 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Consistency driven Sequential Transformers Attention Model for Partially Observable Scenes
Apr 01, 2022
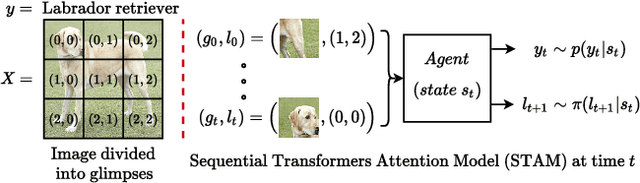
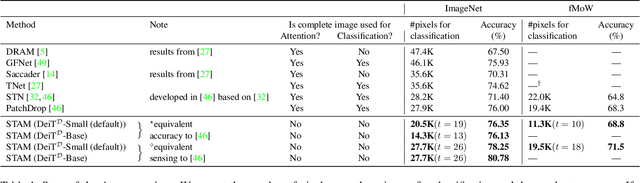
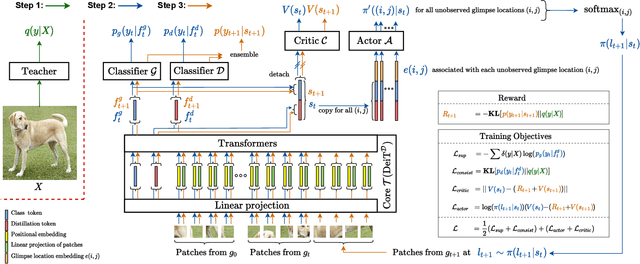
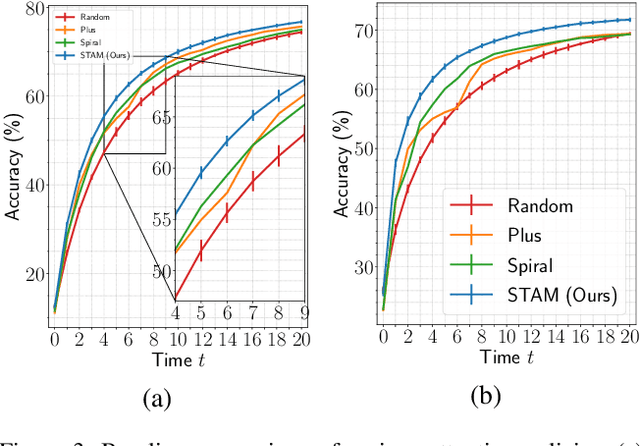
Most hard attention models initially observe a complete scene to locate and sense informative glimpses, and predict class-label of a scene based on glimpses. However, in many applications (e.g., aerial imaging), observing an entire scene is not always feasible due to the limited time and resources available for acquisition. In this paper, we develop a Sequential Transformers Attention Model (STAM) that only partially observes a complete image and predicts informative glimpse locations solely based on past glimpses. We design our agent using DeiT-distilled and train it with a one-step actor-critic algorithm. Furthermore, to improve classification performance, we introduce a novel training objective, which enforces consistency between the class distribution predicted by a teacher model from a complete image and the class distribution predicted by our agent using glimpses. When the agent senses only 4% of the total image area, the inclusion of the proposed consistency loss in our training objective yields 3% and 8% higher accuracy on ImageNet and fMoW datasets, respectively. Moreover, our agent outperforms previous state-of-the-art by observing nearly 27% and 42% fewer pixels in glimpses on ImageNet and fMoW.
A Systematic Study and Analysis of Bengali Folklore with Natural Language Processing Systems
Mar 13, 2022



Folklore, a solid branch of folk literature, is the hallmark of any nation or any society. Such as oral tradition; as proverbs or jokes, it also includes material culture as well as traditional folk beliefs, and various customs. Bengali folklore is as rich in-depth as it is amazing. Nevertheless, in the womb of time, it is determined to sustain its existence. Therefore, our aim in this study is to make our rich folklore more comprehensible to everyone in a more sophisticated computational way. Some studies concluded various aspects of the Bengali language with NLP. Our proposed model is to be specific for Bengali folklore. Technically, it will be the first step towards Bengali natural language processing for studying and analyzing the folklore of Bengal.
Do We Actually Need Dense Over-Parameterization? In-Time Over-Parameterization in Sparse Training
Feb 13, 2021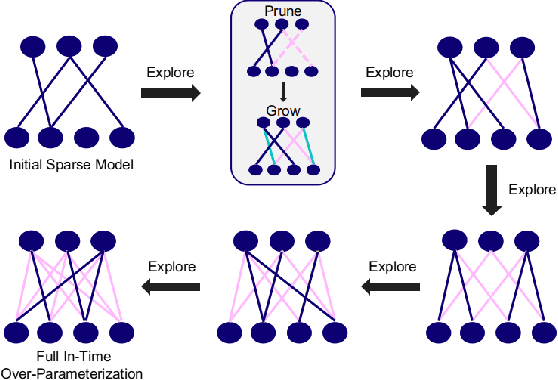
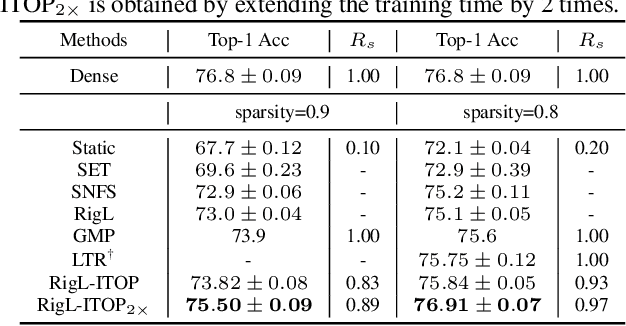
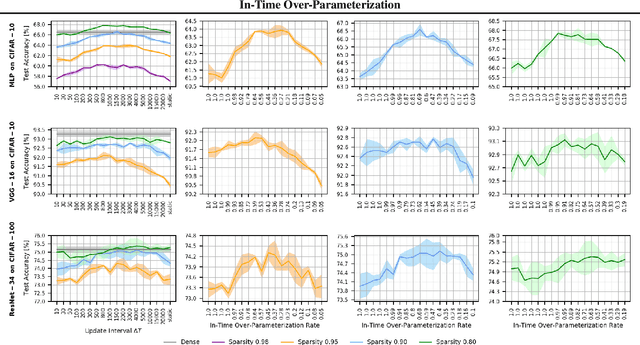

In this paper, we introduce a new perspective on training deep neural networks capable of state-of-the-art performance without the need for the expensive over-parameterization by proposing the concept of In-Time Over-Parameterization (ITOP) in sparse training. By starting from a random sparse network and continuously exploring sparse connectivities during training, we can perform an Over-Parameterization in the space-time manifold, closing the gap in the expressibility between sparse training and dense training. We further use ITOP to understand the underlying mechanism of Dynamic Sparse Training (DST) and indicate that the benefits of DST come from its ability to consider across time all possible parameters when searching for the optimal sparse connectivity. As long as there are sufficient parameters that have been reliably explored during training, DST can outperform the dense neural network by a large margin. We present a series of experiments to support our conjecture and achieve the state-of-the-art sparse training performance with ResNet-50 on ImageNet. More impressively, our method achieves dominant performance over the overparameterization-based sparse methods at extreme sparsity levels. When trained on CIFAR-100, our method can match the performance of the dense model even at an extreme sparsity (98%).
Handling Variable-Dimensional Time Series with Graph Neural Networks
Jul 07, 2020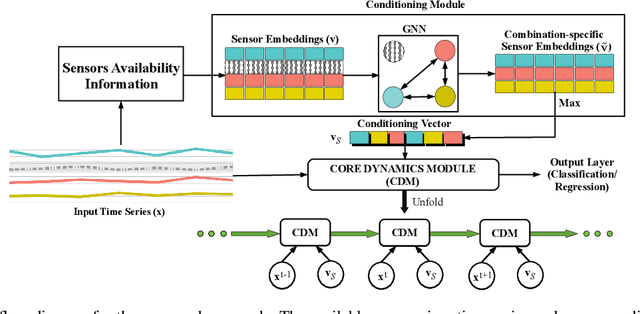
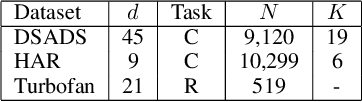
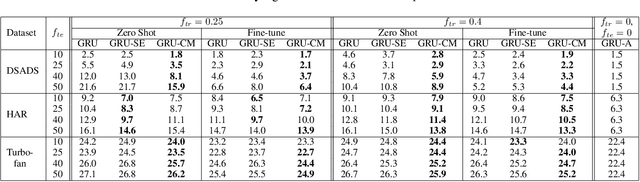
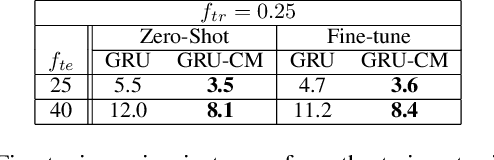
Several applications of Internet of Things (IoT) technology involve capturing data from multiple sensors resulting in multi-sensor time series. Existing neural networks based approaches for such multi-sensor or multivariate time series modeling assume fixed input dimension or number of sensors. Such approaches can struggle in the practical setting where different instances of the same device or equipment such as mobiles, wearables, engines, etc. come with different combinations of installed sensors. We consider training neural network models from such multi-sensor time series, where the time series have varying input dimensionality owing to availability or installation of a different subset of sensors at each source of time series. We propose a novel neural network architecture suitable for zero-shot transfer learning allowing robust inference for multivariate time series with previously unseen combination of available dimensions or sensors at test time. Such a combinatorial generalization is achieved by conditioning the layers of a core neural network-based time series model with a "conditioning vector" that carries information of the available combination of sensors for each time series. This conditioning vector is obtained by summarizing the set of learned "sensor embedding vectors" corresponding to the available sensors in a time series via a graph neural network. We evaluate the proposed approach on publicly available activity recognition and equipment prognostics datasets, and show that the proposed approach allows for better generalization in comparison to a deep gated recurrent neural network baseline.
Designing Interference-Immune Doppler-TolerantWaveforms for Automotive Radar Applications
Apr 05, 2022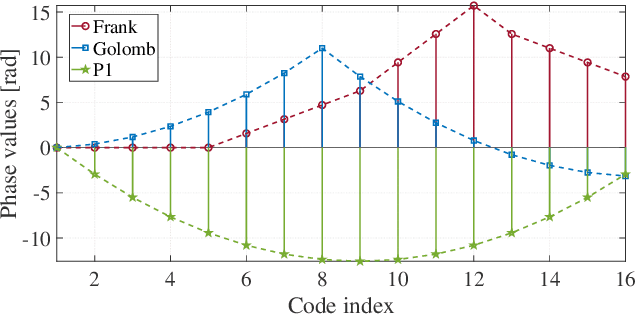
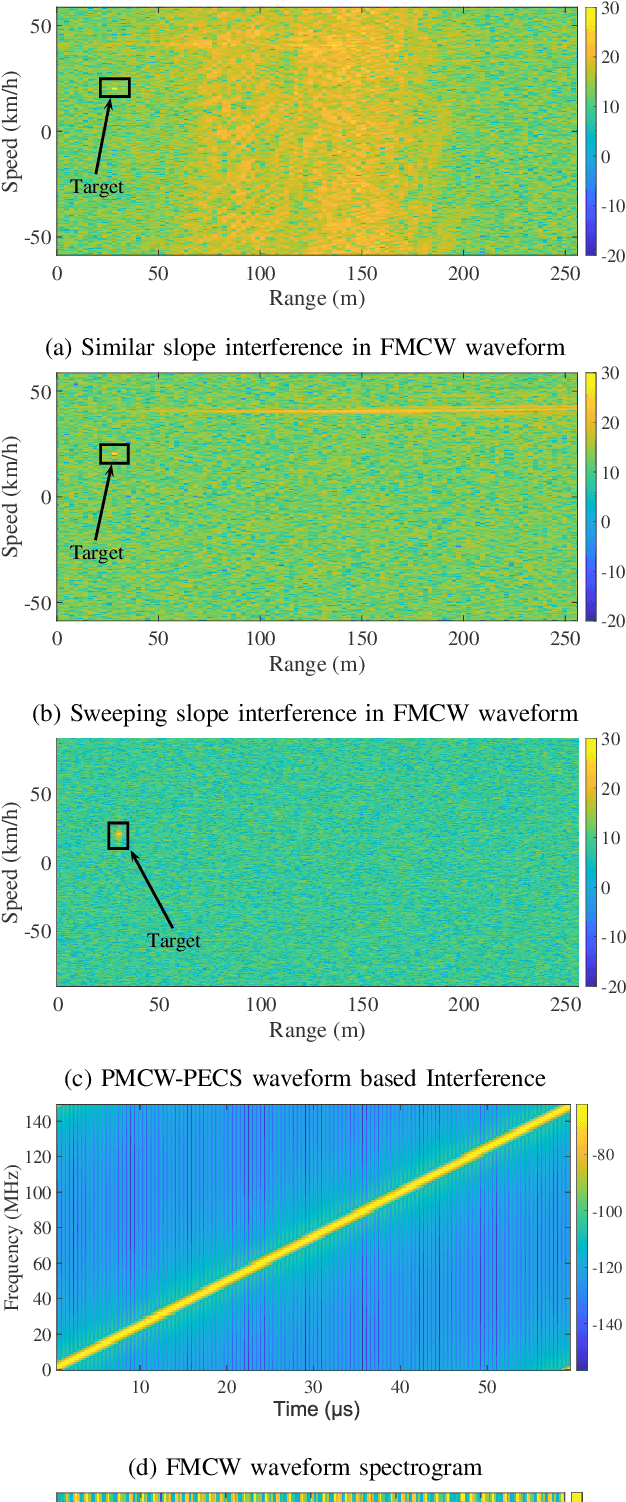
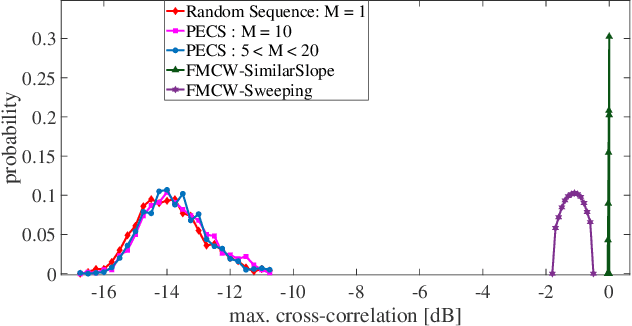
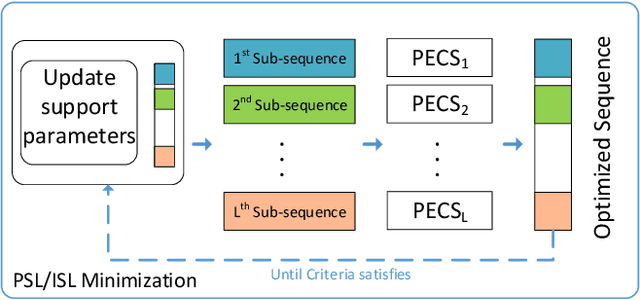
Dynamic target detection using FMCW waveform is challenging in the presence of interference for different radar applications. Degradation in SNR is irreparable and interference is difficult to mitigate in time and frequency domain. In this paper, a waveform design problem is addressed using the Majorization-Minimization (MM) framework by considering PSL/ISL cost functions, resulting in a code sequence with Doppler-tolerance characteristics of an FMCW waveform and interference immune characteristics of a tailored PMCW waveform (unique phase code + minimal ISL/PSL). The optimal design sequences possess polynomial phase behavior of degree Q amongst its sub-sequences and obtain optimal ISL and PSL solutions with guaranteed convergence. By tuning the optimization parameters such as degree Q of the polynomial phase behavior, sub-sequence length M and the total number of sub-sequences L, the optimized sequences can be as Doppler tolerant as FMCW waveform in one end, and they can possess small cross-correlation values similar to random-phase sequences in PMCW waveform on the other end. If required in the event of acute interference, new codes can be generated in the runtime which have low cross-correlation with the interferers. The performance analysis indicates that the proposed method outperforms the state-of-the-art counterparts.
Unsupervised domain adaptation and super resolution on drone images for autonomous dry herbage biomass estimation
Apr 18, 2022
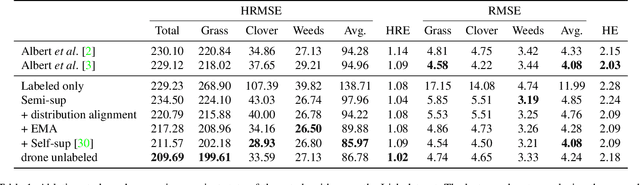

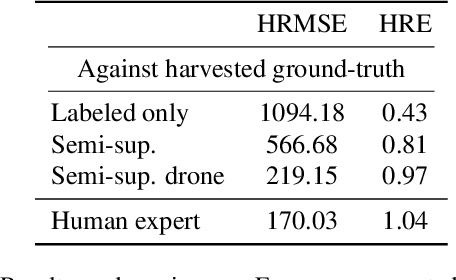
Herbage mass yield and composition estimation is an important tool for dairy farmers to ensure an adequate supply of high quality herbage for grazing and subsequently milk production. By accurately estimating herbage mass and composition, targeted nitrogen fertiliser application strategies can be deployed to improve localised regions in a herbage field, effectively reducing the negative impacts of over-fertilization on biodiversity and the environment. In this context, deep learning algorithms offer a tempting alternative to the usual means of sward composition estimation, which involves the destructive process of cutting a sample from the herbage field and sorting by hand all plant species in the herbage. The process is labour intensive and time consuming and so not utilised by farmers. Deep learning has been successfully applied in this context on images collected by high-resolution cameras on the ground. Moving the deep learning solution to drone imaging, however, has the potential to further improve the herbage mass yield and composition estimation task by extending the ground-level estimation to the large surfaces occupied by fields/paddocks. Drone images come at the cost of lower resolution views of the fields taken from a high altitude and requires further herbage ground-truth collection from the large surfaces covered by drone images. This paper proposes to transfer knowledge learned on ground-level images to raw drone images in an unsupervised manner. To do so, we use unpaired image style translation to enhance the resolution of drone images by a factor of eight and modify them to appear closer to their ground-level counterparts. We then ... ~\url{www.github.com/PaulAlbert31/Clover_SSL}.
Self-adjusting Population Sizes for the $(1, λ)$-EA on Monotone Functions
Apr 01, 2022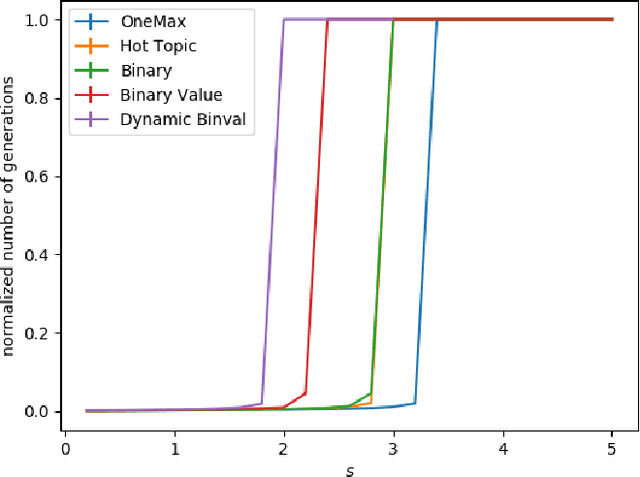
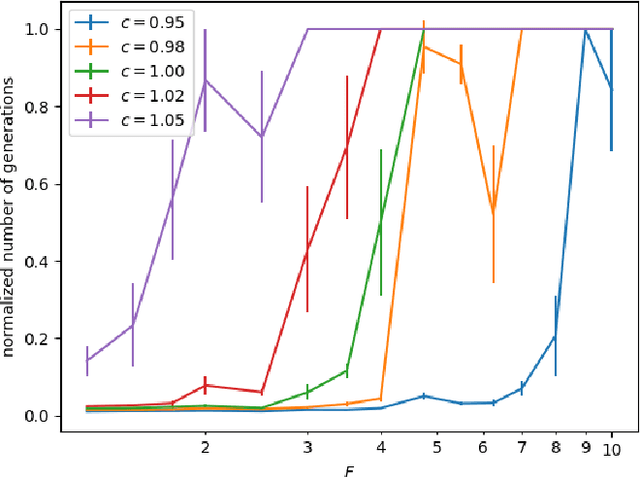
We study the $(1,\lambda)$-EA with mutation rate $c/n$ for $c\le 1$, where the population size is adaptively controlled with the $(1:s+1)$-success rule. Recently, Hevia Fajardo and Sudholt have shown that this setup with $c=1$ is efficient on \onemax for $s<1$, but inefficient if $s \ge 18$. Surprisingly, the hardest part is not close to the optimum, but rather at linear distance. We show that this behavior is not specific to \onemax. If $s$ is small, then the algorithm is efficient on all monotone functions, and if $s$ is large, then it needs superpolynomial time on all monotone functions. In the former case, for $c<1$ we show a $O(n)$ upper bound for the number of generations and $O(n\log n)$ for the number of function evaluations, and for $c=1$ we show $O(n\log n)$ generations and $O(n^2\log\log n)$ evaluations. We also show formally that optimization is always fast, regardless of $s$, if the algorithm starts in proximity of the optimum. All results also hold in a dynamic environment where the fitness function changes in each generation.
Longitudinal Self-Supervision for COVID-19 Pathology Quantification
Mar 21, 2022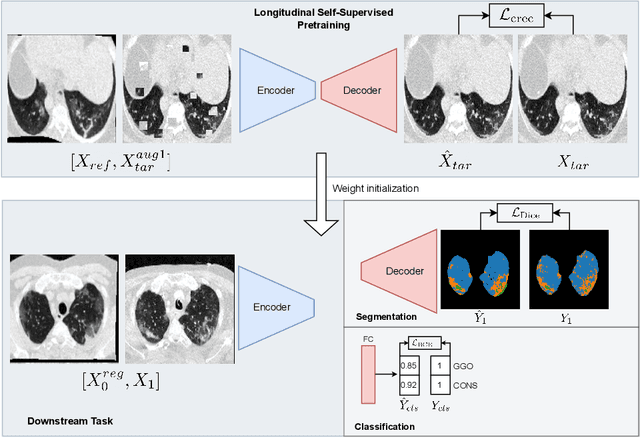
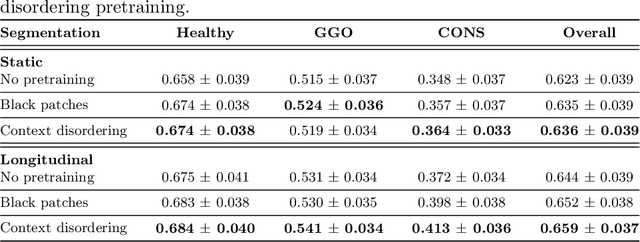
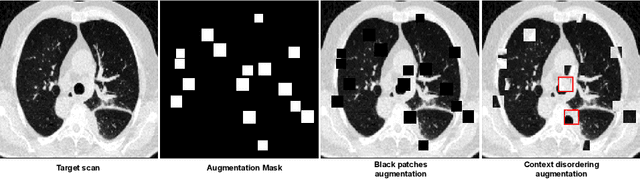

Quantifying COVID-19 infection over time is an important task to manage the hospitalization of patients during a global pandemic. Recently, deep learning-based approaches have been proposed to help radiologists automatically quantify COVID-19 pathologies on longitudinal CT scans. However, the learning process of deep learning methods demands extensive training data to learn the complex characteristics of infected regions over longitudinal scans. It is challenging to collect a large-scale dataset, especially for longitudinal training. In this study, we want to address this problem by proposing a new self-supervised learning method to effectively train longitudinal networks for the quantification of COVID-19 infections. For this purpose, longitudinal self-supervision schemes are explored on clinical longitudinal COVID-19 CT scans. Experimental results show that the proposed method is effective, helping the model better exploit the semantics of longitudinal data and improve two COVID-19 quantification tasks.
Probabilistic Time Series Forecasting with Structured Shape and Temporal Diversity
Oct 14, 2020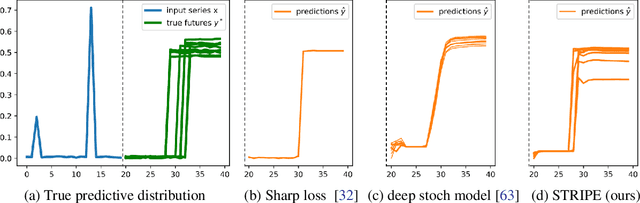
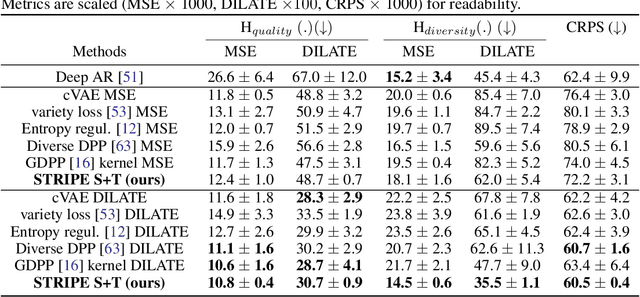
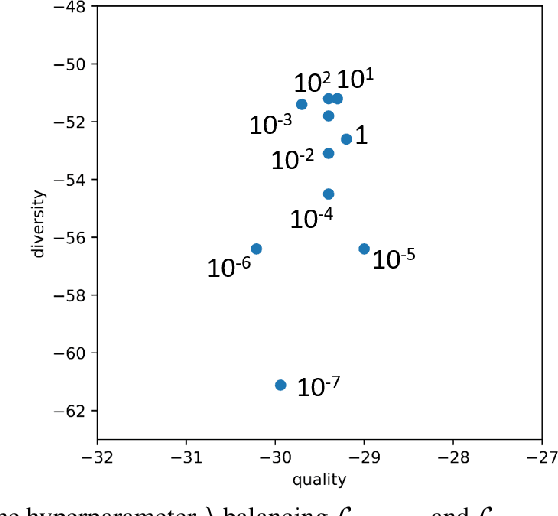

Probabilistic forecasting consists in predicting a distribution of possible future outcomes. In this paper, we address this problem for non-stationary time series, which is very challenging yet crucially important. We introduce the STRIPE model for representing structured diversity based on shape and time features, ensuring both probable predictions while being sharp and accurate. STRIPE is agnostic to the forecasting model, and we equip it with a diversification mechanism relying on determinantal point processes (DPP). We introduce two DPP kernels for modeling diverse trajectories in terms of shape and time, which are both differentiable and proved to be positive semi-definite. To have an explicit control on the diversity structure, we also design an iterative sampling mechanism to disentangle shape and time representations in the latent space. Experiments carried out on synthetic datasets show that STRIPE significantly outperforms baseline methods for representing diversity, while maintaining accuracy of the forecasting model. We also highlight the relevance of the iterative sampling scheme and the importance to use different criteria for measuring quality and diversity. Finally, experiments on real datasets illustrate that STRIPE is able to outperform state-of-the-art probabilistic forecasting approaches in the best sample prediction.
The SKIM-FA Kernel: High-Dimensional Variable Selection and Nonlinear Interaction Discovery in Linear Time
Jun 23, 2021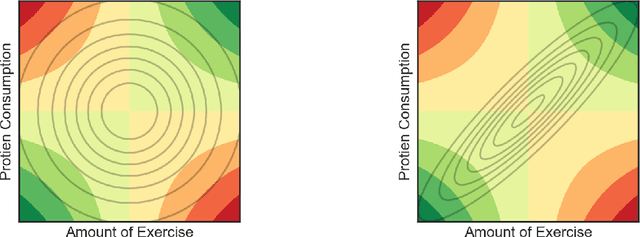
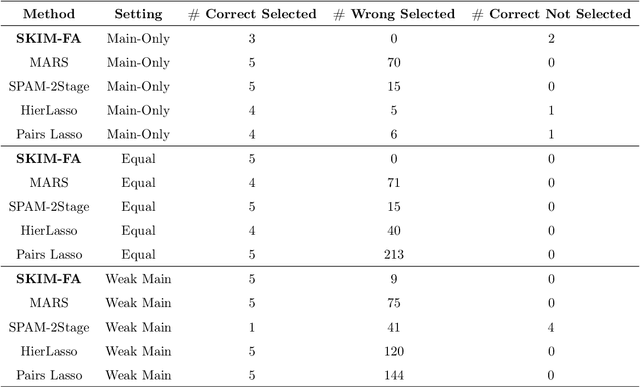
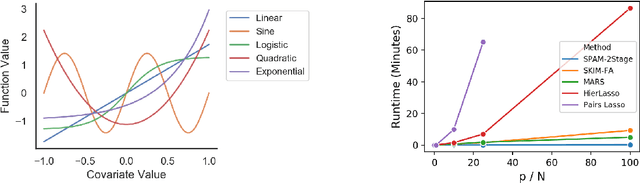
Many scientific problems require identifying a small set of covariates that are associated with a target response and estimating their effects. Often, these effects are nonlinear and include interactions, so linear and additive methods can lead to poor estimation and variable selection. The Bayesian framework makes it straightforward to simultaneously express sparsity, nonlinearity, and interactions in a hierarchical model. But, as for the few other methods that handle this trifecta, inference is computationally intractable - with runtime at least quadratic in the number of covariates, and often worse. In the present work, we solve this computational bottleneck. We first show that suitable Bayesian models can be represented as Gaussian processes (GPs). We then demonstrate how a kernel trick can reduce computation with these GPs to O(# covariates) time for both variable selection and estimation. Our resulting fit corresponds to a sparse orthogonal decomposition of the regression function in a Hilbert space (i.e., a functional ANOVA decomposition), where interaction effects represent all variation that cannot be explained by lower-order effects. On a variety of synthetic and real datasets, our approach outperforms existing methods used for large, high-dimensional datasets while remaining competitive (or being orders of magnitude faster) in runtime.