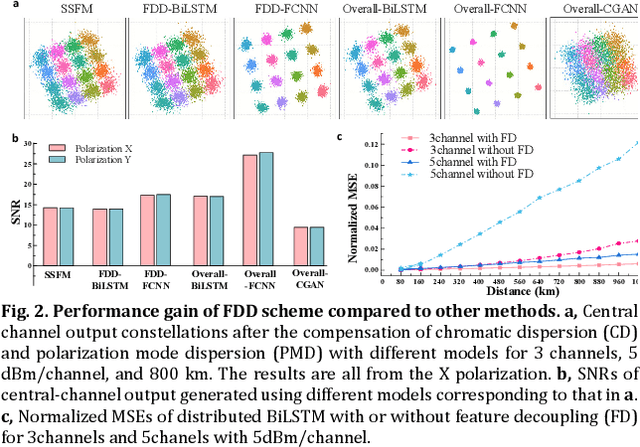
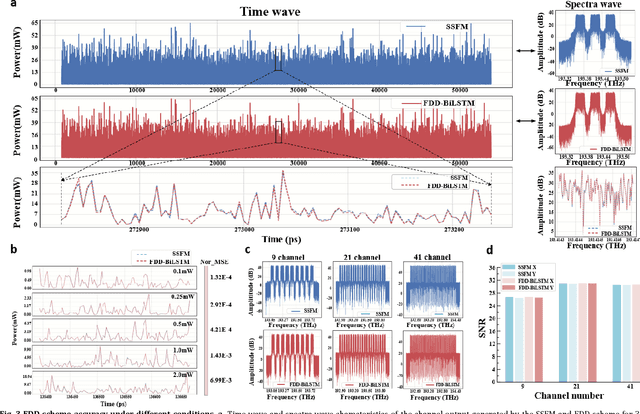
The modeling of optical wave propagation in optical fiber is a task of fast and accurate solving the nonlinear Schr\"odinger equation (NLSE), and can enable the optical system design, digital signal processing verification and fast waveform calculation. Traditional waveform modeling of full-time and full-frequency information is the split-step Fourier method (SSFM), which has long been regarded as challenging in long-haul wavelength division multiplexing (WDM) optical fiber communication systems because it is extremely time-consuming. Here we propose a linear-nonlinear feature decoupling distributed (FDD) waveform modeling scheme to model long-haul WDM fiber channel, where the channel linear effects are modelled by the NLSE-derived model-driven methods and the nonlinear effects are modelled by the data-driven deep learning methods. Meanwhile, the proposed scheme only focuses on one-span fiber distance fitting, and then recursively transmits the model to achieve the required transmission distance. The proposed modeling scheme is demonstrated to have high accuracy, high computing speeds, and robust generalization abilities for different optical launch powers, modulation formats, channel numbers and transmission distances. The total running time of FDD waveform modeling scheme for 41-channel 1040-km fiber transmission is only 3 minutes versus more than 2 hours using SSFM for each input condition, which achieves a 98% reduction in computing time. Considering the multi-round optimization by adjusting system parameters, the complexity reduction is significant. The results represent a remarkable improvement in nonlinear fiber modeling and open up novel perspectives for solution of NLSE-like partial differential equations and optical fiber physics problems.
Improve Sentence Alignment by Divide-and-conquer
Jan 18, 2022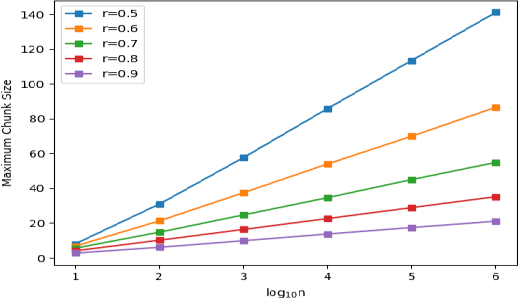
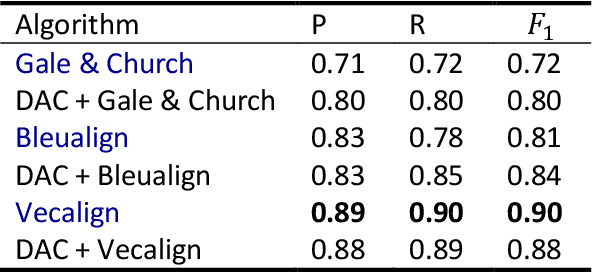
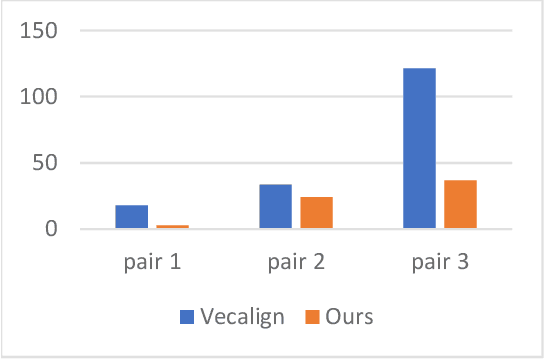
In this paper, we introduce a divide-and-conquer algorithm to improve sentence alignment speed. We utilize external bilingual sentence embeddings to find accurate hard delimiters for the parallel texts to be aligned. We use Monte Carlo simulation to show experimentally that using this divide-and-conquer algorithm, we can turn any quadratic time complexity sentence alignment algorithm into an algorithm with average time complexity of O(NlogN). On a standard OCR-generated dataset, our method improves the Bleualign baseline by 3 F1 points. Besides, when computational resources are restricted, our algorithm is faster than Vecalign in practice.
Sylph: A Hypernetwork Framework for Incremental Few-shot Object Detection
Apr 05, 2022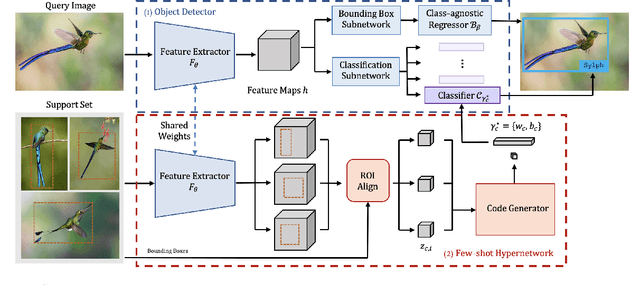

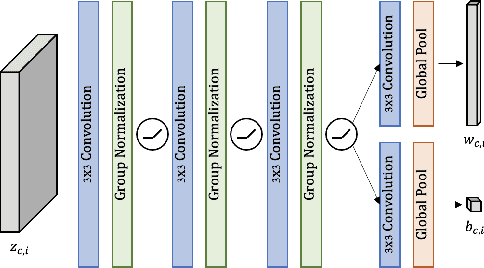
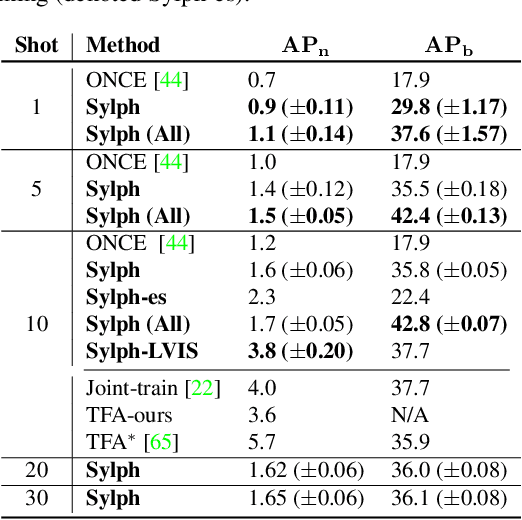
We study the challenging incremental few-shot object detection (iFSD) setting. Recently, hypernetwork-based approaches have been studied in the context of continuous and finetune-free iFSD with limited success. We take a closer look at important design choices of such methods, leading to several key improvements and resulting in a more accurate and flexible framework, which we call Sylph. In particular, we demonstrate the effectiveness of decoupling object classification from localization by leveraging a base detector that is pretrained for class-agnostic localization on a large-scale dataset. Contrary to what previous results have suggested, we show that with a carefully designed class-conditional hypernetwork, finetune-free iFSD can be highly effective, especially when a large number of base categories with abundant data are available for meta-training, almost approaching alternatives that undergo test-time-training. This result is even more significant considering its many practical advantages: (1) incrementally learning new classes in sequence without additional training, (2) detecting both novel and seen classes in a single pass, and (3) no forgetting of previously seen classes. We benchmark our model on both COCO and LVIS, reporting as high as 17% AP on the long-tail rare classes on LVIS, indicating the promise of hypernetwork-based iFSD.
Improving cable network maintenance with machine learning
Mar 09, 2022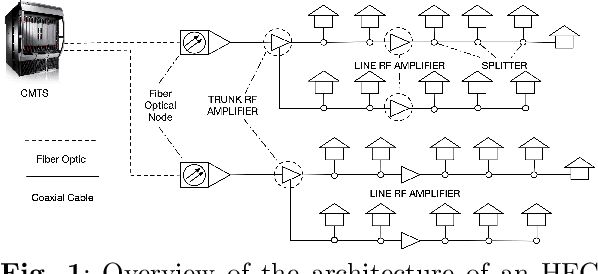
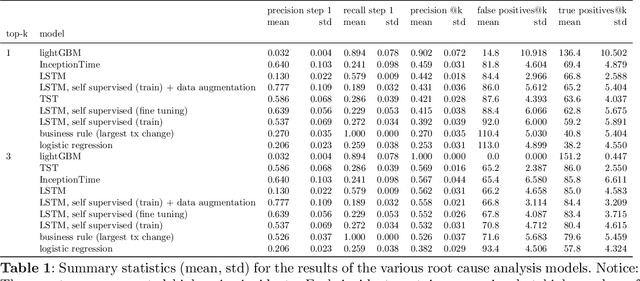
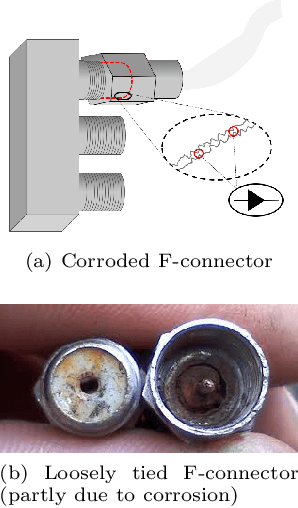
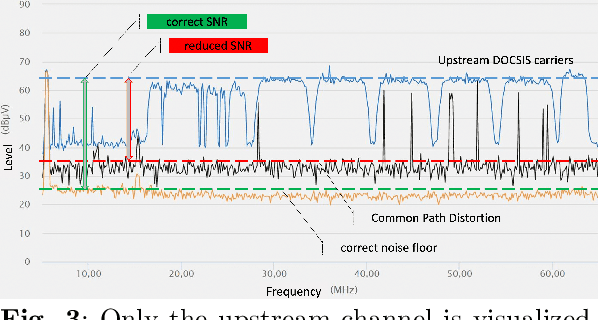
Good quality network connectivity is ever more important. For hybrid fiber coaxial (HFC) networks, searching for upstream \emph{high noise} in the past was cumbersome and time-consuming. Even with machine learning due to the heterogeneity of the network and its topological structure, the task remains challenging. We present the automation of a simple business rule (largest change of a specific value) and compare its performance with state-of-the-art machine-learning methods and conclude that the precision@1 can be improved by 2.3 times. As it is best when a fault does not occur in the first place, we secondly evaluate multiple approaches to forecast network faults, which would allow performing predictive maintenance on the network.
Qualia as physical measurements: a mathematical model of qualia and pure concepts
Mar 20, 2022A space of qualia is defined to be a sober topological space whose points are the qualia and whose open sets are the pure concepts in the sense of Lewis, carrying additional algebraic structure that conveys the conscious experience of subjective time and logical abstraction. This structure is analogous to that of a space of physical measurements. It is conjectured that qualia and measurements have the same nature, corresponding to fundamental processes via which classical information is produced and physically stored, and that therefore the hard problem of consciousness and the measurement problem are two facets of the same problem. The space of qualia is independent from any preexisting notions of spacetime and conscious agent, but its structure caters for a derived geometric model of observer. Intersubjectivity is based on relating different observers in a way that leads to a logical version of quantum superposition.
Search-based Methods for Multi-Cloud Configuration
Apr 20, 2022
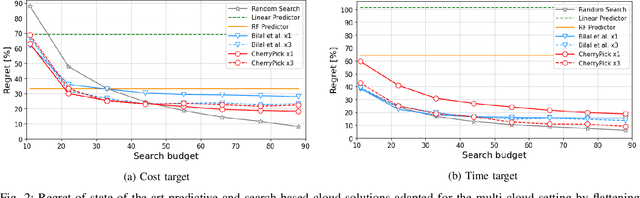
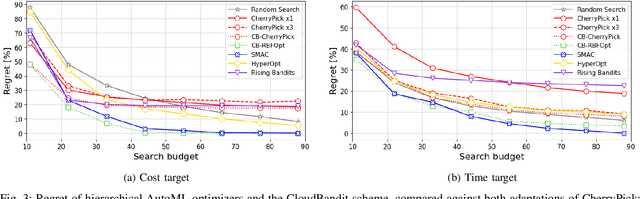
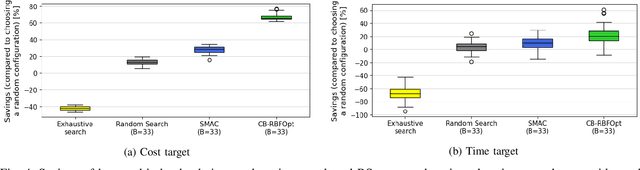
Multi-cloud computing has become increasingly popular with enterprises looking to avoid vendor lock-in. While most cloud providers offer similar functionality, they may differ significantly in terms of performance and/or cost. A customer looking to benefit from such differences will naturally want to solve the multi-cloud configuration problem: given a workload, which cloud provider should be chosen and how should its nodes be configured in order to minimize runtime or cost? In this work, we consider solutions to this optimization problem. We develop and evaluate possible adaptations of state-of-the-art cloud configuration solutions to the multi-cloud domain. Furthermore, we identify an analogy between multi-cloud configuration and the selection-configuration problems commonly studied in the automated machine learning (AutoML) field. Inspired by this connection, we utilize popular optimizers from AutoML to solve multi-cloud configuration. Finally, we propose a new algorithm for solving multi-cloud configuration, CloudBandit (CB). It treats the outer problem of cloud provider selection as a best-arm identification problem, in which each arm pull corresponds to running an arbitrary black-box optimizer on the inner problem of node configuration. Our experiments indicate that (a) many state-of-the-art cloud configuration solutions can be adapted to multi-cloud, with best results obtained for adaptations which utilize the hierarchical structure of the multi-cloud configuration domain, (b) hierarchical methods from AutoML can be used for the multi-cloud configuration task and can outperform state-of-the-art cloud configuration solutions and (c) CB achieves competitive or lower regret relative to other tested algorithms, whilst also identifying configurations that have 65% lower median cost and 20% lower median time in production, compared to choosing a random provider and configuration.
Temporal Latent Auto-Encoder: A Method for Probabilistic Multivariate Time Series Forecasting
Jan 25, 2021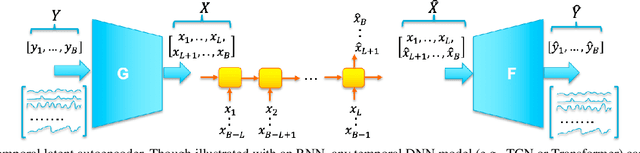
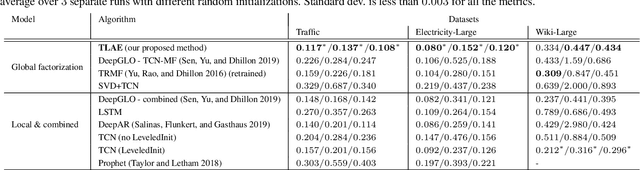
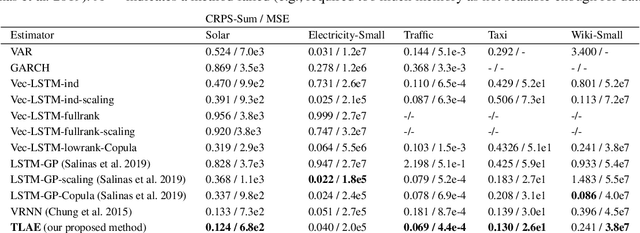
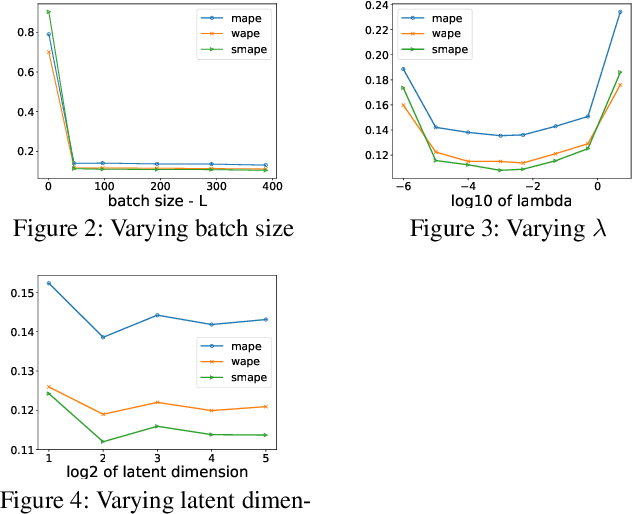
Probabilistic forecasting of high dimensional multivariate time series is a notoriously challenging task, both in terms of computational burden and distribution modeling. Most previous work either makes simple distribution assumptions or abandons modeling cross-series correlations. A promising line of work exploits scalable matrix factorization for latent-space forecasting, but is limited to linear embeddings, unable to model distributions, and not trainable end-to-end when using deep learning forecasting. We introduce a novel temporal latent auto-encoder method which enables nonlinear factorization of multivariate time series, learned end-to-end with a temporal deep learning latent space forecast model. By imposing a probabilistic latent space model, complex distributions of the input series are modeled via the decoder. Extensive experiments demonstrate that our model achieves state-of-the-art performance on many popular multivariate datasets, with gains sometimes as high as $50\%$ for several standard metrics.
TAnoGAN: Time Series Anomaly Detection with Generative Adversarial Networks
Aug 21, 2020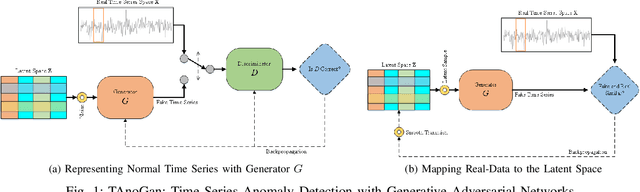
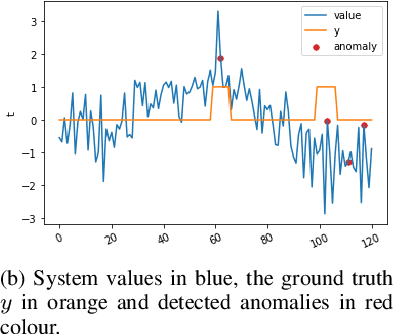
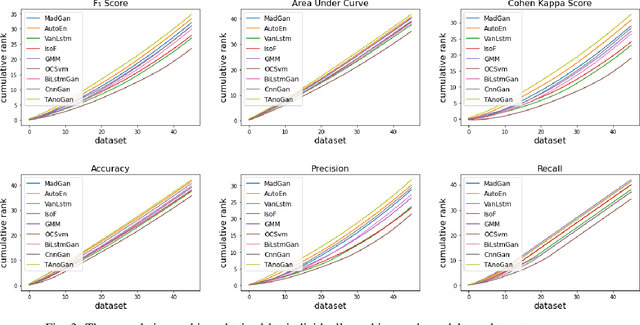
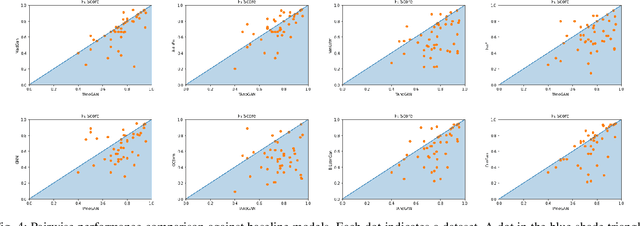
Anomaly detection in time series data is a significant problem faced in many application areas. Recently, Generative Adversarial Networks (GAN) have gained attention for generation and anomaly detection in image domain. In this paper, we propose a novel GAN-based unsupervised method called TAnoGan for detecting anomalies in time series when a small number of data points are available. We evaluate TAnoGan with 46 real-world time series datasets that cover a variety of domains. Extensive experimental results show that TAnoGan performs better than traditional and neural network models.
Near Real-Time Social Distancing in London
Dec 07, 2020
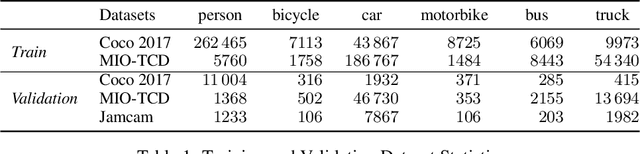
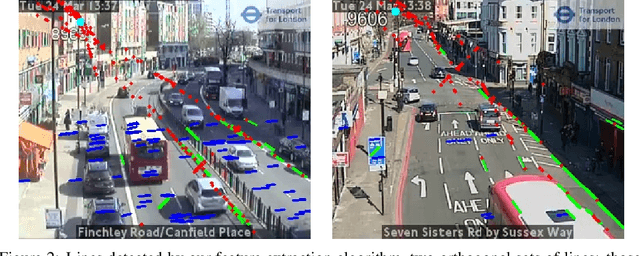
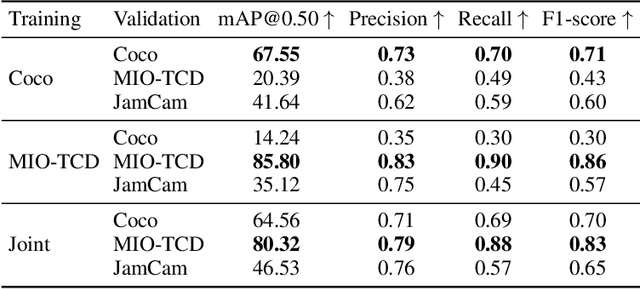
During the COVID-19 pandemic, policy makers at the Greater London Authority, the regional governance body of London, UK, are reliant upon prompt and accurate data sources. Large well-defined heterogeneous compositions of activity throughout the city are sometimes difficult to acquire, yet are a necessity in order to learn 'busyness' and consequently make safe policy decisions. One component of our project within this space is to utilise existing infrastructure to estimate social distancing adherence by the general public. Our method enables near immediate sampling and contextualisation of activity and physical distancing on the streets of London via live traffic camera feeds. We introduce a framework for inspecting and improving upon existing methods, whilst also describing its active deployment on over 900 real-time feeds.