 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
HDR Environment Map Estimation for Real-Time Augmented Reality
Nov 21, 2020
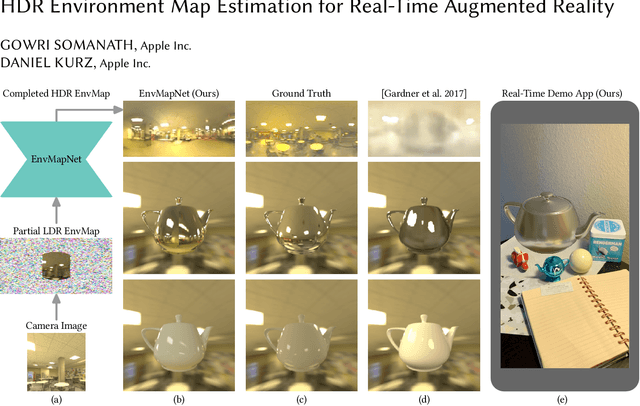

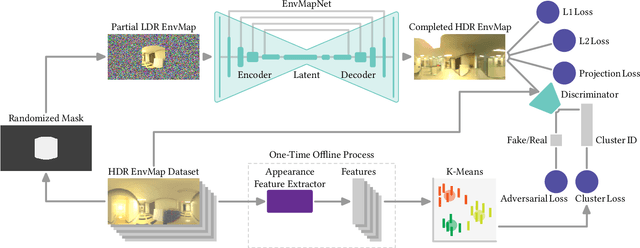

We present a method to estimate an HDR environment map from a narrow field-of-view LDR camera image in real-time. This enables perceptually appealing reflections and shading on virtual objects of any material finish, from mirror to diffuse, rendered into a real physical environment using augmented reality. Our method is based on our efficient convolutional neural network architecture, EnvMapNet, trained end-to-end with two novel losses, ProjectionLoss for the generated image, and ClusterLoss for adversarial training. Through qualitative and quantitative comparison to state-of-the-art methods, we demonstrate that our algorithm reduces the directional error of estimated light sources by more than 50%, and achieves 3.7 times lower Frechet Inception Distance (FID). We further showcase a mobile application that is able to run our neural network model in under 9 ms on an iPhone XS, and render in real-time, visually coherent virtual objects in previously unseen real-world environments.
IOP-FL: Inside-Outside Personalization for Federated Medical Image Segmentation
Apr 16, 2022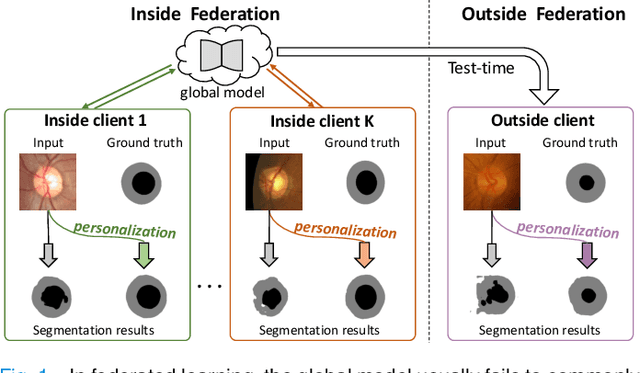
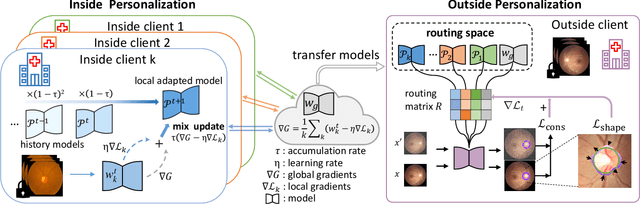
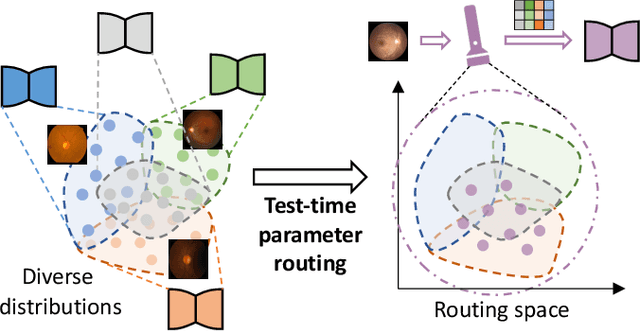
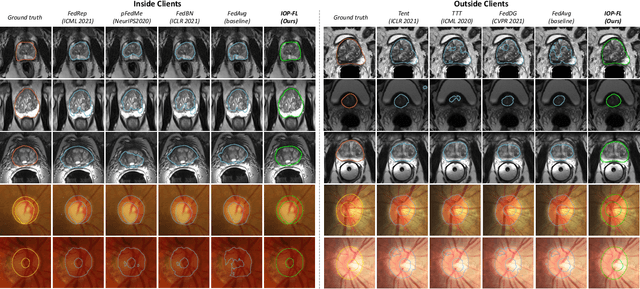
Federated learning (FL) allows multiple medical institutions to collaboratively learn a global model without centralizing all clients data. It is difficult, if possible at all, for such a global model to commonly achieve optimal performance for each individual client, due to the heterogeneity of medical data from various scanners and patient demographics. This problem becomes even more significant when deploying the global model to unseen clients outside the FL with new distributions not presented during federated training. To optimize the prediction accuracy of each individual client for critical medical tasks, we propose a novel unified framework for both Inside and Outside model Personalization in FL (IOP-FL). Our inside personalization is achieved by a lightweight gradient-based approach that exploits the local adapted model for each client, by accumulating both the global gradients for common knowledge and local gradients for client-specific optimization. Moreover, and importantly, the obtained local personalized models and the global model can form a diverse and informative routing space to personalize a new model for outside FL clients. Hence, we design a new test-time routing scheme inspired by the consistency loss with a shape constraint to dynamically incorporate the models, given the distribution information conveyed by the test data. Our extensive experimental results on two medical image segmentation tasks present significant improvements over SOTA methods on both inside and outside personalization, demonstrating the great potential of our IOP-FL scheme for clinical practice. Code will be released at https://github.com/med-air/IOP-FL.
MIMO-GAN: Generative MIMO Channel Modeling
Mar 16, 2022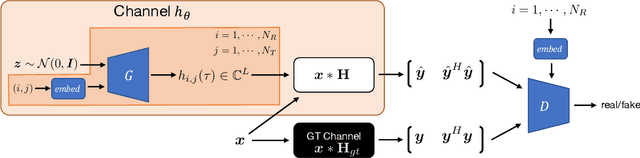
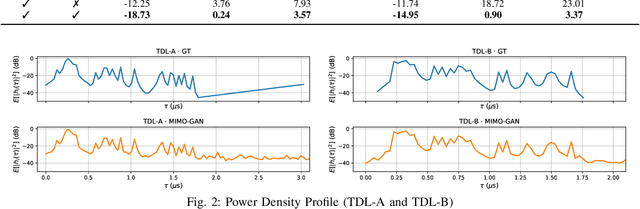
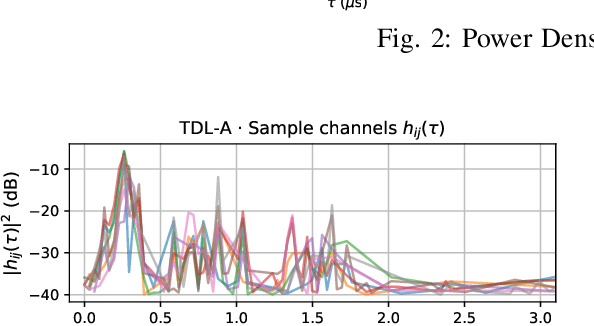
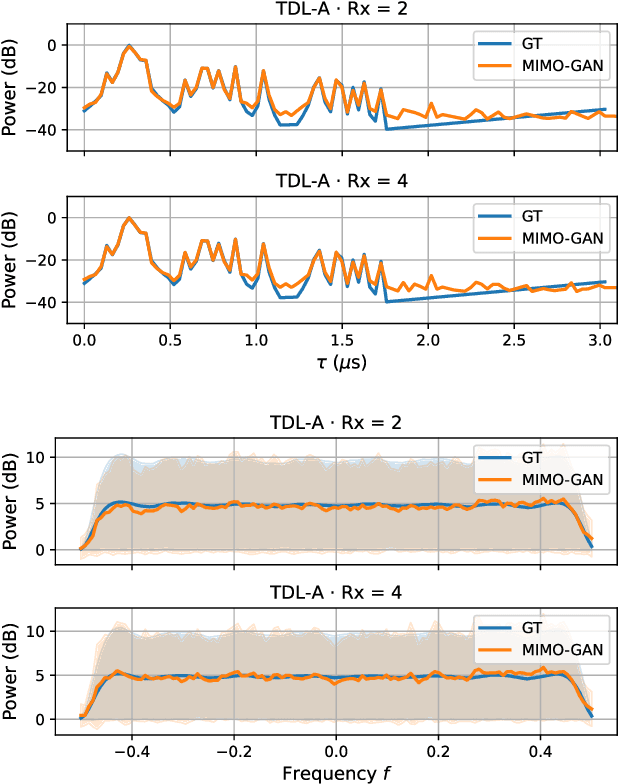
We propose generative channel modeling to learn statistical channel models from channel input-output measurements. Generative channel models can learn more complicated distributions and represent the field data more faithfully. They are tractable and easy to sample from, which can potentially speed up the simulation rounds. To achieve this, we leverage advances in GAN, which helps us learn an implicit distribution over stochastic MIMO channels from observed measurements. In particular, our approach MIMO-GAN implicitly models the wireless channel as a distribution of time-domain band-limited impulse responses. We evaluate MIMO-GAN on 3GPP TDL MIMO channels and observe high-consistency in capturing power, delay and spatial correlation statistics of the underlying channel. In particular, we observe MIMO-GAN achieve errors of under 3.57 ns average delay and -18.7 dB power.
WarpingGAN: Warping Multiple Uniform Priors for Adversarial 3D Point Cloud Generation
Mar 24, 2022We propose WarpingGAN, an effective and efficient 3D point cloud generation network. Unlike existing methods that generate point clouds by directly learning the mapping functions between latent codes and 3D shapes, Warping-GAN learns a unified local-warping function to warp multiple identical pre-defined priors (i.e., sets of points uniformly distributed on regular 3D grids) into 3D shapes driven by local structure-aware semantics. In addition, we also ingeniously utilize the principle of the discriminator and tailor a stitching loss to eliminate the gaps between different partitions of a generated shape corresponding to different priors for boosting quality. Owing to the novel generating mechanism, WarpingGAN, a single lightweight network after one-time training, is capable of efficiently generating uniformly distributed 3D point clouds with various resolutions. Extensive experimental results demonstrate the superiority of our WarpingGAN over state-of-the-art methods in terms of quantitative metrics, visual quality, and efficiency. The source code is publicly available at https://github.com/yztang4/WarpingGAN.git.
SSGCNet: A Sparse Spectra Graph Convolutional Network for Epileptic EEG Signal Classification
Mar 24, 2022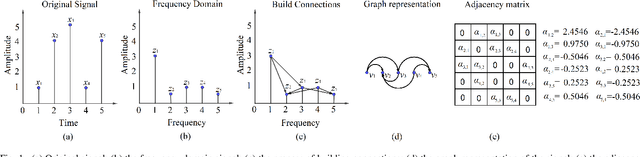
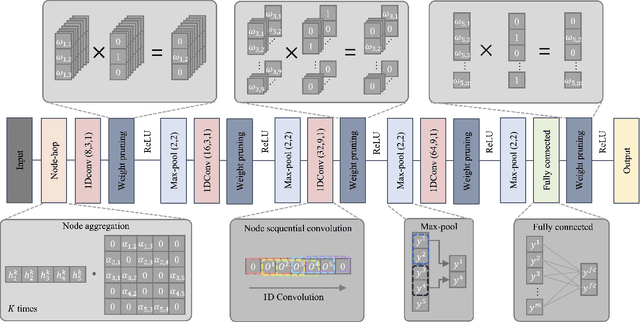
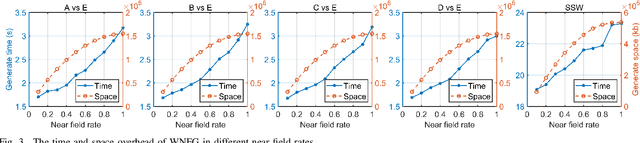
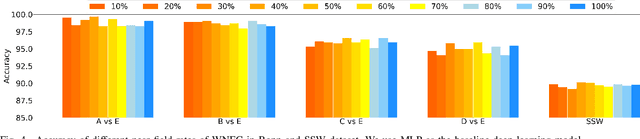
In this article, we propose a sparse spectra graph convolutional network (SSGCNet) for solving Epileptic EEG signal classification problems. The aim is to achieve a lightweight deep learning model without losing model classification accuracy. We propose a weighted neighborhood field graph (WNFG) to represent EEG signals, which reduces the redundant edges between graph nodes. WNFG has lower time complexity and memory usage than the conventional solutions. Using the graph representation, the sequential graph convolutional network is based on a combination of sparse weight pruning technique and the alternating direction method of multipliers (ADMM). Our approach can reduce computation complexity without effect on classification accuracy. We also present convergence results for the proposed approach. The performance of the approach is illustrated in public and clinical-real datasets. Compared with the existing literature, our WNFG of EEG signals achieves up to 10 times of redundant edge reduction, and our approach achieves up to 97 times of model pruning without loss of classification accuracy.
Privileged Attribution Constrained Deep Networks for Facial Expression Recognition
Mar 24, 2022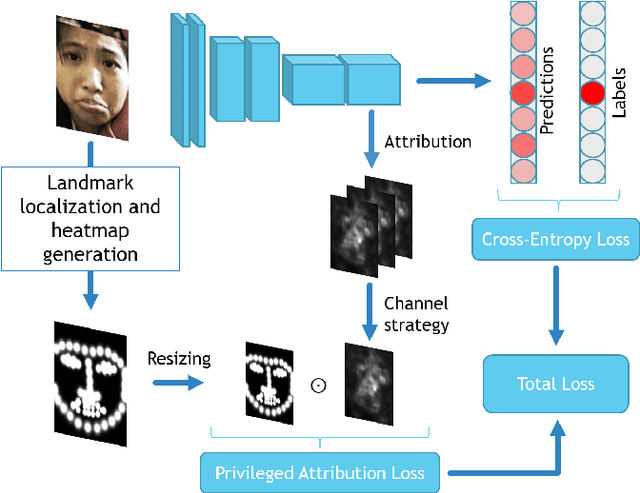

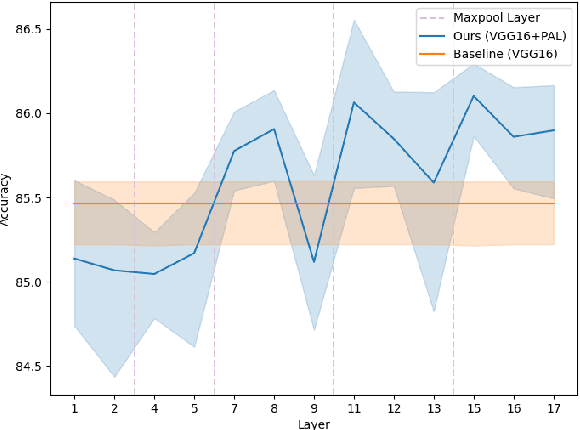
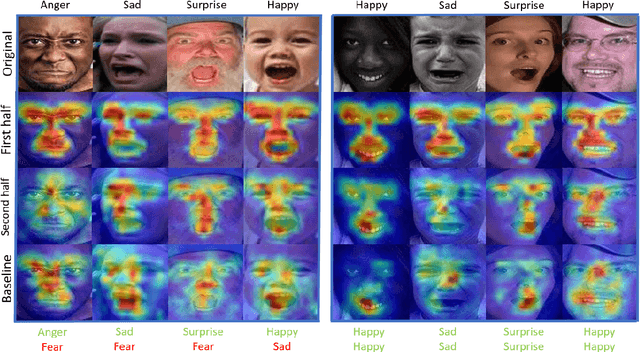
Facial Expression Recognition (FER) is crucial in many research domains because it enables machines to better understand human behaviours. FER methods face the problems of relatively small datasets and noisy data that don't allow classical networks to generalize well. To alleviate these issues, we guide the model to concentrate on specific facial areas like the eyes, the mouth or the eyebrows, which we argue are decisive to recognise facial expressions. We propose the Privileged Attribution Loss (PAL), a method that directs the attention of the model towards the most salient facial regions by encouraging its attribution maps to correspond to a heatmap formed by facial landmarks. Furthermore, we introduce several channel strategies that allow the model to have more degrees of freedom. The proposed method is independent of the backbone architecture and doesn't need additional semantic information at test time. Finally, experimental results show that the proposed PAL method outperforms current state-of-the-art methods on both RAF-DB and AffectNet.
Metaphorical User Simulators for Evaluating Task-oriented Dialogue Systems
Apr 06, 2022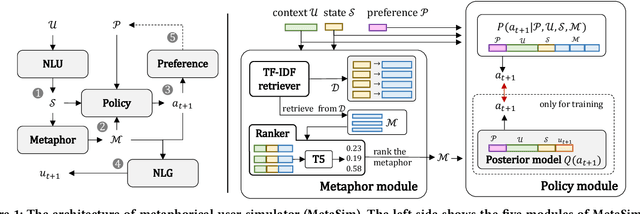
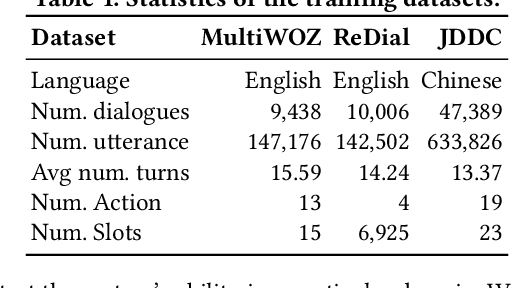

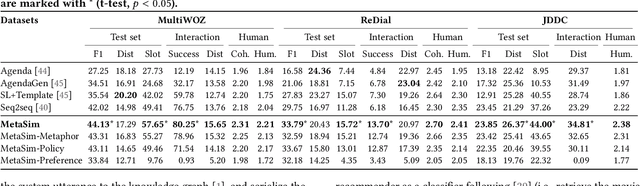
Task-oriented dialogue systems (TDSs) are assessed mainly in an offline setting or through human evaluation. The evaluation is often limited to single-turn or very time-intensive. As an alternative, user simulators that mimic user behavior allow us to consider a broad set of user goals to generate human-like conversations for simulated evaluation. Employing existing user simulators to evaluate TDSs is challenging as user simulators are primarily designed to optimize dialogue policies for TDSs and have limited evaluation capability. Moreover, the evaluation of user simulators is an open challenge. In this work, we proposes a metaphorical user simulator for endto-end TDS evaluation. We also propose a tester-based evaluation framework to generate variants, i.e., dialogue systems with different capabilities. Our user simulator constructs a metaphorical user model that assists the simulator in reasoning by referring to prior knowledge when encountering new items. We estimate the quality of simulators by checking the simulated interactions between simulators and variants. Our experiments are conducted using three TDS datasets. The metaphorical user simulator demonstrates better consistency with manual evaluation than Agenda-based simulator and Seq2seq model on three datasets; our tester framework demonstrates efficiency, and our approach demonstrates better generalization and scalability.
Generative Adversarial Network for Future Hand Segmentation from Egocentric Video
Mar 21, 2022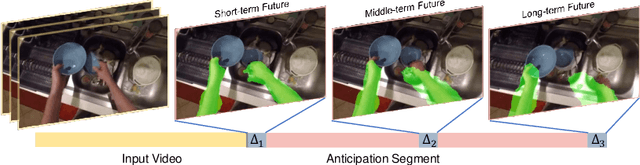
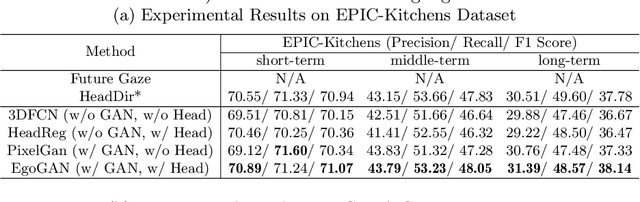
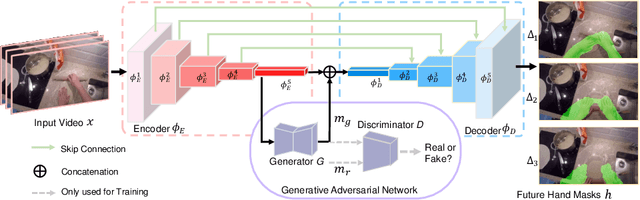
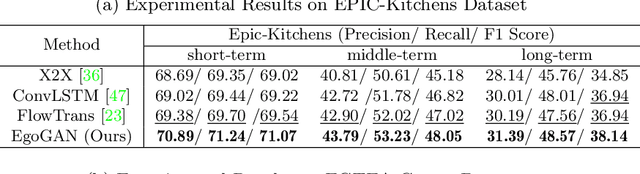
We introduce the novel problem of anticipating a time series of future hand masks from egocentric video. A key challenge is to model the stochasticity of future head motions, which globally impact the head-worn camera video analysis. To this end, we propose a novel deep generative model -- EgoGAN, which uses a 3D Fully Convolutional Network to learn a spatio-temporal video representation for pixel-wise visual anticipation, generates future head motion using Generative Adversarial Network (GAN), and then predicts the future hand masks based on the video representation and the generated future head motion. We evaluate our method on both the EPIC-Kitchens and the EGTEA Gaze+ datasets. We conduct detailed ablation studies to validate the design choices of our approach. Furthermore, we compare our method with previous state-of-the-art methods on future image segmentation and show that our method can more accurately predict future hand masks.
Towards Data-driven LQR with KoopmanizingFlows
Jan 27, 2022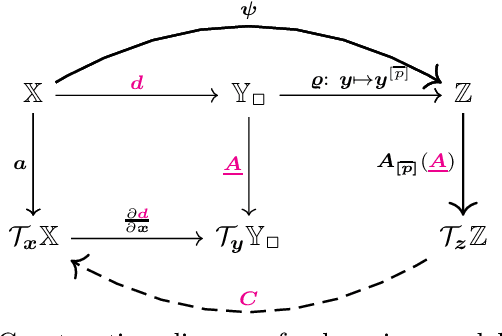
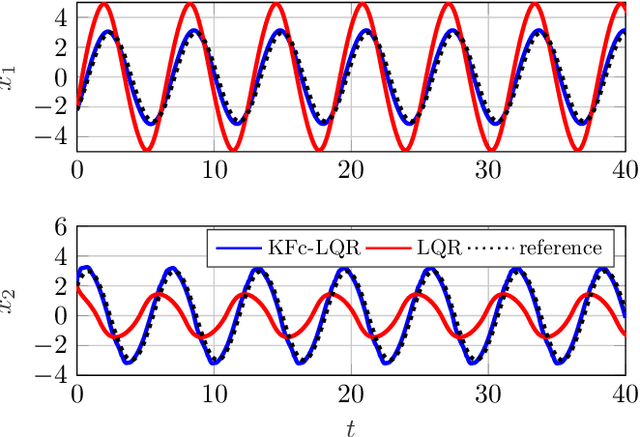
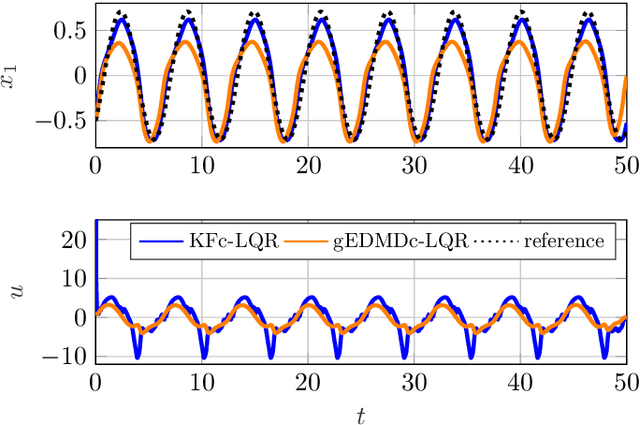
We propose a novel framework for learning linear time-invariant (LTI) models for a class of continuous-time non-autonomous nonlinear dynamics based on a representation of Koopman operators. In general, the operator is infinite-dimensional but, crucially, linear. To utilize it for efficient LTI control, we learn a finite representation of the Koopman operator that is linear in controls while concurrently learning meaningful lifting coordinates. For the latter, we rely on KoopmanizingFlows - a diffeomorphism-based representation of Koopman operators. With such a learned model, we can replace the nonlinear infinite-horizon optimal control problem with quadratic costs to that of a linear quadratic regulator (LQR), facilitating efficacious optimal control for nonlinear systems. The prediction and control efficacy of the proposed method is verified on simulation examples.
On The Cross-Modal Transfer from Natural Language to Code through Adapter Modules
Apr 19, 2022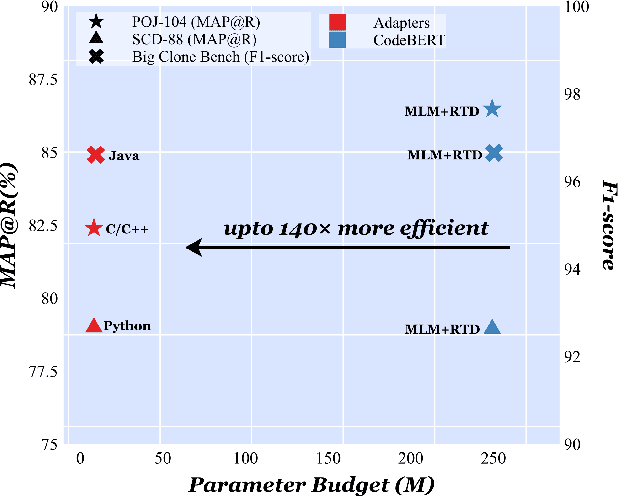
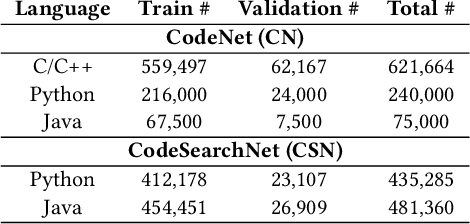
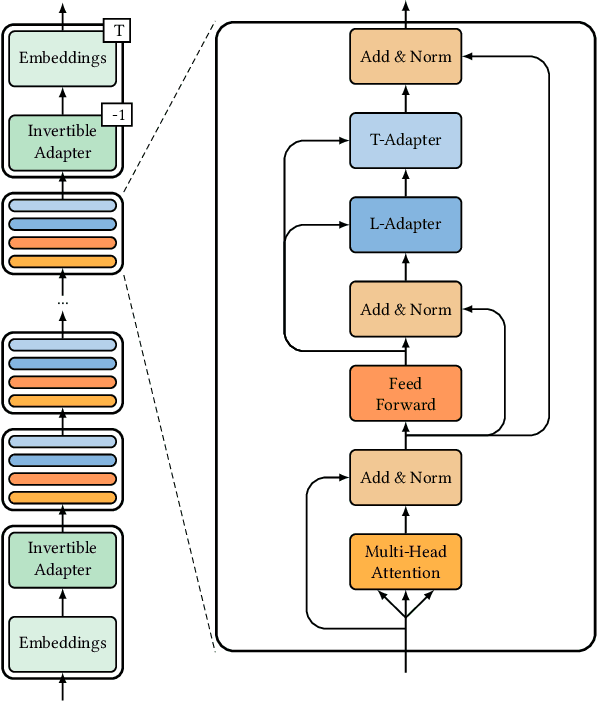
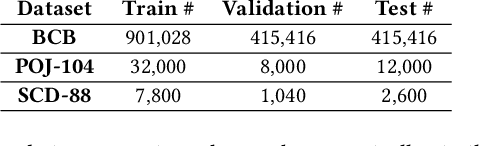
Pre-trained neural Language Models (PTLM), such as CodeBERT, are recently used in software engineering as models pre-trained on large source code corpora. Their knowledge is transferred to downstream tasks (e.g. code clone detection) via fine-tuning. In natural language processing (NLP), other alternatives for transferring the knowledge of PTLMs are explored through using adapters, compact, parameter efficient modules inserted in the layers of the PTLM. Although adapters are known to facilitate adapting to many downstream tasks compared to fine-tuning the model that require retraining all of the models' parameters -- which owes to the adapters' plug and play nature and being parameter efficient -- their usage in software engineering is not explored. Here, we explore the knowledge transfer using adapters and based on the Naturalness Hypothesis proposed by Hindle et. al \cite{hindle2016naturalness}. Thus, studying the bimodality of adapters for two tasks of cloze test and code clone detection, compared to their benchmarks from the CodeXGLUE platform. These adapters are trained using programming languages and are inserted in a PTLM that is pre-trained on English corpora (N-PTLM). Three programming languages, C/C++, Python, and Java, are studied along with extensive experiments on the best setup used for adapters. Improving the results of the N-PTLM confirms the success of the adapters in knowledge transfer to software engineering, which sometimes are in par with or exceed the results of a PTLM trained on source code; while being more efficient in terms of the number of parameters, memory usage, and inference time. Our results can open new directions to build smaller models for more software engineering tasks. We open source all the scripts and the trained adapters.